根据源码,模拟实现 RabbitMQ - 虚拟主机 + Consume设计 (7)
目录
一、虚拟主机 + Consume设计
1.1、承接问题
1.2、具体实现
1.2.1、消费者订阅消息实现思路
1.2.2、消费者描述自己执行任务方式实现思路
1.2.3、消息推送给消费者实现思路
1.2.4、消息确认
一、虚拟主机 + Consume设计
1.1、承接问题
前面已经实现了虚拟主机大部分功能以及转发规则的判定,也就是说,现在消息已经可以通过 转换机 根据对应的转发规则发送给对应的 队列 了.
那么接下来要解决的问题就是,消费者该如何订阅消息(队列),如何把消息推送给消费者,以及消费者如何描述自己怎么执行任务~
1.2、具体实现
1.2.1、消费者订阅消息实现思路
消费者是以队列为维度订阅消息的,并且一个队列可以被多个消费者订阅,那么一旦队列中有消息,这个消息到底因该给谁呢?此处就约定,消费者之间按照 “轮询” 的方式来进行消费.
这里我们就需要定义一个类(ConsumerEnv),用来描述一个消费者,如下
public class ConsumerEnv {private String consumerTag;private String queueName;private boolean autoAck;//通过这个回调来处理收到的消息private Consumer consumer;public ConsumerEnv(String consumerTag, String queueName, boolean autoAck, Consumer consumer) {this.consumerTag = consumerTag;this.queueName = queueName;this.autoAck = autoAck;this.consumer = consumer;}public String getConsumerTag() {return consumerTag;}public void setConsumerTag(String consumerTag) {this.consumerTag = consumerTag;}public String getQueueName() {return queueName;}public void setQueueName(String queueName) {this.queueName = queueName;}public boolean isAutoAck() {return autoAck;}public void setAutoAck(boolean autoAck) {this.autoAck = autoAck;}public Consumer getConsumer() {return consumer;}public void setConsumer(Consumer consumer) {this.consumer = consumer;}
}
再给每个队列对象(MSGQueue 对象)添加一个属性 List,用来包含若干个上述消费者(有哪些消费者订阅了当前队列),如下图:

//当前队列都有哪些消费者订阅了private List<ConsumerEnv> consumerEnvList = new ArrayList<>();//记录当取到了第几个消费者(AtomicInteger 是线程安全的)private AtomicInteger consumerSeq = new AtomicInteger(0);/*** 添加一个新的订阅者* @param consumerEnv*/public void addConsumerEnv(ConsumerEnv consumerEnv) {consumerEnvList.add(consumerEnv);}/*** 删除订阅者暂时先不考虑*//*** 挑选一个订阅者,来处理当前的消息(按照轮询的方式)* @return*/public ConsumerEnv chooseConsumer() {if(consumerEnvList.size() == 0) {//该队列暂时没有人订阅return null;}//计算当前要取的下标int index = consumerSeq.get() % consumerEnvList.size();consumerSeq.getAndIncrement();// 自增return consumerEnvList.get(index);}
VirtualHost 中订阅消息实现
/*** 订阅消息* 添加一个队列的订阅者,当队列收到消息之后,就要把消息推送给对应的订阅者* @param consumerTag 消费者的身份标识* @param queueName* @param autoAck 消息被消费之后,应答的方式,true 标识自动应答,false 标识手动应答* @param consumer 是一个回调函数,此处设定成函数式接口,这样后续调用 basicConsume 并且传实参的时候,就可以写作 lambda 样子了* @return*/public boolean basicConsume(String consumerTag, String queueName, boolean autoAck, Consumer consumer) {//构造一个 ConsumerEnv 对象,把这个对应的队列找到,再把 Consumer 对象添加到队列中queueName = virtualHostName + queueName;try {consumerManager.addConsumer(consumerTag, queueName, autoAck, consumer);System.out.println("[VirtualHost] basicConsume 成功! queueName=" + queueName);return true;} catch (Exception e) {e.printStackTrace();System.out.println("[VirtualHost] basicConsume 失败! queueName=" + queueName);return false;}}
1.2.2、消费者描述自己执行任务方式实现思路
当执行订阅消息的时候,我们就让消费者自己去实现处理消息的操作(消息的内容通过参数传递,具体要干啥,取决于消费者自己的业务路基),最后再让线程池来执行回调函数.
这里我们使用函数式接口(回调函数)的方式(lambda 表达式),让消费者在订阅消息的时候,就可以实现未来收到消息后如何去处理消息的操作.
@FunctionalInterface
public interface Consumer {/*** Delivery 的意思是 ”投递“,这个方法预期是在服务器收到消息之后来调用* 通过这个方法,把消息推送给对应的消费者* (注意,这里的方法名和参数,也都是参考 RabbitMQ 来展开的)* @param consumerTag* @param basicProperties* @param body*/void handlerDelivery(String consumerTag, BasicProperties basicProperties, byte[] body);}
为什么要这样实现?
一方面,这种思路也是参考 RabbitMQ。
另一方面,这是由于Java 的函数是不能脱离类存在的,为了实现这种 lambda,java 曲线救国,引入 函数式接口.
对于函数式接口来说:
- 首先是 interface 类型
- 只能有一个方法
- 添加 @FunctionalInterface 注解.
实际上,这也是 lambda 的底层实现(本质)
1.2.3、消息推送给消费者实现思路
这里我们可以添加一个扫描线程,让他来去队列中拿任务.
为什么用了扫描线程还需要用线程池?
如果就一个扫描线程,既要获取消息,又要执行回调,这一个线程可能会忙不过来,因为消费者给出的回调,具体干什么的,咱们是不知道的.
扫描线程怎么知道哪个队列来了新的消息?
- 一个简单粗暴的办法,就是直接让扫描线程不停的循环遍历所有队列,发现有元素就立即处理。
- 另一个更优雅的办法(我采取的办法),就是用一个阻塞队列,队列中的元素就是接收消息的队列的名字,扫描线程只需要盯住这一个阻塞对垒即可,此时阻塞队列中传递的队列名,就相当于 “令牌”
每次拿到令牌,才能调动一次军队,也就是从对应的队列中取一个消息.
具体的,实现一个 ConsumerManager 类,用来管理消费者的上述行为.
public class ConsumerManager {// 持有上层的 VirtualHost 对象的引用,用来操作数据private VirtualHost parent;// 指定一个线程池,负责取执行具体的回调任务private ExecutorService workerPool = Executors.newFixedThreadPool(4);//存放令牌的队列private BlockingQueue<String> tokenQueue = new LinkedBlockingQueue<>();//扫描线程private Thread scannerThread = null;/*** 初始化* @param parent*/public ConsumerManager(VirtualHost parent) {this.parent = parent;//创建扫描线程,取队列中消费消息scannerThread = new Thread(() -> {while(true) {try {//1.拿到令牌String queueName = tokenQueue.take();//2.根据令牌,找到队列MSGQueue queue = parent.getMemoryDataCenter().getQueue(queueName);if(queue == null) {throw new MqException("[ConsumerManager] 取到令牌后发现,该队列名不存在!queueName=" + queueName);}//3.从这个队列中消费一个消息synchronized (queue) {consumeMessage(queue);}} catch (InterruptedException | MqException e) {throw new RuntimeException(e);}}});//设置为后台线程scannerThread.setDaemon(true);scannerThread.start();}public void notifyConsume(String queueName) throws InterruptedException {tokenQueue.put(queueName);}/*** 添加消费者* 找到对应队列的 List 列表, 把消费者添加进去,最后判断,如果有消息,就立刻消费* @param consumerTag 消费者身份标识* @param queueName* @param autoAck 消息被消费之后,应答的方式,true 标识自动应答,false 标识手动应答* @param consumer 是一个回调函数,此处设定成函数式接口,这样后续调用 basicConsume 并且传实参的时候,就可以写作 lambda 样子了* @throws MqException*/public void addConsumer(String consumerTag, String queueName, boolean autoAck, Consumer consumer) throws MqException {//找到对应的队列MSGQueue queue = parent.getMemoryDataCenter().getQueue(queueName);if(queue == null) {throw new MqException("[ConsumerManager] 队列不存在! queueName=" + queueName);}ConsumerEnv consumerEnv = new ConsumerEnv(consumerTag, queueName, autoAck, consumer);synchronized (queue) {queue.addConsumerEnv(consumerEnv);//如果当前队列中已经有一些消息了,需要立即消费掉int n = parent.getMemoryDataCenter().getMessageCount(queueName);for(int i = 0; i < n; i++) {//这个方法调用一次就消费一条消息consumeMessage(queue);}}}/*** 扫描线程:找到对应的队列后,消费者从队列中拿出消息并消费* @param queue*/private void consumeMessage(MSGQueue queue) {//1.按照轮询的方式,找个消费者出来ConsumerEnv luckDog = queue.chooseConsumer();if(luckDog == null) {//当前队列中没有消费者,暂时不用消费,等后面有消费者了再说return;}//2.从队列中取出一个消息Message message = parent.getMemoryDataCenter().pollMessage(queue.getName());if(message == null) {//当前队列中还没有消息,也不需要消费return;}//3.把消息带入到消费者的回调方法中,丢给线程池执行workerPool.submit(() -> {try {//1.把消息放到待确认的集合当中,这个操作一定要在执行回调之前(防止执行回调过程中出现异常,导致消息丢失)parent.getMemoryDataCenter().addMessageWaitAck(luckDog.getQueueName(), message);//2.真正执行回调操作luckDog.getConsumer().handlerDelivery(luckDog.getConsumerTag(), message.getBasicProperties(),message.getBody());//3.如果当前是 ”自动应答“ ,就可以直接把消息删除了// 如果当前是 ”手动应答“ ,则先不处理,交给后续消费者调用 basicAck 方法来处理if(luckDog.isAutoAck()) {//1) 删除硬盘上的消息if(message.getDeliverMode() == 2) {parent.getDiskDataCenter().deleteMessage(queue, message);}//2) 删除上面的待确认集合中的消息parent.getMemoryDataCenter().removeMessageWaitAck(queue.getName(), message.getMessageId());//3) 删除内存上的消息中心的消息parent.getMemoryDataCenter().removeMessage(message.getMessageId());System.out.println("[ConsumerManager] 消息被成功消费!queueName=" + queue.getName());}} catch (Exception e) {e.printStackTrace();}});}
}
1.2.4、消息确认
消息确认,就是保证消息被正确消费~~
正确消费就是指消费者的回调方法顺利执行完了(没有抛异常之类的),这条消息的使命就完成了,此时就可以删除了。
为了达成消息不丢失这样的效果,具体步骤如下:
- 在真正执行回调之前,把消息放到 “待确认的集合” 中,避免应为回调失败,导致消息丢失.

