使用 Elasticsearch 轻松进行中文文本分类
本文记录下使用 Elasticsearch 进行文本分类,当我第一次偶然发现 Elasticsearch 时,就被它的易用性、速度和配置选项所吸引。每次使用 Elasticsearch,我都能找到一种更为简单的方法来解决我一贯通过传统的自然语言处理 (NLP) 工具和技术来解决的问题。
在某个时刻,我意识到,它可以直接用来解决很多问题,而如果采用我以前学到的方法,则需要从头开始构建解决方案。
环境:
服务器:elasticsearch7.9.3
前端:elasticsearch-head
一、下载ICU和IK中文分词插件
进入elasticsearch/bin,查看是否如下2个插件,如果没有就需要下载。
[elasticsearch@ bin]$ ./elasticsearch-plugin list
analysis-icu
analysis-ik有两种方式,一种是在线下载,一种是离线下载。由于我的网络环境需要代理设置,第一种提示下载超时
root@:/elasticsearch-7.9.3/bin# ./elasticsearch-plugin install analysis-icu
-> Installing analysis-icu
-> Failed installing analysis-icu
-> Rolling back analysis-icu
-> Rolled back analysis-icu
Exception in thread "main" java.net.ConnectException: 连接超时 (Connection timed out)at java.base/java.net.PlainSocketImpl.socketConnect(Native Method)
下载对应版本的ik和icu插件
Gitee 极速下载/elasticsearch-analysis-ik
https://artifacts.elastic.co/downloads/elasticsearch-plugins/analysis-icu/analysis-icu-7.9.3.zip
将2个压缩文件,上传至服务器的elasticsearch/plugin,解压并重启elasticsearch,重启的方式见linux上安装部署elasticsearch7.9_elasticsearch linux部署_一个高效工作的家伙的博客-CSDN博客
二、使用分词器测试用例
1)普通分词
POST _analyze
{"text": ["他是一个前端开发工程师"],"analyzer": "standard"
}POST _analyze
{"text": ["他是一个前端开发工程师"],"analyzer": "keyword"
}2)IK 分词
POST _analyze
{"text": ["他是一个前端开发工程师"],"analyzer": "ik_max_word"
}
{"text": ["他是一个前端开发工程师"],"analyzer": "ik_smart"
}
3) ICU 分词
POST _analyze
{"text": ["他是一个前端开发工程师"],"analyzer": "icu_analyzer"
}使用elasticsearch-head的复合查询,写法如下:

三、分词器的实际应用
1、创建索引
使用ik_smart作为分词器,注:需要新建索引时添加分词器,如果添加数据后,就无法添加分词器了。
put /sample
{"mappings": {"properties": {"content": {"type": "text","analyzer": "ik_smart"},"category": {"type": "text","analyzer": "ik_smart","fields": {"raw": {"type": "keyword"}}}}}
}2、 添加文档
//添加文档
POST /sample/_doc/1
{"content":"我是小鸟","category":"动物"
}POST /sample/_doc/2
{"content":"我是苹果","category":"植物"
}
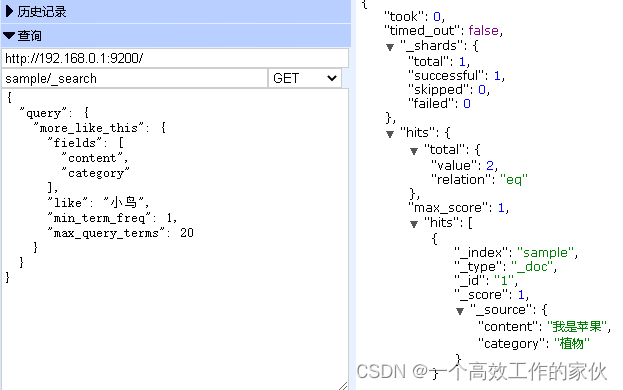
3、使用more_like_this查询:
GET sample/_search
{"query": {"more_like_this": {"fields": ["content","category"],"like": "小鸟","min_term_freq": 1,"max_query_terms": 20}}
}
四、结语:
大多数的 NLP 任务都是从一个标准的预处理管道开始的:
- 采集数据
- 提取原始文本
- 句子拆分
- 词汇切分
- 标准化(词干分解、词形还原)
- 停用词删除
- 词性标注
第 1 步和第 2 步可通过 Elasticsearch 中的采集附件处理器插件(5.0 之前版本为映射工具附件插件)来完成。
这些插件的原始文本提取基于 Apache Tika,这个工具包可处理最常见的数据格式(HTML/PDF/Word 等)。
第 4 步到第 6 步可通过开箱即用的语言分析器来完成。比如icu和ik分词器完成。
有几个现实的原因:训练一个 SVM 模型需要花费大量时间。特别是当您在一家初创公司工作,或需要快速适应各种客户或用例时,这可能会是一个棘手的问题。另外,您可能无法在每次数据变更时都对模型进行重新培训。我在一家德国大银行的项目中曾亲身经历过这个难题。这种情况下,您用过时的模型肯定不会带来好的结果。
而使用 Elasticsearch 方法,不仅可在索引时进行训练,还可在任何时间点动态更新模型,而且应用程序的停机时间为零。如果您的数据存储在 Elasticsearch 中,则不需要任何额外的基础设施。通常,在第一页您就可以获得 10% 以上的高精度结果。这在很多应用程序中足以给人留下良好的第一印象。
既然有其他工具,为什么还要使用 Elasticsearch 呢?
因为您的数据已经存在,它会预先计算底层的统计数据。就像是免费得到一些 NLP 一样!
相关文章:
使用 Elasticsearch 轻松进行中文文本分类
本文记录下使用 Elasticsearch 进行文本分类,当我第一次偶然发现 Elasticsearch 时,就被它的易用性、速度和配置选项所吸引。每次使用 Elasticsearch,我都能找到一种更为简单的方法来解决我一贯通过传统的自然语言处理 (NLP) 工具和技术来解决…...

