基于数据湖的多流拼接方案-HUDI概念篇
目录
一、为什么需要HUDI?
1. 传统技术选型存在哪些问题?
2. Hudi有什么优点?
基于 Hudi Payload 机制的多流拼接方案:
二、HUDI的应用场景
1. 什么场景适合使用hudi?
2. 什么场景不适合使用hudi?
三、什么是HUDI?HUDI能做什么?
1. 什么是HUDI?
2. HUDI能做什么(特性)?
四、HUDI的概念&原理
1. 概念
2. 原理
五、流批一体
一、为什么需要HUDI?
1. 传统技术选型存在哪些问题?
【离线方面】:
这种T+1延迟的结果已经无法满足商业分析同学的日常分析需求。
【实时方面】:
有些场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。
业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:
01 - 维表 JOIN
- 场景挑战:指标数据与维度数据进行关联,其中维度数据量比较大,指标数据 QPS 比较高,导致数据可能会产出延迟。
- 当前方案:将部分维度数据缓存起起来,缓解高 QPS 下访问维度数据存储引擎产生的任务背压问题。
- 存在问题:由于业务方的维度数据和指标数据时间差比较大,所以指标数据流无法设置合理的 TTL;而且存在 Cache 中维度数据没有及时更新,导致下游数据不准确的问题。
02 - 多流 JOIN
- 场景挑战:多个指标数据进行关联,不同指标数据可能会出现时间差比较大的异常情况。
- 当前方案:使用基于窗口的 JOIN,并且维持一个比较大的状态。
- 存在问题:维持大的状态不仅会给内存带来的一定的压力,同时 Checkpoint 和 Restore 的时间会变 得更长,可能会导致任务背压。
总结上述场景遇到的挑战,主要可归结为以下两点:
由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。
由于对维度数据做了 Cache,维度数据数据更新不及时,导致下游数据不准确。

