Linux 虚拟机安装 hadoop
目录
1 hadoop下载
2 解压hadoop
3 为 hadoop 文件夹改名
4 给 hadoop 文件夹赋权
5 修改环境变量
6 刷新环境变量
7 在hadoop313目录下创建文件夹data
8 检查文件
9 编辑 ./core-site.xml文件
10 编辑./hadoop-env.sh文件
11 编辑./hdfs-site.xml文件
12 编辑./mapred-site.xml 文件
13 编辑./yarn-site.xml文件
14 编辑./workers文件
15 初始化
16 配置免密登录
17 启动和关闭hadoop
18 测试 hadoop
1 hadoop下载
hadoop3.1.3网盘资源如下:
链接:https://pan.baidu.com/s/1a2fyIUABQ0e-M8-T522BjA?pwd=2jqu 提取码: 2jqu
2 解压hadoop
解压 hadoop 压缩包到/opt/soft 目录中
tar -zxf ./hadoop-3.1.3.tar.gz -C /opt/soft/查看是否已经解压到/opt/soft 目录中
ls /opt/soft
3 为 hadoop 文件夹改名
将hadoop-3.1.3/ 改成hadoop313
mv hadoop-3.1.3/ hadoop313
4 给 hadoop 文件夹赋权
chown -R root:root ./hadoop313/
5 修改环境变量
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
6 刷新环境变量
source /etc/profile
7 在hadoop313目录下创建文件夹data
mkdir ./data8 检查文件
查看/opt/soft/hadoop313/etc/hadoop路径下是否有如下文件

