大语言模型的分布式训练
什么是大语言模型
大语言模型(Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言数据中的复杂模式。
训练方式
训练语言模型需要向其提供大量的文本数据,模型利用这些数据来学习人类语言的结构、语法和语义。这个过程通常是通过无监督学习完成的,使用一种叫做自我监督学习的技术。在自我监督学习中,模型通过预测序列中的下一个词或标记,为输入的数据生成自己的标签,并给出之前的词。训练过程包括两个主要步骤:预训练(pre-training)和微调(fine-truning):在预训练阶段,模型从一个巨大的、多样化的数据集中学习,通常包含来自不同来源的数十亿词汇,如网站、书籍和文章。这个阶段允许模型学习一般的语言模式和表征。在微调阶段,模型在与目标任务或领域相关的更具体、更小的数据集上进一步训练。这有助于模型微调其理解,并适应任务的特殊要求。
面临的挑战
1. 资源消耗巨大:训练LLM需要大量的计算资源,这使得较小的组织或研究人员在开发和部署这些模型方面面临挑战。此外,与训练LLM有关的能源消耗也引起了一定程度的环境问题。
2. 输出可能带有偏见:由于训练数据中可能带有偏见,而LLM可!以学习并延续其训练数据中的偏见,导致有偏见的输出,可能是冒犯性的、歧视性甚至是错误性的观念。
3. 理解能力受限:虽然大语言模型有能力产生看似连贯和和与背景上下文相关的文本,但LLM有时对其所写的概念缺乏深刻的理解,这很可能导致不正确或无意义的输出。
什么是分布式计算
和集中式计算相反,分布式计算的一个计算过程将会在多台机器上进行。组件之间彼此进行交互以实现一个共同的目标,把需要进行大量计算的工程数据分区成小块,由多台计算机分别计算,再上传运算结果后,将结果统一合并得出数据结论。
如何实现
- 如何拆分计算逻辑
- 如何分发计算逻辑
拆分逻辑
从在哪里发生计算的角度来看,所有的计算逻辑都能够划分为这两种类型:
1能够分发到各个节点上并行执行的
2需要经过一定量的结果合并之后才能继续执行的
两者之间协调完成还需要解决 通讯、容灾、任务调度等问题
首先对此公开提出解决方案的是Google的MapReduce论文
Map Job 对应的就是可以在各个节点上一起执行相互不影响的逻辑
Reduce Job 处理的就是Map产生的中间结果
Map和Reduce之间通过一个Shuffle过程来链接
分发逻辑
与集中式计算最大的不同点:移动计算逻辑而不移动数据
大语言模型的分布式训练
大模型可以带来更精准强大的语义理解和推理能力,所以随着规模计算的普及和数据集的增大,使得模型的参数数量也以指数级的速度增长。训练这样大的模型非常具有挑战性,具体原因如下:
对显存的挑战。即使是最大的GPU的主内存也不可能适合这些模型的参数,比如一个175B的GPT-3模型需要(175B * 4bytes)就是700GB模型参数空间,从而梯度也是700G,优化器状态是1400G,一共2.8TB。
对计算的挑战。即使我们能够把模型放进单个GPU中(例如,通过在主机和设备内存之间交换参数),但是其所需的大量计算操作会导致漫长训练时间(例如,使用单个V100 NVIDIA GPU来训练1750亿个参数的GPT-3需要大约288年)。如何计算可以参见 2104.04473的附录 FLOATING-POINT OPERATIONS。
对计算的挑战。不同并行策略对应的通信模式和通信量不同。数据并行:通信发生在后向传播的梯度规约all-reduce操作,通信量是每个GPU之上模型的大小。模型并行:在下面会详述。
这就需要采用并行化来加速。使用硬件加速器来横向扩展(scale out)深度神经网络训练主要有两种模式:数据并行,模型并行。