- 执行回调
- 当去消费者采取的是 autoAck=true ,就认为回调执行完毕不抛异常,就算消费成功,然后就可以删除消息了
- 硬盘
- 内存中的消息中心
- 待确认的消息集合
- 当前消费者若采取的是 autoAck=false,手动应答,需要消费者这边,在自己的回调方法内部,显式调用 basicAck 这个核心 API 表示应答.
basicAck 完成主动应答
/*** 确认消息* 各个维度删除消息即可* @param queueName* @param messageId* @return*/public boolean basicAck(String queueName, String messageId) {queueName = virtualHostName + queueName;try {//1.获取消息和队列MSGQueue queue = memoryDataCenter.getQueue(queueName);if(queue == null) {throw new MqException("[VirtualHost] 要确认的队列不存在!queueName=" + queueName);}Message message = memoryDataCenter.getMessage(messageId);if(message == null) {throw new MqException("[VirtualHost] 要确认的消息不存在!messageId=" + messageId);}//2.各个维度删除消息if(message.getDeliverMode() == 2) {diskDataCenter.deleteMessage(queue, message);}memoryDataCenter.removeMessage(messageId);memoryDataCenter.removeMessageWaitAck(queueName, messageId);System.out.println("[VirtualHost] basicAck 成功,消息确认成功!queueName=" + queueName +", messageId=" + messageId);return true;} catch (Exception e) {System.out.println("[VirtualHost] basicAck 失败,消息确认失败!queueName=" + queueName +", messageId=" + messageId);e.printStackTrace();return false;}}
扫描线程完成自动应答
/*** 扫描线程:找到对应的队列后,消费者从队列中拿出消息并消费* @param queue*/private void consumeMessage(MSGQueue queue) {//1.按照轮询的方式,找个消费者出来ConsumerEnv luckDog = queue.chooseConsumer();if(luckDog == null) {//当前队列中没有消费者,暂时不用消费,等后面有消费者了再说return;}//2.从队列中取出一个消息Message message = parent.getMemoryDataCenter().pollMessage(queue.getName());if(message == null) {//当前队列中还没有消息,也不需要消费return;}//3.把消息带入到消费者的回调方法中,丢给线程池执行workerPool.submit(() -> {try {//1.把消息放到待确认的集合当中,这个操作一定要在执行回调之前(防止执行回调过程中出现异常,导致消息丢失)parent.getMemoryDataCenter().addMessageWaitAck(luckDog.getQueueName(), message);//2.真正执行回调操作luckDog.getConsumer().handlerDelivery(luckDog.getConsumerTag(), message.getBasicProperties(),message.getBody());//3.如果当前是 ”自动应答“ ,就可以直接把消息删除了// 如果当前是 ”手动应答“ ,则先不处理,交给后续消费者调用 basicAck 方法来处理if(luckDog.isAutoAck()) {//1) 删除硬盘上的消息if(message.getDeliverMode() == 2) {parent.getDiskDataCenter().deleteMessage(queue, message);}//2) 删除上面的待确认集合中的消息parent.getMemoryDataCenter().removeMessageWaitAck(queue.getName(), message.getMessageId());//3) 删除内存上的消息中心的消息parent.getMemoryDataCenter().removeMessage(message.getMessageId());System.out.println("[ConsumerManager] 消息被成功消费!queueName=" + queue.getName());}} catch (Exception e) {e.printStackTrace();}});}
如果在回调方法中抛异常了?
回调方法中抛异常了,后续逻辑执行不到,这个消息就会始终呆在待确认的集合中, RabbitMQ 的做法是另外搞一个扫描线程(其实 RabbitMQ 中不叫线程,人家是叫进程,但是注意,这个进程不是操作系统中的进程,而是 erlang 中的概念),负责关注这个 待确认集合中,每个消息待了多久了,如果超出了一定的时间范围,就会把这个消息放到一个特定的队列 —— “死信队列”(这里就不展示了,需要的可以私聊我)
如果在执行回调过程中,broker server 崩了,内存数据全没了?
此时硬盘的数据还在,broker server 重启之后,这个消息就又被加载回内存了,就像从来没有被消费过一样,消费者就又机会重新拿到这个消息,重新消费(重复消费的问题,是由消费者的业务代码负责保证的,broker server 管不了).