2. Hudi有什么优点?
基于 Hudi Payload 机制的多流拼接方案:
(Payload是一个条数据的内容的抽象,决定了同一个主键的数据的增删改查逻辑也决定了其序列化的方式。通过对payload的自定义,可以实现数据的灵活合并,数据的自定义编码序列化等,丰富Hudi现有的语义,提升性能。)
- 多流数据完全在存储层进行拼接,与计算引擎无关,因此不需要保留状态及其 TTL 的设置。
- 维度数据和指标数据作为不同的流独立更新,更新过程中不需要做多流数据合并,下游读取时再 Merge 多流数据,因此不需要缓存维度数据,同时可以在执行 Compact 时进行 Merge,加速下游查询。
- 支持离线场景和流批混合场景。
- 内置通用模板,支持数据去重等通用接口,同时可满足用户定制化数据处理需求。
二、HUDI的应用场景
1. 什么场景适合使用hudi?
0. 具有相同主键的多个数据源构建一个大宽表;
1. 近实时DB数据入仓/湖:把原来T + 1的数据新鲜度提升到分钟级别;
2. 近实时OLAP:分钟级别的端到端数据新鲜度,同时又非常开放的OLAP查询引擎可以适配;
3. 近实时ETL;
2. 什么场景不适合使用hudi?
下游对时效性要求较高,对数据延迟容忍度较低;
三、什么是HUDI?HUDI能做什么?
1. 什么是HUDI?
Hudi是Hadoop Updates and Incrementals的简写,它是由Uber开发并开源的Data Lakes解决方案。Hudi 用于管理的数据库层上构建具有增量数据管道的流式数据湖,同时针对湖引擎和常规批处理进行了优化。简言之,Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
1. Apache Hudi 本身不存储数据,仅仅管理数据,借助外部存储引擎存储数据,比如HDFS、S3;
2. 此外,Apache Hudi 也不分析数据,需要使用计算分析引擎,查询和保存数据,比如Spark或Flink
参考:Hudi学习一:Hudi简介_Hub-Link的博客-CSDN博客
2. HUDI能做什么(特性)?
- 开放性:上游支持多种数据源格式,下游查询端也同样支持多种查询引擎;
- 丰富的事务支持:对ACID语义(原子性、一致性、隔离性、持久性)的增强;
- Hudi 保管修改历史,可以做时间旅行或回退;
- Hudi 内部有主键到文件级的索引,默认是记录到文件的布隆过滤器;
四、HUDI的概念&原理
1. 概念
COW表(Copy On Write):
在数据写入的时候,通过复制旧文件数据并且与新写入的数据进行合并,对 Hudi 的每一个新批次写入都将创建相应数据文件的新版本。
MOR表(Merge On Read):
对于具有要更新记录的现有数据文件,Hudi 创建增量日志文件记录更新数据。此在写入期间不会合并或创建较新的数据文件版本;在进行数据读取的时候,将本批次读取到的数据进行Merge。Hudi 使用压缩机制来将数据文件和日志文件合并在一起并创建更新版本的数据文件。
| 指标 | COW | MOR |
| 更新代价 | 高 | 低 |
| 读取延迟 | 低 | 一般 |
| 写放大 | 高 | 低 |
总结:COW适用于读多写少的场景;MOR适用于写多读少的场景。
参考:腾讯广告业务基于Apache Flink + Hudi的批流一体实践 - 墨天轮 (modb.pro)
2. 原理
Hudi存储分为两个部分:
元数据:
.hoodie目录对应着表的元数据信息,包括表的版本管理(Timeline)、归档目录(存放过时的instant也就是版本),一个instant记录了一次提交(commit)的行为、时间戳和状态,Hudi以时间轴的形式维护了在数据集上执行的所有操作的元数据;
数据:
和hive一样,以分区方式存放数据;分区里面存放着Base File(.parquet)和Log File(.log.*);
MOR表数据组织架构:
数据构成关系:table -> partition -> FileGroup -> FileSlice -> parquet + log ;
五、流批一体
Flink + Hudi
Flink实现了计算框架一致;
Hudi实现了存储框架一致(不能使用Kafka、Hive,因为不支持迟到数据对结果进行修改,以及长时间的数据回溯);
Hudi(Hadoop Upserts Deletes and Incrementals)是一个开源的数据湖解决方案,旨在简化大数据湖的数据管理和增量处理操作。Hudi 在 Apache Hadoop 生态系统中被广泛使用,并提供了一些核心功能。
以下是 Hudi 的核心功能:
- 增量写入(Incremental Writes):Hudi 允许在数据湖中进行增量写入操作。它支持更新(upsert)和删除(delete)操作,这意味着可以有效地处理变化的数据。用户可以仅仅写入发生变化的数据,而无需覆盖整个数据集。
- 原子性(Atomicity):Hudi 提供原子性写入操作,确保数据写入是事务性的。这意味着要么所有的写入操作都成功,要么都失败,保持数据的一致性。如果写入过程中发生故障或错误,Hudi 可以回滚写入操作,避免数据损坏。
- 时态数据(Point-in-Time Queries):Hudi 允许在数据湖中执行时态查询,即可以查询数据的历史版本。这对于分析和回溯数据非常有用。Hudi 使用了写时复制(copy-on-write)的机制来保存数据的历史版本,并提供了灵活的查询接口。
- 数据索引(Data Indexing):Hudi 提供了一种高效的数据索引机制,以加速数据查询操作。它使用了基于时间和位置的索引,可以快速定位和访问特定数据分区或时间范围内的数据。
- 建表和模式演化(Table Creation and Schema Evolution):Hudi 允许在数据湖中创建表格,并支持模式演化。它可以处理表格架构的变化,例如添加、删除或修改列。这使得在数据湖中进行架构更改变得更加灵活和简单。
- 兼容多种数据格式(Compatibility with Multiple Data Formats):Hudi 可以与多种数据格式兼容,包括 Parquet、Avro、ORC 等。这意味着可以使用不同的数据格式进行存储和读取,根据具体需求选择最合适的格式。
总而言之,Hudi 提供了一种强大而灵活的方式来管理和处理数据湖中的大数据。它的核心功能包括增量写入、原子性操作、时态数据查询、数据索引、表格创建和模式演化,以及与多种数据格式的兼容性。这些功能使得在数据湖中进行数据管理和处理变得更加高效和便捷。
其他HUDI相关资料:
基于Hudi的流批一体:
**基于Apache Hudi + Flink多流拼接(大宽表)最佳实践:万字长文:基于Apache Hudi + Flink多流拼接(大宽表)最佳实践-腾讯云开发者社区-腾讯云
*流批一体Hudi近实时数仓实践:干货|流批一体Hudi近实时数仓实践-腾讯云开发者社区-腾讯云
*腾讯广告业务基于Apache Flink + Hudi的批流一体实践:腾讯广告业务基于Apache Flink + Hudi的批流一体实践 - 墨天轮
*基于 Hudi 的湖仓一体技术在 Shopee 的实践:基于 Hudi 的湖仓一体技术在 Shopee 的实践 - 掘金
Flink+Hudi 构架仓湖一体化解决方案:Apache Flink学习网 ***
触宝科技基于Apache Hudi的流批一体架构实践:https://www.cnblogs.com/leesf456/p/15000030.html
Apache Hudi 原理: Hudi 原理 | 聊一聊 Apache Hudi 原理-轻识 *****
数据湖架构开发-Hudi入门教程
数据湖架构开发-Hudi入门教程 - 知乎
Hudi 快速体验使用(含操作详细步骤及截图)_安装完hudi后如何远程使用_半岛铁子_的博客-CSDN博客
Apache Hudi入门指南(含代码示例) - 墨天轮
相关文章:
基于数据湖的多流拼接方案-HUDI概念篇
目录 一、为什么需要HUDI? 1. 传统技术选型存在哪些问题? 2. Hudi有什么优点? 基于 Hudi Payload 机制的多流拼接方案: 二、HUDI的应用场景 1. 什么场景适合使用hudi? 2. 什么场景不适合使用hudi? …...

