PySpark安装及WordCount实现(基于Ubuntu)
先盘点一下要安装哪些东西:
- VMware
- ubuntu 14.04(64位)
- Java环境(JDK 1.8)
- Hadoop 2.7.1
- Spark 2.4.0(Local模式)
- Pycharm
(一)Ubuntu
VMware 和 ubuntu 14.04(64位)的安装见:在vmware上安装ubuntu 14.04(64位)_study_note_mark的博客-CSDN博客
安装Ubuntu完成后需要完成一些前期准备工作,包括:创建Hadoop用户、更新apt、安装ssh及配置ssh无密码登录,参考:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
总结:
- 在Ubuntu里打开终端窗口的快捷键是 ctrl+alt+t
- sudo命令:sudo是ubuntu中一种权限管理机制,管理员可以授权给一些普通用户去执行一些需要root权限执行的操作。当使用sudo命令时,就需要输入您当前用户的密码
- 在Ubuntu终端窗口中,复制粘贴的快捷键需要加上shift,即粘贴是ctrl+shift+v
-
更改软件源:Ubuntu20.04更新软件源路径_ubuntu20.04软件和更新在哪_donnieliu的博客-CSDN博客
- vim编辑器:
- 正常模式:主要用来浏览文本内容。一开始打开vim都是正常模式。在任何模式下按下Esc键就可以返回正常模式
- 插入编辑模式:用来向文本中添加内容。在正常模式下,输入i键即可进入插入编辑模式
- 退出vim:如果有利用vim修改任何的文本,一定要记得保存。Esc键退回到正常模式中,然后输入:wq即可保存文本并退出vim
- ssh登录:类似于远程登录。可以登录某台Linux主机,并在上面运行命令
- 在Linux系统中,~ 代表的是用户的主文件夹,即 "/home/用户名" 这个目录,如你的用户名为 hadoop,则 ~ 就代表 "/home/hadoop/"
(二)Java(JDK 1.8)
参考Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
总结:
- 常见Linux命令:Linux系统常用命令_厦大数据库实验室博客
- Linux管道命令:Linux Shell中的管道命令_厦大数据库实验室博客
- vim编辑器用法:Linux系统中vim编辑器的安装和使用方法_厦大数据库实验室博客
(三)Hadoop 2.7.1
Hadoop安装、伪分布式配置、启动Yarn参考Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)_厦大数据库实验室博客
总结:
- Hadoop默认模式为非分布式模式(本地模式),即单Java进程,无需进行其他配置即可运行
- Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时读取的是HDFS中的文件
- 运行Hadoop程序时,为了防止覆盖结果,程序指定的输出目录(如output)不能存在,否则会提示错误,因此运行前需要先删除输出目录(如hdfs dfs -rm -r output)
- 三种shell命令方式:
- hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
- hadoop dfs:只能适用于HDFS文件系统
- hdfs dfs:只能适用于HDFS文件系统
- 若要关闭Hadoop,运行stop-dfs.sh;下次启动Hadoop,无需进行NameNode初始化,只需运行start-dfs.sh(仅仅启动了MapReduce环境,没有启动YARN)
- 通过hdfs命令可以访问HDFS的内容
http://localhost:50070/dfshealth.html#tab-overview
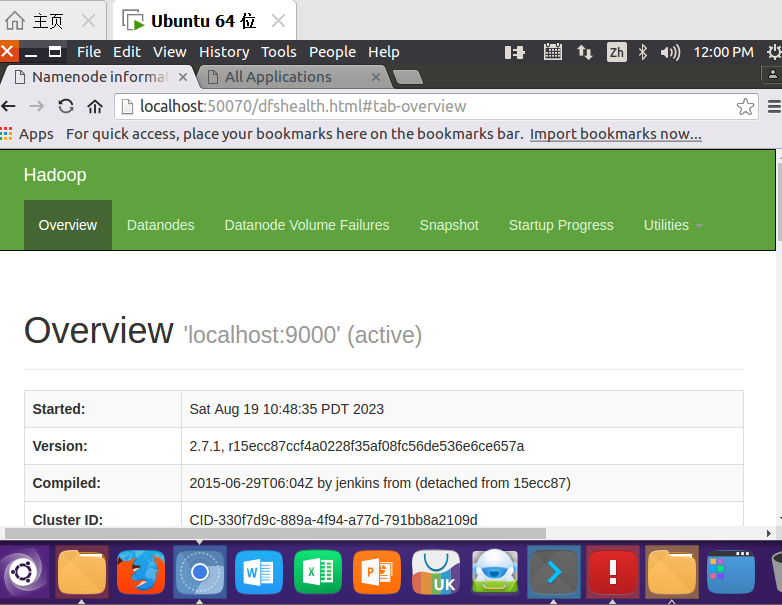
YARN(Yet Another Resource Negotiator)是从MapReduce中分离出来的,负责资源管理与任务调度。YARN运行于MapReduce之上,提供了高可用性、高扩展性
启动YARN之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用YARN时,是 "mapred.LocalJobRunner" 在跑任务;启用YARN之后,是 "mapred.YARNRunner" 在跑任务。启动YARN有个好处是可以通过Web界面查看任务的运行情况:http://localhost:8088/cluster

