【K8S源码之Pod漂移】整体概况分析 controller-manager 中的 nodelifecycle controller(Pod的驱逐)
参考
-
k8s 污点驱逐详解-源码分析 - 掘金
-
k8s驱逐篇(5)-kube-controller-manager驱逐 - 良凯尔 - 博客园
-
k8s驱逐篇(6)-kube-controller-manager驱逐-NodeLifecycleController源码分析 - 良凯尔 - 博客园
-
k8s驱逐篇(7)-kube-controller-manager驱逐-taintManager源码分析 - 良凯尔 - 博客园
整体概况分析
- 基于 k8s 1.19 版本分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h6S3bs1J-1692352728103)(img/nodelifecycle笔记/image-20230818164014721.png)]](https://img-blog.csdnimg.cn/dc9103b43c324cb28bf4d0cfbd4c2104.png)
TaintManager 与 非TaintManager
- TaintManager 模式
- 发现 Node Unhealthy 后(也就是 Node Ready Condition = False 或 Unknown),会更新 Pod Ready Condition 为 False(表示 Pod 不健康),也会给 Node 打上 NoExecute Effect 的 Taint
- 之后 TaintManager 根据 Pod 的 Toleration 判断,是否有设置容忍 NoExecute Effect Taint 的 Toleration
- 没有 Toleration 的话,就立即驱逐
- 有 Toleration ,会根据 Toleration 设置的时长,定时删除该 Pod
- 默认情况下,会设置个 5min 的Toleration,也就是 5min 后会删除此 Pod
- 非 TaintManager 模式(默认模式)
- 发现 Node Unhealthy 后,会更新 Pod Ready Condition 为 False(表示 Pod 不健康)
- 之后会记录该 Node,等待 PodTimeout(5min) - nodegracePeriod(40s) 时间后,驱逐该 Node 上所有 Pod(Node级别驱逐),之后标记该 Node 为 evicted 状态(此处是代码中标记,资源上没有此状态)
- 之后便只考虑单 Pod 的驱逐(可能考虑部分 Pod 失败等)
- 若 Node 已经被标记为 evicted 状态,那么可以进行单 Pod 的驱逐
- 若 Node 没有被标记为 evicted 状态,那将 Node 标记为 tobeevicted 状态,等待上面 Node 级别的驱逐
代码中的几个存储结构
| nodeEvictionMap *nodeEvictionMap | // nodeEvictionMap stores evictionStatus *data for each node. *type nodeEvictionMap struct { lock sync.Mutex nodeEvictions map[string]evictionStatus } | 记录所有 node 的状态 1. 健康 unmarked 2. 等待驱逐 tobeevicted 3. 驱逐完成 evicted |
| zoneStates map[string]ZoneState | type ZoneState string | 记录 zone 的健康状态 1. 新zone Initial 2. 健康的zone Normal 3. 部分健康zone PartialDisruption 4. 完全不健康 FullDisruption 这个是用于设置该zone 的驱逐速率 |
| zonePodEvictor map[string]*scheduler.RateLimitedTimedQueue | 失联(不健康)的 Node 会放入此结构中,等待被驱逐,之后nodeEvictionMap 对应的状态记录会被设置为 evicted 1. 该结构,key 为zone,value 为限速队列处理(也就是上面驱逐效率起作用的地方) 2. 当一个 node 不健康,首先会计算出该 node 对应的zone 3. 然后放入该结构中 | |
| nodeHealthMap *nodeHealthMap | type nodeHealthMap struct { lock sync.RWMutex nodeHealths map[string]*nodeHealthData } | |
| type nodeHealthData struct { probeTimestamp metav1.Time readyTransitionTimestamp metav1.Time status *v1.NodeStatus lease *coordv1.Lease } | 记录每个node的健康状态,主要在 monitorHealth 函数中使用 1. 其中 probeTimestamp 最关键,该参数记录该 Node 最后一次健康的时间,也就是失联前最后一个 lease 的时间 2. 之后根据 probeTimestamp 和宽限时间 gracePeriod,判断该 node 是否真正失联,并设置为 unknown 状态 |
整体代码流程分析
// Run starts an asynchronous loop that monitors the status of cluster nodes.
func (nc *Controller) Run(stopCh <-chan struct{}) {defer utilruntime.HandleCrash()
klog.Infof("Starting node controller")defer klog.Infof("Shutting down node controller")// 1.等待leaseInformer、nodeInformer、podInformerSynced、daemonSetInformerSynced同步完成。if !cache.WaitForNamedCacheSync("taint", stopCh, nc.leaseInformerSynced, nc.nodeInformerSynced, nc.podInformerSynced, nc.daemonSetInformerSynced) {return}// 2.如果enable-taint-manager=true,开启nc.taintManager.Runif nc.runTaintManager {go nc.taintManager.Run(stopCh)}// Close node update queue to cleanup go routine.defer nc.nodeUpdateQueue.ShutDown()defer nc.podUpdateQueue.ShutDown()// 3.执行doNodeProcessingPassWorker,这个是处理nodeUpdateQueue队列的node// Start workers to reconcile labels and/or update NoSchedule taint for nodes.for i := 0; i < scheduler.UpdateWorkerSize; i++ {// Thanks to "workqueue", each worker just need to get item from queue, because// the item is flagged when got from queue: if new event come, the new item will// be re-queued until "Done", so no more than one worker handle the same item and// no event missed.go wait.Until(nc.doNodeProcessingPassWorker, time.Second, stopCh)}// 4.doPodProcessingWorker,这个是处理podUpdateQueue队列的podfor i := 0; i < podUpdateWorkerSize; i++ {go wait.Until(nc.doPodProcessingWorker, time.Second, stopCh)}// 5. 