python 模块lxml 处理 XML 和 HTML 数据
xpath:https://blog.csdn.net/randy521520/article/details/132432903
一、安装
XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。
pip install lxml
二、使用案例
from lxml import etree
import requests
import asyncio
import functools
import re
import jsonhouse_info = []'''异步请求获取链家每页数据'''
async def get_page(page_index):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}request = functools.partial(requests.get, f'https://sh.lianjia.com/ershoufang/pudong/pg{page_index}/',headers=headers)loop = asyncio.get_running_loop()response = await loop.run_in_executor(None, request)return response'''使用xpath获取房屋信息'''
def get_house_info(html):title_list = html.xpath('//a[@data-el="ershoufang"]/text()') # 房屋titlehouse_pattern_list = html.xpath('//div[@class="houseInfo"]/text()') # 房屋格局price_list = html.xpath('//div[@class="unitPrice"]/span/text()') # 房屋单价location_list = html.xpath('//div[@class="positionInfo"]') # 房屋位置信息total_list = html.xpath('//div[contains(@class,"totalPrice")]') # 总价for index, item in enumerate(zip(title_list, house_pattern_list, price_list)):location_item = location_list[index]total_item = total_list[index]house_info.append({'title': item[0],'house_pattern': item[1],'price': item[2],'location': location_item.xpath('./a[1]/text()')[0] + location_item.xpath('./a[last()]/text()')[0],'total': total_item.xpath('./span/text()')[0] + total_item.xpath('./i[last()]/text()')[0]})'''异步获取第一页数据,拿到第一页房屋信息,并返回分页总数和当前页'''
async def get_first_page():response = await get_page(1)#etree.HTML 将获取到的html字符串转为可操作的Element对象get_house_info(etree.HTML(response.text))if __name__ == '__main__':asyncio.run(get_first_page())
三、etree 模块
- etree.Element(element_name, attrib=None, nsmap=None) 创建element对象
from lxml import etree ''' element_name:要创建的元素的名称 attrib:元素的属性字典 nsmap:命名空间映射字典,用于指定元素的命名空间 ''' element = etree.Element('div',attrib={'class':'test'},nsmap={"ns": "http://example.com/ns"}) - etree.SubElement(parent, element_name, attrib=None, nsmap=None) 创建子元素
from lxml import etree ''' parent:element对象 element_name:要创建的元素的名称 attrib:元素的属性字典 nsmap:命名空间映射字典,用于指定元素的命名空间 ''' element = etree.Element('div', attrib={'class': 'test'}, nsmap={"ns": "http://example.com/ns"}) span_element = etree.SubElement(element,'span') span_element.text = '我是span' print(element.xpath('//div/span/text()')) - etree.fromstring(text, parser=None,base_url=None) 将XML、HTML字符串解析为Element对象
from lxml import etree''' text:解析的XML字符串 parse:解析器对象,默认lxml.etree.XMLParser、lxml.etree.HTMLParser base_url: 基本URL,用于解析相对URL。如果HTML文档中包含相对URL,解析器将使用base_url来将其转换为绝对URL。如果未提供base_url,则相对URL将保持不变 ''' html_str = '<div class="test"><span>我是span</span></div>' element = etree.fromstring(html_str) print(element.xpath('//div/span/text()')) - etree.HTML(text, parser=None, base_url=None) 将HTML字符串解析为Element对象
from lxml import etree''' xml_string:解析的XML字符串 parse:解析器对象,默认lxml.etree.HTMLParser base_url: 基本URL,用于解析相对URL。如果HTML文档中包含相对URL,解析器将使用base_url来将其转换为绝对URL。如果未提供base_url,则相对URL将保持不变 ''' html_str = '<div class="test"><span>我是span</span></div>' element = etree.HTML(html_str) print(element.xpath('//div/span/text()')) - etree.XML(text, parser=None, base_url=None) 将XML字符串解析为Element对象
