中文编码问题:raw_input输入、文件读取、变量比较等str、unicode、utf-8转换问题
最近研究搜索引擎、知识图谱和Python爬虫比较多,中文乱码问题再次浮现于眼前。虽然市面上讲述中文编码问题的文章数不胜数,同时以前我也讲述过PHP处理数据库服务器中文乱码问题,但是此处还是准备简单做下笔记。方便以后查阅和大家学习。
中文编码问题的处理核心都是——保证所有的编码方式一致即可,包括编译器、数据库、浏览器编码方式等,而Python通常的处理流程是将unicode作为中间转换码进行过渡。先将待处理字符串用unicode函数以正确的编码转换为Unicode码,在程序中统一用Unicode字符串进行操作;最后输出时,使用encode方法,将Unicode再转换为所需的编码即可,同时保证编辑器服务器编码方式一致。
PS:当然Python3除外!这篇文章比较啰嗦,毕竟是在线笔记和体会嘛,望理解~
在详细讲解概念之前,先讲述我最近遇到的字符编码的两个问题及解决。下图是最常见到几个问题编码问题:

一. raw_input输入str转换unicode处理
背景:在做Python定向图片爬虫时,会通过raw_input输入关键词如“主播”,会爬取标题title中包含"主播"的URL,再去到具体的页面爬取图集。
问题:如果是自定义字符串直接通过: s=u'主播' 定义为Unicode编码,再与同样为Unicode编码的title.text(下一篇文章详细介绍该爬虫)比较即可。但是如果需要raw_input输入呢?而且在通过unicode或decode转换过程中总是报错,为什么呢?
主要问题是如何将str转换为unicode编码(How to convert str to unicode),默认python编码方式ascii码。
unicode(string[, encoding[, errors]])
>>> help(unicode)
Help on classunicode in module __builtin__: classunicode(basestring)
| unicode(object='') -> unicode object
| unicode(string[, encoding[, errors]]) -> unicode object
|
| Create a new Unicode object from the given encoded string.
| encoding defaults to the current default string encoding.
| errors can be 'strict', 'replace'or 'ignore' and defaults to 'strict'. 举个简单的例子:需要判断搜索词key是否在title标题中。
# coding=utf-8
importsys defgetTitle(key,url):
#title = driver.find_element_by_xpath()
title = u'著名女主播Miss与杰伦直播LOL'
print key,type(key)
print title,type(title)
if key in title:
print'YES'
else:
print'NO' key = raw_input("Please input a key: ")
printkey,type(key)
url = 'http://www.baidu.com/'
getTitle(key,url) 输出如下图所示:
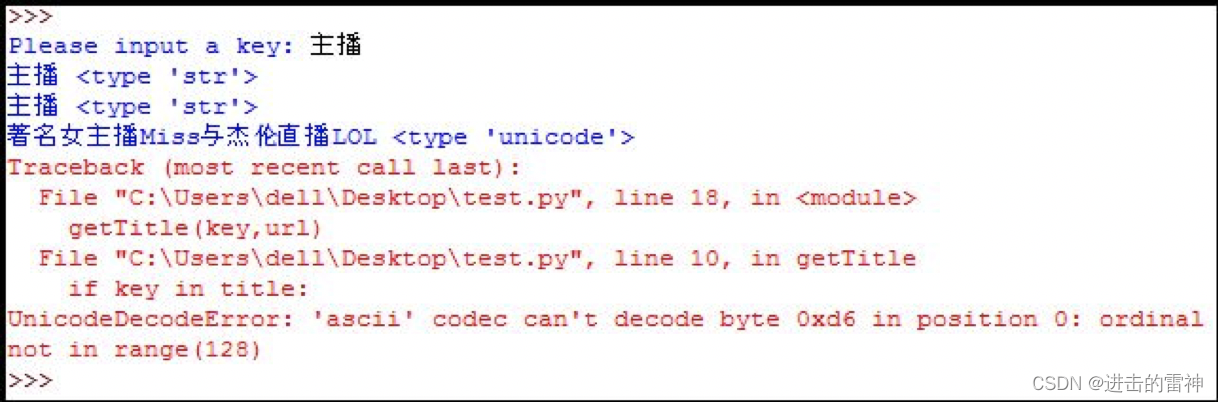
尝试修改的方法包括:通过unicode(key,'utf-8')转码、key.decode('utf-8')转码、重置sys.defaultencoding都不行。而通过key.decode('raw_unicode_escape')转换得到的乱码"Ö÷²¥"(主播)。而同学的Python2.7能将str转换成unicode编码。
"UnicodeDecodeError: 'ascii' codec can't decode byte" 需先将str转换为unicode编码,但是我s.decode('utf-8')就报错 "UnicodeDecodeError: 'utf8' codec can't decode byte"。
s = '主播'
decode('utf-8').encode('gb18030') 最后解决方法从stackoverflow得到,一方面说明自己确实研究得不是很深,另一方面那个论坛确实更强大。参考:
python raw-input odd behavior with accents containing strings
它是将终端的输入编码通过decode转换成unicode编码
key = raw_input("Please input a key: ").decode(sys.stdin.encoding)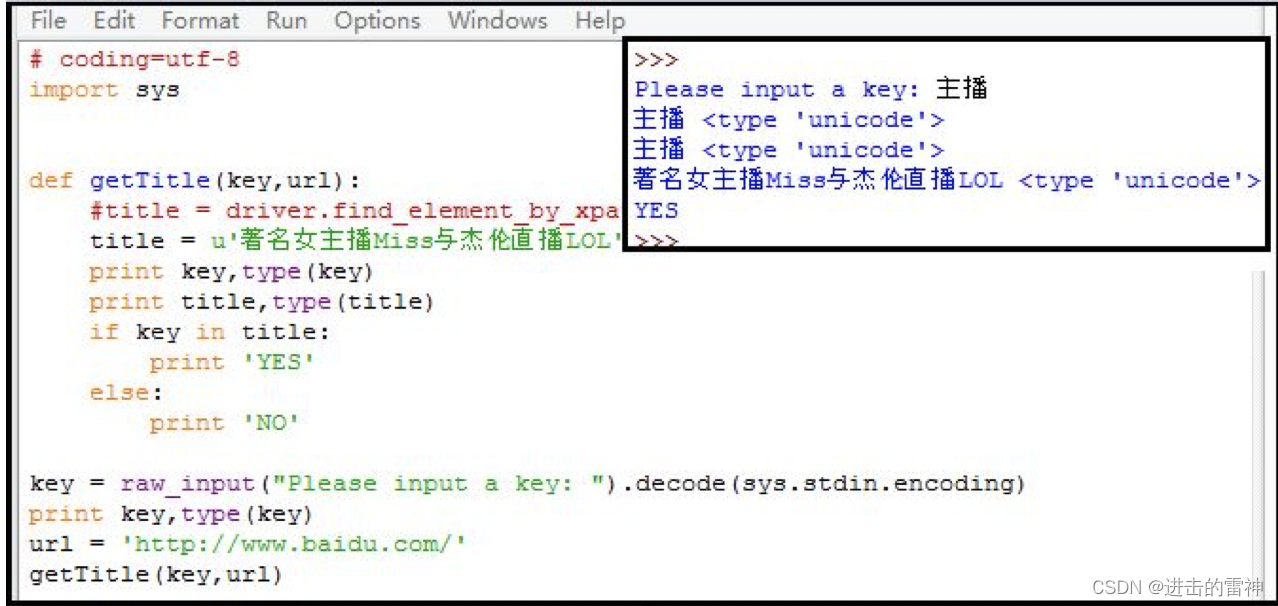
