Datawhale AI夏令营 - 用户新增预测挑战赛 | 学习笔记
数据分析与可视化
为了拟合出更好的结果就要了解训练数据之间的相互关系,进行数据分析是必不可少的一步
导入必要的库
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snspandas库是一个强大的分析结构化数据的python库,是Pythonopen in new window的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。
numpy是python中科学计算的基础库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
可视化的图标能便于分析数据
matplotlib是一个python 2D绘图库,它以多种硬拷贝格式和跨平台的交互式环境生成出版物质量的图形。
seaborn 是一个基于matplotlib进行进行二次封装的绘图库,它也绘制更为集成、复杂的图表。
绘制数据热力图
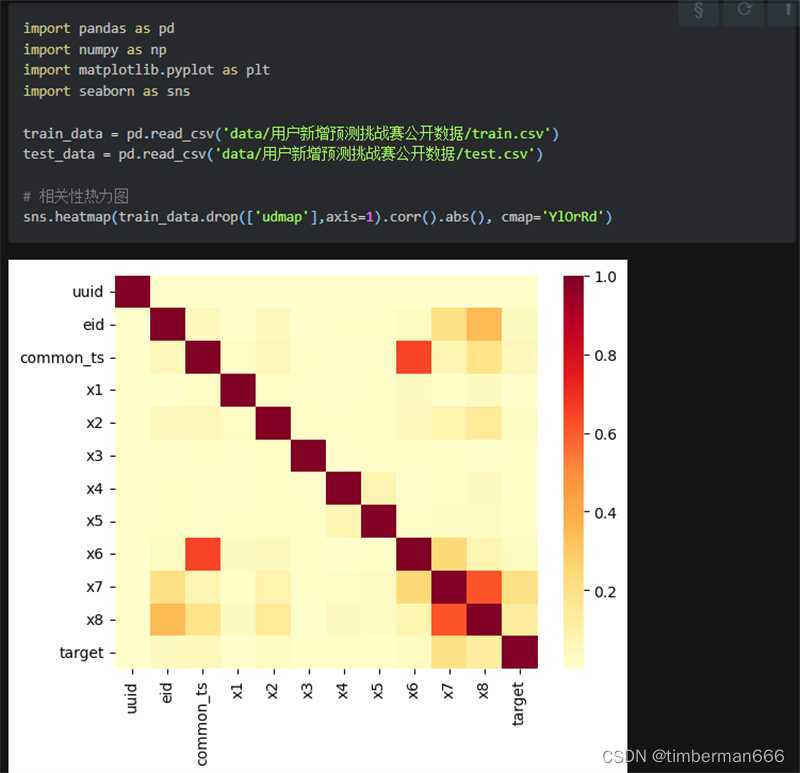
# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')上面是教程给的代码,下面是自己尝试调整了一部分参数后的
# 相关性热力图
fig, ax = plt.subplots(figsize=(18,18))#设置画布大小
sns.heatmap(train_data.corr(),square=True, annot=True, vmax=1, vmin=0,annot_kws={'size': 5},linewidths=0.3, # 控制每个小方格之间的间距linecolor="white", # 控制分割线的颜色cmap="RdBu_r")绘制直方图
# x7分组下标签均值
sns.barplot(x='x7', y='target', data=train_data)模型交叉验证
交叉验证(Cross-Validation)是机器学习中常用的一种模型评估方法,用于评估模型的性能和泛化能力。
简单来说就是通过数据评估不同模型,避免过拟合或欠拟合,从而可以找到性能最优的模型。
上面的代码验证评估了四个模型,通过输出结果,其实不难发现,树模型的macro F1效果好
一般的,随机森林(RandomForestClassifier)效果比决策树(DecisionTreeClassifier)好一些,本题经过一定特征工程后亦是如此。
特征工程
通过进行特征工程,我们可以优化训练数据,使得得到的模型的性能提升
教程给了如上的特征处理,经过训练,发现common_ts_day与x1_mean,x2_mean是其中对提升精度影响比较大的特征
数据清洗 -- 缺失值与异常值处理
训练模型时遇到报错:ValueError:Input contains NaN, infinity or a value too large for dtype('float64').
处理异常值(以训练集 train_data 为例):
1.检查特征类型
print(train_data.dtypes()) #打印训练集特征类型2.针对不符合类型训练时抛弃
train_data.drop(['udmap', 'common_ts', 'uuid') #训练时3.无穷值处理
#检查是否有无穷数据
print(np.isfinite(train_data).all())
#或
print(np.isinf(train_data).all())#处理
train_inf = np.isinf(train_data) #提取
train_data[train_inf] = 0 #替换在使用 dropna 时遇到删除带有缺失值行数据失败的情况:
这里是因为 NaN 是一个空字符串, 但 dropna 并不会将空字符串当作缺失值处理, 所以没能成功删除
同时,因为删除带有缺失值的行会改变行数,处理测试集 test_data 后会导致提交平台检测出错误
所以采用填充处理