from lxml import etree''' text:解析的XML字符串 parse:解析器对象,默认lxml.etree.XMLParser base_url: 基本URL,用于解析相对URL。如果HTML文档中包含相对URL,解析器将使用base_url来将其转换为绝对URL。如果未提供base_url,则相对URL将保持不变 ''' html_str = '<div class="test"><span>我是span</span></div>' element = etree.XML(html_str) print(element.xpath('//div/span/text()')) - etree.parse(source, parser=None, base_url=None) 将XML、HTML字符串解析为ElementTree对象
四、element 对象
- element.xpath(path) 执行xpath语法
- element.nsmap:获取或设置元素命名空间映射
- element.attrib:获取或设置元素属性
- element.text:获取或设置文本
- element.tag:返回对象名称
- element.append(element) 向节点里面追加子节点
- element.insert(index,element) 向节点开始的某个位置添加子节点
from lxml import etreeelement = etree.Element('div', attrib={'class': 'test'}) span_element = etree.SubElement(element, 'span') span_element.text = '我是span'append_child = etree.Element('div', attrib={'class': 'append'}) append_child.text = '我是append_child'insert_child = etree.Element('div', attrib={'class': 'insert'}) insert_child.text = '我是insert_child'element.append(append_child) element.insert(0,insert_child) print(element.xpath('//div/span/text()')) print(element.xpath('//div/div[@class="append"]/text()')) print(element.xpath('//div/div[@class="insert"]/text()')) - element.find(xpath): 在元素的子树中查找与XPath表达式匹配的第一个元素,并返回该元素。如果找不到匹配的元素,则返回None
- element.findall(xpath): 在元素的子树中查找与XPath表达式匹配的所有元素,并返回一个列表
- element.get(attribute_name, default=None): 获取元素的指定属性的值
- element.set(attribute_name, value): 设置元素的指定属性的值
- element.iter(tag=None): 迭代元素及其子元素,可选择指定标签进行过滤
- element.getparent(): 获取元素的父元素
- element.getchildren(): 获取元素的所有子元素
- element.getroottree(): 获取包含元素的根元素的Tree对象
五、elementTree 对象
- elementTree.root: 根元素的Element对象。可以通过访问tree.root来获取根元素。
- elementTree.getroot(): 获取根元素的Element对象。与tree.root属性相同,用于获取根元素
- elementTree.find(path): 在整个文档中查找具有指定路径的第一个元素,并返回该元素的Element对象。路径可以使用XPath表达式指定
- elementTree.findall(path): 在整个文档中查找具有指定路径的所有元素,并返回这些元素的列表。路径可以使用XPath表达式指定
- elementTree.iterfind(path): 在整个文档中迭代查找具有指定路径的元素,并返回这些元素的迭代器。路径可以使用XPath表达式指定
- elementTree.write(file, encoding=None, xml_declaration=None, pretty_print=False): 将整个文档写入文件。file参数可以是文件名或文件对象。encoding参数指定写入文件时使用的字符编码。xml_declaration参数指定是否写入XML声明。pretty_print参数指定是否以更易读的格式写入文档
- elementTree.tostring(element, encoding=None, method=“xml”, pretty_print=False): 将指定元素及其子元素序列化为字符串。element参数是要序列化的元素。encoding参数指定字符串的字符编码。method参数指定序列化的方法,可以是"xml"(默认)或"html"。pretty_print参数指定是否以更易读的格式序列化。
- elementTree.parse(source, parser=None, base_url=None): 静态方法,用于解析XML或HTML文档并返回一个ElementTree对象。与etree.parse函数的用法相同
六、parse 解析器对象
- lxml.etree.XMLParser: 用于解析XML文档的默认解析器。它支持标准的XML解析,并提供了丰富的功能和选项,如命名空间支持、DTD验证等。
- lxml.etree.HTMLParser: 用于解析HTML文档的默认解析器。它专门针对HTML进行了优化,并具有处理HTML特性的功能,如自动修复破碎的标签、处理实体引用等。
- lxml.etree.XMLPullParser: 一种事件驱动的解析器,用于逐行解析XML文档。它提供了一个迭代器接口,可以逐行读取和处理XML文档。
- lxml.etree.HTMLPullParser: 一种事件驱动的解析器,用于逐行解析HTML文档。它提供了一个迭代器接口,可以逐行读取和处理HTML文档。
相关文章:

