2023年高教社杯数学建模思路 - 复盘:校园消费行为分析
文章目录
- 0 赛题思路
- 1 赛题背景
- 2 分析目标
- 3 数据说明
- 4 数据预处理
- 5 数据分析
- 5.1 食堂就餐行为分析
- 5.2 学生消费行为分析
- 建模资料
0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到 11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3 数据说明
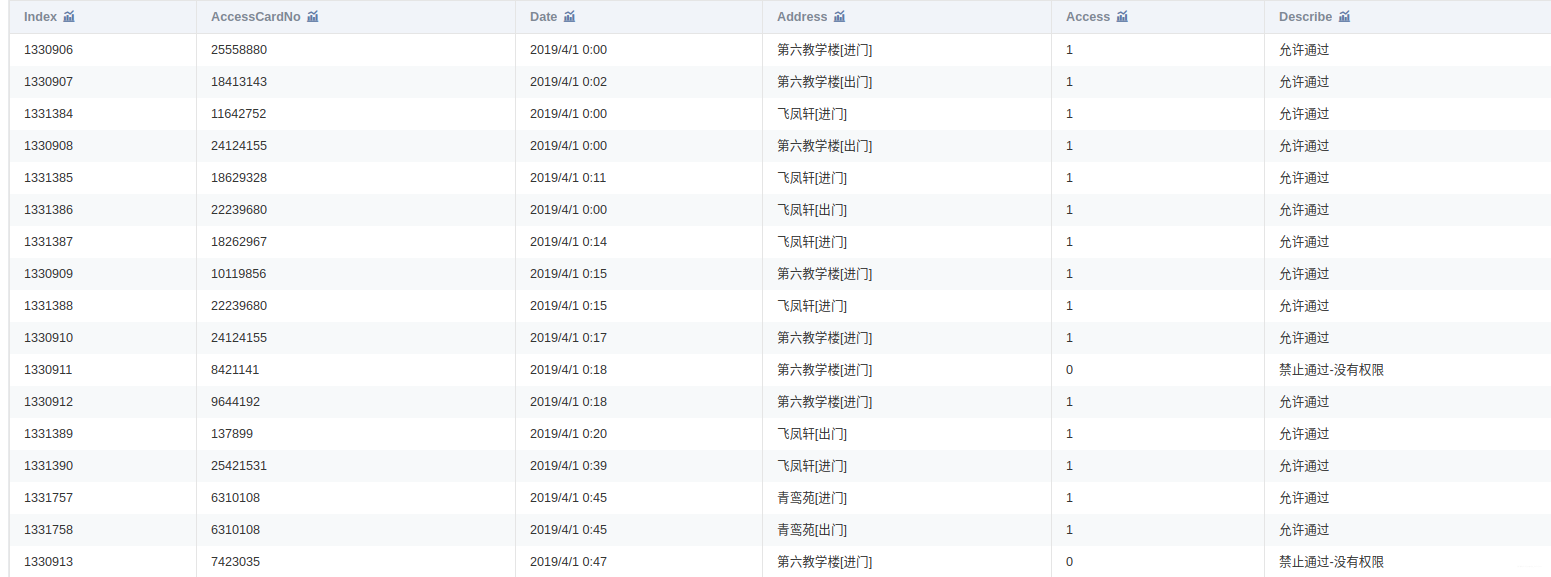
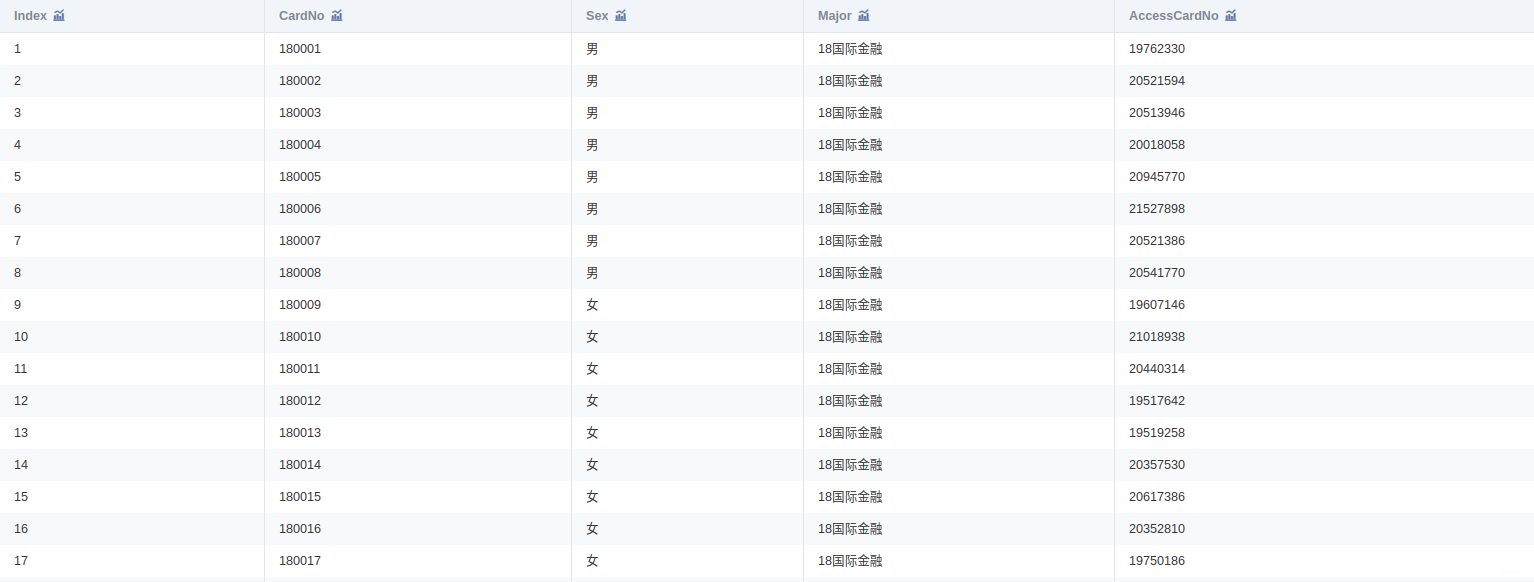
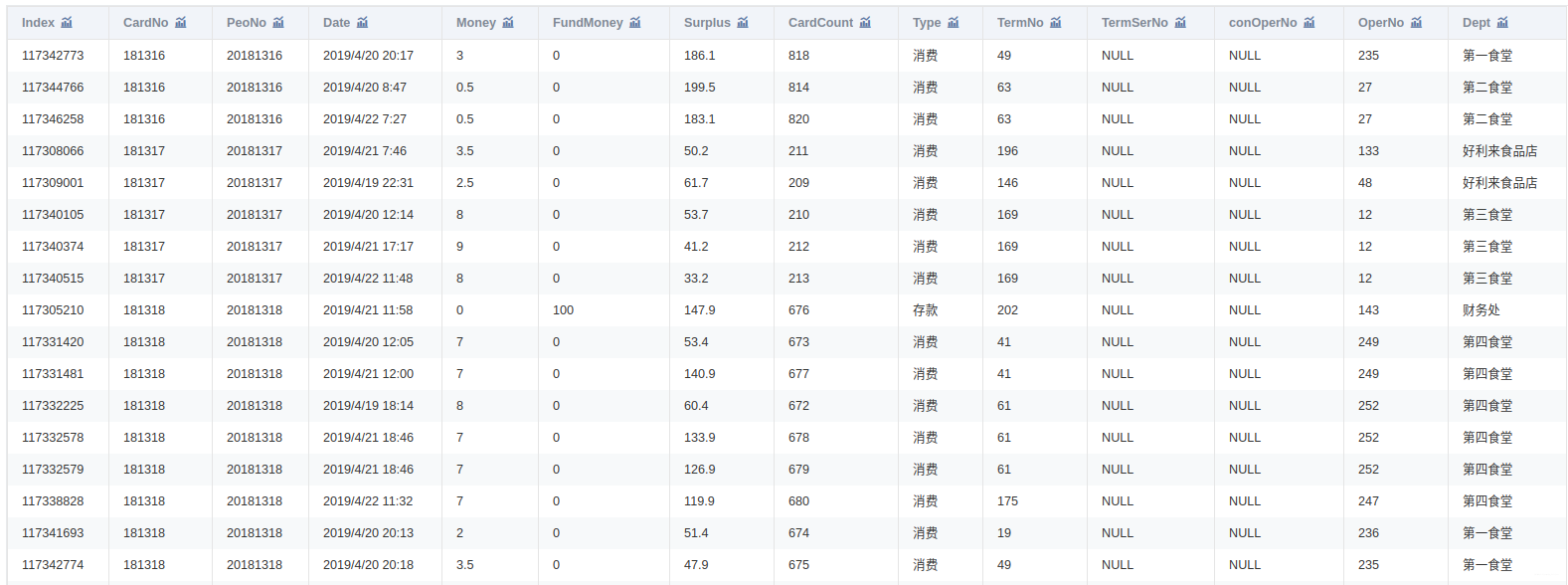
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
4 数据预处理
将附件中的 data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从 1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
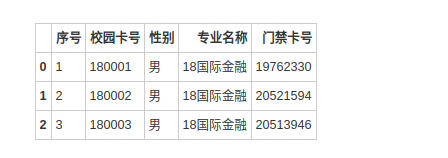
data1.head(3)
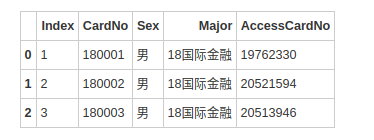
data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']
data1.dtypes