最简单的是用 0 填充
train_data.fillna(0) #将 NaN 替换成 0也可以使用 replace()
train_data.replace("0",np.nan,inplace=True) #将缺失值替换成 0
#如果在其他项目中这里也可以替换成 "nan" 然后使用 dropna 缺失值填补有很多方法
1.人工填补 2.平均数填补 3.众数填补 4.中位数填补 5.临近数填补
等等等等,还可以采用一些算法进行填补
1.独热编码(One-HotEncoding)
可以扩充特征,采用N位状态寄存器来对N个可能的取值进行编码,每个状态都由独立的寄存器来表示
baseline 中的函数 udmap_onethot :
# 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
def udmap_onethot(d):v = np.zeros(9) # 创建一个长度为 9 的零数组if d == 'unknown': # 如果 'udmap' 的值是 'unknown'return v # 返回零数组d = eval(d) # 将 'udmap' 的值解析为一个字典for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身if 'key' + str(i) in d: # 如果当前键存在于字典中v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上return v # 返回 One-Hot 编码后的数组对星期进行 One-Hot 编码 :
# 定义函数 week_onethot,用于将 'common_ts_week' 列进行 One-Hot 编码
def week_onethot(d):v = np.zeros(7)if d == 'Sunday':v[0] = 1elif d == 'Monday':v[1] = 1elif d == 'Tuesday':v[2] = 1elif d == 'Wednesday':v[3] = 1elif d == 'Thursday':v[4] = 1elif d == 'Friday':v[5] = 1elif d == 'Saturday':v[6] = 1return v 2.特征二元化
将数值型的属性转换为布尔值的属性,设定一个阈值或条件划分属性值为0或1
简单来说就是将特征分成两部分,用 1 / 0 区分是否满足某条件
baseline 中的 udmap_isunknown :
# 编码 udmap 是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)判断 x7 是否为 1 :
# 特征 x7 是否为 1
train_data['x7_is1'] = train_data['x7'].apply(lambda d : d == 1)
test_data['x7_is1'] = test_data['x7'].apply(lambda d : d == 1)
相关文章:
Datawhale AI夏令营 - 用户新增预测挑战赛 | 学习笔记
数据分析与可视化 为了拟合出更好的结果就要了解训练数据之间的相互关系,进行数据分析是必不可少的一步 导入必要的库 # 导入库 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns pandas库是一个强大的分析结构化…...
卡片开发AbilityStage组件容器)
HarmonyOS/OpenHarmony(Stage模型)卡片开发AbilityStage组件容器
AbilityStage是一个Module级别的组件容器,应用的HAP在首次加载时会创建一个AbilityStage实例,可以对该Module进行初始化等操作。 AbilityStage与Module一一对应,即一个Module拥有一个AbilityStage。 DevEco Studio默认工程中未自动生成Abilit…...