如果开启了feature-gates=TaintBasedEvictions=true,执行doNoExecuteTaintingPass函数。否则执行doEvictionPass函数if nc.useTaintBasedEvictions {// Handling taint based evictions. Because we don't want a dedicated logic in TaintManager for NC-originated// taints and we normally don't rate limit evictions caused by taints, we need to rate limit adding taints.go wait.Until(nc.doNoExecuteTaintingPass, scheduler.NodeEvictionPeriod, stopCh)} else {// Managing eviction of nodes:// When we delete pods off a node, if the node was not empty at the time we then// queue an eviction watcher. If we hit an error, retry deletion.go wait.Until(nc.doEvictionPass, scheduler.NodeEvictionPeriod, stopCh)}// 6.一直监听node状态是否健康// Incorporate the results of node health signal pushed from kubelet to master.go wait.Until(func() {if err := nc.monitorNodeHealth(); err != nil {klog.Errorf("Error monitoring node health: %v", err)}}, nc.nodeMonitorPeriod, stopCh)<-stopCh
}MonitorNodeHealth
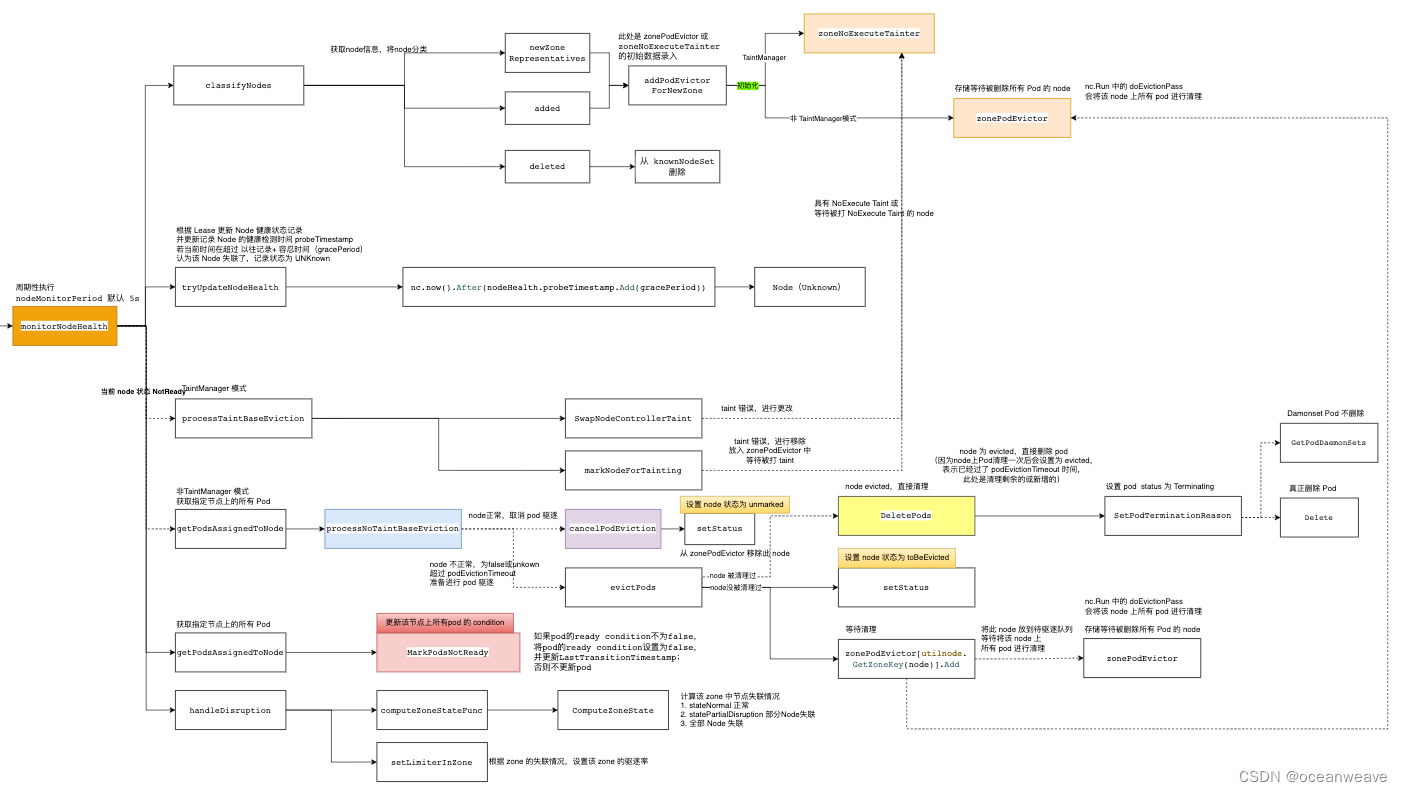
此部分有如下几个作用
-
读取 Node 的 Label,用于确定 Node 属于哪个 zone;若该 zone 是新增的,就注册到 zonePodEvictor 或 zoneNoExecuteTainter (TaintManager 模式)
-
zonePodEvictor 后续用于该 zone 中失联的 Node,用于 Node 级别驱逐(就是驱逐 Node 上所有 Pod,并设置为 evicted 状态,此部分参见)
-
// pkg/controller/nodelifecycle/node_lifecycle_controller.go // addPodEvictorForNewZone checks if new zone appeared, and if so add new evictor. // dfy: 若出现新的 zone ,初始化 zonePodEvictor 或 zoneNoExecuteTainter func (nc *Controller) addPodEvictorForNewZone(node *v1.Node) {nc.evictorLock.Lock()defer nc.evictorLock.Unlock()zone := utilnode.GetZoneKey(node)// dfy: 若出现新的 zone ,初始化 zonePodEvictor 或 zoneNoExecuteTainterif _, found := nc.zoneStates[zone]; !found {// dfy: 没有找到 zone value,设置为 Initialnc.zoneStates[zone] = stateInitial// dfy: 没有 TaintManager,创建一个 限速队列,不太清楚有什么作用???if !nc.runTaintManager {// dfy: zonePodEvictor 负责将 pod 从无响应的节点驱逐出去nc.zonePodEvictor[zone] =scheduler.NewRateLimitedTimedQueue(flowcontrol.NewTokenBucketRateLimiter(nc.evictionLimiterQPS, scheduler.EvictionRateLimiterBurst))} else {// dfy: zoneNoExecuteTainter 负责为 node 打上污点 taintnc.zoneNoExecuteTainter[zone] =scheduler.NewRateLimitedTimedQueue(flowcontrol.NewTokenBucketRateLimiter(nc.evictionLimiterQPS, scheduler.EvictionRateLimiterBurst))}// Init the metric for the new zone.klog.Infof("Initializing eviction metric for zone: %v", zone)evictionsNumber.WithLabelValues(zone).Add(0)} }func (nc *Controller) doEvictionPass() {nc.evictorLock.Lock()defer nc.evictorLock.Unlock()for k := range nc.zonePodEvictor {// Function should return 'false' and a time after which it should be retried, or 'true' if it shouldn't (it succeeded).nc.zonePodEvictor[k].Try(func(value scheduler.TimedValue) (bool, time.Duration) {// dfy: 此处 value.Value 存储的是 Cluster Namenode, err := nc.nodeLister.Get(value.Value)if apierrors.IsNotFound(err) {klog.Warningf("Node %v no longer present in nodeLister!", value.Value)} else if err != nil {klog.Warningf("Failed to get Node %v from the nodeLister: %v", value.Value, err)}nodeUID, _ := value.UID.(string)// dfy: 获得分配到该节点上的 Podpods, err := nc.getPodsAssignedToNode(value.Value)if err != nil {utilruntime.HandleError(fmt.Errorf("unable to list pods from node %q: %v", value.Value, err))return false, 0}// dfy: 删除 Podremaining, err := nodeutil.DeletePods(nc.kubeClient, pods, nc.recorder, value.Value, nodeUID, nc.daemonSetStore)if err != nil {// We are not setting eviction status here.// New pods will be handled by zonePodEvictor retry// instead of immediate pod eviction.utilruntime.HandleError(fmt.Errorf("unable to evict node %q: %v", value.Value, err))return false, 0}// dfy: 在nodeEvictionMap设置node的状态为evictedif !nc.nodeEvictionMap.setStatus(value.Value, evicted) {klog.V(2).Infof("node %v was unregistered in the meantime - skipping setting status", value.Value)}if remaining {klog.Infof("Pods awaiting deletion due to Controller eviction")}if node != nil {zone := utilnode.GetZoneKey(node)evictionsNumber.WithLabelValues(zone).Inc()}return true, 0})} }