数据并行
数据并行模式会在每个worker之上复制一份模型,这样每个worker都有一个完整模型的副本。输入数据集是分片的,一个训练的小批量数据将在多个worker之间分割;
worker定期汇总它们的梯度,以确保所有worker看到一个一致的权重版本。对于无法放进单个worker的大型模型,人们可以在模型之中较小的分片上使用数据并行。
数据并行扩展通常效果很好,但有两个限制:a)超过某一个点之后,每个GPU的batch size变得太小,这降低了GPU的利用率,增加了通信成本;b)可使用的最大设备数就是batch size,着限制了可用于训练的加速器数量。
模型并行
WHY:业界内训练的模型越来越大,模型朝着更深和更宽的方向发展。以自然语言处理(NLP)领域为例,模型从Bert发展到GPT,模型规模从数亿参数量增加到数百亿甚至是数千亿。当参数规模为千亿时,存储模型参数就需要数百GB的显存空间,超出单个GPU卡的显存容量。显然,仅靠数据并行无法满足超大规模模型训练对于显存的需求。为了解决这个问题,可以采用模型并行技术。人们会使用一些内存管理技术,如激活检查点(activation checkpointing)来克服数据并行的这种限制,也会使用模型并行来对模型进行分区来解决这两个挑战,使得权重及其关联的优化器状态不需要同时驻留在处理器上。WHAT:模型并行模式会让一个模型的内存和计算分布在多个worker之间,以此来解决一个模型在一张卡上无法容纳的问题,其解决方法是把模型放到多个设备之上。
模型并行分为两种:流水线并行和张量并行,就是把模型切分的方式。
流水线并行
流水线并行(pipeline model parallel)是把模型不同的层放到不同设备之上,比如前面几层放到一个设备之上,中间几层放到另外一个设备上,最后几层放到第三个设备之上。
张量并行
张量并行则是层内分割,把某一个层做切分,放置到不同设备之上,也可以理解为把矩阵运算分配到不同的设备之上,比如把某个矩阵乘法切分成为多个矩阵乘法放到不同设备之上。
通信
张量并行:通信发生在每层的前向传播和后向传播过程之中,通信类型是all-reduce,不但单次通信数据量大,并且通信频繁。
流水线并行:通信在流水线阶段相邻的切分点之上,通信类型是P2P通信,单词通信数据量较少但是比较频繁,而且因为流水线的特点,会产生GPU空闲时间,这里称为流水线气泡(Bubble)。
PS
NCCL是Nvidia Collective multi-GPU Communication Library的简称,它是一个实现多GPU的collective communication通信(all-gather, reduce, broadcast)库,Nvidia做了很多优化,以在PCIe、Nvlink、InfiniBand上实现较高的通信速度。
All-reduce:从多个sender那里接收数据,最终combine到每一个节点上。
Transformer Attention MLP GeLU Dropout
未完待续…
引用
https://blog.csdn.net/weixin_47364682/article/details/122674457
https://zhuanlan.zhihu.com/p/507877303
https://zhuanlan.zhihu.com/p/617087561
https://zhuanlan.zhihu.com/p/28653942
https://zhuanlan.zhihu.com/p/129912419
https://www.zhihu.com/question/508671222
相关文章:

大语言模型的分布式训练
什么是大语言模型 大语言模型(Large Language Model,缩写LLM),也称大型语言模型,是一种人工智能模型,旨在理解和生成人类语言。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。LLM的特点是规模庞大,包含数十亿的参数,帮助它们学习语言…...
【JavaEE】Spring全家桶实现AOP-统一处理
【JavaEE】AOP(2) 文章目录 【JavaEE】AOP(2)1. 统一登录校验处理1.1 自定义拦截器1.2 将自定义拦截器加入到系统配置1.3 测试1.4 对于静态资源的处理1.5 小练习:统一登录拦截处理1.6 拦截器原理1.6.1 执行流程1.6.2 源…...
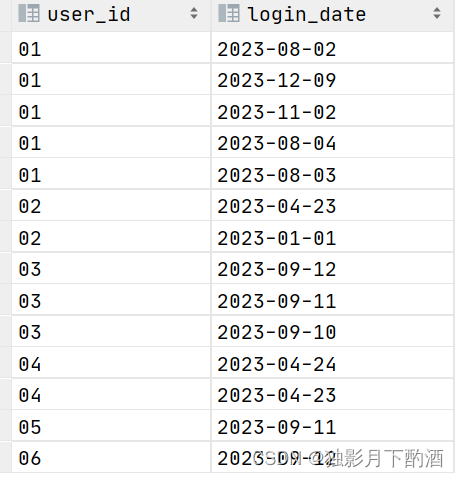
HQL解决连续三天登陆问题
1.背景 统计连续登录天数超过3天的用户,输出信息包括:用户id,登录天数,起始时间,结束时间; 2.准备数据 -- 建表 create table if not exists user_login_3days(user_id STRING,login_date date );--插入…...
Docker简介(一篇足以))
(一)Docker简介(一篇足以)
一、简介 一个项目环境配置相当麻烦,如果换一台机器跑起来,所有配置就要重来一次,费力费时。很多人想到,能不能从根本上解决问题,软件可以带环境安装?也就是说,安装的时候,把原始环…...
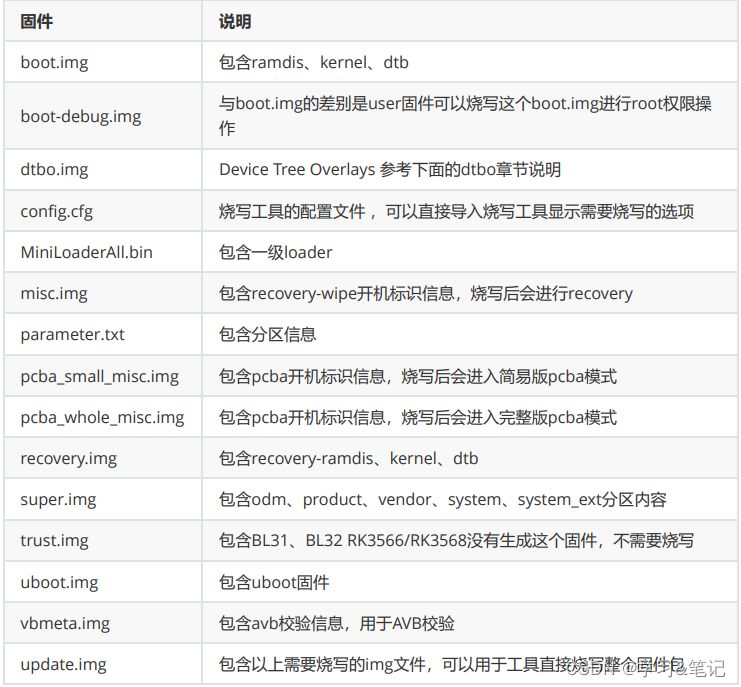
RK3568 安卓源码编译
一.repo安卓编译工具 项目模块化/组件化之后各模块也作为独立的 Git 仓库从主项目里剥离了出去,各模块各自管理自己的版本。Android源码引用了很多开源项目,每一个子项目都是一个Git仓库,每个Git仓库都有很多分支版本,为了方便统…...
第4篇:vscode+platformio搭建esp32 arduino开发环境
第1篇:Arduino与ESP32开发板的安装方法 第2篇:ESP32 helloword第一个程序示范点亮板载LED 第3篇:vscode搭建esp32 arduino开发环境 1.配置默认安装路径,安装到D盘。 打开环境变量,点击新建 输入变量名PLATFORMIO_CORE_DIR与路径:D:\PLATF…...
2023前端面试笔记 —— CSS3
系列文章目录 内容链接2023前端面试笔记HTML52023前端面试笔记CSS3 文章目录 系列文章目录前言一、CSS选择器的优先级二、通过 CSS 的哪些方式可以实现隐藏页面上的元素三、px、em、rem之间有什么区别?四、让元素水平居中的方法有哪些五、在 CSS 中有哪些定位方式六…...
iOS 如何对整张图分别局部磨砂,并完全贴合
官方磨砂方式 - (UIVisualEffectView *)effectView{if(!_effectView){UIBlurEffect *blur [UIBlurEffect effectWithStyle:UIBlurEffectStyleLight];_effectView [[UIVisualEffectView alloc] initWithEffect:blur];}return _effectView; }使用这种方式对一张图的上半部分和…...
Packet_Tracer的使用
一、实验目的: 通过该实验了解Packet Tracer的使用方法,能够用Packet Tracer建立和模拟网络模型。 二、主要任务: 1.熟悉PT的界面,了解按键用途。 2.尝试自己建立一个小型网络,并测试连通性。 3.学习P…...

