pytorch内存泄漏
问题描述:
内存泄漏积累过多最终会导致内存溢出,当内存占用过大,进程会被killed掉。
解决过程:
在代码的运行阶段输出内存占用量,观察在哪一块存在内存剧烈增加或者显存异常变化的情况。但是在这个过程中要分级确认问题点,也即如果存在三个文件main.py、train.py、model.py。
在此种思路下,应该先在main.py中确定问题点,然后,从main.py中进入到train.py中,再次输出显存占用量,确定问题点在哪。随后,再从train.py中的问题点,进入到model.py中,再次确认。如果还有更深层次的调用,可以继续追溯下去。
import psutil
process = psutil.Process()
current_memory = process.memory_info().rss
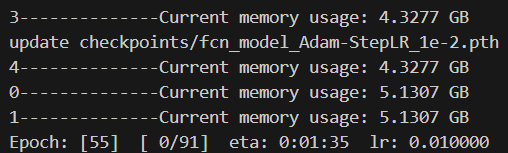
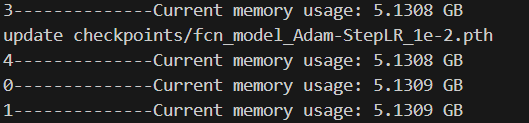
print(f"0--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")
具体使用的代码
for epoch in range(start_epoch+1, args.epochs+1):process = psutil.Process()current_memory = process.memory_info().rssprint(f"0--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")count_step = (epoch-1)*len(train_loader) print(f"1--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")mean_loss, lr = train_one_epoch(model, optimizer, train_loader, device, epoch, count_step,writer,lr_scheduler,print_freq=args.print_freq)print(f"2--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")val_info = evaluate_vgg(model, epoch, val_loader, device, writer, num_classes=num_classes)print(f"3--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")with open(results_file, "a") as f:# 记录每个epoch对应的train_loss、lr以及验证集各指标 train_info = f"[epoch: {epoch}]\n" \f"train_loss: {mean_loss:.4f}\n" \f"lr: {lr:.6f}\n"f.write(train_info + val_info + "\n\n")save_vgg_file = {"model": model.state_dict(),"optimizer": optimizer.state_dict(),# "lr_scheduler": lr_scheduler.state_dict(),"epoch": epoch,"args": args}torch.save(save_vgg_file, 'checkpoints/fcn_model_Adam-StepLR_1e-2.pth')print(f"update checkpoints/fcn_model_Adam-StepLR_1e-2.pth")print(f"4--------------Current memory usage: {current_memory / (1024 ** 3):.4f} GB")
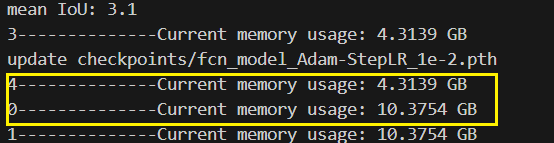
每个epoch训练完之后所占内存会不断增加,也就是说,每轮跑完之后会有冗余的数据一直在消耗内存。于是criterion、train_one_epoch、evaluate三个部分
criterion部分
Mem usage:5310 MiB
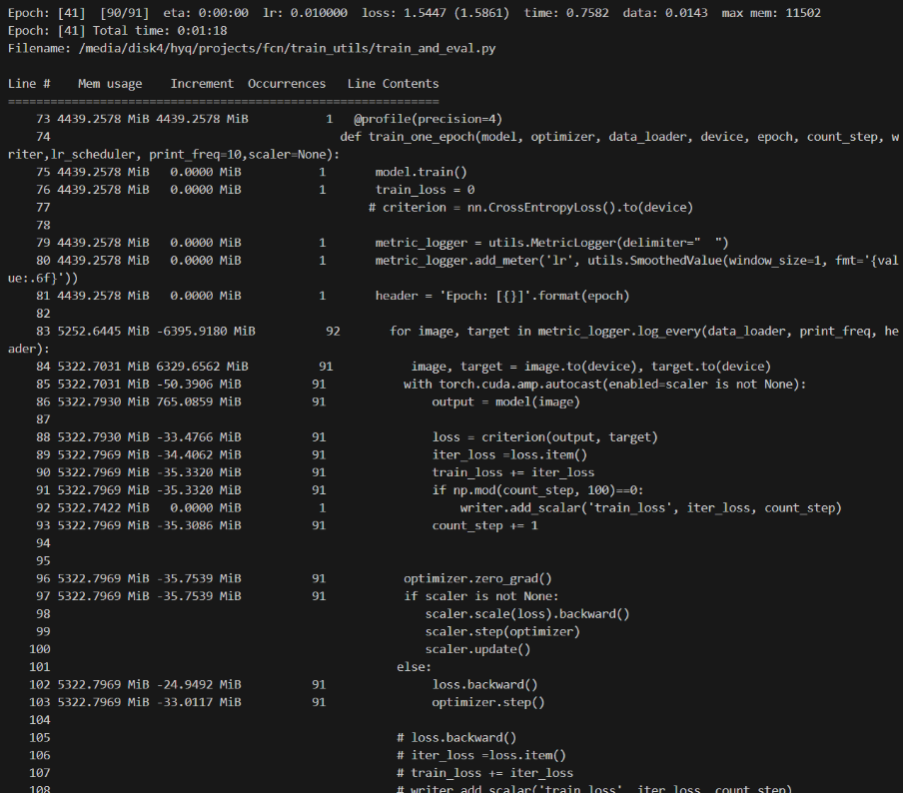
train_one_epoch部分
Mem usage:4439 MiB
evaluate部分
Mem usage:10644
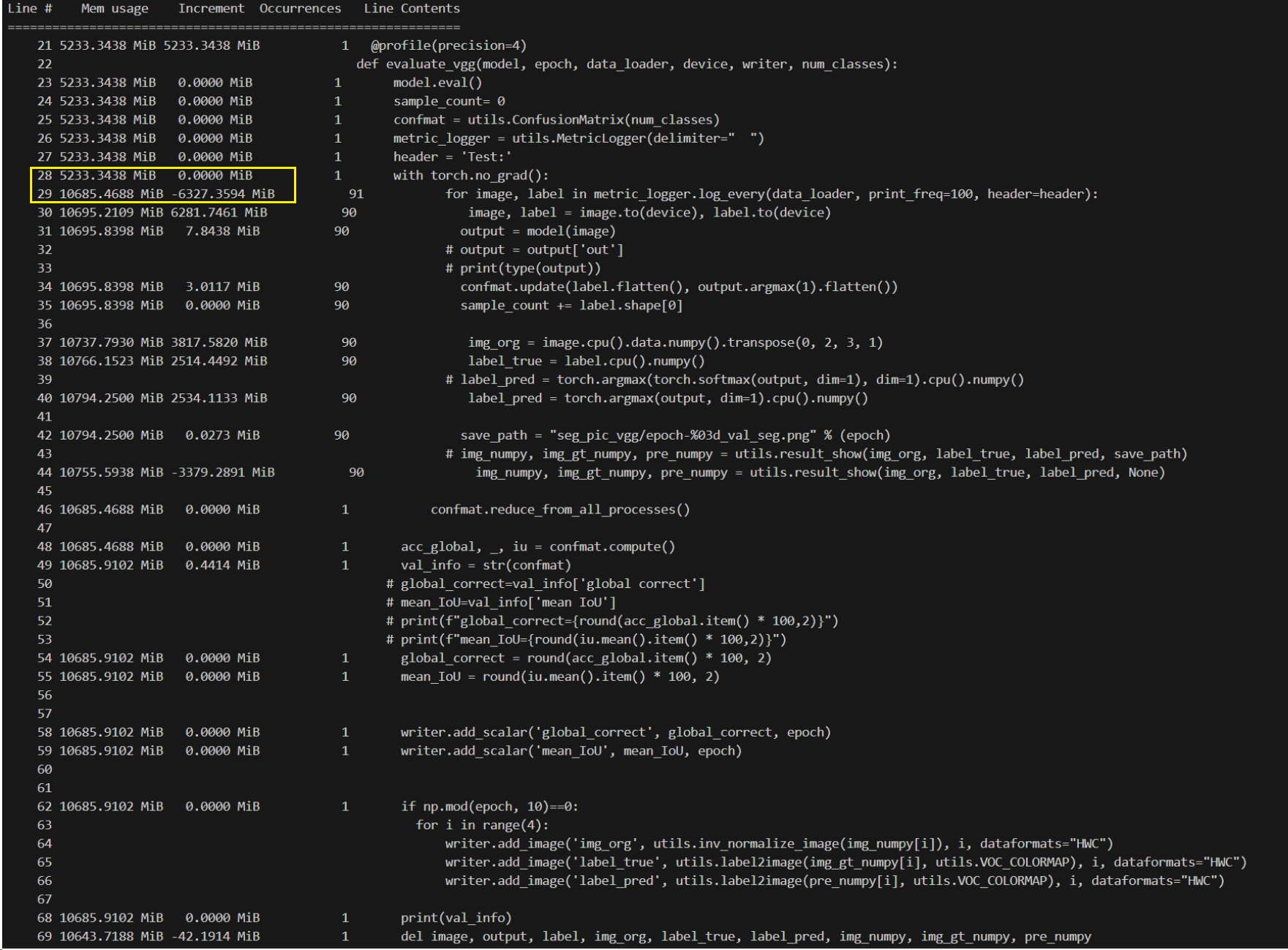
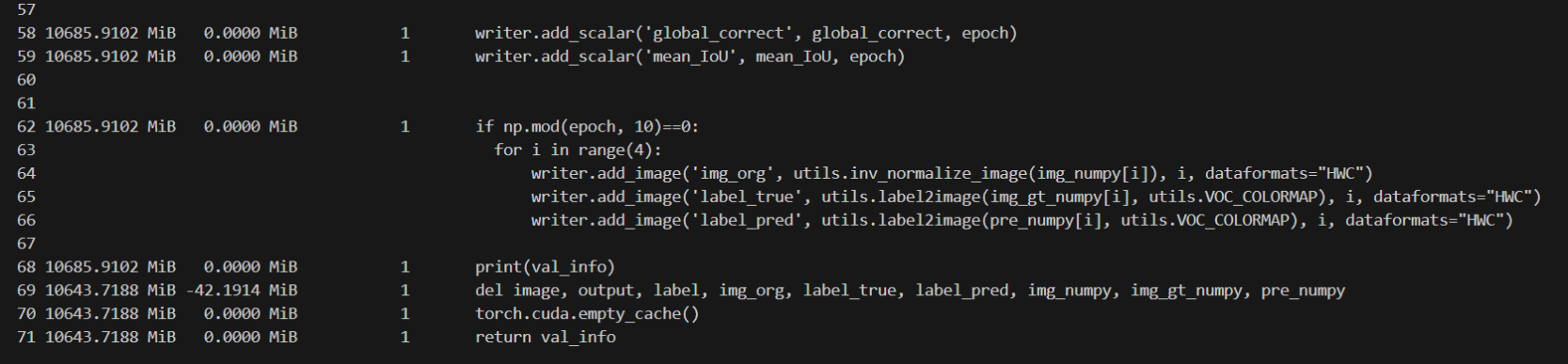
在evaluate部分可以看到,所占用内存突然增大,并且之后的代码也占用了大量内存,继续监控得知在下一个epoch中criterion部分占用内存也是16064MiB,由此推测出内存消耗在evaluate部分。
解决办法:
删除变量数据在for循环外,把暂时不用的可视化代码注释掉,发现占用内存变化很小
解决pytorch训练时的显存占用递增的问题
Pytorch训练过程中,显存(内存)爆炸解决方法
Python代码优化工具——memory_profiler
相关文章:
pytorch内存泄漏
问题描述: 内存泄漏积累过多最终会导致内存溢出,当内存占用过大,进程会被killed掉。 解决过程: 在代码的运行阶段输出内存占用量,观察在哪一块存在内存剧烈增加或者显存异常变化的情况。但是在这个过程中要分级确认…...
)
20230821-字符串相乘-给树命名(unordered_map)
字符串相乘 有两个非负整数字符串num1,num2,计算num1和num2所表达整数的乘积,结果以字符串形式存储。注意:不能通过强制转换方法解题。 示例1: 输入: "4", "3" 输出: "12" …...