启动/关闭YARN的脚本:
start-yarn.sh # 启动YARN
mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver如果需要安装Hadoop集群,参考Hadoop 2.7分布式集群环境搭建_厦大数据库实验室博客
(四)Spark 2.4.0(Local模式)
Apache Spark是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。Spark最大的特点就是快,可比Hadoop MapReduce的处理速度快100倍
Spark采用Local模式进行安装,也就是在单机上运行Spark。因此,在安装Hadoop时,需要按照伪分布式模式进行安装。在单台机器上按照“Hadoop(伪分布式)+Spark(Local模式)”这种方式进行Hadoop和Spark组合环境的搭建,可以较好满足入门级Spark学习的需求
Index of /dist/spark/spark-2.4.0
参考以下链接中 “安装Spark(Local模式)” 部分即可(这篇帖子是Spark 3.4.0,但原理相同):Spark安装和编程实践(Spark3.4.0)_厦大数据库实验室博客
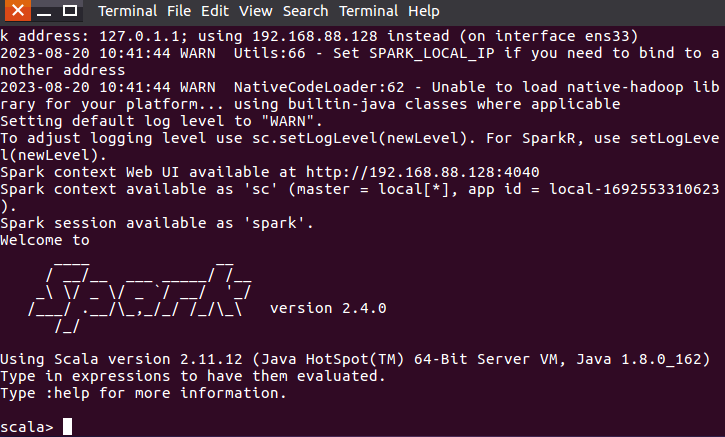
cd /usr/local/spark
bin/spark-shellSpark Shell界面如下,不过是以Scala为交互语言(Ctrl+c退出):
进入Pyspark:
cd /usr/local/spark
./bin/pyspark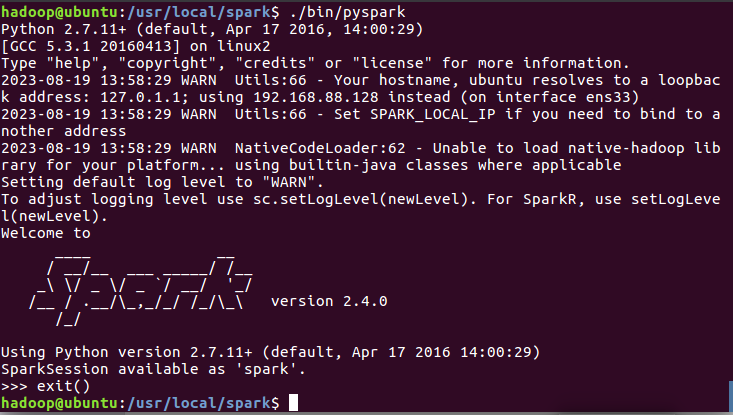
总结:
- bash和shell的区别:
- shell:负责人机交互的一种抽象,接收用户输入交给内核,内核执行完后返回给用户。有多种实现,sh/bash/csh/ksh/ash,当前用户登录后操作系统会用哪种shell,是由配置文件中对应用户的配置来决定的,可由echo $SHELL查看
- bash:shell的一种实现(/bin/bash)。用户远程连接后,操作系统会默认生成一个bash进程

(五)PyCharm
Download PyCharm: Python IDE for Professional Developers by JetBrains
安装参考:使用Pycharm开发Spark应用程序(以WordCount为例)_厦大数据库实验室博客 以及
第一章 python分布式爬虫打造搜索引擎环境搭建 第一节 CentOS7环境下pycharm的安装和使用_Demon丶冷漠的博客-CSDN博客
安装过程中我遇到一个报错如下:

解决方法是新开一个terminal再执行命令,参考linux安装pycharm报错:Unable to detect graphics environment_pycharm unable to detect graphics environment_我有明珠一颗的博客-CSDN博客
编辑hosts文件时遇到以下两个问题,原因是权限不足:
vim 修改文件出现错误 “ E45: ‘readonly’ option is set (add to override)“_大红烧肉的博客-CSDN博客
Linux使用vi编辑文件报错:E212: Can‘t open file for writing Press ENTER or type command to continue_/ect/hosts" e212: can't open file for writing_凝眸伏笔的博客-CSDN博客
(六)案例(以WordCount为例)
参考:使用Pycharm开发Spark应用程序(以WordCount为例)_厦大数据库实验室博客
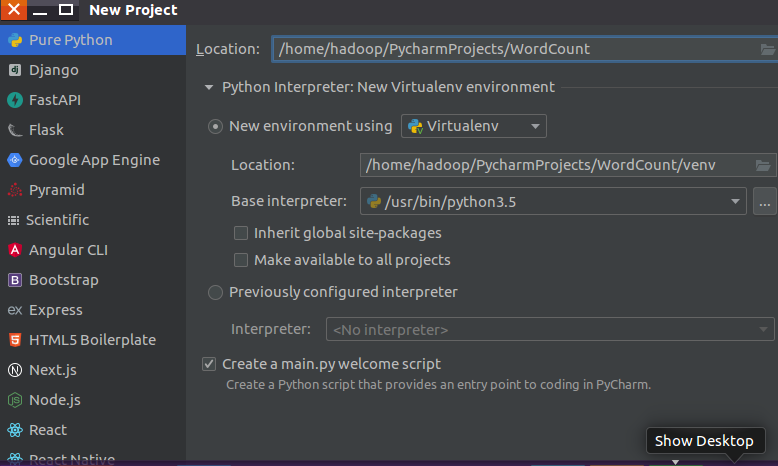
启动pycharm:

创建文件夹(注意Base interpreter选择的是 /usr/bin/python3.5):
上传word.txt文件(本地地址为/home/hadoop/Downloads/word.txt)至HDFS(创建一个文件夹aaa,上传至aaa文件夹下)
hadoop fs -ls # 查看hdfs下的文件
hdfs dfs -mkdir /aaa # 创建一个目录aaa
hdfs dfs -put /home/hadoop/Downloads/word.txt /aaa # 上传word.txt文件至aaa文件夹下
hadoop fs -ls /aaa # 检查是否上传成功# 三种shell命令方式:
# hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
# hadoop dfs:只能适用于HDFS文件系统
# hdfs dfs:只能适用于HDFS文件系统打开HDFS:
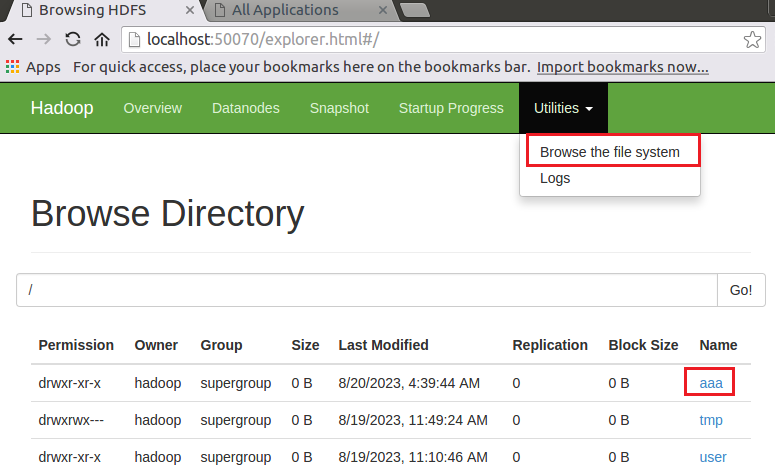
关于HDFS的一些操作可以参考:如何上传文件到hdfs?_数据上传至hdfs://crash目录下_你看这人,真菜的博客-CSDN博客
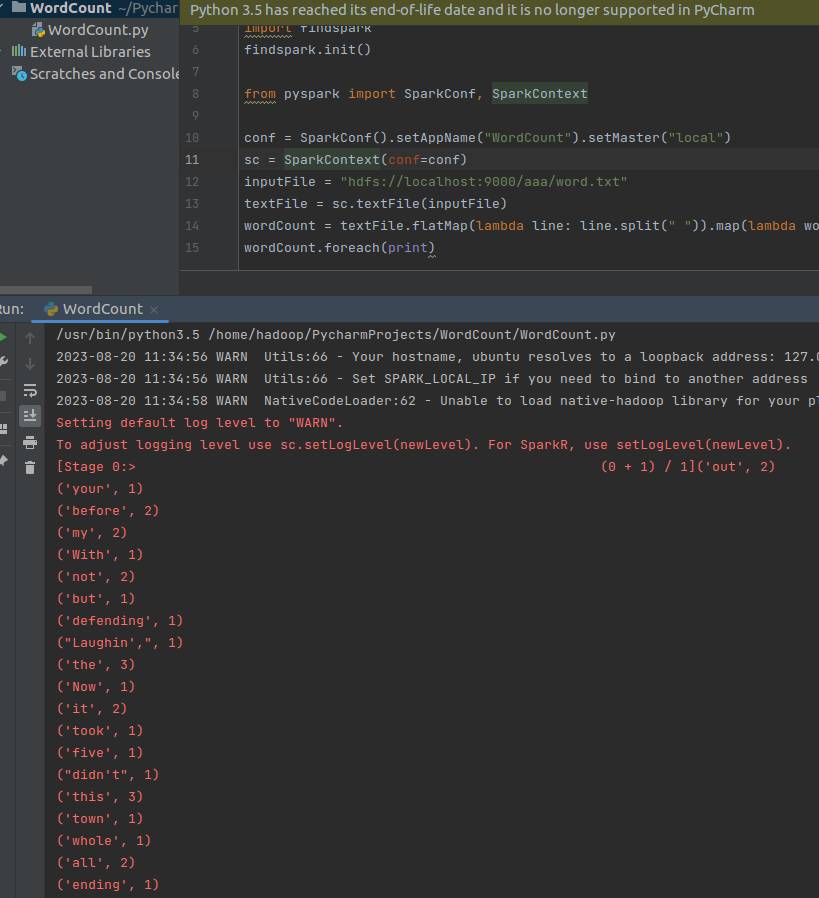
WordCount.py代码如下:
# -*- coding:utf8-*-
# 安装pyspark:在终端输入pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pysparkimport os
os.environ['PYSPARK_PYTHON'] = '/usr/bin/python3.5' # python解释器路径import findspark
findspark.init()from pyspark import SparkConf, SparkContextconf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = "hdfs://localhost:9000/aaa/word.txt" # 文件放在hdfs伪分布式文件系统上(必须开启hdfs文件系统)
textFile = sc.textFile(inputFile)
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
wordCount.foreach(print)- flatMap:将文件按空格进行拍扁
- map:将拍扁后的一个个单词分别映射成 (word, 1) 的形式
- reduceByKey:将map输出中key相同的值加起来
- foreach:循环遍历打印输出结果

