数据驱动洞察:各种词频分析技术挖掘热点数据
一、引言
随着信息时代的发展,人们的关注点日益复杂多样。社交媒体、新闻网站和论坛等平台上涌现了大量的信息,这使得热点分析成为了解社会热点话题和舆情动向的重要手段。词频统计是热点分析的基础,本文将分别介绍基于ElasticSearch、基于Spark和基于Python的三种词频统计技术方案。
几种常见的热点词频统计技术方案:
- 基于ElasticSearch的聚合功能: ElasticSearch是一种开源的分布式搜索和分析引擎,具备强大的文本分析和聚合功能。通过使用ElasticSearch的聚合功能,可以对文档中的关键词进行聚合,统计每个关键词的出现次数,从而得到热点词频统计结果。
- 基于Spark的分布式计算: Spark是一种基于内存的分布式计算框架,能够高效地处理大规模数据。在Spark中,可以通过MapReduce等算子实现词频统计,从而进行热点词频统计。
- 基于Python的本地计算: 对于小规模的数据集,可以使用Python编程语言进行热点词频统计。Python拥有丰富的文本处理库和工具,能够快速实现简单的词频统计任务。
- 基于自然语言处理(NLP)技术: NLP技术能够从文本中提取关键词、短语和实体等信息,可以帮助实现更加智能化和精准的热点词频统计。NLP技术包括分词、词性标注、命名实体识别等。
- 基于机器学习模型: 通过训练机器学习模型,可以预测和识别出现频率较高的关键词,从而实现热点词频统计。常用的机器学习模型包括朴素贝叶斯、支持向量机(SVM)等。
- 基于深度学习模型: 深度学习模型如循环神经网络(RNN)、长短期记忆网络(LSTM)等能够学习文本中的语义信息,可以帮助更好地理解文本内容,实现更准确的热点词频统计。
二、技术原理
1、热点词频统计
热点词频统计是一种基于文本数据的频次分析方法,用于统计文本中每个单词出现的次数,并按照出现次数降序排列,从而找出频率最高的关键词。这些关键词通常是热点话题的代表,其出现频次反映了社会关注的焦点。以下是热点词频统计的技术原理:
- 文本预处理: 在进行词频统计之前,需要对原始文本进行预处理。预处理包括以下步骤:
- 将文本转换为小写:为了确保大小写不敏感的统计,通常将所有单词转换为小写形式。
- 分词:将文本拆分成单词或词语的序列,这个过程称为分词。分词的方法可以根据实际情况选择,例如基于空格、标点符号或者更复杂的自然语言分词处理技术。
- 构建词频统计表: 将预处理后的文本数据按照单词进行统计,构建一个词频统计表。该表将每个单词作为键,出现的次数作为对应的值,记录了每个单词的频率信息。
- 排序与选取热点词: 对词频统计表按照出现次数降序排列,从频率最高的关键词开始,这些关键词即为热点词。通常情况下,只有少数几个词频最高的单词才会被认为是热点词,因为它们代表了社会话题的核心。
2、中文分词

