[NLP]LLM--transformer模型的参数量
1. 前言
最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量为1750亿,训练数据量达到了570GB。进而,训练大规模语言模型面临两个主要挑战:显存效率和计算效率。
现在业界的大语言模型都是基于transformer模型的,模型结构主要有两大类:encoder-decoder(代表模型是T5)和decoder-only,具体的,decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和Prefix LM(代表模型是GLM)。归因于GPT系列取得的巨大成功,大多数的主流大语言模型都采用Causal LM结构。因此,针对decoder-only框架,为了更好地理解训练训练大语言模型的显存效率和计算效率.
完整的Transformer模型包括encoder和decoder,而GPT只使用了decoder部分,且因为少了encoder,所以和原始的Transformer decoder相比,不再需要encoder-decoder attention层,对比图如下:

本文分析采用decoder-only框架transformer模型的模型参数量、计算量、中间激活值、KV cache。
`

为了方便分析,先定义好一些数学符号。记transformer模型的层数为 L ,隐藏层维度为 h ,注意力头数为 a。词表大小为 V,训练数据的批次大小为 b ,序列长度为 s。
2. 模型参数量
可以参考:[NLP] BERT模型参数量_奇思闻影的舒克与贝克的博客-CSDN博客
基本方法一样
transformer模型由 L个相同的层组成,每个层分为两部分:self-attention块和MLP块。
Self-attention模块参数包含Q, K V 的权重矩阵Wq, Wk, Wv 输出及偏置Bias,4个权重矩阵形状为[h, h],4个偏置形状为[h], Self-attention参数量为4 + 4h
MLP块由2个线性层组成,一般地,第一个线性层是先将维度从 h 映射到 4h ,第二个线性层再将维度从4h映射到h。第一个线性层的权重矩阵 W1 的形状为 [h,4h] ,偏置的形状为 [4h] 。第二个线性层权重矩阵 W2 的形状为 [4h,h] ,偏置形状为 [h] 。MLP块的参数量为 8 + 5h
self-attention块和MLP块各有一个layer normalization,包含了2个可训练模型参数:缩放参数 gaama和平移参数 beta ,形状都是 [h] 。2个layer normalization的参数量为 4h 。
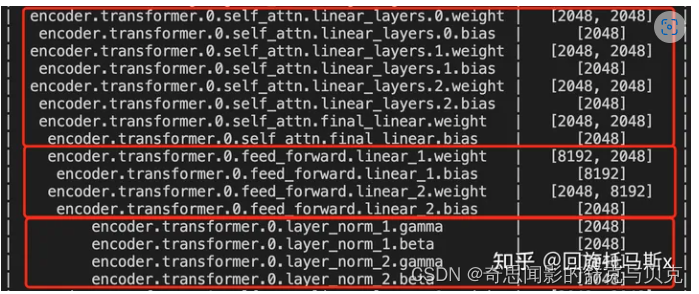
总的,每个transformer层的参数量为12 + 13h
除此之外,词嵌入矩阵的参数量也较多,词向量维度通常等于隐藏层维度 h ,词嵌入矩阵的参数量为 Vh 。最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的。
关于位置编码,如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如RoPE和ALiBi,则不包含可训练的模型参数。我们忽略这部分参数。
综上, L层transformer模型的可训练模型参数量为 L(12 + 13h)+Vh 。当隐藏维度 h 较大时,可以忽略一次项,模型参数量近似为 12L
接下来,我们估计不同版本LLaMA模型的参数量。
| 实际参数量 | 隐藏维度h | 层数l | 12L |
|---|---|---|---|
| 6.7B | 4096 | 32 | 6,442,450,944 |
| 13.0B | 5120 | 40 | 12,582,912,000 |
| 32.5B | 6656 | 60 | 31,897,681,920 |
| 65.2B | 8192 | 80 | 64,424,509,440 |
特此声明,此文主体参考知乎文章https://zhuanlan.zhihu.com/p/624740065(在此感该作者“回旋托马斯x”的辛苦付出)
参考
[1] https://arxiv.org/pdf/1706.03762.pdf
[2] https://arxiv.org/pdf/2302.13971.pdf
[3] https://arxiv.org/pdf/2104.04473.pdf
[4] https://zhuanlan.zhihu.com/p/624740065
相关文章:
[NLP]LLM--transformer模型的参数量
1. 前言 最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量…...

5 Python的面向对象编程
概述 在上一节,我们介绍了Python的函数,包括:函数的定义、函数的调用、参数的传递、lambda函数等内容。在本节中,我们将介绍Python的面向对象编程。面向对象编程(Object-Oriented Programming, 即OOP)是一种…...