data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)

将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5 数据分析
5.1 食堂就餐行为分析
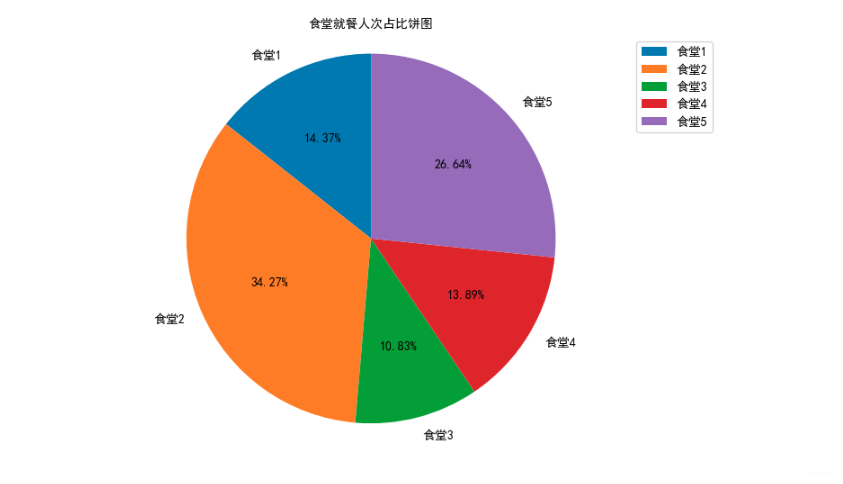
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消费地点'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消费地点'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消费地点'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消费地点'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消费地点'].apply(str).str.contains('第五食堂').sum()
# 绘制饼图
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
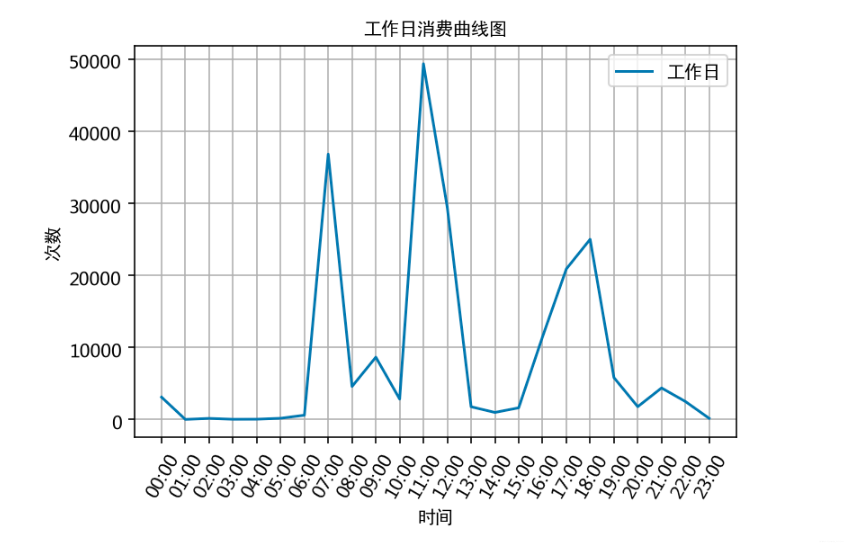
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。

# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,'消费时间'] = pd.to_datetime(data.loc[:,'消费时间'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data['消费星期'] = data['消费时间'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,'消费星期'] <= 5
unwork_day_query = data.loc[:,'消费星期'] > 5work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):work_day_times.append(work_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):x.append('{:02d}:00'.format(i))
# 绘图
plt.plot(x, work_day_times, label='工作日')
# x,y轴标签
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
# 标题
plt.title('工作日消费曲线图', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):unwork_day_times.append(unwork_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24): x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
plt.title('非工作日消费曲线图', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
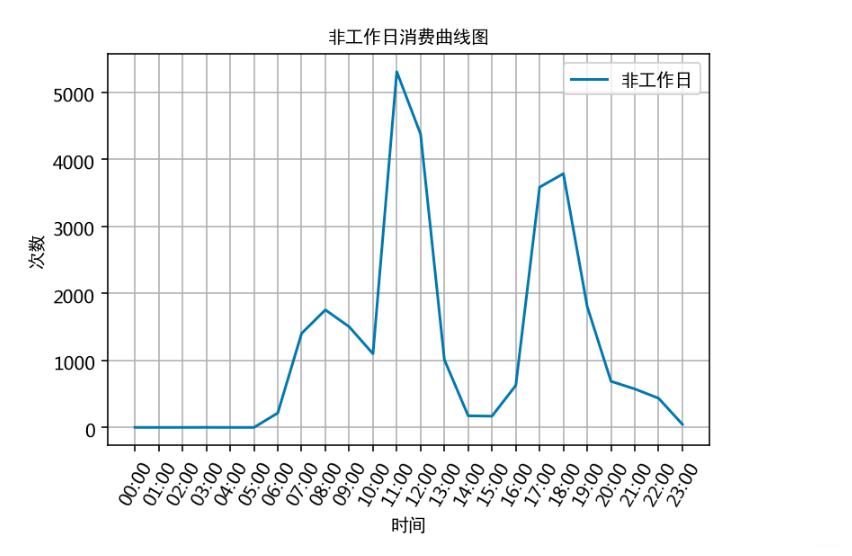
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
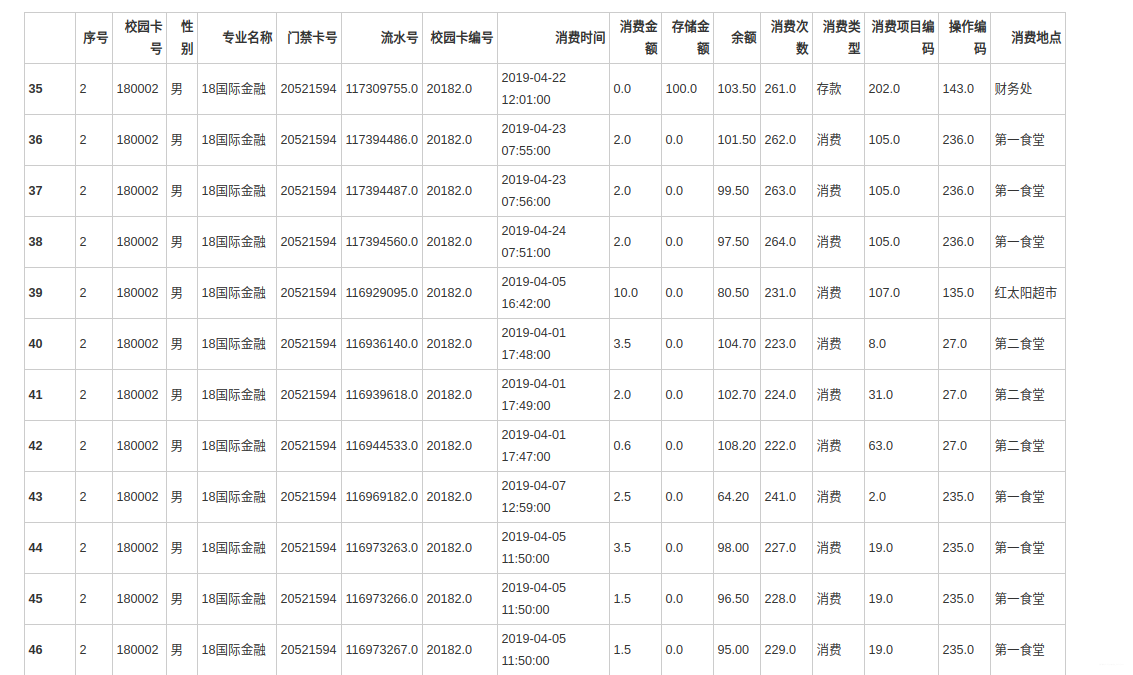
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data['消费时间'].count()
student_count = data['校园卡号'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data['消费金额'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money# 选择消费次数最多的3个专业进行分析
data['专业名称'].value_counts(dropna=False)
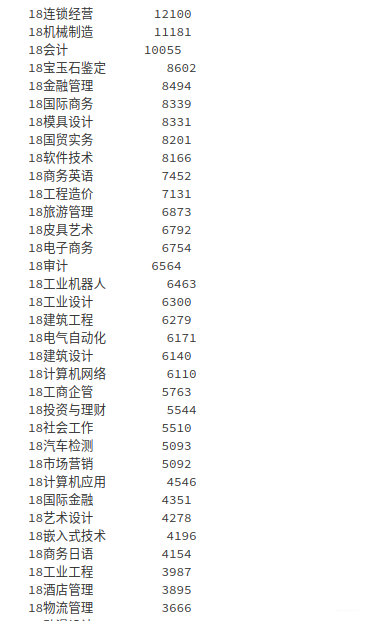
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data['专业名称'].apply(str).str.contains('18连锁经营')
major2 = data['专业名称'].apply(str).str.contains('18机械制造')
major3 = data['专业名称'].apply(str).str.contains('18会计')
major4 = data['专业名称'].apply(str).str.contains('18机械制造(学徒)')data_new = data[(major1 | major2 | major3) ^ major4]
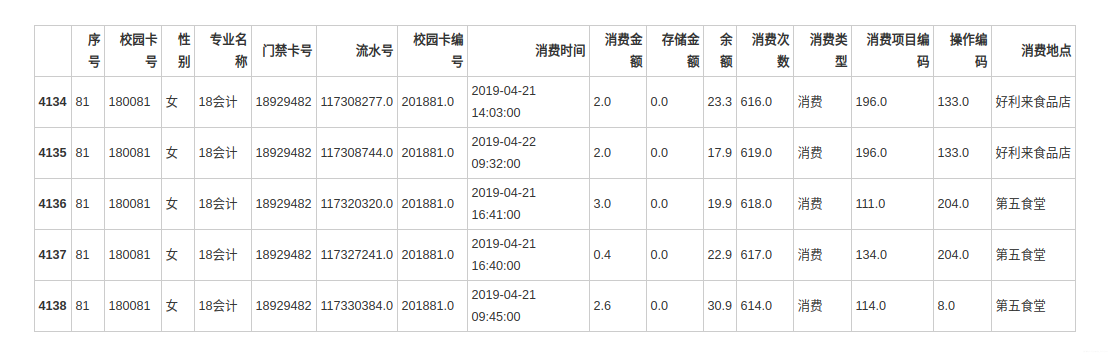
data_new['专业名称'].value_counts(dropna=False)分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new['性别'] == '男']
data_female = data_new[data_new['性别'] == '女']
data_female.head()
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data['专业名称'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[['校园卡号','性别']].drop_duplicates().reset_index(drop=True)
data_1['性别'] = data_1['性别'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校园卡号'], inplace=True)
data_2 = data.groupby('校园卡号').sum()[['消费金额']]
data_2.columns = ['总消费金额']
data_3 = data.groupby('校园卡号').count()[['消费时间']]
data_3.columns = ['总消费次数']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
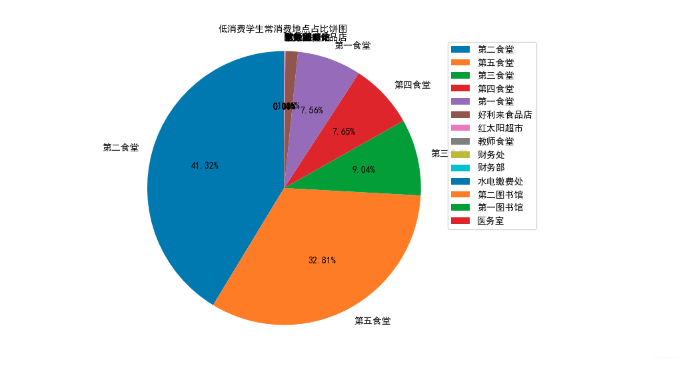
r.columns = list(data_123.columns) + ['类别数目']# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby('校园卡号').sum()[['消费金额']]
data_500.sort_values(by=['消费金额'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校园卡号'].isin(data_500_index)]
data_500.head(10)
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
建模资料
资料分享: 最强建模资料


