Elasticsearch也能“分库分表“,rollover实现自动分索引
一、自动创建新索引的方法
MySQL的分库分表大家是非常熟悉的,在Elasticserach中有存在类似的场景需求。为了不让单个索引太过于庞大,从而引发性能变差等问题,我们常常有根据索引大小、时间等创建新索引的需求,解决方案一般有两个:
1、开发一个定时任务调用Elasticsearch索引API创建新索引,应用程序兼容新索引的命名规则;
2、使用Elasticsearch rollover功能。
第二种Elasticsearch自带的功能更加简单方便,无需定时任务。我们今天的主角就是Elasticsearch rollover功能。

二、使用rollover自动创建新索引
2.1、rollover API介绍
Elasticsearch rollover是Elasticsearch中一项用于管理索引的功能,它可以自动创建新的索引并将旧的索引移动到另一个位置,从而使历史数据不受影响,同时可以为新的索引设置不同的设置。它还可以根据特定的时间间隔(比如每天)来滚动索引,这可以有效地降低索引大小,提高搜索性能。
rollover的原理是先创建一个带别名的索引,然后设定一定的规则(例如满足一定的时间范围的条件),当满足该设定规则的时候,Elasticsearch会自动建立新的索引,别名也自动切换指向新的索引,这样相当于在物理层面自动建立了索引的分区功能,当查询数据落在特定时间内时,会到一个相对小的索引中查询,相对所有数据都存储在一个大索引的情况,可以有效提升查询效率。
rollover API会为data stream或者索引别名创建一个新的索引。(在Elasticsearch 7.9之前,一般使用索引别名的方式来管理时间序列数据,在Elasticsearch之后data stream取代了这个功能,它维护更加简单,并自动与数据层集成)。
rollover API的效果依据待滚动的索引别名的情况不同而有不同的表现:
- 如果一个索引别名对应了多个索引,其中一个一定是写索引,rollover创建出新索引的时候会设置
is_write_index为true,并且上一个被滚动的索引的is_write_index设置为false。 - 如果待滚动的索引别名对应的只有一个索引,那么在创建新的索引的同时,会删除原索引。
使用rollover API的时候如果指定新的索引的名称,并且原索引以“-”结束并且以数字结尾,那么新索引将会沿用名称并且将数字增加,例如原索引是my-index-000001那么新索引会是my-index-000002。
如果对时间序列数据使用索引别名,则可以在索引名称中使用日期来跟踪滚动日期。例如,可以创建一个别名来指向名为<my-index-{now/d}-000001>的索引,如果在2099年5月6日创建索引,则索引的名称为my-index-2099.05.06-000001。如果在2099年5月7日滚动别名,则新索引的名称为my-index-2099.05.07-000002。
rollover API的格式如下:
POST /<rollover-target>/_rollover/POST /<rollover-target>/_rollover/<target-index>