MNN学习笔记(八):使用MNN推理Mediapipe模型
1.项目说明 最近需要用到一些mediapipe中的模型功能,于是尝试对mediapipe中的一些模型进行转换,并使用MNN进行推理;主要模型包括:图像分类、人脸检测及人脸关键点mesh、手掌检测及手势关键点、人体检测及人体关键点、图像嵌入特征…...

主力吸筹指标及其分析和使用说明
文章目录 主力吸筹指标指标代码分析使用说明使用配图主力吸筹指标 VAR1:=REF(LOW,1); VAR2:=SMA(MAX(LOW-VAR1,0),3,1)/SMA(ABS(LOW-VAR1),3,1)*100; VAR3:=EMA(VAR2,3); VAR4:=LLV(LOW,34); VAR5:=HHV(VAR3,34); VAR7:=EMA(IF(LOW<=VAR4,(VAR3+VAR5*2)/2,0),3); /*底线:0,…...
Python高光谱遥感数据处理与高光谱遥感机器学习方法教程
详情点击链接:Python高光谱遥感数据处理与高光谱遥感机器学习方法教程 第一:高光谱基础 一:高光谱遥感基本 01)高光谱遥感 02)光的波长 03)光谱分辨率 04)高光谱遥感的历史和发展 二:高光谱传感器与数据获取 01)高光谱遥感…...
【洛谷】P1678 烦恼的高考志愿
原题链接:https://www.luogu.com.cn/problem/P1678 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 将每个学校的分数线用sort()升序排序,再二分查找每个学校的分数线,通过二分找到每个同学估分附近的分数线。 最后…...

开机自启CPU设置定频
sudo apt-get install expect sudo apt-get install cpufrequtils具体步骤如下: 安装 cpufrequtils 工具 ⚫ sudo apt-get install cpufrequtils ⚫ 需要联网下载修改配置文件 ⚫ sudo vi /etc/init.d/cpufrequtils ⚫ 将 GOVERNOR“ondemand” 改为: &g…...
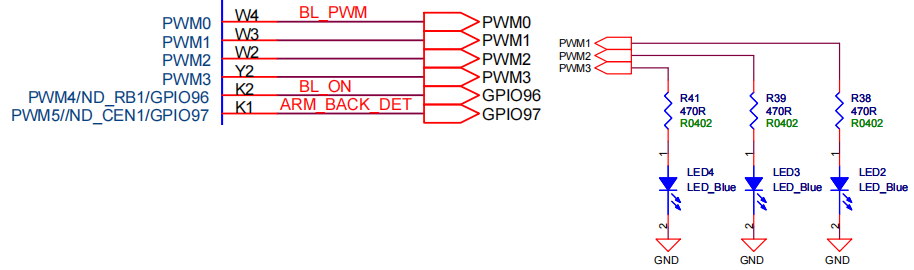
嵌入式Linux开发实操(十二):PWM接口开发
# 前言 使用pwm实现LED点灯,可以说是嵌入式系统的一个基本案例。那么嵌入式linux系统下又如何实现pwm点led灯呢? # PWM在嵌入式linux下的操作指令 实际使用效果如下,可以通过shell指令将开发板对应的LED灯点亮。 点亮3个LED,则分别使用pwm1、pwm2和pwm3。 # PWM引脚的硬…...

消息中间件介绍
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。当今市面上有很多主流的消息中间件,如ActiveMQ、RabbitMQ,Kafka,还有阿里巴巴…...

