Elasticsearch 查询之Function Score Query
前言
ES 的主查询评分模式分为两种,是信息检索领域的重要算法: TF-IDF 算法 和 BM25 算法。
Elasticsearch 从版本 5.0 开始引入了 BM25 算法作为默认的文档评分(relevance scoring)算法。在此之前,Elasticsearch 使用的是 TF-IDF 算法作为默认的文档评分算法。从版本 5.0 起,BM25 算法取代了 TF-IDF,成为了默认的算法,用于计算文档与查询之间的相关性得分。
这个变化主要是为了更好地适应现代信息检索需求,BM25 算法在一些情况下能够提供更准确的文档排序和检索结果。
而 Function Score Query 不夸张的说是 ES 里面终极自定义打分的大招,非常的灵活并且功能强大,常规情况下,我们排序都是基于 _score 的,如果 _score相等的情况下,我们还可以额外增加排序字段,比如按日期,数量,价格等,但在搜索引擎中,排序往往并不像 SQL 那样,从左到右规整的按照多字段排序,在 SQL 里面,排序的主顺序一定是由左边的第一个字段决定的,但在搜索引擎种,却不仅仅是这样的,还可以通过 function score 做到那个字段贡献的分值大,排序顺序就以谁为主,因为这些是真实存在的需求场景,如下:
- 新闻场景:搜索具有某个关键词的文档,同时结合文档的时效性进行综合排序
- 导航场景:搜索某个地点附近的饭店,同时根据距离远近和价格等因素综合排序
- 论坛场景:搜索包含某个关键词的文章,同时根据浏览次数和点赞数进行综合排序
SQL 的排序模型
select * from table order by A, B, C搜索引擎的排序模型
query * from index oder by score max(A, B, C)写入数据
为了用实际例子讲解 function score,我们先写入几条数据
POST test01/doc/_bulk
{ "index" : { "_id" : "1" } }
{"title": "kubernetes", "content": "Development History","vote": 3,"year": 2015}
{ "index" : { "_id" : "2" } }
{"title": "kubernetes", "content": "Competitive Analysis","vote": 5,"year": 2018}
{ "index" : { "_id" : "3" } }
{"title": "kubernetes docker","content": "The connection between virtual and docker technology","vote": 100,"year": 2011}
{ "index" : { "_id" : "4" } }
{"title": "kubernetes network","content": "router vlan tcp","vote": 20,"year": 2009}查询数据
查询关键词:kubernetes
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"bool": {"should": [{"term": {"title": "kubernetes"}}]}},"explain": false
}返回结果:
"hits" : [{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.12776,"_source" : {"title" : "kubernetes","content" : "Competitive Analysis","vote" : 5,"year" : 2018}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 0.12776,"_source" : {"title" : "kubernetes","content" : "Development History","vote" : 3,"year" : 2015}},{"_index" : "test01","_type" : "doc","_id" : "4","_score" : 0.09954306,"_source" : {"title" : "kubernetes network","content" : "router vlan tcp","vote" : 20,"year" : 2009}},{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 0.081535265,"_source" : {"title" : "kubernetes mesos swarm","content" : "The connection between virtual and docker technology","vote" : 100,"year" : 2011}}]结果看起来是正常的,ok,现在我们要改变需求了,加入了基于点赞量的加权,也就是说匹配关键词并且点赞量高的优先展示,因为点赞量高意味着这些文章质量更高,所以需要优先曝光,这个时候我们就需要用到 function score
Function Score Query介绍
计算原理
使用主查询 的 TF-IDF 或者 BM25 算法得出来的默认评分简称为: query_score
使用 Function Score 查询结合自定义策略得出来的评分简称为:function_score
最终用于排序的评分称为 sort_score
在使用了 自定义的 Fuction Score 之后,我们最终得出来的 sort_score 就是使用 query_score 和 function_score以某种运算形式 (score_mode) 计算出来的,这个策略默认是相乘,也即:
sort_score = query_score * function_score
function_score内的score_mode
score_mode有六种:
| mode | 描述 |
| multiply | 多个函数 score 相乘(默认) |
| sum | 多个函数 score 求和 |
| avg | 多个函数 score 取平均值 |
| first | 使用第一个 filter 函数的 score |
| max | 取多个函数 score 中最大的那个 |
| min | 取多个函数 score 中最大的那个 |
sort_score运算策略
sort_score 是 query_score 和 function_score以某种形式运算而来,支持的运算操作也有六种:
| mode | 描述 |
| multiply | sort_score = query_score * function_score(默认) |
| sum | sort_score = query_score + function_score |
| avg | sort_score = avg ( query_score + function_score ) / 2 |
| replace | sort_score = function_score |
| max | sort_score = max ( query_score + function_score ) |
| min | sort_score = min ( query_score + function_score ) |