rollover API也支持Query Parameters和Request Body,其中Query parameters支持wait_for_active_shards、master_timeout、timeout和dry_run,特别说一下dry_run,如果将dry_run设置为true,那么这次请求不会真的执行,但是会检查当前索引是否满足conditions指定的条件,这对于提前进行测试非常有用。
Request Body支持aliases、mappings和settings(这三个参数只支持索引,不支持data stream)和conditions。
特别展开讲一下conditions。这是一个可选参数,如果指定了conditions,则需要在满足conditions指定的一个或者多个条件的情况下才会执行滚动,如果没有指定则无条件滚动,如果需要自动滚动,可以使用ILM Rollover。
conditions支持的属性有:
max_age
从索引建立开始算起的时间周期,支持Time Units,如7d、4h、30m、60s、1000ms、10000micros、500000nanos。max_docs
索引主分片的数量达到设定的值;max_size
所有主分片的大小之和达到了设定值,可以通过_cat indices API进行查询,其中pri.store.size的值就是目标值。max_primary_shard_size
所有主分片中存在主分片的大小达到了设定值,可以通过_cat shards API查看分片的大小,store值代表每个分片的大小,prirep代表了分片是primary分片还是replica分片。max_primary_shard_docs
所有主分片中存在主分片的文档大小达到了设定值,可以通过_cat shards API查询,其中的docs字段代表了分片上文档数量的大小。
2.2、rollover一个索引
- 首先创建一个索引并且设置为write index。
# PUT <my-index-{now/d}-000001>
curl -X PUT "localhost:9200/%3Cmy-index-%7Bnow%2Fd%7D-000001%3E?pretty" -H 'Content-Type: application/json' -d'
{"aliases": {"my-alias": {"is_write_index": true}}
}
'
-
执行rollover API
如下所示,代表间隔7天、文档数量最多达到100000、主分片大小达到50gb、主分片最大文档数量达到20000,这些条件中哪个先匹配则都会自动切换到新索引。
curl -X POST "localhost:9200/my-alias/_rollover?pretty" -H 'Content-Type: application/json' -d'
{"conditions": {"max_age": "7d","max_docs": 100000,"max_primary_shard_size": "50gb","max_primary_shard_docs": "20000"}
}
'
如果别名的索引名称使用日期数学表达式,并且按定期间隔滚动索引,则可以使用日期数学表达式来缩小搜索范围。例如,下面的搜索目标是最近三天内创建的索引。