相关文章:
根据源码,模拟实现 RabbitMQ - 虚拟主机 + Consume设计 (7)
目录 一、虚拟主机 Consume设计 1.1、承接问题 1.2、具体实现 1.2.1、消费者订阅消息实现思路 1.2.2、消费者描述自己执行任务方式实现思路 1.2.3、消息推送给消费者实现思路 1.2.4、消息确认 一、虚拟主机 Consume设计 1.1、承接问题 前面已经实现了虚拟主机大部分功…...

docker中bridge、host、container、none四种网络模式简介
目录 一.bridge模式 1.简介 2.演示 (1)运行两个容器,不指定网络模式情况下默认是bridge模式 (2)在主机中自动生成了两个veth设备 (3)查看两个容器的IP地址 (4)可以…...
排序算法之详解冒泡排序
引入 冒泡排序顾名思义,就是像冒泡一样,泡泡在水里慢慢升上来,由小变大。虽然冒泡排序和冒泡并不完全一样,但却可以帮助我们理解冒泡排序。 思路 一组无序的数组,要求我们从小到大排列 我们可以先将最大的元素放在数组…...

el-upload组件调用后端接口上传文件实践
要点说明: 使用:http-request覆盖默认的上传行为,可以添加除文件外的其他参数,注意此时仍需保留action属性,action可以传个空串给http-request属性绑定的函数,函数入参必须为param调用接口请求,注意 heade…...