中文分词是将中文文本切分成一个个独立的词语或词组的过程。由于中文不像英文那样有空格或标点符号来界定词语的边界,因此中文分词是自然语言处理中的一个重要任务。以下是几种常见的中文分词技术:
- 基于规则的分词方法: 这种方法依赖于预先定义的规则和词典来进行分词。将中文文本与词典中的词语进行匹配,如果找到匹配项,则切分出该词语。如果匹配不上,则根据预定义的规则进行切分。这种方法比较简单,但需要手动维护词典和规则,不适用于生僻词等情况。
- 基于统计的分词方法: 这种方法利用统计模型和概率分布来进行分词。常用的方法包括最大匹配法、最大概率分词法和隐马尔可夫模型(HMM)。最大匹配法是一种启发式算法,从文本的左边开始找到最长的匹配词,然后从剩余文本中继续找下一个最长匹配词,直到整个文本被切分完毕。最大概率分词法是基于条件概率计算词的分割点。HMM是一种序列标注模型,通过学习文本中的词语出现概率和相邻词语之间的转移概率来进行分词。
- 基于机器学习的分词方法: 这种方法利用机器学习算法,如条件随机场(CRF)、支持向量机(SVM)和深度学习模型(如循环神经网络)来进行分词。这些模型能够自动学习词语的特征和上下文信息,从而更准确地进行分词。
- 基于字典的分词方法: 这种方法是将中文文本切分成字的序列,然后通过字典匹配的方式将字序列组合成词。这种方法对于未登录词有较好的处理效果,但由于字的组合较多,对于歧义较大的文本有一定挑战。
- 结合多种方法的分词技术: 为了提高分词的准确性,有些分词系统结合了多种方法,如规则+统计、规则+机器学习等。通过综合利用不同方法的优势,可以得到更好的分词结果。
三、实现方案
1、基于ElasticSearch方式
ElasticSearch是一种开源的分布式搜索和分析引擎,它提供了强大的文本分析功能,非常适合进行词频统计和热点分析。
优点:
- 实现简单,只需要配置好ElasticSearch,并将数据导入即可。
- 性能高,ElasticSearch可以利用分布式计算和缓存机制来加速查询和聚合。
- 可扩展性强,ElasticSearch可以动态地增加或减少节点来应对不同的数据量和负载。
缺点:
- 数据预处理较复杂,需要对数据进行分词,过滤,标准化等操作。
- 聚合结果可能不准确,因为ElasticSearch默认使用倒排索引来存储词频,这会导致一些词被忽略或合并。
- 资源消耗较大,ElasticSearch需要占用大量的内存和磁盘空间来存储索引和缓存。
适用于:
- 数据量大,更新频繁,需要实时查询和分析的场景。
- 数据结构简单,不需要复杂的语义分析和处理的场景。
主要有两种实现方式:
方案一:使用ElasticSearch聚合功能实现热点词频统计
该方案主要利用ElasticSearch的聚合功能来实现热点词频统计。通过使用Terms Aggregation将文档中的关键词进行聚合,并统计每个关键词的出现次数,从而得到热点词频统计结果。
public class ElasticSearchAggregationDemo {public static void main(String[] args) throws IOException {// 创建RestHighLevelClient客户端RestHighLevelClient client = new RestHighLevelClient();// 创建SearchRequest请求SearchRequest searchRequest = new SearchRequest("your_index_name");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 设置查询条件,这里假设要查询的字段为"text"searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 创建聚合器,使用terms聚合方式TermsAggregationBuilder aggregation = AggregationBuilders.terms("hot_keywords").field("text.keyword"); // 使用.keyword来表示不分词// 将聚合器添加到查询中searchSourceBuilder.aggregation(aggregation);// 设置size为0,表示只获取聚合结果而不获取具体文档searchSourceBuilder.size(0);// 将SearchSourceBuilder设置到SearchRequest中searchRequest.source(searchSourceBuilder);// 执行搜索请求SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 获取聚合结果Terms terms = searchResponse.getAggregations().get("hot_keywords");for (Terms.Bucket bucket : terms.getBuckets()) {String keyword = bucket.getKeyAsString();long docCount = bucket.getDocCount();System.out.println("Keyword: " + keyword + ", Count: " + docCount);}// 关闭客户端client.close();}
}方案二:使用ElasticSearch Term Vector功能实现热点词频统计
该方案通过使用ElasticSearch的Term Vector功能,直接获取文档中的词频信息,实现热点词频统计。这种方法可以更细粒度地获取单个文档的词频信息,适用于需要深入分析单个文档的场景。
public class ElasticSearchTermVectorDemo {public static void main(String[] args) throws IOException {// 创建RestHighLevelClient客户端RestHighLevelClient client = new RestHighLevelClient();// 创建TermVectorsRequest请求TermVectorsRequest termVectorsRequest = new TermVectorsRequest("your_index_name", "your_document_id");termVectorsRequest.setFields("text"); // 设置要统计的字段名// 设置term_statistics为true,表示需要获取词频信息termVectorsRequest.setTermStatistics(true);// 执行termvector请求TermVectorsResponse termVectorsResponse = client.termvectors(termVectorsRequest, RequestOptions.DEFAULT);// 获取termvector结果Map<String, Integer> termFreqMap = termVectorsResponse.getTermFreqMap("text");for (Map.Entry<String, Integer> entry : termFreqMap.entrySet()) {String term = entry.getKey();int freq = entry.getValue();System.out.println("Term: " + term + ", Frequency: " + freq);}// 关闭客户端client.close();}
}这两种方案都可以实现热点词频统计,具体选择哪种方案取决于实际需求和数据规模。方案一适用于对整个索引或多个文档进行热点词频统计,而方案二适用于深入分析单个文档的词频信息。根据具体场景,可以选择合适的方案或者结合两者使用,以达到更好的分析效果。
2、基于Spark方式