# GET /<my-index-{now/d}-*>,<my-index-{now/d-1d}-*>,<my-index-{now/d-2d}-*>/_search
curl -X GET "localhost:9200/%3Cmy-index-%7Bnow%2Fd%7D-*%3E%2C%3Cmy-index-%7Bnow%2Fd-1d%7D-*%3E%2C%3Cmy-index-%7Bnow%2Fd-2d%7D-*%3E/_search?pretty"
2.3、rollover data stream
rollover不仅可以针对index,也可以针对data stream。data stream是 Elastic Stack 7.9 的一个新的功能。Data stream 使你可以跨多个索引存储只追加数据的时间序列数据,同时为请求提供唯一的一个命名资源,搜索请求提交给data stream以后,data stream会自动将请求路由到其后备的索引中。
rollover data stream与index类似,如下:
curl -X POST "localhost:9200/my-data-stream/_rollover?pretty" -H 'Content-Type: application/json' -d'
{"conditions": {"max_age": "7d","max_docs": 100000,"max_primary_shard_size": "50gb","max_primary_shard_docs": "20000"}
}
'
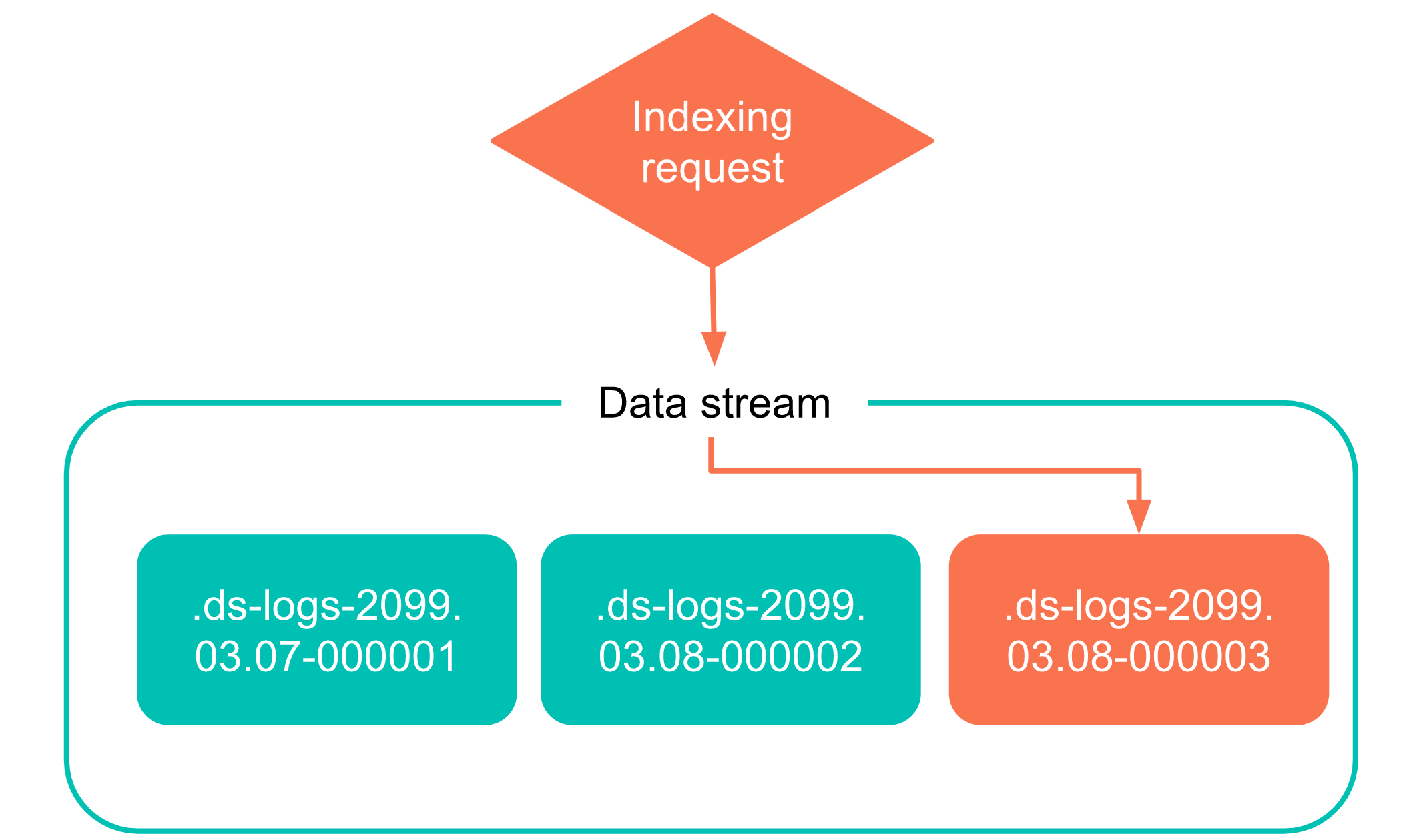
响应信息如下,当max_docs数量达到了100000,自动会创建一个new_index,命令为".ds-my-data-stream-2099.05.07-000002"。
{"acknowledged": true,"shards_acknowledged": true,"old_index": ".ds-my-data-stream-2099.05.06-000001","new_index": ".ds-my-data-stream-2099.05.07-000002","rolled_over": true,"dry_run": false,"conditions": {"[max_age: 7d]": false,"[max_docs: 100000]": true,"[max_primary_shard_size: 50gb]": false,"[max_primary_shard_docs: 2000]": false}
}
rollover是一个非常实用的功能,特别是对于随着时间推移,索引数据量会快速增长的场景。不过也需要注意conditions要设置合理,否则容易产生太多的小索引,Elasticsearch集群对于索引的维护成本也是比较高的,太多的小索引会严重影响集群的性能。
你所在团队是否有遇到过需要自动分索引的场景,又是如何处理的呢?欢迎和我分享交流。
相关文章:
Elasticsearch也能“分库分表“,rollover实现自动分索引
一、自动创建新索引的方法 MySQL的分库分表大家是非常熟悉的,在Elasticserach中有存在类似的场景需求。为了不让单个索引太过于庞大,从而引发性能变差等问题,我们常常有根据索引大小、时间等创建新索引的需求,解决方案一般有两个…...

