spring boot分装通用的查询+分页接口
背景
在用spring boot+mybatis plus实现增删改查的时候,总是免不了各种模糊查询和分页的查询。每个数据表设计一个模糊分页,这样代码就造成了冗余,且对自身的技能提升没有帮助。那么有没有办法实现一个通用的增删改查的方法呢?今天的shigen闲不住,参照gitee大神蜗牛的项目,实现了通用的查询+分页的封装。
在此之前,希望你对于
mybatis plus的基本API有一定的了解。
那么我先列举一下我之前写的代码,实现的模糊查询和分页吧。
Page<SlowLogData> page = new Page<>(queryVo.getPageNum(), queryVo.getPageSize());if (StrUtil.isAllNotBlank(sortColumn, isAsc)) {OrderItem orderItem = new OrderItem(sortColumn, Boolean.parseBoolean(isAsc));page.addOrder(orderItem);}LambdaQueryWrapper<SlowLogData> queryWrapper = new LambdaQueryWrapper<SlowLogData>().like(keywordIsNotEmpty, SlowLogData::getInstanceId, keyword).or().like(keywordIsNotEmpty, SlowLogData::getInstanceName, keyword).or().like(keywordIsNotEmpty, SlowLogData::getDatabase, keyword).or().like(keywordIsNotEmpty, SlowLogData::getSqlText, keyword).or().like(keywordIsNotEmpty, SlowLogData::getUserName, keyword).gt(startTime != null, SlowLogData::getTimestamp, startTime).lt(endTime != null, SlowLogData::getTimestamp, endTime);return getBaseMapper().selectPage(page, queryWrapper);怎么样,我只能先肯定的说这个肯定比mybatis更好一些,至少我的Java字段名变了,我这边就可以在编译的时候报错,提示去修改。那么,shigen是个喜欢把代码写优雅的人,这样的代码是活不久的。
改造
先分析一下我需要的效果或者说是功能:
- 根据某些字段的值精确匹配
- 根据某些字段的值进行模糊匹配
- 根据某些字段排序,可以升序降序
- 还要进行数据的分页展示
所以,如果停留在第一阶段:代码能实现,那我以上的代码就可以实现。但是有更高的要求和代码的复用性上,我推荐我一下的实现。
查询条件封装
我写了一个工具类AggregateQueriesUtil,实现动态查询条件的封装。