[Go版]算法通关村第十二关黄金——字符串冲刺题
目录 题目:最长公共前缀解法1:纵向对比-循环内套循环写法复杂度:时间复杂度 O ( n ∗ m ) O(n*m) O(n∗m)、空间复杂度 O ( 1 ) O(1) O(1)Go代码 解法2:横向对比-两两对比(类似合并K个数组、合并K个链表)复…...

neovim为工作区添加本地clangd配置
1 背景 尝试使用neovim开发stm32,使用clangd作为LSP提供代码补全等功能。 2 思路 使用stm32cubeMX生成一个基于makefile的stm32工程。 使用bear或compiledb基于makefile生成compile_commands.json文件。 为clangd配置--query-driver选项,使其使用arm…...
信号处理--基于EEG脑电信号的眼睛状态的分析
本实验为生物信息学专题设计小项目。项目目的是通过提供的14导联EEG 脑电信号,实现对于人体睁眼和闭眼两个状态的数据分类分析。每个脑电信号的时长大约为117秒。 目录 加载相关的库函数 读取脑电信号数据并查看数据的属性 绘制脑电多通道连接矩阵 绘制两类数据…...
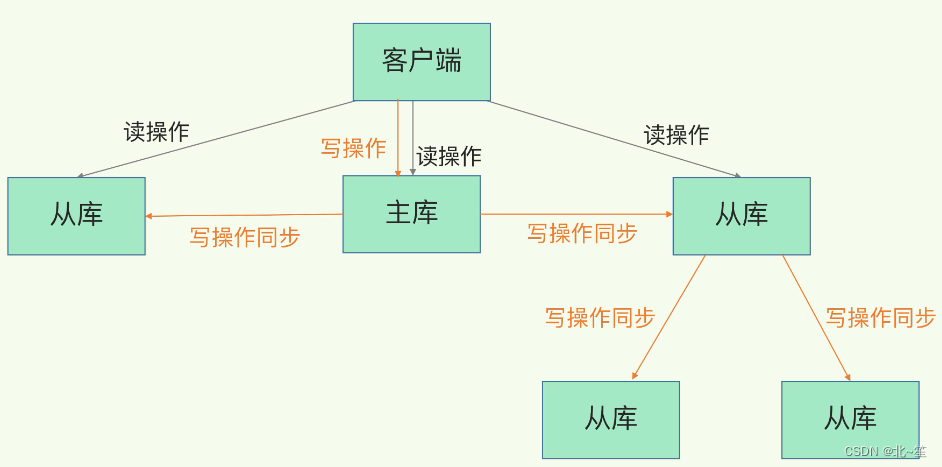
Redis高可用:主从复制详解
目录 1.什么是主从复制? 2.优势 3.主从复制的原理 4.全量复制和增量复制 4.1 全量复制 4.2 增量复制 5.相关问题总结 5.1 当主服务器不进行持久化时复制的安全性 5.2 为什么主从全量复制使用RDB而不使用AOF? 5.3 为什么还有无磁盘复制模式ÿ…...
 {})报错?)
[Flutter]有的时候调用setState(() {})报错?
先看FlutterSDK的原生类State中有一个变量mounted。 abstract class State<T extends StatefulWidget> with Diagnosticable {/// mounted的作用是,此State对象当前是否在树中。/// 在创建State对象之后,在调用initState之前,框架通过…...
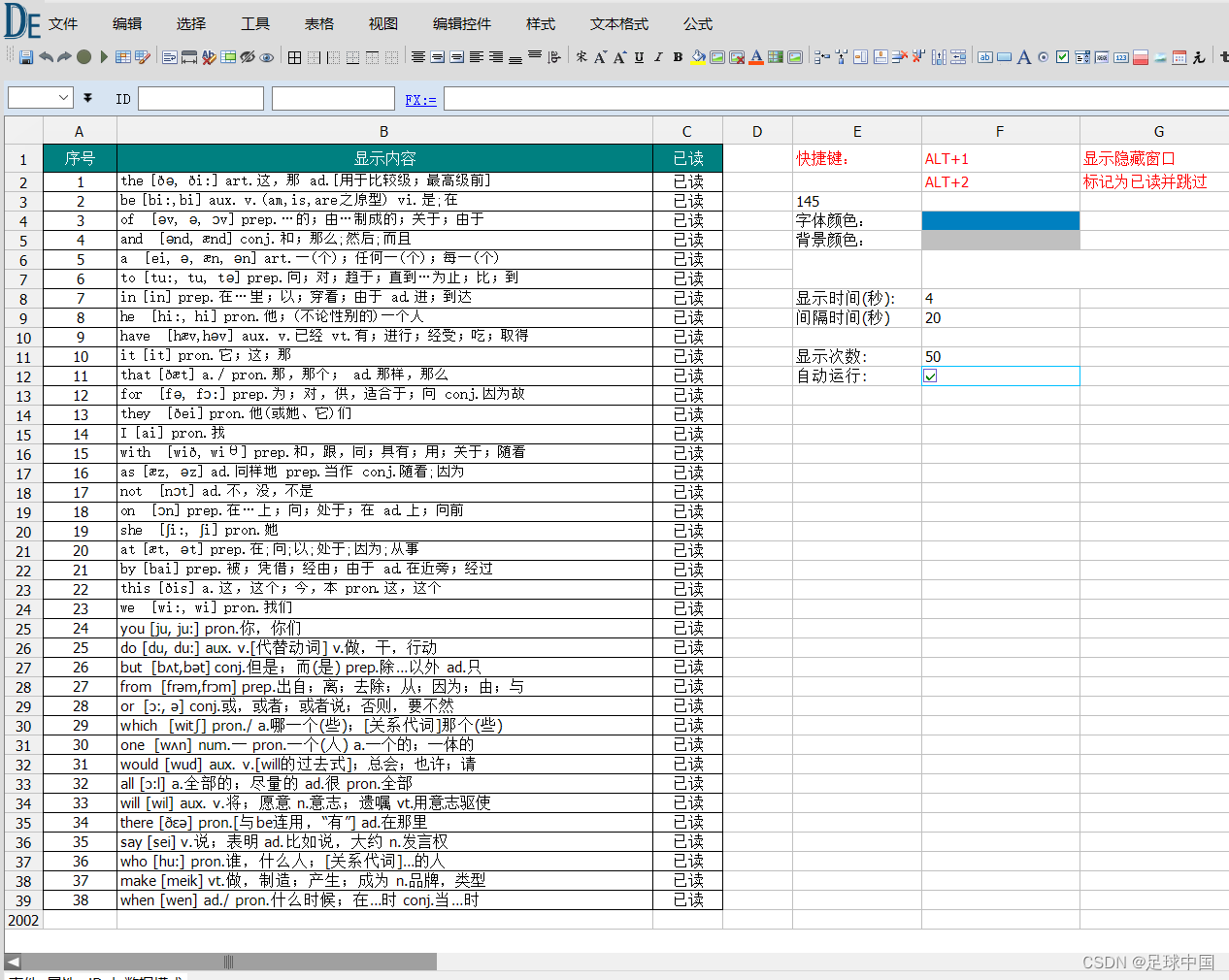
利用屏幕水印学习英语单词,无打扰英语单词学习
1、利用屏幕水印学习英语单词,不影响任何鼠标键盘操作,不影响工作 2、利用系统热键快速隐藏(ALT1键 隐藏与显示) 3、日积月累单词会有进步 4、软件下载地址: 免安装,代码未加密,安全的屏幕水印学习英语…...

