【elasticsearch】elasticsearch es读写原理
一、前言:
今天来学习下 es 的写入原理。
Elasticsearch底层使用Lucene来实现doc的读写操作:
Luence 存在的问题:
-
没有并发设计
lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量数据,并利用分布式的能力,就必须在其之上进行分布式的相关设计。 -
非实时
将文件写入lucence后并不能立即被检索,需要等待lucene生成一个完整的segment才能被检索 -
数据存储不可靠
写入lucene的数据不会立即被持久化到磁盘,如果服务器宕机,那存储在内存中的数据将会丢失 -
不支持部分更新
lucene中提供仅支持对文档的全量更新,对部分更新不支持。例如:对文档进行部分更新,只新增一个字段或者修改某一字段的值,Lucene是不支持的。
二、Elasticsearch的写入方案
针对Lucene的问题,ES做了如下设计
2.1 shard:
为了支持对海量数据的存储和查询,需要用到分布式系统,通过大规模集群来提高系统水平扩展能力,因此Elasticsearch引入分片的概念,一个索引被分成多个分片(shard)。
除了将index 分片以提高水平扩展能力,Elasticsearch还会将shard复制成多个副本,放置到不同的机器上,提高系统可用性,并且副分片还提供读服务,分担集群压力。
每个shard都是一个lucene段,是可以独立执行搜索任务最小单位。
但是多副本也会带来一致性问题。部分副本写成功,部分副本写失败。
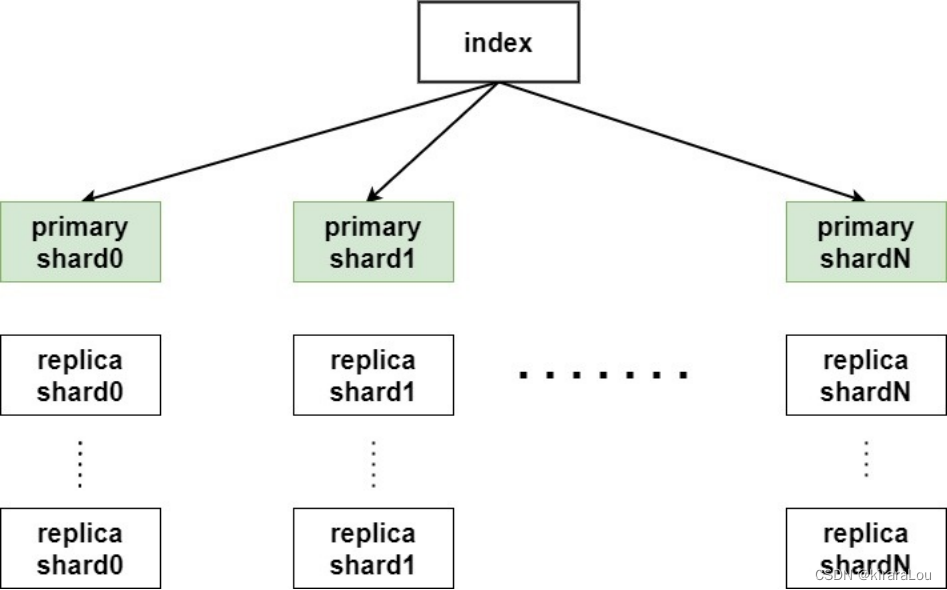
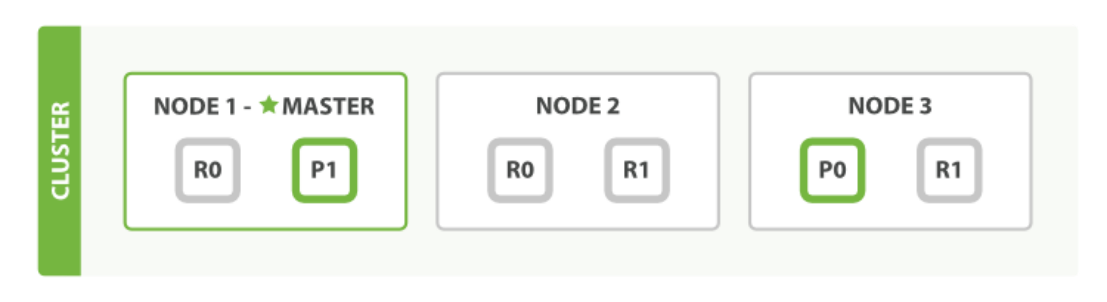
例如:下面的集群由三个节点组成。 存在一个索引,有两个主分片,每个主分片有两个副本分片。相同分片的副本不会放在同一节点。
Elasticsearch采用多Shard方式,通过路由规则将数据分成多个数据子集,每个数据子集提供独立的索引和搜索功能。当写入文档的时候,根据routing规则,将文档发送给特定Shard中建立索引。这样就能实现分布式了。
如何确定一条数据属于哪个shard?
ES会根据公式:
shard_num = hash(_routing) % num_primary_shards
_routing的默认值是文档的_id
通过计算得出文档要分配到的分片,在从集群元数据中找出对应主分片的位置,将请求路由到该分片进行文档写操作。
2.2 近实时性-refresh操作
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 当然还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
2.3 部分更新
lucene支持对文档的整体更新,ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。另外为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
三、写入操作:
分别从集群角度和 shard 自身角度来介绍数据如何写入。
3.1 集群角度: Primary -> Replica
我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。
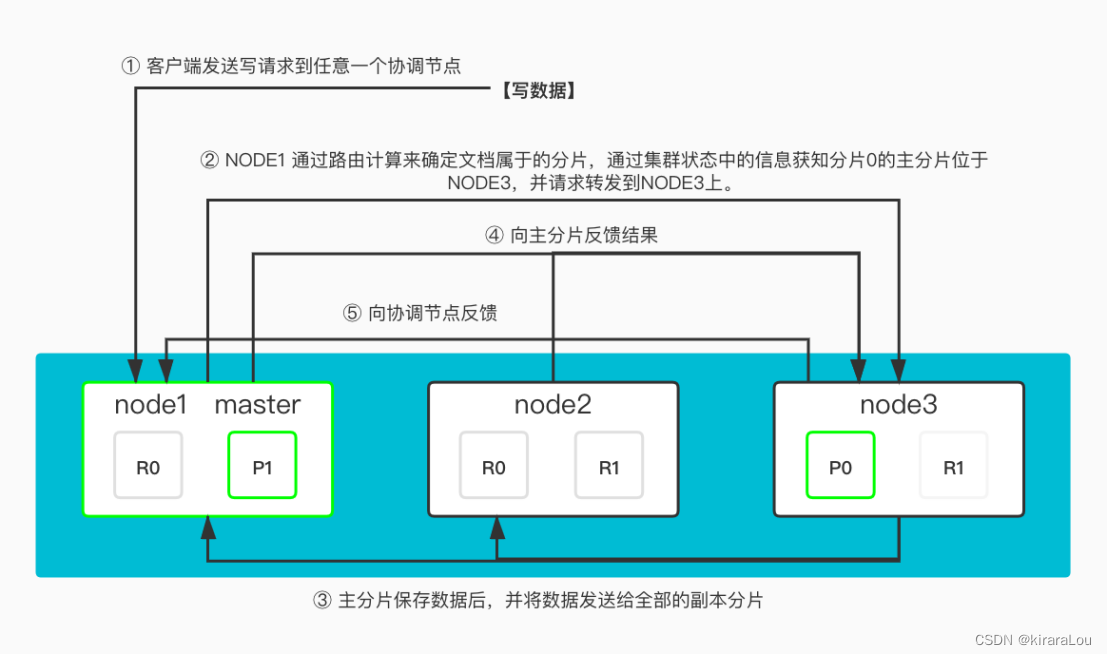
- 客户端向