相关文章:
2023年高教社杯数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

Flink_state 的优化与 remote_state 的探索
摘要:本文整理自 bilibili 资深开发工程师张杨,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分: 相关背景state 压缩优化Remote state 探索未来规划 点击查看原文视频 & 演讲PPT 一、相关背景 1.1 业务概况 从…...

Kdab QML (part9)自由缩放时钟
文章目录 Kdab QML (part9)自由缩放时钟代码详细解释运行截图 Kdab QML (part9)自由缩放时钟 代码 import QtQuick 2.15 import QtQuick.Window 2.15Window {id: rootwidth: 500height: 500visible: truecolor: "lightgrey"title: qsTr("Hello World")It…...
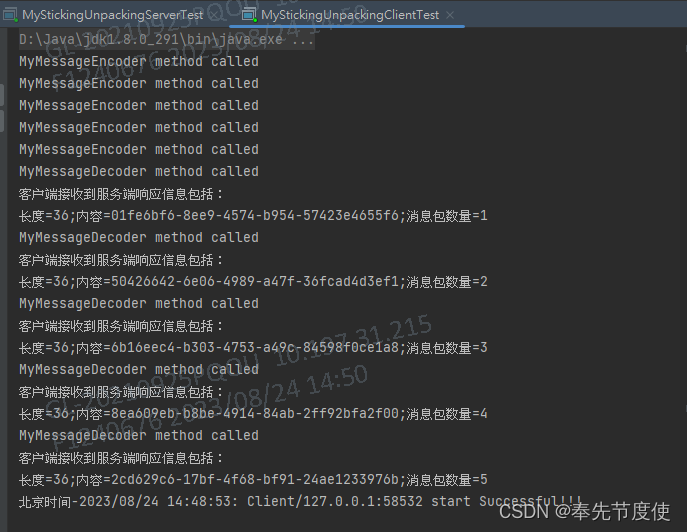
Java网络编程(二)经典案例[粘包拆包]
粘包拆包 概述 TCP是面向流的协议,TCP在网络上传输的数据就是一连串的数据,完全没有分界线。 TCP协议的底层并不了解上层业务的具体定义,它会根据TCP缓冲区的实际情况进行包的划分。 在业务层面认为一个完整的包可能会被TCP拆分成多个小包进行发送,也可能把多个小的包封装成一…...

无分布式锁的ID生成
起因 TEAM GARDEN 本来ID是自增的,后面发现自增ID比较麻烦,有问题: 不可控的间隔: 如果你在插入数据时,中途删除了一些行,导致自增的ID出现间隔,那么新插入的行会填充这些间隔,可能…...