(1)右键运行。运行结果如下:
(2)也可以把代码提交到Spark运行。在终端运行:
cd /usr/local/spark/
./bin/spark-submit /home/hadoop/PycharmProjects/WordCount/WordCount.py翻一下我们的输出信息可以找到结果:
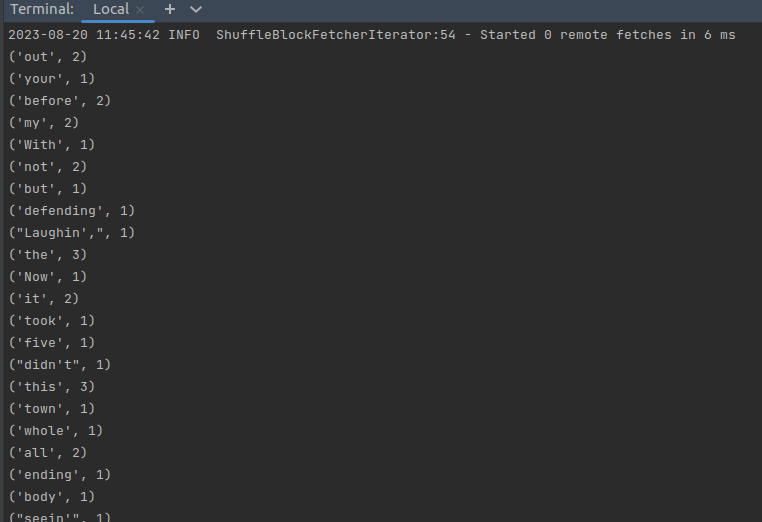
注:Spark & PySpark 的执行可以特别详细,很多INFO日志消息都会打印到屏幕。开发过程中,这非常恼人,因为可能丢失Python栈跟踪或者print的输出。为了减少Spark输出,可以设置$SPARK_HOME/conf 下的log4j
cd /usr/local/spark/conf
cp log4j.properties.template log4j.properties
vim log4j.properties
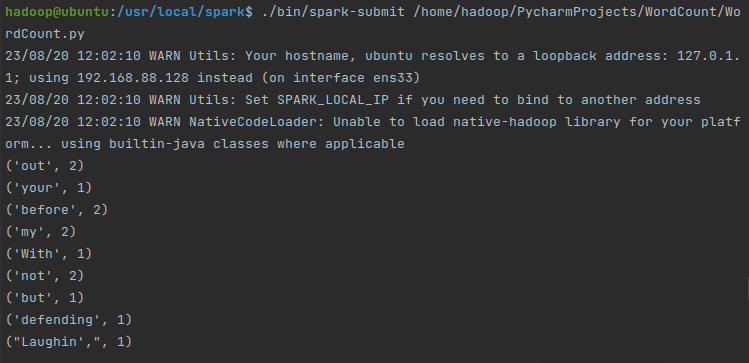
将 log4j.rootCategory=INFO, console 中的 INFO 改为 WARN 或者 ERROR,保存退出,如下图:

再运行,输出结果就一目了然了:
更多案例参考:
基于Python语言的Spark数据处理分析案例集锦(PySpark)_厦大数据库实验室博客
更多大数据相关博客:大数据_厦大数据库实验室博客
相关文章:
PySpark安装及WordCount实现(基于Ubuntu)
先盘点一下要安装哪些东西: VMwareubuntu 14.04(64位)Java环境(JDK 1.8)Hadoop 2.7.1Spark 2.4.0(Local模式)Pycharm (一)Ubuntu VMware 和 ubuntu 14.04(…...
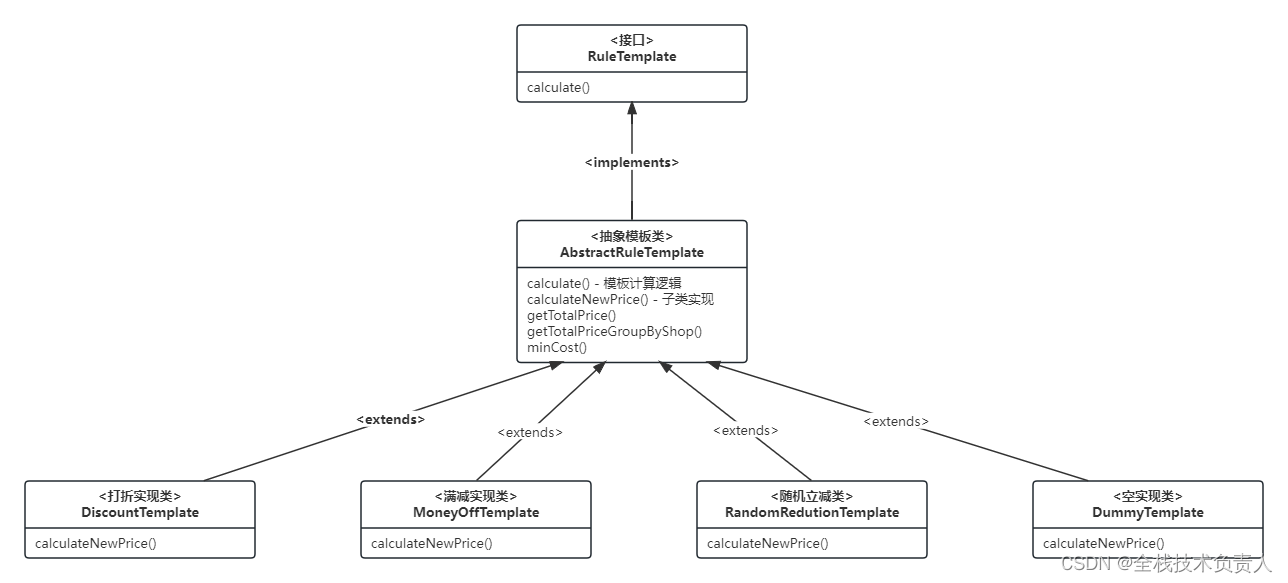
SpringBoot 模板模式实现优惠券逻辑
一、计算逻辑的类结构图 在这张图里,顶层接口 RuleTemplate 定义了 calculate 方法,抽象模板类 AbstractRuleTemplate 将通用的模板计算逻辑在 calculate 方法中实现,同时它还定义了一个抽象方法 calculateNewPrice 作为子类的扩展点。各个具…...
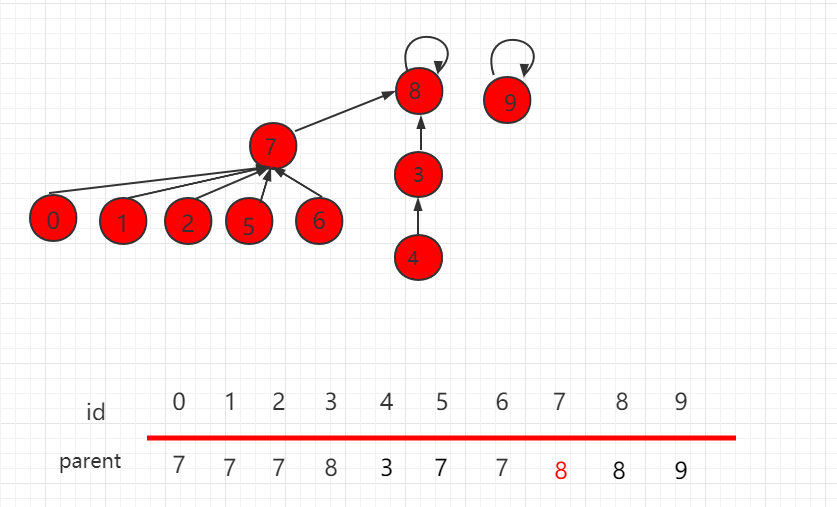
并查集 rank 的优化(Java 实例代码)
目录 并查集 rank 的优化 Java 实例代码 UnionFind3.java 文件代码: 并查集 rank 的优化 上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。 根据上一小节&…...