OpenCV基础知识(5)— 几何变换
前言:Hello大家好,我是小哥谈。OpenCV中的几何变换是指改变图像的几何结构,例如大小、角度和形状等,让图像呈现出缩放、翻转、旋转和透视效果。这些几何变换操作都涉及复杂、精密的计算。OpenCV将这些计算过程都封装成了非常灵活的…...

Linux下源码安装MySQL 8.0
MySQL 8.0源码安装 环境准备步骤 环境准备 Linux环境,本文基于CentOS 8 MySQL安装包,本文基于MySQL 8.1,以下为带boost MySQL 8.1源码下载地址: https://dev.mysql.com/get/Downloads/MySQL-8.1/mysql-boost-8.1.0.tar.gz 步骤…...

大聪明教你学Java | 深入浅出聊 Java 内存模型
前言 🍊作者简介: 不肯过江东丶,一个来自二线城市的程序员,致力于用“猥琐”办法解决繁琐问题,让复杂的问题变得通俗易懂。 🍊支持作者: 点赞👍、关注💖、留言💌~ 在多线程环境下,多个线程同时访问共享数据可能导致一系列问题,如数据不一致、竞态条件和死锁等…...
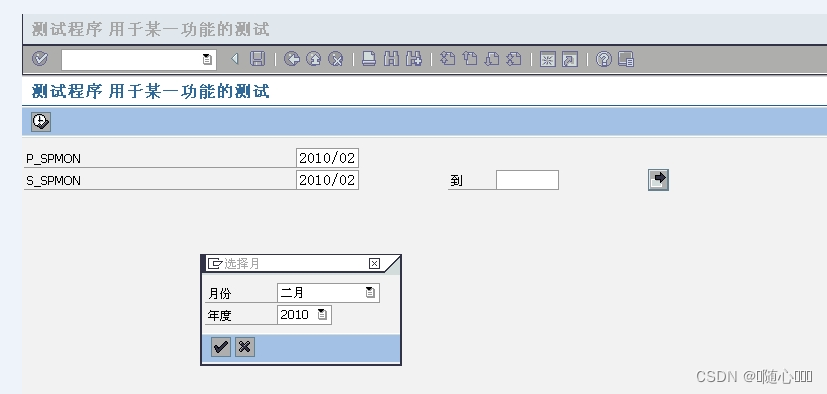
SAP ABAPG开发屏幕自动生成日期的搜索帮助
代码如下: REPORT z_jason_test_f4 . TABLES: s031. PARAMETER p_spmon TYPE spmon DEFAULT sy-datum0(6) OBLIGATORY. SELECT-OPTIONS s_spmon FOR s031-spmon DEFAULT sy-datum0(6) OBLIGATORY. AT SELECTION-SCREEN ON VALUE-REQUEST…...

