5.从头跑一个pipeline
1.安装torch
pip install torchvision torchPyTorch的torchvision.models模块中自带的很多预定义模型。torchvision 是PyTorch的一个官方库,专门用于处理计算机视觉任务。在这个库中,可以找到许多常用的卷积神经网络模型,包括ResNet、VGG、AlexNet等,以及它们的不同变体,如resnet50、vgg16等
2.准备模型
1.导出resnet50模型
import torch
import torchvision.models as modelsresnet50 = models.resnet50(pretrained=True)
resnet50.eval()
image = torch.randn(1, 3, 244, 244)
resnet50_traced = torch.jit.trace(resnet50, image)
resnet50(image)
resnet50_traced.save('model.pt')
创建resnet50_pytorch目录,目录下创建目录1(1表示版本号),然后将model.pt模型放到resnet50_pytorch/1目录下
执行该Python文件的时候会从https://download.pytorch.org/models/resnet50-0676ba61.pth下载模型文件,保存到本地的.cache/torch/hub/checkoutpoints
如我是在容器中执行的,保存路径为/root/.cache/torch/hub/checkpoints/resnet50-0676ba61.pth
2.准备模型配置
name: "resnet50_pytorch"
platform: "pytorch_libtorch"
max_batch_size: 128
input [{name: "INPUT__0"data_type: TYPE_FP32dims: [ 3, -1, -1 ]}
]
output [{name: "OUTPUT__0"data_type: TYPE_FP32dims: [ 1000 ]label_filename: "labels.txt"}
]
instance_group [{count: 1kind: KIND_GPU}
]
此时目录结构为
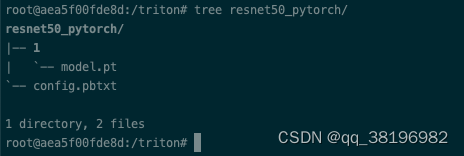
模型目录的名称必须与config.pbtxt中指定的模型名称完全匹配。这是为了确保 Triton 能够正确地识别和加载模型
3.加载模型
此时已经可以通过triton加载模型,需要注意的model-repository指出resnet50_pytorch的上一级目录即可(否则会报错),Triton会加载model-repo路径下的所有模型
/opt/tritonserver/bin/tritonserver --model-repository=/triton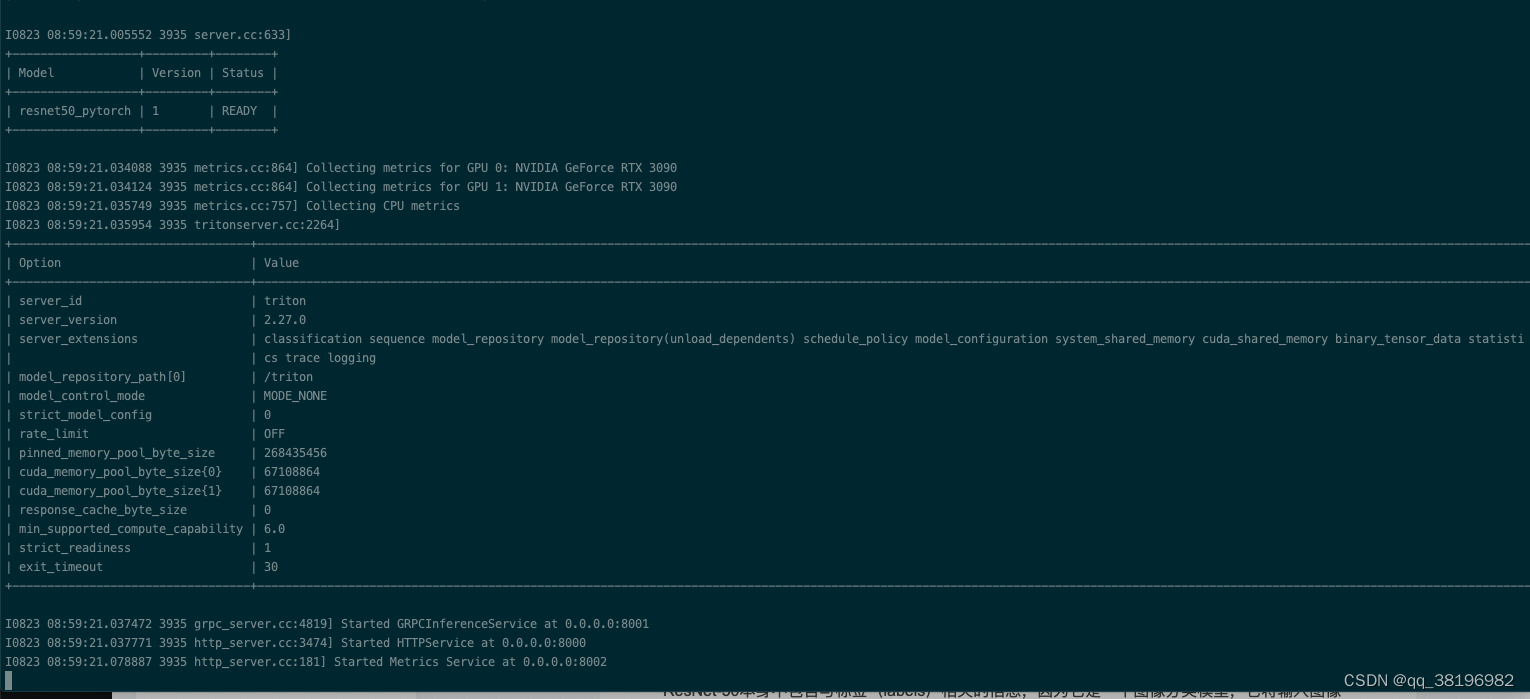
4.发送请求
想要获取分类的结果,可以设置 class_count=k,表示获取 TopK 分类预测结果。如果没有设置这个选项,那么将会得到一个 1000 维的向量。
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Imageif __name__ == '__main__':#1.创建triton clienttriton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')#2.加载图片image = Image.open('/test_triton/24poJOgl7m_small.jpg')#3.对图片进行预处理,以满足resnet50的input要求image = image.resize((224, 224), Image.ANTIALIAS)image = np.asarray(image)image = image / 255image = np.expand_dims(image, axis=0)image = np.transpose(image, axes=[0, 3, 1, 2])image = image.astype(np.float32)#4.创建inputsinputs = []inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))inputs[0].set_data_from_numpy(image, binary_data=False)#5.创建outputsoutputs = []outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False, class_count=1))#6.向triton server发送请求results = triton_client.infer('resnet50_pytorch', inputs=inputs, outputs=outputs)output_data0 = results.as_numpy('OUTPUT__0')print(output_data0.shape)print(output_data0)AttributeError: module 'PIL.Image' has no attribute 'ANTIALIAS'