6 大经典机器学习数据集,3w+ 用户票选得出,建议收藏
内容一览:本期汇总了超神经下载排名众多的 6 个数据集,涵盖图像识别、机器翻译、遥感影像等领域。这些数据集质量高、数据量大,经历人气认证值得收藏码住。 关键词:数据集 机器翻译 机器视觉 数据集是机器学习模型训练的基础&…...

Logview下载
Logview下载 之前一直用的NotePad 后来偶尔的看到作者有发布不当言论 就卸载了又去下载了NotePad– 但是,其实不管是 还是 – 打开大一些的文件都会卡死 所以就搜了这个logview 用起来还不错,目前我这再大的文件 这个软件都是秒打开 但是也会有一点点小…...
macos 下载 macOS 系统安装程序及安装U盘制作方法
01 下载 macOS 系统安装程序的方法 本文来自: https://discussionschinese.apple.com/docs/DOC-250004259 简介 Mac 用户时不时会需要下载 macOS 的安装程序,目的不同,或者升级或者降级,或者研究或者收藏。为了方便不同用户,除…...
c++动态内存分布以及和C语言的比较
文章目录 前言一.c/c内存分布 C语言的动态内存管理方式 C内存管理方式 operator new和operator delete函数 malloc/free和new/delete的区别 定位new 内存泄漏的危害总结前言 c是在c的基础上开发出来的,所以关于内存管理这一方面是兼容c的&…...

软考高级信息系统项目管理师系列之三十一:项目变更管理
软考高级信息系统项目管理师系列之三十一:项目变更管理 一、项目变更管理内容二、项目变更管理基本概念1.项目变更管理定义2.项目变更产生的原因3.项目变更的分类三、项目变更管理的原则和工作流程1.项目变更管理的原则2.变更管理的组织机构3.变更管理的工作程序四、项目变更管…...
【Vue3源码】第二章 effect功能的完善补充
【Vue3源码】第二章 effect功能的完善补充 前言 上一章节我们实现了effect函数的功能stop和onstop,这次来优化下stop功能。 优化stop功能 之前我们的单元测试中,stop已经可以成功停止了响应式更新(清空了收集到的dep依赖) st…...
)
CHAPTER 2 Web Server - apache(httpd)
Web Server - httpd2.1 http2.1.1 协议版本2.1.2 http报文2.1.3 web资源(web resource)2.1.4 一次完整的http请求处理过程2.1.5 接收请求的模型2.2 httpd配置2.2.1 MPM(多进程处理模块)1. 工作模式2. 切换MPM3. MPM参数配置2.2.2 主配置文件1. 基本配置2. 站点访问控制常见机制…...
【Vagrant】下载安装与基本操作
文章目录概述软件安装安装VirtualBox安装Vagrant配置环境用Vagrant创建一个VMVagrantfile文件配置常用命令概述 Vagrant是一个创建虚拟机的技术,是用来创建和管理虚拟机的工具,本身自己并不能创建管理虚拟机。创建和管理虚拟机必须依赖于其他的虚拟化技…...
常用类(五)System类
(1)System类常见方法和案例: (1)exit:退出当前程序 我们设计的代码如下所示: package com.ypl.System_;public class System_ {public static void main(String[] args) {//exit: 退出当前程序System.out.println("ok1"…...