卷积神经网络——上篇【深度学习】【PyTorch】【d2l】
文章目录 5、卷积神经网络5.1、卷积5.1.1、理论部分5.1.2、代码实现5.1.3、边缘检测 5.2、填充和步幅5.2.1、理论部分5.2.2、代码实现 5.3、多输入多输出通道5.3.1、理论部分5.3.2、代码实现 5.4、池化层 | 汇聚层5.4.1、理论部分5.4.2、代码实现 5、卷积神经网络 5.1、卷积 …...

【从零学习python 】54. 内存中写入数据
文章目录 内存中写入数据StringIOBytesIO进阶案例 内存中写入数据 除了将数据写入到一个文件以外,我们还可以使用代码,将数据暂时写入到内存里,可以理解为数据缓冲区。Python中提供了StringIO和BytesIO这两个类将字符串数据和二进制数据写入…...
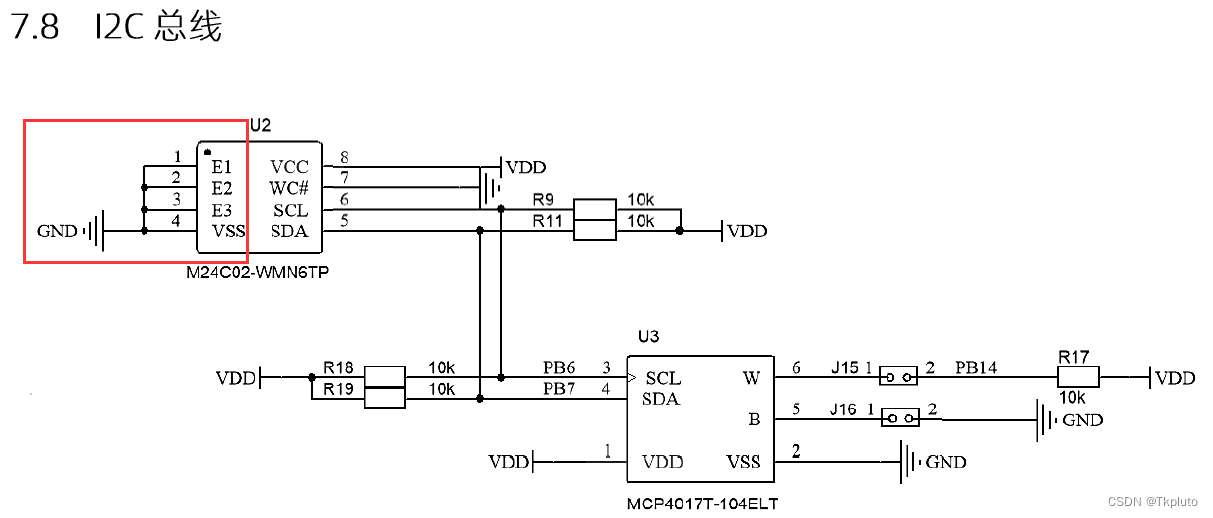
速通蓝桥杯嵌入式省一教程:(九)AT24C02芯片(E2PROM存储器)读写操作与I2C协议
AT24C02芯片(又叫E2PROM存储器、EEPROM存储器),是一种通过I2C(IIC)协议通信的掉电保存存储器芯片,其内部含有256个8位字节。在介绍这款芯片之前,我们先来粗略了解一下I2C协议。 I2C总线是一种双向二线制的同步串行总线…...

负载均衡:优化性能与可靠性的关键
在现代互联网时代,数以万计的用户访问着各种在线服务,从即时通讯、社交媒体到电子商务和媒体流媒体,无不需要应对海量的请求和数据传输。在这个高并发的环境下,负载均衡成为了关键的技术,它旨在分散工作负载࿰…...

T113-S3-TCA6424-gpio扩展芯片调试
目录 前言 一、TCA6424介绍 二、原理图连接 三、设备树配置 四、内核配置 五、gpio操作 总结 前言 TCA6424是一款常用的GPIO(通用输入输出)扩展芯片,可以扩展微控制器的IO口数量。在T113-S3平台上,使用TCA6424作为GPIO扩展芯…...

奥威BI数据可视化工具:个性化定制,打造独特大屏
每个人都有自己独特的审美,因此即使是做可视化大屏,也有很多人希望做出不一样的报表,用以缓解审美疲劳的同时提高报表浏览效率。因此这也催生出了数据可视化工具的个性化可视化大屏制作需求。 奥威BI数据可视化工具:个性化定制&a…...