二. 读取中文文件乱码处理
此时你的爬虫仅仅是能从raw_input中输入进行处理或者定义unicode的字符串进行定向爬取,但是如果关键词很多就需要通过读取文件来实现。如下图所示,是我"Python爬取百度InfoBox"这篇文章。同样,你会遇到各种中文乱码问题需要处理。
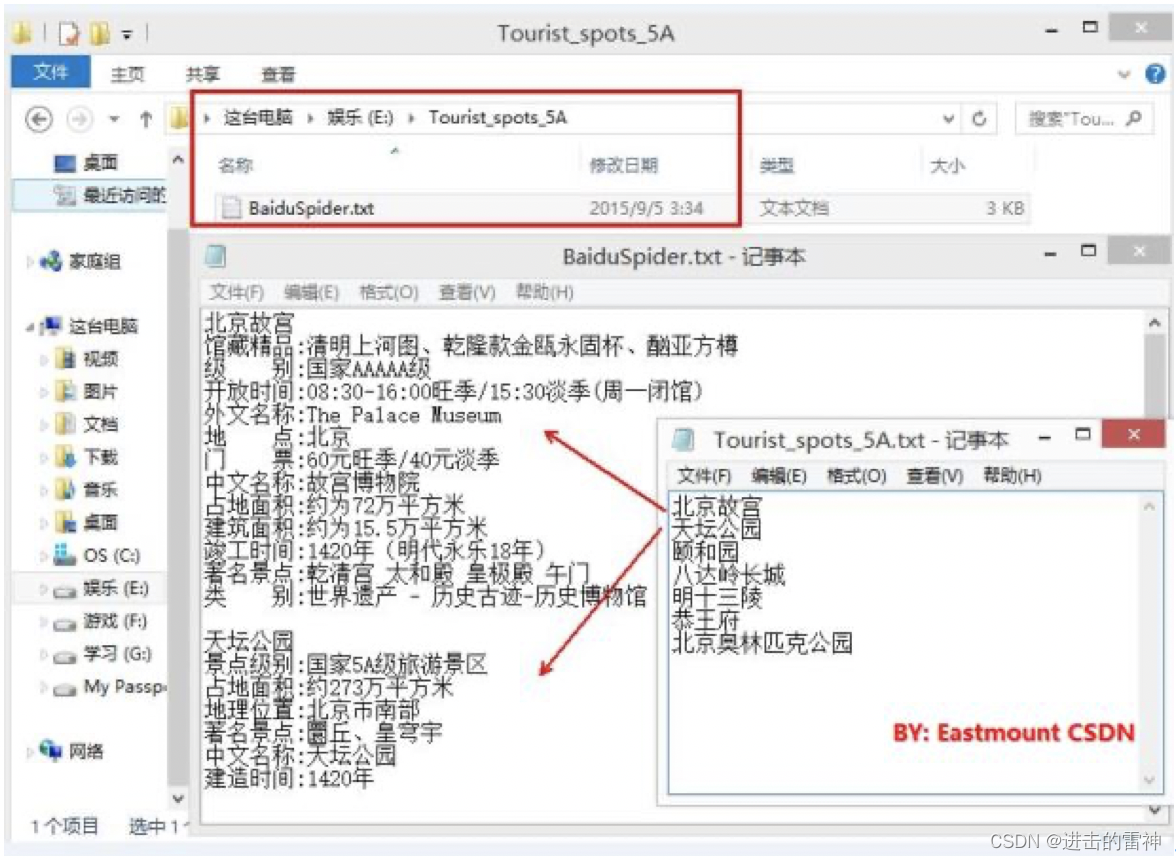
举个简单例子:通过Selenium爬取百度百科Summary第一段。
# coding=utf-8
importsys
importos
importurllib
importtime
fromselenium import webdriver
fromwebdriver.common.keys importKeys
importwebdriver.support.ui as ui
fromwebdriver.common.action_chains importActionChains #driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10) defgetTitle(line,info):
print'Fun: ' + line,type(line)
get("http://baike.baidu.com/")
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
send_keys(line)
send_keys(Keys.RETURN)
elem_value = driver.find_element_by_xpath("//div[@class='lemma-summary']/div[1]").text
print'Summary ',type(elem_value)
printelem_value,'\n'
write(line.encode('utf-8')+'\n'+elem_value.encode('utf-8')+'\n')
sleep(5) defmain():
source = open("E:\\Baidu.txt",'r')
info = open("E:\\BaiduSpider.txt",'w')
forline in source:
line = line.rstrip('\n')
print'Main: ' + line,type(line)
line = unicode(line,"utf-8")
getTitle(line,info)
else:
close() main() 其中TXT通常默认为ANSI编码,代码步骤:
1.我先把Baidu.txt修改为utf-8编码,同时读入通过unicode(line,'utf-8')将str转换为unicode编码;
2.Selenium先通过打开百度百科,在输入关键词"北京故宫"进行搜索,通过find_element_by_xpath爬取"故宫"的summary第一段内容,而且编码方式为unicode;
3.最后文件写操作,通过line.encode('utf-8')将unicode转换成utf-8,否则会报错UnicodeDecodeError: 'ascii'。
总之过程满足:编码=》Unicode=》处理=》utf-8或gbk
由于创建txt文件时默认是ascii格式,而文字为'utf-8'格式时会报错。当然你也可以通过CODECS方法创建制定格式文件。
codes是COder/DECoder的首字母组合。它定义了文本跟二进制值的转换方式,跟ASCII那种用一个字节把字符转换成数字的方式不同,Unicode用的是多字节。这也导致了Unicode支持多种不同的编码方式。codes支持的四种编码方式包括:ASCII、ISO 8859-1/Latin-1、UTF-8和UTF-16。
importcodecs #用codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
info = codecs.open(baiduFile,'w','utf-8') #该方法不是io故换行是'\r\n'
writelines(key.text+":"+elem_dic[key].text+'\r\n') 三. Unicode详解
PS: 该部分主要参考书籍《Python核心编程(第二版)》作者Wesley J.Chun
什么是Unicode
Unicode字符串声明通过字母"u",它用来将标准字符串或者是包含Unicode字符的字符串转换成完全的Unicode字符串对象。Python1.6起引进Unicode字符串支持,是用来在多种双字节字符的格式、编码进行转换的。
Unicode是计算机支持这个星球上多种语言的秘密武器。在Unicode之前,用的都是ASCII码,每个英文字符都是以7位二进制数的方式存储在计算机内,其范围是32~126。当用户在文件中键入A时,计算机会把A的ASCII码值65写入磁盘,然后当计算机读取该文件时,它会首先把65转换成字符A再显示到屏幕上。
