总结记录Keras开发构建神经网络模型的三种主流方式:序列模型、函数模型、子类模型
Keras是一个易于使用且功能强大的神经网络建模库,它是基于Python语言开发的。Keras提供了高级API,使得用户能够轻松地定义和训练神经网络模型,无论是用于分类、回归还是其他任务。

Keras的主要特点如下:
-
简单易用:Keras的设计理念是用户友好性,它提供了简洁一致的API,使得模型的构建、训练、评估以及部署变得非常简单。不需要编写大量底层代码,可以快速实现模型。
-
多后端支持:Keras支持多个深度学习后端,包括TensorFlow、Theano和CNTK。用户可以根据自己的需要选择合适的后端,进行模型开发。而TensorFlow的2.0版本中已经将Keras纳入其中,成为其官方高层API。
-
多种建模方式:Keras提供了不同的建模方式,包括序列模型(Sequential Model)、函数模型(Functional Model)和子类模型(Subclassing Model)。用户可以根据需要选择适合的建模方式,从简单的线性模型到复杂的非线性模型都可以构建。
-
大量预定义层和模型:Keras提供了丰富的预定义层(例如,全连接层、卷积层、池化层等)和模型(例如,VGG、ResNet等),用户可以直接使用这些层和模型,加快模型开发的速度。
-
支持自定义层和损失函数:Keras支持用户自定义层和损失函数,用户可以根据自己的需求自定义特定的层或损失函数,并与其他预定义层和损失函数进行组合。
如果之前有参考过我的博文的话应该会有所了解,我基本上90%的项目都是基于keras+Tensorflow构建的,而基于PyTorch的相关项目开发实践会偏少一下,因为最初入坑深度学习的时候就是接触的Tensorflow,现在是想要系统性地梳理对比学习一下。
本文就以最为熟悉的keras来入手,系统性地总结回顾一下keras搭建模型的主流方式。Keras提供了三种主要的建模方式:序列模型、函数模型和子类模型。下面对每种方式进行详细介绍。
1. 序列模型(Sequential Model):
序列模型是Keras中最简单的一种建模方式,它通过将层(Layer)按顺序堆叠来构建神经网络模型。每个层之间只有一个输入和一个输出。这种方式适用于简单的线性堆叠模型或者只有单一输入/输出的模型。
序列模型的建模步骤如下:
- 导入`Sequential`类和需要使用的层(例如,`Dense`、`Conv2D`、`MaxPooling2D`等)。
- 使用`Sequential`类创建一个模型实例。
- 通过调用模型实例的`add`方法逐步添加层到模型中。
- 使用`compile`方法配置模型的优化器、损失函数和评估指标。
- 使用`fit`方法对模型进行训练。
- 使用`evaluate`方法对模型进行评估。
如果说是搭建比较基础的模型没有什么残差连接、多分支结构等特殊网络链路的话,这种方式一定会是首选,非常的简单易懂,直至现在我依旧觉得keras的可读性非常高,对于学习和理解来说是非常友好的,这里以Mnist数据集为例,给出来实例实现:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 数据预处理
x_train = x_train.reshape(-1, 784).astype('float32') / 255.0
x_test = x_test.reshape(-1, 784).astype('float32') / 255.0
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)# -----------------------------
# 使用序列模型建立模型
model = Sequential([Dense(64, activation='relu', input_shape=(784,)),Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))# 模型评估
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test Accuracy:', test_acc)
2. 函数模型(Functional Model):
函数模型是一种更为灵活的建模方式,它允许构建具有多个输入和多个输出的模型,以及包含层共享和跳跃连接的复杂模型。通过在层之间创建显式的数据流图,可以构建非线性的模型结构。
函数模型的建模步骤如下:
- 导入`Model`类和需要使用的层(例如,`Input`、`Conv2D`、`MaxPooling2D`等)。
- 创建模型的输入张量(`Input`),并将其传递给需要连接该输入的层。