TDA4超级玩家浮出水面,行泊一体功能、成本刷到极致
2023年以来,智能驾驶市场进入L2普及、高阶ADAS功能(NOA)大规模量产的新周期,降本增效,打造极致性价比、提升用户体验等,成为了竞争的焦点。 其中,替换更具性价比的硬件平台、传感器复用、系统优…...

3分钟了解Android中稳定性测试
一、什么是Monkey Monkey在英文里的含义是猴子,在测试行业的学名叫“猴子测试”,指的是没有测试经验的人甚至是根本不懂计算机的人(就像一只猴子),不需要知道程序的任何用户交互方面的知识,给他一个程序&a…...
LVS-DR+keepalived实现高可用负载群集
VRRP 通信原理: VRRP就是虚拟路由冗余协议,它的出现就是为了解决静态路由的单点故障。 VRRP是通过一种竞选的一种协议机制,来将路由交给某台VRRP路由。 VRRP用IP多播的方式(多播地址224.0.0.18)来实现高可用的通信&…...

阿里云国际版注册教程
什么是阿里云国际版? 阿里云国际版是阿里云专为海外客户供给的服务器及核算资源,涵盖了云主机、弹性裸金属服务器、容器服务、数据库及安全和监控等一系列云核算解决方案。 与其他云核算服务供给商不同,阿里云国际版在安全性、稳定性、性能方…...

基于百度文心大模型创作的实践与谈论
文心概念 百度文心大模型源于产业、服务于产业,是产业级知识增强大模型。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的AI底座,大幅降低了AI开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型…...
)
Java基础知识题(五)
系列文章目录 Java基础知识题(一) Java基础知识题(二) Java基础知识题(三) Java基础知识题(四) Java基础知识题(五) 文章目录 系列文章目录 前言 一 Java的数据连接——JDBC 1. 简述什么是JDBC?重点 2. JDBC PreparedStatement比Statement有什么优势&…...

攻防世界-fileinclude
原题 解题思路 题目已经告诉了,flag在flag.php中,先查看网页源代码(快捷键CTRLU)。 通过抓包修改,可以把lan变量赋值flag。在cookie处修改。新打开的网页没有cookie,直接添加“Cookie: languagephp://filte…...
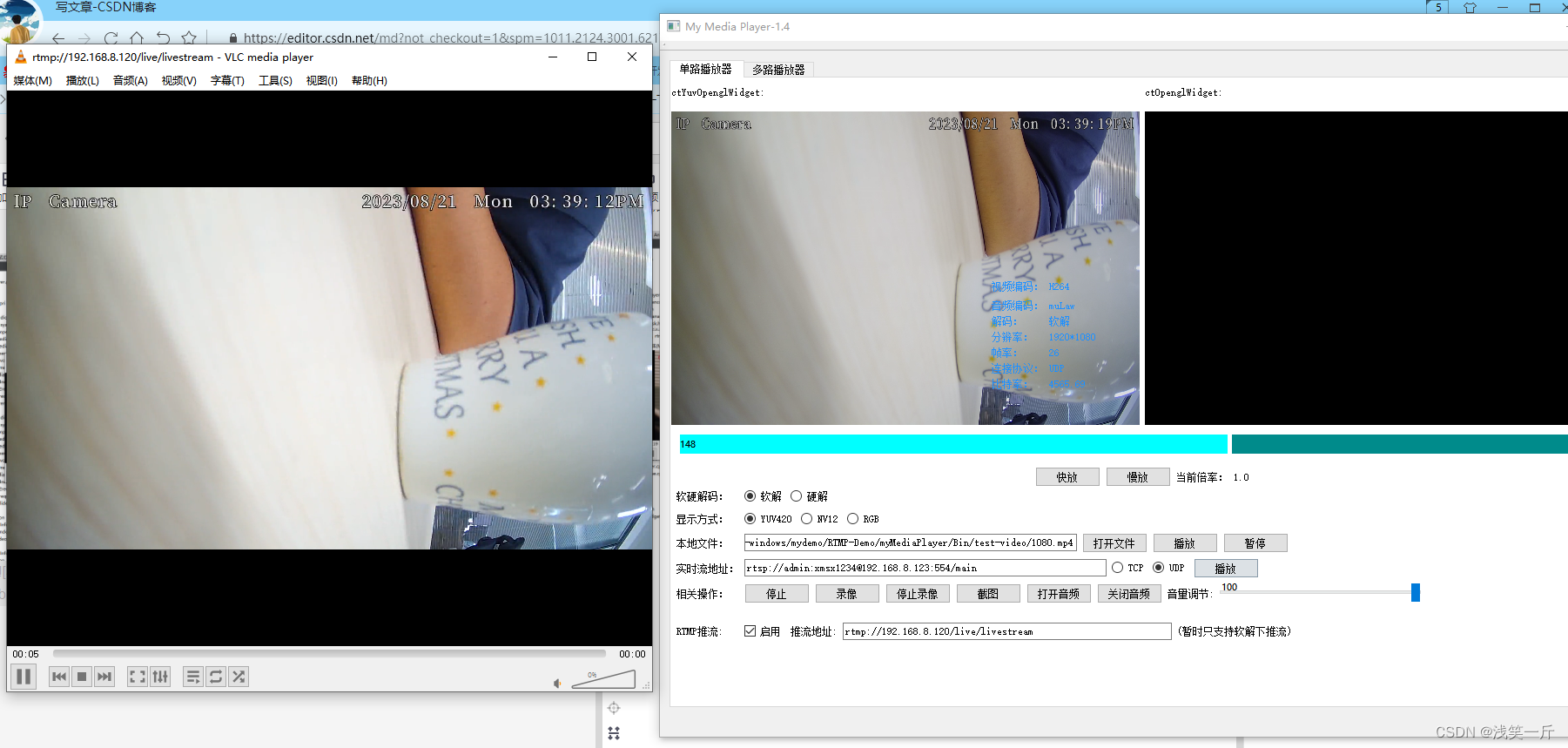
流媒体服务器SRS的搭建及QT下RTMP推流客户端的编写
一、前言 目前市面上有很多开源的流媒体服务器解决方案,常见的有SRS、EasyDarwin、ZLMediaKit和Monibuca。这几种的对比如下: (本图来源:https://www.ngui.cc/zz/1781086.html?actiononClick) 二、SRS的介绍 SRS&am…...
)
Effective C++条款11——在operator=中处理“自我赋值”(构造/析构/赋值运算)
“自我赋值”发生在对象被赋值给自己时: class Widget {}; Widget w; // ... w w; // 赋值给自己 这看起来有点愚蠢,但它合法,所以不要认定客户绝不会那么做。此外赋值动作并不总是那么可被一眼辨识出来,例如: a[i] a[j]; …...
-气泡图(一))
可视化绘图技巧100篇基础篇(八)-气泡图(一)
目录 前言 适用场景 图例 绘图工具及代码实现 EXCEL 1、单轴气泡图...