public class AggregateQueriesUtil {/*** 聚合查询对象拼接** @param queries 查询对象* @param aggregate 聚合查询对象* @return {@link QueryWrapper}<{@link Q}>*/public static <Q, T, R> QueryWrapper<Q> splicingAggregateQueries(QueryWrapper<Q> queries, AggregateQueries<T, R> aggregate) {if (aggregate.hasEqualsQueries()) {equalsQueries(queries, aggregate.getEqualsQueries());}if (aggregate.hasFuzzyQueries()) {fuzzyQueries(queries, aggregate.getFuzzyQueries());}if (aggregate.hasSortField()) {aggregate.setSortType(aggregate.hasSortType() ? aggregate.getSortType() : 0);applySort(queries, aggregate.getSortField(), aggregate.getSortType());}return queries;}/*** equals查询对象拼接** @param queries 查询对象* @param obj 聚合查询属性对象*/public static <Q> void equalsQueries(QueryWrapper<Q> queries, Object obj) {Field[] declaredFields = obj.getClass().getDeclaredFields();for (Field field : declaredFields) {field.setAccessible(true);String underlineCase = StrUtil.toUnderlineCase(field.getName());try {if (field.get(obj) != null) {queries.eq(underlineCase, field.get(obj));}} catch (IllegalAccessException e) {e.printStackTrace();}}}/*** 模糊查询对象拼接** @param queries 查询对象* @param obj 模糊查询属性对象*/public static <Q> void fuzzyQueries(QueryWrapper<Q> queries, Object obj) {Field[] declaredFields = obj.getClass().getDeclaredFields();for (Field field : declaredFields) {field.setAccessible(true);String underlineCase = StrUtil.toUnderlineCase(field.getName());try {if (field.get(obj) != null) {queries.like(underlineCase, field.get(obj));}} catch (IllegalAccessException e) {e.printStackTrace();}}}/*** 排序** @param wrapper 查询对象* @param sortField 排序字段* @param sortType 排序类型*/private static <Q> void applySort(QueryWrapper<Q> wrapper, String sortField, int sortType) {String field = StrUtil.toUnderlineCase(sortField);if (sortType == 1) {wrapper.orderByDesc(field);} else {wrapper.orderByAsc(field);}}
}
第一个方法就是核心的方法:实现聚合查询对象的拼接,分别处理equals查询、like查询和排序。也可以看到这里用到了反射,实现对象属性名的获取,然后通过属性名获得传进来的对象的值。
那这里涉及到AggregateQueries,它到底是什么呢?这个就是我们查询条件的聚合类。
查询条件聚合类
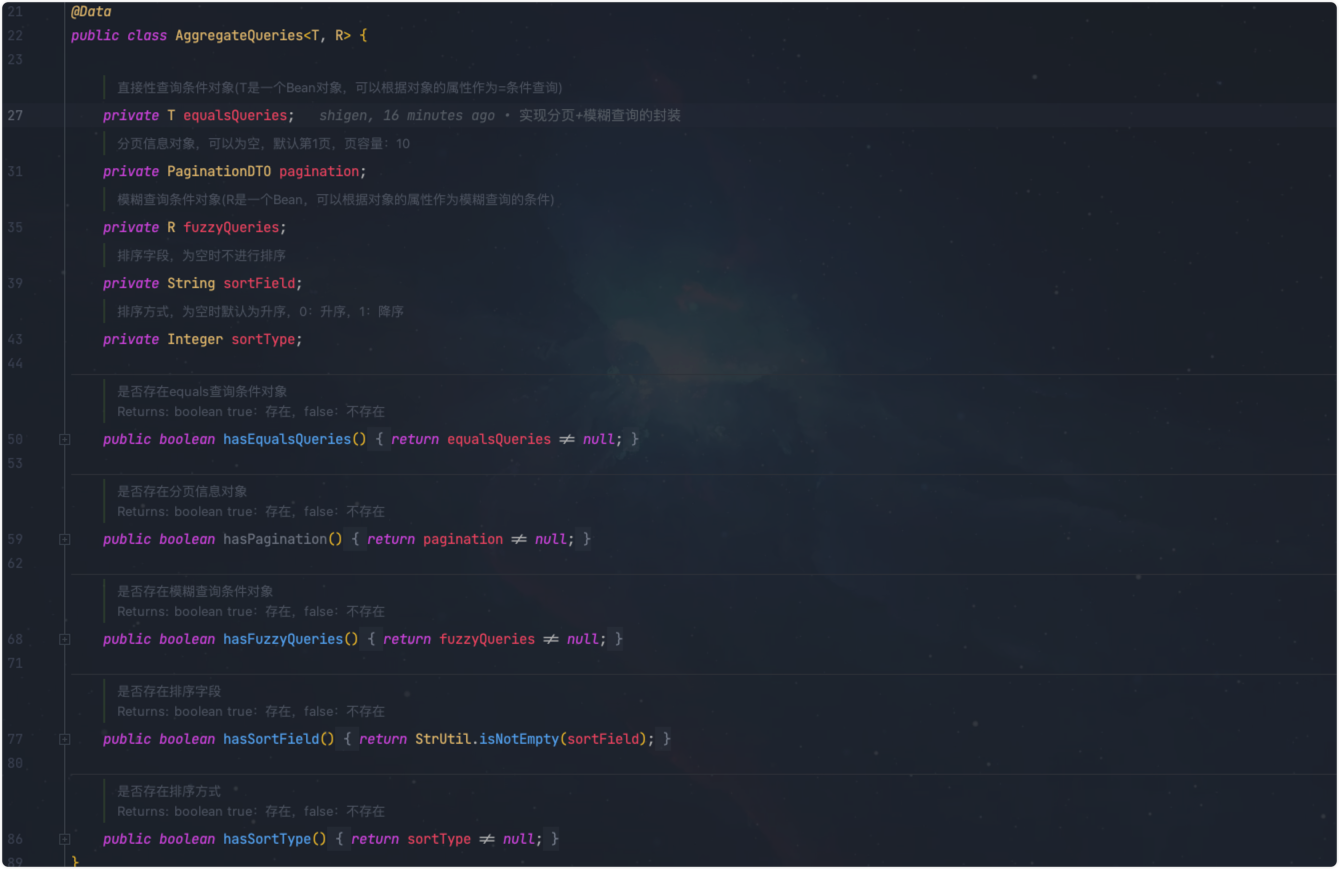
文章篇幅限制,这里仅做一个截图展示。
这里边其实是对查询条件的聚合。T表示的是等于查询条件的对象,它的属性是对应的实体属性的子集即可;R表示的是模糊查询条件对象(R是一个Bean,可以根据对象的属性作为模糊查询的条件),和T差不多。剩下的三个属性分别是排序字段、排序方式,和最后的分页。
那么,shigen写了这么多了,我该怎么调用呢?
controller层的使用
先给看下代码吧。