则降低PIL版本
pip uninstall Pillow
pip install Pillow==9.5.0结果如下:
test_triton.py:12: DeprecationWarning: ANTIALIAS is deprecated and will be removed in Pillow 10 (2023-07-01). Use LANCZOS or Resampling.LANCZOS instead.image = image.resize((224, 224), Image.ANTIALIAS)
(1, 1)
[['10.245845:283']]输出的几个数字的含义如下:
-
(1, 1):这是输出数据的形状。这个元组表示输出数据的维度,第一个数字表示批处理大小(batch size),第二个数字表示每个样本的输出数目。在这个结果中,批处理大小是1,每个样本有1个输出。 -
['10.245845:283']:这是模型的输出值。它是一个字符串数组,通常包含了一个或多个浮点数值,以字符串形式表示。在这个结果中,字符串'10.245845:283'可以分为两部分:10.245845:这是模型对输入图像的分类概率得分。它表示模型认为输入图像属于某个特定类别的概率得分。通常,这个值越高,模型越确信输入图像属于这个类别。283:这通常是与类别标签相关的索引或标识符。这个索引可以用来查找与模型输出的概率得分对应的类别名称。具体来说,索引283对应于 ImageNet 数据集中的一个类别。您可以使用相应的labels.txt文件来查找该索引对应的类别名称。
5.准备标签
在第4步无论是使用class_count与否,都没有直接返回分类结果。这是因为ResNet-50本身不包含与标签(labels)相关的信息,因为它是一个图像分类模型,它将输入图像分为一组预定义的类别,但它并不知道这些类别的名称。标签信息通常是根据您的具体任务和数据集来定义的。
不同的labels.txt会导致最终的分类结果不一样
wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt下载之后重命名为labels.txt,
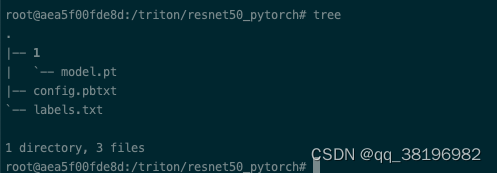
将config.pbtxt的内容改为如下:
name: "resnet50_pytorch"
platform: "pytorch_libtorch"
max_batch_size: 128
input [{name: "INPUT__0"data_type: TYPE_FP32dims: [ 3, -1, -1 ]}
]
output [{name: "OUTPUT__0"data_type: TYPE_FP32dims: [ 1000 ]label_filename: "labels.txt"}
]
instance_group [{count: 1kind: KIND_GPU}
]重新启动服务,重新发送请求,结果为
(1, 1)
[['10.245845:283:Persian cat']]查询labels.txt,283对应的类别是Persian cat(索引从0开始)
3.使用ensemble
第2部分的client.py里可以看到进行了数据处理,现在我们专门使用一个模型来进行数据处理
首先创建resnet50_ensemble目录,并把resnet50_pytorch拷贝到resnet50_ensemble目录下
1.python script model
使用Python Script Model来完成image的数据处理,以符合input需求(正式叫法是前处理),该类型的model通过python backend来进行execute。编写Python script model,需要实现如下接口供triton server调用
-
initialize:加载model config;创建image预处理所需要的对象 -
execute:有两种模式:-
Default model:execute输入为batch request,返回的结果也应该是相同order和number的batch response
-
Decoupled model:这里对返回的order和number都没有限制,主要应用在Automated Speech Recognition (ASR)
-
-
finalize:是可选的。该函数允许在从Triton服务器卸载模型之前进行任何必要的清理。
看不懂不要紧,先跑就行
创建一个model.py文件,内容如下
import numpy as np
import sys
import json
import ioimport triton_python_backend_utils as pb_utilsfrom PIL import Image
import torchvision.transforms as transforms
import os