-
-
监听 Node 健康状态(通过监听 Node Lease 进行判别)
-
若 Lease 不更新,且超过了容忍时间 gracePeriod,认为该 Node 失联(更新 Status Ready Condition 为 Unknown)
-
// tryUpdateNodeHealth checks a given node's conditions and tries to update it. Returns grace period to // which given node is entitled, state of current and last observed Ready Condition, and an error if it occurred. func (nc *Controller) tryUpdateNodeHealth(node *v1.Node) (time.Duration, v1.NodeCondition, *v1.NodeCondition, error) {// 省略一大部分 probeTimestamp 更新逻辑// dfy: 通过 lease 更新,来更新 probeTimestampobservedLease, _ := nc.leaseLister.Leases(v1.NamespaceNodeLease).Get(node.Name)if observedLease != nil && (savedLease == nil || savedLease.Spec.RenewTime.Before(observedLease.Spec.RenewTime)) {nodeHealth.lease = observedLeasenodeHealth.probeTimestamp = nc.now()}// dfy: 注意此处, Lease 没更新,导致 probeTimestamp 没变动,因此 现在时间超过了容忍时间,将此 Node 视作失联 Nodeif nc.now().After(nodeHealth.probeTimestamp.Add(gracePeriod)) {// NodeReady condition or lease was last set longer ago than gracePeriod, so// update it to Unknown (regardless of its current value) in the master.nodeConditionTypes := []v1.NodeConditionType{v1.NodeReady,v1.NodeMemoryPressure,v1.NodeDiskPressure,v1.NodePIDPressure,// We don't change 'NodeNetworkUnavailable' condition, as it's managed on a control plane level.// v1.NodeNetworkUnavailable,}nowTimestamp := nc.now()// dfy: 寻找 node 是否有上面几个异常状态for _, nodeConditionType := range nodeConditionTypes {// dfy: 具有异常状态,就进行记录_, currentCondition := nodeutil.GetNodeCondition(&node.Status, nodeConditionType)if currentCondition == nil {klog.V(2).Infof("Condition %v of node %v was never updated by kubelet", nodeConditionType, node.Name)node.Status.Conditions = append(node.Status.Conditions, v1.NodeCondition{Type: nodeConditionType,Status: v1.ConditionUnknown,Reason: "NodeStatusNeverUpdated",Message: "Kubelet never posted node status.",LastHeartbeatTime: node.CreationTimestamp,LastTransitionTime: nowTimestamp,})} else {klog.V(2).Infof("node %v hasn't been updated for %+v. Last %v is: %+v",node.Name, nc.now().Time.Sub(nodeHealth.probeTimestamp.Time), nodeConditionType, currentCondition)if currentCondition.Status != v1.ConditionUnknown {currentCondition.Status = v1.ConditionUnknowncurrentCondition.Reason = "NodeStatusUnknown"currentCondition.Message = "Kubelet stopped posting node status."currentCondition.LastTransitionTime = nowTimestamp}}}// We need to update currentReadyCondition due to its value potentially changed._, currentReadyCondition = nodeutil.GetNodeCondition(&node.Status, v1.NodeReady)if !apiequality.Semantic.DeepEqual(currentReadyCondition, &observedReadyCondition) {if _, err := nc.kubeClient.CoreV1().Nodes().UpdateStatus(context.TODO(), node, metav1.UpdateOptions{}); err != nil {klog.Errorf("Error updating node %s: %v", node.Name, err)return gracePeriod, observedReadyCondition, currentReadyCondition, err}nodeHealth = &nodeHealthData{status: &node.Status,probeTimestamp: nodeHealth.probeTimestamp,readyTransitionTimestamp: nc.now(),lease: observedLease,}return gracePeriod, observedReadyCondition, currentReadyCondition, nil}}return gracePeriod, observedReadyCondition, currentReadyCondition, nil }