python 模块lxml 处理 XML 和 HTML 数据
xpath:https://blog.csdn.net/randy521520/article/details/132432903 一、安装 XPath (XML Path Language) 是一门在 HTML\XML 文档中查找信息的语言,可用来在 HTML\XML 文档中对元素和属性进行遍历。 pip install lxml二、使用案例 from lxml impo…...

SpringBoot 统⼀功能处理
统⼀功能处理 1. 拦截器2. 统⼀异常处理3. 统⼀数据返回格式 1. 拦截器 Spring 中提供了具体的实现拦截器:HandlerInterceptor,拦截器的实现分为以下两个步骤: 创建⾃定义拦截器,实现 HandlerInterceptor 接⼝的 preHandle&…...

hadoop 报错 java.io.IOException: Inconsistent checkpoint fields
背景: 使用了格式化,导致首重了新的集群ID org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /work1/home/hadoop/dfs/data/current/BP-1873526852-172.16.21.30-1692769875005 is in an inconsistent state: namespaceID is incompatible with …...
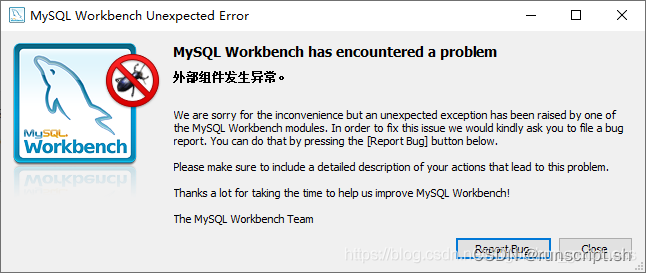
workbench连接MySQL8.0错误 bad conversion 外部组件 异常
阿里云搭建MySQL实用的版本是8.0 本地安装的版本是: workbench 6.3 需要升级到: workbench 8.0 https://dev.mysql.com/downloads/workbench/...
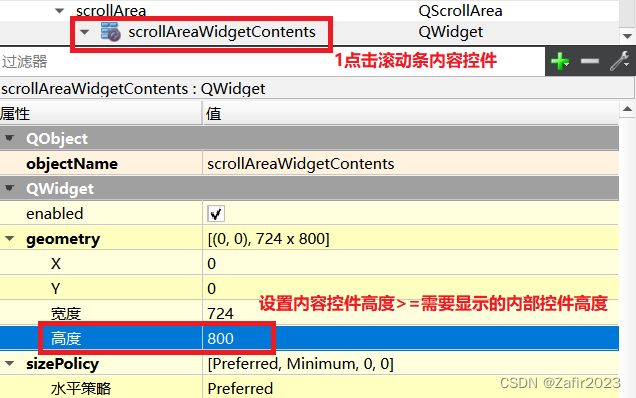
Qt Scroll Area控件设置,解决无法显示全部内容,且无法滚动显示问题。
前言,因为要显示很多条目的内容,原来是用Vertical Layout控件里面嵌套Horizontal layout显示了很多行控件,发现最简单的方法就是使用滚动条控件,但是无论如何调整需要滚动的控件高度,始终无法滚动显示内容。也就是说添…...
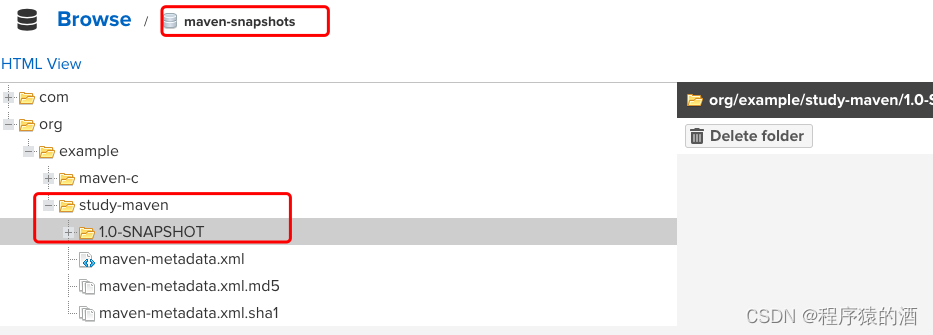
【Java架构-包管理工具】-Maven私服搭建-Nexus(三)
本文摘要 Maven作为Java后端使用频率非常高的一款依赖管理工具,在此咱们由浅入深,分三篇文章(Maven基础、Maven进阶、私服搭建)来深入学习Maven,此篇为开篇主要介绍Maven私服搭建-Nexus 文章目录 本文摘要1. Nexus安装…...