但是它的缺点也很明显:对于成千上万的字符来说,ASCII实在太少。而Unicode通过使用一个或多个字节来表示一个字符的方法,可以表示超过90,000个字符。
>>> s1 = "中文"
>>> s1
'\xd6\xd0\xce\xc4'
>>> prints1,type(s1)
中文<type 'str'> >>> s2 = u"中文"
>>> s2
u'\xd6\xd0\xce\xc4'
>>> prints2,type(s2)
ÖÐÎÄ <type 'unicode'>
>>> 前面添加'u'声明为Unicode字符串,但它实际的编码并没有改变。
编码转码
Unicode支持多种编码格式,这为程序员带来了额外的负担,每当你向一个文件写入字符串的时候,你必须定义一个编码(encoding参数)用于把对应的Unicode内容转换成你定义的格式,通过encode()函数实现;相应地,当我们从这个文件读取数据时,必须"解码"该文件,使之成为相应的Unicode字符串对象。
str1.decode('gb2312') 解码表示将gb2312编码字符串转换成unicode编码
str2.encode('gb2312') 编码表示将unicode编码的字符串转换成gb2312编码
>>> s = '中文'
>>> s
'\xd6\xd0\xce\xc4'
>>> prints,type(s)
中文<type 'str'>
>>> s.decode('gb2312')
u'\u4e2d\u6587'
>>> printdecode('gb2312'),type(s.decode('gb2312'))
中文<type 'unicode'> >>> len(s)
4
>>> len(s.decode('gb2312'))
2 >>> t = u'中文'
>>> t
u'\xd6\xd0\xce\xc4'
>>> len(t)
4
>>> printt,type(t)
ÖÐÎÄ <type 'unicode'>
>>> 前缀'u'表示字符串是一个Unicode串,仅仅是一个声明。
Unicode实际应用
1.程序中出现字符串时一定要加个前缀u
2.不要用str()函数,而是用unicode()代替
3.不要用过时的string模块——如果给它的是非ASCII字符,它会把一切搞砸
4.不到必要时不要再程序里面编解码Unicode字符。只在你要写入文件或数据库或网络时,才调用encode()函数;相应地,只在需要把数据读回来时才调用decode()函数
5.由于pickle模块只支持ASCII字符串,尽量避免基于文本的pickle操作
6.假设构建一个用数据库来读写Unicode数据的Web应用,必须保持以下对Unicode的支持
· 数据库服务器(MySQL、PostgreSQL、SQL Server等)
· 数据库适配器(MySQLLdb等)
· Web开发框架(mod_python、cgi、Zope、Django等)
数据库方面确保每张表都用UTF-8编码,适配器如果不支持Unicode如MySQLdb,则必须在connect()方法里面用一个特殊的关键字use_unicode来确保得到的查询结果是Unicode字符串。mod_python开启对Unicode的支持即可,只要在request对象里面把text-encoding设为“utf-8”就OK了。同时浏览器也注意下。
总结:使用应用程序完全支持Unicode,兼容其他的语言本身就是一个工程。它需要详细的考虑、计划。所有涉及的软件、系统都需要检查,包括Python的标准库和其他要用到的第三方扩展模块。你甚至需要组件一个经验丰富的团队来专门负责国家化(I18N)问题。
四. 常用处理方法总结
源自:porkbun.com | parked domain
结合我遇到的两个问题,归纳了以下几点。常见中文编码问题解决方法包括:
1.遵循PEP0263原则,声明编码格式
在PEP 0263--Defining Python Source Code Encodings中提出了对Python编码问题的最基本的解决方法:在Python源码文件中声明编码格式,最常见的声明方式:
#!/usr/bin/python
# -*- coding: <encoding name> -*- 根据这个声明,Python会尝试将文件中的字符编码转为encoding编码,它可以是任意一种Python支持的格式,一般都会使用utf-8\gbk的编码格式。并且它尽可能的将指定地编码直接写成Unicode文本。
注意,coding:encoding只是告诉Python文件使用了encoding格式的编码,但是编辑器可能会以自己的方式存储.py文件,因此最后文件保存的时候还需要编码中选指定的ecoding才行。
2.字符串变量赋值时添加前缀u,使用 u'中文' 替代 '中文'
str1 = '中文'
str2 = u'中文' Python中有以上两种声明字符串变量的方式,它们的主要区别是编码格式的不同,其中tr1的编码格式和Python文件声明的编码格式一致,而str2的编码格式则是Unicode。
