深度学习-实验1
一、Pytorch基本操作考察(平台课+专业课)
- 使用𝐓𝐞𝐧𝐬𝐨𝐫初始化一个 𝟏×𝟑的矩阵 𝑴和一个 𝟐×𝟏的矩阵 𝑵,对两矩阵进行减法操作(要求实现三种不同的形式),给出结果并分析三种方式的不同(如果出现报错,分析报错的原因)同时需要指出在 计算过程中发生了什么
import torch
a = torch.rand(1,3)
b = torch.rand(2,1)
print('a=',a)
print('b=',b)
print(a-b)
print(torch.sub(a,b))
a.sub_(b)
- 利用 𝐓𝐞𝐧𝐬𝐨𝐫创建两个大小分别 𝟑×𝟐 和 𝟒×𝟐的 随机数矩阵 𝑷和 𝑸,要求服从均值为 0 ,标准差 0.01 为的 正态分布 ;② 对第二步得到的矩阵 𝑸 进行形状变换得到 𝑸的转置 𝑸𝑻;③ 对上述得到的矩阵 𝑷和矩阵 𝑸𝑻 求矩阵相乘
import torch
import numpy as np
x = np.random.normal(0,0.01,3*2)
y = np.random.normal(0,0.01,4*2)
P = torch.from_numpy(x).clone().view(3,2)
print("P矩阵为:",P)
Q = torch.from_numpy(y).clone().view(4,2)
print("Q矩阵为:",Q)
Qt = Q.t()
print("Qt矩阵为:",Qt)
R = torch.mm(P,Qt)
print("P矩阵与Qt矩阵相乘的结果为:",R)
- 给定公式𝑦3=𝑦1+𝑦2=𝑥2+𝑥3 且 𝑥=1。利用学习所得到的 Tensor 的相关知识,求 𝑦3对 𝑥的梯度,即 𝑑𝑦3𝑑𝑥。要求在计算过程中,在计算 𝑥3 时中断梯度的追踪, 观察结果并进行原因分析
import torch
x = torch.tensor(1.,requires_grad=True)
y1 = x**2
y2 = x**3
y3 = y1+y2
y3.backward()
print("计算x的梯度:",x.grad)
import torch
x = torch.tensor(1.,requires_grad=True)
y1 = x**2
with torch.no_grad():y2 = x**3
y3 = y1+y2
y3.backward()
print("不计算x三次方的梯度:",x.grad)
二、手动实现logistic回归
- 要求动手从 0 实现 logistic 回归 (只借助 Tensor 和 Numpy 相关的库)在 人工构造的数据集上进行训练和测试,并从 loss 以及训练集上的准确率等多个角度对结果进行分析
导入包
import torch
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import torch.nn as nn
生成训练集
#标准化数据
def sdata(data):sdata = np.interp(data, (data.min(), data.max()), (0, 1))return sdata
num_examples = 500num1 = np.c_[np.random.normal(3, 1, (num_examples , 2)),np.ones(num_examples)]
num2 = np.c_[np.random.normal(1, 1, (num_examples , 2)),np.zeros(num_examples)]
num = np.vstack((num1,num2))
np.random.shuffle(num)#打乱数据
np.savetxt('test',(num))#将数据等比例压缩在0-1之间
snum1 = sdata(num[:,0]).reshape(num_examples*2,1)
snum2 = sdata(num[:,1]).reshape(num_examples*2,1)
snum = np.concatenate((snum1,snum2,num[:,2].reshape(num_examples*2,1)), axis=1)#将numpy格式的数据转为tensor格式
num1_tensor = torch.tensor((np.c_[snum[:,0],snum[:,1]]),dtype=torch.float)
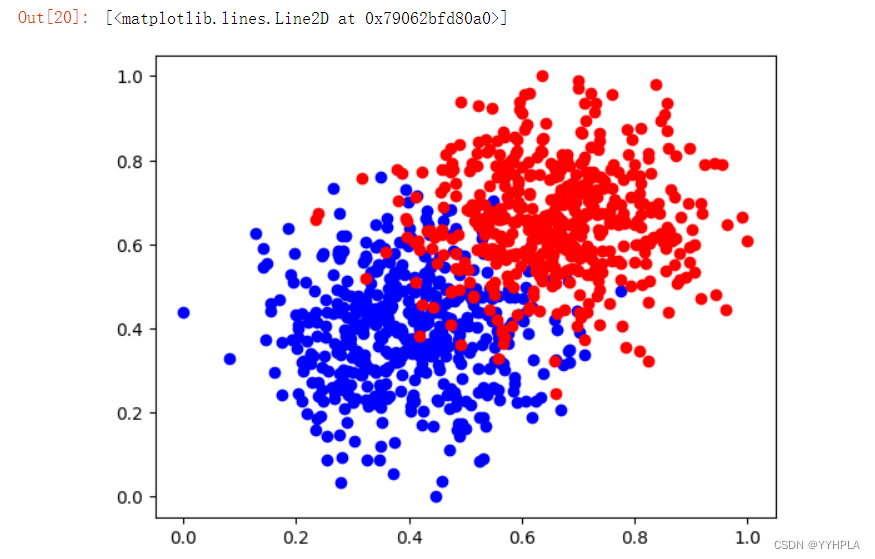
num2_tensor = torch.tensor(snum[:,2],dtype=torch.float).unsqueeze(1)#绘制数据的图像
column_values = num[:,2]
xy0 = snum[column_values == 0]
xy1 = snum[column_values == 1]
plt.plot(xy0[:,0],xy0[:,1],'bo', label='x_1')
plt.plot(xy1[:,0],xy1[:,1],'ro', label='x_1')
运行结果:
损失函数:二元交叉熵
def binary_loss(y_pred, y):loss = nn.BCELoss()return loss(y_pred , y)
优化算法:梯度优化算法
def sgd(w,b):w.data = w.data - 0.1 * w.grad.datab.data = b.data - 0.1 * b.grad.dataw.grad.zero_()b.grad.zero_()
构建模型和模型训练
#sigmoid函数
def sigmoid(x):return 1 / (1 + torch.exp(-x))def logistic_regression(x):return sigmoid(torch.mm(x, w) + b)#正确率计算
def accu(y_pred,y):correct = (y_pred == y).sum()/y.numel()return correctw = torch.rand(2, 1, requires_grad=True)##torch.rand默认随机产生的数据都是0-1
b = torch.zeros(1, requires_grad=True)#模型训练
for nums in range(1,1000):y_pred = logistic_regression(num1_tensor)loss = binary_loss(y_pred, num2_tensor)loss.backward()sgd(w,b)if nums%200==0 :mask = y_pred.ge(0.5).float()acc = accu(mask,num2_tensor)print('第',nums,'次循环后','los =',f"{loss.data.float().item():.3f}",' acc =',f"{acc.item():.3f}")
print('第',nums+1,'次循环后','los =',f"{loss.data.float().item():.3f}",' acc =',f"{acc.item():.3f}")运行结果:

绘制图像
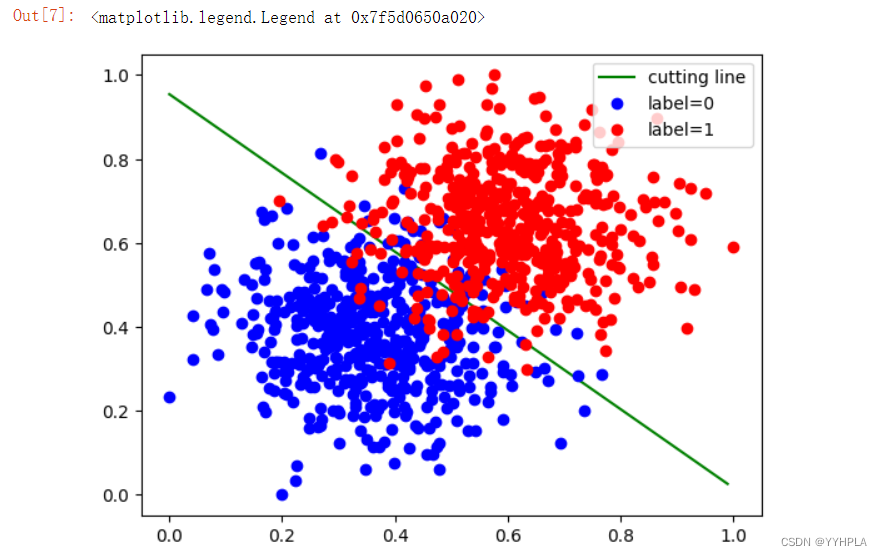
cline_x = np.arange(0, 1, 0.01)
cline_y = (-w[0].data[0] * cline_x - b.data[0]) / w[1].data[0]column_values = num[:,2]
xy0 = snum[column_values == 0]
xy1 = snum[column_values == 1]plt.plot(cline_x, cline_y, 'g', label='cutting line')
plt.plot(xy0[:,0],xy0[:,1],'bo', label='label=0')
plt.plot(xy1[:,0],xy1[:,1],'ro', label='label=1')
plt.legend(loc='best')
运行结果:
- 利用torch.nn实现logistic回归在人工构造的数据集上进行训练和测试,并对结果进行分析并从loss以及训练集上的准确率等多个角度 对结果进行分析
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np# 构造训练数据集
# 假设特征向量为2维,标签为0或1
def sdata(data):sdata = np.interp(data, (data.min(), data.max()), (0, 1))return sdatanum_examples = 500num1 = np.c_[np.random.normal(3, 1, (num_examples , 2)),np.ones(num_examples)]
num2 = np.c_[np.random.normal(1, 1, (num_examples , 2)),np.zeros(num_examples)]
num = np.vstack((num1,num2))
np.random.shuffle(num)#打乱数据
np.savetxt('test',(num))#将数据等比例压缩在0-1之间
snum1 = sdata(num[:,0]).reshape(num_examples*2,1)
snum2 = sdata(num[:,1]).reshape(num_examples*2,1)
snum = np.concatenate((snum1,snum2,num[:,2].reshape(num_examples*2,1)), axis=1)#将numpy格式的数据转为tensor格式
train_features = torch.tensor((np.c_[snum[:,0],snum[:,1]]),dtype=torch.float)
train_labels = torch.tensor(snum[:,2],dtype=torch.float).unsqueeze(1)# 定义 logistic 回归模型
class LogisticRegression(nn.Module):def __init__(self, input_dim):#继承super().__init__()self.linear = nn.Linear(input_dim, 1)#设置一个全连接层def forward(self, x):out = self.linear(x)#先经过一遍全连接层,得到outself.sigmoid = nn.Sigmoid()out = self.sigmoid(out)#使用out经过激活函数return out# 初始化模型和损失函数
net = LogisticRegression(2)
BCEloss = nn.BCELoss()#损失函数
optimizer = optim.SGD(net.parameters(), lr=0.01)##优化器# 迭代训练
num_epochs = 6000
for epoch in range(num_epochs):# 前向传播outputs = net(train_features)#算下lossloss = BCEloss(outputs.flatten(), train_labels.float().squeeze())# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()#参数更新# 打印最终的损失
print(f"Final loss: {loss.item()}")# 在训练集上进行预测
with torch.no_grad():predicted_labels = net(train_features).round()# 计算训练集上的准确率
accuracy = (predicted_labels == train_labels).sum().item() / len(train_labels)
print(f"Accuracy on the training set: {accuracy}")运行结果:

动手实现softmax回归
- 要求动手从 0 实现 softmax 回归 (只借助 Tensor 和 Numpy 相关的库)在 Fashion MNIST 数据集上进行训练和测试 ,并从 loss 、训练集以及测试集上的准确率等多个角度对结果进行分析
导入数据
# 1、加载Fashion-MNIST数据集(采用已划分好的训练集和测试集)
#训练集
mnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST',train=True,download=True,transform=transforms.ToTensor())
#测试集
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST',train=False,download=True,transform=transforms.ToTensor()
)数据加载
BATCH_SIZE = 500
train_loader = torch.utils.data.DataLoader(dataset = mnist_train,batch_size=BATCH_SIZE,shuffle=True,num_workers=0
)test_loader = torch.utils.data.DataLoader(dataset = mnist_test,batch_size=BATCH_SIZE,shuffle=False,num_workers=0
)
损失函数:交叉熵损失函数(代码略)
优化算法:SGD(代码略)
搭建softmax回归模型
def softmax(X):X_exp = torch.exp(X)partition = X_exp.sum(1, keepdim=True)return X_exp / partitiondef net(X):return softmax(torch.mm(X.view((-1, 784)), W) + b)
准确率计算
def evaluate_accurcy(data_iter): #测试集正确率计算right_count, all_num = 0.0, 0for x, y in data_iter:right_count += (net(x).argmax(dim=1) == y).float().sum().item()all_num += y.shape[0]return right_count / all_numdef corrcet_num(predicted_probs, labels):predicted_labels = torch.argmax(predicted_probs, dim=1)correct = (predicted_labels == labels).sum().item()return correct
模型训练
lr = 0.1
num_epochs = 5
W = torch.normal(0, 0.1, (784, 10), dtype=torch.float32).requires_grad_()
b = torch.normal(0, 0.01, (1, 10), dtype=torch.float32).requires_grad_()for epoch in range(num_epochs):train_right_sum, train_all_sum, train_loss_sum = 0.0, 0, 0.0for X, y in train_loader:y_pred = net(X)loss = CEloss(y_pred, y).sum()loss.backward()sgd([W, b], lr, BATCH_SIZE)train_loss_sum += loss.item()train_right_sum += corrcet_num(y_pred,y) #训练集正确数量train_all_sum += y.shape[0]test_acc = evaluate_accurcy(test_loader) # 测试集正确率print('epoch:{}|loss:{}'.format(epoch, train_loss_sum/train_all_sum))print('训练集正确率:{}|测试集正确率:{}'.format(train_right_sum/train_all_sum, test_acc))输出结果:

- 利用 torch.nn 实现 softmax 回归在 Fashion MNIST 数据集上进行训练和测试,并从 loss ,训练集以及测试集上的准确率等多个角度对结果进行分析
import torch
import torch.nn as nn
from torch import tensor
import torch.optim as optim
import numpy as np
import torchvision
import torchvision.transforms as transformsmnist_train = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST',train=True,download=True,transform=transforms.ToTensor()) # 将所有数据转换为Tensor