默认情况下,修改分数不会更改匹配的文档。要排除不满足特定分数阈值的文档,可以将 min_score 参数设置为所需的分数阈值
fuction score的评分函数
script_score
script_score 支持自定义脚本打分,也就是说可以用类编程语言的脚本来嵌入的打分逻辑,ES 之前用的是 groovy脚本因安全性有问题,现在换成了 Painless 脚本,详细可参考:Painless scripting language | Elasticsearch Guide [8.9] | Elastic
现在我们用 script_score 来完成上面查询场景中的,给点赞量的加权:
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match": { "title": "kubernetes" }},"script_score": {"script": {"params": {"baseScore": 1},"source": "params.baseScore + doc['vote'].value"}},"boost_mode": "replace","score_mode": "multiply"}},"explain": false
}结果如下:
"hits" : [{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 101.0,"_source" : {"title" : "kubernetes mesos swarm","content" : "The connection between virtual and docker technology","vote" : 100,"year" : 2011}},{"_index" : "test01","_type" : "doc","_id" : "4","_score" : 21.0,"_source" : {"title" : "kubernetes network","content" : "router vlan tcp","vote" : 20,"year" : 2009}},{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 6.0,"_source" : {"title" : "kubernetes","content" : "Competitive Analysis","vote" : 5,"year" : 2018}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 4.0,"_source" : {"title" : "kubernetes","content" : "Development History","vote" : 3,"year" : 2015}}]在这个函数查询中,我们使用了 replace 策略,来直接使用 fuction_score的分数,注意 从 docValue 里面取出来的字段必须是number 类型才可以
weight
直接对查询加权:
例子一:
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match": { "title": "kubernetes" }},"weight": 10}},"explain": false
}
结果:
"hits" : [{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 1.2775999,"_source" : {"title" : "kubernetes","content" : "Competitive Analysis","vote" : 5,"year" : 2018}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 1.2775999,"_source" : {"title" : "kubernetes","content" : "Development History","vote" : 3,"year" : 2015}},{"_index" : "test01","_type" : "doc","_id" : "4","_score" : 0.9954306,"_source" : {"title" : "kubernetes network","content" : "router vlan tcp","vote" : 20,"year" : 2009}},{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 0.8153527,"_source" : {"title" : "kubernetes mesos swarm","content" : "The connection between virtual and docker technology","vote" : 100,"year" : 2011}}]例子二:
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match_all": {}},"functions": [{"filter": { "match": { "content": "kubernetes" } },"weight": 1},{"filter": { "match": { "title": "mesos" } },"weight": 10},{"filter": { "match": { "content": "tcp" } },"weight": 20}]}},"explain": false
}结果如下:
"hits" : [{"_index" : "test01","_type" : "doc","_id" : "4","_score" : 20.0,"_source" : {"title" : "kubernetes network","content" : "router vlan tcp","vote" : 20,"year" : 2009}},{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 10.0,"_source" : {"title" : "kubernetes mesos swarm","content" : "The connection between virtual and docker technology","vote" : 100,"year" : 2011}},{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 1.0,"_source" : {"title" : "kubernetes","content" : "Competitive Analysis","vote" : 5,"year" : 2018}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 1.0,"_source" : {"title" : "kubernetes","content" : "Development History","vote" : 3,"year" : 2015}}]这个 filter 很适合竞价排名
random_score
random score 相当于把返回文档的顺序给打乱,比较适合随机召回文档