X2000 Linux UVC
参考文档:\doc\开发使用说明\USB使用说明文档\设备\USB_UVC\xburst2\USB_UVC.pdf 一、内核添加USB UVC功能 1、确定所用dts文件 进入到/tools/iconfigtool/IConfigToolApp/路径下,执行./IConfigTool 选择config文件,查看kernel默认配置 配…...
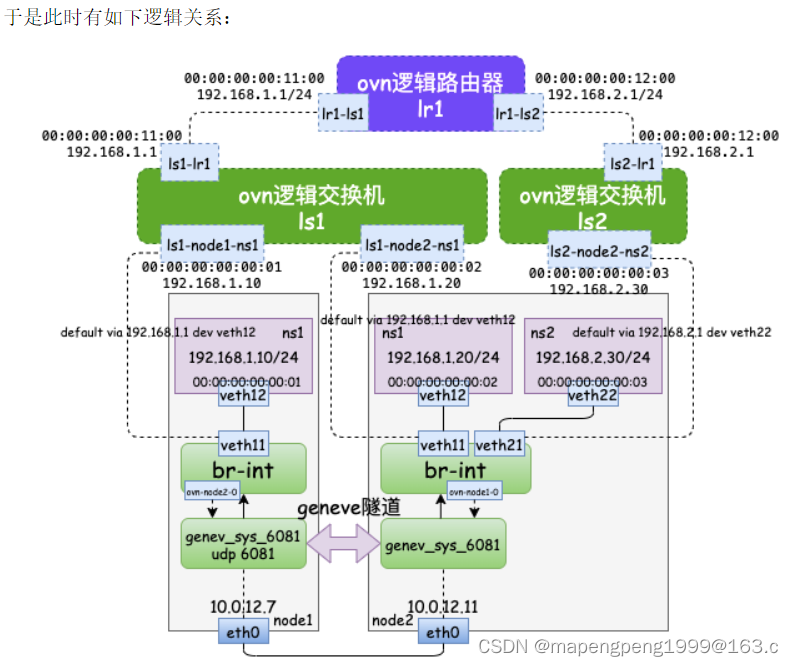
HCIP-OpenStack组件之neutron
neutron(ovs、ovn) OVS OVS(Open vSwitch)是虚拟交换机,遵循SDN(Software Defined Network,软件定义网络)架构来管理的。 OVS介绍参考:https://mp.weixin.qq.com/s?__bizMzAwMDQyOTcwOA&mid2247485088&idx1…...
)
数学建模-常见算法(3)
KMP算法(Knuth-Morris-Pratt算法) KMP算法是一种用于字符串匹配的算法,它的时间复杂度为O(mn)。该算法的核心思想是在匹配失败时,利用已经匹配的信息,减少下一次匹配的起始位置。 def kmp(text, pattern): n len(…...
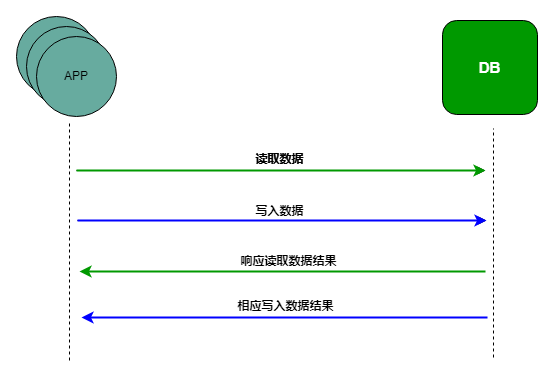
缓存的设计方式
问题情况: 当有大量的请求到内部系统时,若每一个请求都需要我们操作数据库,例如查询操作,那么对于那种数据基本不怎么变动的数据来说,每一次都去数据库里面查询,是很消耗我们的性能 尤其是对于在海量数据…...
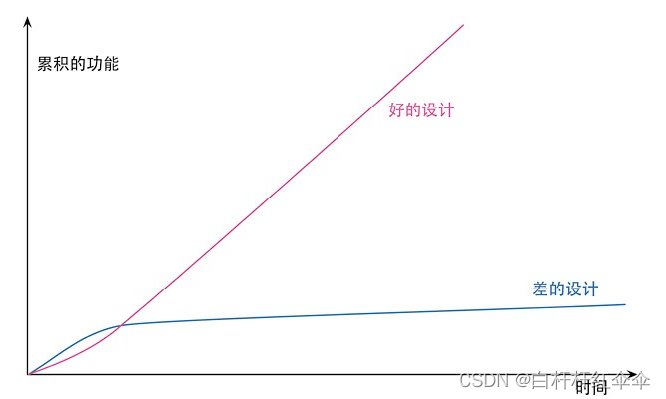
CH02_重构的原则(什么是重构、为什么重构、何时重构)
什么是重构 重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。 重构(动词):使用一系列重构手法࿰…...
)
26. 删除有序数组中的重复项(简单系列)
给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。 考虑 nums 的唯一元素的数量为 k ,你需要做…...
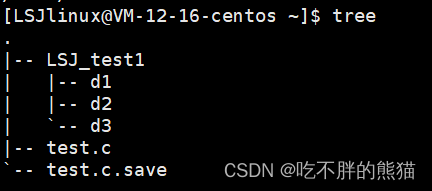
【linux】基本指令(二)【man、echo、cat、cp】
目录 一、man指令二、echo指令三、cat指令二、cp指令一些常见快捷键 一、man指令 Linux的命令有很多参数,我们不可能全记住,可以通过查看联机手册获取帮助。访问Linux手册页的命令是 man 语法: man [选项] 命令 常用选项 1.-k 根据关键字搜索联机帮助 2…...