Navicat Premium 安装 注册
Navicat Premium 一.Navicat Premium的安装 1.暂时关闭windows的病毒与威胁防护弄完再开,之后安装打开过程中弹窗所有警告全部允许,不然会被拦住 2.下载安装包,解压 链接:https://pan.baidu.com/s/1X24VPC4xq586YdsnasE5JA?pwdu4vi 提取码…...
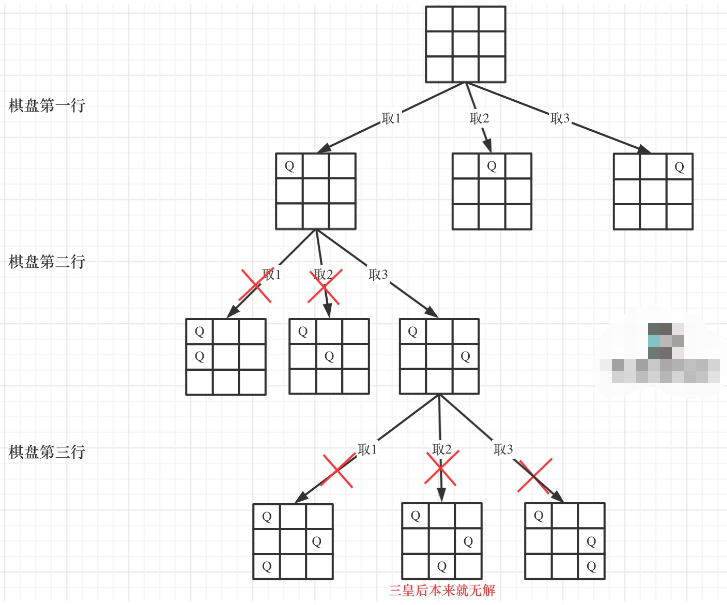
回溯算法总结
首先回溯算法本身还是一个纯暴力的算法,只是回溯过程可能比较抽象,导致大家总是感觉看到的相关题目做的不是很顺畅,回溯算法一般来说解决的题目有以下几类:组合问题:lq77、lq17、lq39、lq40、lq216、切割问题ÿ…...
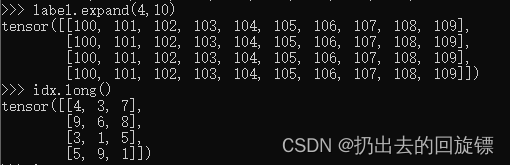
ccc-pytorch-基础操作(2)
文章目录1.类型判断isinstance2.Dimension实例3.Tensor常用操作4.索引和切片5.Tensor维度变换6.Broadcast自动扩展7.合并与分割8.基本运算9.统计属性10.高阶OP大伙都这么聪明,注释就只写最关键的咯1.类型判断isinstance 常见类型如下: a torch.randn(…...

独居老人一键式报警器
盾王居家养老一键式报警系统,居家养老一键式报警设备 ,一键通紧急呼救设备,一键通紧急呼救系统,一键通紧急呼救器 ,一键通紧急呼救终端,一键通紧急呼救主机终端产品简介: 老人呼叫系统主要应用于…...

软考案例分析题精选
试题一:阅读下列说明,回答问题1至问题4,将解答填入答题纸的对应栏内。某公司中标了一个软件开发项目,项目经理根据以往的经验估算了开发过程中各项任务需要的工期及预算成本,如下表所示:任务紧前任务工期PV…...