mnist_test = torchvision.datasets.FashionMNIST(root='~/Datasets/FashionMNIST',train=False,download=True,transform=transforms.ToTensor()
)BATCH_SIZE = 256
train_loader = torch.utils.data.DataLoader(dataset = mnist_train,batch_size=BATCH_SIZE,shuffle=True,num_workers=0
)test_loader = torch.utils.data.DataLoader(dataset = mnist_test,batch_size=BATCH_SIZE,shuffle=False,num_workers=0
)input_dim = 784
output_dim = 10class SoftmaxRegression(nn.Module):def __init__(self, input_dim , output_dim):#继承super().__init__()self.linear = nn.Linear(input_dim, output_dim)#设置一个全连接层def forward(self, x):x = x.view(-1,input_dim)out = self.linear(x)#先经过一遍全连接层,得到outself.softmax = nn.Softmax()out = self.softmax(out)#使用out经过激活函数return outnet = SoftmaxRegression(input_dim,output_dim)
lr = 0.1
CEloss = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr)num_epoch = 5def evaluate_accurcy(data_iter): #测试集正确率计算right_count, all_num = 0.0, 0for x, y in data_iter:right_count += (net(x).argmax(dim=1) == y).float().sum().item()all_num += y.shape[0]return right_count / all_numdef corrcet_num(predicted_probs, labels):predicted_labels = torch.argmax(predicted_probs, dim=1)correct = (predicted_labels == labels).sum().item()return correctfor epoch in range(num_epoch):train_right_sum, train_all_sum, train_loss_sum = 0.0, 0, 0.0for X, y in train_loader:# 前向传播y_pred = net(X)#算下lossloss = CEloss(y_pred, y)# 反向传播和优化loss.backward()optimizer.step()optimizer.zero_grad()#参数更新train_loss_sum += loss.item()train_right_sum += corrcet_num(y_pred,y) #训练集正确数量train_all_sum += y.shape[0]test_acc = evaluate_accurcy(test_loader)print('epoch:{}|loss:{}'.format(epoch, train_loss_sum/train_all_sum))print('训练集正确率:{}|测试集正确率:{}'.format(train_right_sum/train_all_sum, test_acc))
相关文章:
深度学习-实验1
一、Pytorch基本操作考察(平台课专业课) 使用𝐓𝐞𝐧𝐬𝐨𝐫初始化一个 𝟏𝟑的矩阵 𝑴和一个 𝟐𝟏的矩阵 𝑵&am…...
互联网医院开发|医院叫号系统提升就医效率
在这个数字化时代,互联网医院不仅改变了我们的生活方式,也深刻影响着医疗行业。医院叫号系统应运而生,它能够有效解决患者管理和服务方面的难题。不再浪费大量时间在排队上,避免患者错过重要信息。同时,医护工作效率得…...
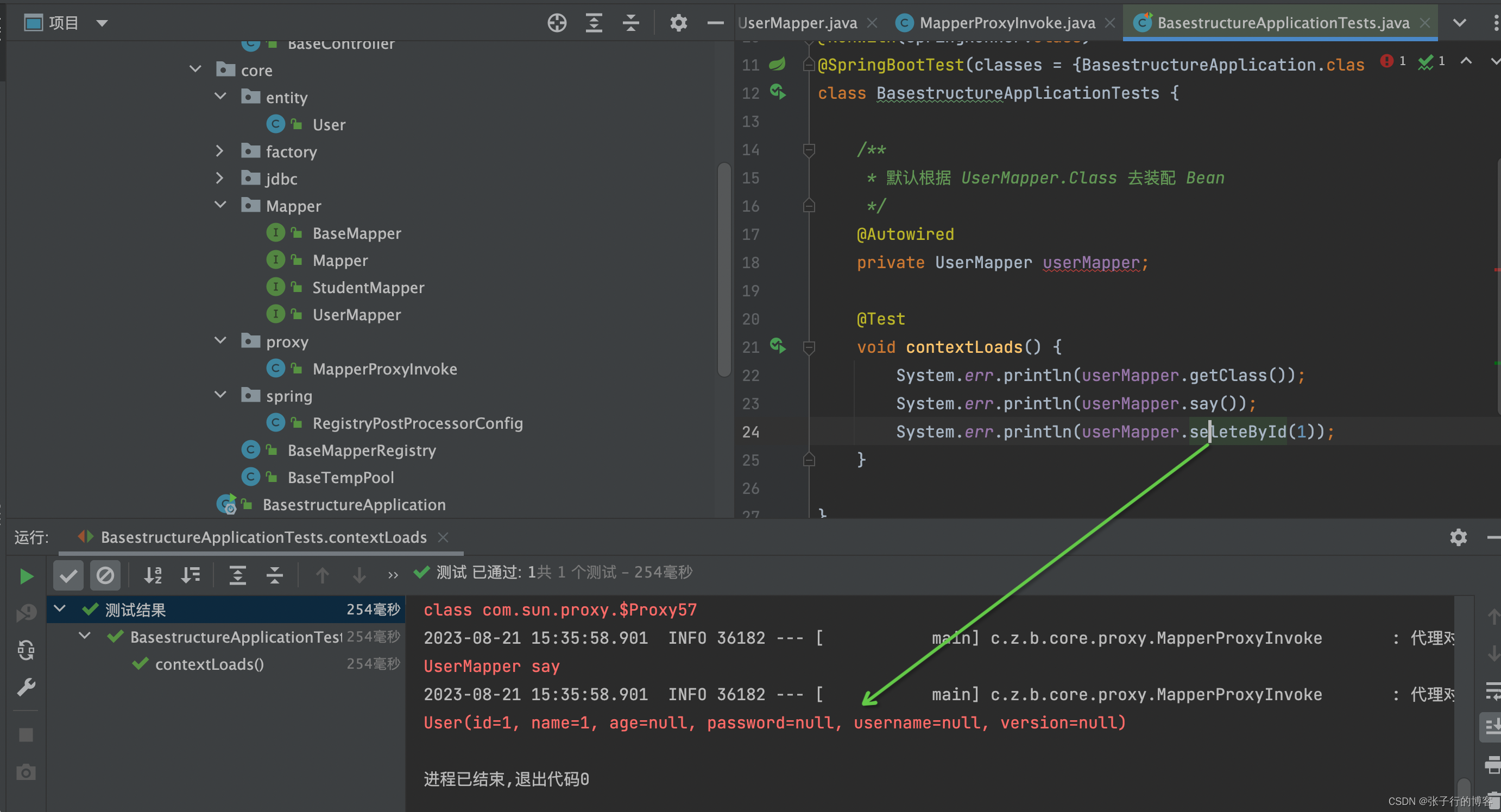
手写 Mybatis-plus 基础架构(工厂模式+ Jdk 动态代理统一生成代理 Mapper)
这里写目录标题 前言温馨提示手把手带你解析 MapperScan 源码手把手带你解析 MapperScan 源码细节剖析工厂模式Jdk 代理手撕脚手架,复刻 BeanDefinitionRegistryPostProcessor手撕 FactoryBean代理 Mapper 在 Spring 源码中的生成流程手撕 MapperProxyFactory手撕增…...