-
-
根据 zone 设置驱逐速率
-
每个 zone 有不同数量的 Node,根据该 zone 中 Node 失联数量的占比,设置不同的驱逐速率
-
// dfy: 1. 计算 zone 不健康程度; 2. 根据 zone 不健康程度设置不同的驱逐速率 func (nc *Controller) handleDisruption(zoneToNodeConditions map[string][]*v1.NodeCondition, nodes []*v1.Node) {newZoneStates := map[string]ZoneState{}allAreFullyDisrupted := truefor k, v := range zoneToNodeConditions {zoneSize.WithLabelValues(k).Set(float64(len(v)))// dfy: 计算该 zone 的不健康程度(就是失联 node 的占比)// nc.computeZoneStateFunc = nc.ComputeZoneStateunhealthy, newState := nc.computeZoneStateFunc(v)zoneHealth.WithLabelValues(k).Set(float64(100*(len(v)-unhealthy)) / float64(len(v)))unhealthyNodes.WithLabelValues(k).Set(float64(unhealthy))if newState != stateFullDisruption {allAreFullyDisrupted = false}newZoneStates[k] = newStateif _, had := nc.zoneStates[k]; !had {klog.Errorf("Setting initial state for unseen zone: %v", k)nc.zoneStates[k] = stateInitial}}allWasFullyDisrupted := truefor k, v := range nc.zoneStates {if _, have := zoneToNodeConditions[k]; !have {zoneSize.WithLabelValues(k).Set(0)zoneHealth.WithLabelValues(k).Set(100)unhealthyNodes.WithLabelValues(k).Set(0)delete(nc.zoneStates, k)continue}if v != stateFullDisruption {allWasFullyDisrupted = falsebreak}}// At least one node was responding in previous pass or in the current pass. Semantics is as follows:// - if the new state is "partialDisruption" we call a user defined function that returns a new limiter to use,// - if the new state is "normal" we resume normal operation (go back to default limiter settings),// - if new state is "fullDisruption" we restore normal eviction rate,// - unless all zones in the cluster are in "fullDisruption" - in that case we stop all evictions.if !allAreFullyDisrupted || !allWasFullyDisrupted {// We're switching to full disruption modeif allAreFullyDisrupted {klog.V(0).Info("Controller detected that all Nodes are not-Ready. Entering master disruption mode.")for i := range nodes {if nc.runTaintManager {_, err := nc.markNodeAsReachable(nodes[i])if err != nil {klog.Errorf("Failed to remove taints from Node %v", nodes[i].Name)}} else {nc.cancelPodEviction(nodes[i])}}// We stop all evictions.for k := range nc.zoneStates {if nc.runTaintManager {nc.zoneNoExecuteTainter[k].SwapLimiter(0)} else {nc.zonePodEvictor[k].SwapLimiter(0)}}for k := range nc.zoneStates {nc.zoneStates[k] = stateFullDisruption}// All rate limiters are updated, so we can return early here.return}// We're exiting full disruption modeif allWasFullyDisrupted {klog.V(0).Info("Controller detected that some Nodes are Ready. Exiting master disruption mode.")// When exiting disruption mode update probe timestamps on all Nodes.now := nc.now()for i := range nodes {v := nc.nodeHealthMap.getDeepCopy(nodes[i].Name)v.probeTimestamp = nowv.readyTransitionTimestamp = nownc.nodeHealthMap.set(nodes[i].Name, v)}// We reset all rate limiters to settings appropriate for the given state.for k := range nc.zoneStates {// dfy: 设置 zone 的驱逐速率nc.setLimiterInZone(k, len(zoneToNodeConditions[k]), newZoneStates[k])nc.zoneStates[k] = newZoneStates[k]}return}// We know that there's at least one not-fully disrupted so,// we can use default behavior for rate limitersfor k, v := range nc.zoneStates {newState := newZoneStates[k]if v == newState {continue}klog.V(0).Infof("Controller detected that zone %v is now in state %v.", k, newState// dfy: 设置 zone 的驱逐速率nc.setLimiterInZone(k, len(zoneToNodeConditions[k]), newState)nc.zoneStates[k] = newState}} }// ComputeZoneState returns a slice of NodeReadyConditions for all Nodes in a given zone. // The