Spark是一种基于内存的分布式计算框架,它能够高效地处理大规模数据。通过Spark,我们可以实现并行处理大量文本数据,进行词频统计和热点分析。
优点:
- 实现灵活,可以使用不同的编程语言(如Java, Scala, Python等)和API(如RDD, DataFrame, Dataset等)来编写Spark应用。
- 性能高,Spark可以利用内存计算和懒加载机制来加速数据处理。
- 可扩展性强,Spark可以动态地调整资源分配和任务调度来应对不同的数据量和负载。
缺点:
- 数据预处理较复杂,需要对数据进行分词,过滤,标准化等操作。
- 资源消耗较大,Spark需要占用大量的内存和CPU资源来执行任务。
适用于:
- 数据量大,更新频繁,需要批处理或流处理的场景。
- 数据结构复杂,需要复杂的语义分析和处理的场景。
具体实现:
Spark官方提供了JavaWordCount的Demo,演示了如何使用Spark进行词频统计。该Demo使用Java编写,但Spark也支持Scala和Python等多种编程语言,具有较高的灵活性和可扩展性。
public class JavaWordCount {public static void main(String[] args) {// 创建Spark配置SparkConf conf = new SparkConf().setAppName("JavaWordCount").setMaster("local[*]"); // 在本地模式下运行,使用所有可用的CPU核心// 创建JavaSparkContextJavaSparkContext sc = new JavaSparkContext(conf);// 读取文本文件JavaRDD<String> lines = sc.textFile("input.txt");// 切分每行文本为单词JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());// 转换每个单词为键值对,并计数JavaPairRDD<String, Integer> wordCounts = words.mapToPair(word -> new Tuple2<>(word, 1)).reduceByKey((count1, count2) -> count1 + count2);// 打印结果wordCounts.foreach(pair -> System.out.println(pair._1() + ": " + pair._2()));// 关闭JavaSparkContextsc.close();}
}
3、基于Python方式

对于简单的数据词频统计,Python是一种简便高效的方式。Python的代码量通常较少,但它足够应对小规模数据集的热点分析需求。
优点:
- 实现简单,只需要使用Python的标准库或第三方库即可。
- 代码简洁,Python有着优雅的语法和风格,可以用少量的代码实现复杂的功能。
- 适应性强,Python可以与其他语言或工具(如C, Java, R, Excel等)进行交互和集成。
缺点:
- 可扩展性差,Python不支持分布式计算和并行处理,难以应对大规模的数据和负载。
- 兼容性差,Python有着多个版本和实现(如Python 2, Python 3, CPython, PyPy等),它们之间可能存在不兼容的问题。
适用于:
- 数据量小,更新不频繁,不需要实时查询和分析的场景。
- 数据结构简单,不需要复杂的语义分析和处理的场景。
以下是一个基于Python的简单词频统计示例:
text = "http request high client spring boot"
data = text.lower().split()
words = {}
for word in data:if word not in words:words[word] = 1else:words[word] += 1
result = sorted(words.items(), key=lambda x: x[1], reverse=True)
print(result)四、小结
不同的热点分析技术方案适用于不同的场景。如果处理的数据量较小,且仅需简单的词频统计,Python是最为便捷的选择。对于大规模数据的处理,基于ElasticSearch或Spark的方式更为适合。ElasticSearch提供了强大的文本分析功能,而Spark能够高效地处理分布式计算任务。因此,在选择合适的技术方案时,需要结合实际场景和需求综合考虑。
如果文章对你有帮助,欢迎点赞+关注!
相关文章:
数据驱动洞察:各种词频分析技术挖掘热点数据
一、引言 随着信息时代的发展,人们的关注点日益复杂多样。社交媒体、新闻网站和论坛等平台上涌现了大量的信息,这使得热点分析成为了解社会热点话题和舆情动向的重要手段。词频统计是热点分析的基础,本文将分别介绍基于ElasticSearch、基于S…...