【C++11算法】iota算法
文章目录 前言一、iota函数1.1 iota是什么?1.2 函数原型1.3 参数和返回值1.4 示例代码1.5 示例代码21.6 示例代码3 总结 前言 C标准库提供了丰富的算法,其中之一就是iota算法。iota算法用于填充一个区间,以递增的方式给每个元素赋予一个值。…...

付费加密音乐格式转换Mp3、Flac工具
一、工具介绍 这是一款免费的将付费加密音乐等多种格式转换Mp3 Flac工具,现在大部分云音乐公司,比如QQ音乐、酷我音乐、酷狗音乐、网易云音乐、虾米音乐(RIP🙏)等,都推出了自己专属的云音乐格式,这些格式一般只能在制定的播放器里播放,其它的播放软件并不支持,在很多情…...
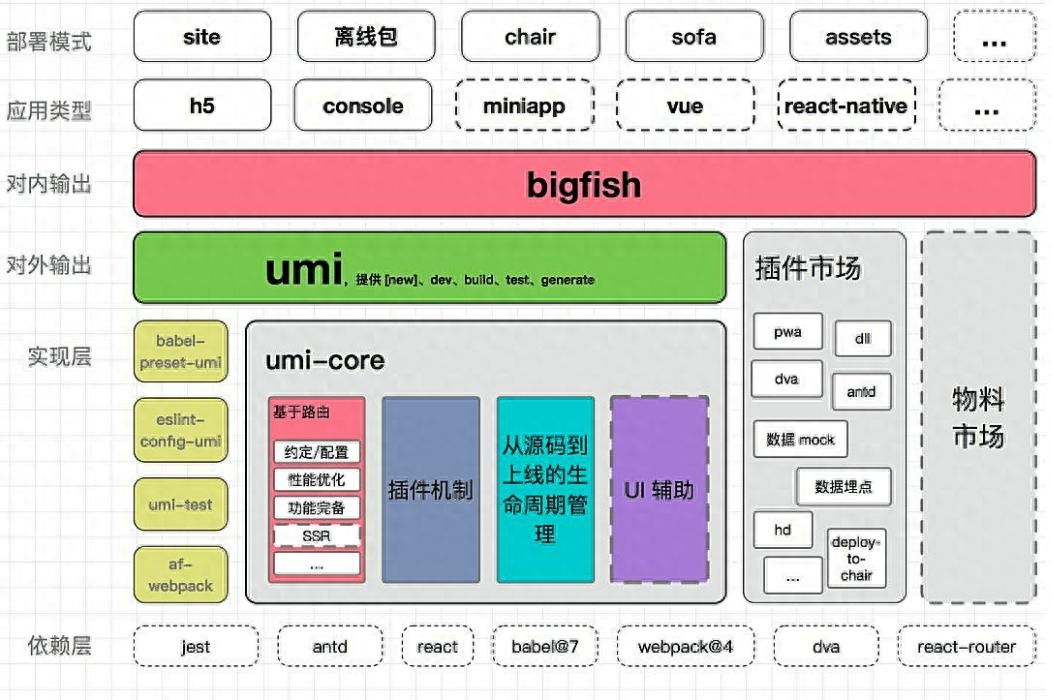
React前端开发架构:构建现代响应式用户界面
在当今的Web应用开发中,React已经成为最受欢迎的前端框架之一。它的出色性能、灵活性和组件化开发模式,使得它成为构建现代响应式用户界面的理想选择。在这篇文章中,我们将探讨React前端开发架构的核心概念和最佳实践,以帮助您构建…...
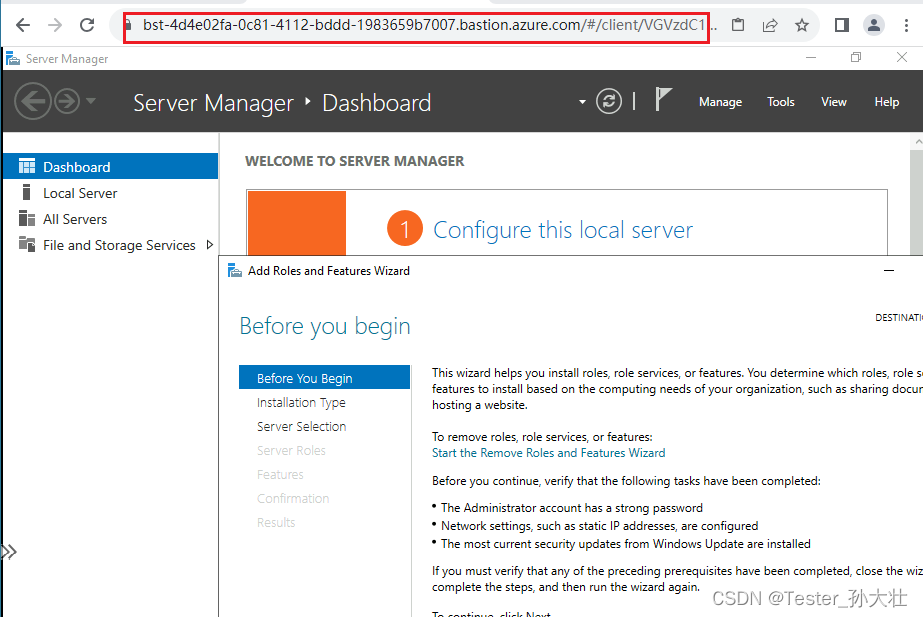
Azure Bastion的简单使用
什么是Azure Bastion Azure Bastion 是一个提供安全远程连接到 Azure 虚拟机(VM)的服务。传统上,访问 VM 需要使用公共 IP 或者设立 VPN 连接,这可能存在一些安全风险。Azure Bastion 提供了一种更安全的方式,它是一个…...