- 通过将每个层的输出连接到下一个层的输入来构建模型。
- 使用`Model`类指定模型的输入和输出,创建一个模型实例。
- 使用`compile`方法配置模型的优化器、损失函数和评估指标。
- 使用`fit`方法对模型进行训练。
- 使用`evaluate`方法对模型进行评估。
这种方式我平时使用的频次也是很高的,简单一句话总结就是:序列模型能完成的函数模型都能完成,函数模型能完成的序列模型未必能完成,如果只是想要学习掌握一种主流方式的话可以直接选择函数模型,像经典的残差网络、多分支网络结构等等都是基于函数模型进行搭建的。这里同样以Mnist数据集为例给出代码实例:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 数据预处理
x_train = x_train.reshape(-1, 784).astype('float32') / 255.0
x_test = x_test.reshape(-1, 784).astype('float32') / 255.0
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)# 使用函数式模型建立模型
inputs = tf.keras.Input(shape=(784,))
x = Dense(64, activation='relu')(inputs)
outputs = Dense(10, activation='softmax')(x)model = tf.keras.Model(inputs=inputs, outputs=outputs)model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test Accuracy:', test_acc)
3. 子类模型(Subclassing Model):
子类模型是使用Python的继承机制构建模型的一种方式,它提供了最大的灵活性,可以按照需要自定义前向传播逻辑和反向传播逻辑。通过编写一个继承自`Model`类的子类,可以完全自定义模型的构建过程。
子类模型的建模步骤如下:
- 导入`Model`类和需要使用的层(例如,`Dense`、`Conv2D`、`MaxPooling2D`等)。
- 创建一个继承自`Model`类的子类,定义类的`__init__`方法,其中实例化模型层和变量。
- 在子类中定义`call`方法,实现模型的前向传播逻辑。
- 创建模型的实例。
- 使用`compile`方法配置模型的优化器、损失函数和评估指标。
- 使用`fit`方法对模型进行训练。
- 使用`evaluate`方法对模型进行评估。
这种方式的使用频度,主要也是这种方式实现起来也是相对更加复杂一点的,而且对于模型的保存还有问题,所以对于我自己来说,这种子类模型的构建方式本身使用频度不高,这里同样以Mnist数据集为例给出代码实例:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 数据预处理
x_train = x_train.reshape(-1, 784).astype('float32') / 255.0
x_test = x_test.reshape(-1, 784).astype('float32') / 255.0
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)# 使用子类模型建立模型
class MyModel(tf.keras.Model):def __init__(self):super(MyModel, self).__init__()self.dense1 = Dense(64, activation='relu')self.dense2 = Dense(10, activation='softmax')def call(self, inputs):x = self.dense1(inputs)outputs = self.dense2(x)return outputsmodel = MyModel()model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test Accuracy:', test_acc)相关文章:
总结记录Keras开发构建神经网络模型的三种主流方式:序列模型、函数模型、子类模型
Keras是一个易于使用且功能强大的神经网络建模库,它是基于Python语言开发的。Keras提供了高级API,使得用户能够轻松地定义和训练神经网络模型,无论是用于分类、回归还是其他任务。 Keras的主要特点如下: 简单易用:Kera…...