【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享...
全文下载链接:http://tecdat.cn/?p23544 在本文中,长短期记忆网络——通常称为“LSTM”——是一种特殊的RNN递归神经网络,能够学习长期依赖关系(点击文末“阅读原文”获取完整代码数据)。 本文使用降雨量数据…...
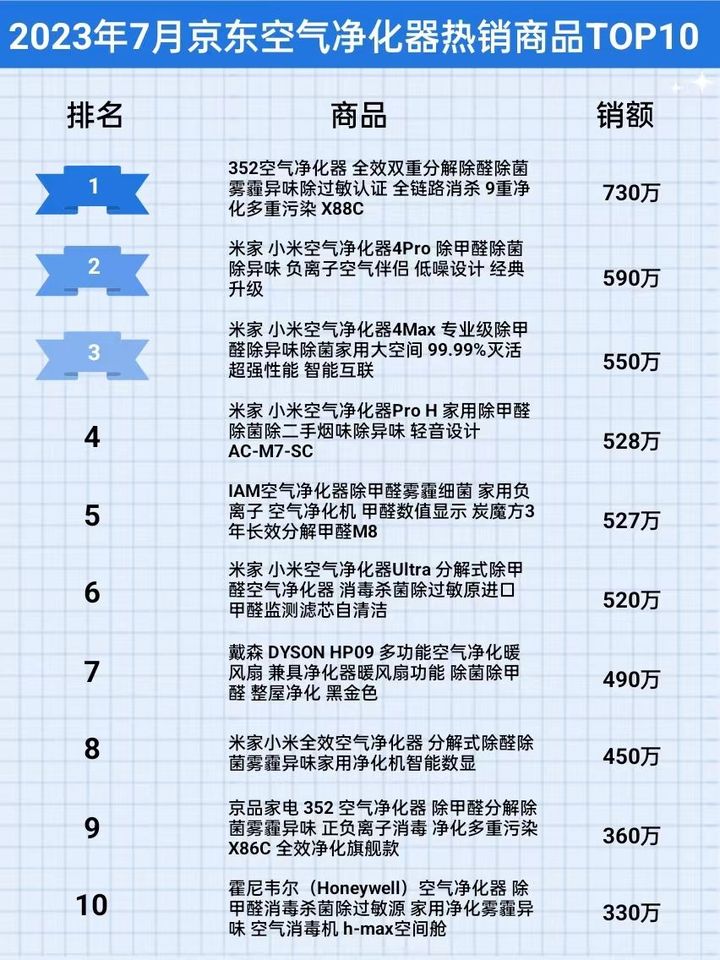
2023年7月京东空气净化器行业品牌销售排行榜(京东运营数据分析)
随着科技发展,智能家具在日常生活中出现的频率越来越高,许多曾经不被关注的家电也出现在其中,包括近年来逐渐兴起的空气净化器。伴随人们对自身健康的重视度越来越高,作为能够杀灭空气污染物、有效提高空气清洁度的产品࿰…...
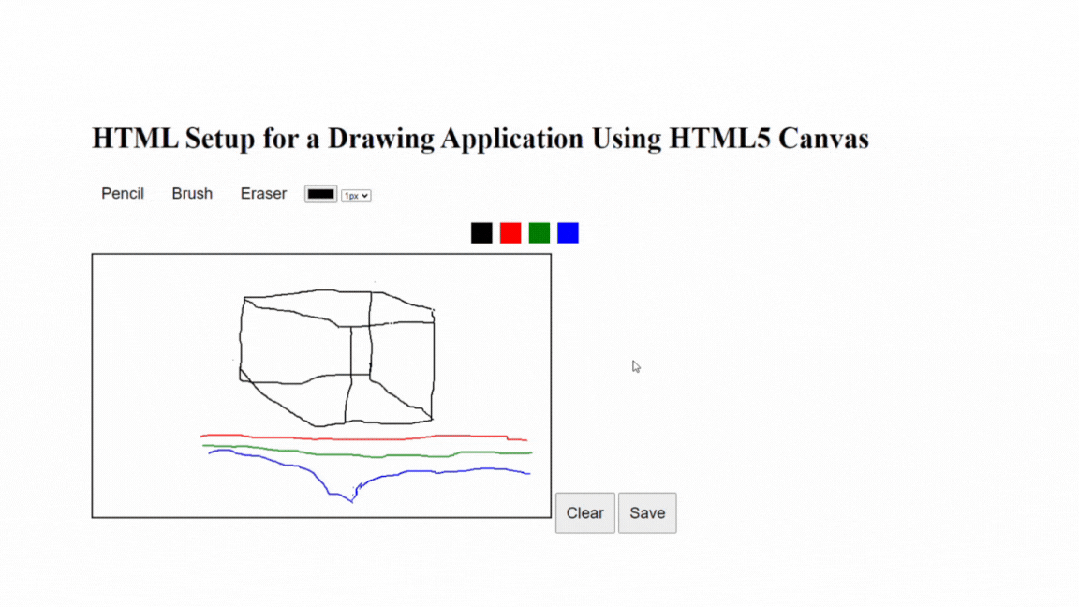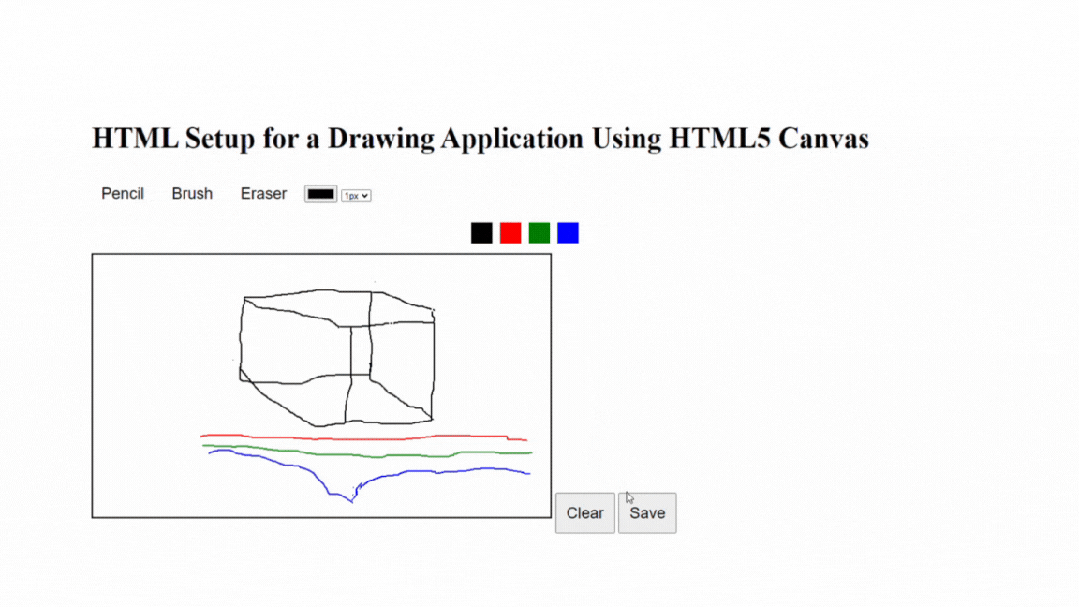