zone is considered: // - fullyDisrupted if there're no Ready Nodes, // - partiallyDisrupted if at least than nc.unhealthyZoneThreshold percent of Nodes are not Ready, // - normal otherwise func (nc *Controller) ComputeZoneState(nodeReadyConditions []*v1.NodeCondition) (int, ZoneState) {readyNodes := 0notReadyNodes := 0for i := range nodeReadyConditions {if nodeReadyConditions[i] != nil && nodeReadyConditions[i].Status == v1.ConditionTrue {readyNodes++} else {notReadyNodes++}}switch {case readyNodes == 0 && notReadyNodes > 0:return notReadyNodes, stateFullDisruptioncase notReadyNodes > 2 && float32(notReadyNodes)/float32(notReadyNodes+readyNodes) >= nc.unhealthyZoneThreshold:return notReadyNodes, statePartialDisruptiondefault:return notReadyNodes, stateNormal} }// dfy: 根据该 zone 健康状态(也就是健康比例),设置驱逐效率(频率) func (nc *Controller) setLimiterInZone(zone string, zoneSize int, state ZoneState) {switch state {case stateNormal:if nc.runTaintManager {nc.zoneNoExecuteTainter[zone].SwapLimiter(nc.evictionLimiterQPS)} else {nc.zonePodEvictor[zone].SwapLimiter(nc.evictionLimiterQPS)}case statePartialDisruption:if nc.runTaintManager {nc.zoneNoExecuteTainter[zone].SwapLimiter(nc.enterPartialDisruptionFunc(zoneSize))} else {nc.zonePodEvictor[zone].SwapLimiter(nc.enterPartialDisruptionFunc(zoneSize))}case stateFullDisruption:if nc.runTaintManager {nc.zoneNoExecuteTainter[zone].SwapLimiter(nc.enterFullDisruptionFunc(zoneSize))} else {nc.zonePodEvictor[zone].SwapLimiter(nc.enterFullDisruptionFunc(zoneSize))}} }
-
-
进行 Pod 驱逐的处理 proceeNoTaintBaseEviction
TaintManger.Run
-
TainManager 的驱逐逻辑,看代码不难理解,大概说明
-
若开启 TaintManager 模式,所有 Pod、Node 的改变都会被放入,nc.tc.podUpdateQueue 和 nc.tc.nodeUpdateQueue 中
-
当 Node 失联时,会被打上 NoExecute Effect Taint(不在此处,在 main Controller.Run 函数中)
-
此处会先处理 nc.tc.nodeUpdateQueue 的驱逐
-
首先会检查 Node 是否有 NoExecute Effect Taint;没有就取消驱逐
-
有的话,进行 Pod 的逐个驱逐,检查 Pod 是否有该 Taint 的 toleration,有的话,就根据 toleration 设置 pod 的定时删除;没有 Toleration,就立即删除
-
-
接下来处理 nc.tc.podUpdateQueue 的驱逐
- 进行 Pod 的逐个驱逐,检查 Pod 是否有该 Taint 的 toleration,有的话,就根据 toleration 设置 pod 的定时删除;没有 Toleration,就立即删除
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OUQO1kpN-1692352728105)(img/nodelifecycle笔记/image-20230818160542117.png)]](https://img-blog.csdnimg.cn/c32a564a79f84311a06edc32b5b7e42a.png)
Node Pod 的处理
- 此处就是 nc.podUpdateQueue 和 nc.NodeUpdateQueue 的一些驱逐逻辑
- 比如给 Node 打上 NoSchedule Taint
- 检测到 Node 不健康,给 Pod 打上 Ready Condition = False 的 Status Condition
- 进行 Pod 驱逐的处理 proceeNoTaintBaseEviction
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ogwwC6Jx-1692352728105)(img/nodelifecycle笔记/image-20230818160649929.png)]](https://img-blog.csdnimg.cn/4451019d0ae04a8588c3223fb47fb1fc.png)
驱逐
- 此处 TaintManager 模式,只是打上 NoExecute Effect Taint —— doNoExecuteTaintingPass 函数
- 非 TaintManager 模式,会清理 zonePodEvicotr 记录的 Node 上的所有 Pod( Node 级别驱逐)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lHU7oJde-1692352728105)(img/nodelifecycle笔记/image-20230818160708127.png)]](https://img-blog.csdnimg.cn/a41689a722c7494a9d6806e05cfdcd5b.png)
相关文章:
【K8S源码之Pod漂移】整体概况分析 controller-manager 中的 nodelifecycle controller(Pod的驱逐)
参考 k8s 污点驱逐详解-源码分析 - 掘金 k8s驱逐篇(5)-kube-controller-manager驱逐 - 良凯尔 - 博客园 k8s驱逐篇(6)-kube-controller-manager驱逐-NodeLifecycleController源码分析 - 良凯尔 - 博客园 k8s驱逐篇(7)-kube-controller-manager驱逐-taintManager源码分析 - 良…...
[保研/考研机试] KY212 二叉树遍历 华中科技大学复试上机题 C++实现
题目链接: 二叉树遍历_牛客题霸_牛客网二叉树的前序、中序、后序遍历的定义: 前序遍历:对任一子树,先访问根,然后遍历其左子树,最。题目来自【牛客题霸】https://www.nowcoder.com/share/jump/43719512169…...
CSS笔记
介绍 CSS导入方式 三种方法都将文字设置成了红色 CSS选择器 元素选择器 id选择器 图中div将颜色控制为红色,#name将颜色控制为蓝色,谁控制的范围最小,谁就生效,所以第二个div是蓝色的。id属性值要唯一,否则报错。 clas…...