深入理解高并发编程 - 深度解析ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor 并实现了 ScheduledExecutorService 接口,这使得它可以同时充当线程池和定时任务调度器。 构造方法 public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, …...
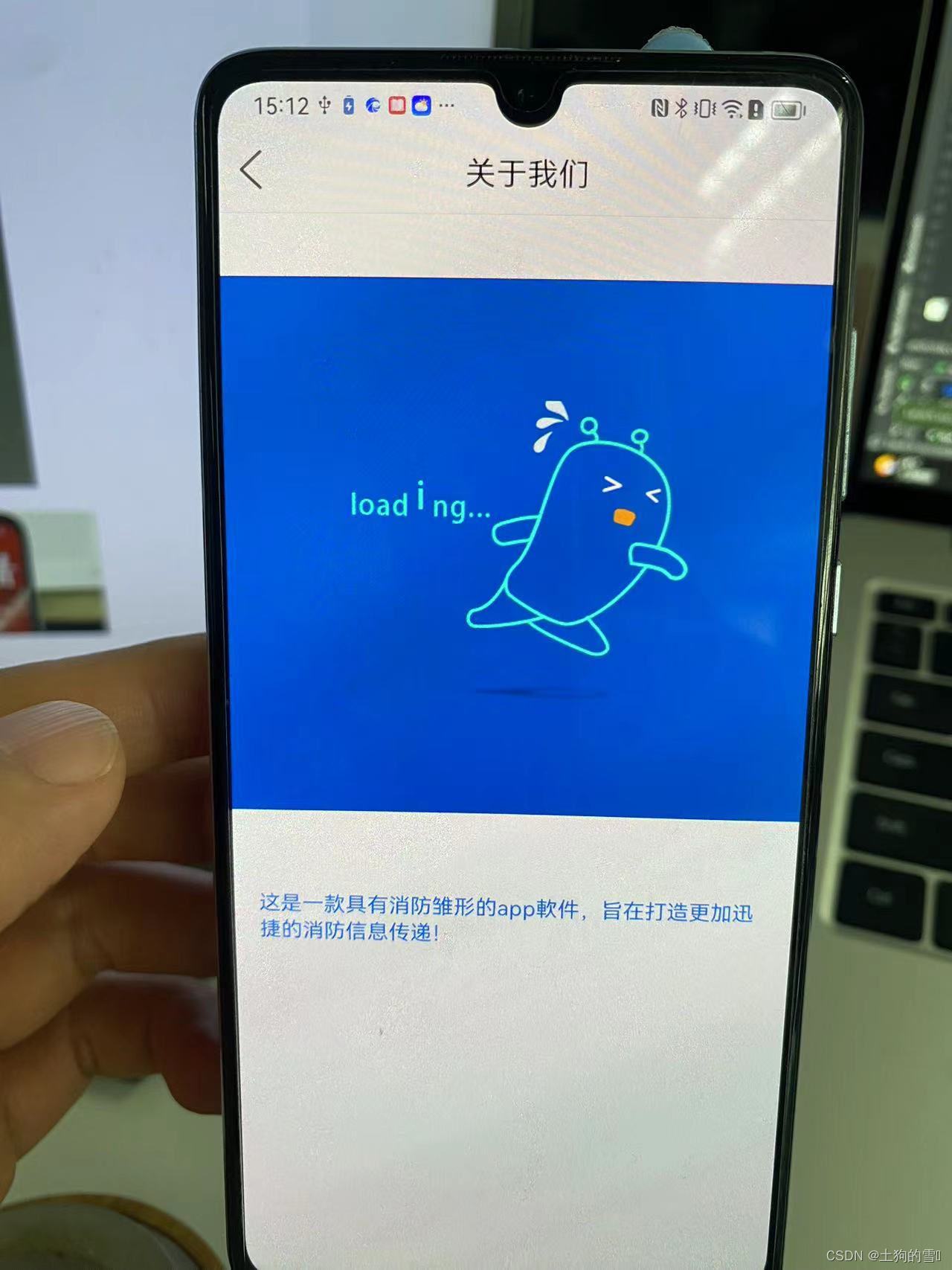
Android---- 一个完整的小项目(消防app)
前言: 针对不同群体的需求,想着应该拓展写方向。医疗app很受大家喜欢,就打算顺手写个消防app,里面基础框架还是挺简洁 规整的。登陆注册和本地数据库写的便于大家理解。是广大学子的毕设首选啊! 此app主要为了传递 消防…...
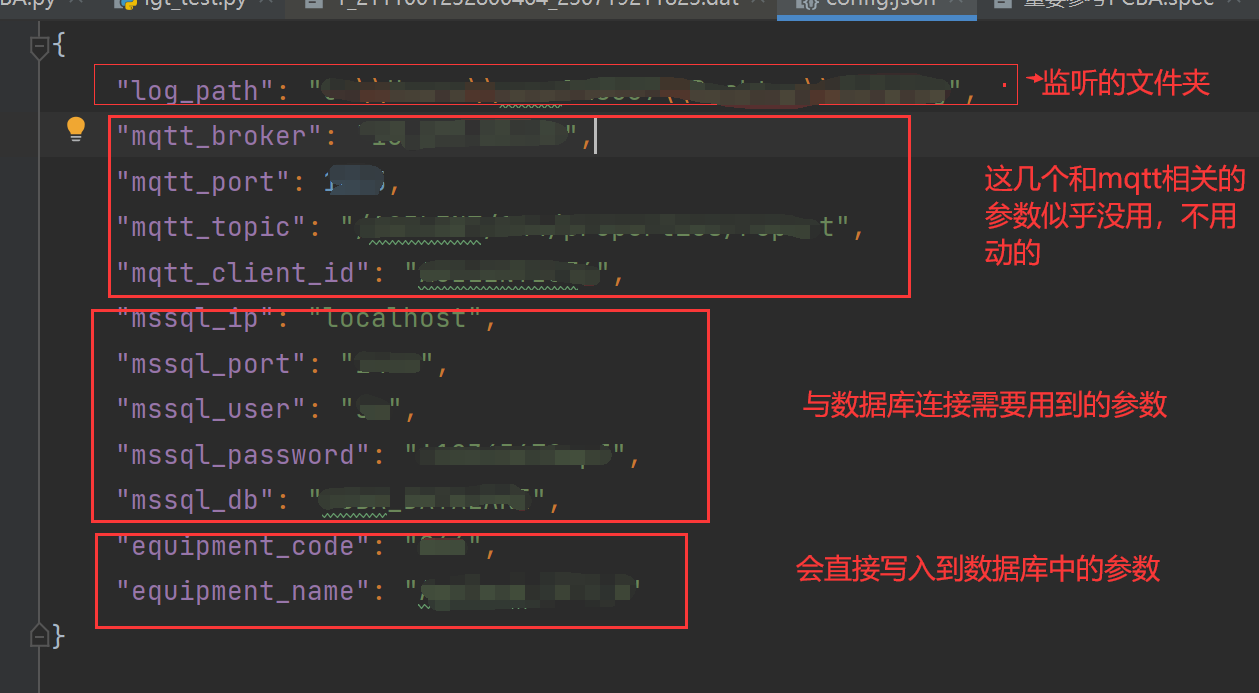
XXX程序 详细说明
用于记录理解PC程序的程序逻辑 1、程序的作用 根据原作者的说明(文件说明.txt),该程序 (PC.py) 的主要作用是提取某一个文件夹中的某个设备 (通过config中的信息看出来是Ag_T_8) 产生的日志文件,然后提取其中某些需要的数据&…...