守护进程(精灵进程)
目录 前言 1.如何理解前台进程和后台进程 2.守护进程的概念 3.为什么会存在守护进程 4.如何实现守护进程 5.测试 总结 前言 今天我们要介绍的是关于守护进程如何实现,可能有小伙伴第一次听到守护进程这个概念,感觉很懵,知道进程的概念&…...
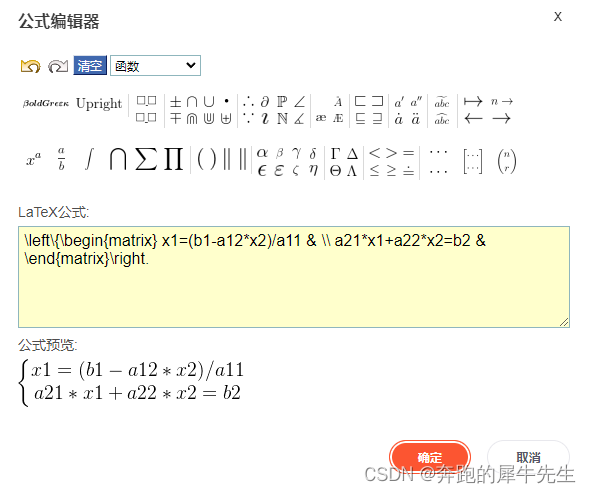
csdn冷知识:如何在csdn里输入公式或矩阵
目录 1 输入公式 2 输入矩阵 3 如何输入复杂公式 4 如何修改,已经生成的公式 1 输入公式 进入编辑模式点击右边的菜单:公式然后进入公式编辑器,选择右边的 ... 可以选择大括号等,右边还有矩阵符号选择后你需要创建几行几列的…...

【前端】CSS技巧与样式优化
目录 一、前言二、精灵图1、什么是精灵图2、为什么需要精灵图3、精灵图的使用①、创建CSS精灵图的步骤1)、选择合适的图标2)、合并图片3)、设置背景定位 ②、优化CSS精灵图的技巧1)、维护方便2)、考虑Retina屏幕3&…...
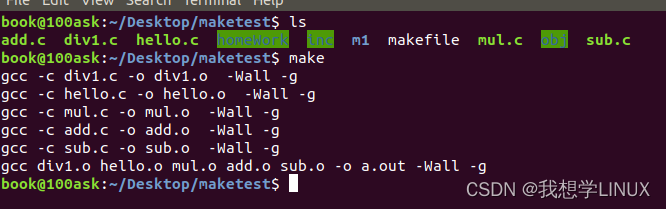
Linux下的系统编程——makefile入门
前言: 或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员,makefile还是要懂。这就好像现在有这么多的HTML的编辑器,但如果你想成为一个专…...

redis常用五种数据类型详解
目录 前言: string 相关命令 内部编码 应用场景 hash 相关命令 内部编码 应用场景 list 相关命令 内部编码 应用场景 set 相关命令 内部编码 应用场景 Zset 相关命令 内部编码 应用场景 渐进式遍历 前言: redis有多种数据类型&…...

Python代理池健壮性测试 - 压力测试和异常处理
大家好!在构建一个可靠的Python代理池时,除了实现基本功能外,我们还需要进行一系列健壮性测试来确保其能够稳定运行,并具备应对各种异常情况的能力。本文将介绍如何使用压力测试工具以及合适的异常处理机制来提升Python代理池的可…...

回文子串-中心拓展
给你一个字符串 s ,请你统计并返回这个字符串中 回文子串 的数目。 回文字符串 是正着读和倒过来读一样的字符串。 子字符串 是字符串中的由连续字符组成的一个序列。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不…...

2023.8各大浏览器11家对比:Edge/Chrome/Opera/Firefox/Tor/Vivaldi/Brave,安全性,速度,体积,内存占用
测试环境:全默认设置的情况下,均在全新的系统上进行测试,系统并未进行任何改动,没有杀毒软件,浏览器进程全部在后台,且为小窗模式,小窗分辨率均为浏览器厂商默认缩放大小(变量不唯一)࿰…...
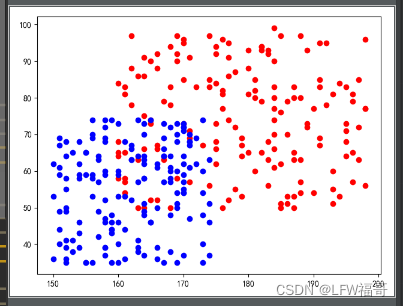
python中的matplotlib画散点图(数据分析与可视化)
python中的matplotlib画散点图(数据分析与可视化) import numpy as np import pandas as pd import matplotlib.pyplot as pltpd.set_option("max_columns",None) plt.rcParams[font.sans-serif][SimHei] plt.rcParams[axes.unicode_minus]Fa…...
2023前端面试笔记 —— HTML5
系列文章目录 内容链接2023前端面试笔记HTML5 文章目录 系列文章目录前言一、HTML 文件中的 DOCTYPE 是什么作用二、HTML、XML、XHTML 之间有什么区别三、前缀为 data- 开头的元素属性是什么四、谈谈你对 HTML 语义化的理解五、HTML5 对比 HTML4 有哪些不同之处六、meta 标签有…...