如果你要声明的字符串变量中存在非ASCII的字符,那么最好使用str2的声明格式,这样你就可以不需要执行decode,直接对字符串进行操作,可以避免一些出现异常的情况。
3.重置默认编码
Python中出现这么多编码问题的根本原因是Python 2.x的默认编码格式是ASCII,所以你也可以通过以下的方式修改默认的编码格式:sys.getdefaultencoding()默认是'ascii'编码。
#设置编码utf-8
importsys
reload(sys)
setdefaultencoding('utf-8')
#显示当前默认编码方式
printgetdefaultencoding() 这种方法是可以解决部分编码问题,但是同时也会引入很多其他问题,得不偿失,不建议使用这种方式。
其原理: 首先, 这个就是Python语言本身的问题。因为在Python 2.x的语法中, 默认的str并不是真正意义上我们理解的字符串, 而是一个byte数组, 或者可以理解成一个纯ascii码字符组成的字符串, 与Python 3中的bytes类型的变量对应; 而真正意义上通用的字符串则是unicode类型的变量, 它则与Python 3中的str变量对应。本来应该用作byte数组的类型, 却被用来做字符串用, 这种看似奇葩的设定是Python 2一直被人诟病的东西, 不过也没有办法, 为了与之前的程序保持兼容.。
在Python 2中作为两种字符串类型, str与unicode之间就需要各种转换的方式。首先是一种显式转换的方式, 就是encode和decode两种方法。在这里这两货的意思很容易被搞反, 科学的调用方式是:
str --- decode方法 ---> unicode
unicode --- encode方法 ---> str
4.终极原则:decode early, unicode everywhere, encode late
Decode early:尽早decode, 将文件中的内容转化成unicode再进行下一步处理
Unicode everywhere:程序内部处理都用unicode,比如字符串拼接、替换、比较等操作
Encode late:最后encode回所需的encoding, 例如把最终结果写进结果文件
按照这个原则处理Python的字符串,基本上可以解决所有的编码问题(只要你的代码和Python环境没有问题)。前面讲述的两个问题解决实质也是这样,只是有些取巧即可。
5.使用decode().encode()方法
网页采集时,代码指定#coding:utf-8,如果网页的编码为gbk需要这样处理:
html = html.decode('gbk').encode('utf-8')
6.输入变量raw_input中文编码
将终端的输入编码str通过decode转换成unicode编码,再使用unicode处理:
key = raw_input("Please input a key: ").decode(sys.stdin.encoding)
7.文件读写操作
由于默认的txt文件为ANSI编码,读取时通过unicode转码,经过“编码=》Unicode=》处理=》utf-8或gbk ”顺序即可。同时文件输出时encode('utf-8')转换txt为UTF-8格式。终极代码:
info = codecs.open(baiduFile,'w','utf-8')
8.升级Python 2.x到3.x
最后一个方法:升级Python 2.x,使用Python 3.x版本。这样说主要是为了吐槽Python 2.x的编码设计问题。当然,升级到Python 3.x肯定可以解决大部分因为编码产生的异常问题。毕竟Python 3.x版本对字符串这部分还是做了相当大的改进的。
在Python 3.0之后的版本中,所有的字符串都是使用Unicode编码的字符串序列,同时还有以下几个改进:
· 默认编码格式改为unicode
· 所有的Python内置模块都支持unicode
· 不再支持u'中文'的语法格式
所以,对于Python 3.x来说,编码问题已经不再是个大的问题,基本上很少遇到上述的几个异常。
相关文章:
中文编码问题:raw_input输入、文件读取、变量比较等str、unicode、utf-8转换问题
最近研究搜索引擎、知识图谱和Python爬虫比较多,中文乱码问题再次浮现于眼前。虽然市面上讲述中文编码问题的文章数不胜数,同时以前我也讲述过PHP处理数据库服务器中文乱码问题,但是此处还是准备简单做下笔记。方便以后查阅和大家学习。 …...
基于Jenkins自动打包并部署Tomcat环境
目录 1、配置git主机 2、配置jenkins主机 3、配置web主机 4、新建Maven项目 5、验证 Jenkins 自动打包部署结果 Jenkins 的工作原理是先将源代码从 SVN/Git 版本控制系统中拷贝一份到本地,然后根据设置的脚本调用Maven进行 build(构建)。…...

