使用 DPO 微调 Llama 2
简介
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。然而,它也给 NLP 引入了一些 RL 相关的复杂性: 既要构建一个好的奖励函数,并训练一个模型用以估计每个状态的价值 (value); 又要注意最终生成的 LLM 不能与原始模型相差太远,如果太远的话会使得模型容易产生乱码而非有意义的文本。该过程非常复杂,涉及到许多复杂的组件,而这些组件本身在训练过程中又是动态变化的,因此把它们料理好并不容易。
Rafailov、Sharma、Mitchell 等人最近发表了一篇论文 Direct Preference Optimization,论文提出将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直接优化的目标,这一做法大大简化了 LLM 的提纯过程。
本文介绍了直接偏好优化 (Direct Preference Optimization,DPO) 法,该方法现已集成至 TRL 库 中。同时,我们还展示了如何在 stack-exchange preference 数据集上微调最新的 Llama v2 7B 模型, stack-exchange preference 数据集中包含了各个 stack-exchange 门户上的各种问题及其排序后的回答。
DPO 与 PPO
在通过 RL 优化人类衍生偏好时,一直以来的传统做法是使用一个辅助奖励模型来微调目标模型,以通过 RL 机制最大化目标模型所能获得的奖励。直观上,我们使用奖励模型向待优化模型提供反馈,以促使它多生成高奖励输出,少生成低奖励输出。同时,我们使用冻结的参考模型来确保输出偏差不会太大,且继续保持输出的多样性。这通常需要在目标函数设计时,除了奖励最大化目标外再添加一个相对于参考模型的 KL 惩罚项,这样做有助于防止模型学习作弊或钻营奖励模型。
DPO 绕过了建模奖励函数这一步,这源于一个关键洞见: 从奖励函数到最优 RL 策略的分析映射。这个映射直观地度量了给定奖励函数与给定偏好数据的匹配程度。有了它,作者就可与将基于奖励和参考模型的 RL 损失直接转换为仅基于参考模型的损失,从而直接在偏好数据上优化语言模型!因此,DPO 从寻找最小化 RLHF 损失的最佳方案开始,通过改变参量的方式推导出一个 仅需 参考模型的损失!
有了它,我们可以直接优化该似然目标,而不需要奖励模型或繁琐的强化学习优化过程。
如何使用 TRL 进行训练
如前所述,一个典型的 RLHF 流水线通常包含以下几个环节:
有监督微调 (supervised fine-tuning,SFT)
用偏好标签标注数据
基于偏好数据训练奖励模型
RL 优化
TRL 库包含了所有这些环节所需的工具程序。而 DPO 训练直接消灭了奖励建模和 RL 这两个环节 (环节 3 和 4),直接根据标注好的偏好数据优化 DPO 目标。
使用 DPO,我们仍然需要执行环节 1,但我们仅需在 TRL 中向 DPOTrainer 提供环节 2 准备好的偏好数据,而不再需要环节 3 和 4。标注好的偏好数据需要遵循特定的格式,它是一个含有以下 3 个键的字典:
prompt: 即推理时输入给模型的提示chosen: 即针对给定提示的较优回答rejected: 即针对给定提示的较劣回答或非给定提示的回答
例如,对于 stack-exchange preference 数据集,我们可以通过以下工具函数将数据集中的样本映射至上述字典格式并删除所有原始列:
def return_prompt_and_responses(samples) -> Dict[str, str, str]:return {"prompt": ["Question: " + question + "\n\nAnswer: "for question in samples["question"]],"chosen": samples["response_j"], # rated better than k"rejected": samples["response_k"], # rated worse than j}dataset = load_dataset("lvwerra/stack-exchange-paired",split="train",data_dir="data/rl"
)
original_columns = dataset.column_namesdataset.map(return_prompt_and_responses,batched=True,remove_columns=original_columns
)一旦有了排序数据集,DPO 损失其实本质上就是一种有监督损失,其经由参考模型获得隐式奖励。因此,从上层来看,DPOTrainer 需要我们输入待优化的基础模型以及参考模型:
dpo_trainer = DPOTrainer(model, # 经 SFT 的基础模型model_ref, # 一般为经 SFT 的基础模型的一个拷贝beta=0.1, # DPO 的温度超参train_dataset=dataset, # 上文准备好的数据集tokenizer=tokenizer, # 分词器args=training_args, # 训练参数,如: batch size, 学习率等
)其中,超参 beta 是 DPO 损失的温度,通常在 0.1 到 0.5 之间。它控制了我们对参考模型的关注程度,beta 越小,我们就越忽略参考模型。对训练器初始化后,我们就可以简单调用以下方法,使用给定的 training_args 在给定数据集上进行训练了:
dpo_trainer.train()基于 Llama v2 进行实验
在 TRL 中实现 DPO 训练器的好处是,人们可以利用 TRL 及其依赖库 (如 Peft 和 Accelerate) 中已有的 LLM 相关功能。有了这些库,我们甚至可以使用 bitsandbytes 库提供的 QLoRA 技术 来训练 Llama v2 模型。
有监督微调