9 编辑 ./core-site.xml文件
vim ./core-site.xml在<configuration></configuration> 中添加如下内容
注意自己的 hostname 是否一致,还有是否做了域名映射
域名映射可以参考Linux安装配置Oracle+plsql安装配置(详细)_sqlplus 安装_超爱慢的博客-CSDN博客
前几步骤
<property><name>fs.defaultFS</name><value>hdfs://kb129:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop313/data</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>io.file.buffer.size</name><value>131073</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>10 编辑./hadoop-env.sh文件
找到被注释的export JAVA_HOME或者直接重新写一个
注意自己的 JAVA_HOME 路径是否与本文一致
vim ./hadoop-env.shexport JAVA_HOME=/opt/soft/jdk18011 编辑./hdfs-site.xml文件
vim ./hdfs-site.xml在<configuration></configuration> 中添加如下内容
<property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/opt/soft/hadoop313/data/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/opt/soft/hadoop313/data/dfs/data</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property>
12 编辑./mapred-site.xml 文件
vim ./mapred-site.xml在<configuration></configuration> 中添加如下内容
注意自己的主机名
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>kb129:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>kb129:19888</value></property><property><name>mapreduce.map.memory.mb</name><value>4096</value></property><property><name>mapreduce.reduce.memory.mb</name><value>4096</value></property><property><name>mapreduce.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/had oop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/ share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/op t/soft/hadoop313/share/hadoop/yarn/lib/*</value></property>13 编辑./yarn-site.xml文件
vim ./yarn-site.xml在<configuration></configuration> 中添加如下内容
注意自己的主机名(hostname)是否一致
<property><name>yarn.resourcemanager.connect.retry-interval.ms</name><value>20000</value></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value></property><property><name>yarn.nodemanager.localizer.address</name><value>kb129:8040</value></property><property><name>yarn.nodemanager.address</name><value>kb129:8050</value></property><property><name>yarn.nodemanager.webapp.address</name><value>kb129:8042</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.local-dirs</name><value>/opt/soft/hadoop313/yarndata/yarn</value></property><property><name>yarn.nodemanager.log-dirs</name><value>/opt/soft/hadoop313/yarndata/log</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
14 编辑./workers文件
vim ./workers将里面的内容替换成你的主机名(hostname)
如:
kb129
15 初始化
hadoop namenode -format看到下面内容即为成功初始化
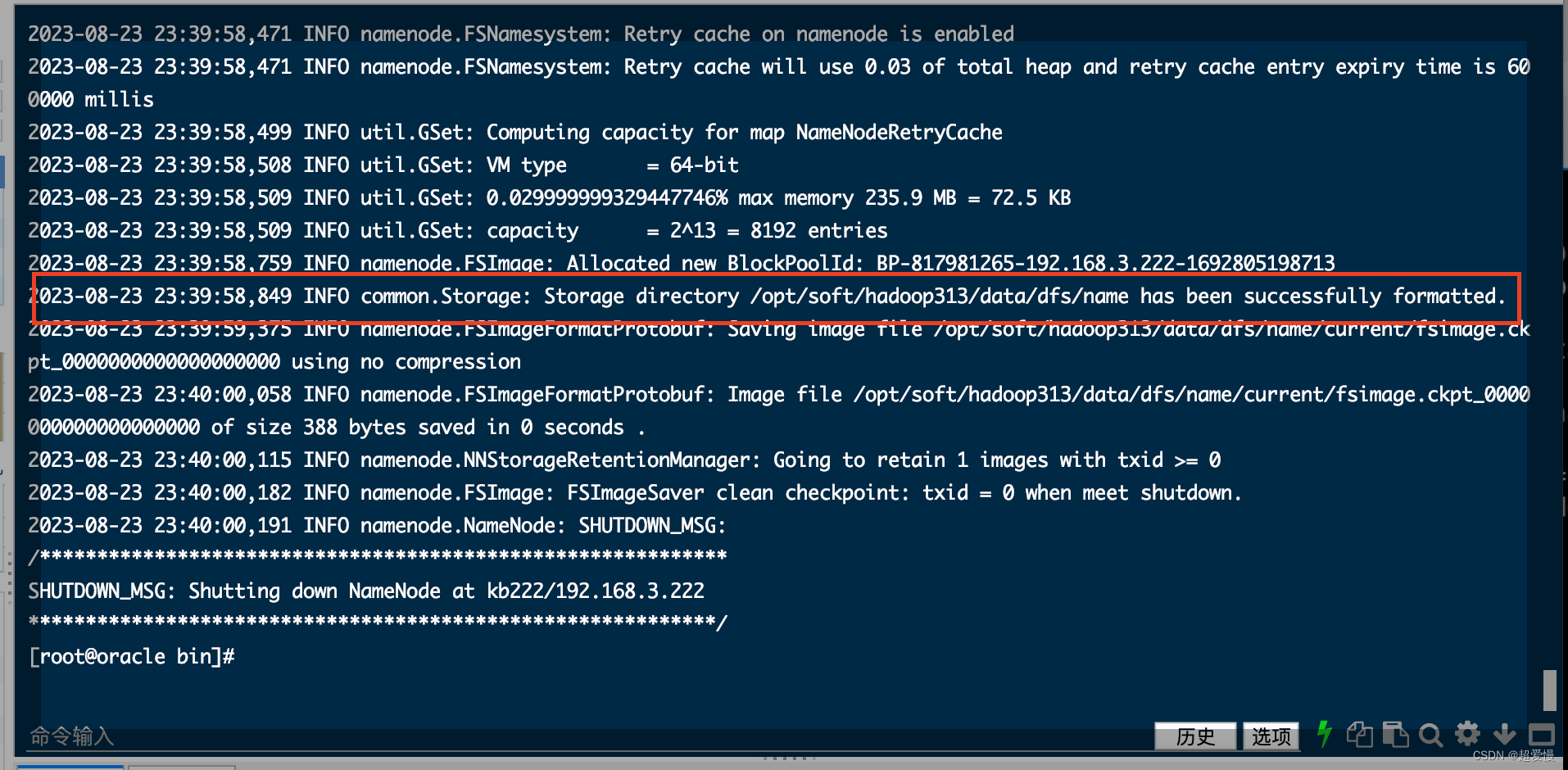
16 配置免密登录
返回家目录
ssh-keygen -t rsa -P ""回车后再回车
会出现以下画面
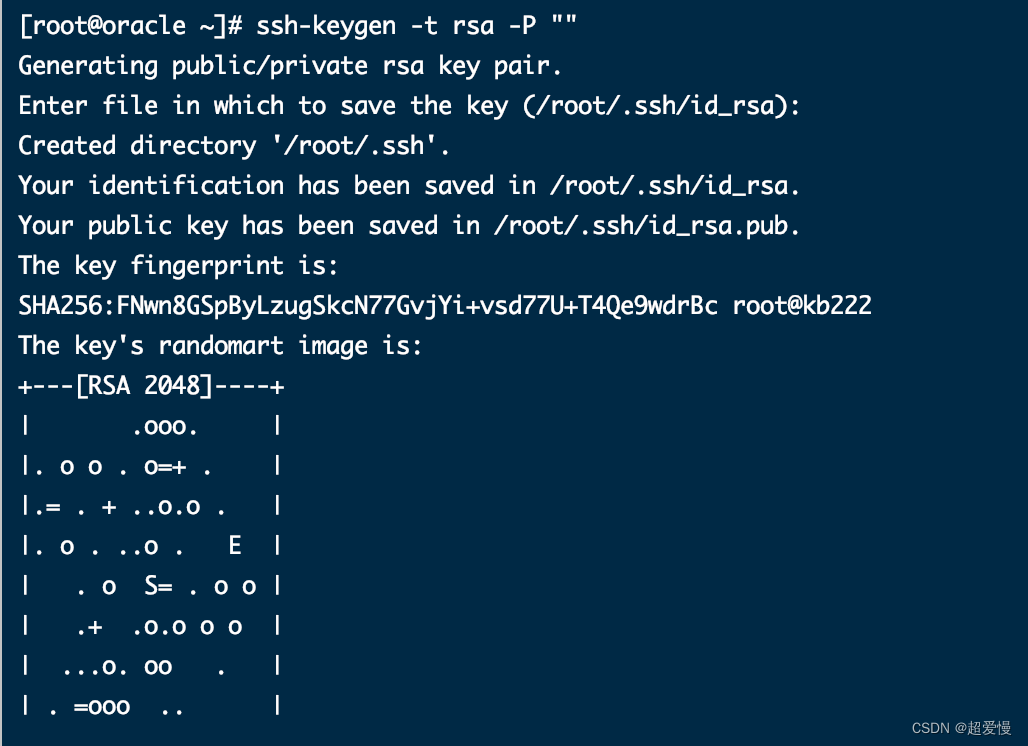
查看是否有.ssh文件
ll -a
配置免密登录
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys测试免密登录(ssh连接自己)
ssh -p 22 root@kb159如果不用输密码就算配置成功
第一次连接会有输入 yes 或 no 的选择
以后连接不会有这样的提示会直接连接成功
连接成功后返回本机输入 exit 回车
17 启动和关闭hadoop
启动 hadoop
start-all.sh 关闭 hadoop
stop-all.sh 18 测试 hadoop
输入 jps 会出现以下六个信息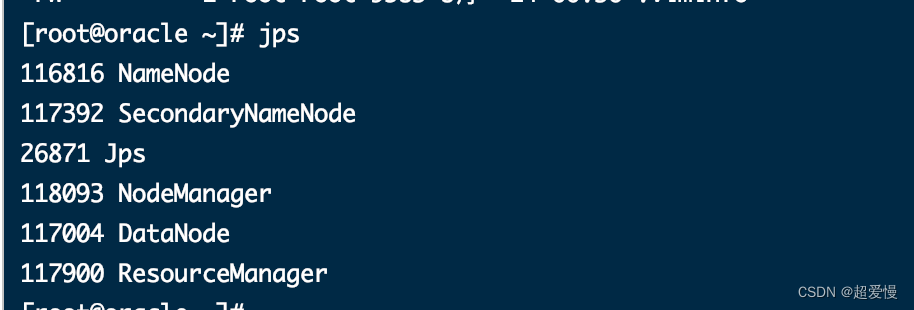
在浏览器输入网址http://192.168.153.129:9870/ 可出现页面(注意替换自己的 IP 地址)