NODE1发送写请求。 - 检查
Active的Shard数。 NODE1使用文档ID来确定文档属于的分片(图例是:分片0),通过集群状态中的信息获知分片0的主分片位于NODE3,因此请求被转发到NODE3上。NODE3上的主分片执行写操作。- 并发的向所有同步副本发起写入请求,将请求并行转发到
NODE1和NODE2的副分片上。 - 等待所有同步副本返回结果,返回成功或者失败后,返回给
Client。
(1)为什么要检查Active的Shard数?
ES中有一个参数,叫做wait_for_active_shards。这个参数的含义是,在每次写入前,该shard至少具有的active副本数。假设我们有一个Index,其每个Shard有3个Replica,加上Primary则总共有4个副本。如果配置wait_for_active_shards为3,那么允许最多有一个Replica挂掉,如果有两个Replica挂掉,则Active的副本数不足3,此时不允许写入。
这个参数默认是1,即只要Primary在就可以写入。如果配置大于1,可以起到一种保护的作用,保证写入的数据具有更高的可靠性。但是这个参数只在写入前检查,并不保证数据一定在至少这些个副本上写入成功,所以并不是严格保证了最少写入了多少个副本。
(2)写入Primary完成后,为何要等待所有同步Replica响应(或连接失败)后返回?
早期ES版本,Primary和Replica之间是允许异步复制的,即写入Primary成功即可返回。但是这种模式下,如果Primary挂掉,就有丢数据的风险,而且从Replica读数据也很难保证能读到最新的数据。所以后来ES就取消异步模式了,改成Primary等同步Replica返回后再返回给客户端。
https://github.com/elastic/elasticsearch/blob/master/docs/reference/docs/data-replication.asciidoc
Once all in-sync replicas have successfully performed the operation and responded to the primary, the primary acknowledges the successful completion of the request to the client.
{"_shards" : {"total" : 2,"failed" : 0,"successful" : 2}
}
(3) 如果某个Replica持续写失败,用户是否会经常查到旧数据?
假如一个Replica持续写入失败,那么这个Replica上的数据可能落后Primary很多。Primary会将这个信息报告给Master,然后Master会在Meta中更新这个Index的InSyncAllocations配置,将这个Replica从中移除,移除后它就不再承担读请求。在Meta更新到各个Node之前,用户可能还会读到这个Replica的数据,但是更新了Meta之后就不会了。所以这个方案并不是非常的严格,考虑到ES本身就是一个近实时系统,数据写入后需要refresh才可见,所以一般情况下,在短期内读到旧数据应该也是可接受的。
3.2 shard自身角度:
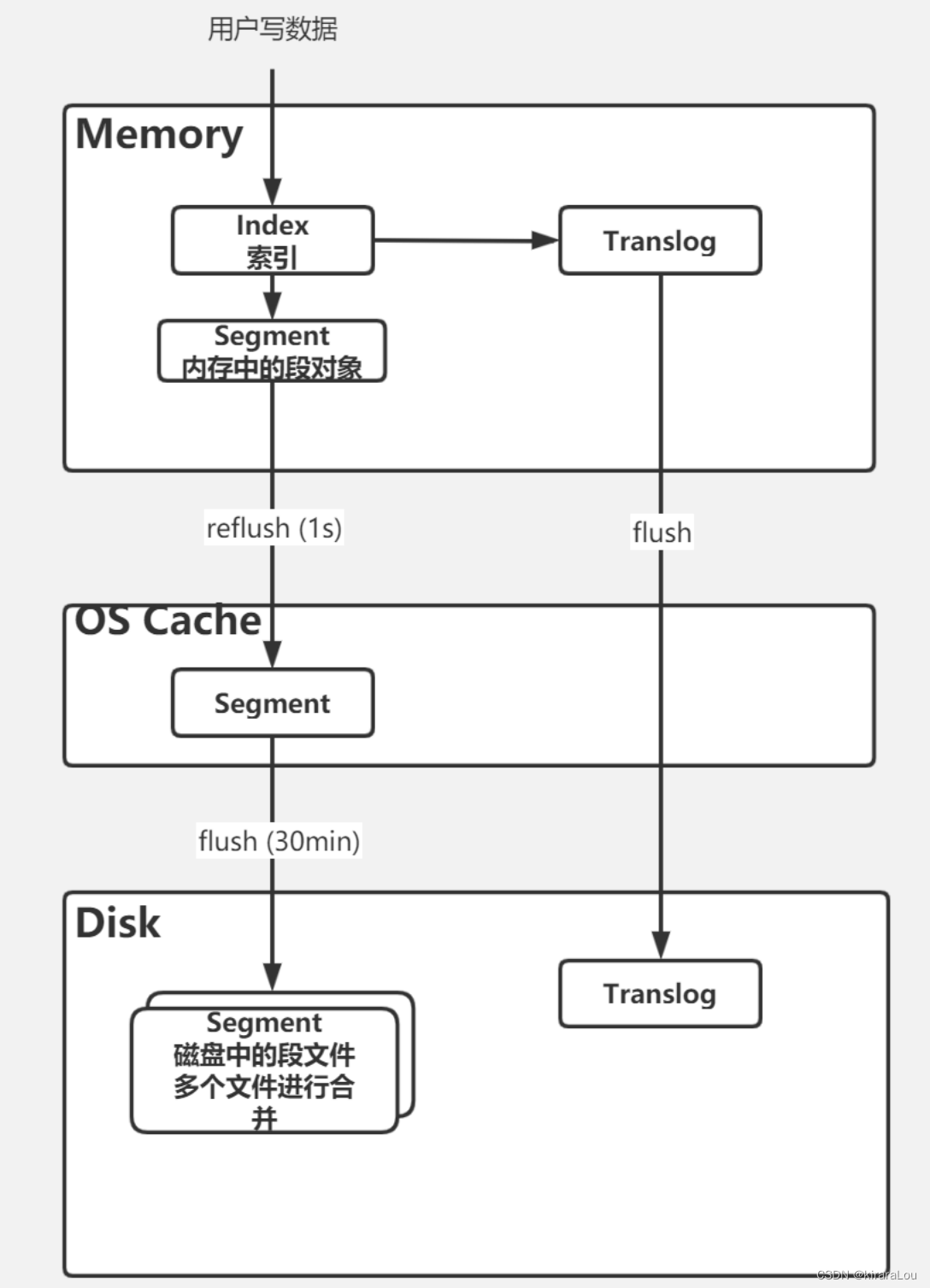
在每一个Shard中,写入流程分为两部分, 先写入Lucene,再写入TransLog。
- 写入请求到达
Shard后,先写Lucene文件。 - 此时索引还在内存里面,接着去写