如上文所述,我们先用 TRL 的 SFTTrainer 在 SFT 数据子集上使用 QLoRA 对 7B Llama v2 模型进行有监督微调:
# load the base model in 4-bit quantization
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16,
)base_model = AutoModelForCausalLM.from_pretrained(script_args.model_name, # "meta-llama/Llama-2-7b-hf"quantization_config=bnb_config,device_map={"": 0},trust_remote_code=True,use_auth_token=True,
)
base_model.config.use_cache = False# add LoRA layers on top of the quantized base model
peft_config = LoraConfig(r=script_args.lora_r,lora_alpha=script_args.lora_alpha,lora_dropout=script_args.lora_dropout,target_modules=["q_proj", "v_proj"],bias="none",task_type="CAUSAL_LM",
)
...
trainer = SFTTrainer(model=base_model,train_dataset=train_dataset,eval_dataset=eval_dataset,peft_config=peft_config,packing=True,max_seq_length=None,tokenizer=tokenizer,args=training_args, # HF Trainer arguments
)
trainer.train()DPO 训练
SFT 结束后,我们保存好生成的模型。接着,我们继续进行 DPO 训练,我们把 SFT 生成的模型作为 DPO 的基础模型和参考模型,并在上文生成的 stack-exchange preference 数据上,以 DPO 为目标函数训练模型。我们选择对模型进行 LoRa 微调,因此我们使用 Peft 的 AutoPeftModelForCausalLM 函数加载模型:
model = AutoPeftModelForCausalLM.from_pretrained(script_args.model_name_or_path, # location of saved SFT modellow_cpu_mem_usage=True,torch_dtype=torch.float16,load_in_4bit=True,is_trainable=True,
)
model_ref = AutoPeftModelForCausalLM.from_pretrained(script_args.model_name_or_path, # same model as the main onelow_cpu_mem_usage=True,torch_dtype=torch.float16,load_in_4bit=True,
)
...
dpo_trainer = DPOTrainer(model,model_ref,args=training_args,beta=script_args.beta,train_dataset=train_dataset,eval_dataset=eval_dataset,tokenizer=tokenizer,peft_config=peft_config,
)
dpo_trainer.train()
dpo_trainer.save_model()可以看出,我们以 4 比特的方式加载模型,然后通过 peft_config 参数选择 QLora 方法对其进行训练。训练器还会用评估数据集评估训练进度,并报告一些关键指标,例如可以选择通过 WandB 记录并显示隐式奖励。最后,我们可以将训练好的模型推送到 HuggingFace Hub。
总结
SFT 和 DPO 训练脚本的完整源代码可在该目录 examples/stack_llama_2 处找到,训好的已合并模型也已上传至 HF Hub (见 此处)。
你可以在 这儿 找到我们的模型在训练过程的 WandB 日志,其中包含了 DPOTrainer 在训练和评估期间记录下来的以下奖励指标:
rewards/chosen (较优回答的奖励): 针对较优回答,策略模型与参考模型的对数概率二者之差的均值,按beta缩放。rewards/rejected (较劣回答的奖励): 针对较劣回答,策略模型与参考模型的对数概率二者之差的均值,按beta缩放。rewards/accuracy (奖励准确率): 较优回答的奖励大于相应较劣回答的奖励的频率的均值rewards/margins (奖励余裕值): 较优回答的奖励与相应较劣回答的奖励二者之差的均值。
直观上讲,在训练过程中,我们希望余裕值增加并且准确率达到 1.0,换句话说,较优回答的奖励高于较劣回答的奖励 (或余裕值大于零)。随后,我们还可以在评估数据集上计算这些指标。
我们希望我们代码的发布可以降低读者的入门门槛,让大家可以在自己的数据集上尝试这种大语言模型对齐方法,我们迫不及待地想看到你会用它做哪些事情!如果你想试试我们训练出来的模型,可以玩玩这个 space: trl-lib/stack-llama。
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/dpo-trl
原文作者: Kashif Rasul, Younes Belkada, Leandro von Werra
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
审校/排版: zhongdongy (阿东)
相关文章:

使用 DPO 微调 Llama 2
简介 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。然而,它也给 NLP 引入了一些 RL 相关…...
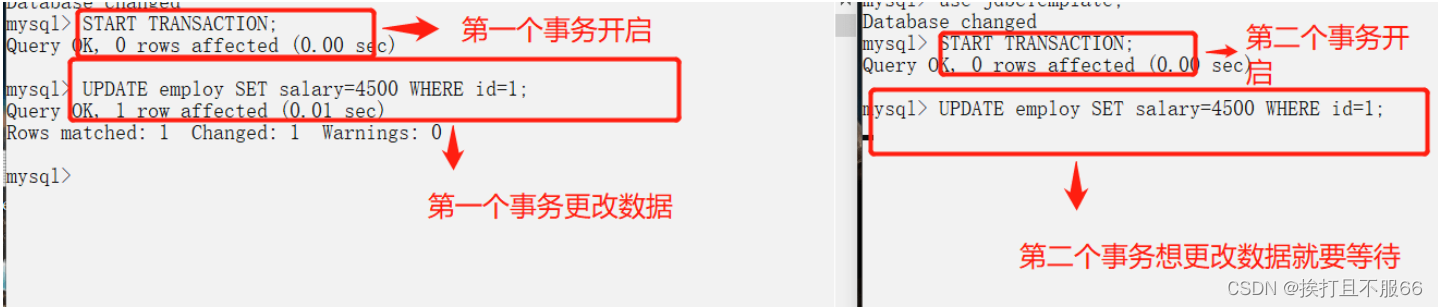
数据库——事务,事务隔离级别
文章目录 什么是事务?事务的特性(ACID)并发事务带来的问题事务隔离级别实际情况演示脏读(读未提交)避免脏读(读已提交)不可重复读可重复读防止幻读(可串行化) 什么是事务? 事务是逻辑上的一组操作,要么都执行,要么都不执行。 事务最经典也经常被拿出…...
对《VB.NET通过VB6 ActiveX DLL调用PowerBasic及FreeBasic动态库》的改进
《VB.NET通过VB6 ActiveX DLL调用PowerBasic及FreeBasic动态库》使用的Activex DLL公共对象是需要先注册的。https://blog.csdn.net/weixin_45707491/article/details/132437502?spm1001.2014.3001.5501 Activex DLL事前注册,一次多用说起来也不是啥大问题&#x…...