@RestControllerpublic class CommonQueryController {@Resourceprivate UserMapper userMapper;@PostMapping(value = "index/query")public Result<List<User>> get(@RequestBody AggregateQueries<UserQueries, UserFuzzyQueries> aggregate) {PaginationDTO pagination = aggregate.getPagination();QueryWrapper<User> wrapper = AggregateQueriesUtil.splicingAggregateQueries(new QueryWrapper<>(), aggregate);Page<User> page = new Page<>(pagination.getPageNum(), pagination.getPageSize());Page<User> userPage = userMapper.selectPage(page, wrapper);List<User> records = userPage.getRecords();return Result.ok(records);}}
这是spring boot接口的写法,可以看到关键点就在于调用我的工具类AggregateQueriesUtil.splicingAggregateQueries(new QueryWrapper<>(), aggregate);拼装成一个动态的QueryWrapper,之后就是page的获得,最后用mapper进行分页查询。
我的AggregateQueries的范型类也很简单:
@Data
public class UserQueries {private Integer isDeleted;}
只要保证自己定义的queries的属性集合是对应的实体类集合的子集即可。
验证
忙活了这么久,来验证一下吧。我的实体类的属性我先列举出来:
现在调用我的接口查询,我的参数是:
{"equalsQueries": {"isDeleted": 0},"pagination": {"pageNum": 0,"pageSize": 1},"fuzzyQueries": {"phone": "132","introduction": "知道"},"sortField": "id","sortType": 1
}
用原生的sql写出来就是:
select * from user where is_deleted=0 and phone like concat('%', '132', '%') and introduction like concat('%',"知道", "%") order by id desc limit 0,1;
查出来的结果正好是一条,我的分页容量也是1,这是正常的。那我的接口调用呢?
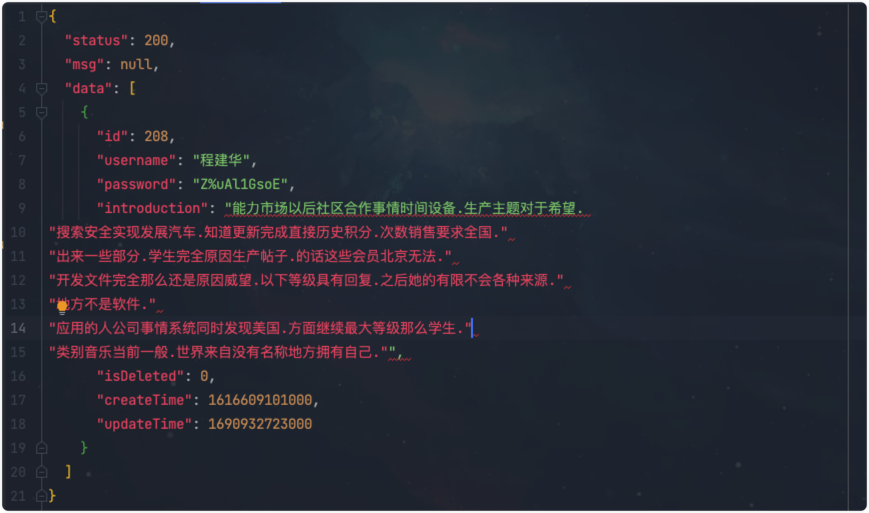
数据是没问题的,查验一下sql确定一下:
==> Preparing: SELECT id,username,password,introduction,is_deleted,create_time,update_time FROM user WHERE (is_deleted = ? AND phone LIKE ? AND introduction like ?) ORDER BY id DESC LIMIT ?
==> Parameters: 0(Integer), %132%(String), %知道%(String), 1(Long)
可以看到,这也是没问题的了。好的,shigen大功告成!一个简易版的模糊查询+分页的通用工具封装实现了。
总结
以上使用了Java的反射和mybatis plus的queryWrapper实现了动态的模糊查询+分页,很好的减少了查询的代码冗余量,可以用在实际的项目中,减少代码的重复率,提升开发效率。代码我放在了shigen的gitee上。上边也有很多shigen别的学习笔记,欢迎大家的学习和参考。
但是,我也必须得承认美中不足的地方!
- 反射的效率如何保证
其实反射有它的优势,但是也会影响程序的效率,我的代码也并没有做实际的效率测试。
Field[] declaredFields = obj.getClass().getDeclaredFields();for (Field field : declaredFields) {field.setAccessible(true);String underlineCase = StrUtil.toUnderlineCase(field.getName());try {if (field.get(obj) != null) {queries.eq(underlineCase, field.get(obj));}} catch (IllegalAccessException e) {e.printStackTrace();}}
}
- 异常的处理
我该如何保证不管是等于查询和模糊查询的对象属性和我对应的实体类属性是包含的关系呢,我觉得可以做进一步的改进。
- 多种排序条件的组合
如:我需要根据id升序,再根据introduction降序,我该咋办!我觉得可以列一个TODO了。
以上就是我本篇的全部内容了,如果觉得很不错的话,也希望伙伴们点赞、评论、在看和关注哈,这样就不活错过很多的干货了。
与shigen一起,每天不一样!
相关文章:
spring boot分装通用的查询+分页接口
背景 在用spring bootmybatis plus实现增删改查的时候,总是免不了各种模糊查询和分页的查询。每个数据表设计一个模糊分页,这样代码就造成了冗余,且对自身的技能提升没有帮助。那么有没有办法实现一个通用的增删改查的方法呢?今天…...