TransLog。 - 写完
TransLog后,刷新TransLog数据到磁盘上,并且保留一定的translog中的数据。例如:在进行数据恢复,可以通过translog来进行数据回放,而不是基于数据副本的恢复。提高磁盘的利用率。 - 写磁盘成功后,请求返回给用户。
(1)为什么引入translog?
当一个文档写入Lucence后是存储在内存中的,即使执行了refresh操作仍然是在文件系统缓存中,如果此时服务器宕机,那么这部分数据将会丢失。为此ES增加了translog, 当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的,这样就可以防止服务器宕机后数据的丢失。由于translog是追加写入,因此性能比较好。
而且key value的形式写Translog, Key是Id, Value是Doc的内容。当查询的时候,如果请求的是GetDocById则可以直接根据_id从translog中获取。满足nosql场景的实时性。
(2)为什么es要先写入lucene,后写入translog?
Lucene的内存写入会有很复杂的逻辑,很容易失败,比如分词,字段长度超过限制等,比较重,为了避免TransLog中有大量无效记录,为了减少写入失败回滚的复杂度和提高速度,所以就把写Lucene放在了最前面。
当一个文档写入Lucene后是不能被立即查询到的,Elasticsearch提供了一个refresh操作,会定时地为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s。
flush操作
另外每30分钟或当translog达到一定大小(由index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘。此时lucene中的数据就完成了持久化。
merge操作
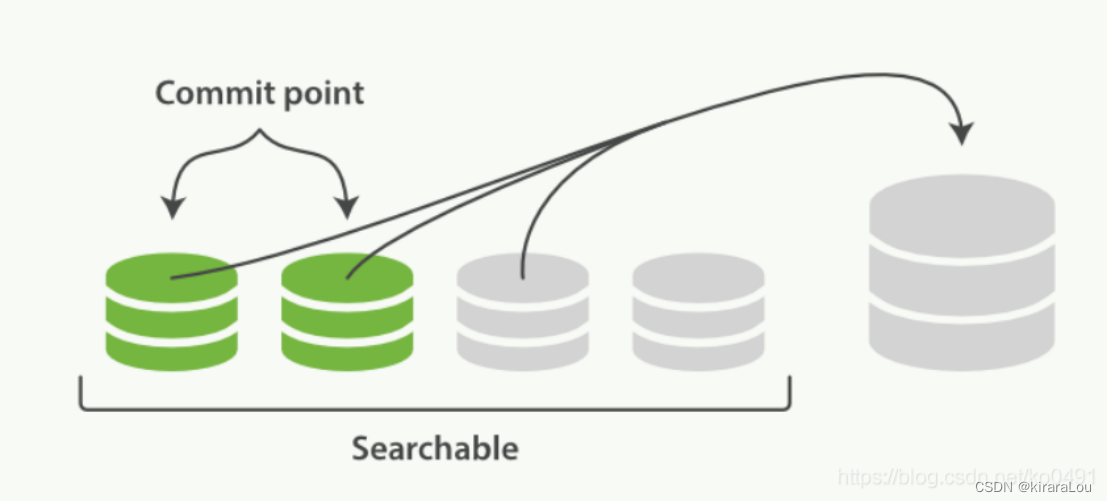
由于refresh默认间隔为1s中,因此会产生大量的小segment,为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。
不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
- 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
- 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
- 新的段被打开用来搜索
- 老的段会被删除
四、更新操作:
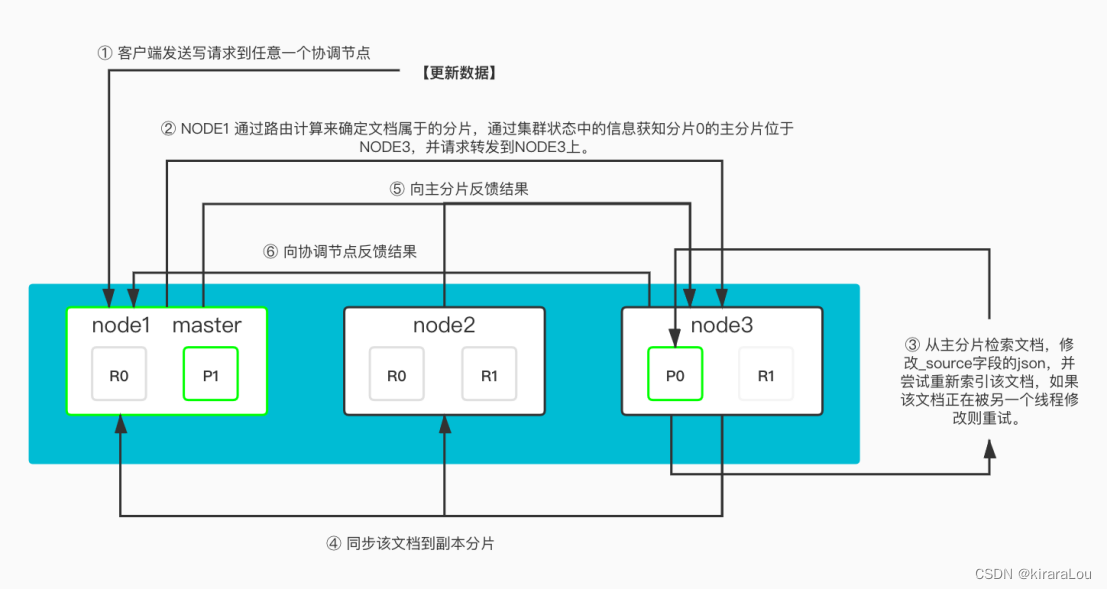
更新流程:
- 客户端A、B发起Updata操作,并几乎同时获取同一个文档, 一并获得
_version版本信息, 假设此时_version=1。 - 客户端A将版本V1的全量Doc和请求中的部分字段
Doc合并为一个完整的Doc。Update请求就变成了Index请求。 Elasticsearch在写入索引时, 检查客户端A提交的文档的版本信息(这里仍然是1) 和 现存的文档的版本信息(这里也是1), 发现相同后, 执行写入操作, 并修改版本号_version=2。- 客户端B也修改文档中的部分内容, 其操作写回索引的速度稍慢. 此时同样执行过程(4): ES发现客户端B提交的文档的版本为1, 而现存文档的版本为2 ===> 发生冲突, 此次