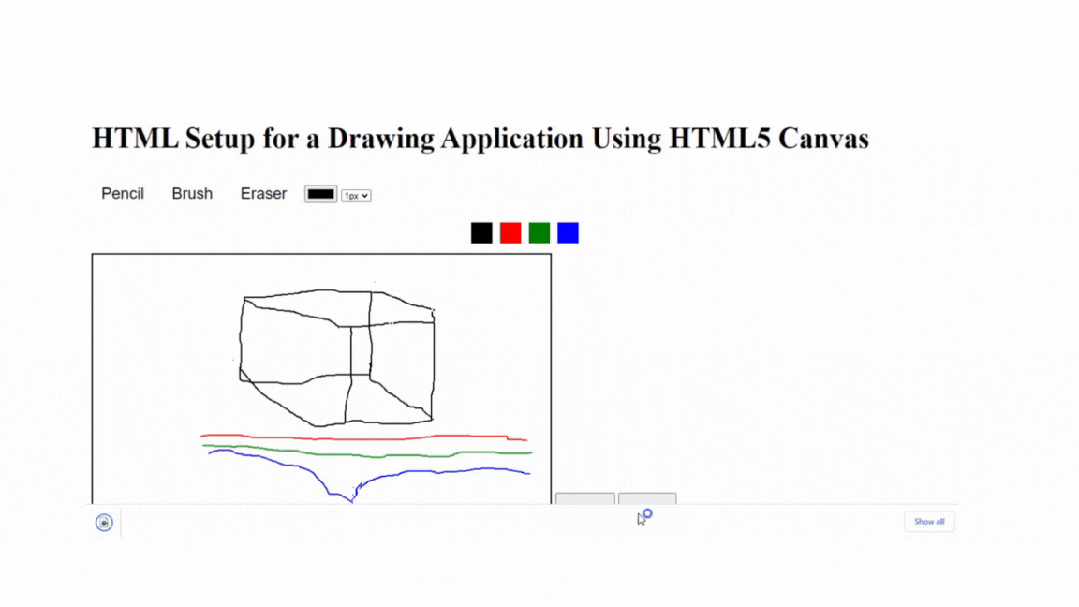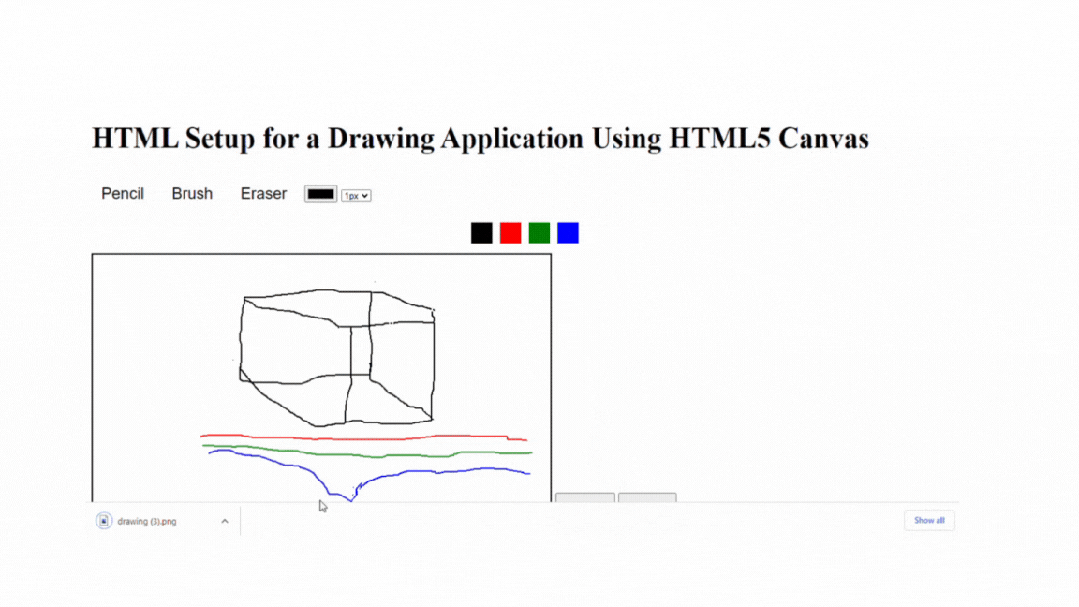
原生小案例:如何使用HTML5 Canvas构建画板应用程序
使用HTML5 Canvas构建绘图应用是在Web浏览器中创建交互式和动态绘图体验的绝佳方式。HTML5 Canvas元素提供了一个绘图表面,允许您操作像素并以编程方式创建各种形状和图形。本文将为您提供使用HTML5 Canvas创建绘图应用的概述和指导。此外,它还将通过解释…...
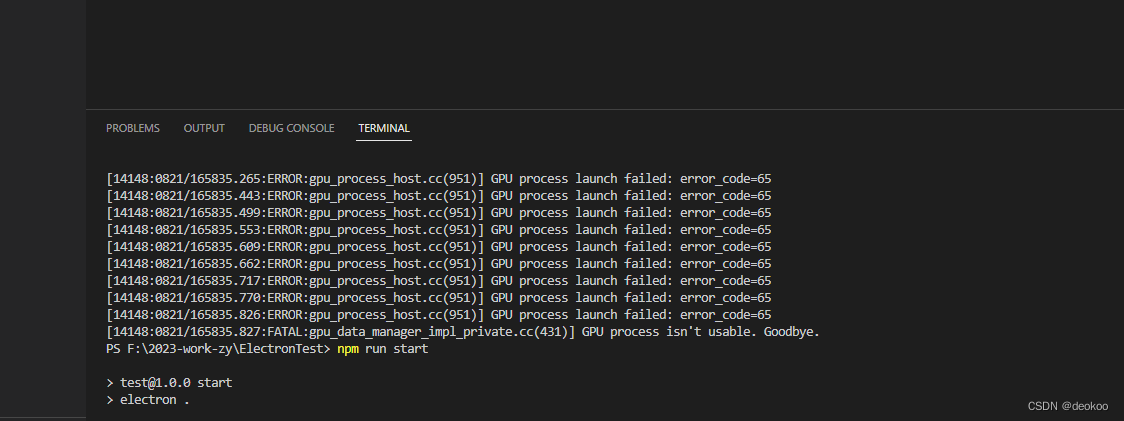
Electron 报gpu_process_host.cc(951)] GPU process launch faile错误
解决方法,在入口js文件中,添加如下代码: app.commandLine.appendSwitch(no-sandbox)...