WPF如果未定义绑定的属性,程序如何处理
问题:wpf中,<Button IsEnabled"{Binding IsValid1}"></Button>,如果没定义绑定的属性IsValid1,可以正常用吗 解答:在 WPF 中,如果没有定义绑定的属性 IsValid1,会导致绑…...

韩国留学生生活之-租房篇,柯桥韩语培训留学韩语需要学到什么程度
对于计划在韩国留学的人来说,找到合适的租房是一个重要而且有挑战性的任务。 留学生遇到的常见租房类型为月付型、全税房。月付型就是我们常见的租房方式,一般都需要支付一个月或数个月月租的押金,按时间付房租即可,租期通常为一…...

论文笔记:基于概念漂移的在线类非平衡学习系统研究
0 摘要 论文:A Systematic Study of Online Class Imbalance Learning With Concept Drift 发表:2018年发表在TNNLS上 源代码:? 作为一个新兴的研究课题,在线类非平衡学习往往结合了类非平衡和概念漂移的挑战。它处理…...

ubuntu22.04下rv1109 rootfs编译问题处理
ubuntu22.04下rv1109 rootfs编译问题处理 buildroot编译出错记录问题一:c-stack.c的SIGSTKSZ错误解决办法问题二:libfakeroot.c的_STAT_VER报错解决办法问题三:fwriter_buffer重复定义解决办法问题四: qfloat16.h报错解决办法问题…...

Spring Boot Dubbo Zookeeper
文章目录 Spring Boot Dubbo Zookeeper简介DubboCommonProviderConsumer Zookeeper Spring Boot Dubbo Zookeeper 简介 Dubbo Common 公共依赖 <!-- Spring Boot Starter --> <dependency><groupId>org.springframework.boot</groupId><artifac…...
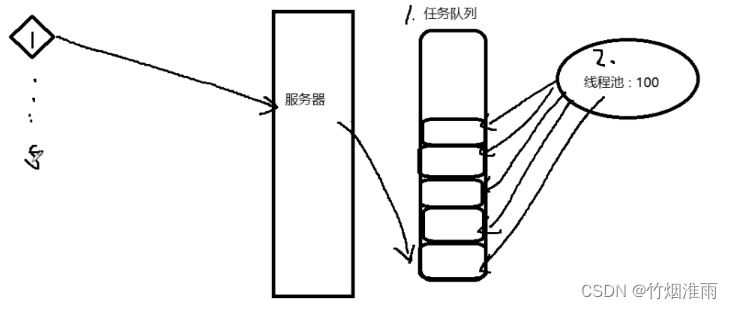
线程池的概念及实现原理
本篇是对前面线程池具体实现过程的补充,实现过程可参考 线程池的实现全过程v1.0版本(手把手创建,看完必掌握!!!)_竹烟淮雨的博客-CSDN博客 线程池的实现v2.0(可伸缩线程池…...
iOS App逆向之:iOS应用砸壳技术
在iOS逆向,有一项关键的技术叫做“iOS砸壳”(iOS App Decryption)。自iOS 5版本以来,苹果引入了应用程序加密机制,使得大部分应用都需要进行砸壳操作才能进行逆向分析。因此作为开发者、逆向工程师和安全研究人员都需要…...

【高性能计算】opencl安装及相关概念
目录 从异构计算讲起opencl安装的相关说明查看linux系统cpu及gpu型号方法安装opencl helloword程序运行 从异构计算讲起 异构计算是一种利用多种不同类型的计算资源来协同解决计算问题的方法。它的核心思想是将不同特性和能力的计算设备(例如CPU、GPU、FPGA等&…...

盛最多水的容器——力扣11
int maxArea(vector<int>& height) {int l=0, r=height.size()...