链栈Link-Stack
0、节点结构体定义 typedef struct SNode{int data;struct SNode *next; } SNode, *LinkStack; 1、初始化 bool InitStack(LinkStack &S) //S为栈顶指针(存数据的头节点) {S NULL;return true; } 2、入栈 bool Push(LinkStack &S, int e) {…...

Ubuntu 20系统WIFI设置静态IP地址,以及断连问题
最近工作需要购置了一台GPU机器,然后搭建了深度学习的运行环境,在工作中将这台机器当做深度学习的服务器来使用,前期已经配置好多用户以及基础环境。但最近通过xshell连接总是不间断的出现断连现象。 补充一点,Ubuntu系统中与网…...
(一)idea连接GitHub的全部流程(注册GitHub、idea集成GitHub、增加合作伙伴、跨团队合作、分支操作)
(二)Git在公司中团队内合作和跨团队合作和分支操作的全部流程(一篇就够)https://blog.csdn.net/m0_65992672/article/details/132336481 4.1、简介 Git是一个免费的、开源的*分布式**版本控制**系统*,可以快速高效地…...

-bash: java: command not found笔记
文章目录 场景解决方案找java的方法find命令进行查找根据java进程找寻具体位置 场景 linux系统执行java命令时报错: -bash: java: command not found。 解决方案 可能是没有安装java(这种情况比较少)或者安装了java但是没有设置环境变量(一般是这种情况)。 找ja…...