基于SpringBoot+vue的无偿献血后台管理系统
基于SpringBootvue的无偿献血后台管理系统 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背…...
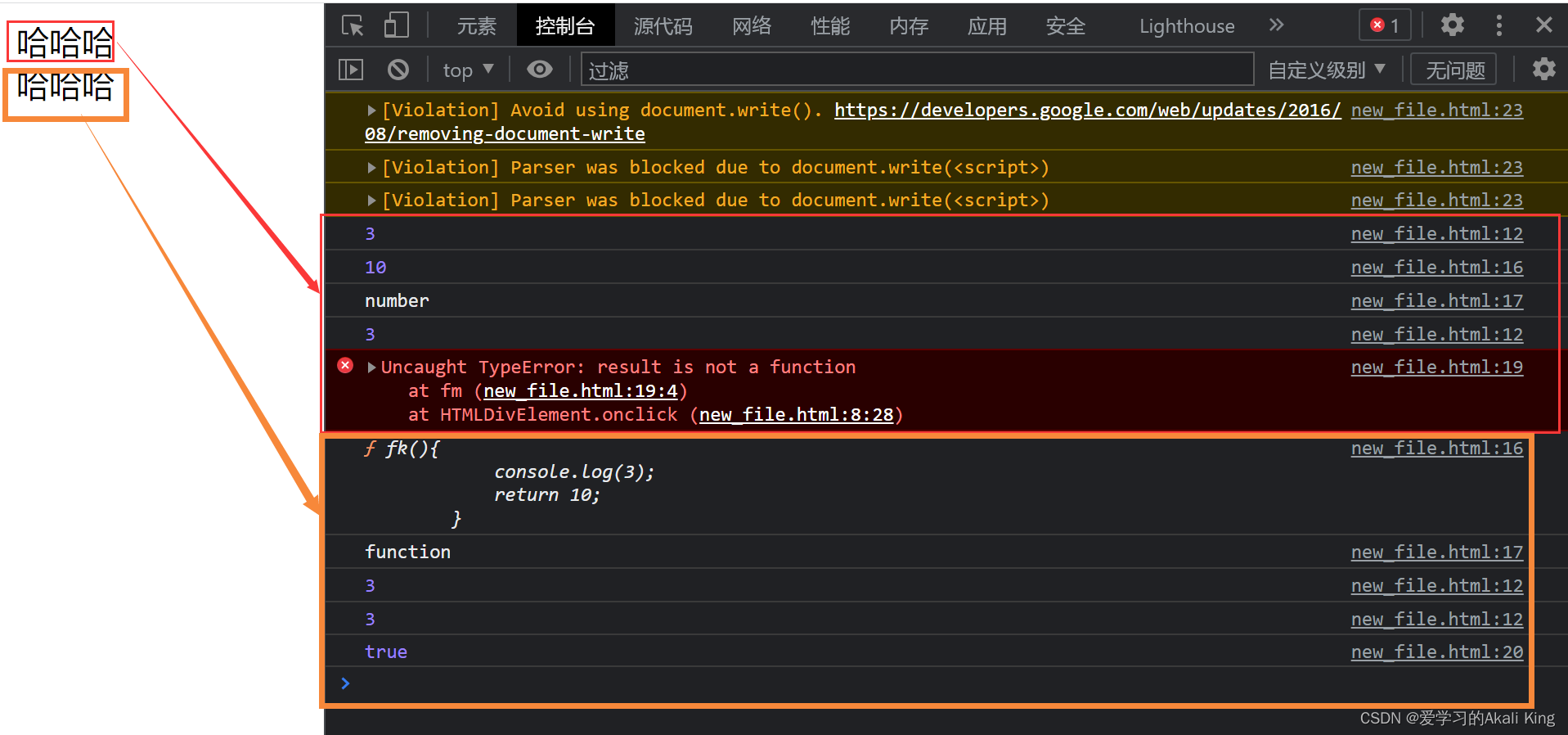
详解js在事件中,如何传递复杂数据类型(数组,对象,函数)
文章目录 前言一、何谓预编译,变量提升?二、复杂数据类型的传递 1.数组2.对象3.函数总结前言 在JavaScript这门编程语言学习中,如何传参,什么是变量提升,js代码预编译等等。要想成为一名优秀的js高手,这些内…...

高并发架构 第一章大型网站数据演化——核心解释与说明。大型网站技术架构——核心原理与案例分析
大型网站架构烟花发展历程1.1.1初始阶段的网站构架1.1.2应用服务和数据服务分离1.1.3使用缓存改善网络性能1.1.4使用应用服务器集群改善网站的并发处理能力1.1.5数据库读写分离1.1.6使用反向代理和cdn加速网站相应1.1.1初始阶段的网站构架 大型网站都是由小型网站一步步发展而…...

VPP接口INPUT节点运行数据
在设置virtio接口接收/发送队列函数的最后,更新接口的运行数据。 void virtio_vring_set_rx_queues (vlib_main_t *vm, virtio_if_t *vif) { ...vnet_hw_if_update_runtime_data (vnm, vif->hw_if_index); } void virtio_vring_set_tx_queues (vlib_main_t *vm,…...

RabbitMQ学习(九):延迟队列
一、延迟队列概念延时队列中,队列内部是有序的,最重要的特性就体现在它的延时属性上,延时队列中的元素是希望 在指定时间到了以后或之前取出和处理。简单来说,延时队列就是用来存放需要在指定时间内被处理的 元素的队列。其实延迟…...