【LeetCode】面试题总结 消失的数字 最小k个数
1.消失的数字 两种思路 1.先升序排序,再遍历并且让后一项与前一项比较 2.转化为数学问题求等差数列前n项和 (n的大小为数组的长度),将根据公式求得的应有的和数与数组中实际的和作差 import java.util.*; class Solution {public …...
)
导入功能importExcel (现成直接用)
1. 实体类字段上加 Excel(name "xxx"), 表示要导入的字段 Excel(name "用户名称")private String nickName; 2. controller (post请求) /*** 导入用户数据** param file 文件* param updateSupport 是否更新支持,如果已存在,则进…...

cvc-complex-type.2.4.a: 发现了以元素 ‘base-extension‘ 开头的无效内容。应以 ‘{layoutlib}‘ 之一开头
不能飞的猪只是没用的猪。 —— 宫崎骏 《红猪》 常见的1种case 记录一下,新电脑安装android studio导入公司那些gradle还是5.5左右的工程以后,各种不适应。编译问题出现了。老电脑都是好好的。 cvc-complex-type.2.4.a: 发现了以元素 ‘base-extensi…...

cortex-A7核IIC实验
iic.h: #ifndef __IIC_H__ #define __IIC_H__ #include "stm32mp1xx_gpio.h" #include "stm32mp1xx_rcc.h"/* 通过程序模拟实现I2C总线的时序和协议* GPIOF ---> AHB4* I2C1_SCL ---> PF14* I2C1_SDA ---> PF15** */#define SET_SDA_…...
)
二叉树‘找叶子’的三种姿势:从PTA真题到LeetCode变体(层次/先序/后序遍历对比)
二叉树‘找叶子’的三种姿势:从PTA真题到LeetCode变体(层次/先序/后序遍历对比) 在算法学习的道路上,二叉树遍历是每个程序员必须掌握的基本功。而"找叶子节点"这一看似简单的任务,却能衍生出多种解法&…...

代码语义可视化架构的突破性实现:MultiHighlight如何将代码理解效率提升300%
代码语义可视化架构的突破性实现:MultiHighlight如何将代码理解效率提升300% 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiH…...

2025最权威的AI学术网站解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能技术迅猛快速发展的当下,各种各样的 AI 辅助论文写作工具不断地大量涌…...

MASA模组全家桶汉化包:3329条专业翻译,彻底告别英文界面困扰
MASA模组全家桶汉化包:3329条专业翻译,彻底告别英文界面困扰 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Minecraft技术模组的英文界面而头疼吗&#x…...

终极风扇控制解决方案:3步实现Windows系统智能温控管理
终极风扇控制解决方案:3步实现Windows系统智能温控管理 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

ARM Boot Monitor与闪存编程实战指南
1. ARM Boot Monitor核心功能解析Boot Monitor是ARM架构嵌入式系统中的核心启动管理组件,它相当于系统的"第一响应者",负责硬件初始化、启动流程控制和运行时服务提供。这个不足100KB的微型系统却承担着三大关键职责:硬件抽象层&am…...

Windows用户的救星:APK Installer让你在电脑上轻松运行Android应用
Windows用户的救星:APK Installer让你在电脑上轻松运行Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上体验Androi…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼
LrcHelper:3分钟掌握网易云音乐双语歌词下载,告别歌词烦恼 【免费下载链接】LrcHelper 从网易云音乐下载带翻译的歌词 Walkman 适配 项目地址: https://gitcode.com/gh_mirrors/lr/LrcHelper 你是否曾为找不到心爱歌曲的歌词而烦恼?或…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...