【PHP】数据类型运算符位运算
文章目录 数据类型简单(基本)数据类型:4个小类复合数据类型:2个小类特殊数据类型:2个小类类型转换类型判断整数类型浮点类型布尔类型 运算符赋值运算符算术运算符比较运算符逻辑运算符连接运算符错误抑制符三目运算符自…...

使用 Nacos 作为 Spring Boot 配置中心
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
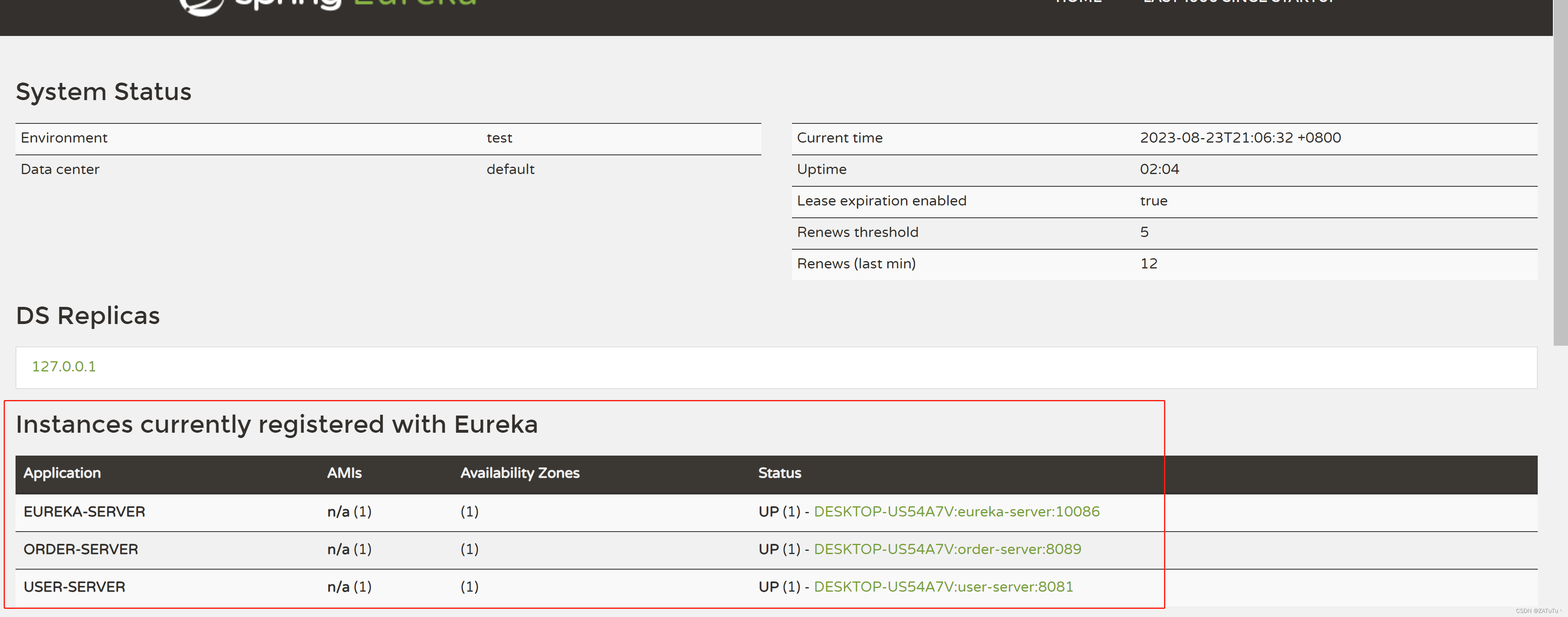
微服务 Eureka
Eureka Eureka是Netflix开源的一个用于构建基于微服务架构的服务发现和注册中心技术。在微服务架构中,系统被拆分成多个小型、自治的服务,每个服务负责特定的业务功能。这些服务需要能够相互发现和通信,这就是Eureka所提供的功能。 Eureka主…...