再或者查看 hadoop 版本
hadoop version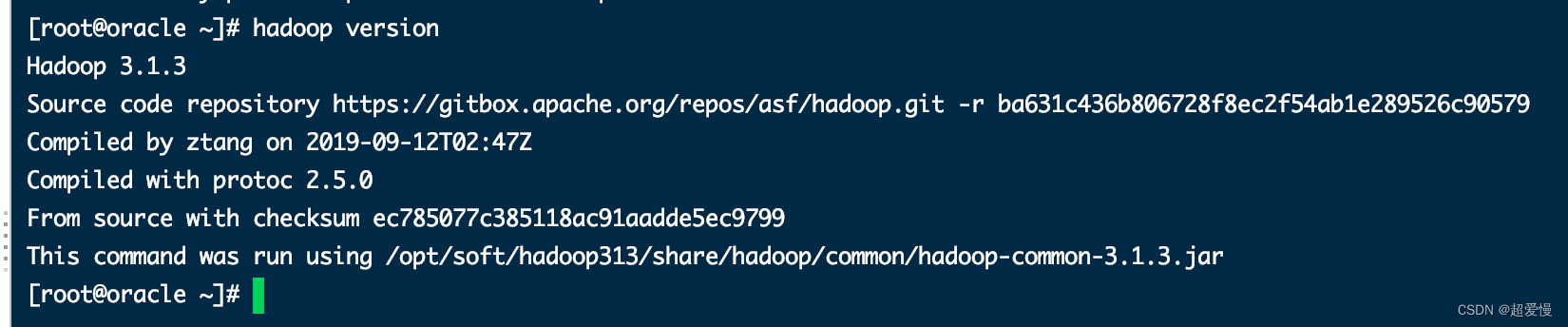
相关文章:
Linux 虚拟机安装 hadoop
目录 1 hadoop下载 2 解压hadoop 3 为 hadoop 文件夹改名 4 给 hadoop 文件夹赋权 5 修改环境变量 6 刷新环境变量 7 在hadoop313目录下创建文件夹data 8 检查文件 9 编辑 ./core-site.xml文件 10 编辑./hadoop-env.sh文件 11 编辑./hdfs-site.xml文件 12 编辑./mapr…...