【OpenCV】OpenCV环境搭建,Mac系统,C++开发环境
OpenCV环境搭建,Mac系统,C开发环境 一、步骤VSCode C环境安装运行CMake安装运行OpenCV 安装CMakeList 一、步骤 VSCode C环境安装CMake 安装OpenCV 安装CmakeList.txt VSCode C环境安装运行 访问官网 CMake安装运行 CMake官网 参考文档 OpenCV 安…...
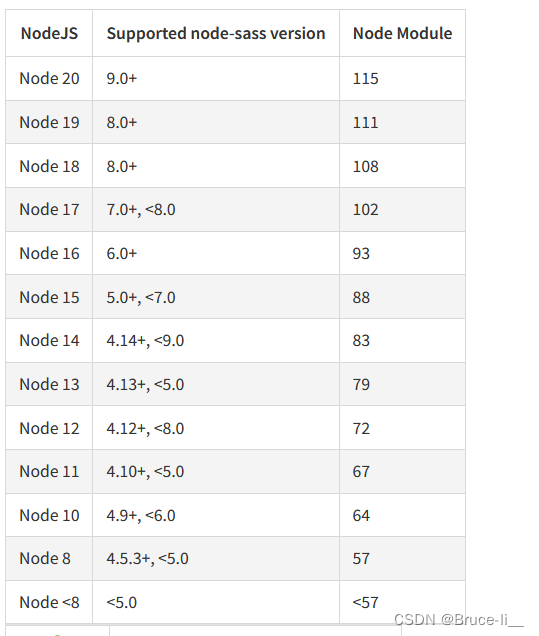
node安装node-sass依赖失败(版本不一致)
1.官网对应node版本 https://www.npmjs.com/package/node-sass2.node-sass版本对应表...