深度学习-实验1
一、Pytorch基本操作考察(平台课专业课) 使用𝐓𝐞𝐧𝐬𝐨𝐫初始化一个 𝟏𝟑的矩阵 𝑴和一个 𝟐𝟏的矩阵 𝑵&am…...
互联网医院开发|医院叫号系统提升就医效率
在这个数字化时代,互联网医院不仅改变了我们的生活方式,也深刻影响着医疗行业。医院叫号系统应运而生,它能够有效解决患者管理和服务方面的难题。不再浪费大量时间在排队上,避免患者错过重要信息。同时,医护工作效率得…...
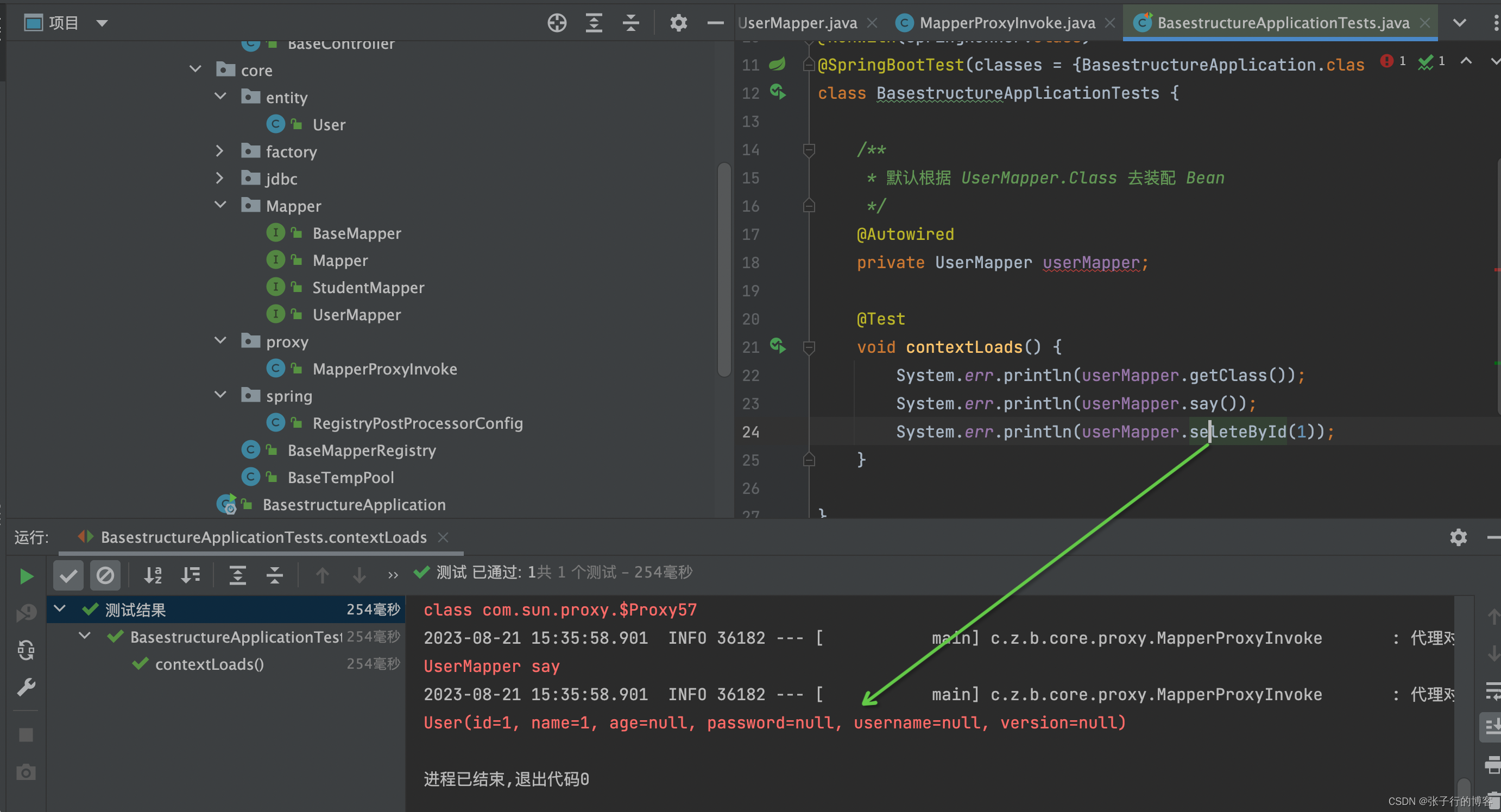
手写 Mybatis-plus 基础架构(工厂模式+ Jdk 动态代理统一生成代理 Mapper)
这里写目录标题 前言温馨提示手把手带你解析 MapperScan 源码手把手带你解析 MapperScan 源码细节剖析工厂模式Jdk 代理手撕脚手架,复刻 BeanDefinitionRegistryPostProcessor手撕 FactoryBean代理 Mapper 在 Spring 源码中的生成流程手撕 MapperProxyFactory手撕增…...