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match_all": {}},"random_score": {}}},"explain": false
}默认情况下,是每次查询的值都是随机的,但有时候我们想用同一个 id 的保持不变,不同 id 的结果随机,这个时候可以使用 seed 和 field 来控制:
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match_all": {}},"random_score": {"seed": 10,"field": "_seq_no"}}},"explain": false
}这个时候 seed 的值,就可以等同于 id,id 值一样的结果不变
field_value_factor
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match": {"title":"kubernetes"}},"field_value_factor": {"field": "vote","factor": 1.2,"modifier": "sqrt","missing": 1},"boost_mode": "max"}},"explain": false
}等价于script score 脚本 sqrt(1.2 * doc['vote'].value)
其中field 是文档种的字段,missing 是缺失值,factor 是放大的比值默认是 1,modifier 是对结果的再次处理,支持多种函数如:none, log, log1p, log2p, ln, ln1p, ln2p, square, sqrt, or reciprocal
decay functions
衰减函数
- 以某个数值作为中心点,距离多少的范围之外逐渐衰减(缩小分数)
- 以某个日期作为中心点,距离多久的范围之外逐渐衰减(缩小分数)
- 以某个地理位置点作为中心点,方圆多少距离之外逐渐衰减(缩小分数)
一个例子:
"DECAY_FUNCTION": { "FIELD_NAME": { "origin": "11, 12","scale": "2km","offset": "0km","decay": 0.33}
}上例的意思就是在距中心点方圆 2 公里之外,分数减少到三分之一(乘以 decay 的值 0.33)
DECAY_FUNCTION 可以是以下任意一种函数:
linear : 线性衰减函数
exp : 指数衰减函数
gauss : 高斯正常衰减函数origin :
用于计算距离的原点。对于数字字段,必须以数字形式给出;对于日期字段,必须以日期形式给出;对于地理字段,必须以地理点形式给出。地理和数字字段是必需的。对于日期字段,默认值为现在。 origin 支持日期数学(例如 now-1h)
scale :
定义计算得分等于衰减参数时距原点 + 偏移量的距离。对于地理字段:可以定义为数字+单位(1km、12m、...)。默认单位是米。对于日期字段:可以定义为数字+单位(“1h”、“10d”、...)。默认单位是毫秒。对于数字字段:任何数字
offset :
如果定义了偏移量,则衰减函数将仅计算距离大于定义的偏移量的文档的衰减函数。默认值为 0
decay :
衰减参数定义如何在给定比例的距离上对文档进行评分。如果未定义衰减,则距离尺度上的文档将评分为 0.5
例如,现在新数据,标题匹配 kubernetes 后,按照优先检索位于 2011-2015 年份进行加权,不再按照点赞量:
GET test01/_search?search_type=dfs_query_then_fetch
{"query": {"function_score": {"query": {"match": {"title":"kubernetes"}},"gauss": {"year": {"origin": "2013", "offset": "2","scale": "2","decay": 0.1 }},"boost_mode": "max"}},"explain": false
}解释一下:
上面使用高斯函数作为衰减,使用的是年份字段:
orgin:代表中心点是 2013 年
offset:2 代表 [2011, 2015] 作为中心圆,也就是 [2011, 2015]位于这之间的文档评分直接为 1
scala: 2 代表 [2009, 2017]之外的评分为 0.1
其他的,如果位于 2009-2011 范围的以及 2015-2017 范围的,就按正常评分就好了
结果如下:
"hits" : [{"_index" : "test01","_type" : "doc","_id" : "3","_score" : 1.0,"_source" : {"title" : "kubernetes mesos swarm","content" : "The connection between virtual and docker technology","vote" : 100,"year" : 2011}},{"_index" : "test01","_type" : "doc","_id" : "1","_score" : 1.0,"_source" : {"title" : "kubernetes","content" : "Development History","vote" : 3,"year" : 2015}},{"_index" : "test01","_type" : "doc","_id" : "2","_score" : 0.12776,"_source" : {"title" : "kubernetes","content" : "Competitive Analysis","vote" : 5,"year" : 2018}},{"_index" : "test01","_type" : "doc","_id" : "4","_score" : 0.1,"_source" : {"title" : "kubernetes network","content" : "router vlan tcp","vote" : 20,"year" : 2009}}]三种衰减的函数的曲线如下:
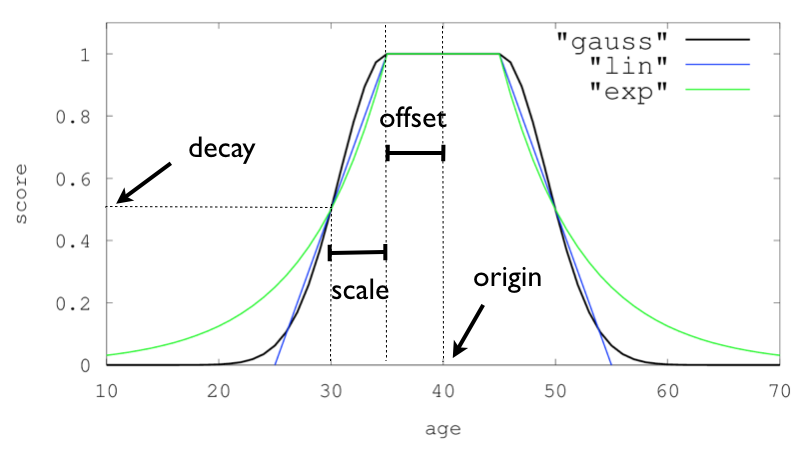
此外,如果用于计算衰减的字段包含多个值,则默认情况下会选择最接近中心点的值来确定距离。这可以通过设置 multi_value_mode 来更改:
min:距离是最小距离
max:距离是最大距离
avg:距离是平均距离
sum:距离是所有距离的总和
"DECAY_FUNCTION": {"FIELD_NAME": {"origin": ...,"scale": ...},"multi_value_mode": "avg"}function score 的其他参数
max_boost: 最大权重值的范围
boost_mode: 最终 query_score 和 function_score的计算策略
min_score: 最终的结果过滤掉评分低于这个值的
相关文章:
Elasticsearch 查询之Function Score Query
前言 ES 的主查询评分模式分为两种,是信息检索领域的重要算法: TF-IDF 算法 和 BM25 算法。 Elasticsearch 从版本 5.0 开始引入了 BM25 算法作为默认的文档评分(relevance scoring)算法。在此之前,Elasticsearch 使…...