FxFactory 8 Pro Mac 苹果电脑版 fcpx/ae/motion视觉特效软件包
FxFactory pro for mac是应用在Mac上的fcpx/ae/pr视觉特效插件包,包含了成百上千的视觉效果,打包了很多插件,如调色插件,转场插件,视觉插件,特效插件,文字插件,音频插件,…...

解决问题:如何在 Git 中查看提交历史
可以使用以下命令查看 Git 中的提交历史: git log这将显示当前分支上的所有提交历史。每个提交的输出包括提交哈希(SHA-1 值)、作者、日期和提交注释。 您也可以添加一些选项,以获取更详细的提交历史: --oneline 显示…...
不同规模的测试团队分别适合哪些测试用例管理工具?测试用例管理工具选型指南
随着软件系统规模的持续增大,业务复杂度的持续增加,软件测试的复杂度也随之越来越大。软件测试工作的复杂性主要体现在测试用例的编写、维护、执行和管理方面。而创建易于阅读、维护和管理的测试用例能够显著减轻测试工作的复杂性。 本篇文章将较为系统的…...

服务器遭受攻击,CPU升高,流量升高,你一般如何处理
服务器遭受攻击,CPU升高,流量升高,你一般如何处理? 在什么情况下服务器遭受攻击,会导致CPU升高,流量升高 1.DDoS(分布式拒绝服务攻击):这是一种常见的网络攻击方式&…...

GPT生产实践之定制化翻译
GPT生产实践之定制化翻译 GPT除了能用来聊天以外,其实功能非常强大,但是我们如何把它运用到生产实践中去,为公司带来价值呢?下面一个使用案例–使用gpt做专业领域定制化翻译 思路: 定制化:有些公司词条的…...

SpringMVC入门笔记
一、SpringMVC简介 1. 什么是MVC MVC是一种软件架构的思想,将软件按照模型、视图、控制器来划分 M:Model,模型层,指工程中的JavaBean,作用是处理数据 JavaBean分为两类: 一类称为实体类Bean࿱…...