Elasticsearch查询之Disjunction Max Query
前言 Disjunction Max Query 又称最佳 best_fields 匹配策略,用来优化当查询关键词出现在多个字段中,以单个字段的最大评分作为文档的最终评分,从而使得匹配结果更加合理 写入数据 如下的两条例子数据: docId: 1 title: java …...
Lock wait timeout exceeded; try restarting transaction的错误
文章目录 一、异常发现二、异常定位1、锁表语句确认2、实际场景排查三、解决思路1、本次解决方式2、其他场景解决思路扩展1、【治标方法】innodb_lock_wait_timeout 锁定等待时间改大2、【治标方法】事务信息查询3、【治标方法】如果杀掉线程依然不能解决,可以查找执行线程耗时…...

ShardingSphere01-docker环境安装
使用docker安装数据库是一个非常好的选择,后续的读写分离、数据分片等功能的数据库都是由docker创建。 一、安装准备 1、前提条件 Docker可以运行在Windows、Mac、CentOS、Ubuntu等操作系统上 Docker支持以下的CentOS版本: CentOS 7 (64-bit)CentOS …...
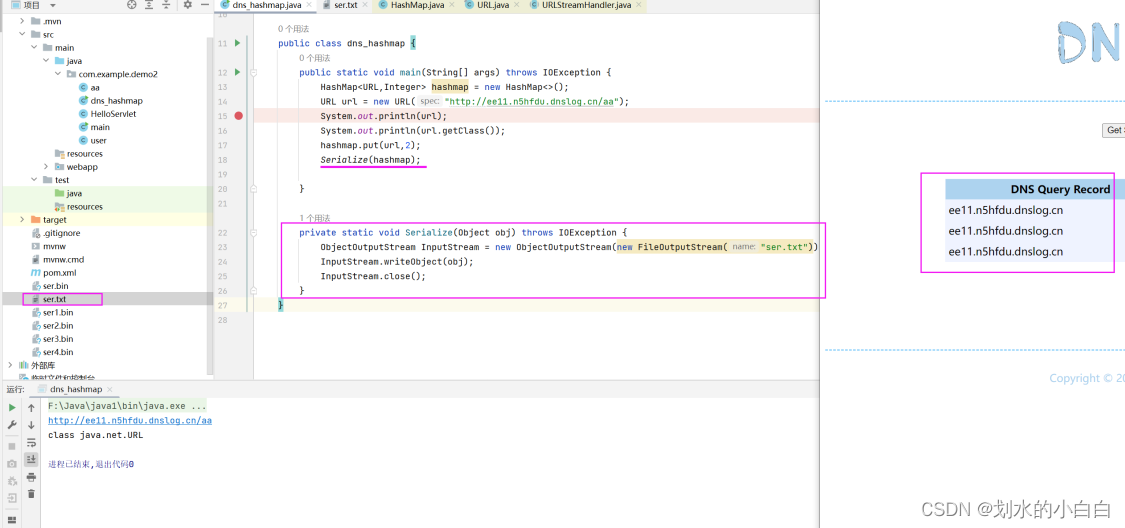
Java代码审计13之URLDNS链
文章目录 1、简介urldns链2、hashmap与url类的分析2.1、Hashmap类readObject方法的跟进2.2、URL类hashcode方法的跟进2.3、InetAddress类的getByName方法 3、整个链路的分析3.1、整理上述的思路3.2、一些疑问的测试3.3、hashmap的put方法分析3.4、反射3.5、整个代码 4、补充说明…...