【3D激光SLAM】LOAM源代码解析--scanRegistration.cpp
系列文章目录 【3D激光SLAM】LOAM源代码解析–scanRegistration.cpp 【3D激光SLAM】LOAM源代码解析–laserOdometry.cpp 【3D激光SLAM】LOAM源代码解析–laserMapping.cpp 【3D激光SLAM】LOAM源代码解析–transformMaintenance.cpp 写在前面 本系列文章将对LOAM源代码进行讲解…...

解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题 LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。 但,想要直接利用 LLM 完成…...
Apipost:提升API开发效率的利器
在数字化时代,API已经成为企业和开发者实现业务互通的关键工具。然而,API的开发、调试、文档编写以及测试等工作繁琐且复杂。Apipost为这一问题提供了完美的解决方案。 Apipost是一款专为API开发人员设计的协同研发平台,旨在简化API的生命周…...

论文解读:Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
发布时间:2022.4.4 (2021发布,进过多次修订) 论文地址:https://arxiv.org/pdf/2112.08088.pdf 项目地址:https://github.com/wenyyu/Image-Adaptive-YOLO 虽然基于深度学习的目标检测方法在传统数据集上取得了很好的结果…...
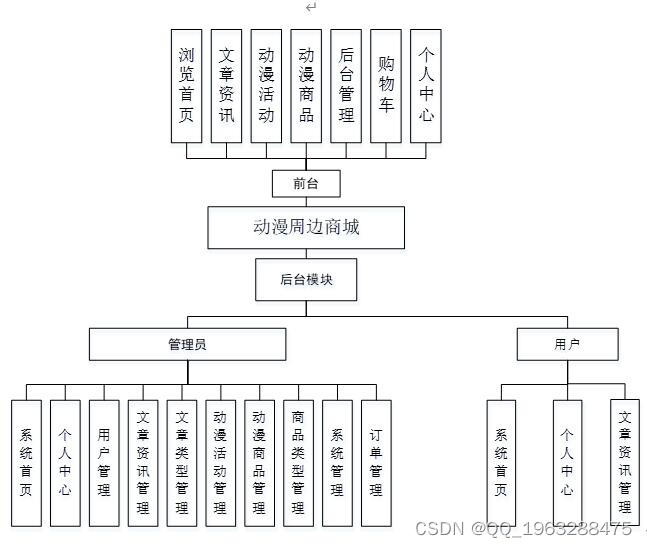
springboot 基于JAVA的动漫周边商城的设计与实现64n21
动漫周边商城分为二个模块,分别是管理员功能模块和用户功能模块。管理员功能模块包括:文章资讯、文章类型、动漫活动、动漫商品功能,用户功能模块包括:文章资讯、动漫活动、动漫商品、购物车,传统的管理方式对时间、地…...
uniapp - 全平台兼容实现上传图片带进度条功能,用户上传图像到服务器时显示上传进度条效果功能(一键复制源码,开箱即用)
效果图 uniapp小程序/h5网页/app实现上传图片并监听上传进度,显示进度条完整功能示例代码 一键复制,改下样式即可。 全部代码 记得改下样式,或直接...