【C++11算法】iota算法
文章目录 前言一、iota函数1.1 iota是什么?1.2 函数原型1.3 参数和返回值1.4 示例代码1.5 示例代码21.6 示例代码3 总结 前言 C标准库提供了丰富的算法,其中之一就是iota算法。iota算法用于填充一个区间,以递增的方式给每个元素赋予一个值。…...

付费加密音乐格式转换Mp3、Flac工具
一、工具介绍 这是一款免费的将付费加密音乐等多种格式转换Mp3 Flac工具,现在大部分云音乐公司,比如QQ音乐、酷我音乐、酷狗音乐、网易云音乐、虾米音乐(RIP🙏)等,都推出了自己专属的云音乐格式,这些格式一般只能在制定的播放器里播放,其它的播放软件并不支持,在很多情…...
React前端开发架构:构建现代响应式用户界面
在当今的Web应用开发中,React已经成为最受欢迎的前端框架之一。它的出色性能、灵活性和组件化开发模式,使得它成为构建现代响应式用户界面的理想选择。在这篇文章中,我们将探讨React前端开发架构的核心概念和最佳实践,以帮助您构建…...
Azure Bastion的简单使用
什么是Azure Bastion Azure Bastion 是一个提供安全远程连接到 Azure 虚拟机(VM)的服务。传统上,访问 VM 需要使用公共 IP 或者设立 VPN 连接,这可能存在一些安全风险。Azure Bastion 提供了一种更安全的方式,它是一个…...