开利网络受邀参与御盛马术庄园发展专委会主题会议
近日,开利网络受邀参与深度合作客户御盛马术庄园组织的首届发展专委会主体会议,就马术庄园发展方向进行沟通,数字化也是重要议题之一。目前,御盛马术庄园已经完成数字化系统的初步搭建,将通过线上线下相结合的方式搭建…...

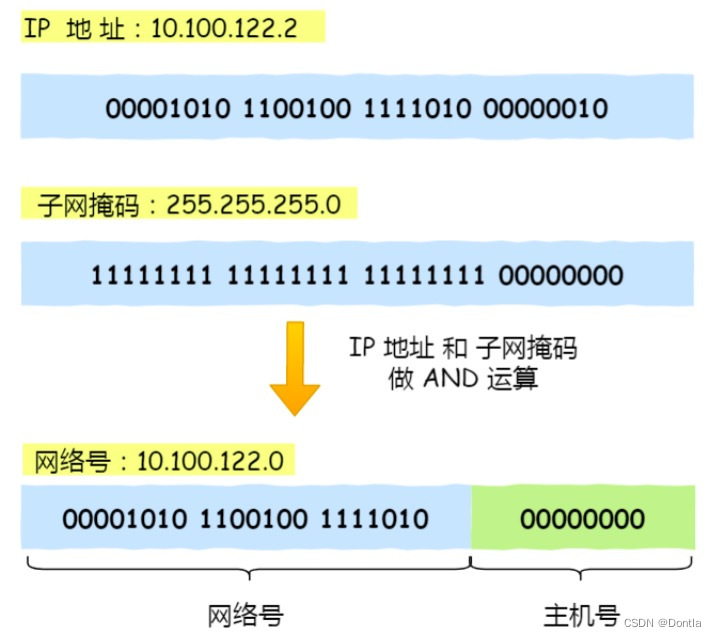
无类别域间路由(Classless Inter-Domain Routing, CIDR):理解IP网络和子网划分(传统的IP地址类ABCDE:分类网络)
文章目录 无类别域间路由(CIDR):理解IP网络和子网划分引言传统的IP地址类关于“IP地址的浪费” IP地址与CIDRIP地址概述网络号与主机号CIDR记法(网络 网络地址/子网掩码)网络和广播地址 CIDR的优势减少路由表项缓解IP…...