[Unity] 基础的编程思想, 组件式开发
熟悉 C# 开发的朋友, 在刚进入 Unity 开发时, 不可避免的会有一些迷惑, 例如不清楚 Unity 自己的思想, 如何设计与架构一个应用程序之类的. 本篇文章简要的介绍一下 Unity 的基础编程思想. 独立 Unity 很少使用 C# 的标准库, 例如 C# 的网络, 事件驱动, 对象模型, 这些概念在 …...
SVN 项目管理笔记
SVN 项目管理笔记 主要是介绍 SVN 管理项目的常用操作,方便以后查阅!!! 一、本地项目提交到SVN流程 在SVN仓库下创建和项目名同样的文件夹目录;选中本地项目文件,选择SVN->checkout,第一个是远程仓库项…...

Android获取手机已安装应用列表JAVA实现
最终效果: 设计 实现java代码: //获取包列表private List<String> getPkgList() {List<String> packages new ArrayList<String>();try {//使用命令行方式获取包列表Process p Runtime.getRuntime().exec("pm list packages");//取得命令行输出…...

【校招VIP】有一个比赛获奖项目和参与的开源小项目,秋招项目竞争力够不够?三个标准,自己都可以估算
有个24届的学生问我:现在没有实习,能不能参与大厂秋招?手里有两个项目,一个是比赛的获奖项目,一个是CSDN上博主做的开源小项目,这两个项目竞争力够不够? 其实项目这块,无非就是三个…...

量化开发学习入门-概念篇
1.网格交易法 网格交易法(Grid Trading)是一种基于价格波动和区间震荡的交易策略。它适用于市场处于横盘或震荡的情况下。 网格交易法的基本思想是在设定的价格区间内均匀地建立多个买入和卖出水平(网格),并在价格上…...
以及向量处理)
【草稿】关于文本句子分割(中文+英文)以及向量处理
获取文本 主函数 Main # -*- encoding: utf-8 -*- # Author: SWHL # Contact: liekkaskono163.com from pathlib import Path from typing import Dict, List, Unionimport filetypefrom ..utils import logger from .image_loader import ImageLoader from .office_loader i…...
【瑞吉外卖】所遇问题及解决方法
太菜了实习之余瑞吉外卖补充一下基础知识(,不然真啥也不会了。 请输入正确的手机号! 是因为我测试了我的手机号,爆红,以为方法有错。但其实是前端代码检查手机号是否符合规范的语句有点()啊啊…...

【Hugo入门】基础用法
检查Hugo是否安装 hugo version显示所有可用命令 hugo help显示指定命令的可用子命令,例如查询server的所有子命令 hugo server --help建立你的网站,cd进入你的项目根目录运行 hugo默认发布内容到自动创建的public文件夹。 覆盖hugo或hugo server的默…...

Java实现一个简单的图书管理系统(内有源码)
简介 哈喽哈喽大家好啊,之前作者也是讲了Java不少的知识点了,为了巩固之前的知识点再为了让我们深入Java面向对象这一基本特性,就让我们完成一个图书管理系统的小项目吧。 项目简介:通过管理员和普通用户的两种操作界面࿰…...
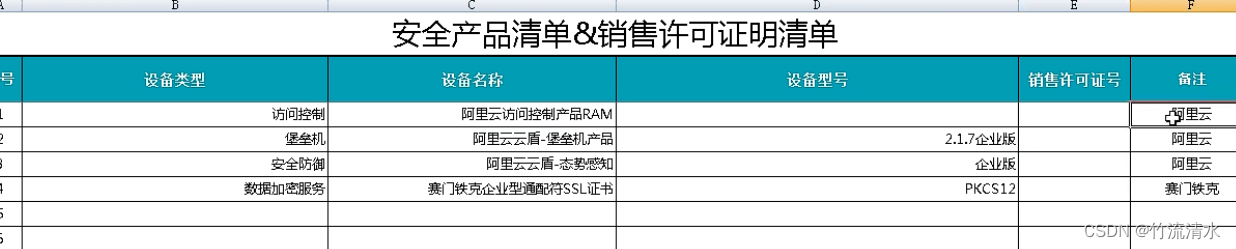
网络安全等级保护2.0
等保介绍 信息系统运维安全管理规定(范文)| 资料 等保测评是为了符合国家法律发挥的需求,而不是安全认证(ISO) 一般情况没有高危安全风险一般可以通过,但若发现高位安全风险则一票否决 二级两年一次 三…...
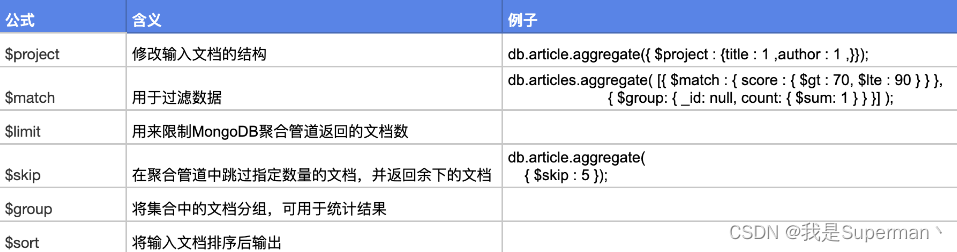
【sql】MongoDB 增删改查 高级用法
【sql】MongoDB 增删改查 高级用法 相关使用文档 MongoDB Query API — MongoDB Manual https://www.mongodb.com/docs/manual/reference/sql-comparison //增 //新增数据2种方式 db.msg.save({"name":"springboot😀"}); db.msg.insert({&qu…...