深入理解高并发编程 - 深度解析ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor 并实现了 ScheduledExecutorService 接口,这使得它可以同时充当线程池和定时任务调度器。 构造方法 public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, …...
Android---- 一个完整的小项目(消防app)
前言: 针对不同群体的需求,想着应该拓展写方向。医疗app很受大家喜欢,就打算顺手写个消防app,里面基础框架还是挺简洁 规整的。登陆注册和本地数据库写的便于大家理解。是广大学子的毕设首选啊! 此app主要为了传递 消防…...
XXX程序 详细说明
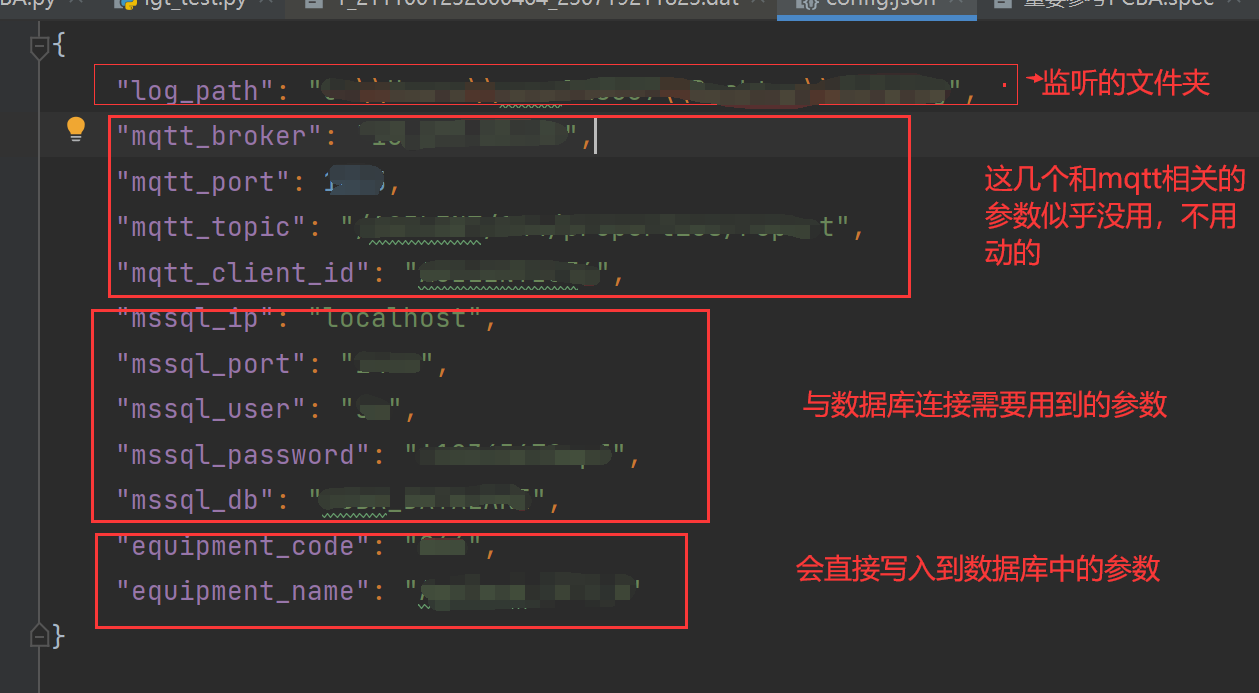
用于记录理解PC程序的程序逻辑 1、程序的作用 根据原作者的说明(文件说明.txt),该程序 (PC.py) 的主要作用是提取某一个文件夹中的某个设备 (通过config中的信息看出来是Ag_T_8) 产生的日志文件,然后提取其中某些需要的数据&…...

perl下载与安装教程【工具使用】
Perl是一个高阶程式语言,由 Larry Wall和其他许多人所写,融合了许多语言的特性。它主要是由无所不在的 C语言,其次由 sed、awk,UNIX shell 和至少十数种其他的工具和语言所演化而来。Perl对 process、档案,和文字有很强…...

Chrome谷歌浏览器修改输入框自动填充样式
Chrome谷歌浏览器修改输入框自动填充样式 背景字体 背景 input:-webkit-autofill{-webkit-box-shadow:0 0 0 1000px #fff inset !important; }字体 input:-internal-autofill-selected {-webkit-text-fill-color: #000 !important; }...
Azure CLI 进行磁盘加密
什么是磁盘加密 磁盘加密是指在Azure中对虚拟机的磁盘进行加密保护的一种机制。它使用Azure Key Vault来保护磁盘上的数据,以防止未经授权的访问和数据泄露。使用磁盘加密,可以保护磁盘上的数据以满足安全和合规性要求。 参考文档:https://l…...
速卖通商品列表页面数据获取方法,速卖通API实现批量商品数据抓取示例)
Java“牵手”根据关键词搜索(分类搜索)速卖通商品列表页面数据获取方法,速卖通API实现批量商品数据抓取示例
速卖通商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取速卖通商品列表和商品详情页面数据,您可以通过开放平台的接口或者直接访问速卖通商城的网页来获取商品详情信息。以下是两种常用方法的介…...
商城-学习整理-高级-消息队列(十七)
目录 一、RabbitMQ简介(消息中间件)1、RabbitMQ简介:2、核心概念1、Message2、Publisher3、Exchange4、Queue5、Binding6、Connection7、Channel8、Consumer9、Virtual Host10、Broker 二、一些概念1、异步处理2、应用解耦3、流量控制5、概述 三、Docker安装RabbitM…...
:初识Camera)
Android Camere开发入门(1):初识Camera
Android Camere开发入门(1):初识Camera 初步了解 在Android开发中,相机(Camera)是一个常见而重要的功能模块。它允许我们通过设备的摄像头捕捉照片和录制视频,为我们的应用程序增加图像处理和视觉交互的能力。 随着Android系统的不断发展和更新,相机功能也不断改进和增…...