leetcode 674. 最长连续递增序列
2023.8.24 与最长递增子序列 类似,不同的是, 本题要求连续序列,所以不需要第二层遍历比较之前所有的元素了,只需要比较上一个元素i-1。 dp[i]的含义为:以nums[i]元素为结尾的序列的最长递增子序列。 注意这里是以i为结…...
Mysql简短又易懂
MySql 连接池:的两个参数 最大连接数:可以同时发起的最大连接数 单次最大数据报文:接受数据报文的最大长度 数据库如何存储数据 存储引擎: InnoDB:通过执行器对内存和磁盘的数据进行写入和读出 优化SQL语句innoDB会把需要写入或者更新的数…...
vue 简单实验 v-model 变量和htm值双向绑定
1.代码 <script src"https://unpkg.com/vuenext" rel"external nofollow" ></script> <div id"two-way-binding"><p>{{ message }}</p><input v-model"message" /> </div> <script>…...
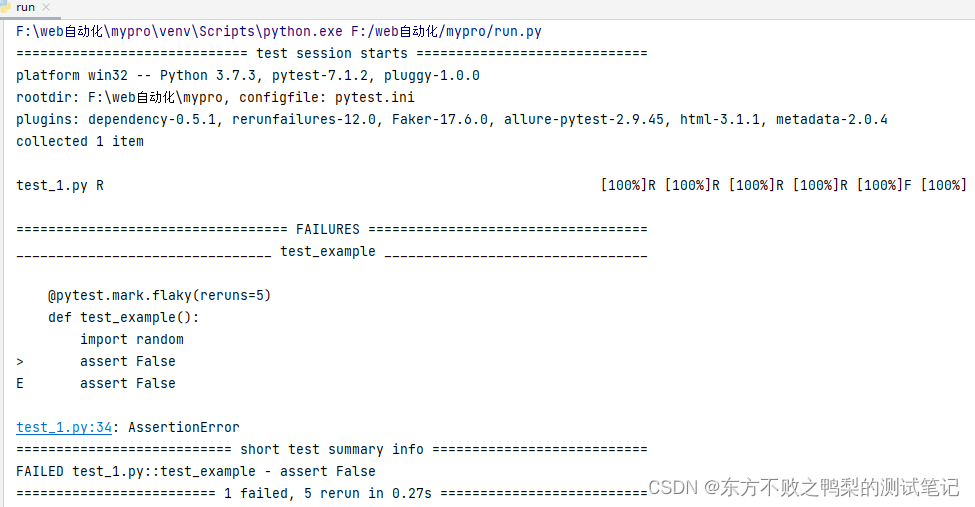
测试框架pytest教程(8)失败重试-pytest-rerunfailures
pytest-rerunfailures是一个pytest插件,用于重新运行失败的测试用例。当测试用例在第一次运行时失败,该插件会自动重新运行指定次数的失败用例,以提高稳定性和减少偶发性错误的影响。 要使用pytest-rerunfailures插件,需要按照以…...