每天一分享#读up有感#
不知道开头怎么写,想了一下,要不,就这样吧,开头也就写完 今日分享 分享一博主的分享——https://blog.csdn.net/zhangay1998/article/details/121736687 全程高能,大佬就diao,一鸣惊人、才能卓越、名扬四…...

threejs贴图系列(一)canvas贴图
threejs不仅支持各种texture的导入生成贴图,还可以利用canvas绘制图片作为贴图。这就用到了CanvasTexture,它接受一个canas对象。只要我们绘制好canvas,就可以作为贴图了。这里我们利用一张图片来实现这个效果。 基础代码: impo…...
taro react/vue h5 中的上传input onchange 值得区别
<inputclassNamebase-input-file-h5typefileacceptimage/*capturecameraonChange{onChangeInput} />1、taro3react 2、taro3vue3...
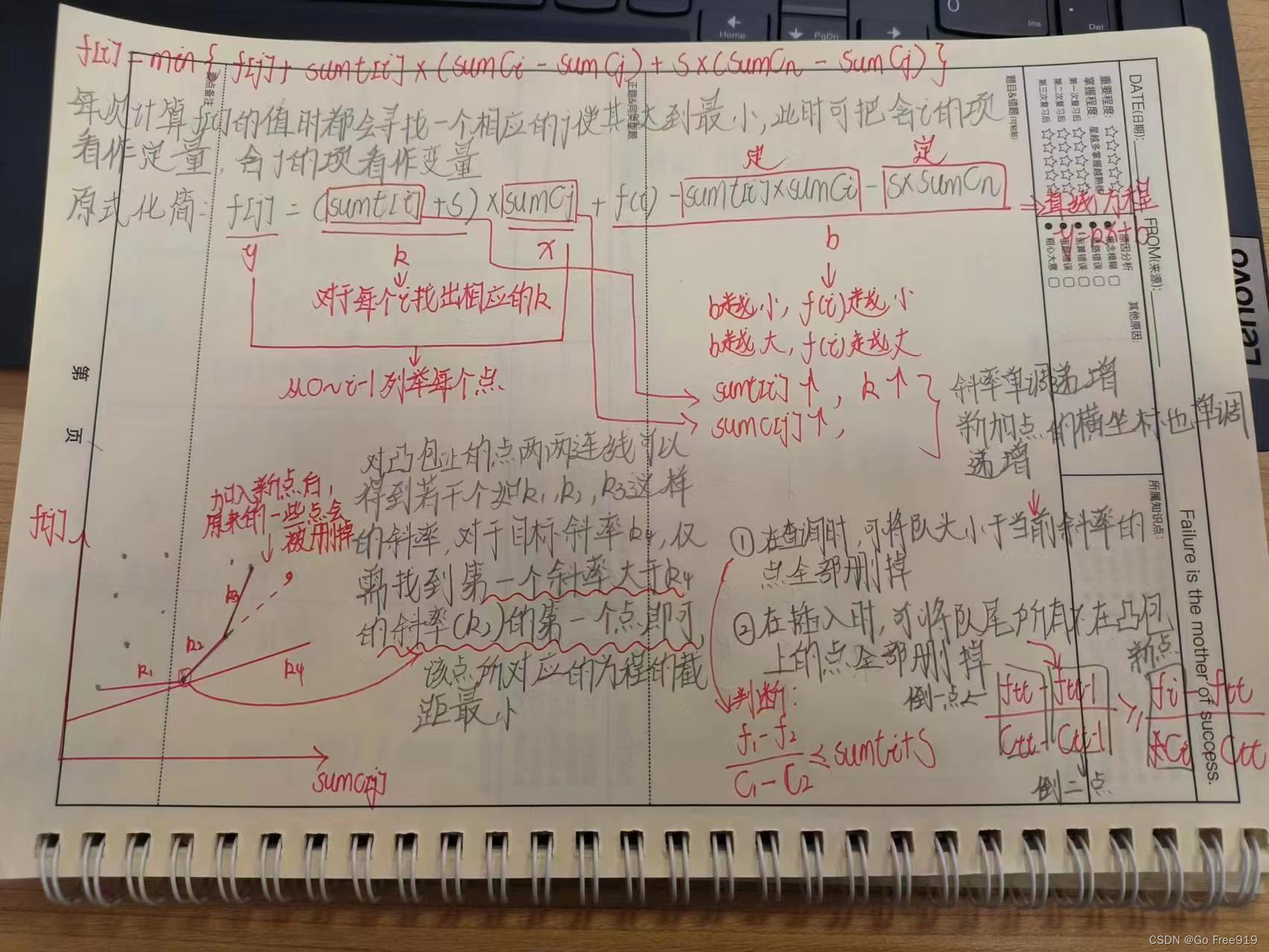
(AcWing) 任务安排(I,II,III)
任务安排I: 有 N 个任务排成一个序列在一台机器上等待执行,它们的顺序不得改变。 机器会把这 N 个任务分成若干批,每一批包含连续的若干个任务。 从时刻 0 开始,任务被分批加工,执行第 i 个任务所需的时间是 Ti。 另外&#x…...

STM32F103移植FreeRTOS实战:从零构建多任务系统
1. 项目概述:为什么要在STM32F103上跑RTOS? 如果你玩过一阵子STM32,特别是经典的“蓝桥杯”神板——STM32F103C8T6,那你大概率已经习惯了在 main 函数里写一个 while(1) 大循环,里面塞满了各种 HAL_Delay 和状态…...

CANN/asc-devkit SIMD向量长度获取函数
GetVecLen 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/…...

RK3576嵌入式平台Weston配置实战:从显示校准到性能调优
1. 项目概述:为什么Weston配置值得深挖?如果你正在基于RK3576这类高性能嵌入式平台进行产品开发,尤其是涉及图形化人机交互界面的项目,那么你大概率已经接触或正在使用Wayland/Weston这套显示协议栈。RK3576作为一款集成了强大GPU…...

实战手册:三小时精通waifu2x-caffe深度图像修复技术
实战手册:三小时精通waifu2x-caffe深度图像修复技术 【免费下载链接】waifu2x-caffe waifu2xのCaffe版 项目地址: https://gitcode.com/gh_mirrors/wa/waifu2x-caffe 你是否曾经面对一张低分辨率的老照片,渴望能看清其中的每一个细节?…...

从STM32转战合泰HT32F52352:手把手教你用GPTM定时器搞定四路舵机PWM控制
从STM32到HT32F52352的平滑迁移:GPTM定时器实现四路舵机PWM控制实战 对于习惯了STM32生态的开发者而言,初次接触合泰HT32系列MCU时往往面临两个挑战:如何快速理解新芯片的架构设计,以及如何将已有的STM32开发经验有效迁移。HT32F…...

UrsPahoMqttClient 心跳问题解决指南——Paho 底层已自动处理,设好 KeepAlive 就行
UrsPahoMqttClient 心跳问题解决指南 ——Paho 底层已自动处理,设好 KeepAlive 就行 问题 用 UrsPahoMqttClient 做 MQTT 连接时,心跳 PingReq 报文怎么发送?目的是保持连接,防止被 Broker 踢下线。 结论 不需要手动发心跳&#x…...

RK3568扩展模块实战:4G/Wi-Fi 6/多串口集成与Linux驱动适配
1. 项目概述:当“小”模块遇上“大”平台最近在折腾一块瑞芯微的RK3568开发板,这板子性能不错,四核A55加上独立的NPU,做边缘计算、多媒体网关或者轻量级服务器都挺合适。但在实际项目落地时,我遇到了一个几乎所有硬件开…...

Folcolor:让你的Windows文件夹告别“黄脸婆“,用色彩提升3倍工作效率
Folcolor:让你的Windows文件夹告别"黄脸婆",用色彩提升3倍工作效率 【免费下载链接】Folcolor Windows explorer folder coloring utility 项目地址: https://gitcode.com/gh_mirrors/fo/Folcolor 想象一下这样的场景:你的电…...

暗黑破坏神2存档编辑器终极指南:5步轻松掌握角色定制与物品管理
暗黑破坏神2存档编辑器终极指南:5步轻松掌握角色定制与物品管理 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否曾因暗黑破坏神2中稀有的装备掉落率而烦恼?是否想重新调整角色属性却不想从头开始&a…...

深入UE渲染管线:从.usf文件到FGlobalShader,理解全局Shader的完整生命周期与最佳实践
深入UE渲染管线:从.usf文件到FGlobalShader,理解全局Shader的完整生命周期与最佳实践 当我们需要在Unreal Engine中实现一个全新的后处理效果或定制底层渲染管线时,全局Shader(Global Shader)往往是必经之路。与材质编…...