python环境建设
1. 查看通过pip安装包的路径 问题:devchat vscode中配置需要查找devchat的安装路径,使用pip相关的命令查看 pip list | grep package_name 命令显示获取已安装包的信息(包名与版本号)pip show package_name命令能显示该安装的包…...
)
Python学习笔记第五十九天(Matplotlib 安装)
Python学习笔记第五十九天 Matplotlib 安装后记 Matplotlib 安装 本章节,我们使用 pip 工具来安装 Matplotlib 库,如果还未安装该工具,可以参考 Python pip 安装与使用。 如果您还没有安装Matplotlib,您可以按照以下步骤在Pytho…...

(6)(6.3) 自动任务中的相机控制
文章目录 前言 6.3.1 概述 6.3.2 自动任务类型 6.3.3 创建合成图像 前言 本文介绍 ArduPilot 的相机和云台命令,并说明如何在 Mission Planner 中使用这些命令来定义相机勘测任务。这些说明假定已经连接并配置了相机触发器和云台(camera trigger and gimbal ha…...

什么是cssreset ?为什么要用到cssreset?
1,什么是cssreset ? 顾名思义,css reset,样式重置。即重新设置界面的样式。 CSS reset,又叫做 CSS 重写或者 CSS 重置,用于改写HTML标签的默认样式。 有些HTML标签在浏览器里有默认的样式,例如 p 标签有上…...

SpringCloud学习笔记(四)_ZooKeeper注册中心
基于Spring Cloud实现服务的发布与调用。而在18年7月份,Eureka2.0宣布停更了,将不再进行开发,所以对于公司技术选型来说,可能会换用其他方案做注册中心。本章学习便是使用ZooKeeper作为注册中心。 本章使用的zookeeper版本是 3.6…...
【算法专题突破】双指针 - 移动零(1)
目录 写在前面 1. 题目解析 2. 算法原理 3. 代码编写 写在最后: 写在前面 在进行了剑指Offer和LeetCode hot100的毒打之后, 我决心系统地学习一些经典算法,增强我的综合算法能力。 1. 题目解析 题目链接:283. 移动零 - 力…...
Nginx高可用集群
目录 一.简介二.案例1.实现思路2.配置文件修改3.实现效果故障转移机制 一.简介 以提高应用系统的可靠性,尽可能地减少中断时间为目标,确保服务的连续性,达到高可用的容错效果。例如“故障切换”、“双机热备”、“多机热备”等都属于高可用集…...

Rust 基础入门 ——所有权 引言 :垃圾自动回收机制的缺陷。
在以往,内存安全几乎都是通过 GC 的方式实现,但是 GC 会引来性能、内存占用以及 Stop the world 等问题,在高性能场景和系统编程上是不可接受的, 我们先介绍一下这些概念都是什么: 内存安全是指程序在运行过程中不会访…...

Ubuntu20.04安装软件报错:The following packages have unmet dependencies
Ubuntu20.04更换阿里云源后安装软件都会报错:The following packages have unmet dependencies 查看资料,大概是ubuntu本身的源比较版本较老,而阿里云的源比较新,因此版本不匹配造成依赖的库不匹配,所以只要将阿里云的…...
:享元模式)
Java 与设计模式(12):享元模式
一、定义 享元模式是一种结构型设计模式,旨在有效地共享对象以减少内存使用和提高性能。该模式的核心思想是通过共享尽可能多的相似对象来减少内存占用。它将对象分为可共享的内部状态和不可共享的外部状态。内部状态是对象的固有属性,可以在多个对象之…...
)
React配置代理(proxy)
使用axios进行请求,而配置代理过程。 第一种 在package.json中,添加proxy配置项,之后所有的请求都会指向该地址 但这种方法只能配置一次,也只有一个 示例: "proxy":"https://localhost:5000" 添加后&am…...
队列(Queue):先进先出的数据结构队列
栈与队列https://blog.csdn.net/qq_45467165/article/details/127958960?csdn_share_tail%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22127958960%22%2C%22source%22%3A%22qq_45467165%22%7D 队列(Queue)是一种常见的线…...

CentOS ens160 显示disconnected
使用nmcli device查看网卡状态,显示如图: 检查宿主机系统VMware DHCP Sevice和VMware NAT Sevice服务是否正常运行。 右键点击我的电脑管理按钮,打开计算机管理点击服务...