ES6-简介、语法
ES6 ES6简介 ECMAScript 6(简称ES6)是于2015年6月正式发布的JavaScript语言的标准,正式名为ECMAScript 2015(ES2015)。它的目标是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语…...

诚迈科技子公司智达诚远与Unity中国达成合作,打造智能座舱新时代
2023 年 8 月 23 日,全球领先的实时 3D 引擎 Unity 在华合资公司 Unity 中国举办发布会,正式对外发布 Unity 引擎中国版——团结引擎,并带来专为次世代汽车智能座舱打造的团结引擎车机版。发布会上,诚迈科技副总裁、诚迈科技子公司…...

算法与数据结构(十)--图的入门
一.图的定义和分类 定义:图是由一组顶点和一组能够将两个顶点连接的边组成的。 特殊的图: 1.自环:即一条连接一个顶点和其自身的边; 2.平行边:连接同一对顶点的两条边; 图的分类: 按照连接两个顶点的边的…...

【Go 基础篇】Go语言 init函数详解:包的初始化与应用
介绍 在Go语言中,init() 函数是一种特殊的函数,用于在包被导入时执行一次性的初始化操作。init() 函数不需要手动调用,而是在包被导入时自动执行。这使得我们可以在包导入时完成一些必要的初始化工作,确保包的使用具有正确的环境…...

wazuh环境配置及漏洞复现
目录 一、wazuh配置 1进入官网下载OVA启动软件 2.虚拟机OVA安装 二、wazuh案例复现 1.wazuh初体验 2.这里我们以SQL注入为例,在我们的代理服务器上进行SQL注入,看wazuh如何检测和响应 一、wazuh配置 1进入官网下载OVA启动软件 Virtual Machine (O…...

Java接收前端请求体方式
💗wei_shuo的个人主页 💫wei_shuo的学习社区 🌐Hello World ! 文章目录 RequestBodyPathVariableRequestParamValidated方法参数校验方法返回值校验 RequestHeaderHttpServletRequest ## Java接收前端请求体的方式 请求体…...

私有化部署即时通讯平台,30分钟替换钉钉和企业微信
随着企业对即时通讯和协作工具的需求不断增长,私有化部署的即时通讯平台成为企业的首选。WorkPlus作为有10余年行业深耕经验与技术沉淀品牌,以其安全高效的私有化部署即时通讯解决方案,帮助企业在30分钟内替换钉钉和企业微信。本文将深入探讨…...
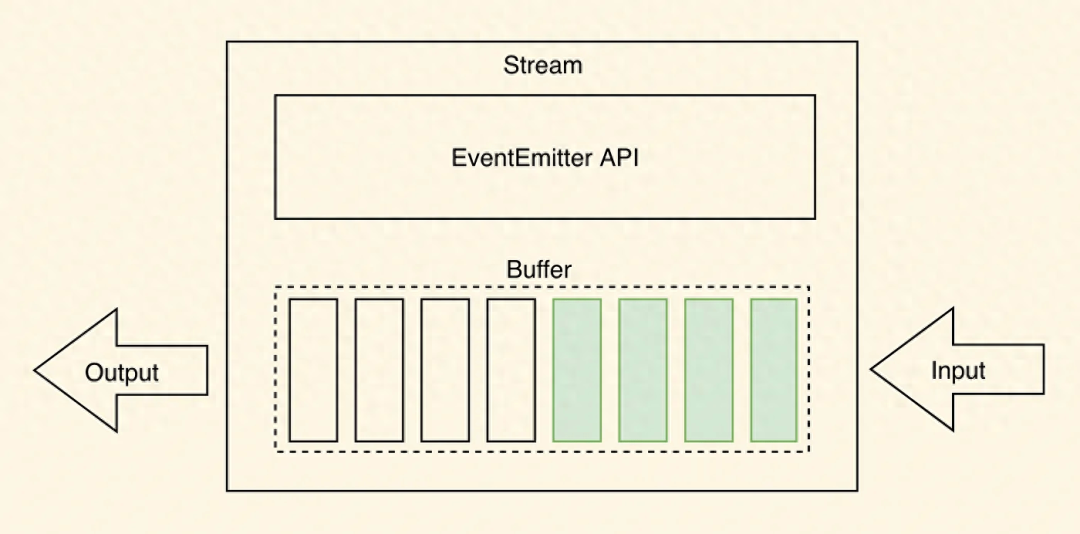
如何深入理解 Node.js 中的流(Streams)
Node.js是一个强大的允许开发人员构建可扩展和高效的应用程序。Node.js的一个关键特性是其内置对流的支持。流是Node.js中的一个基本概念,它能够实现高效的数据处理,特别是在处理大量信息或实时处理数据时。 在本文中,我们将探讨Node.js中的流…...
MSP430FR2xxx开发(一)添加driverlib
一、新建工程 根据自己手上的硬件型号新建工程,文中已MSP430FR2355为例。 二、添加driverlib 首先去官方下载driverlib. https://www.ti.com.cn/tool/cn/MSPDRIVERLIB?keyMatchMSP430%20DRIVERLIB#downloads 下载后的内容如下: 我这里就选择MSP430…...