Spring Boot 事务和事务传播机制
1. 为什么需要事务? 事务定义 将一组操作封装成一个执行单元 (封装到一起),这一组的执行具备原子性, 那么就要么全部成功,要么全部失败. 为什么要用事务? 比如转账分为两个操作: 第一步操作:A 账户-100 元。 第二步操作:B账户 100 元。 如果没有事务&a…...

计算机组成原理(巨巨巨基础篇)
有关《计算机组成原理》课本中有关 内存计算换算(字,位,字节) 个人理解 前面知识点搭建框架,最后两道例题是直观理解体会 主存储器的基本概念 位:存储信息的最小单位,称为存储位或存储元。 背…...

C语言:选择+编程(每日一练Day7)
目录 选择题: 题一: 题二: 题三: 题四: 题五: 编程题: 题一:图片整理 思路一: 思路二: 题二:寻找数组的中心下标 思路一࿱…...

leetcode做题笔记93. 复原 IP 地址
有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。 例如:"0.1.2.201" 和 "192.168.1.1" 是 有效 IP 地址,但是 "0.011.255.2…...

HTTPS 中间人攻击
HTTPS 中间人攻击 中间人攻击过程 通讯过程 客户端——中间人——服务器 过程如下 服务器向客户端发送公钥攻击者截获公钥,保留在自己手上然后攻击者自己生成一个【伪造的】公钥,发给客户端客户端收到【伪造的】公钥后,利用【伪造的】公…...
MATLAB打开excel读取写入操作例程
本文使用素材含代码测试用例等 MATLAB读写excel文件历程含,内含有测试代码资源-CSDN文库 打开文件 使用uigetfile函数过滤非xlsx文件,找到需要读取的文件,首先判断文件是否存在,如果文件不存在,程序直接返回&#x…...

[C语言]分支与循环
导言: 在人生中我们总会有选择,**如下一顿吃啥?**又或者每天都是在重复,吃饭!!!!,当然在C语言中也有选择和重复那就是分支语句与循环语句 文章目录 分支循环循环中的关键…...

绘制区块链之链:解码去中心化、安全性和透明性的奇迹
区块链技术以其去中心化、安全性和透明性等特点在全球范围内引起了广泛的关注和兴趣。区块链是一种分布式账本技术,通过将数据以不可篡改的方式链接在一起,创建了一个安全可靠的数据库。这种革命性的技术正在许多领域中发挥作用,包括加密货币…...

4G工业路由器的功能与选型!详解工作原理、关键参数、典型品牌
随着工业互联网的发展,4G工业路由器得到越来越广泛的应用。但是如何根据实际需求选择合适的4G工业路由器,是许多用户关心的问题。为此,本文将深入剖析4G工业路由器的工作原理、重要参数及选型要点,并推荐优质的品牌及产品,以提供选型参考。 一、4G工业路由器的工作原理 4G工业…...

c与c++中struct的主要区别和c++中的struct与class的主要区别
1、c和c中struct的主要区别 c中的struct不可以含有成员函数,而c中的struct可以。 C语言 c中struct 是一种用于组合多个不同数据类型的数据成员的方式。struct 声明中的成员默认是公共的,并且不支持成员函数、访问控制和继承等概念。C中的struct通常被用…...
和length())
mysql中char_length()和length()
MySQL中计算字符串长度有两个函数分别为char_length和length。 char_length char_length函数可以计算unicode字符,包括中文等字符集的长度 char_length(‘string’)/char_length(column_name) 1、返回值为字符串string或者对应字段长度,长度的单位为字…...