如何构建多域名HTTPS代理服务器转发
在当今互联网时代,安全可靠的网络访问是至关重要的。本文将介绍如何使用SNI Routing技术来构建多域名HTTPS代理服务器转发,轻松实现多域名的安全访问和数据传输。 SNI代表"Server Name Indication",是TLS协议的扩展,用于…...

【Java 高阶】一文精通 Spring MVC - 数据验证(七)
👉博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO 专家博主 ⛪️ 个人社区&#x…...

木叶飞舞之【机器人ROS2】篇章_第一节、ROS2 humble及cartorgrapher安装
ROS2的humble安装 1、系统配置ubuntu 22.04 假如长期使用ros2,建议是ubuntu系统或者双系统下安装操作,不要在虚拟机中进行。ubuntu系统能用最新的大系统就用最新的,比如22.04。等明年24.04出来可以用24.04 2、humble安装 ros版本选择humb…...
patch操作和分支操作整理)
Git版本管理(02)patch操作和分支操作整理
1 git patch操作 1.1 git diff比较 使用git diff用于显示当前工作区与暂存区或提交历史之间的差异,如果使用它生成patch,则需要使用git apply命令来引入patch 1.2 git patch打包 使用git format-patch生成patch # 打包最近的一个patch: $git format…...

前端需要理解的HTML知识
HTML(超文本标记语言,HyperText Markup Language)不是编程语言,而是定义了网页内容的含义和结构的标记语言。。“超文本”(hypertext)是指连接单个网站内或多个网站间的网页的链接。HTML 使用“标记”&…...

机器学习笔记 - 数据科学中基于 Scikit-Learn、Tensorflow、Pandas 和 Scipy的7种最常用的特征工程技术
一、概述 特征工程描述了制定相关特征的过程,这些特征尽可能准确地描述底层数据科学问题,并使算法能够理解和学习模式。换句话说:您提供的特征可作为将您自己对世界的理解和知识传达给模型的一种方式。 每个特征描述一种信息“片段”。这些部分的总和允许算法得出有关目标变…...

深眸科技创新赋能视觉应用产品,以AI+机器视觉解决行业应用难题
随着工业4.0时代的加速到来,我国工业领域对于机器视觉技术引导的工业自动化和智能化需求持续上涨,国内机器视觉行业进入快速发展黄金期,但需求广泛出现同时也对机器视觉产品的检测能力提出了更高的要求。 传统机器视觉由人工分析图像特征&am…...

2023年国赛 高教社杯数学建模思路 - 案例:异常检测
文章目录 赛题思路一、简介 -- 关于异常检测异常检测监督学习 二、异常检测算法2. 箱线图分析3. 基于距离/密度4. 基于划分思想 建模资料 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 一、简介 – 关于异常…...