【C++】做一个飞机空战小游戏(九)——发射子弹的编程技巧
[导读]本系列博文内容链接如下: 【C】做一个飞机空战小游戏(一)——使用getch()函数获得键盘码值 【C】做一个飞机空战小游戏(二)——利用getch()函数实现键盘控制单个字符移动【C】做一个飞机空战小游戏(三)——getch()函数控制任意造型飞机图标移动 【C】做一个飞…...

34.SpringMVC获取请求参数
SpringMVC获取请求参数 通过ServletAPI获取 将HttpServletRequest作为控制器方法的形参,此时HttpServletRequest类型的参数表示封装了当前请求的请求报文的对象 index.html <form th:action"{/test/param}" method"post">用户名&#…...

TC1016-同星4路CAN(FD),2路LIN转USB接口卡
TC1016是同星智能推出的一款多通道CAN(FD)和LIN总线接口设备,CANFD总线速率最高支持8M bps,LIN支持速率0~20K bps,产品采用高速USB2.0接口与PC连接,Windows系统免驱设计使得设备具备极佳的系统兼容性。 支…...

Android源码——从Looper看ThreadLocal
1 概述 ThreadLocal用于在当前线程中存储数据,由于存储的数据只能在当前线程内使用,所以自然是线程安全的。 Handler体系中,Looper只会存在一个实例,且只在当前线程使用,所以使用ThreadLocal进行存储。 2 存储原理 …...
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

MySQL 自定义 split 存储过程
MySQL 没有提供 split 函数,但可以自己建立一个存储过程,将具有固定分隔符的字符串转成多行。之所以不能使用自定义函数实现此功能,是因为 MySQL 的自定义函数自能返回标量值,不能返回多行结果集。 MySQL 8: drop pr…...
专题-【十字链表】
有向图的十字链表表示法:...
)
微信小程序教学系列(2)
第二章:小程序开发基础 1. 小程序页面布局与样式 在小程序开发中,我们可以使用 WXML(WeiXin Markup Language)和 WXSS(WeiXin Style Sheet)来定义页面的布局和样式。 1.1 WXML基础 WXML 是一种类似于 H…...
社科院与美国杜兰大学金融管理硕士项目——畅游于金融世界
随着社会经济的不断发展,职场竞争愈发激烈,很多同学都打算通过报考研究生来实现深造,提升自己的综合能力和竞争优势,获得优质的证书。而对于金融专业的学生和在职人员来说,社科院与美国杜兰大学金融管理硕士项目是一个…...
功能强大、超低功耗的STM32WL55JCI7、STM32WL55CCU7、STM32WL55CCU6 32位无线远距离MCU
STM32WL55xx 32位无线远距离MCU嵌入了功能强大、超低功耗、符合LPWAN标准的无线电解决方案,可提供LoRa、(G)FSK、(G)MSK和BPSK等各种调制。STM32WL55xx无线MCU的功耗超低,基于高性能Arm Cortex-M4 32位RISC内核(工作频率高达48MHz)…...
)
STM32实战:用HAL库搞定RS485 Modbus液压传感器数据采集(附自动收发电路避坑)
STM32实战:HAL库驱动RS485 Modbus液压传感器全流程解析 液压系统压力监测的稳定性往往取决于传感器数据采集的可靠性。在工业现场,RS485总线搭配Modbus RTU协议已成为液压传感器数据传输的黄金标准。本文将深入探讨基于STM32 HAL库的完整解决方案&#x…...