开学必备物品清单!这几款优先考虑!
马上就要开学了,同学们也要准备一系列开学用品,方便我们的学习生活,那有哪些数码物品可以在开学前准备的呢,接下来给大家安利几款很不错很实用的数码好物! 推荐一:南卡00压开放式蓝牙耳机 南卡00压开放式…...

聊聊调制解调器
目录 1.什么是调制解调器 2.调制解调器的工作原理 3.调制解调器的作用 4.调制解调器未来发展 1.什么是调制解调器 调制解调器(Modem)是一种用于在数字设备和模拟设备之间进行数据传输的设备。调制解调器将数字数据转换为模拟信号进行传输,…...
Go语言入门指南:基础语法和常用特性(下)
上一节,我们了解Go语言特性以及第一个Go语言程序——Hello World,这一节就让我们更深入的了解一下Go语言的**基础语法**吧! 一、行分隔符 在 Go 程序中,一行代表一个语句结束。每个语句不需要像 C 家族中的其它语言一样以分号 ;…...

【MFC常用问题记录】
MFC 记录 MFC的edit control控件显示1.控件添加变量M_edit后:2.控件ID为IDC_EDIT1: 线程函数使用 MFC的edit control控件显示 1.控件添加变量M_edit后: CString str; int x 10; str.Format(_T("%d"),x); M_edit.SetWindowText(str)2.控件ID…...