6个主流的工业3D管道设计软件
3D 管道设计软件是大多数行业工程工作的主要部分,例如: 电力、石油和天然气、石化、炼油厂、纸浆和造纸、化学品和加工业。 全球各工程公司使用了近 50 种工厂或管道设计软件。 每个软件都有优点和缺点,包括价格点。 EPC 和业主部门当前的趋势…...
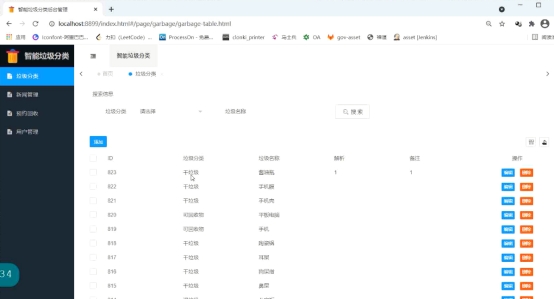
基于微信小程序的垃圾分类系统设计与实现(2.0 版本,附前后端代码)
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 1 简介 视频演示地址: 基于微信小程序的智能垃圾分类回收系统,可作为毕业设计 小…...
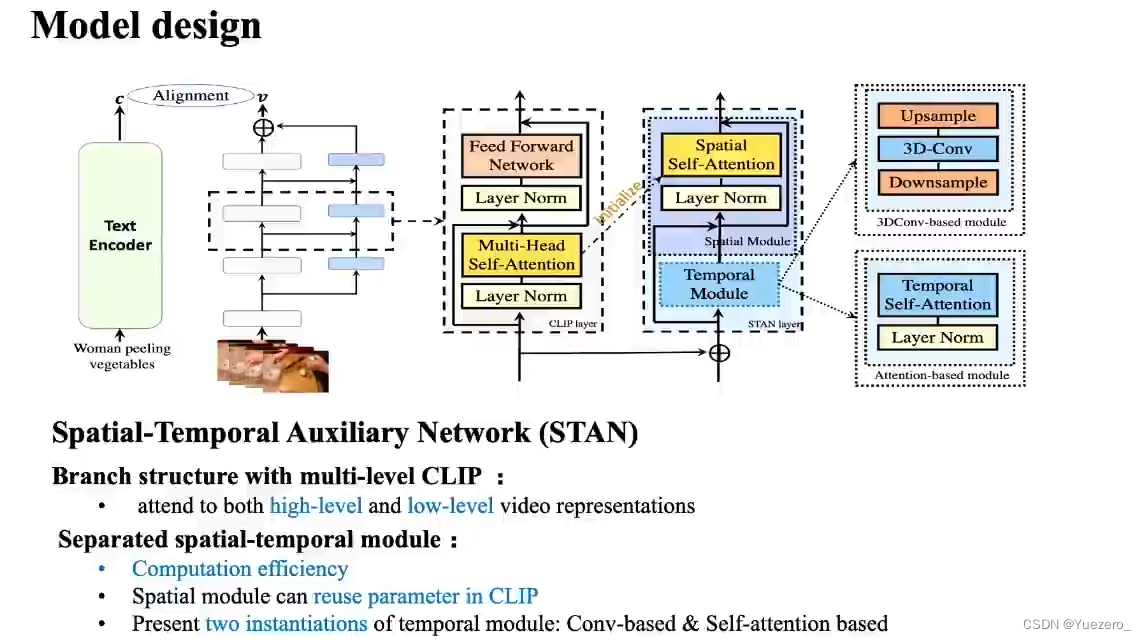
基础论文学习(4)——CLIP
《Learning Transferable Visual Models From Natural Language Supervision》 CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moc…...

SpringBoot利用ConstraintValidator实现自定义注解校验
一、前言 ConstraintValidator是Java Bean Validation(JSR-303)规范中的一个接口,用于实现自定义校验注解的校验逻辑。ConstraintValidator定义了两个泛型参数,分别是注解类型和被校验的值类型。在实现ConstraintValidator接口时&…...
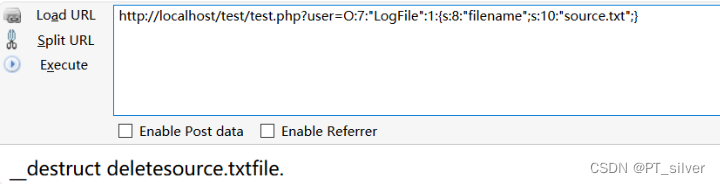
十、pikachu之php反序列化
文章目录 1、php反序列化概述2、实战3、关于Magic function4、__wakeup()和destruct() 1、php反序列化概述 在理解这个漏洞前,首先搞清楚php中serialize(),unserialize()这两个函数。 (1)序列化serialize():就是把一个…...
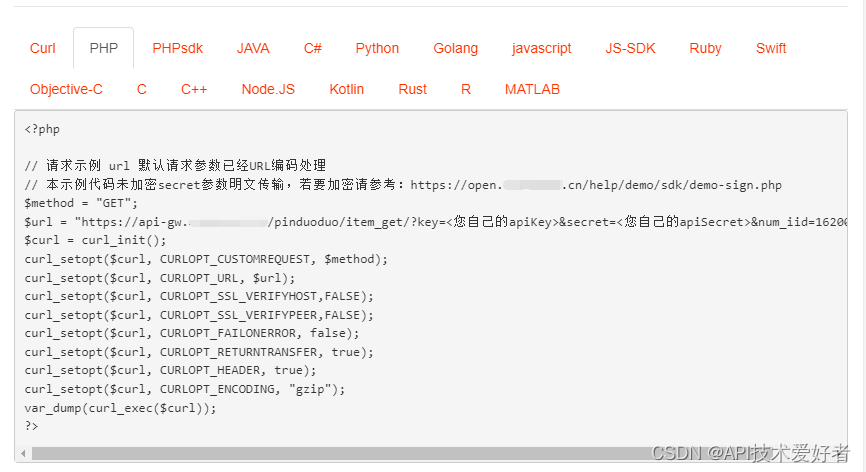
PHP“牵手”拼多多商品详情数据获取方法,拼多多API接口批量获取拼多多商品详情数据说明
拼多多商品详情接口 API 是开放平台提供的一种 API 接口,它可以帮助开发者获取拼多多商品的详细信息,包括商品的标题、描述、图片等信息。在拼多多电商平台的开发中,拼多多详情接口 API 是非常常用的 API,因此本文将详细介绍拼多多…...