Numpy学习笔记
科学计算库(Numpy) 通常数据都能转换成矩阵,行就是每一条样本数据,列就是每个字段的特征,Numpy在矩阵运算上非常高效,可以快速处理数据并进行数据计算。 Numpy基本操作 先导入 import numpy as nparray…...
LAMP配置与应用
目录 一、LAMP架构的组成 1、WEB资源类型 2、LAMP架构的组成 二、编译安装LAMP 编译安装apache 1、环境准备 2、导入apache相关压缩安装包,然后安装编译环境 3、解压软件包,并移动apr包与apr-util包到安装目录中,并切换到http解压出…...

Dockerfile搭建LNMP运行Wordpress平台
Dockerfile搭建LNMP运行Wordpress平台 一、项目1.1 项目环境1.2 服务器环境1.3 任务需求 二、Linux 系统基础镜像三、Nginx1、建立工作目录2、编写 Dockerfile 脚本3、准备 nginx.conf 配置文件4、生成镜像5、创建自定义网络6、启动镜像容器7、验证 nginx 四、Mysql1、建立工作…...

全网资源嗅探下载神器:轻松获取视频音频资源的终极指南
全网资源嗅探下载神器:轻松获取视频音频资源的终极指南 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gitcode.co…...
)
flbook电子书下载神器!用这招把网页变PDF(Python+JS双解法)
从网页到PDF:PythonJS双引擎实现FlBook电子书高效归档方案 在数字阅读时代,电子书平台已成为获取知识的重要渠道,但许多优质内容往往缺乏便捷的下载选项。对于技术从业者和数字内容管理者而言,掌握将在线电子书转化为可离线保存的…...

PySide6商业项目避坑指南:从许可证验证到Qt Designer实战
PySide6商业项目避坑指南:从许可证合规到UI开发实战 当企业开发者选择PySide6作为桌面应用开发框架时,往往会被其商业友好的LGPL许可证所吸引。但真正落地到项目开发中,从法律合规到技术实现都存在诸多需要特别注意的细节。本文将深入剖析那些…...

Qwen3.5-4B-Claude-Opus真实作品:网络协议TCP三次握手状态机推理生成
Qwen3.5-4B-Claude-Opus真实作品:网络协议TCP三次握手状态机推理生成 1. 模型介绍 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF 是一个基于 Qwen3.5-4B 的推理蒸馏模型,专门针对结构化分析、分步骤回答、代码与逻辑类问题进行了优化。该模型…...

QLVideo终极指南:让macOS Finder完美预览所有视频格式
QLVideo终极指南:让macOS Finder完美预览所有视频格式 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcod…...

Axure RP中文界面完全指南:4步实现高效设计工作流
Axure RP中文界面完全指南:4步实现高效设计工作流 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 作为产…...

突破百度网盘限速:从问题诊断到性能优化的实战全攻略
突破百度网盘限速:从问题诊断到性能优化的实战全攻略 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 问题诊断:揭开网盘下载的痛点图谱 场景引入&…...

Hunyuan-HY-MT1.8B性能报告解读:380ms处理500token实测
Hunyuan-HY-MT1.8B性能报告解读:380ms处理500token实测 1. 测试背景与模型简介 腾讯混元团队最新发布的HY-MT1.5-1.8B翻译模型,以其轻量级架构和卓越性能引起了广泛关注。这个仅有18亿参数的模型,在保持高质量翻译效果的同时,实…...

滞回比较器设计实战:从理论到参数优化
1. 滞回比较器基础:从门铃到航天器的抗噪神器 第一次接触滞回比较器是在大学电子设计课上,当时教授用一个生动的例子开场:"想象你家的门铃——如果它对任何风吹草动都响个不停,你会疯掉;但如果连用力敲门都没反应…...

目标检测损失函数进化史:从IoU到EIoU/SIoU/WIoU,YOLOv8性能提升完全指南
引言在目标检测领域,损失函数的设计直接影响着模型的收敛速度和检测精度。作为YOLOv8等先进检测器的核心组件,边界框回归损失函数经历了从简单到复杂的演进过程。传统的IoU(Intersection over Union)损失虽然直观有效,…...