C++ typename and .template
https://makecleanandmake.com/2015/07/20/leading-typename-dot-template-and-why-they-are-necessary/ typename Obj<T>::type var;v.template m<int>();...
uniapp,使用canvas制作一个签名版
先看效果图 我把这个做成了页面,没有做成组件,因为之前我是配合uview-plus的popup弹出层使用的,这种组件好像是没有生命周期的,第一次打开弹出层可以正常写字,但是关闭之后再打开就不会显示绘制的线条了,还…...

【大数据】Flink 详解(五):核心篇 Ⅳ
Flink 详解(五):核心篇 Ⅳ 45、Flink 广播机制了解吗? 从图中可以理解 广播 就是一个公共的共享变量,广播变量存于 TaskManager 的内存中,所以广播变量不应该太大,将一个数据集广播后࿰…...

设计模式-建造者模式
核心思想 抽取共同的行为,允许使用者指定复杂对象的类型和内容,不需要了解内部的构建细节使用多个简单的行为构建一个复杂的对象,将对象的构建过程和它的表示分离,同样的构建过程可以创建不同的表示 优缺点 优点 使用者不需要知…...

flutter 设置app图标
使用插件 flutter_launcher_icons 在 pubspec.yaml 配置文件中 加入 dev_dependencies dev_dependencies: flutter_launcher_icons: "^0.13.1" 准备好app得 icon 图标 其中icon的名字为icon.png 创建assets文件夹 和子文件夹icon iamge 配置静态资源路径 完整配置…...

守护网络安全:深入了解DDOS攻击防护手段
ddos攻击防护手段有哪些?在数字化快速发展的时代,网络安全问题日益凸显,其中分布式拒绝服务(DDOS)攻击尤为引人关注。这种攻击通过向目标网站或服务器发送大量合法或非法的请求,旨在使目标资源无法正常处理其他用户的请求,从而达…...
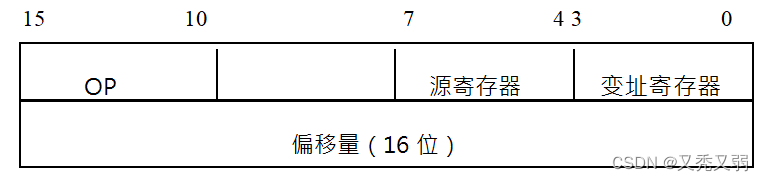
计组 | 寻址方式
目录 一、知识点 1.寻址方式什么? 2.根据操作数所在的位置,都有哪些寻址方式? 3.直接寻址 4.立即寻址 5.隐含寻址 6.相对寻址 7.寄存器 8.寄存器-寄存器型(RR)、寄存器-存储器型(RS)和…...

matlab工具箱Filter Designer设计butterworth带通滤波器
1、在matlab控制界面输入fdatool; 2、在显示的界面中选择合适的参数;本实验中采样频率是200,低通30hz,高通60hz,点击butterworth滤波器。 3、点击设计滤波器按钮后,在生成的界面点击红框按钮,可生成simulink模型到当前…...
)
Python学习笔记第六十天(Matplotlib Pyplot)
Python学习笔记第六十天 Matplotlib Pyplot后记 Matplotlib Pyplot Pyplot 是 Matplotlib 的子库,提供了和 MATLAB 类似的绘图 API。 Pyplot 是常用的绘图模块,能很方便让用户绘制 2D 图表。 Pyplot 包含一系列绘图函数的相关函数,每个函数…...

服务器自动备份、打包、传输脚本
备份脚本 #!/bin/bash #author cheng #备份服务器自动打包归档每天的备份文件 Path/backhistory Host$(hostname) Date$(date %F) Dest${Host}_${Date}#创建目录 mkdir -p ${Path}/${Dest}#打包文件到目录 cd / && \#结合autoback.sh脚本,它往那个地方备&a…...