前端面试:【Redux】状态管理的精髓
嘿,亲爱的Redux探险家!在前端开发的旅程中,有一个强大的状态管理工具,那就是Redux。Redux是一个状态容器,它以一种可预测的方式管理应用的状态,通过Store、Action、Reducer、中间件和异步处理等核心概念&am…...

element-ui中的el-table的summary-method(合计)的使用
场景图片: 图片1: 图片2: 一:使用element中的方法 优点: 直接使用summary-method方法,直接,方便 缺点: 只是在表格下面添加了一行,如果想有多行就不行了 1:h…...

“深入探索JVM:解析Java虚拟机的工作原理与性能优化“
标题:深入探索JVM:解析Java虚拟机的工作原理与性能优化 摘要:本文将深入探讨Java虚拟机(JVM)的工作原理和性能优化。我们将首先介绍JVM的基本组成和工作流程,然后重点讨论JVM内存管理、垃圾回收算法以及性…...
【后端】Core框架版本和发布时间以及.net 6.0启动文件的结构
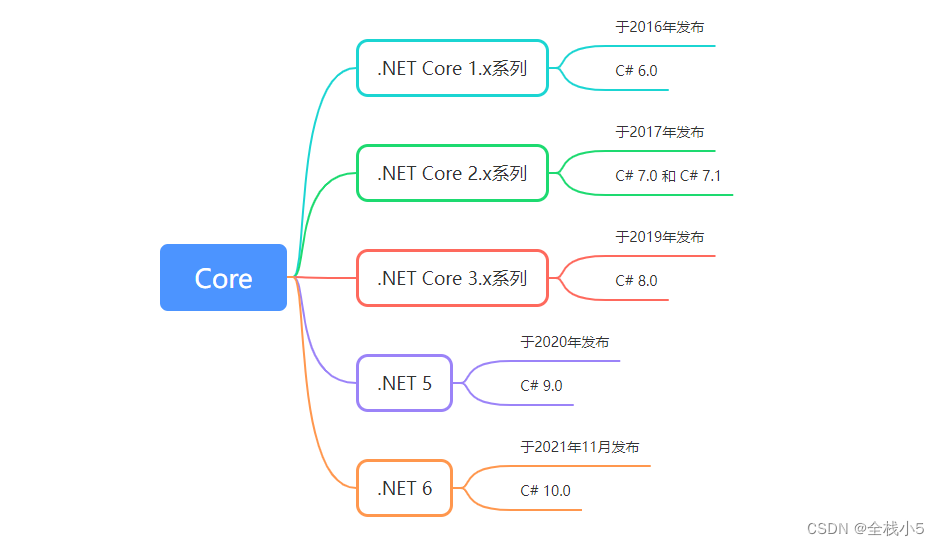
2023年,第35周,第1篇文章。给自己一个目标,然后坚持总会有收货,不信你试试! .NET Core 是一个跨平台的开源框架,用于构建现代化的应用程序。它在不同版本中有一些重要的区别和发布时间 目录 一、Core版本和…...
Linux 定时任务 crontab 用法学习整理
一、linux版本 lsb_release -a 二、crontab 用法学习 2.1,crontab 简介 linux中crontab命令用于设置周期性被执行的指令,该命令从标准输入设备读取指令,并将其存放于“crontab”文件中,以供之后读取和执行。cron 系统调度进程。…...