2023年高教社杯数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

Flink_state 的优化与 remote_state 的探索
摘要:本文整理自 bilibili 资深开发工程师张杨,在 Flink Forward Asia 2022 核心技术专场的分享。本篇内容主要分为四个部分: 相关背景state 压缩优化Remote state 探索未来规划 点击查看原文视频 & 演讲PPT 一、相关背景 1.1 业务概况 从…...

巡检记录分析不全面,导致安全隐患遗漏频发怎么办?揭秘实在Agent非侵入式提效方案
摘要:在2026年工业4.0与智慧安全深度融合的背景下,许多企业仍面临“巡检记录分析不全面,安全隐患遗漏频发”的顽疾。传统的纸质记录或初级数字化巡检,往往因数据孤岛、老旧系统无API接口、以及AI无法触达内网执行层等问题…...
)
DeepSeek SSO权限同步失效深度复盘(附完整日志追踪链路图)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek SSO权限同步失效深度复盘(附完整日志追踪链路图) 问题现象与影响范围 2024年10月17日 02:48 UTC,DeepSeek内部SSO系统(基于Keycloak 22.0.5&am…...
内核移植:基于i.MX6ULL的嵌入式Linux终端系统构建与多子系统控制器驱动开发—将 NXP 官方 Linux内核4.9.88 移植到韦东山IMX6ULLPro)
个人项目记录(二)内核移植:基于i.MX6ULL的嵌入式Linux终端系统构建与多子系统控制器驱动开发—将 NXP 官方 Linux内核4.9.88 移植到韦东山IMX6ULLPro
本文是个人项目记录(二)内核移植:基于i.MX6ULL的嵌入式Linux终端系统构建与多子系统控制器驱动开发,记录了将NXP官方Linux内核4.9.88移植到百问网(100ASK)IMX6ULL Pro开发板的完整过程,包括defc…...

90%的人只用了Superpowers 10%的能力,实战案例带你走通全流程
装了Superpowers还是不会用?这套完整工作流,让你的AI从“工具”变“搭档”你可能已经在 GitHub 上给 Superpowers 点过 Star 了,甚至在本地环境里跑了一遍安装流程。但说实话,你大概率只触发了其中一两个 Skill——写代码时偶尔触…...

RK3576+Hailo-8异构计算:破解高帧率摄像头实时AI分析算力瓶颈
1. 项目概述:从“看得见”到“看得懂”的实时化挑战最近在折腾一个智能安防的项目,客户提了个听起来简单但做起来挠头的要求:他们希望摄像头不仅能24小时不间断录像,还要能“实时”分析画面里发生的事——比如识别出有人闯入、车辆…...

在Blender中创建逼真流体模拟:FLIP Fluids插件完全指南
在Blender中创建逼真流体模拟:FLIP Fluids插件完全指南 【免费下载链接】Blender-FLIP-Fluids The FLIP Fluids addon is a tool that helps you set up, run, and render high quality liquid fluid effects all within Blender, the free and open source 3D crea…...

2026年初中生赴新加坡留学,费用究竟几何?一文为你揭秘!
在教育全球化的今天,越来越多的家长将目光投向海外,新加坡凭借其优质的教育资源、安全的社会环境和多元的文化氛围,成为众多初中生留学的热门选择。那么,2026年初中生赴新加坡留学的费用到底是多少呢?本文将为你详细揭…...

BGP状态机详解:从邻居建立到故障排查的完整指南
1. 项目概述:从“拒绝一切”到“稳定对话”的BGP邻居建立之旅如果你在网络运维或者数据中心工作的岗位上待过一阵子,肯定对BGP(边界网关协议)又爱又恨。爱的是它作为互联网“大管家”的稳定和强大,恨的是它一旦出问题&…...

论文小白必看!书匠策AI到底怎么帮你把毕业论文“拼“出来?看完这篇你就全懂了
各位还在深夜对着Word文档抓头发的同学,先别急着崩溃,今天咱们用最轻松的方式,聊聊一个正在帮无数毕业生"逆天改命"的工具——书匠策AI。 官方网址:** 官网直达:www.shujiangce.com*,微信搜一搜…...

猫抓浏览器扩展:基于网络请求拦截的智能资源嗅探技术实现
猫抓浏览器扩展:基于网络请求拦截的智能资源嗅探技术实现 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat Catch&a…...