合宙Air724UG LuatOS-Air LVGL API-概念
概念 在 LVGL 中,用户界面的基本构建块是对象。例如,按钮,标签,图像,列表,图表或文本区域。 属性 基本属性 所有对象类型都共享一些基本属性: Position (位置) Size (尺寸) Parent (父母) Cli…...

【C语言】位段,枚举和联合体详解
目录 1.位段 1.1 什么是位段 1.2 位段的内存分配 1.3 位段的跨平台问题 2.枚举 2.1 枚举类型的定义 2.2 枚举的优点 3. 联合(共用体) 3.1 联合类型的定义 3.2 联合的特点 3.3 联合大小的计算 1.位段 1.1 什么是位段 位段的声明和结构体是类…...

python学习-文件管理
文件管理 shutil 文件拷贝 shutil.copy(src,dst) 注:srcrE:\python\.vscode\文件操作 windows上运行时候,如果不加r,上述文件路径在代码运行时会报错,因为其会先将双引号”“去掉,然后系统看到了文件路径中有\nc&…...

【LeetCode 算法】Number of Ways of Cutting a Pizza 切披萨的方案数-记忆化
文章目录 Number of Ways of Cutting a Pizza 切披萨的方案数问题描述:分析代码递归 Tag Number of Ways of Cutting a Pizza 切披萨的方案数 问题描述: 给你一个 rows x cols 大小的矩形披萨和一个整数 k ,矩形包含两种字符: A…...

机器视觉之光流
光流(Optical Flow)是计算机视觉领域的一个重要概念,用于描述图像中物体的运动模式。光流可以用来跟踪图像中物体的运动,检测运动中的物体,或者在机器视觉任务中估计物体的速度和位移。 光流的基本思想是根据图像像素…...
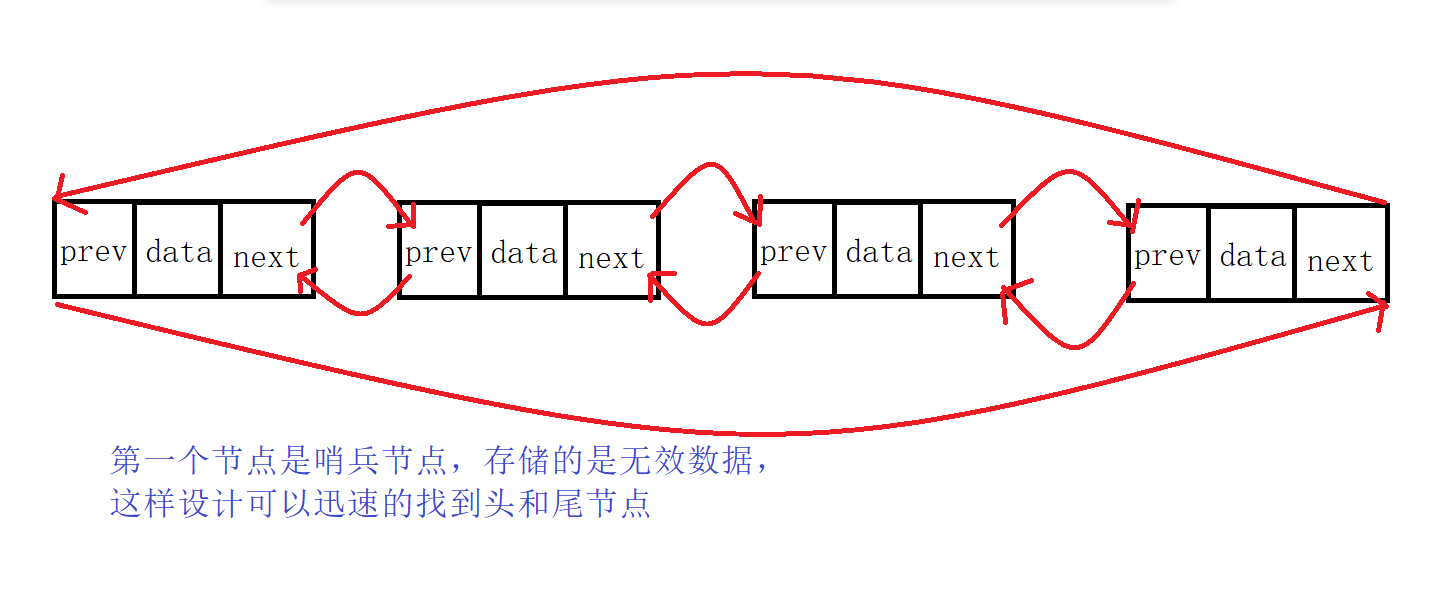
C++:list使用以及模拟实现
list使用以及模拟实现 list介绍list常用接口1.构造2.迭代器3.容量4.访问数据5.增删查改6.迭代器失效 list模拟实现1.迭代器的实现2.完整代码 list介绍 list是一个类模板,加<类型>实例化才是具体的类。list是可以在任意位置进行插入和删除的序列式容器。list的…...