class TritonPythonModel:def initialize(self, args):# You must parse model_config. JSON string is not parsed hereself.model_config = model_config = json.loads(args['model_config'])# Get OUTPUT0 configurationoutput0_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT_0")# Convert Triton types to numpy typesself.output0_dtype = pb_utils.triton_string_to_numpy(output0_config['data_type'])self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])self.loader = transforms.Compose([transforms.Resize([224, 224]),transforms.CenterCrop(224),transforms.ToTensor(), self.normalize])def _image_preprocess(self, image_name):image = self.loader(image_name)#expand the dimension to nchwimage = image.unsqueeze(0)return imagedef execute(self, requests):output0_dtype = self.output0_dtyperesponses = []# Every Python backend must iterate over everyone of the requests# and create a pb_utils.InferenceResponse for each of them.for request in requests:# 1) 获取request中name为INPUT_0的tensor数据, 并转换为image类型in_0 = pb_utils.get_input_tensor_by_name(request, "INPUT_0")img = in_0.as_numpy()image = Image.open(io.BytesIO(img.tobytes())) # 2) 进行图片的transformer,并将结果设置为numpy类型img_out = self._image_preprocess(image)img_out = np.array(img_out)# 3) 构造output tesnorout_tensor_0 = pb_utils.Tensor("OUTPUT_0", img_out.astype(output0_dtype))# 4) 设置resposneinference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor_0])responses.append(inference_response)return responsesdef finalize(self):print('Cleaning up...')该model.py的主要功能是对图像进行预处理,并生成推理响应
对应的config.pbtxt为
name: "preprocess"
backend: "python"
max_batch_size: 256
input [
{name: "INPUT_0"data_type: TYPE_UINT8 dims: [ -1 ]
}
]output [
{name: "OUTPUT_0"data_type: TYPE_FP32dims: [ 3, 224, 224 ]
}
]instance_group [{ kind: KIND_CPU }]我将这个模块放在了preprocess
2.ensemble model
ensemble model是用来描述Triton server模型处理的pipeline,其中仅有一个配置文件,并不存在真实的model
config.pbtxt内容如下:
其中通过platform设置当前model的类型为ensemble
通过ensemble_scheduling来指明model间的调用关系,其中step指定了执行的前后依赖关系
name: "ensemble_python_resnet50"
platform: "ensemble"
max_batch_size: 256
input [{name: "INPUT"data_type: TYPE_UINT8dims: [ -1 ]}
]
output [{name: "OUTPUT"data_type: TYPE_FP32dims: [ 1000 ]}
]
ensemble_scheduling {step [{model_name: "preprocess"model_version: -1input_map {key: "INPUT_0"value: "INPUT" # 指向ensemble的input}output_map {key: "OUTPUT_0"value: "preprocessed_image"}},{model_name: "resnet50_pytorch"model_version: -1input_map {key: "INPUT__0" #对应resnet50_pytorch里的input名字value: "preprocessed_image" # 指向preprocess的output}output_map {key: "OUTPUT__0" #对应resnet50_pytorch里的outputvalue: "OUTPUT" # 指向ensemble的output}}]