update将失败。 - update操作失败后, 将重复(1) - (3) 过程, 并重复几次。参数有配置控制。
五、扩展
为了对比学习,也对比了一下 ES 和我之前学习过的组件一些大方向上的原理做了个比对。
1. HBase VS ES
相同点:
- 每隔一段比较长的时间/ 日志文件达到一定的大小/ 手动flush,会把内存中数据刷新到磁盘上。
- 删除数据并不会真正的删除,当发生合并时才会真正的删除数据。
- hbase 和 es 都会保留一定的translog。
不同点:
- HBase是先写入日志,然后再写内存,而Elasticsearch是先写内存,最后才写TransLog。
- hbase只有发生major compact才会真正的删除数据。
2. Kafka vs ES
相似点:
- ES 是一个索引通过shard来进行水平拆分,Kafka是通过partition来进行水平拆分。
- ES和Kafka的可靠性都是通过副本来保障。
- 都会维护一个ISR信息。
不同点:
- ES 支持读分离 可以在副本分片上读取数据,而Kafka不支持读写分离,读写都必须leader 分区上。
为什么Kafka不支持读写分离,而ES支持读分离?
- 数据一致性问题。数据从主节点转到从节点必然会有一个延时的时间窗口,这个时间窗口会导致主从节点之间的数据不一致。
- 延时问题。数据从写入主节点到同步至从节点中的过程需要经历网络→主节点内存→主节点磁盘→网络→从节点内存→从节点磁盘这几个阶段。对延时敏感的应用而言,主写从读的功能并不太适用。
六、读原理
Elasticsearch中每个Shard都会有多个Replica,主要是为了保证数据可靠性,除此之外,还可以增加读能力,因为写的时候虽然要写大部分Replica Shard,但是查询的时候只需要查询Primary和Replica中的任何一个就可以了。
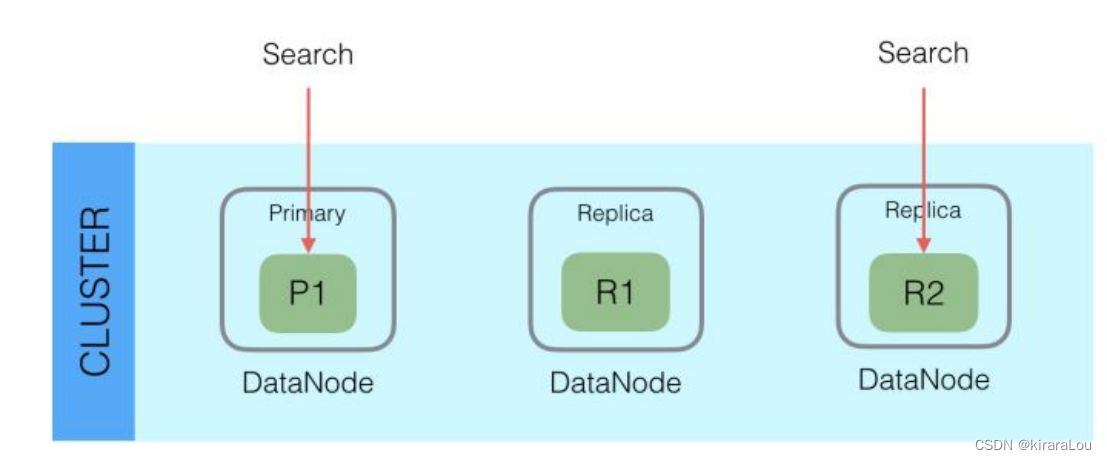
所有的搜索系统一般都是两阶段查询,第一阶段查询到匹配的DocID,第二阶段再查询DocID对应的完整文档,这种在Elasticsearch中称为query_then_fetch。
Query流程:
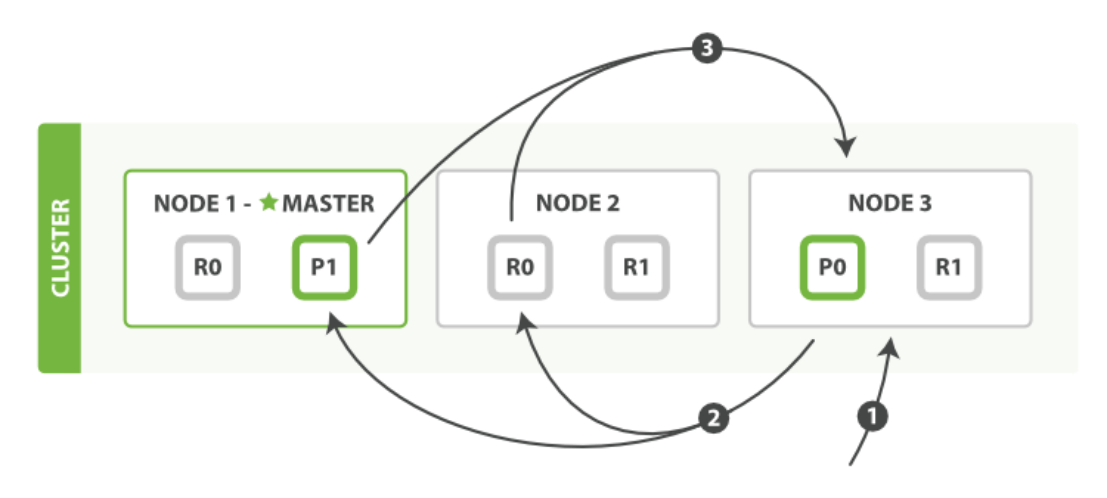
- 客户端发送一个 search 请求到
Node 3。 Node 3将查询请求转发到索引的每个主分片或副本分片中。- 每个分片返回各自优先队列中所有文档的
ID和排序值给协调节点,也就是Node 3 - 协调节点合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
Fetch阶段:
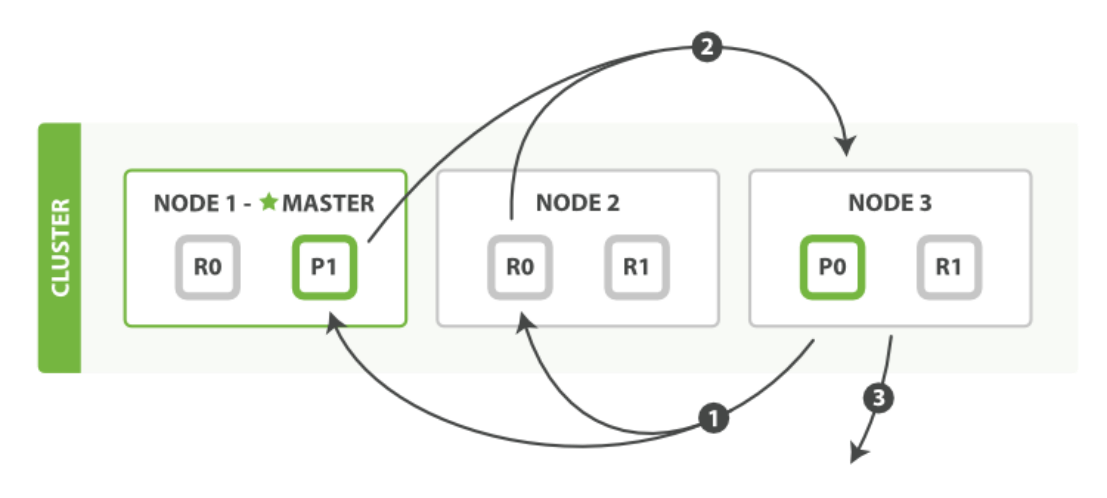
查询阶段标识哪些文档满足搜索请求,然后需要取回这些文档。
- 协调节点首先决定哪些文档“确实”需要被取回,例如:如果查询指定了
{"from":90, "size": 10},则只有从第91个开始的10个结果需要被取回。 - 协调节点向相关node发送GET请求。
- 分片所在的节点向协调节点返回结果。
- 协调节点等待所有文档被取得,然后返回给客户端。
相关文章:
【elasticsearch】elasticsearch es读写原理
一、前言: 今天来学习下 es 的写入原理。 Elasticsearch底层使用Lucene来实现doc的读写操作: Luence 存在的问题: 没有并发设计 lucene只是一个搜索引擎库,并没有涉及到分布式相关的设计,因此要想使用Lucene来处理海量…...