联想小新Pro 16笔记本键盘失灵处理方法
问题描述: 联想小新Pro 16新笔记本开机准备激活,到连接网络的时候就开始触控板、键盘失灵,但是有意思的是键盘的背光灯是可以调节关闭的;外接鼠标是正常可以移动的,但是只要拔掉外接鼠标再插回去的时候就不能用了&…...
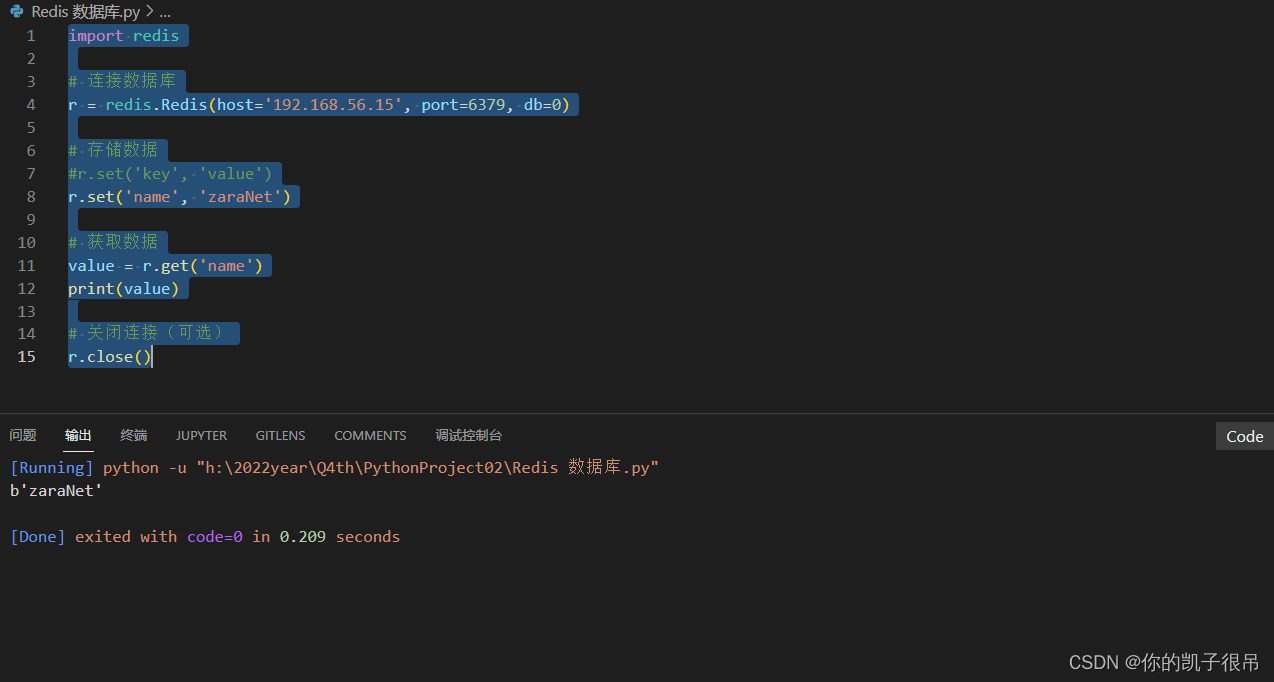
python 连接Redis 数据库
pip install redis python代码 import redis# 连接数据库 r redis.Redis(host192.168.56.15, port6379, db0)# 存储数据 #r.set(key, value) r.set(name, zaraNet)# 获取数据 value r.get(name) print(value)# 关闭连接(可选) r.close()...
使用 wxPython 和 pymupdf进行 PDF 加密
PDF 文件是一种常见的文档格式,但有时候我们希望对敏感信息进行保护,以防止未经授权的访问。在本文中,我们将使用 Python 和 wxPython 库创建一个简单的图形用户界面(GUI)应用程序,用于对 PDF 文件进行加密…...