使用 ChatGPT 创建 PowerPoint 演示文稿
让 ChatGPT 成为您的助手来帮助您编写电子邮件很简单,因为众所周知,它非常能够生成文本。很明显,ChatGPT 无法帮助您做饭。但您可能想知道它是否可以生成文本以外的其他内容。在上一篇文章中,您了解到 ChatGPT 只能通过中间语言为您生成图形。在这篇文章中,您将了解使用中…...
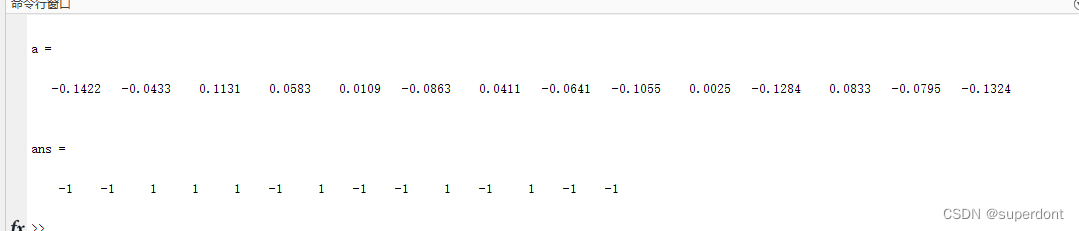
matlab将数组值划分为两类
例如:大于0的处理为1,小于0的处理为-1. 当然,可以选择循环结构和选择结构,但是效率会很低。 这里直接使用逻辑语句完成。 % 不使用循环语句,将数组内值划分为两类 clc; clearvars; a[-0.1422 , -0.0433 , 0.1131 …...
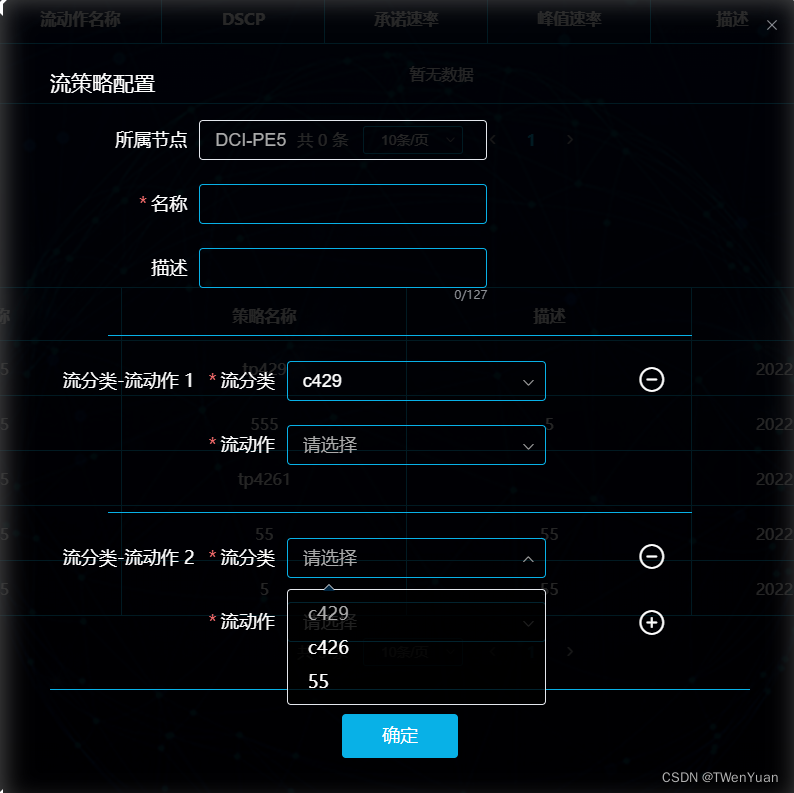
【点击新增一个下拉框 与前一个内容一样 但不能选同一个值】