perl下载与安装教程【工具使用】
Perl是一个高阶程式语言,由 Larry Wall和其他许多人所写,融合了许多语言的特性。它主要是由无所不在的 C语言,其次由 sed、awk,UNIX shell 和至少十数种其他的工具和语言所演化而来。Perl对 process、档案,和文字有很强…...

Chrome谷歌浏览器修改输入框自动填充样式
Chrome谷歌浏览器修改输入框自动填充样式 背景字体 背景 input:-webkit-autofill{-webkit-box-shadow:0 0 0 1000px #fff inset !important; }字体 input:-internal-autofill-selected {-webkit-text-fill-color: #000 !important; }...
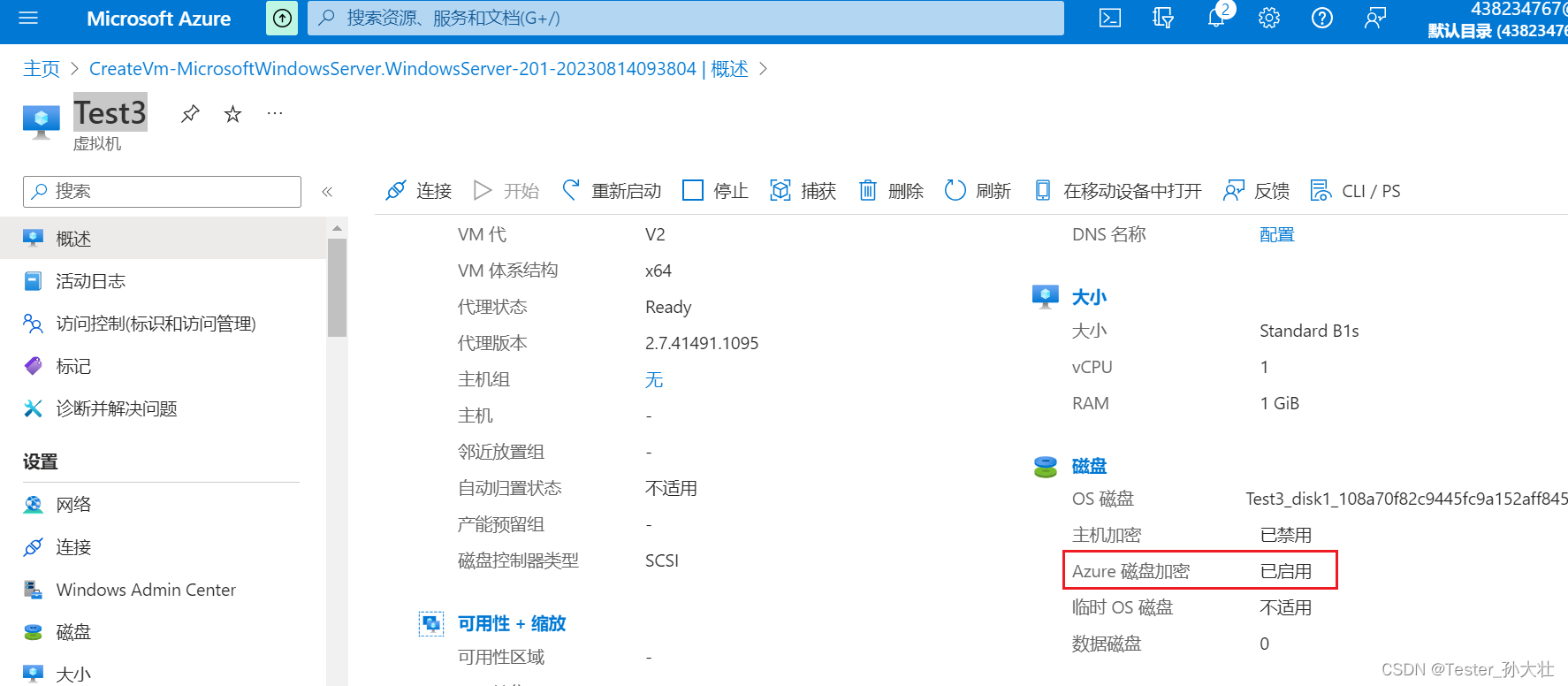
Azure CLI 进行磁盘加密
什么是磁盘加密 磁盘加密是指在Azure中对虚拟机的磁盘进行加密保护的一种机制。它使用Azure Key Vault来保护磁盘上的数据,以防止未经授权的访问和数据泄露。使用磁盘加密,可以保护磁盘上的数据以满足安全和合规性要求。 参考文档:https://l…...
速卖通商品列表页面数据获取方法,速卖通API实现批量商品数据抓取示例)
Java“牵手”根据关键词搜索(分类搜索)速卖通商品列表页面数据获取方法,速卖通API实现批量商品数据抓取示例
速卖通商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取速卖通商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问速卖通商城的网页来获取商品详情信息。以下是两种常用方法的介…...
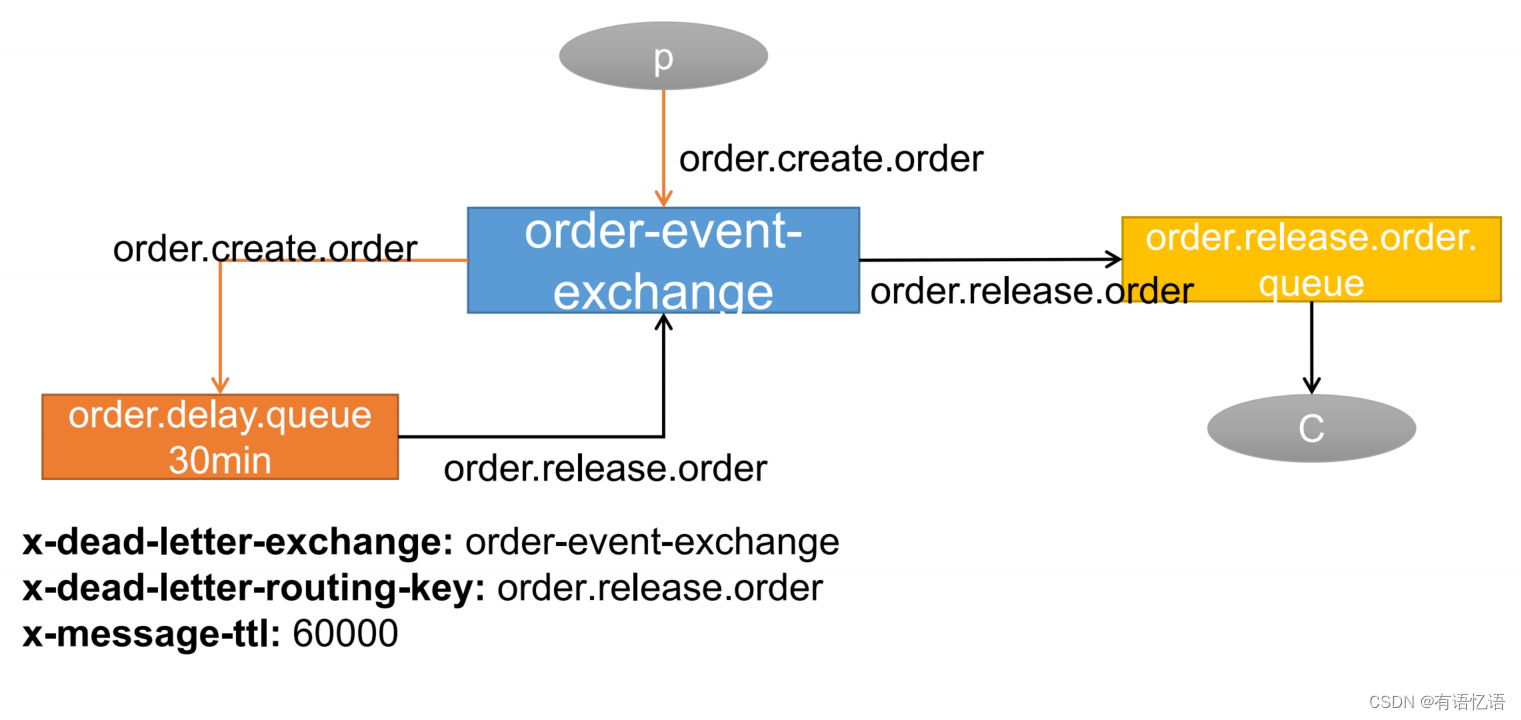
商城-学习整理-高级-消息队列(十七)
目录 一、RabbitMQ简介(消息中间件)1、RabbitMQ简介:2、核心概念1、Message2、Publisher3、Exchange4、Queue5、Binding6、Connection7、Channel8、Consumer9、Virtual Host10、Broker 二、一些概念1、异步处理2、应用解耦3、流量控制5、概述 三、Docker安装RabbitM…...
:初识Camera)
Android Camere开发入门(1):初识Camera
Android Camere开发入门(1):初识Camera 初步了解 在Android开发中,相机(Camera)是一个常见而重要的功能模块。它允许我们通过设备的摄像头捕捉照片和录制视频,为我们的应用程序增加图像处理和视觉交互的能力。 随着Android系统的不断发展和更新,相机功能也不断改进和增…...