【Electron】使用electron-builder打包时下载electron失败或慢的解决方案
问题描述 electron-builder打包时报错信息如下: Building app with electron-builder:• electron-builder version22.14.5 os10.0.19042• description is missed in the package.json appPackageFileE:\h-world\hscmweb-diagrams\dist_electron\bundled\packa…...
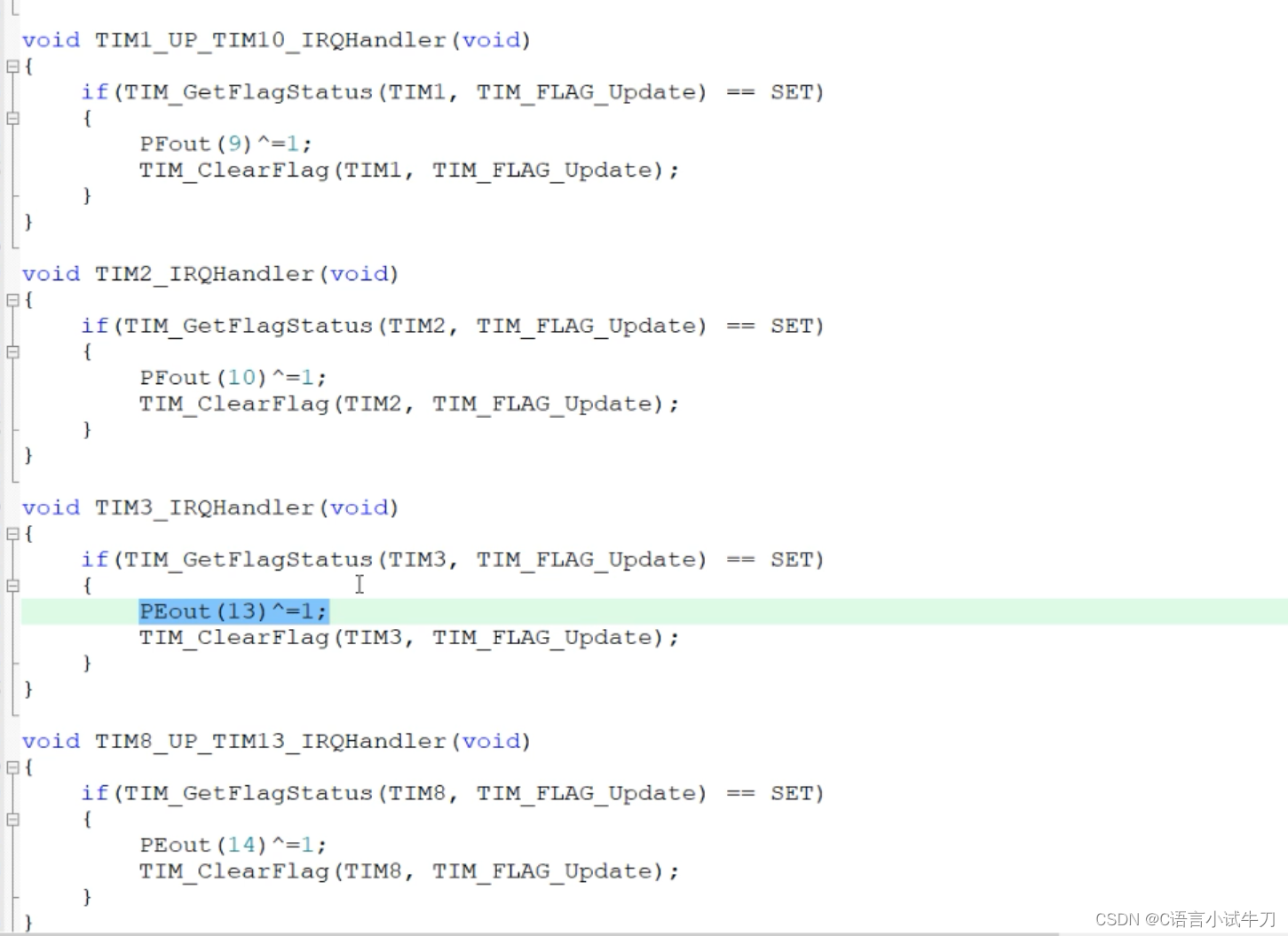
stm32之16.外设定时器——TIM3
----------- 源码 void tim3_init(void) {NVIC_InitTypeDef NVIC_InitStructure;TIM_TimeBaseInitTypeDef TIM_TimeBaseStructure;//使能TIM3的硬件时钟RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM3,ENABLE);//配置TIM3的定时时间TIM_TimeBaseStructure.TIM_Period 10000-1…...

vue3自定义指令防止表单重复提交
可以设置在某个事件段内不允许重复提交;或者点击提交后设置提交flag,flag为true则不能再次提交 <template><div><h1>防止表单重复提交</h1><button click"submitForm" v-throttle>提交</button></di…...

