解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。
但,想要直接利用 LLM 完成一些任务会存在一些答案解析上的困难,如规范化输出格式,严格服从输入信息等。
因此,在这个项目下我们参考 ChatGLM-Tuning 的代码,尝试对大模型 ChatGLM-6B 进行 Finetune,使其能够更好的对齐我们所需要的输出格式。
1. 环境安装
由于 ChatGLM 需要的环境和该项目中其他实验中的环境有所不同,因此我们强烈建议您创建一个新的虚拟环境来执行该目录下的全部代码。
下面,我们将以 Anaconda 为例,展示如何快速搭建一个环境:
- 创建一个虚拟环境,您可以把
llm_env修改为任意你想要新建的环境名称:
conda create -n llm_env python=3.8
- 激活新建虚拟环境并安装响应的依赖包:
conda activate llm_env
pip install -r requirements.txt
- 安装对应版本的
peft:
cd peft-chatglm
python setup.py install
2. 数据集准备
在该实验中,我们将尝试使用 信息抽取 + 文本分类 任务的混合数据集喂给模型做 finetune,数据集在 data/mixed_train_dataset.jsonl。
每一条数据都分为 context 和 target 两部分:
-
context部分是接受用户的输入。 -
target部分用于指定模型的输出。
在 context 中又包括 2 个部分:
-
Instruction:用于告知模型的具体指令,当需要一个模型同时解决多个任务时可以设定不同的 Instruction 来帮助模型判别当前应当做什么任务。
-
Input:当前用户的输入。
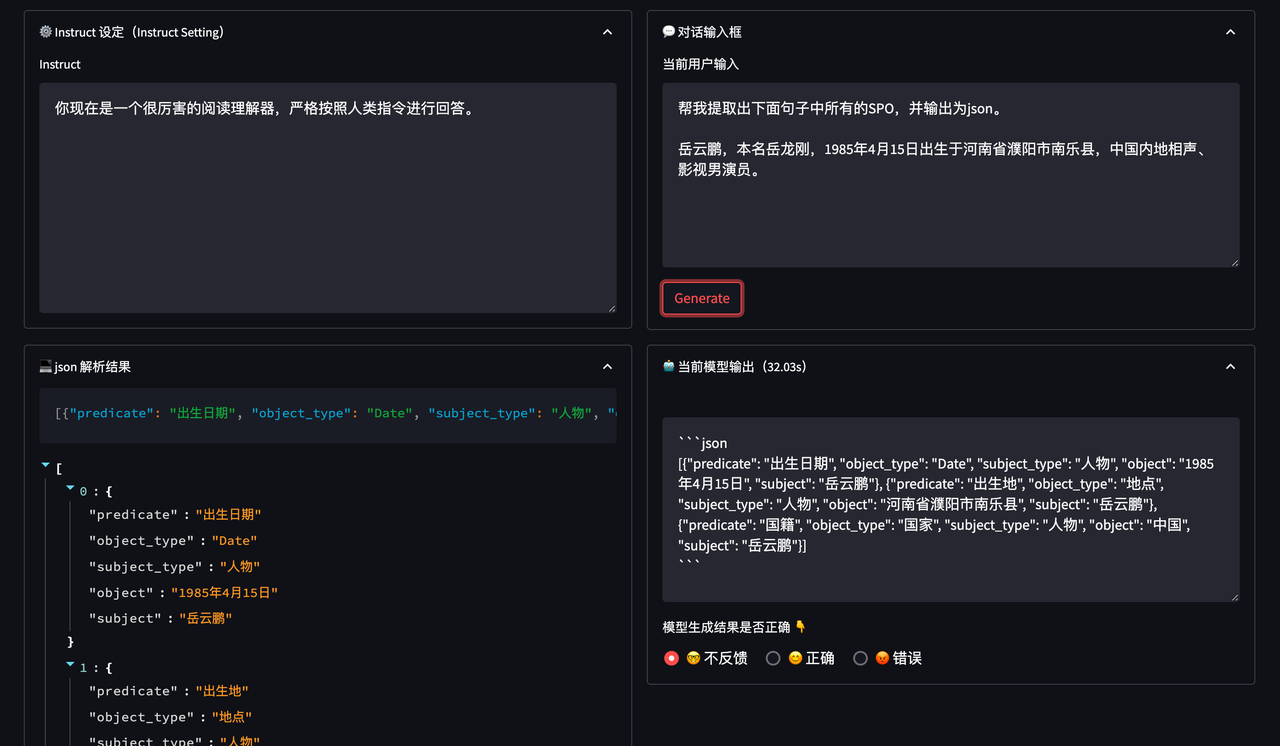
- 信息抽取数据示例
Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
{"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 找到句子中的三元组信息并输出成json给我:\n\n九玄珠是在纵横中文网连载的一部小说,作者是龙马。\nAnswer: ", "target": "```json\n[{\"predicate\": \"连载网站\", \"object_type\": \"网站\", \"subject_type\": \"网络小说\", \"object\": \"纵横中文网\", \"subject\": \"九玄珠\"}, {\"predicate\": \"作者\", \"object_type\": \"人物\", \"subject_type\": \"图书作品\", \"object\": \"龙马\", \"subject\": \"九玄珠\"}]\n```"
}
- 文本分类数据示例
Instruction 部分告诉模型现在需要做「阅读理解」任务,Input 部分告知模型要抽取的句子以及输出的格式。
{"context": "Instruction: 你现在是一个很厉害的阅读理解器,严格按照人类指令进行回答。\nInput: 下面句子可能是一条关于什么的评论,用列表形式回答:\n\n很不错,很新鲜,快递小哥服务很好,水果也挺甜挺脆的\nAnswer: ", "target": "[\"水果\"]"
}
3. 模型训练
3.1 单卡训练
实验中支持使用 LoRA Finetune 和 P-Tuning 两种微调方式。
运行 train.sh 文件,根据自己 GPU 的显存调节 batch_size, max_source_seq_len, max_target_seq_len 参数:
# LoRA Finetune
python train.py \--train_path data/mixed_train_dataset.jsonl \--dev_path data/mixed_dev_dataset.jsonl \--use_lora True \--lora_rank 8 \--batch_size 1 \--num_train_epochs 2 \--save_freq 1000 \--learning_rate 3e-5 \--logging_steps 100 \--max_source_seq_len 400 \--max_target_seq_len 300 \--save_dir checkpoints/finetune \--img_log_dir "log/fintune_log" \--img_log_name "ChatGLM Fine-Tune" \--device cuda:0# P-Tuning
python train.py \--train_path data/mixed_train_dataset.jsonl \--dev_path data/mixed_dev_dataset.jsonl \--use_ptuning True \--pre_seq_len 128 \--batch_size 1 \--num_train_epochs 2 \--save_freq 200 \--learning_rate 2e-4 \--logging_steps 100 \--max_source_seq_len 400 \--max_target_seq_len 300 \--save_dir checkpoints/ptuning \--img_log_dir "log/fintune_log" \--img_log_name "ChatGLM P-Tuning" \--device cuda:0
成功运行程序后,会看到如下界面:
...
global step 900 ( 49.89% ) , epoch: 1, loss: 0.78065, speed: 1.25 step/s, ETA: 00:12:05
global step 1000 ( 55.43% ) , epoch: 2, loss: 0.71768, speed: 1.25 step/s, ETA: 00:10:44
Model has saved at checkpoints/model_1000.
Evaluation Loss: 0.17297
Min eval loss has been updated: 0.26805 --> 0.17297
Best model has saved at checkpoints/model_best.
global step 1100 ( 60.98% ) , epoch: 2, loss: 0.66633, speed: 1.24 step/s, ETA: 00:09:26
global step 1200 ( 66.52% ) , epoch: 2, loss: 0.62207, speed: 1.24 step/s, ETA: 00:08:06
...
在 log/finetune_log 下会看到训练 loss 的曲线图:

3.2 多卡训练
运行 train_multi_gpu.sh 文件,通过 CUDA_VISIBLE_DEVICES 指定可用显卡,num_processes 指定使用显卡数:
# LoRA Finetune
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=2 train_multi_gpu.py \--train_path data/mixed_train_dataset.jsonl \--dev_path data/mixed_dev_dataset.jsonl \--use_lora True \--lora_rank 8 \--batch_size 1 \--num_train_epochs 2 \--save_freq 500 \--learning_rate 3e-5 \--logging_steps 100 \--max_source_seq_len 400 \--max_target_seq_len 300 \--save_dir checkpoints_parrallel/finetune \--img_log_dir "log/fintune_log" \--img_log_name "ChatGLM Fine-Tune(parallel)"# P-Tuning
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=2 train_multi_gpu.py \--train_path data/mixed_train_dataset.jsonl \--dev_path data/mixed_dev_dataset.jsonl \--use_ptuning True \--pre_seq_len 128 \--batch_size 1 \--num_train_epochs 2 \--save_freq 500 \--learning_rate 2e-4 \--logging_steps 100 \--max_source_seq_len 400 \--max_target_seq_len 300 \--save_dir checkpoints_parrallel/ptuning \--img_log_dir "log/fintune_log" \--img_log_name "ChatGLM P-Tuning(parallel)"
相同数据集下,单卡使用时间:
Used 00:27:18.
多卡(2并行)使用时间:
Used 00:13:05.
4. 模型预测
修改训练模型的存放路径,运行 python inference.py 以测试训练好模型的效果:
device = 'cuda:0'
max_new_tokens = 300
model_path = "checkpoints/model_1000" # 模型存放路径tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True
)model = AutoModel.from_pretrained(model_path,trust_remote_code=True
).half().to(device)
...
您也可以使用我们提供的 Playground 来进行模型效果测试:
streamlit run playground_local.py --server.port 8001
在浏览器中打开对应的 机器ip:8001 即可访问。
5. 标注平台
如果您需要标注自己的数据,也可以在 Playground 中完成。
streamlit run playground_local.py --server.port 8001
在浏览器中打开对应的 机器ip:8001 即可访问。