hive表的全关联full join用法
背景:实际开发中需要用到全关联的用法,之前没遇到过,现在记录一下。需求是找到两张表的并集。 全关联的解释如下; 下面建两张表进行测试 test_a表的数据如下 test_b表的数据如下; 写第一个full join 的SQL进行查询…...

PMP串讲
!5种冲突解决策略 !敏捷3355。 ?PMP项目管理132种工具技术合集: 参考2:项目管理的132种工具 - 水之座 ?质量管理,有多少种图: ?风险管理,有多少种图: --参考:PMP相关的十八种…...

最长回文子序列——力扣516
动态规划 int longestPalindromeSubseq(string s){int n=s.length();vector<vector<int>>...
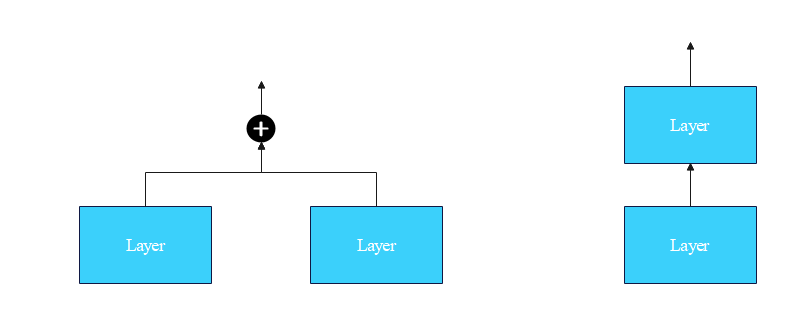
从零实现深度学习框架——Transformer从菜鸟到高手(二)
引言 💡本文为🔗[从零实现深度学习框架]系列文章内部限免文章,更多限免文章见 🔗专栏目录。 本着“凡我不能创造的,我就不能理解”的思想,系列文章会基于纯Python和NumPy从零创建自己的类PyTorch深度学习框…...

别再死记硬背了!用这5个真实数据处理场景,彻底搞懂Python列表、字典和集合
别再死记硬背了!用这5个真实数据处理场景,彻底搞懂Python列表、字典和集合 当你第一次学习Python时,列表、字典和集合可能只是教科书上的几个定义。但真正掌握它们的关键,在于理解如何将这些数据结构转化为解决实际问题的工具。本…...

用OpenMV4 H7 PLUS做个智能分拣小车:颜色识别实战项目从硬件选型到代码集成
智能分拣小车实战:OpenMV4 H7 PLUS颜色识别与嵌入式系统集成 在创客竞赛和毕业设计中,智能分拣系统一直是热门选题。传统方案往往面临识别精度不足、响应延迟高或硬件兼容性差等问题。OpenMV4 H7 PLUS凭借其强大的图像处理能力和丰富的硬件接口ÿ…...

从OCP协议到3D寄生提取:EDA/IP技术演进与工程实践深度解析
1. 行业动态综述:从新闻简报到深度洞察每周追踪EDA(电子设计自动化)和IP(知识产权核)领域的动态,已经成了我从业十几年来的一个习惯。这不仅仅是看看新闻,更像是定期参加一场虚拟的行业技术交流…...

3款实用论文降重神器,帮你轻松解决重复率难题
对于正在撰写毕业论文或者期刊论文的创作者来说,重复率不达标绝对是最头疼的问题之一。自己手动改了三五遍,重复率还是卡在要求线以上,不仅耽误时间还影响心态,这时候一款好用的降重工具就能帮你省下不少精力。今天我们就以第三方…...
)
使用 LikeShop 搭建商城的完整流程(从0到上线)
先说结论用 LikeShop 搭建商城,本质可以拆成 5 步:👉 部署系统 → 配置基础 → 上架商品 → 打通交易 → 引流运营只要这 5 步跑通,就可以实现“可正常卖货”的商城。一、准备阶段(很多人会忽略)在动手之前…...

QQ音乐加密文件解密终极指南:qmcdump工具完全使用教程
QQ音乐加密文件解密终极指南:qmcdump工具完全使用教程 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...

从零构建开源语音AI交互中枢:EchoKit Server部署与调优指南
1. 项目概述:构建你自己的语音AI交互中枢 如果你对智能音箱、语音助手这类设备感兴趣,但又觉得市面上的产品要么功能封闭,要么隐私堪忧,那么今天聊的这个项目——EchoKit Server,可能会让你眼前一亮。简单来说&#x…...

从一次失败的模型交付说起:我是如何用random_state拯救项目复现的
从一次失败的模型交付说起:我是如何用random_state拯救项目复现的 那是一个周五的下午,团队群里的消息突然炸开了锅。"你确定这是同一个模型?测试集AUC从0.92跌到0.68了!"看着同事发来的对比截图,我的后背瞬…...

品牌AI印相失效90%源于这7个参数误设,可口可乐级商业输出必须校准的4项色彩/构图硬指标
更多请点击: https://intelliparadigm.com 第一章:Midjourney Coca Cola印相失效的底层归因诊断 Midjourney v6 及后续版本中,针对品牌标识(如 Coca-Cola 经典红白波浪字体与动态弧线)的“印相”(prompt i…...

地表温度反演进阶:对比单窗算法与大气校正法,用ENVI/ERDAS分析Landsat 7 ETM+数据哪个更准?
地表温度反演技术深度对比:单窗算法与大气校正法的实战解析 遥感技术在地表温度反演领域的应用已经发展出多种成熟算法,其中单窗算法和大气校正法(RTE)是最为常用的两种方法。对于中高级遥感用户而言,理解这两种算法的…...