数据在内存中的存储【上篇】
文章目录⚙️1.数据类型的详细介绍🔩1.1.类型的基本归类⚙️2.整型在内存中的存储🔩2.1.原码、反码、补码🔩2.2.大小端的介绍⚙️1.数据类型的详细介绍 🥳基本的内置类型 : 💡char ---------- 字符数据类型…...
慕了没?3年经验,3轮技术面+1轮HR面,拿下字节30k*16薪offer
前段时间有个朋友出去面试,这次他面试目标比较清晰,面的都是业务量大、业务比较核心的部门。前前后后去了不少公司,几家大厂里,他说给他印象最深的是字节3轮技术面1轮HR面,他最终拿到了30k*16薪的offer。第一轮主要考察…...

「可信计算」与软件行为学
可信计算组织(Ttrusted Computing Group,TCG)是一个非盈利的工业标准组织,它的宗旨是加强在相异计算机平台上的计算环境的安全性。TCG于2003年春成立,并采纳了由可信计算平台联盟(the Trusted Computing Platform Alli…...
| 代码+思路+重要知识点)
华为OD机试题 - 找字符(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...

Linux 进程启动方法
现实中程序编写的时候,经常会碰到一些这样需求:调用系统命令,完成一些操作,或判定结果 或获取结果作为启动进程,调用第三方进程,并监控进程是否退出加载升级进程,升级进程kill调用者或调用者自行…...