利用torchvision库实现目标检测与语义分割
一、介绍 利用torchvision库实现目标检测与语义分割。 二、代码 1、目标检测 from PIL import Image import matplotlib.pyplot as plt import torchvision.transforms as T import torchvision import numpy as np import cv2 import randomCOCO_INSTANCE_CATEGORY_NAMES …...
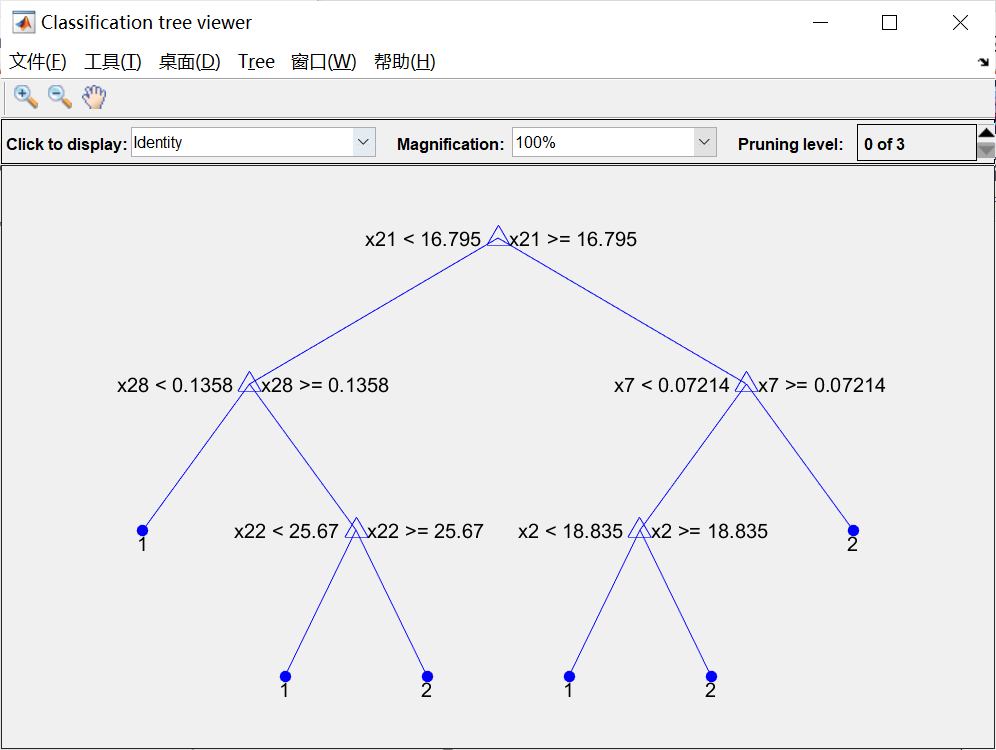
基于决策树(Decision Tree)的乳腺癌诊断
决策树(DecisionTree)学习是以实例为基础的归纳学习算法。算法从--组无序、无规则的事例中推理出决策树表示形式的分类规则,决策树也能表示为多个If-Then规则。一般在决策树中采用“自顶向下、分而治之”的递归方式,将搜索空间分为若千个互不相交的子集,在决策树的内部节点(非叶…...
每天10个小知识点)
前端面试的计算机网络部分(2)每天10个小知识点
目录 系列文章目录前端面试的计算机网络部分(1)每天10个小知识点 知识点11. DNS 完整的查询过程递归查询过程:迭代查询过程: 12. OSI 七层模型13. TCP 的三次握手和四次挥手三次握手(Three-Way Handshake)&…...