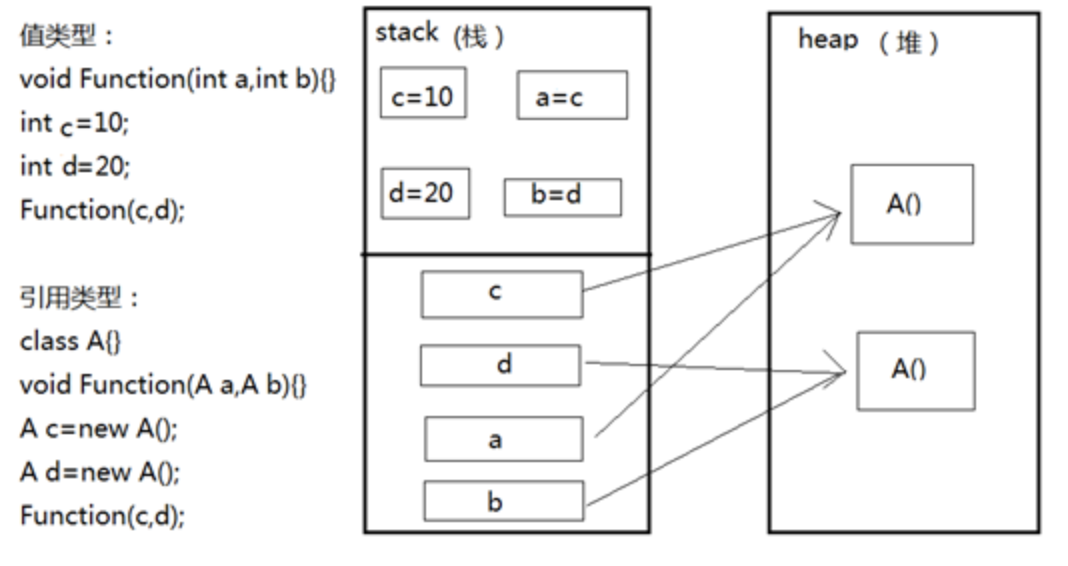
深度学习基础知识-pytorch数据基本操作
1.深度学习基础知识 1.1 数据操作 1.1.1 数据结构 机器学习和神经网络的主要数据结构,例如 0维:叫标量,代表一个类别,如1.0 1维:代表一个特征向量。如 [1.0,2,7,3.4] 2维:就是矩…...

Springboot使用QueryDsl实现融合数据查询
SpringbootQueryDsl技术 1、添加依赖 <!--基于JPA--> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <!--QueryDSL支持--> <dependenc…...

解决方案 | 电子签打通消费电子行业数智化经营通路
技术迭代不断驱动产业快速增长,从PC电脑到手机平板、再到可穿戴设备的兴起,每一次设备的迭代都代表着技术为产品注入了新的发展动能。与此同时,消费电子设备迭代更新周期的不断缩短,市场增长疲缓等因素,也对行业的流转…...
JVM理论知识
一、JVM内存结构 java的内存模型主要分为5个部分,分别是:JVM堆、JVM栈、本地栈、方法区还有程序计数器,他们的用途分别是: JVM堆:新建的对象都会放在这里,他是JVM中所占内存最大的区域。他又分为新生区还…...

idea - 报错 Mybatis提示Tag name expected的问题< 小于号 无法识别
问题:Mybatis提示Tag name expected 原因: 当我们在mapper中编写sql语句的时候会发现使用"<“符号会提示一个Tag name expected。这是因为xml文件中不识别”<"符号和“&”符号。防止与xml本身的元素命名混淆,导致无法解…...

合宙Air724UG LuatOS-Air LVGL API--对象
对象 概念 在 LVGL 中,用户界面的基本构建块是对象。例如,按钮,标签,图像,列表,图表或文本区域。 属性 基本属性 所有对象类型都共享一些基本属性: Position (位置) Size (尺寸) Parent (父母…...
Java将PDF文件转为Word文档
Java将PDF文件转为Word文档 一、创建Springboot Maven项目 二、导入依赖信息 <repositories><repository><id>com.e-iceblue</id><url>https://repo.e-iceblue.cn/repository/maven-public/</url></repository></repositories&g…...