}此时resnet50_ensemble的目录结构为:
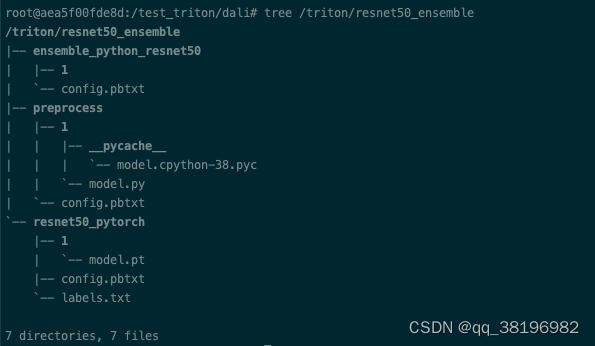
3.启动程序并测试
启动程序
/opt/tritonserver/bin/tritonserver --model-repository=/triton/resnet50_ensemble测试代码为
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Imageif __name__ == '__main__':triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')img_path = '/test_triton/24poJOgl7m_small.jpg'image = np.fromfile(img_path, dtype='uint8')image = np.expand_dims(image, axis=0)#设置inputinputs = []inputs.append(httpclient.InferInput('INPUT', image.shape, "UINT8"))inputs[0].set_data_from_numpy(image)#设置outputoutputs = []outputs.append(httpclient.InferRequestedOutput('OUTPUT', binary_data=False, class_count=1))#发送请求results = triton_client.infer('ensemble_python_resnet50', inputs=inputs, outputs=outputs)output_data0 = results.as_numpy('OUTPUT')print(output_data0.shape)print(output_data0)运行结果为
(1, 1)
[['9.462329:434:bath towel']]4.dali model
在第3部分,把数据处理放到了triton server进行,但问题在于数据处理的操作并没有充分利用硬件资源。为了加速模型的推理速度,一般将triton server部署在GPU节点上(第3部分的数据处理是在CPU上进行的)。将数据处理转移到GPU上,可以使用nvidia提供的dali数据处理库
首先创建resnet50_ensemble_dali目录,并把resnet50_pytorch模型拷贝到resnet50_ensemble_dali路径下
1.准备dali模型
安装依赖
curl -O https://developer.download.nvidia.com/compute/redist/nvidia-dali-cuda110/nvidia_dali_cuda110-1.28.0-8915299-py3-none-manylinux2014_x86_64.whlpip install nvidia_dali_cuda110-1.28.0-8915299-py3-none-manylinux2014_x86_64.whl在Releases · NVIDIA/DALI · GitHub下载与自己系统适配的whl
Python文件如下
import nvidia.dali as dali
import nvidia.dali.fn as fn@dali.pipeline_def(batch_size=128, num_threads=4, device_id=0)
def pipeline():images = fn.external_source(device='cpu', name='DALI_INPUT_0')images = fn.resize(images, resize_x=224, resize_y=224)images = fn.transpose(images, perm=[2, 0, 1])images = images / 255return imagespipeline().serialize(filename='./model.dali')
执行该Python文件将得到model.dali模型
在resnet50_ensemble_dali目录下创建resnet50_dali,把model.dali放到该目录下
对应的config.pbtxt文件为
name: "resnet50_dali"
backend: "dali"
max_batch_size: 128
input [{name: "DALI_INPUT_0"data_type: TYPE_FP32dims: [ -1, -1, 3 ]}
]output [{name: "DALI_OUTPUT_0"data_type: TYPE_FP32dims: [ 3, 224, 224 ]}
]
instance_group [{count: 1kind: KIND_GPUgpus: [ 0 ]}
]2.创建pipeline
创建ensemble_python_resnet50目录,和3.2一样,对应的config.pbtxt内容为
name: "ensemble_python_resnet50"
platform: "ensemble"
max_batch_size: 128
input [{name: "INPUT"data_type: TYPE_FP32dims: [ -1, -1, 3 ]}
]