【LeetCode】224. 基本计算器
224. 基本计算器(困难) 方法:双栈解法 思路 我们可以使用两个栈 nums 和 ops 。 nums : 存放所有的数字ops :存放所有的数字以外的操作,/- 也看做是一种操作 然后从前往后做,对遍历到的字符做…...

服务器数据恢复-EVA存储磁盘故障导致存储崩溃的数据恢复案例
EVA系列存储是一款以虚拟化存储为实现目的的中高端存储设备。EVA存储中的数据在EVA存储设备工作过程中会不断进行迁移,如果运行的任务比较复杂,EVA存储磁盘负载加重,很容易出现故障的。EVA存储通过大量磁盘的冗余空间和故障后rss冗余磁盘动态…...

【stylus】通过css简化搜索页面样式
发现stylus专门修改样式的插件后,发现之前写JS调整样式的方式是在太蠢了,不过有一些交互的东西还是得用JS,例如设置按钮来交互显示功能,或记录功能等。插件可以让简化网站变得简单,而且可以实时显示,真的不…...

【官方中文文档】Mybatis-Spring #使用 SqlSession
使用 SqlSession 在 MyBatis 中,你可以使用 SqlSessionFactory 来创建 SqlSession。 一旦你获得一个 session 之后,你可以使用它来执行映射了的语句,提交或回滚连接,最后,当不再需要它的时候,你可以关闭 s…...
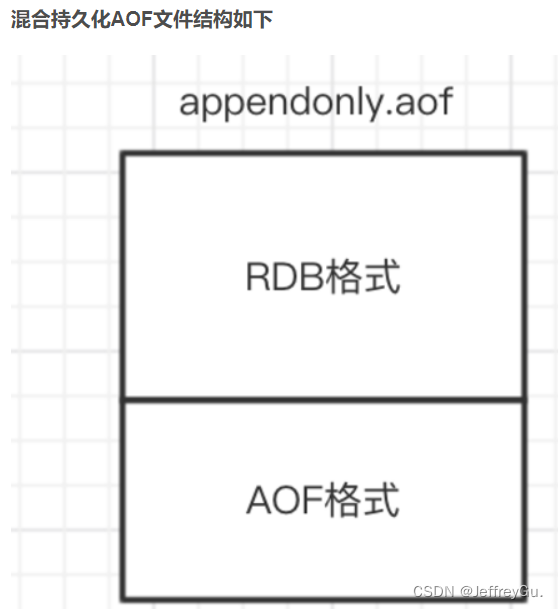
Redis三种持久化方式详解
一、Redis持久性 Redis如何将数据写入磁盘 持久性是指将数据写入持久存储,如固态磁盘(SSD)。Redis提供了一系列持久性选项。其中包括: RDB(快照):RDB持久性以指定的时间间隔执行数据集的时间点…...
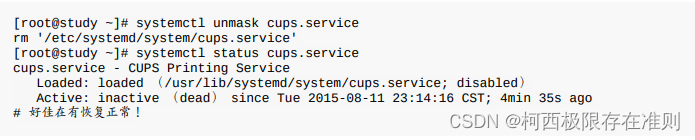
17.2 【Linux】通过 systemctl 管理服务
systemd这个启动服务的机制,是通过一支名为systemctl的指令来处理的。跟以前 systemV 需要 service / chkconfig / setup / init 等指令来协助不同, systemd 就是仅有systemctl 这个指令来处理而已。 17.2.1 通过 systemctl 管理单一服务 (s…...

第 7 章 排序算法(3)(选择排序)
7.6选择排序 7.6.1基本介绍 选择式排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到排序的目的。 7.6.2选择排序思想: 选择排序(select sorting)也是一种简单的排序方法…...

Less文件可以做哪些复杂操作
在Less文件中,你可以进行许多复杂的操作来增强样式表的功能和灵活性。以下是一些常见的操作: 变量(Variables):使用符号定义和使用变量,可以在整个样式表中重复使用相同的值,以便轻松修改和维护…...

HTML5岗位技能实训室建设方案
一 、系统概述 HTML5岗位技能技术是计算机类专业重要的核心课程,课程所包含的教学内容多,实践性强,并且相关技术更新快。传统的课堂讲授模式以教师为中心,学生被动式接收,难以调动学生学习的积极性和主动性。混合式教学…...

【Linux】GNOME图形化界面安装
Linux下具有多种图形化界面,每种图形化界面具有不同的功能,在这里我们安装的是GNOME。 1、 挂载yum源 挂载之前首先确保使用ISO映像文件 2.挂载之前先在/mnt下面创建一个cdrom目录用来作为挂载点目录 挂载完成之后那么就要去修改yum源了 Vi /etc/yum.r…...

大数据课程J3——Scala的类定义
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Scala的柯里化 Currying; ⚪ 掌握Scala的类定义; ⚪ 掌握Scala的样例类、option类; ⚪ 掌握Scala的隐式转换机制; 一、柯里化 Currying 柯里化(Currying)技术 Christopher St…...
Ribbon:使用Ribbon实现负载均衡
Ribbon实现的是实线走的 建立三个数据库 /* SQLyog Enterprise v12.09 (64 bit) MySQL - 5.7.25-log : Database - db01 ********************************************************************* *//*!40101 SET NAMES utf8 */;/*!40101 SET SQL_MODE*/;/*!40014 SET OLD_UNIQ…...