项目链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/LLM/chatglm_finetune/readme.md
相关文章:
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题 LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。 但,想要直接利用 LLM 完成…...
Apipost:提升API开发效率的利器
在数字化时代,API已经成为企业和开发者实现业务互通的关键工具。然而,API的开发、调试、文档编写以及测试等工作繁琐且复杂。Apipost为这一问题提供了完美的解决方案。 Apipost是一款专为API开发人员设计的协同研发平台,旨在简化API的生命周…...

论文解读:Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
发布时间:2022.4.4 (2021发布,进过多次修订) 论文地址:https://arxiv.org/pdf/2112.08088.pdf 项目地址:https://github.com/wenyyu/Image-Adaptive-YOLO 虽然基于深度学习的目标检测方法在传统数据集上取得了很好的结果…...
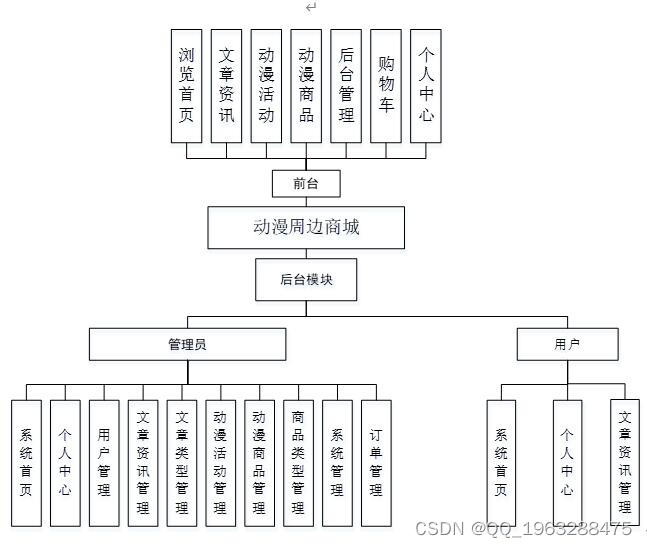
springboot 基于JAVA的动漫周边商城的设计与实现64n21
动漫周边商城分为二个模块,分别是管理员功能模块和用户功能模块。管理员功能模块包括:文章资讯、文章类型、动漫活动、动漫商品功能,用户功能模块包括:文章资讯、动漫活动、动漫商品、购物车,传统的管理方式对时间、地…...
uniapp - 全平台兼容实现上传图片带进度条功能,用户上传图像到服务器时显示上传进度条效果功能(一键复制源码,开箱即用)
效果图 uniapp小程序/h5网页/app实现上传图片并监听上传进度,显示进度条完整功能示例代码 一键复制,改下样式即可。 全部代码 记得改下样式,或直接...

第 7 章 排序算法(2)(冒泡排序)
7.5冒泡排序 7.5.1基本介绍 冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部…...

软件测试技术之可用性测试之WhatsApp Web
Tag:可行性测试、测试流程、结果分析、案例分析 WhatsApp是一款面向智能手机的网络通讯服务,它可以通过网络传送短信、图片、音频和视频。WhatsApp在全球范围内被广泛使用,是最受欢迎的即时聊天软件。 虽然,在电脑上使用WhatsAp…...

制作 Mikrotik CHR AWS AMI 镜像
文章目录 制作 Mikrotik RouterOS CHR AWS AMI 镜像前言前期准备配置 Access Key安装配置 AWS CLI创建 S3 bucket上传 Mikrotik CHR 镜像trust-policy配置role-policy 配置创建 AMI导入镜像查看导入进度导入进度查看注册镜像参考:制作 Mikrotik RouterOS CHR AWS AMI 镜像 前言…...