13 秒插入 30 万条数据,批量插入!
数据库表 CREATE TABLE t_user (id int(11) NOT NULL AUTO_INCREMENT COMMENT 用户id,username varchar(64) DEFAULT NULL COMMENT 用户名称,age int(4) DEFAULT NULL COMMENT 年龄,PRIMARY KEY (id) ) ENGINEInnoDB DEFAULT CHARSETutf8 COMMENT用户信息表; User实体 /*** …...
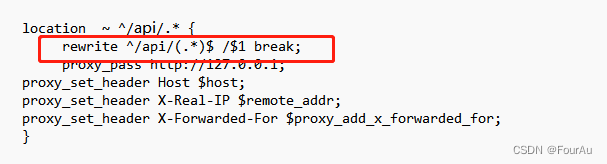
Nginx代理转发地址不正确问题
使用ngix前缀去代理转发一个地址,貌似成功了,但是进不到正确的页面,能够访问,但是一直404远处出来nginx会自动拼接地址在后面 后面才知道要将这段代码加上去,去除前缀转发...

HyperMotion高度自动化云迁移至华为HCS8.1解决方案
项目背景 2020 年以来,金融证券已经成为信创落地最快的领域。2021 年证监会发布的《证券期货业科技发展十四五规划》中,将“加强信创规划与实施”作为证券行业重点建设任务之一。为了符合国家信创标准,某证券企业计划将网管系统、呼叫中心管…...

pbootcms系统安全防护设置大全
PbootCMS系统简介 PbootCMS是全新内核且永久开源免费的PHP企业网站开发建设管理系统,是一套高效、简洁、 强悍的可免费商用的PHP CMS源码,能够满足各类企业网站开发建设的需要。系统采用简单到想哭的模板标签,只要懂HTML就可快速开发企业网站…...

【环境】docker时间与宿主同步
1.容器创建后 docker cp /etc/localtime 容器名:/etc/2.容器创建时 加入 -v /ect/localtime/:/etc/localtime:ro参考链接...
亮点!视频云存储/安防监控视频智能分析平台睡岗离岗检测
在生产过程中,未经领导允许的擅自离岗、睡岗会带来很多的潜在危害。TSINGSEE青犀推出的视频云存储/安防监控视频智能分析平台得睡岗离岗检测根据AI视频分析技术建立人工智能算法,对视频画面展开分析与识别。自动识别出人员睡岗、离岗、玩手机与抽烟等动作…...

编程锦囊妙计——快速创建本地Mock服务
点击上方👆蓝色“Agilean”,发现更多精彩。 前情提要 在本系列上一篇文章《全文干货:打破前后端数据传递鸿沟,高效联调秘笈》中我们分享了使用Zod这一运行时类型校验库来对后端服务响应结果进行验证达到增加项目质量的方式。 这次…...

简单认识镜像底层原理详解和基于Docker file创建镜像
文章目录 一、镜像底层原理1.联合文件系统(UnionFS)2.镜像加载原理3.为什么Docker里的centos的大小才200M? 二、Dockerfile1.简介2.Dockerfile操作常用命令 三、创建Docker镜像1.基于已有镜像创建2.基于本地模板创建3.基于Dockerfile创建4.Dockerfile多阶段构建镜像 一、镜像底…...

加速乐(__jsl_clearance_s)动态cookie生成分析实战
文章目录 一、写在前面二、抓包分析三、逆向分析 一、写在前面 加速乐(JSL)是阿里推出的一项反爬虫服务,其生成cookie的原理基于浏览器的行为特征 我们知道普通网站生成cookie是在请求时生成,而它先生成cookie,然后向服…...

启动Vue项目踩坑记录
前言 在启动自己的Vue项目时,遇到一些报错,当时很懵,解决了以后豁然开朗,特写此博客记录一下。 一、<template>里多加了个div标签 [vite] Internal server error: At least one <template> or <script> is req…...

vue-pc上传优化-uni-app上传优化
vue-pc上传优化 当我们使用自己搭建的文档服务器上传图片时候,在本地没问题,上线上传会比较慢 这时候我们最简单的方法就是写一个加载组件,上传之前打开组件,掉完接口关闭组件 或者不想写直接使用element的loading写一个遮罩层加…...

【计算机视觉|生成对抗】StackGAN:使用堆叠生成对抗网络进行文本到照片逼真图像合成
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题:StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 链接:[1612.03242] StackGAN: Text to Photo-realistic Image Synthesis…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界
3步零基础掌握星露谷物语SMAPI模组加载器:高效管理你的模组世界 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI SMAPI(Stardew Valley Modding API)是星露谷物语官…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...

PrediPrune:机器学习驱动的编译器超级优化候选剪枝策略
1. 项目概述与核心挑战在编译器优化的世界里,我们总在追求极致的性能。传统的编译器优化器,比如LLVM的Pass,依赖于一系列预定义的、经过验证的转换规则。它们很高效,但想象力也受限于这些规则。超级优化器(Superoptimi…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...