从YOLOv1到YOLOv5:一个算法工程师的实战避坑与版本选择指南
从YOLOv1到YOLOv5:算法工程师的版本选择与实战调优指南 在计算机视觉领域,目标检测算法的发展日新月异,而YOLO(You Only Look Once)系列作为其中的佼佼者,凭借其出色的实时性和准确性,已成为工业界和学术界广泛采用的核…...

AI编程助手效率革命:结构化配置与提示词工程实战
1. 项目概述:一个为AI编程时代量身定制的开发者工具箱如果你和我一样,日常开发已经离不开像 Cursor 和 Claude 这样的 AI 编程助手,那你肯定也遇到过类似的困扰:每次开启一个新项目,或者在不同项目间切换时,…...
指标解析——专业级语音稳定性评估体系首度披露)
【限时解密】ElevenLabs未公开的“Voice Stability Index”(VSI)指标解析——专业级语音稳定性评估体系首度披露
更多请点击: https://intelliparadigm.com 第一章:【限时解密】ElevenLabs未公开的“Voice Stability Index”(VSI)指标解析——专业级语音稳定性评估体系首度披露 VSI 的本质与工程意义 Voice Stability Index(VSI&…...

如何突破窗口限制:3分钟掌握WindowResizer强制调整技巧
如何突破窗口限制:3分钟掌握WindowResizer强制调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些无法拖拽大小的应用程序窗口而烦恼吗?Win…...

Perplexity AI集成开发工具:MCP协议与零成本API实战指南
1. 项目概述:将Perplexity AI深度集成到你的开发工作流 如果你是一名开发者,或者经常需要处理信息检索、代码问题排查、技术方案调研这类工作,那么你肯定对“搜索”这件事又爱又恨。爱的是它能瞬间连接海量知识,恨的是在IDE和浏览…...

Jellyfin智能片头检测解决方案:Intro Skipper插件技术指南
Jellyfin智能片头检测解决方案:Intro Skipper插件技术指南 【免费下载链接】intro-skipper Fingerprint audio to automatically detect and skip intro sequences in Jellyfin 项目地址: https://gitcode.com/gh_mirrors/in/intro-skipper Intro Skipper是一…...

NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案
NodeMCU PyFlasher:ESP8266图形化固件烧录终极解决方案 【免费下载链接】nodemcu-pyflasher Self-contained NodeMCU flasher with GUI based on esptool.py and wxPython. 项目地址: https://gitcode.com/gh_mirrors/no/nodemcu-pyflasher 对于ESP8266开发者…...

龙为权,凰为心:凰标守住文化最柔软的底线@凤凰标志
龙为权凰为心 中国文艺生态的双轨平衡宣言秩序权力与创作初心,一刚一柔, 如日月轮值,缺一不可。 龙标掌「权」,凰标守「心」, 双轨并行,方可让文化既筋骨强健,又血肉温润。一、龙标:…...

Fusion 360 数据迁移与路径重定向实战
1. 为什么需要迁移Fusion 360数据? 很多设计师朋友都遇到过这样的困扰:C盘空间莫名其妙被占满,系统开始频繁提示存储空间不足。打开磁盘分析工具一看,发现Fusion 360的缓存和用户数据竟然占用了数十GB空间。这种情况在长期使用Fus…...