科技成果鉴定测试有什么意义?专业CMA、CNAS软件测评公司
科技成果鉴定测试是指通过一系列科学的实验和检测手段,对科技成果进行客观评价和鉴定的过程。通过测试,可以对科技成果的技术优劣进行评估,从而为科技创新提供参考和指导。 一、科技成果鉴定测试的意义 1、帮助客户了解科技产品的性能特点和…...

知识储备--基础算法篇-排序算法
1.知识--时间复杂度和空间复杂度 1.2时间复杂度 一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。 1.3空间复杂度 空间复杂度不是程序占用了多少bytes的空间,空间复杂度算的是变量的个…...
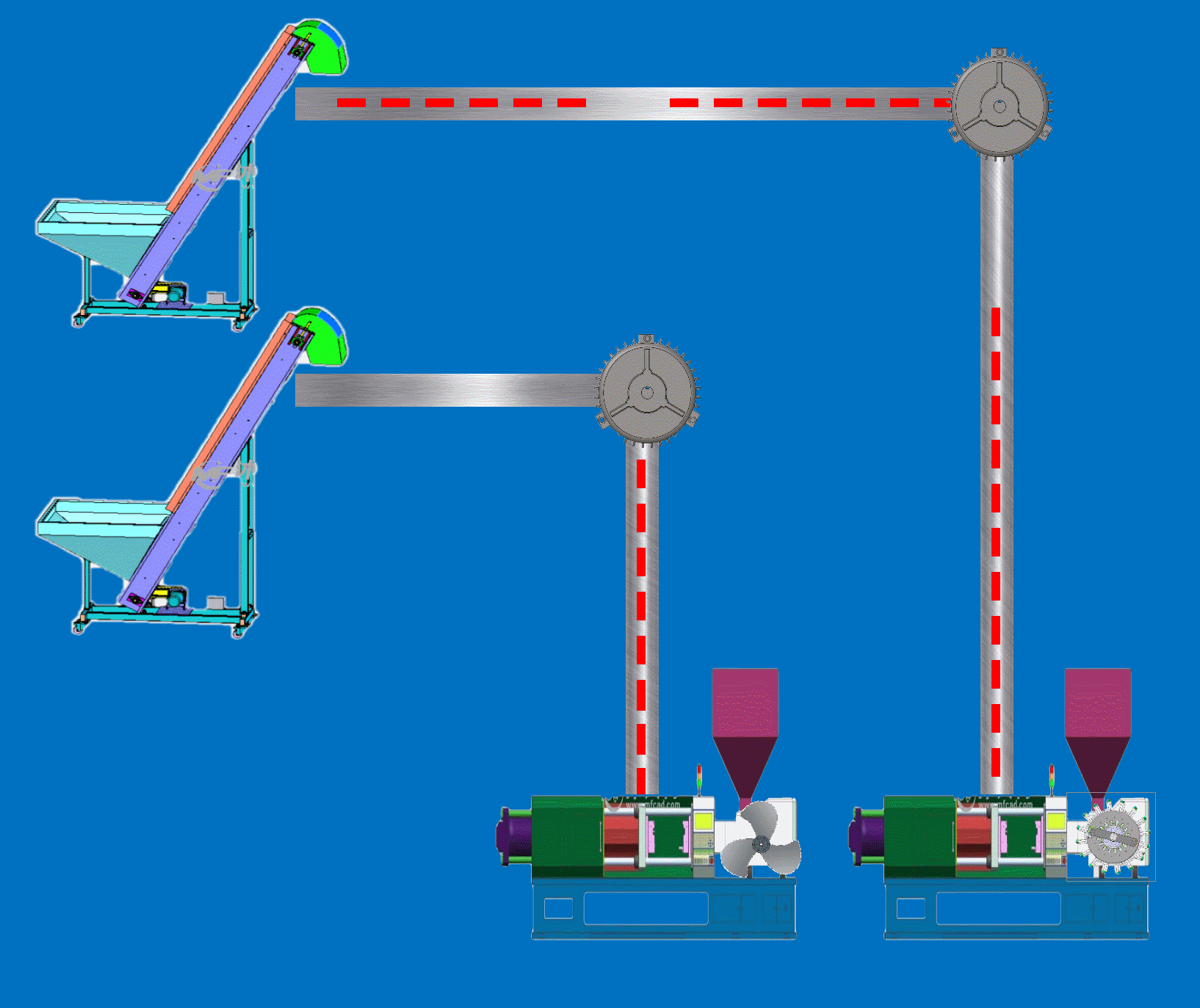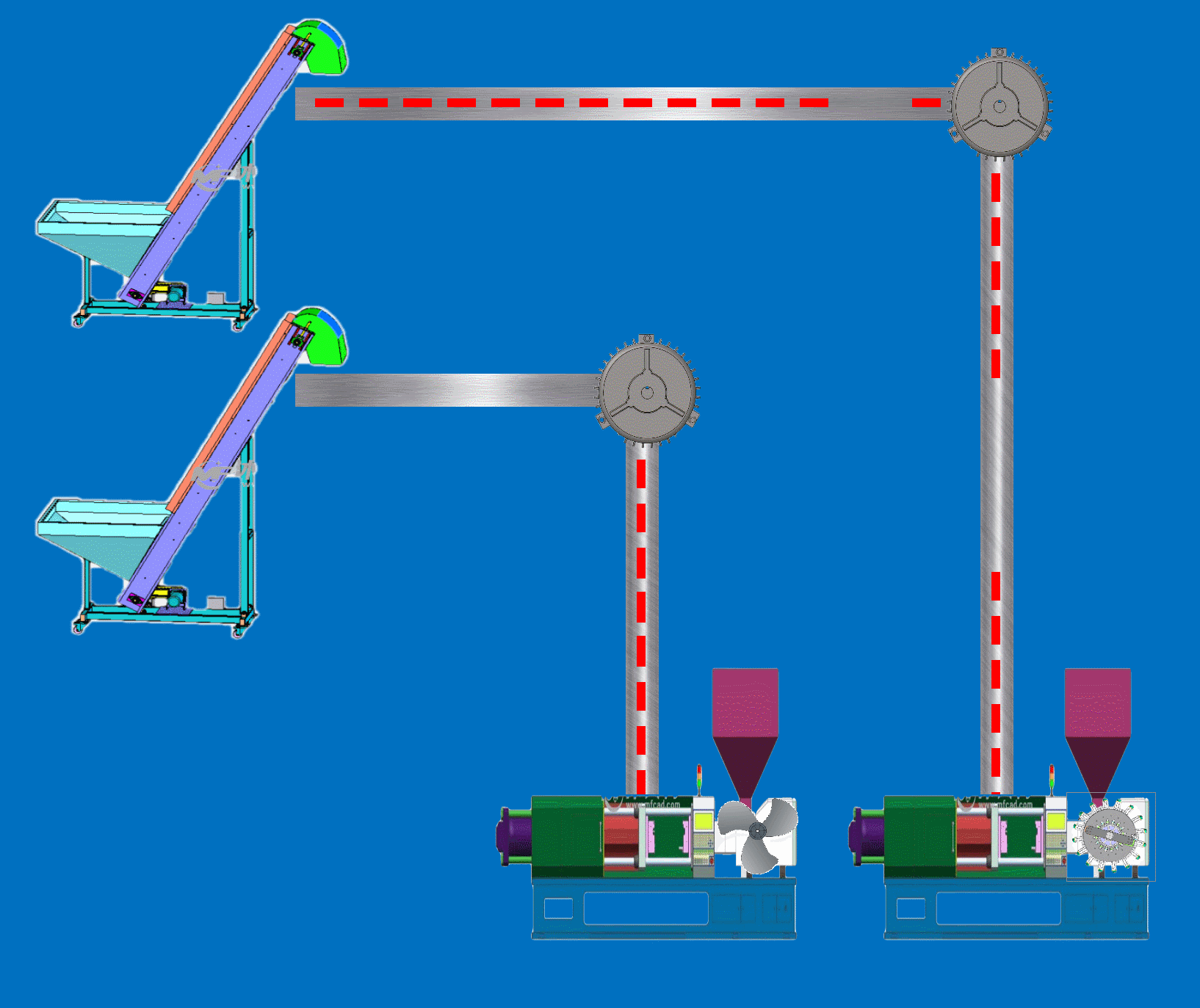