CLEVE:事件抽取的对比预训练
CLEVE: Contrastive Pre-training for Event Extraction 论文:CLEVE: Contrastive Pre-training for Event Extraction (arxiv.org) 代码:THU-KEG/CLEVE: Source code for ACL 2021 paper “CLEVE: Contrastive Pre-training for Event Extraction” (g…...
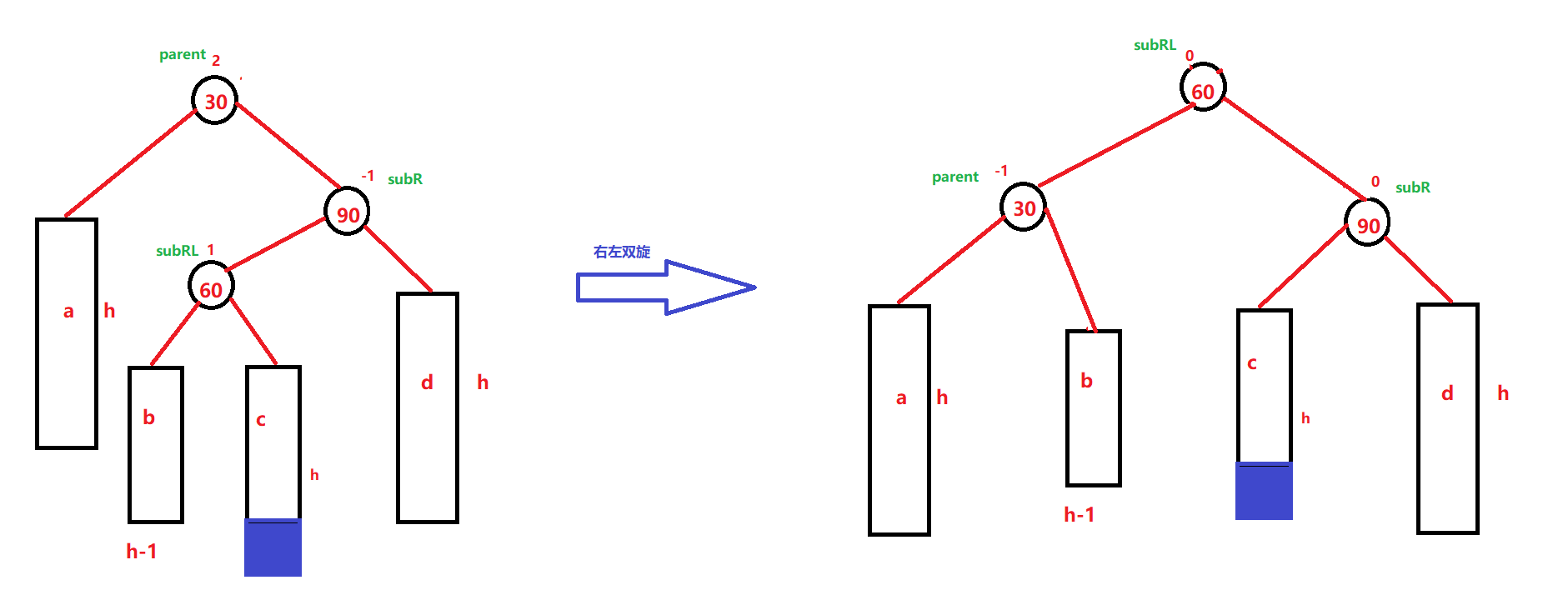
【C++】AVLTree——高度平衡二叉搜索树
文章目录一、AVL树的概念二、AVL树节点的定义三、AVL树的插入四、AVL树的旋转1.左单旋2.右单旋3.左右双旋4.右左双旋五、进行验证六、AVLTree的性能个人简介📝 🏆2022年度博客之星Top18;🏆2022社区之星Top2;的🥇C/C领域优质创作者…...
软考中级-嵌入式系统设计师(二)
1、逻辑电路:组合逻辑单路、时序逻辑电路。根据电路是否有存储功能判断。 2、组合逻辑电路 指该电路在任一时刻的输出,仅取决于该时刻的输入信号,而与输入信号作用前电路的状态无关。一般由门电路组成,不含记忆元器件࿰…...

