从零开始使用MMSegmentation训练Segformer
从零开始使用MMSegmentation训练Segformer
写在前面:最新想要用最新的分割算法如:Segformer or SegNeXt 在自己的数据集上进行训练,但是有不是搞语义分割出身的,而且也没有系统的学过MMCV以及MMSegmentation。所以就折腾了很久,感觉利用MMSegmentation搭建框架可能比较系统,但是对于不熟悉的或者初学者非常不友好,因此记录一下自己training Segformer的心路历程。
Segformer paper: https://arxiv.org/abs/2105.15203>
官方实现: https://github.com/NVlabs/SegFormer>
纯Torch版Segformer: https://github.com/camlaedtke/segmentation_pytorch>
方法
由于本人不是研究语义分割的,所以只能简要地介绍一下Segformer。
SegFormer的动机在于:
① ViT作为backbone只能输出固定分辨率的特征图,这对于密集预测任务显然不够友好;
② 由于self-attention操作的存在,transformer的运算量和参数两都非常大,不利于大尺度图像的分割。
为此作者提出了相应的创新:
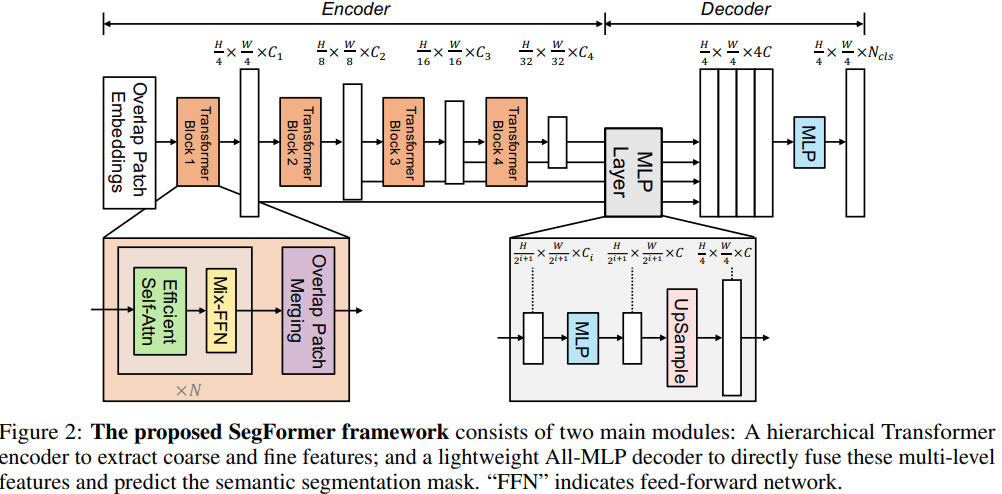
① 先是对transformer进行层次化结构设计,得到多层级的特征图;
② 构造轻量级的decoder,仅使用MLP进行特征聚合。
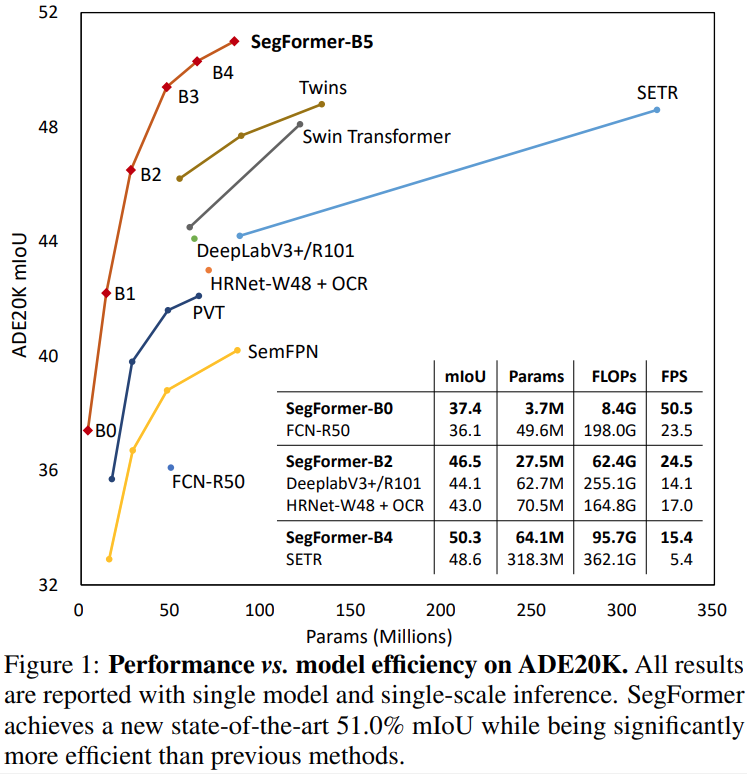
③ 除此之外,SegFormer抛弃了位置信息编码,选择采用MixFCN来学习位置信息,这样可以很好地扩充到不同尺度的测试环境下(避免由于尺寸变化,需要对positional-encoding进行插值,从而影响性能)。最后提出的模型在ADE20k上达到了新sota,并且在速度、性能和鲁棒性上都表现很好。
程序复现
在重新训练过程中主要参考了:手把手教你使用Segformer训练自己的数据
作者给的教程比较详细, 但是有几处修改并不合适,导致我复现出来的结果没啥效果,因此记录一下自己的采坑记录。
自己的主要配置为:
CUDA 10.1
Pytorch 1.10.0, torchvision 0.11.1
MMCV-full 1.3.0
其中在安装MMCV-full过程中还遇到了很多问题,主要是版本不适配的原因导致的。
在安装好环境后,首先从Github下载SegFormer的项目工程: https://github.com/NVlabs/SegFormer
然后进去SegFormer目录:
pip install -r requirements.txt