第 7 章 排序算法(2)(冒泡排序)
7.5冒泡排序 7.5.1基本介绍 冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部…...

软件测试技术之可用性测试之WhatsApp Web
Tag:可行性测试、测试流程、结果分析、案例分析 WhatsApp是一款面向智能手机的网络通讯服务,它可以通过网络传送短信、图片、音频和视频。WhatsApp在全球范围内被广泛使用,是最受欢迎的即时聊天软件。 虽然,在电脑上使用WhatsAp…...

制作 Mikrotik CHR AWS AMI 镜像
文章目录 制作 Mikrotik RouterOS CHR AWS AMI 镜像前言前期准备配置 Access Key安装配置 AWS CLI创建 S3 bucket上传 Mikrotik CHR 镜像trust-policy配置role-policy 配置创建 AMI导入镜像查看导入进度导入进度查看注册镜像参考:制作 Mikrotik RouterOS CHR AWS AMI 镜像 前言…...

科技成果鉴定测试有什么意义?专业CMA、CNAS软件测评公司
科技成果鉴定测试是指通过一系列科学的实验和检测手段,对科技成果进行客观评价和鉴定的过程。通过测试,可以对科技成果的技术优劣进行评估,从而为科技创新提供参考和指导。 一、科技成果鉴定测试的意义 1、帮助客户了解科技产品的性能特点和…...

知识储备--基础算法篇-排序算法
1.知识--时间复杂度和空间复杂度 1.2时间复杂度 一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法的时间复杂度。 1.3空间复杂度 空间复杂度不是程序占用了多少bytes的空间,空间复杂度算的是变量的个…...
Qt+C++动力监控动画仿真SCADA上位机
程序示例精选 QtC动力监控动画仿真SCADA上位机 如需安装运行环境或远程调试,见文章底部个人QQ名片,由专业技术人员远程协助! 前言 这篇博客针对<<QtC动力监控动画仿真SCADA上位机>>编写代码,代码整洁,规则…...
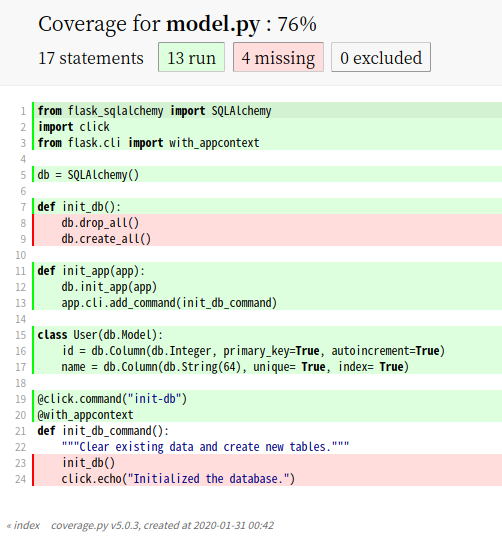
Flask 单元测试
如果一个软件项目没有经过测试,就像做的菜里没加盐一样。Flask 作为一个 Web 软件项目,如何做单元测试呢,今天我们来了解下,基于 unittest 的 Flask 项目的单元测试。 什么是单元测试 单元测试是软件测试的一种类型。顾名思义&a…...

前端面试:【前端工程化】CommonJS 与 ES6 模块
嗨,亲爱的前端开发者!在现代Web开发中,模块化是构建可维护和可扩展应用程序的关键。本文将深入探讨两种主要的JavaScript模块系统:CommonJS 和 ES6 模块,以帮助你了解它们的工作原理、用法以及如何选择合适的模块系统。…...

keepalived双机热备,keepalived+lvs(DR)
本节主要学习了keepalivedlvs的作用和配置方法主要配置调度器和web节点,还有keepalived的双击热备,主要内容有概述,安装,功能模块,配置双击热备,验证方法,双击热备的脑裂现象和VIP无法通信。 目…...

unity-ShaderGraph全节点
1.Artistic美术 Adjustment调整 Channel Mixer 混合颜色通道 Contrast 设置对比度 Hue 设置色调 range需要选normalized Invert Colors 反转颜色 Replace Color 设置两个颜色通道互换,可调参数 Saturation 设置饱和度 White Balance 白平衡(调冷暖色调&a…...