Docker 的数据管理 网络通信
目录 1.管理容器数据的方式 数据卷 数据卷的容器 2.操作命令 3.Docker 镜像的创建 1.管理容器数据的方式 数据卷 可以独立于容器生命周期存储的机制 可提供持久化 数据共享 docker run -v /var/www:/data1 --name web1 -it centos:7 /bin/bash 数据卷的容器 用来提供持久化数…...

目标检测YOLO实战应用案例100讲-基于孤立森林算法的高光谱遥感图像异常目标检测
目录 前言 孤立森林算法的基本理论 2.1 引言 2.2 孤立森林算法的基本思想...
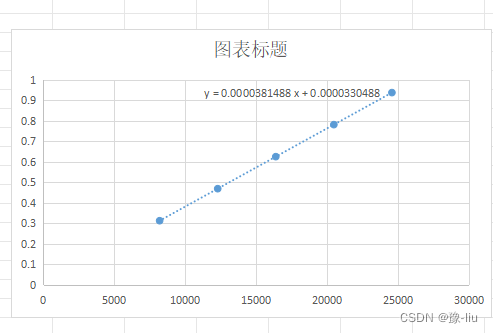
excel中两列数据生成折线图
WPS中excel的两列数据,第一列为x轴,第二列为y轴,生成折线图,并生成拟合函数。 1.选中两列数据,右击选择插入图表,选择XY(散点图),生成散点折线图 2.选中图中散点&#x…...

2026论文降AI实战SOP:保留排版格式,8款工具与结构级优化指南
内容ai率检测数值太高,不得不熬夜改了一遍又一遍,润色到想吐,结果检测报告上数字还是不尽人意,截止日期越逼越近,真的是没办法了。 我花了整整三天,把2026全网热门的几十款降AI工具通通测了个遍࿰…...
)
MATLAB roots函数实战:5分钟搞定高阶系统稳定性判断(附完整代码)
MATLAB roots函数实战:高阶系统稳定性分析的黄金法则 在控制工程和自动化领域,系统稳定性分析是每个工程师的必修课。面对复杂的高阶系统特征方程,传统的手工计算方法不仅耗时耗力,还容易出错。而MATLAB的roots函数配合简单的可视…...
)
毕设成品 深度学习安全帽佩戴检测(源码+论文)
文章目录 0 前言🔥这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力…...

终极ComfyUI视频插件指南:从零开始构建AI视频生成工作流
终极ComfyUI视频插件指南:从零开始构建AI视频生成工作流 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 你是否曾梦想过让静态图片“活”起来,或者让文字描述直接变成生动…...
)
STM32实战:手把手教你用Cubemx配置交流充电桩的CP信号检测(附代码)
STM32实战:从零构建充电桩CP信号检测系统 充电桩作为新能源汽车基础设施的核心组件,其通信协议的可靠性直接关系到充电安全。在实际工程中,CP(Control Pilot)信号的检测往往是开发者的第一个技术拦路虎。我曾在一个海外…...
)
【OpenClaw从入门到精通】第78篇:OpenClaw安全防护实测——360龙虾保 vs 奇安信安全伴侣全维度对比(2026万字实战版)
摘要:2026年OpenClaw爆发式普及,全球公网暴露实例超58万个,7个高危CVE漏洞接踵而至,企业私自部署的“裸奔”智能体成为内网安全重灾区。在此背景下,360与奇安信两大安全巨头同步推出专属防护方案——360龙虾保与奇安信安全伴侣。本文从技术架构、核心能力、部署实操、场景…...

三步实现iOS虚拟定位:无需越狱的终极免费方案
三步实现iOS虚拟定位:无需越狱的终极免费方案 【免费下载链接】iFakeLocation Simulate locations on iOS devices on Windows, Mac and Ubuntu. 项目地址: https://gitcode.com/gh_mirrors/if/iFakeLocation iFakeLocation是一个专业级的iOS虚拟定位工具&am…...

如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 [特殊字符]
如何通过 Pretty TypeScript Errors 提升开发效率:下载量激增背后的成功秘诀 🔥 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mi…...

解决ClaudeCode频繁封号与Token不足的Taotoken替代方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决ClaudeCode频繁封号与Token不足的Taotoken替代方案 对于依赖Claude Code这类编程助手工具的开发者而言,访问不稳定…...
)
别再为Matlab App打包发愁了!手把手教你从Web部署到桌面应用(含Runtime安装避坑)
从零到一:Matlab App Designer全流程打包实战指南 第一次尝试将Matlab App Designer开发的应用程序打包成可执行文件时,那种既期待又忐忑的心情相信很多开发者都深有体会。作为一款强大的交互式开发环境,Matlab App Designer让图形用户界面(G…...