output [{name: "OUTPUT"data_type: TYPE_FP32dims: [ 1000 ]}
]
ensemble_scheduling {step [{model_name: "resnet50_dali"model_version: -1input_map {key: "DALI_INPUT_0"value: "INPUT" # 指向ensemble的input}output_map {key: "DALI_OUTPUT_0"value: "preprocessed_image"}},{model_name: "resnet50_pytorch"model_version: -1input_map {key: "INPUT__0"value: "preprocessed_image" # 指向resnet50_dali的output}output_map {key: "OUTPUT__0"value: "OUTPUT" # 指向ensemble的output}}]
}现在整个resnet50_ensemble_dali目录结构为
3.启动并测试
启动Triton加载模型
/opt/tritonserver/bin/tritonserver --model-repository=/triton/resnet50_ensemble_dali/测试代码为
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Imageif __name__ == '__main__':triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')img_path = '/test_triton/24poJOgl7m_small.jpg'image = Image.open(img_path)image = np.asarray(image)image = np.expand_dims(image, axis=0)image = image.astype(np.float32)inputs = []inputs.append(httpclient.InferInput('INPUT', image.shape, "FP32"))inputs[0].set_data_from_numpy(image, binary_data=False)outputs = []outputs.append(httpclient.InferRequestedOutput('OUTPUT', binary_data=False, class_count=1))#发送请求results = triton_client.infer('ensemble_python_resnet50', inputs=inputs, outputs=outputs)output_data0 = results.as_numpy('OUTPUT')print(output_data0.shape)print(output_data0)结果为
root@aea5f00fde8d:/triton/resnet50_ensemble_dali# python3 /test_triton/dali/client.py
(1, 1)
[['10.661538:283:Persian cat']]
结束!
相关文章:
5.从头跑一个pipeline
1.安装torch pip install torchvision torch PyTorch的torchvision.models模块中自带的很多预定义模型。torchvision 是PyTorch的一个官方库,专门用于处理计算机视觉任务。在这个库中,可以找到许多常用的卷积神经网络模型,包括ResNet、VGG、…...
)
leetcode原题: 堆箱子(动态规划实现)
题目: 给你一堆n个箱子,箱子宽 wi、深 di、高 hi。箱子不能翻转,将箱子堆起来时,下面箱子的宽度、高度和深度必须大于上面的箱子。实现一种方法,搭出最高的一堆箱子。箱堆的高度为每个箱子高度的总和。 输入使用数组…...
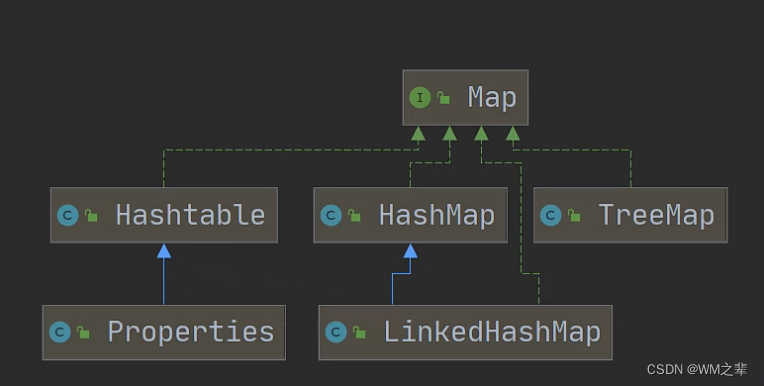
Java中数组和集合的对比,以及什么情况下使用数组更合适,什么情况下使用集合更合适。集合的基本介绍和集合体系图。
在Java中,数组和集合(Java集合框架)都用于存储多个元素。它们各自有不同的特点和适用场景。下面我会对数组和集合进行对比,并解释何时使用集合更好,以及何时使用数组更合适。 数组和集合的对比: 数组&…...
STM32之17.PWM脉冲宽度调制
一LED0脉冲宽度调制在TIM14_CHI,先将LED(PF9)代码配置为AF推挽输出模式,将PF9引脚连接到TIM14, #include <stm32f4xx.h>static GPIO_InitTypeDef GPIO_InitStruct;void Led_init(void) {//打开端口F的硬件时钟&a…...
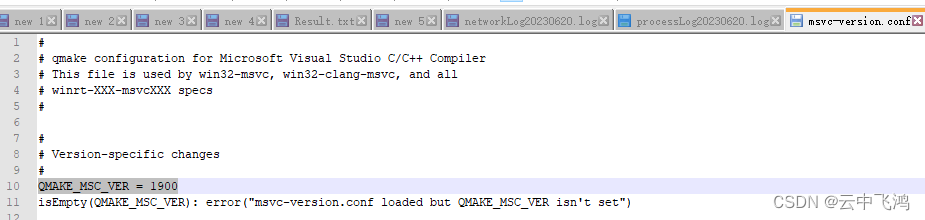
VS2015打开Qt的pro项目文件 报错
QT报错:Project ERROR: msvc-version.conf loaded but QMAKE_MSC_VER isn‘t set 解决方法: 找到本机安装的QT路径,找到“msvc-version.conf”文件,用记事本打开, 在其中添加版本“QMAKE_MSC_VER 1900”保存即可。 …...