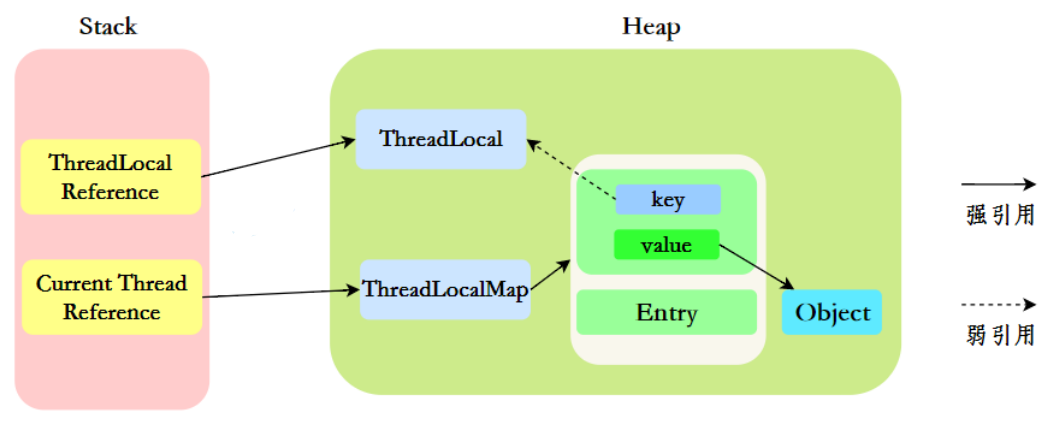
ThreadLocal内存泄漏问题
引子: 内存泄漏:是指本应该被GC回收的无用对象没有被回收,导致内存空间的浪费,当内存泄露严重时会导致内存溢出。Java内存泄露的根本原因是:长生命周期的对象持有短生命周期对象的引用,尽管短生命周期对象已…...
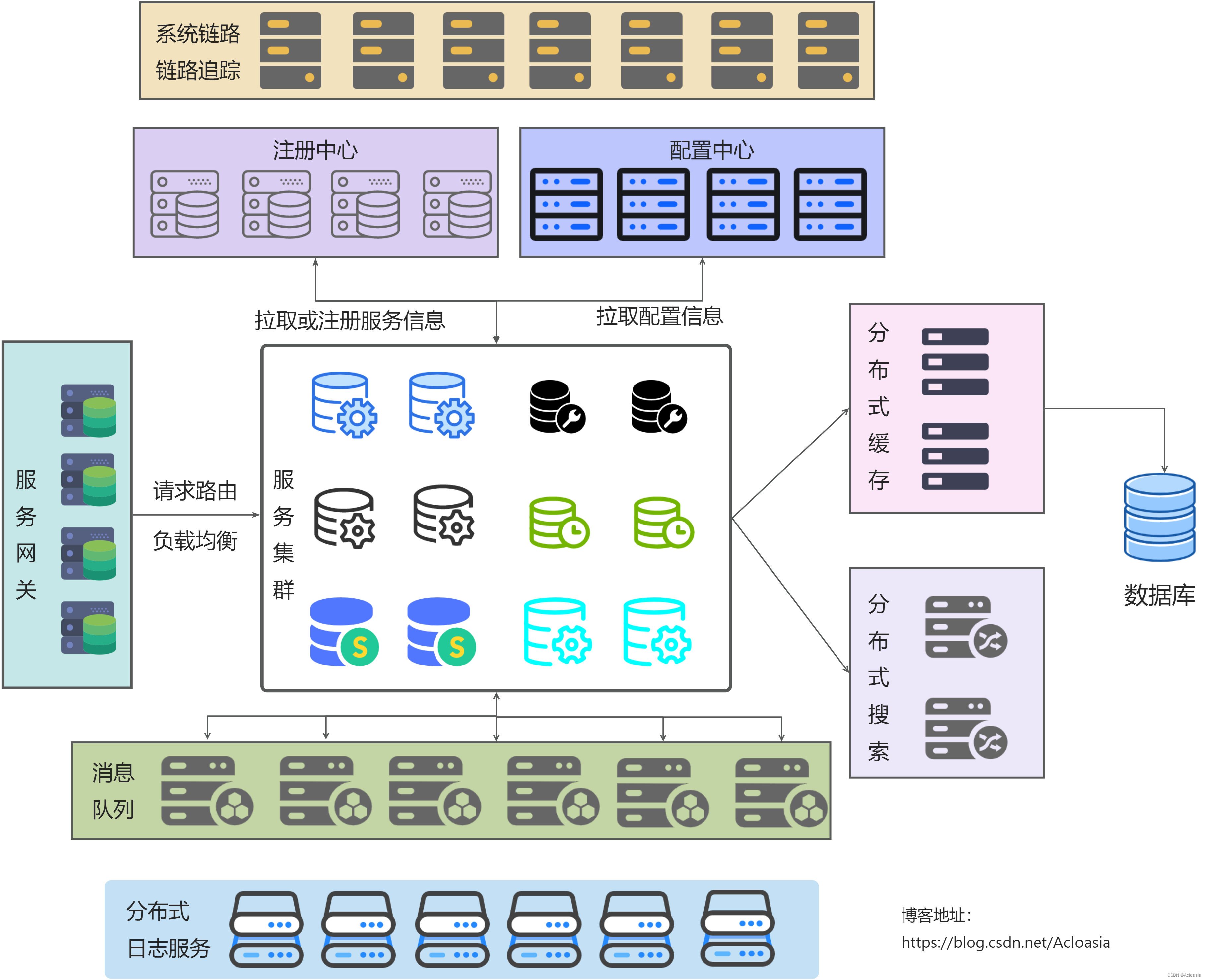
微服务基础概念【内含图解】
目录 拓展补充: 单体架构 分布式架构 面向服务的体系结构 云原生 微服务架构 什么是微服务? 微服务定义 拓展补充: 单体架构 单体架构:将业务的所有功能集中在一个项目中开发,最终打成一个包部署 优点&#x…...
Dockerfile创建 LNMP 服务+Wordpress 网站平台
文章目录 一.环境及准备工作1.项目环境2.服务器环境3.任务需求 二.Linux 系统基础镜像三.docker构建Nginx1.建立工作目录上传安装包2.编写 Dockerfile 脚本3.准备 nginx.conf 配置文件4.生成镜像5.创建自定义网络6.启动镜像容器7.验证 nginx 四.docker构建Mysql1. 建立工作目录…...