C++入门:内联函数,auto,范围for循环,nullptr
目录 1.内联函数 1.1 概念 1.2 特性 1.3 内联函数与宏的区别 2.auto关键字(C11) 2.1 auto简介 2.2 auto的使用细则 2.3 auto不能推导的场景 3.基于范围的for循环(C11) 3.1 范围for的语法 3.2 范围for的使用方法 4.指针空值nullptr(C11) 4.1 C98中的指针空值 1.内联…...

五、多表查询-1.多表关系介绍
一、概述 项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种: 一对多&a…...

Linux:编写编译脚本Makefile文件
一、生成可执行文件 1、一个源文件编译 本例子主要区别.c及.cpp文件及编译该文件时使用的编译链。 1).c文件 // testadd.c #include <stdio.h> int main() {int a 1;int b 2;int sum a b;printf("sum %d\n", sum);return 0; }// Makefie GXX g CC gcc…...

NCM解密终极指南:3步解锁网易云音乐加密文件
NCM解密终极指南:3步解锁网易云音乐加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在官方客户端播放,无法在其他设备或播放器上欣赏&…...

H5GG完整指南:如何用JavaScript和HTML5轻松修改iOS游戏内存
H5GG完整指南:如何用JavaScript和HTML5轻松修改iOS游戏内存 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 你是否曾经想过修改iOS游戏中的数值,却因为复杂的越…...

为OpenClaw配置Taotoken作为自定义模型供应商的详细指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为自定义模型供应商的详细指南 OpenClaw是一个流行的开源Agent框架,它允许开发者灵活地配置和…...

从汽车电子到工业控制:手把手教你用STM32CubeMX和HAL库玩转CAN总线多节点通信
从零构建工业级CAN总线通信系统:基于STM32CubeMX的实战指南 1. CAN总线技术基础与工业应用场景 在现代工业控制系统中,CAN总线因其高可靠性和实时性已成为设备间通信的事实标准。不同于普通串行通信,CAN采用差分信号传输和先进的错误检测机…...

Overleaf实战:利用multicol宏包实现LaTeX文档的灵活分栏布局
1. 为什么需要分栏布局? 第一次用LaTeX写论文时,我被期刊模板要求"双栏排版"整懵了。单栏文档写得好好的,突然要在同一页并排显示两列内容,还要处理图片表格的跨栏问题。传统\twocolumn命令虽然简单,但调整…...

cube studio开源一站式云原生机器学习平台--pytorch分布式训练
全栈工程师开发手册 (作者:栾鹏) 一站式云原生机器学习平台 前言 开源地址:https://github.com/data-infra/cube-studio cube studio 开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户,…...

MindStudio组合技,让Host Bound问题看得见、调得准
背景介绍:Host Bound问题在NPU训练和推理场景中,Host侧(CPU)的任务下发(如算子调度、内存分配)与Device侧(NPU)的任务执行是异步进行的。当Host侧任务下发耗时超过Device侧任务执行耗…...

别再乱调了!Unity Shader中ZWrite的‘开’与‘关’,一份给程序员的避坑实践指南
Unity Shader深度写入实战:ZWrite的正确打开方式 1. 深度写入的底层逻辑 在计算机图形学中,深度缓冲(Depth Buffer)是一个至关重要的概念。它本质上是一个二维数组,存储了每个像素距离摄像机的深度值。当Unity渲染场景…...

告别手动计算!用Python+ArcPy脚本批量搞定MODIS ET数据从8天到月均值的完整流程
从8天到月均值:PythonArcPy全自动处理MODIS ET数据的工程实践 当面对跨越多年、覆盖大区域的MOD16A2数据集时,传统的手工操作不仅效率低下,还容易引入人为错误。本文将展示如何用PythonArcPy构建一套完整的自动化流程,实现从原始8…...

Windows HEIC缩略图插件:为什么你的iPhone照片在Windows上无法预览?
Windows HEIC缩略图插件:为什么你的iPhone照片在Windows上无法预览? 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumb…...