骨传导耳机会头疼吗?骨传导耳机会对身体不好吗
一般情况下,骨传导耳机不会引起头疼。由于骨传导耳机的工作原理是通过将声音传导到颞骨和耳部周围的骨骼来传达音频信号,而不是直接进入耳道,因此不会对耳朵造成压力或产生耳疼的感觉。 然而,每个人的感受和体验可能不同ÿ…...

【面试题系列】(一)
Redis有哪些数据结构?其底层是怎么实现的? Redis 系列(一):深入了解 Redis 数据类型和底层数据结构 字符串(String): 用于存储文本或二进制数据。可以执行字符串的基本操作…...

vscode C++17便捷配置教程(懒人版)
环境链接 以上是已经配置好的c17环境链接,直接下载解压即可(注意文件路径上不要带有中文) 下载解压之后按照msys64-mingw64-bin路径打开 然后单击该路径右方空白区域可直接复制路径 然后点击开始菜单搜索“环境变量“并打开(如…...

动态数组实现链地址法哈希表
通常情况下哈希函数的输入空间远大于输出空间,因此理论上哈希冲突是不可避免的。比如,输入空间为全体整数,输出空间为数组容量大小,则必然有多个整数映射至同一数组索引。 解决哈希冲突方法常见有:链地址法、开放寻址…...
Eclipse(STS):pom.xml 报错:Multiple markers at this line
pom.xml 报错:Multiple markers at this line STS中,项目能够正常运行,但是 pom.xml 报错:Multiple markers at this line 项目本身没有任何修改,之前不报错的,突然报错了。 Multiple markers at this li…...
 - CSerialPort在MFC中的使用)
CSerialPort教程4.3.x (3) - CSerialPort在MFC中的使用
CSerialPort教程4.3.x (3) - CSerialPort在MFC中的使用 环境: 系统:windows 10 64位 编译器:Visual Studio 2008前言 CSerialPort项目是一个基于C/C的轻量级开源跨平台串口类库,可以轻松实现跨平台多操作系统的串口读写&#x…...
2022版 的IDEA创建一个maven项目(超详细)
一.设置idea中指定的maven的位置以及本地存储仓库 开发中一般我们使用自己下载的maven,不使用IDEA工具自带的,这就需要将我们下载的maven配置到IDEA工具中,配置如下图所示: 或者直接 快捷键 CtrlAltS 直接进入设置 maven home pa…...
lvs实现DR模型搭建
目录 一,实现DR模型搭建 1, 负载调度器配置 1.1调整ARP参数 1.2 配置虚拟IP地址重启网卡 1.3 安装ipvsadm 1.4 加载ip_vs模块 1.5 启动ipvsadm服务 1.6 配置负载分配策略 1.7 保存策略 2, web节点配置 1.1 调整ARP参数 1.2 配置虚拟I…...