消息中间件篇
消息中间件篇 RabbitMQ 如何保证消息不丢失 面试官: RabbitMQ如何保证消息不丢失 候选人: 嗯!我们当时MYSQL和Redis的数据双写一致性就是采用RabbitMQ实现同步的,这里面就要求了消息的高可用性,我们要保证消息的不…...
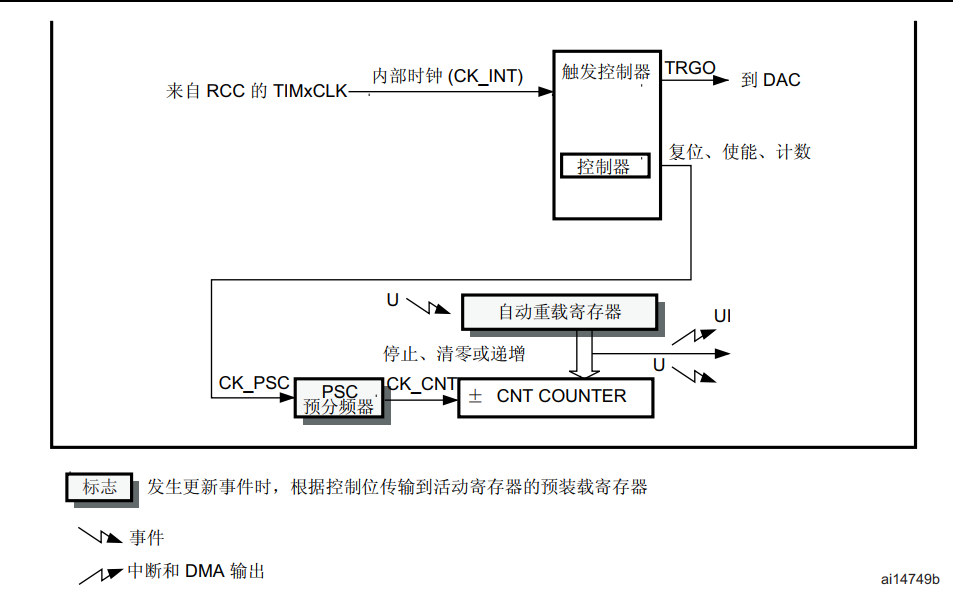
基本定时器
1.简介 1. 基本定时器 TIM6 和 TIM7 包含一个 16 位自动重载计数器 2. 可以专门用于驱动数模转换器 (DAC), 用于触发 DAC 的同步电路 3. 16 位自动重载递增计数器 4. 16 位可编程预分频器 5. 计数器溢出时, 会触发中断/DMA请求 从上往下看 1.开始RCC供给定时器的时钟 RCC_APB1…...

MySQL 中文全文检索
创建索引(MySQL 5.7.6后全文件索引可用WITH PARSER ngram,针对中文,日文,韩文) ALTER TABLE 表 ADD FULLTEXT 索引名 (字段) WITH PARSER ngram;或者CREATE FULLTEXT INDEX 索引名 ON 表 (字段) WITH PARSER ngram; …...
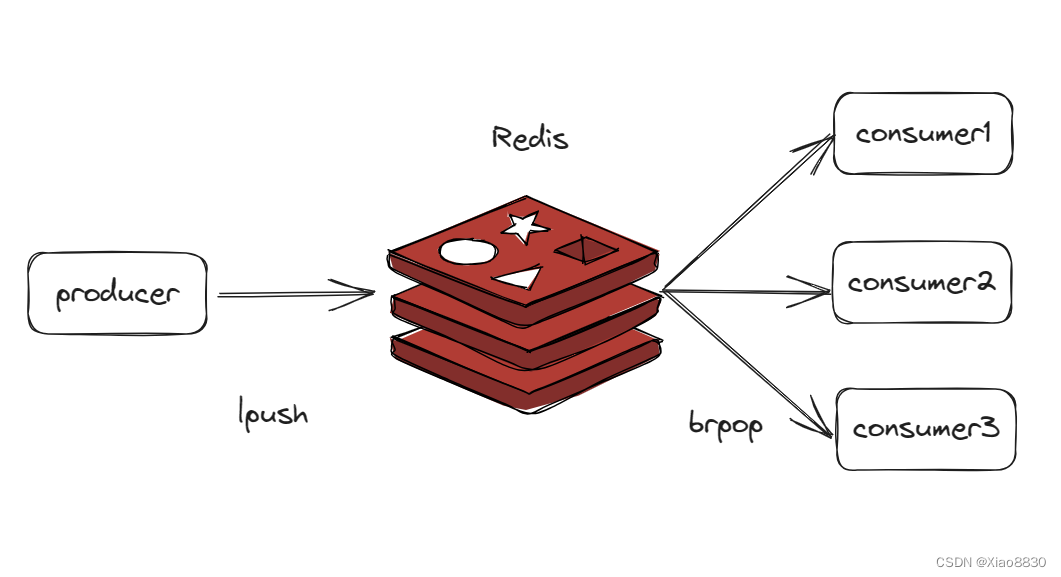
Redis——list类型详解
概要 Redis中的list类型相当于双端队列,支持头插,头删,尾插,尾删,并且列表中的内容是可以重复的。 如果搭配使用rpush和lpop,那么就相当于队列 如果搭配使用rpush和rpop,那么就相当于栈 lpu…...