点击新增一个下拉框 与前一个内容一样 但不能选同一个值 主要是看下拉选择el-option的disabled,注意不要混淆 <el-form label-width"120px" :model"form" ref"form" style"color: #fff"><template v-for"(trapolicy, i…...
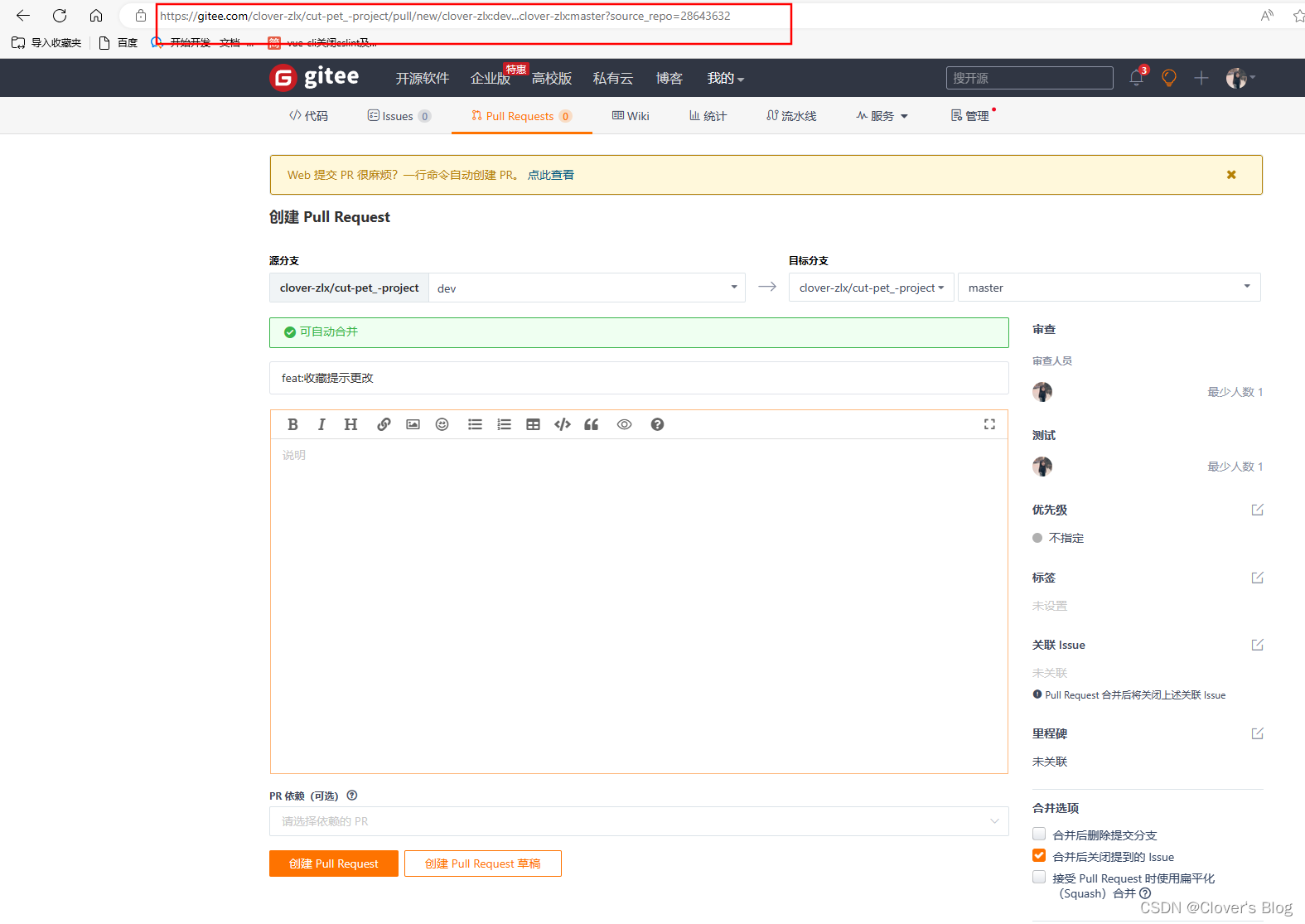
【Gitee提交pr】
Gitee提交pr 什么是pr怎样提交一个pr嘞? 什么是pr pr:指的是将自己的修改从自己的账号仓库dev下提交到官方账号仓库master下; 通俗来讲就是Gitee线上有属于自己的分支,然后本地在自己地分支修改完代码之后,提交到自己的线上分支&a…...
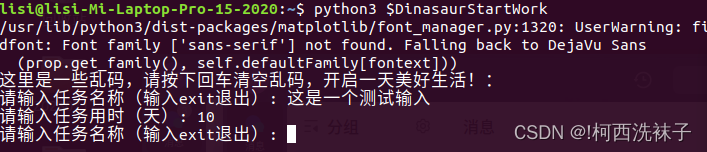
一款打工人必备的电脑端自律软件!!冲鸭打工人!!
你!有没有渴望进步!! 你!有没有渴望变强!!! 成为大佬!!!超越巨佬!!! 这就是一款为这样的你量身定做的程序:输入…...