为AI编程助手设置安全规则:从原理到实践的工程指南
1. 项目概述:为你的AI编程伙伴戴上“紧箍咒”如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过那种“冰火两重天”的感觉。一方面,它能以惊人的速度生成代码、重构函数、甚至解释复杂逻辑,极大地提升了开发…...

5分钟上手Efficient-KAN:高效Kolmogorov-Arnold网络实战指南
5分钟上手Efficient-KAN:高效Kolmogorov-Arnold网络实战指南 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan 还在为传统神…...

图像处理核心技术:分辨率、信噪比与形态学算法解析
1. 图像处理基础概念解析在数字图像处理领域,我们经常需要面对几个核心问题:如何量化系统的分辨能力?如何评估图像质量?如何从噪声中提取有用信息?这些问题的答案构成了现代图像处理技术的理论基础。作为一名从业十余年…...

告别黑盒:手把手教你用S-Function在Simulink里打造自己的16QAM调制解调模块
从零构建16QAM通信链路:Simulink S-Function深度开发指南 在通信系统仿真领域,现成模块虽然方便,却常常成为深入理解底层原理的障碍。当我们需要验证特定算法、优化系统性能或进行教学演示时,自主构建核心模块的能力显得尤为重要…...
实现原理和本地化最佳实践)
Sonixd多语言支持详解:国际化(i18n)实现原理和本地化最佳实践
Sonixd多语言支持详解:国际化(i18n)实现原理和本地化最佳实践 【免费下载链接】sonixd A full-featured Subsonic/Jellyfin compatible desktop music player 项目地址: https://gitcode.com/gh_mirrors/so/sonixd Sonixd是一款功能强大的桌面音乐播放器&…...

HarmonyOS 6.0 跨端页面构建实践:从 UI 代码到热力交互卡片设计
HarmonyOS 6.0 跨端页面构建实践:从 UI 代码到热力交互卡片设计 前言 在 HarmonyOS 6.0 的跨端开发体系中,页面构建的核心目标已经从“能运行”逐步转向“高一致性体验 低成本跨端复用”。尤其是在多设备协同的场景下,一个 UI 组件不仅要适配…...

快图设计:5个理由告诉你为什么这款Vue图片编辑器值得尝试
快图设计:5个理由告诉你为什么这款Vue图片编辑器值得尝试 【免费下载链接】vue-fabric-editor 快图设计-基于fabric.js和Vue的开源图片编辑器,可自定义字体、素材、设计模板。fabric.js and Vue based image editor, can customize fonts, materials, de…...

前端工程化:开发环境配置最佳实践
前端工程化:开发环境配置最佳实践 前言 开发环境配置是前端工程化的基础。一个良好的开发环境能大大提高开发效率,减少团队协作中的环境问题。今天我就来给大家讲讲如何配置一套高效的前端开发环境。 为什么开发环境配置如此重要 开发环境是开发者日常工…...

ARM系统指令与内存管理深度解析
1. ARM系统指令概述与内存管理基础在ARM架构中,系统指令扮演着关键角色,它们为操作系统和底层软件开发提供了必要的硬件控制接口。这些指令通常运行在特权模式下,用于执行诸如内存管理、缓存控制、系统配置等敏感操作。ATS1CPWP、BPIALL和CCS…...

联想拯救者15ISK加装NVMe SSD实战:从硬件兼容到系统部署的避坑指南
1. 联想拯救者15ISK加装NVMe SSD前的准备工作 我手上这台联想拯救者15ISK已经陪伴我征战了五年多,最近明显感觉到系统响应变慢,游戏加载时间变长。经过一番排查,发现瓶颈主要出在机械硬盘上。于是决定给它加装一块NVMe SSD,让老战…...