npm 安装 git 仓库包
安装 #v1.0.0 代表版本, 例如打了仓库一个tag叫v1.0.0; 如果不指定版本则默认是最新的代码 npm install githttp://mygitlab.xxxx.net/chengchongzhen/hex-event-track.git#v1.0.0在项目根目录执行以下命令, 此时你的代码会被链接到npm的全局仓库, 类似执行了 npm install xxx …...

终极指南:5分钟免费解锁Cursor Pro全部功能的完整解决方案
终极指南:5分钟免费解锁Cursor Pro全部功能的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

Ninja构建系统实战:手写BUILD.ninja为你的Python/Go小工具加速
Ninja构建系统实战:手写BUILD.ninja为你的Python/Go小工具加速 在快速迭代的现代开发中,构建流程的效率往往成为瓶颈。当你的Python脚本需要打包成可执行文件,Go模块需要交叉编译,同时还要处理资源文件复制、依赖下载等一系列任务…...

AI Agent配置安全实践:用Config-Guard为自动化变更加锁
1. 项目概述:为AI Agent系统配置变更加上“安全锁”如果你正在运行一个基于OpenClaw或其他类似框架的AI Agent系统,那么你一定对那个核心的配置文件——通常是openclaw.json或类似的config.json——又爱又恨。它掌控着网关、模型、渠道和工具的命脉&…...
)
Win11精简版系统缺失画图工具?三步教你从微软商店找回(附快速启动技巧)
Win11精简版系统缺失画图工具?三步教你从微软商店找回(附快速启动技巧) 不少追求系统流畅性的用户会选择安装第三方精简版Win11系统,却在需要基础功能时发现连画图工具都找不到了。这并非微软的疏漏,而是精简版系统为了…...

插入排序,选择排序,希尔排序
一、插入排序从头开始依次选取一个元素,和他前面的数比较,先把值存为 c ,这样就不用交换值了若比前面的元素大,就让 qq 1的位置的值改为前面的数,qq 往前移一位若前面的数小,就把 qq 1的位置的值改为cvo…...

learn claude code S11 自主 Agent 详解笔记
S11 自主 Agent 详解笔记基于 s11_autonomous_agents.py 源码逐行分析,配合 s11-autonomous-agents.md 设计思路。一、问题:队友需要有人持续指派任务 s09-s10 的 teammate 有一个尴尬的空白期:完成当前任务后进入 idle,然后呢&am…...

分形超材料实现电磁波绕障传输:原理、实验与射频应用
1. 项目概述:让信号“穿墙”的隐身斗篷如果你看过《星际迷航》,肯定对克林贡人或罗慕伦人的隐形装置印象深刻,它能让整艘飞船从雷达上消失。虽然我们还没法让宏观物体真正“隐形”,但在电磁波的世界里,让信号“无视”一…...

如何在Windows上快速安装iPhone网络共享驱动:3分钟终极解决方案
如何在Windows上快速安装iPhone网络共享驱动:3分钟终极解决方案 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.c…...

构建高效AI学习伙伴:从系统提示词到结构化交互设计
1. 项目概述:一个为学习者量身定制的AI交互模式最近在GitHub上看到一个挺有意思的项目,叫“learner-ai-mode”。光看名字,你可能会觉得这又是一个普通的AI应用或者学习工具。但当我深入去研究它的代码和设计理念后,发现它其实指向…...

小米Agent岗二面:你们 RAG 知识库上线之后,文档更新了怎么办?
👔面试官:你们 RAG 知识库上线之后,文档更新了怎么办?总不能每次改个文档就把整个知识库重建一遍吧。 🙋♂️我:可以直接找到变了的那个 chunk,更新它的向量就行了。 👔面试官&a…...