区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列…...

Python面向对象植物大战僵尸
先来一波效果图 来看看如何设计游戏架构 import sysimport pygameclass BaseSprite(pygame.sprite.Sprite):def __init__(self, name):super().__init__()self.image pygame.image.load(name)self.rect self.image.get_rect()class AnimateSprite(BaseSprite):def __init__(…...
)
大屏模板,增加自适应(包含websocket)
1、简单的Node服务端 const WebSocket require(ws);// 创建 WebSocket 服务器 const wss new WebSocket.Server({ port: 8888 });const getHeader (protocol) > {const protocolArr protocol.split(,)const headers {};for (let i 0; i < protocolArr.length; i …...

Nanbeige 4.1-3B专属UI实战:一键部署沉浸式游戏风格聊天应用
Nanbeige 4.1-3B专属UI实战:一键部署沉浸式游戏风格聊天应用 1. 项目概述与核心价值 南北阁(Nanbeige)4.1-3B是一款性能优异的中英双语大语言模型,而今天我们要介绍的是为其量身打造的专属Web交互界面。这个界面最特别之处在于&…...

解决QGroundControl或华科尔地面站因QT版本冲突导致的启动失败问题
1. 当QGroundControl或华科尔地面站打不开时该怎么办 遇到QGroundControl或华科尔地面站安装后无法启动的问题,很多用户第一反应是软件安装包损坏了。但实际上,这很可能是由于QT框架版本冲突导致的。QT是一个跨平台的C图形用户界面应用程序开发框架&…...

OpenClaw多模型切换指南:Qwen3-32B与其他镜像协同工作
OpenClaw多模型切换指南:Qwen3-32B与其他镜像协同工作 1. 为什么需要多模型切换? 去年冬天,当我第一次尝试用OpenClaw自动化处理公司周报时,发现单一模型很难同时满足"数据分析"和"文案润色"两种需求。Qwen…...

AgentCPM深度研报助手C语言文件操作实战:批量处理本地研报文本文件
AgentCPM深度研报助手C语言文件操作实战:批量处理本地研报文本文件 你是不是也遇到过这样的场景?手头有一堆下载好的行业研报,有PDF,有TXT,堆在文件夹里。想快速了解每份报告的核心观点,但一份份打开看&am…...

AnotherRedisDesktopManager:让Redis管理变得简单高效的5个理由
AnotherRedisDesktopManager:让Redis管理变得简单高效的5个理由 【免费下载链接】AnotherRedisDesktopManager qishibo/AnotherRedisDesktopManager: Another Redis Desktop Manager 是一款跨平台的Redis桌面管理工具,提供图形用户界面,支持连…...

Qwen3-Embedding国产化部署
从单一型人才到AI带领下的复合型人才 1.1 传统职能的终结 传统软件公司怎么干的? 销售、售前、交付、研发、市场、运维——各司其职,职能清晰。看起来很专业,但实际上是什么?一堆冗余的角色在等活干。 这不是高效,这是…...

制造业数据库选型实战:为什么我们从 MySQL 迁移到 TiDB
写在前面 作为一个制造业数字化团队的开发负责人,我最怕听到的一句话就是:“数据库又慢了”。 MOM 平台上线 4 年,数据量从最初的几百 G 涨到几个 T。每次月底报表、跨工厂查询,系统就开始”喘气”。加索引、拆表、优化 SQL………...

OpenClaw怎么集成?OpenClaw移动云小白6分钟搭建及使用指南【最新!】
OpenClaw怎么集成?OpenClaw移动云小白6分钟搭建及使用指南【最新!】。OpenClaw怎么部署?本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程&#…...

【人物传记】唯一一位两次获得诺贝尔物理学奖-约翰·巴
1 约翰巴丁简介 约翰巴丁(英语:John Bardeen,1908年5月23日—1991年1月30日[6])是一名美国物理学家和工程师。他是唯一一个两度获得诺贝尔物理学奖的人:第一次是在1956年与威廉肖克利和沃尔特布拉顿一起发明晶体管&am…...

QGIS 3.28 保姆级配置指南:从中文界面到高德底图,手把手搞定智驾地图工作流
QGIS 3.28 智能驾驶地图工程师开箱指南:从零构建高精度工作流 刚拿到工牌的智能驾驶地图工程师小李,面对全新的QGIS界面有些手足无措。作为空间数据处理的核心工具,QGIS的配置直接决定了后续高精地图生产的效率与精度。本文将带你完成从软件…...