最新最全的~教你如何搭建高可用Lustre双机集群
1.搭建双机lustre高可用集群: 1.环境说明: 主机名系统挂载情况IP地址Lustre集群名内存mds001Centos7.9(共享磁盘)1个mgs,1个MDT,2个OST192.168.10.21/209.21global1Gmds002Centos7.9(共享磁盘)1个mgs,1个MDT,2个OST192.168.10.22/209.22global1GclientCentos7.9无19…...

深入浅出Pytorch函数——torch.nn.init.uniform_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...
会员管理系统实战开发教程02-H5应用创建
低代码平台作为一个应用的快速生成工具,可以方便的进行一页多端的开发,可以在一个应用里生成三端的应用,也可以拆分成三个应用来制作。三端包括H5、小程序和PC管理后台。 上一篇我们介绍了PC管理后台的创建方法,本篇我们介绍一下…...

TrollInstallerX:iOS内核漏洞利用与TrollStore安装技术深度解析
TrollInstallerX:iOS内核漏洞利用与TrollStore安装技术深度解析 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款基于内核漏洞利用的iO…...

6.1 图表选择指南
本章学习目标: 理解数据可视化的核心目的:探索 vs 解释掌握不同分析场景对应的图表类型了解每种图表的优势和局限学会根据数据特征和分析目标选择图表核心能力:不只会画图,更知道为什么画这张图一、为什么要做数据可视化ÿ…...

别再傻傻分不清!用Python+Matplotlib手把手教你画出NBI和WBI的频谱与时频图
用PythonMatplotlib实战解析NBI与WBI的频谱与时频特性 在信号处理领域,窄带干扰(NBI)和宽带干扰(WBI)的区分对雷达系统、通信工程等应用至关重要。理论教材中复杂的数学公式常常让初学者望而生畏,而可视化呈现能瞬间让抽象概念变得直观可感。本文将带您用…...

STATA CLI:我把 Stata 接进了命令行,也接进了 AI 工作流
为什么要做这个工具 我写 stata-cli,不是因为想再造一个 Stata,也不是因为命令行天然高级,而是因为 Stata 明明是很多实证研究者最熟悉的工具,却一直很难进入现代自动化工作流。 做计量、做实证、做政策评估的人都知道,…...


终极指南:使用dmg2img免费快速转换苹果DMG镜像文件
终极指南:使用dmg2img免费快速转换苹果DMG镜像文件 【免费下载链接】dmg2img DMG2IMG allows you to convert a (compressed) Apple Disk Images (imported from http://vu1tur.eu.org/dmg2img). Note: the master branch contains imported code, but lacks bugfix…...
)
告别盲调!用STM32CubeMonitor实时可视化你的MCU变量(附Windows/Mac安装包)
告别盲调!用STM32CubeMonitor实时可视化你的MCU变量(附Windows/Mac安装包) 调试嵌入式系统时,最令人抓狂的莫过于反复修改代码、下载、断点查看变量——这种"盲人摸象"式的开发方式,在调试动态系统ÿ…...

通过Taotoken用量看板清晰掌握团队API成本与模型使用偏好
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken用量看板清晰掌握团队API成本与模型使用偏好 对于项目负责人或技术管理者而言,在引入大模型能力后&#x…...

阴阳师百鬼夜行自动化脚本终极指南:3种智能模式解放你的双手
阴阳师百鬼夜行自动化脚本终极指南:3种智能模式解放你的双手 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 你是否曾在深夜为刷百鬼夜行而手指酸痛?是否…...

告别WSL安装玄学:从0x80072f78到0x800701bc,一次搞懂Windows 11下的完整避坑指南
从0x80072f78到0x800701bc:Windows 11下WSL完整避坑手册 每次在Windows 11上安装WSL时,那些神秘的错误代码是否让你抓狂?0x80072f78、0x800701bc...它们像是一道道密码,阻挡着你进入Linux开发环境的大门。作为长期在Windows和Linu…...