epoll 笔记
maxevents 参数大小一般不超过64必须够了 maxevents 个事件,才会传到用户空间吗?可见,只要有事件就可以传到用户空间。一台服务器可以支撑多少个链接https://blog.csdn.net/mijichui2153/article/details/81331345 0、两台虚拟机的初始状态如…...

vue(5)
文章目录1. 监测数据原理1.1 通过问题引出1.2 开始1.3 Vue.set() 方法1.4 vue 监视 数组1.5 小练习2. 收集表数据3. 过滤器4. 内置指令4.1 v-text4.2 v-html4.3 v-cloak4.4 v-once4.5 v-pre1. 监测数据原理 1.1 通过问题引出 1.2 开始 要想解决上面的这个问题 ,需要…...
Android OTA 相关工具(一) 虚拟 A/B 之 snapshotctl
Android 虚拟 A/B 分区推出快三年了,不论是 google 还是百度结果,除了源代码之外,竟然没有人提到这个 Android Virtual A/B 的调试工具 ,着实让人感觉意外。 所以我相信还有不少人不知道 Android OTA 到底都有哪些调试工具&#…...
QT for Android BLE Bluetooch QT BLE
小白式的介绍,很详细了,很多主要内容写在程序的注释里,慢慢看 下面是我的源码 https://download.csdn.net/download/qq_27620407/87464307 源码打不开的话可以试试下图的操作,之后电机确定,可能是加图标搞的࿰…...

【蓝桥集训】第四天——双指针
作者:指针不指南吗 专栏:Acwing 蓝桥集训每日一题 🐾或许会很慢,但是不可以停下🐾 文章目录1.字符串删减2.最长连续不重复子序列3.数组元素的目标和1.字符串删减 给定一个由 n 个小写字母构成的字符串。 现在ÿ…...

List<Map<String, Object>>的数据结构的添加和删除实例
对List<Map<String, Object>>的数据结构的添加和删除实例添加//初始化List<Map<String, Object>> products new ArrayList<Map<String,Object>>();//也可以这样初始化List<Map<String, Object>> products null//初始Map<…...