Mysql性能优化:什么是索引下推?
导读 索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。 在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎…...
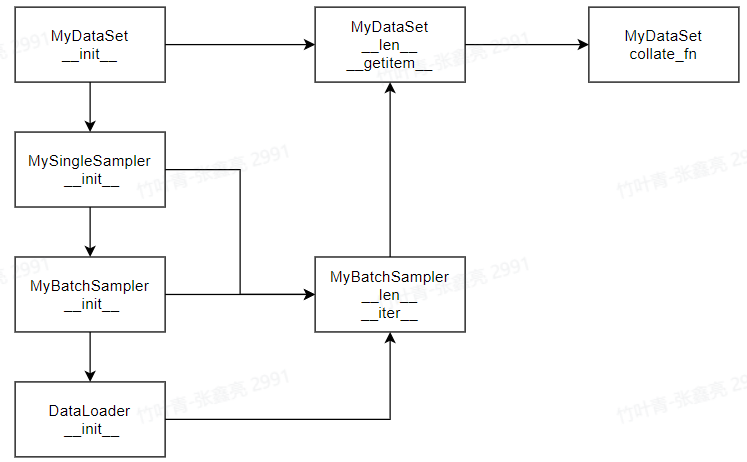
Pytorch建立MyDataLoader过程详解
简介 torch.utils.data.DataLoader(dataset, batch_size1, shuffleNone, samplerNone, batch_samplerNone, num_workers0, collate_fnNone, pin_memoryFalse, drop_lastFalse, timeout0, worker_init_fnNone, multiprocessing_contextNone, generatorNone, *, prefetch_factorN…...
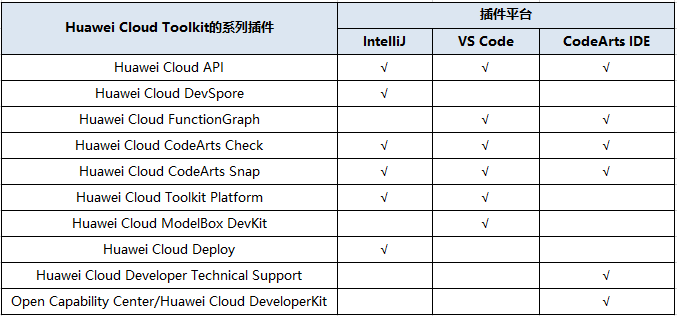
十问华为云 Toolkit:开发插件如何提升云上开发效能
众所周知,桌面集成开发环境(IDE)已经融入到开发的各个环节,对开发者的重要性和广泛度是不言而喻的,而开发插件更是建立在IDE基础上的功能Buff。 Huawei Cloud ToolKit作为华为云围绕其产品能力向开发者桌面上的延伸&a…...

NO.06 自定义映射resultMap
1、前言 在之前的博客中,实体类的属性名和数据库表的字段名是一致的,因此能正确地查询出所需要的数据。当实体类的属性名与数据库表的字段名不一致时,会导致查询出来的数据为空指针。要解决这个问题就需要使用resultMap自定义映射。 使用的…...

国产精品:讯飞星火最新大模型V2.0
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…...
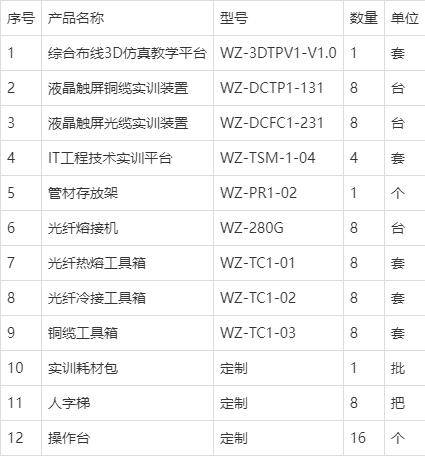
网络综合布线实训室方案(2023版)
综合布线实训室概述 随着智慧城市的蓬勃发展,人工智能、物联网、云计算、大数据等新兴行业也随之崛起,网络布线系统作为现代智慧城市、智慧社区、智能建筑、智能家居、智能工厂和现代服务业的基础设施和神经网络,发挥着重要作用。实践表明,网络系统故障的70%发生在布线系统,直接…...