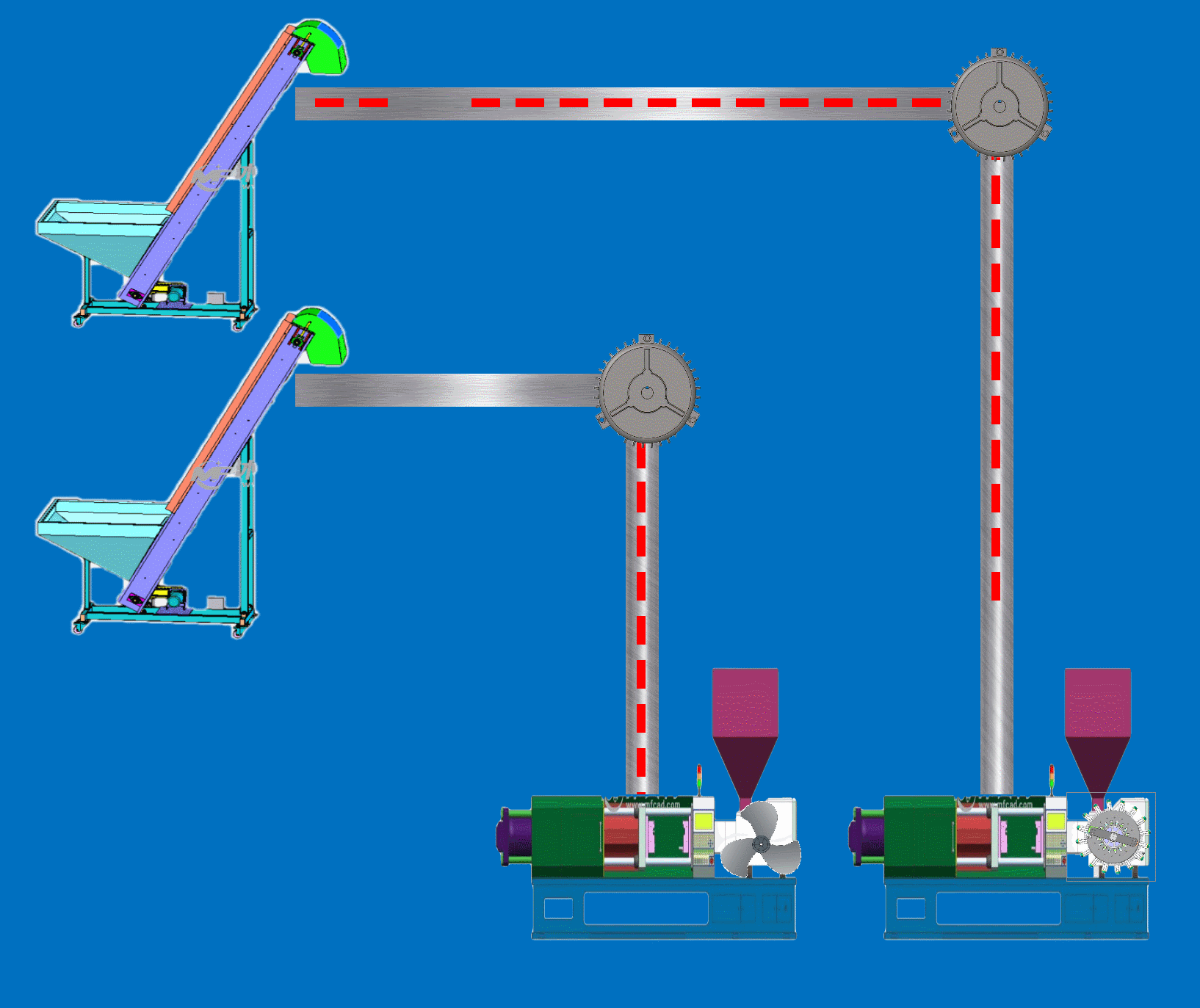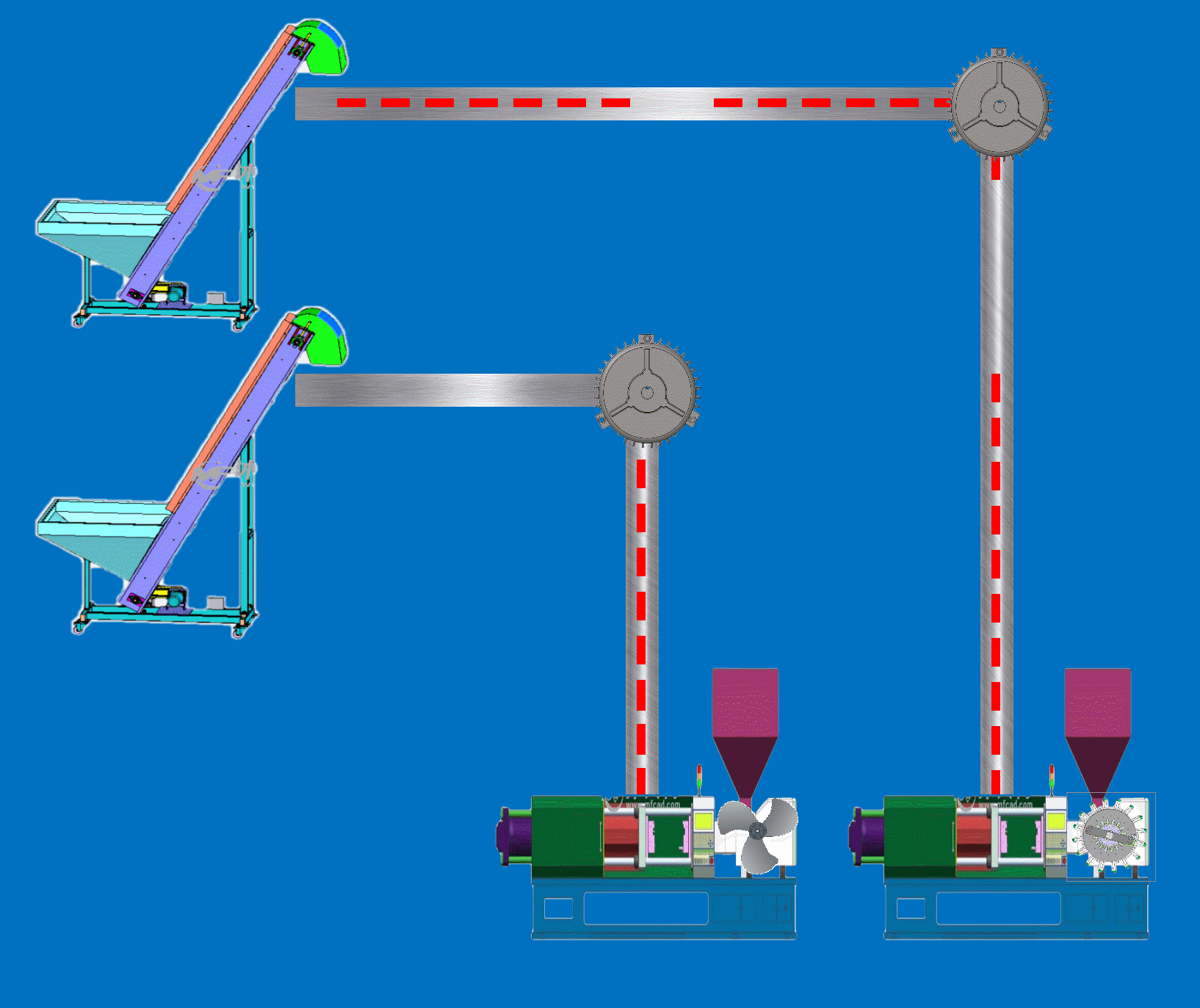
Qt+C++动力监控动画仿真SCADA上位机
程序示例精选 QtC动力监控动画仿真SCADA上位机 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对<<QtC动力监控动画仿真SCADA上位机>>编写代码,代码整洁,规则…...
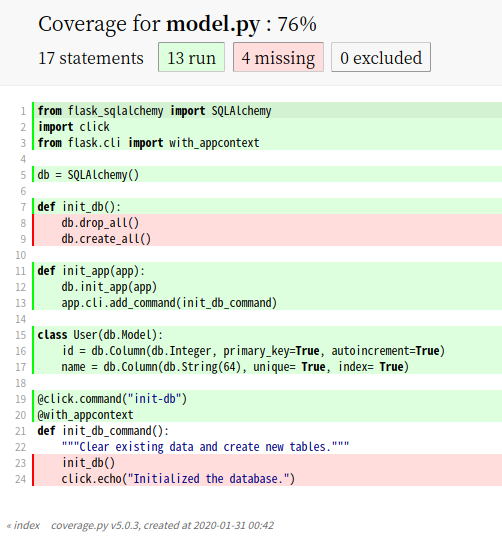
Flask 单元测试
如果一个软件项目没有经过测试,就像做的菜里没加盐一样。Flask 作为一个 Web 软件项目,如何做单元测试呢,今天我们来了解下,基于 unittest 的 Flask 项目的单元测试。 什么是单元测试 单元测试是软件测试的一种类型。顾名思义&a…...