设计模式之迭代器模式(Iterator)的C++实现
1、迭代器模式的提出 在软件开发过程中,操作的集合对象内部结构常常变化,在访问这些对象元素的同时,也要保证对象内部的封装性。迭代器模式提供了一种利用面向对象的遍历方法来遍历对象元素。迭代器模式通过抽象一个迭代器类,不同…...
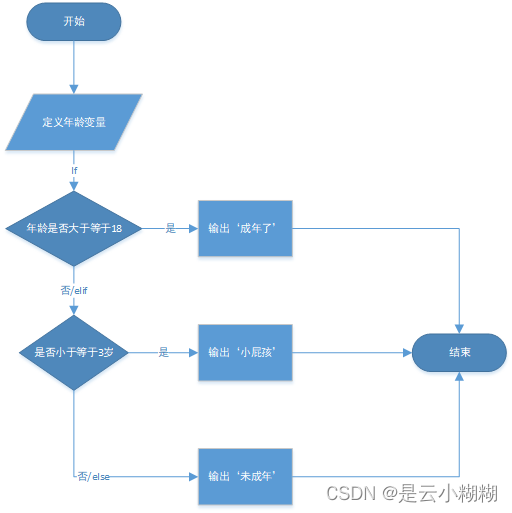
【0基础入门Python Web笔记】二、python 之逻辑运算和制流程语句
二、python 之逻辑运算和制流程语句 逻辑运算控制流程语句条件语句(if语句)循环结构(for循环、while循环)continue、break和pass关键字控制流程语句的嵌套以及elif 更多实战项目可进入下方官网 逻辑运算 Python提供基本的逻辑运算…...