怎么做才能有效更新和优化产品手册文档
更新和优化产品手册文档是确保用户获得准确和最新信息的重要步骤。如果不及时地更新和优化信息,很容易导致我们的产品有滞后性,不能满足客户最新的需求。所以looklook总结了一些相关内容,以下是一些建议来更新和优化产品手册文档:…...

零基础实战:在AutoDL云端一键部署GPT-SoVITS并实现音色克隆API调用
1. 为什么选择AutoDL部署GPT-SoVITS 第一次接触音色克隆技术时,我和很多人一样被两个问题困扰:本地电脑配置不够怎么办?复杂的Linux环境怎么配置?直到发现AutoDL这个云端算力平台,所有问题迎刃而解。这里实测用RTX3090…...

哔哩下载姬终极指南:三步掌握B站视频批量下载技巧
哔哩下载姬终极指南:三步掌握B站视频批量下载技巧 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等࿰…...

WinRing0深度解析:Windows硬件访问的终极解决方案
WinRing0深度解析:Windows硬件访问的终极解决方案 【免费下载链接】WinRing0 WinRing0 is a hardware access library for Windows. 项目地址: https://gitcode.com/gh_mirrors/wi/WinRing0 WinRing0是一个功能强大的Windows硬件访问库,为开发者提…...
)
别再手动算矩阵了!CloudCompare 2025版点云变换保姆级教程(齐次/欧拉/轴角一键搞定)
别再手动算矩阵了!CloudCompare 2025版点云变换保姆级教程(齐次/欧拉/轴角一键搞定) 点云数据处理中,最让人头疼的莫过于各种空间变换操作。传统方法需要手动计算变换矩阵,不仅容易出错,还耗费大量时间。Cl…...

如何快速下载Fansly内容:完整Fansly Downloader使用指南
如何快速下载Fansly内容:完整Fansly Downloader使用指南 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content offlin…...

SMARC嵌入式模块规范解析:从标准化接口到硬件设计实战
1. 项目概述:从“黑盒子”到标准化接口的进化在嵌入式系统开发领域,尤其是工业控制、边缘计算和物联网设备中,我们经常会遇到一个核心矛盾:如何平衡设计的灵活性与开发效率?早些年,很多项目都是从零开始&am…...

最新英语作文批改APP测评 适合学生党写作提分的实用指南
一、当前英语作文批改工具的共性痛点我们团队做了5年英语作文批改领域的内容产出,前后调研过近20款市面上的主流工具,发现行业内的共性痛点其实一直没得到很好的解决:对学生来说,多数工具只能改表层语法错误,不会结合写…...

Cream开发者进阶指南:深入理解架构搜索算法
Cream开发者进阶指南:深入理解架构搜索算法 【免费下载链接】Cream This is a collection of our NAS and Vision Transformer work. 项目地址: https://gitcode.com/gh_mirrors/cr/Cream 在深度学习模型设计领域,神经架构搜索(NAS&am…...

PyInstaller Extractor终极指南:5分钟学会提取可执行文件源码
PyInstaller Extractor终极指南:5分钟学会提取可执行文件源码 【免费下载链接】pyinstxtractor PyInstaller Extractor 项目地址: https://gitcode.com/gh_mirrors/py/pyinstxtractor 你是否曾经面对一个PyInstaller打包的可执行文件,想要查看其中…...
)
【计算机网络硬核指南】子网划分终极篇:定长+VLSM+超网三合一实战(3道大厂真题逐字节演算)
【计算机网络硬核指南】子网划分终极篇:定长VLSM超网三合一实战(3道大厂真题逐字节演算) 前言 在上一篇文章中,我们系统学习了IP地址基础和子网划分的核心方法,逐题演算了9道经典真题。很多读者反馈说,看…...