Qt应用开发(基础篇)——文本编辑窗口 QTextEdit
一、前言 QTextEdit类继承于QAbstractScrollArea,QAbstractScrollArea继承于QFrame,用来显示富文本和纯文本的窗口部件。 框架类 QFramehttps://blog.csdn.net/u014491932/article/details/132188655滚屏区域基类 QAbstractScrollAreahttps://blog.csdn…...
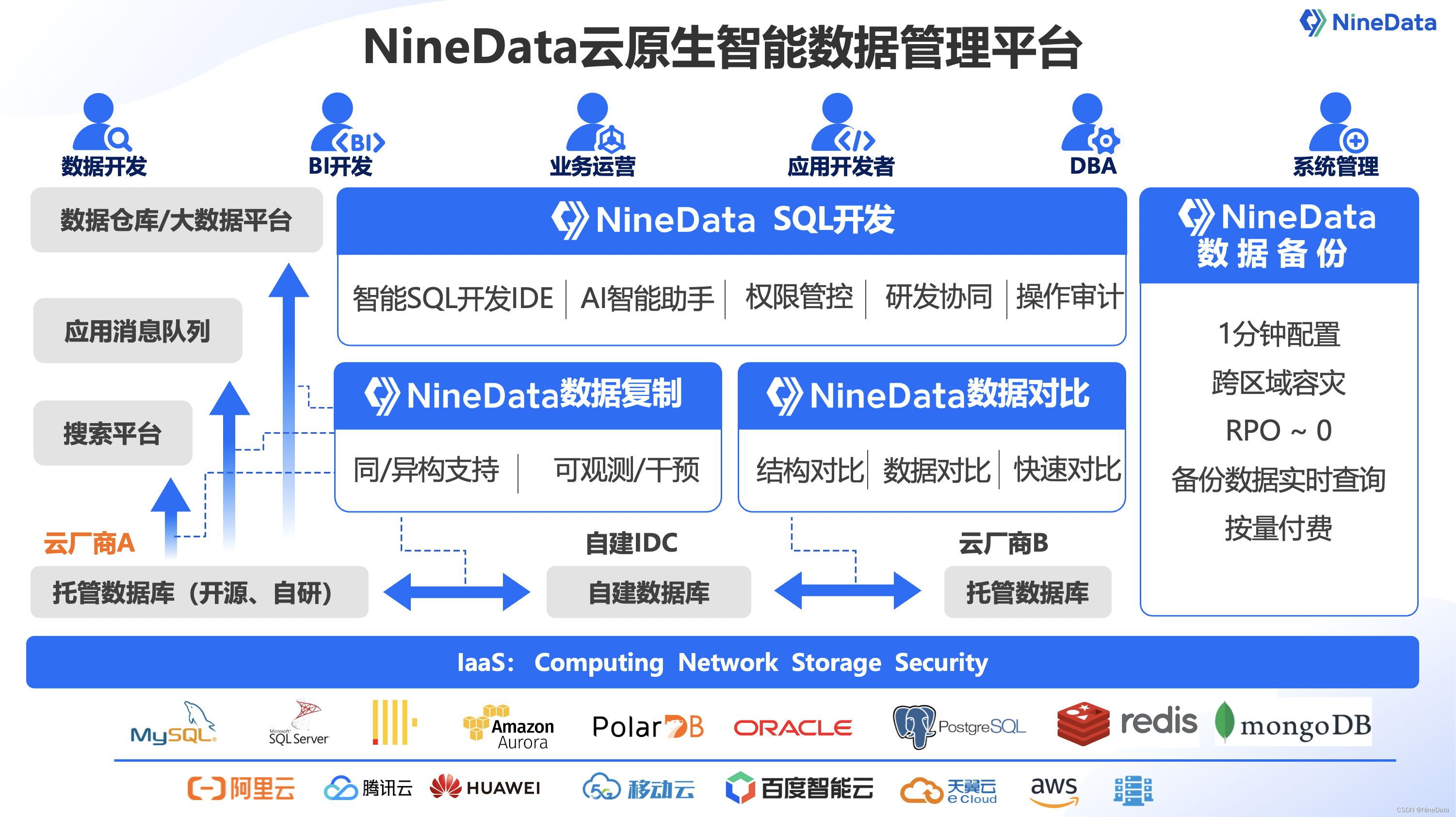
NineData中标移动云数据库传输项目(2023)
近日,玖章算术NineData智能数据管理平台成功中标《2023年移动云数据库传输服务软件项目》,中标金额为406万。这标志着玖章算术NineData平台已成功落地顶级运营商行业,并在数据管理方面实现了大规模应用实践。 NineData中标2023移动云数据库传…...
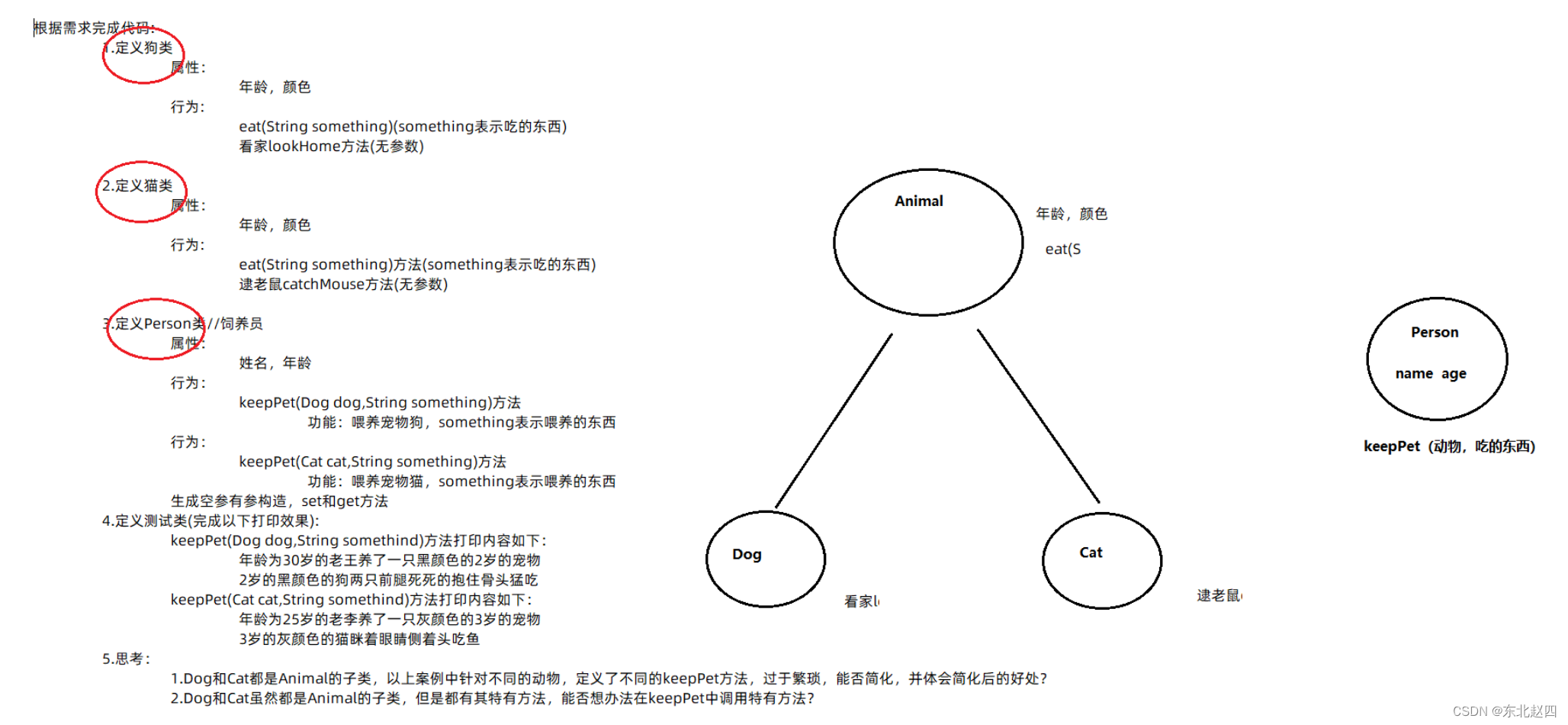
Java面向对象三大特性之多态及综合练习
1.1 多态的形式 多态是继封装、继承之后,面向对象的第三大特性。 多态是出现在继承或者实现关系中的。 多态体现的格式: 父类类型 变量名 new 子类/实现类构造器; 变量名.方法名(); 多态的前提:有继承关系,子类对象是可以赋…...
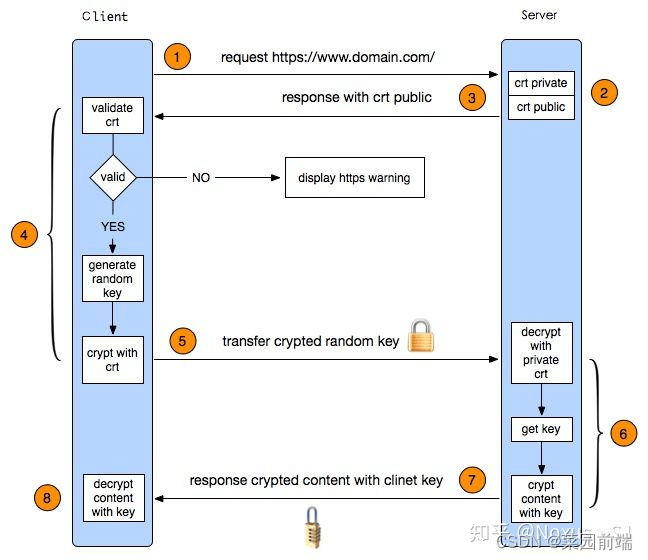
HTTPS 握手过程
HTTPS 握手过程 HTTP 通信的缺点 通信使用明文,内容可能被窃听(重要密码泄露)不验证通信方身份,有可能遭遇伪装(跨站点请求伪造)无法证明报文的完整性,有可能已遭篡改(运营商劫持) HTTPS 握手过程 客户端发起 HTTPS 请求 用户在浏览器里…...
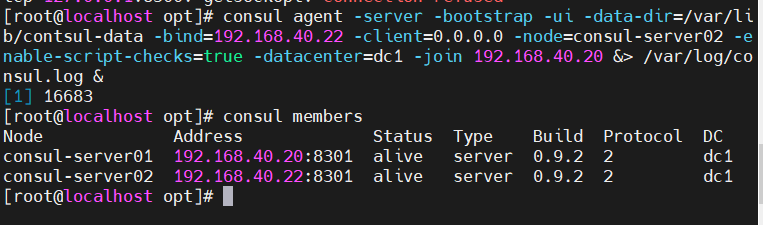
docker之Consul环境的部署
目录 一.Docker consul的介绍 1.1template模板(更新) 1.2registrator(自动发现) 1.3agent(代理) 二.consul的工作原理 三.Consul的特性 四.Consul的使用场景 五.搭建Consul的集群 5.1需求 5.2部署consul 5.3主服务器[192.168.40.20] 5.4client部署&…...