浏览器超能力开发指南:解锁Greasy Fork用户脚本的实战手册
浏览器超能力开发指南:解锁Greasy Fork用户脚本的实战手册 【免费下载链接】greasyfork An online repository of user scripts. 项目地址: https://gitcode.com/gh_mirrors/gr/greasyfork 在数字化工作流中,我们每天都在重复着大量机械操作——手…...

3步完成B站视频转文字:免费开源工具bili2text完整指南
3步完成B站视频转文字:免费开源工具bili2text完整指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为手动记录B站视频内容而烦恼吗&#x…...

OpenClaw多通道管理:飞书+钉钉同时接入Phi-3-mini-128k-instruct
OpenClaw多通道管理:飞书钉钉同时接入Phi-3-mini-128k-instruct 1. 为什么需要多通道管理 上周我在整理团队周报时遇到了一个典型问题:部分同事习惯在飞书群里提交需求,另一些则偏好通过钉钉直接我。这种多渠道沟通导致任务分散,…...

FireRedASR-AED-L效果实测:微信语音转文字→长语音断句与上下文连贯性
FireRedASR-AED-L效果实测:微信语音转文字→长语音断句与上下文连贯性 你是不是也遇到过这种情况?微信里收到一段长达5分钟的语音消息,点开听吧,太费时间;不听吧,又怕错过重要信息。更让人头疼的是&#x…...

从线性模型到梯度下降:手把手拆解回归任务核心流程
1. 回归任务:从预测房价开始理解 第一次接触回归任务时,我盯着"预测连续值"这个定义看了半天也没明白。直到用房价预测的例子才恍然大悟——这不就是我们平时看房时,中介根据面积、地段、房龄估算价格的过程吗?回归任务…...

Qwen3-ASR-1.7B效果展示:中英混合技术文档讲解音频精准转写案例
Qwen3-ASR-1.7B效果展示:中英混合技术文档讲解音频精准转写案例 专业级语音识别模型在实际技术场景中的表现究竟如何?本文通过真实的中英混合技术文档讲解音频测试,带你全面了解Qwen3-ASR-1.7B的精准转写能力。 1. 测试背景与场景选择 在技术…...

OpenClaw+千问3.5-9B监控方案:网站异常自动检测与告警
OpenClaw千问3.5-9B监控方案:网站异常自动检测与告警 1. 为什么需要轻量级网站监控 去年我的个人博客遭遇了一次持续6小时的宕机,直到读者发邮件反馈才发现问题。传统监控工具如UptimeRobot虽然能检测HTTP状态,但无法识别内容篡改或样式异常…...

Jenkins Pipeline 脚本踩坑记:我是如何被两种语法折磨并最终选择的
最近在折腾公司的 CI/CD 流水线,想把原来那套老掉牙的构建脚本升级一下。本以为 Jenkins Pipeline 挺简单的,结果一上手就懵了——竟然有两种写法!这不是逼死选择困难症吗? 我当时的内心OS:这玩意儿就像去饭店点菜&am…...

别再死磕公式了!用OpenCV StereoBM/SGBM实战双目测距,从标定到3D点云一气呵成
双目视觉实战:从标定到3D点云的完整OpenCV实现 去年夏天,我尝试用两个普通的USB摄像头搭建了一个简易的深度感知系统。最初以为只要简单调用几个OpenCV函数就能搞定,结果在标定环节就卡了整整两周——棋盘格图像拍了几十张,参数却…...

基于R语言的自动数据收集:网络抓取和文本挖掘实用指南【1.8】
3.6 JSON文档示例在本节,我们要熟悉数据交换标准JSON的优点。这个首字母缩写(发音是“Jason”)代表JavaScript对象标记(JavaScript Object Notation)。JSON的设计和XML如出一辙,两者通常都是用来存储和交换…...