5.2 线程实际案例练习
文章目录1.概述2.实现方案一:继承Thread2.1 代码实现2.2 代码分析3.实现方案二:实现Runnable接口3.1 代码实现3.2 代码分析4.实现方案三:构建线程池4.1 代码实现4.2 代码分析1.概述 接下来我们通过一个售票案例的实际操作来深入理解线程的相…...

stm32f407探索者开发板(十七)——串口寄存器库函数配置方法
文章目录一、STM32串口常用寄存器和库函数1.1 常用的串口寄存器1.2 串口相关的库函数1.3 状态寄存器(USART_ SR)1.4 数据寄存器(USART_ DR)1.5 波特率寄存器(USART_BRR)二、串口配置一般步骤一、STM32串口常…...

山西省2023年软考报名3月14日开始
根据2023年上半年计算机技术与软件专业技术资格(水平)考试工作计划,可以得知,全国考务管理服务平台将于2023年3月13日开放,各地开始组织报名,如山西已发布2023上半年报名简章,从3月14号开始报名。 软考报名官网 大部…...
进程章节总结性实验
进程实验课笔记 本节需要有linux基础,懂基本的linux命令操作即可。 Ubuntu镜像下载 https://note.youdao.com/s/VxvU3eVC ubuntu安装 https://www.bilibili.com/video/BV1j44y1S7c2/?spm_id_from333.999.0.0 实验环境ubuntu22版本,那个linux环境都可以…...

【MyBatis】MyBatis的缓存
10、MyBatis的缓存 10.1、MyBatis的一级缓存 一级缓存是SqlSession级别的,通过同一个SqlSession查询的数据会被缓存,下次查询相同的数据,就会从缓存中直接获取,不会从数据库重新访问 使一级缓存失效的四种情况: 不…...
的保姆级避坑指南)
STM32H7实战:用CubeMX动态切换主频(72M到16M)的保姆级避坑指南
STM32H7动态主频切换实战:从72MHz到16MHz的工程化解决方案 在嵌入式系统开发中,动态调整主频是平衡性能与功耗的关键技术。想象一下,你的智能穿戴设备正在执行运动数据实时分析,此时需要全速运行;而当进入待机状态时&a…...

如何迁移到@ngx-translate/core:从其他i18n库的平滑过渡终极指南
如何迁移到ngx-translate/core:从其他i18n库的平滑过渡终极指南 【免费下载链接】core The internationalization (i18n) library for Angular 项目地址: https://gitcode.com/gh_mirrors/core81/core Angular国际化(i18n)是构建全球应…...

智能体公司的发展都会变成解决方案型公司
当前AI智能体公司众多,但多数难以持续盈利。主要原因在于AI本质是工具,仅能解放生产力而非解决生产关系,对业务直接收入提升有限;其次,多数团队缺乏行业经验,商业模式局限于传统互联网模式,难以…...

弃投《Nature Communications》转投它?这些期刊正在让这批科研人弯道超车!
《Science Advances》影响因子分区自引率12.5JCR Q1 / 综合1区 1.6%研究方向:多学科综合、自然科学与工程期刊亮点:AAAS顶刊,年发文约2000篇,国人占比约30%,审稿3-5个月,OA发表,是各学科冲一区顶…...

Simulink电气系统建模遇阻?一文详解powergui模块缺失报错与修复
1. 为什么你的Simulink电气模型总是报错? 最近在技术论坛上看到不少电气工程师吐槽:"明明是按照教程搭建的Simscape电机模型,一运行就弹出红色报错框,说什么必须包含powergui模块..." 这让我想起自己刚接触Simulink电气…...
)
手把手教你调用MiniMax API:快速集成聊天、语音合成到你的应用(Python示例)
手把手教你调用MiniMax API:快速集成聊天、语音合成到你的应用(Python示例) 在AI技术快速落地的今天,将大模型能力集成到自己的应用中已成为开发者的刚需。MiniMax作为国内领先的大模型服务提供商,其API平台提供了对话…...

【Agent】大模型在线API接入基础入门
大模型在线API接入基础入门一、全球AI模型版图与平台选型1、OpenRouter突破封锁的中转平台2、国内模型生态:性价比与可用性的平衡4、模型选型决策二、获取并保存API KEY三、调用API1、非SDK方式调用2、 OpenAI SDK方式调用(1)什么是SDK&#…...

2026东南亚电商平台对比:Shopee vs Lazada终极指南
进入东南亚市场时,很多商家都会面临一个典型问题:Shopee 和 Lazada 应该如何选择?两大平台在流量结构、用户习惯、入驻门槛以及成本模型上存在明显差异。随着 2026 年市场环境变化,TikTok Shop 的崛起也在重塑整体流量格局。对于商…...
✅)
计算机毕业设计:Python智慧航班数据大屏及管理后台 Django框架 可视化 MLP 大数据 机器学习 深度学习(建议收藏)✅
1、项目介绍 技术栈 采用 Python 3.10 编程语言,基于 Django 框架进行后端开发,前端使用 Echarts 可视化技术搭建数据大屏,并结合多层感知器(MLP)神经网络模型实现航班延误状态与机票价格的预测功能。 功能模块飞机航…...

华为CE12808/S9700交换机istack/CSS堆叠主备倒换实战指南与常见问题解析
1. 华为交换机堆叠技术基础认知 第一次接触华为CE12808和S9700交换机的堆叠功能时,我被istack和CSS这两个专业术语搞得有点懵。后来在实际项目中反复折腾才发现,这其实就是华为针对不同系列交换机设计的两种堆叠技术方案。简单来说,istack主要…...