【Vue框架】 router和route是什么关系
前言 之前没太注意,写着写着突然发现它们貌似不太一样,记录以下,回顾的看总结就好。 1、总结✨ route:当前激活路由的对象,用于访问和操作当前路由的信息 router:管理多个route的对象,整个应…...

《从GIS前端到AIGC大厂:WebGIS、WebGL、Three.js技术栈的底层能力拆解与岗位适配指南》
前端GIS技术栈:从图形学底层到AIGC营销增长的全链路实战指南 (附大厂AI前端JD精准匹配与可落地项目) 🔖 目录理论篇:GIS中必学的图形学、WebGL、Three.js核心内容(含GIS实战细节) 1.1 计算机图形…...

简单认识显卡
学习视频来自B站(从零开始认识显卡):https://www.bilibili.com/video/BV1xE421j7Uv 这是你最近在玩的电脑游戏,形态各异的建筑、细节丰富的车辆,一切都很真实,它们的本质其实是一个个不同位置的点ÿ…...

【无人机路径规划】基于K-means 聚类和遗传算法实现多架无人机任务区域进行划分,并优化各区域内的访问路径附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

TrollInstallerX终极指南:3分钟完成iOS安装工具的零基础教程
TrollInstallerX终极指南:3分钟完成iOS安装工具的零基础教程 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS设备设计的智能越…...

碳纤维板的导电特性
简 介: 碳纤维板导电性能测试表明,其表面有机膜被刺破后会呈现导电性,电阻值从十几欧姆到几百欧姆不等,且导电性能随测量点位置变化。测试中使用尖头万用表探针穿透表面薄膜,发现同一束碳纤维连接处电阻较低࿰…...

CursorLearn2API:基于AI辅助编程的本地代码自动化部署为云端API实践
1. 项目概述:从本地代码到云端API的自动化桥梁最近在折腾一个挺有意思的项目,叫gmh5225/cursorlearn2api。乍一看这个标题,可能有点摸不着头脑,但如果你是一个经常在本地用 Cursor 这类 AI 辅助编程工具写代码,同时又想…...

Windows和Office激活难题?3分钟永久激活的智能方案
Windows和Office激活难题?3分钟永久激活的智能方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成只读模…...

Next.js 14全栈样板工程解析:集成Prisma与NextAuth的现代Web开发实践
1. 项目概述:一个为现代Web应用量身定制的启动器如果你正在寻找一个能让你跳过繁琐的初始化配置,直接进入核心业务逻辑开发的Next.js项目起点,那么nemanjam/nextjs-prisma-boilerplate这个项目很可能就是你需要的。这不是一个简单的“Hello W…...
)
【法学研究效率革命】:NotebookLM如何将文献综述时间压缩73%?(20年法律AI实践者亲测)
更多请点击: https://codechina.net 第一章:NotebookLM法学研究辅助 NotebookLM 是 Google 推出的基于用户自有文档构建的 AI 助手,其核心能力在于对上传文本进行深度语义理解与上下文感知问答。在法学研究场景中,它可高效处理判…...

listmonk CI/CD安全扫描集成:在部署前发现漏洞
listmonk CI/CD安全扫描集成:在部署前发现漏洞 邮件营销系统作为企业与用户沟通的重要渠道,其安全性直接关系到用户数据保护和品牌声誉。根据行业统计,超过68%的邮件系统漏洞是在生产环境中被发现的,而此时修复成本已增加10倍以上…...