基于RAG与向量数据库的智能知识库系统构建实战
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的开源项目,叫IIMS-By-AI。这个名字乍一看有点唬人,IIMS是“Intelligent Information Management System”的缩写,翻译过来就是“智能信息管理系统”。但它的核心玩法…...
)
别再手动点选了!用Python脚本5分钟搞定Abaqus批量加载节点力(附完整代码)
Python自动化赋能Abaqus:高效批量加载节点力的工程实践 在有限元分析领域,Abaqus作为行业标杆软件,其强大的计算能力与灵活的二次开发接口深受工程师青睐。然而,当面对需要为数百甚至上千个节点分别施加不同载荷的复杂工况时&…...

OpenClaw自动化配置实战:从入门到精通,打造高效工作流
1. 项目概述与核心价值最近在折腾开源自动化工具,发现了一个宝藏仓库:ShuyuZ1999/awesome-openclaw-configs。这个项目乍一看名字有点长,但核心价值非常明确——它是一个专门为开源自动化工具OpenClaw收集、整理和分享高质量配置文件的集合。…...

OpenAgents:从零构建数据驱动的AI智能体平台实战指南
1. 项目概述:当AI不只是聊天,而是能替你“干活”的智能体最近在AI圈子里,一个名为“OpenAgents”的项目热度持续攀升。它不是一个简单的聊天机器人,也不是一个封闭的单一应用。简单来说,OpenAgents是一个开源的、数据驱…...

基于MCP协议的AI思维链结构化存储服务器设计与应用
1. 项目概述:一个为AI思维链提供结构化存储的MCP服务器最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)进行复杂推理和规划的项目时,我总被一个问题困扰:如何有效地管理和复用模型在思考过程中产生的…...

对比直接使用原生 API 与通过 Taotoken 调用在账单清晰度上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原生 API 与通过 Taotoken 调用在账单清晰度上的差异 对于需要频繁调用多个大语言模型的团队或个人开发者而言&#x…...

抠图怎么抠出来?2026年最好用的免费AI抠图工具测评指南
你是否经常为了一张证件照、商品图或者头像而烦恼?想要快速去掉背景但又不想学复杂的PS操作?我今天要分享的,就是如何用现代AI抠图工具轻松搞定这一切。为什么抠图这么难?抠图之所以成为很多人的"老大难",主…...

面试题详解:Agent 记忆管理全解析——历史对话获取、摘要记忆、事实记忆、知识图谱记忆一次讲透
1. 什么是 Agent 记忆管理?为什么这件事越来越重要?1.1 如果没有记忆,Agent 就只能“活在当下”很多人第一次接触 Agent 时,会觉得记忆似乎就是保存聊天记录。可一旦系统要跨多轮、多天、甚至跨任务持续工作,就会发现单…...

KVQuant:突破LLM推理显存瓶颈的KV Cache量化技术详解
1. 项目概述:KVQuant是什么,以及它为何重要如果你最近在折腾大语言模型(LLM)的本地部署、微调或者推理优化,大概率已经对“KV Cache”这个名词不陌生了。随着模型参数规模从几十亿飙升到上千亿,推理过程中的…...

用 Mass Change Wizard 批量治理 SAP S/4HANA Business Role
在 SAP S/4HANA Cloud 的权限治理里,最怕的不是创建一个 Business Role,而是系统上线一段时间后,几十个甚至上百个 Business Role 需要一起调整。业务团队说,财务共享中心要启用新的 SAP Fiori Launchpad Space。Basis 团队说,旧的自定义 Space 要逐步退出。审计团队又补了…...