无涯教程-Perl - wait函数
描述 该函数等待子进程终止,返回已故进程的进程ID。进程的退出状态包含在$?中。 语法 以下是此函数的简单语法- wait返回值 如果没有子进程,则此函数返回-1,否则将显示已故进程的进程ID Perl 中的 wait函数 - 无涯教程网无涯教程网提供描述该函数等待子进程终止,返回已故…...
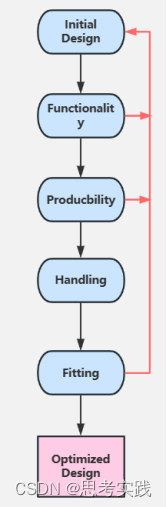
DFMA是一种设计思想与方法论
DFMA(Design for Manufacturing and Assembly)是指在产品设计阶段,充分考虑来自于产品制造和装配的要求,使得机械工程师设计的产品具有很好的可制造性和可装配性,从根本上避免在产品开发后期出现的制造和装配质量问题。…...

Cartographer闭环优化里的‘分支定界’:一个机器人SLAM工程师的实战笔记与避坑心得
Cartographer闭环优化中的分支定界算法:工程实践与性能调优指南 在SLAM(即时定位与地图构建)领域,闭环检测的准确性直接决定了系统长期运行的稳定性。作为Cartographer算法的核心组件之一,分支定界(Branch …...

开源情报工具Openeir:自动化资产发现与关联分析实战指南
1. 项目概述:一个开源情报(OSINT)工具的诞生与使命 在信息爆炸的时代,数据本身不再是稀缺品,如何从海量、异构、碎片化的公开信息中,精准、高效地提取出有价值的情报,才是真正的挑战。无论是安全…...

打破高频、高速四种材料混压
打破高频、高速四种材料混压,铸就PCB行业硬核实力。在航空航天领域,每一次技术的突破都意味着对材料与工艺的极致追求。今天,我们要聊的这款产品,堪称多材料混压天花板,——16层、四种材料混压、三次压合、板厚5.0mm、…...

深入解析epoll ET模式与守护进程
引言在前面的文章中,我们学习了 epoll 的基础用法和 LT 模式。本文将深入讲解两个重要主题:epoll 的 ET 模式:边缘触发模式的编程要点与完整实现守护进程:Linux 后台服务进程的原理与编写规范ET 模式是 epoll 高性能的关键&#x…...

飞书文档批量导出工具:25分钟搞定700+文档的迁移难题
飞书文档批量导出工具:25分钟搞定700文档的迁移难题 【免费下载链接】feishu-doc-export 飞书文档导出服务 项目地址: https://gitcode.com/gh_mirrors/fe/feishu-doc-export 当企业需要切换办公平台或进行数据备份时,飞书文档的批量迁移常常成为…...
)
华为eNSP模拟器实战:用VRRP+MSTP给公司网络做个高可用冗余(附完整配置命令)
华为eNSP企业级网络高可用架构实战:VRRP与MSTP深度协同设计 当一家中型企业的终端规模突破500台时,网络架构的脆弱性往往会突然暴露——某个交换机的意外宕机可能导致整个部门断网,核心链路的拥塞会让关键业务卡顿不已。这时仅靠基础的STP和…...

实测Taotoken平台API调用稳定性与延迟体感观察记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken平台API调用稳定性与延迟体感观察记录 在将大模型能力集成到生产应用时,服务的稳定性和响应延迟是开发者关…...

Token Plan 套餐怎么选,Taotoken 预付费模式下的成本控制实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Token Plan 套餐怎么选,Taotoken 预付费模式下的成本控制实践 对于有稳定大模型调用需求的开发者或团队而言࿰…...

IP核验证责任共担模型:从授权方到被授权方的实践策略
1. IP核验证的责任边界:一场持续多年的行业对话在SoC设计领域,IP核的集成与验证从来都不是一个轻松的话题。随着芯片设计复杂度的指数级增长,一个现代SoC中可能集成了数十甚至上百个来自不同供应商的IP核,从处理器、内存控制器到各…...

Gmail只读命令行工具gcli:云端自动化邮件查询与SSH隧道授权方案
1. 项目概述:一个专为自动化场景设计的Gmail只读命令行工具 如果你和我一样,经常需要在没有图形界面的云服务器上处理邮件查询任务,那你一定对Gmail API的授权流程深恶痛绝。传统的OAuth流程要求你在浏览器里点来点去,但服务器上哪…...