vite创建项目命令
1.第一步运行创建命令(npm) npm create vitelatest也可以使用yarn yarn create vite还可以 pnpm create vite注意的地方:首次创建的时候会出现这个 Need to install the following packages:create-vitelatest Ok to proceed? (y) 直接y就…...
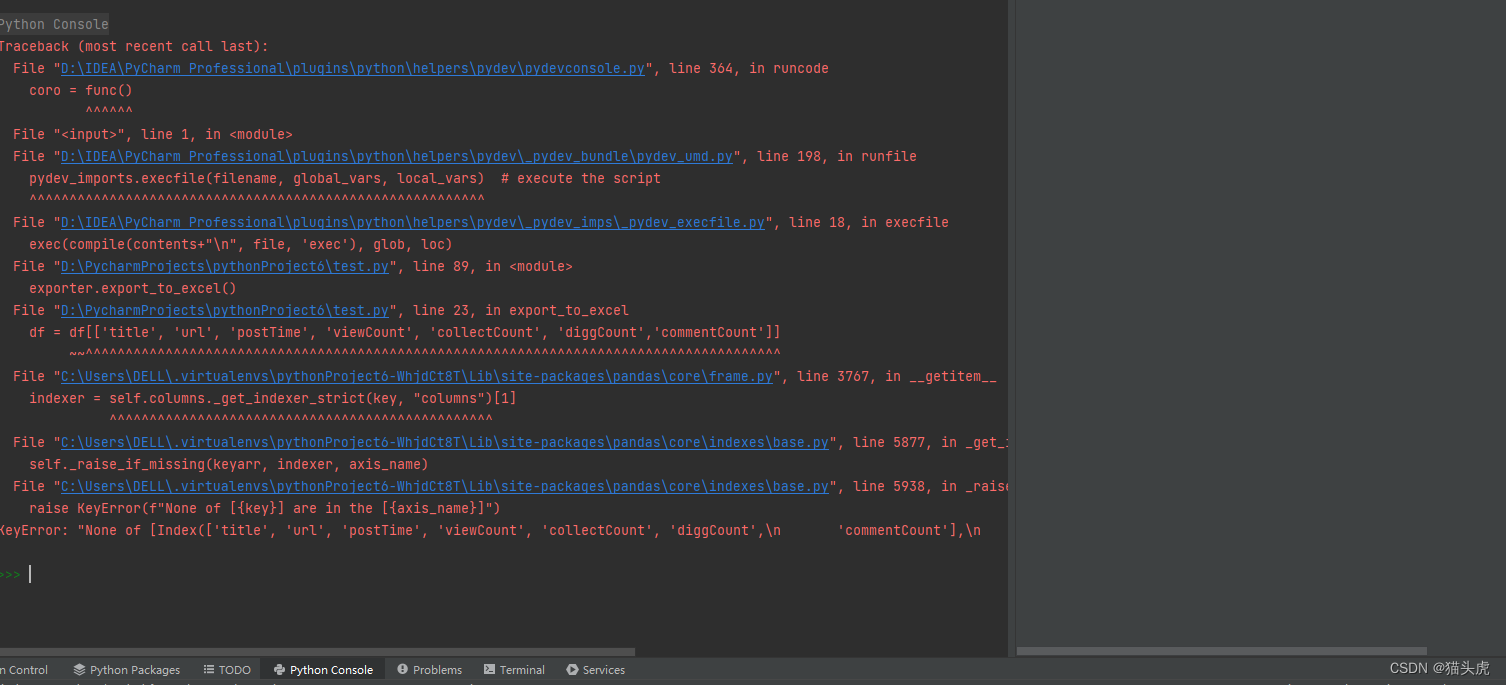
解决Pandas KeyError: “None of [Index([...])] are in the [columns]“问题
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...

FastAPI清洁架构实践:从分层设计到可维护项目搭建
1. 项目概述:一个为FastAPI项目设立的“洁净室”当你开始一个新的FastAPI项目时,面对的是一个空白的画布。理论上,你可以自由地绘制任何架构,但现实往往是:随着第一个路由、第一个数据库模型、第一个业务逻辑的加入&am…...

同样遍历 Mat,为什么你的代码慢 10 倍?
文章目录前言一、什么是不连续Mat?1.产生不连续内存的常见场景2.连续与不连续内存本质区别二、常见错误遍历方式&踩坑分析1.错误一:at<>()逐像素访问(速度慢)2.错误二:强行使用一维 data 指针(高危崩溃&…...

MCP2MQTT 完全指南:用 AI 自然语言控制硬件设备的开源 MCP 工具
前言 2025年4月,MCP2Everything 团队正式开源MCP2MQTT,这是全球首个将 MCP(模型上下文协议)与 MQTT 物联网协议无缝桥接的开源工具,彻底打通了 AI 大模型与物理硬件之间的"最后一公里"。无需编写任何胶水代码…...

iOS模拟器效率革命:Alfred工作流实现键盘流式开发
1. 项目概述与核心价值如果你是一名iOS开发者,或者正在学习Swift或React Native,那么你一定对Xcode自带的iOS模拟器又爱又恨。爱的是它让我们在没有实体设备的情况下也能快速测试应用;恨的是每次想启动模拟器、安装应用、截图或录屏ÿ…...

Windows平台PDF处理终极解决方案:Poppler预编译包深度解析
Windows平台PDF处理终极解决方案:Poppler预编译包深度解析 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 在Windows环境下处理PDF文件…...

松下绿色科技战略:技术复用与协同效应如何驱动企业转型
1. 松下困局:消费电子巨头的十字路口2013年初的拉斯维加斯,消费电子展(CES)的喧嚣与霓虹之下,松下的时任社长津贺一宏站在聚光灯前,面对的却是一个冰冷而残酷的现实:公司预计将连续第二年录得高…...

从零搭建VGG16:深入解析网络架构与PyTorch实战
1. VGG16网络架构解析 VGG16作为卷积神经网络发展史上的里程碑,其核心设计理念至今仍影响着现代深度学习模型。我第一次接触这个网络时,被它简洁优雅的结构深深吸引——全部使用33小卷积核堆叠,配合22最大池化,这种设计就像用乐高…...

Clawforce:开源AI智能体团队基础设施,实现持久化与安全协作
1. 项目概述:Clawforce,一个为持久化AI智能体团队构建的基础设施最近在AI智能体领域,一个词被反复提及:“Agentic AI”,即智能体驱动的AI。这不再是让单个AI模型回答一个问题那么简单,而是构建一个能够自主…...
:风险计算、工具应用)
信息安全工程师-网络安全风险评估(下篇):风险计算、工具应用
一、引言风险评估是软考信息安全工程师考试中风险管理模块的核心考点,分值占比约 8%-12%,涵盖客观题、案例分析题两类题型。从技术定位来看,风险评估是连接安全需求与安全建设的核心枢纽,其输出结果直接作为安全策略制定、安全措施…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...