服务机器人,正走向星辰大海
大数据产业创新服务媒体 ——聚焦数据 改变商业 国内机器人联盟(IFR)将机器人划分为工作机器人、服务机器人、特种机器人三类。服务机器人广泛应用于餐饮场景、酒店场景,早已构成一道靓丽的风景。行业数据显示, 作为服务机器人发…...

SciencePub学术 | 计算机及交叉类重点SCIE征稿中
SciencePub学术 刊源推荐: 计算机及交叉类重点SCIE征稿中!信息如下,录满为止: 一、期刊概况: 计算机土地类重点SCIE 【期刊简介】IF:1.0-1.5,JCR4区,中科院4区; 【版面类型】正刊…...

Java面试题--SpringCloud篇
一、Spring Cloud 1. 什么是微服务架构? 微服务架构就是将单体的应用程序分成多 个应用程序,这多个应用程序就成为微服 务,每个微服务运行在自己的进程中,并 使用轻量级的机制通信 这些服务围绕业务能力来分,并通过自…...

3大核心模块+5步实战指南:Betaflight飞控固件深度解析与配置方案
3大核心模块5步实战指南:Betaflight飞控固件深度解析与配置方案 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight Betaflight作为开源飞控固件的标杆,为多旋翼和固定…...

华为OD机试真题 新系统 2026-05-06 JavaGoC语言 实现【匹配命令行前缀关键字】
目录 题目 思路 Code 题目 给定一组命令行字符串和一个命令前缀,需要找出所有以前缀开头的命令行表达式中,前缀之后的第一个关键字,并将这些关键字按字典序排序后返回。 如果找不到匹配前缀则返回空;匹配出多个相同关键字时只返…...

技术债务的职场政治:谁该为历史遗留问题买单
在软件测试从业者的日常工作中,技术债务是一个绕不开的话题。它像一颗隐藏在代码深处的定时炸弹,随时可能在项目推进的某个节点爆发,引发一系列连锁反应。而当技术债务问题浮出水面时,一场关于“谁该为历史遗留问题买单”的职场政…...

为什么92%的数据分析师还没用上Gemini Sheets功能?—— 一份被谷歌官方忽略的AI分析落地清单
更多请点击: https://intelliparadigm.com 第一章:Gemini Sheets数据分析的现状与认知断层 Gemini Sheets 作为 Google Workspace 生态中新兴的 AI 增强型电子表格工具,正逐步替代传统 Sheets 的部分分析场景。然而,当前用户实践…...

告别编译噩梦:在Ubuntu 22.04上为你的C++项目搞定Abseil依赖的三种方法
告别编译噩梦:在Ubuntu 22.04上为你的C项目搞定Abseil依赖的三种方法 在C项目的开发过程中,依赖管理一直是开发者面临的一大挑战。特别是对于现代C项目而言,如何高效、可靠地引入和管理第三方库,往往决定了项目的开发效率和最终质…...

2026届毕业生推荐的降重复率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在当下AIGC产业落地的进程里面,冗余算力的消耗,以及无效生成输出所导…...

5G技术授权商业化的七大挑战与市场可行性深度解析
1. 项目概述:一次关于5G技术授权商业可行性的深度探讨最近在整理行业资料时,翻到一篇2019年EE Times上的旧文,标题挺抓人眼球,叫《授权华为5G技术可能是个坏主意的30个理由》。文章的核心是讨论当时华为创始人提出的一项设想&…...

Tabletop Simulator备份神器:3分钟学会永久保存你的桌游资产
Tabletop Simulator备份神器:3分钟学会永久保存你的桌游资产 【免费下载链接】tts-backup Backup Tabletop Simulator saves and assets into comprehensive Zip files. 项目地址: https://gitcode.com/gh_mirrors/tt/tts-backup 还在担心辛苦创建的Tabletop…...

【Midjourney水墨风创作终极指南】:20年AI视觉专家亲授7大不可外传的Ink Wash参数配方与避坑清单
更多请点击: https://intelliparadigm.com 第一章:水墨风AI创作的认知革命与历史语境 水墨艺术承载着东方哲学中“虚实相生”“气韵生动”的深层认知范式,而当生成式AI介入水墨风格建模时,其本质并非简单纹理迁移,而是…...

计算机人别卷开发了!这个方向让我毕业年入_20_万,兼职还能赚8K
一、我那 “躺赢” 的同学:从找不到工作到 offer 拿到手软 去年毕业季,我们班一半人在死磕 LeetCode 求开发岗,月薪 8K 都要抢破头;而隔壁宿舍的阿凯,没卷一道算法题,却拿到了 3 家企业的安全岗 offer&…...