前端面试:【前端工程化】CommonJS 与 ES6 模块
嗨,亲爱的前端开发者!在现代Web开发中,模块化是构建可维护和可扩展应用程序的关键。本文将深入探讨两种主要的JavaScript模块系统:CommonJS 和 ES6 模块,以帮助你了解它们的工作原理、用法以及如何选择合适的模块系统。…...

keepalived双机热备,keepalived+lvs(DR)
本节主要学习了keepalivedlvs的作用和配置方法主要配置调度器和web节点,还有keepalived的双击热备,主要内容有概述,安装,功能模块,配置双击热备,验证方法,双击热备的脑裂现象和VIP无法通信。 目…...

unity-ShaderGraph全节点
1.Artistic美术 Adjustment调整 Channel Mixer 混合颜色通道 Contrast 设置对比度 Hue 设置色调 range需要选normalized Invert Colors 反转颜色 Replace Color 设置两个颜色通道互换,可调参数 Saturation 设置饱和度 White Balance 白平衡(调冷暖色调&a…...

C++入门:内联函数,auto,范围for循环,nullptr
目录 1.内联函数 1.1 概念 1.2 特性 1.3 内联函数与宏的区别 2.auto关键字(C11) 2.1 auto简介 2.2 auto的使用细则 2.3 auto不能推导的场景 3.基于范围的for循环(C11) 3.1 范围for的语法 3.2 范围for的使用方法 4.指针空值nullptr(C11) 4.1 C98中的指针空值 1.内联…...

五、多表查询-1.多表关系介绍
一、概述 项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种: 一对多&a…...

Linux:编写编译脚本Makefile文件
一、生成可执行文件 1、一个源文件编译 本例子主要区别.c及.cpp文件及编译该文件时使用的编译链。 1).c文件 // testadd.c #include <stdio.h> int main() {int a 1;int b 2;int sum a b;printf("sum %d\n", sum);return 0; }// Makefie GXX g CC gcc…...

深入浅出Pytorch函数——torch.nn.init.calculate_gain
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

【PHP】PHP入门指南:从基础到进阶
PHP(Hypertext Preprocessor)是一种广泛使用的服务器端脚本语言,尤其在Web开发领域有着重要的地位。本文旨在为初学者提供一份详尽的PHP入门指南,帮助您了解PHP的基础知识和语法,掌握基本的编程技巧,并熟悉…...
)
手把手教你用STM32F103驱动TLC7528双路DAC(附完整代码与避坑指南)
手把手教你用STM32F103驱动TLC7528双路DAC(附完整代码与避坑指南) 在嵌入式开发中,数字模拟转换器(DAC)是实现数字信号到模拟信号转换的关键组件。TLC7528作为一款经典的双路8位DAC芯片,以其高性价比和简单…...

Captain AI助力Ozon大卖店群高效管理,实现规模化运营
随着Ozon商家运营规模的扩大,多店铺运营(店群)成为很多资深大卖的选择,通过多店铺布局,可扩大市场覆盖、分散运营风险、提升整体销量。但店群运营过程中,商家常常面临“管理繁琐、数据混乱、效率低下”的问…...

别再只盯着RMSE了!MATLAB里这7个模型评价指标,你用对了吗?
别再只盯着RMSE了!MATLAB里这7个模型评价指标,你用对了吗? 在数据建模的世界里,我们常常陷入一个误区:用单一指标评判模型的优劣。就像用一把尺子测量所有物体,RMSE(均方根误差)固然…...

Linux内核动态调试技术:pr_debug与dynamic_debug实战指南
1. 动态输出:内核调试的“可控探针”在Linux内核开发与调试的日常里,最让人头疼的莫过于“日志”问题。printk虽然直接,但一旦开启,信息洪流会瞬间淹没控制台,不仅影响性能,更让你在关键信息里大海捞针。更…...

深度解析MSPM0G3106数据手册:从80MHz Cortex-M0+内核到电机控制实战
1. 项目概述:为什么是MSPM0G3106?如果你最近在寻找一款兼具高性能、低功耗和成本效益的微控制器,用于电机控制、数字电源或者需要复杂模拟信号处理的场合,那么TI的MSPM0G系列很可能已经进入了你的视野。而其中的MSPM0G3106&#x…...

无王无帝定乾坤,来自田间第一人 大道同行赴新程
无王无帝定乾坤,来自田间第一人。 ——题记一、旧世终章:王权尽头的暮色朝代崛起方式落幕原因秦铁血征伐暴政失心汉布衣起义外戚乱政唐门阀更迭藩镇割据……………… “千秋岁月流转,世道几经更迭,无数王朝踏着烽烟崛起࿰…...

透明计费如何帮助精准预测与控制AI功能月度开支
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 透明计费如何帮助精准预测与控制AI功能月度开支 1. 项目背景:深度集成AI的网站 我们负责一个内容创作辅助网站&#x…...
)
【新手向】:OpenClaw 本地 AI 智能体 Windows 部署教程(包含安装包)
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置 2026 年开源圈备受关注的「数字员工」OpenClaw(昵称小龙虾),凭借本地运行 零代码操作 自动执行任务的核心优势,成为实用型本地 …...

开始举报功能测试
这说明记录添加成功,举报功能测试正常...

5分钟精通英雄联盟信息修改:LeaguePrank新手完全使用指南
5分钟精通英雄联盟信息修改:LeaguePrank新手完全使用指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 你是否曾在英雄联盟中羡慕别人的华丽段位边框,却苦于自己的段位不够理想?你是否想要…...