容器——Docker
1.安装docker服务,配置镜像加速器 2.下载系统镜像(Ubuntu、 centos) 3.基于下载的镜像创建两个容器 (容器名一个为自己名字全拼,一个为首名字字母) 4.容器的启动、 停止及重启操作 5.怎么查看正在运行的容器…...

SQL注入之宽字节注入
文章目录 宽字节注入是什么?注入练习让转义符失效联合查询 代码审计 宽字节注入是什么? 宽字节注入准确来说不是注入手法,而是另外一种比较特殊的情况。宽字节注入的目的是绕过单双引号转义。 宽字节注入是一种绕过单双引号转义的手段&#x…...

MyBatis动态sql
文章目录 一、MyBatis动态sql1.1 概述1.2 if元素1.3 foreach元素 二、模糊查询2.1 使用#{字段名}2.2 使用${字段名}2.3 使用concat{%,#{字段名},%}2.4 mybatis中#与$的区别 三、MyBatis结果映射3.1 区别3.2 应用场景 一、MyBatis动态sql 1.1 概述 MyBatis是一个Java持久化框架…...

L1-032 Left-pad 测试点全过
题目 根据新浪微博上的消息,有一位开发者不满NPM(Node Package Manager)的做法,收回了自己的开源代码,其中包括一个叫left-pad的模块,就是这个模块把javascript里面的React/Babel干瘫痪了。这是个什么样的…...
ssm+Vue.js在线购物系统源码和论文
ssmVue.js在线购物系统源码和论文049 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势…...

暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备
暗黑2存档编辑器:免费开源工具助你轻松修改角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 暗黑2存档编辑器是一款专门为《暗黑破坏神2》玩家设计的免费开源工具,让你能够轻松修改游戏存档&…...

终极Windows激活解决方案:3分钟永久激活Windows和Office的完整指南
终极Windows激活解决方案:3分钟永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经遇到过这样的场景:新安装的Windows系统弹出…...

别再死磕梯形图了!IEC61131-3的ST语言实战:用5分钟搞定一个PID功能块
别再死磕梯形图了!IEC61131-3的ST语言实战:用5分钟搞定一个PID功能块 当PLC工程师第一次接触结构化文本(ST)时,往往会被它类似高级编程语言的语法吓退。但事实上,ST在处理复杂算法时的简洁性和高效性&#…...

连开车回家都靠肌肉记忆——芯片工程师到底有多累
下班开车,到家的时候不记得路上发生了什么。这件事很多芯片工程师都经历过。那种精神层面的透支——脑子里塞满了太多东西,意识没有余量去关注开车这件事,只能交给身体的自动驾驶。体力劳动的疲惫,睡一觉就好了。芯片研发的疲惫不…...

Instill Core:一站式AI应用构建平台,从数据处理到模型部署全流程实战
1. 项目概述:一站式AI应用构建平台如果你正在为如何将一堆杂乱无章的文档、图片、音频视频数据,转化为可供AI模型直接“食用”的格式而头疼,或者厌倦了在模型部署、API编排和数据处理工具之间反复横跳,那么Instill Core的出现&…...

OpenClaw微信公众号插件wemp v2:双Agent路由与混合知识库实战
1. 项目概述:一个为OpenClaw设计的微信公众号插件如果你正在寻找一个能够将你的AI助手能力无缝接入微信公众号,实现自动化客服、智能问答甚至更复杂交互的解决方案,那么你找对地方了。wemp(WeChat MP Plugin)正是这样一…...

SoC早期流片策略:风险控制与工程实践深度解析
1. 早期流片的风险与回报:一次深度权衡在系统级芯片开发这个行当里干了十几年,验证始终是悬在每个项目团队头顶的达摩克利斯之剑。面对动辄数亿门级、集成数十个异构核心的复杂SoC,想要在流片前达到“万无一失”的验证覆盖率,所需…...

AI任务自动化五阶段工作流:从需求到代码的可靠实践
1. 项目概述:从混乱到有序的AI任务自动化五阶段工作流上次我们聊了这套自动化系统的技术架构,把JIRA、GitHub和Cursor智能体串了起来。今天咱们不聊“怎么连”,聊聊“怎么跑”——也就是那个能把一个粗糙的需求工单,最终变成一行行…...

GroundTruth-MCP:为AI生成代码构建实时事实核查防火墙
1. 项目概述:当AI助手自信地写出过时代码时你的AI助手刚刚又“自信满满”地给你生成了一堆过时的代码。它告诉你React 19里forwardRef用得没问题,Next.js 15的cookies()还是同步函数,或者用字符串模板拼接SQL查询“既简洁又高效”。更糟的是&…...

AJV $data引用:10个终极动态验证规则实现指南 [特殊字符]
AJV $data引用:10个终极动态验证规则实现指南 🚀 【免费下载链接】ajv The fastest JSON schema Validator. Supports JSON Schema draft-04/06/07/2019-09/2020-12 and JSON Type Definition (RFC8927) 项目地址: https://gitcode.com/gh_mirrors/aj/…...