pip install -e . --use
安装需要的依赖。
数据集准备
代码默认用的是ADE20K数据集进行训练
ADE20K数据集 格式如下,按照要求放就完了
├── data
│ ├── ade
│ │ ├── ADEChallengeData2016
│ │ │ ├── annotations
│ │ │ │ ├── training
│ │ │ │ ├── validation
│ │ │ ├── images
│ │ │ │ ├── training
│ │ │ │ ├── validation
但是@中科哥哥使用的是VOC的数据格式,因此就使用了VOC的数据格式
├── VOCdevkit
│ ├── VOC2012
│ │ ├── ImageSets
│ │ │ ├── Segmentation
│ │ │ │ ├── train.txt
│ │ │ │ ├── val.txt
│ │ │ │ ├── trainval.txt│ │ │ ├── JPEGImages
│ │ │ │ ├── *.jpg #所有图片│ │ │ ├── SegmentationClass
│ │ │ │ ├── *.jpg #所有标签图
在这里可以根据自己的需要修改
下面是我自己的数据格式:
├── VOCdevkit
│ ├── VOC2012
│ │ ├── ImageSets
│ │ │ ├── Segmentation
│ │ │ │ ├── train.txt
│ │ │ │ ├── val.txt
│ │ │ │ ├── test.txt│ │ │ ├── JPEGImages
│ │ │ │ ├── *.png#所有图片│ │ │ ├── SegmentationClass
│ │ │ │ ├── *.png #所有标签图
其实完全可以简洁一点:
├── MFNet
│ ├── Segmentation
│ │ ├── train.txt
│ │ ├── val.txt
│ │ ├── test.txt│ ├── Images
│ │ ├── *.png#所有图片│ ├── Label
│ │ ├── *.png #所有标签图
其中: train.txt; val.txt; test.txt; 只要图片名,不需要后缀和路径 如下
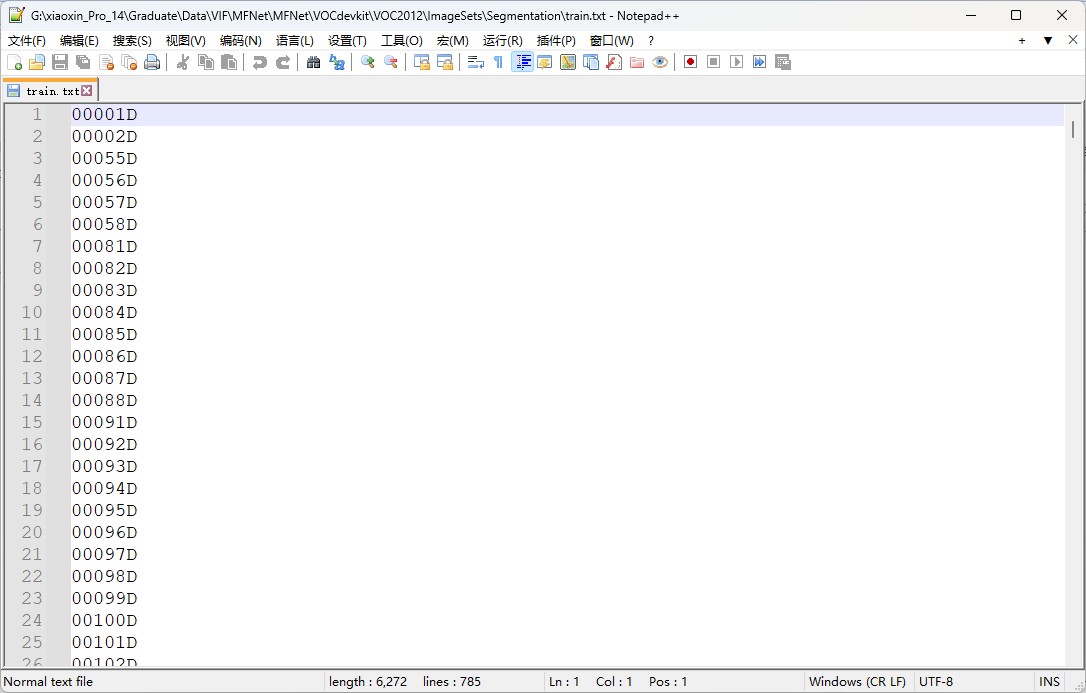
后面的程序修改都基于复杂的版本进行介绍(自己在程序复现时使用的复杂的目录,因为是按照的教程来的)
数据准备好之后可以在SegFormer目录先新建一个/datasets/ 目录来存放自己的数据集
程序修改
-
在 mmseg/datasets/voc.py修改自己数据集的类别即修改CLASSES 和 PALETTE在我自己的数据集中一共由于9个类别,所以修改如下:

-
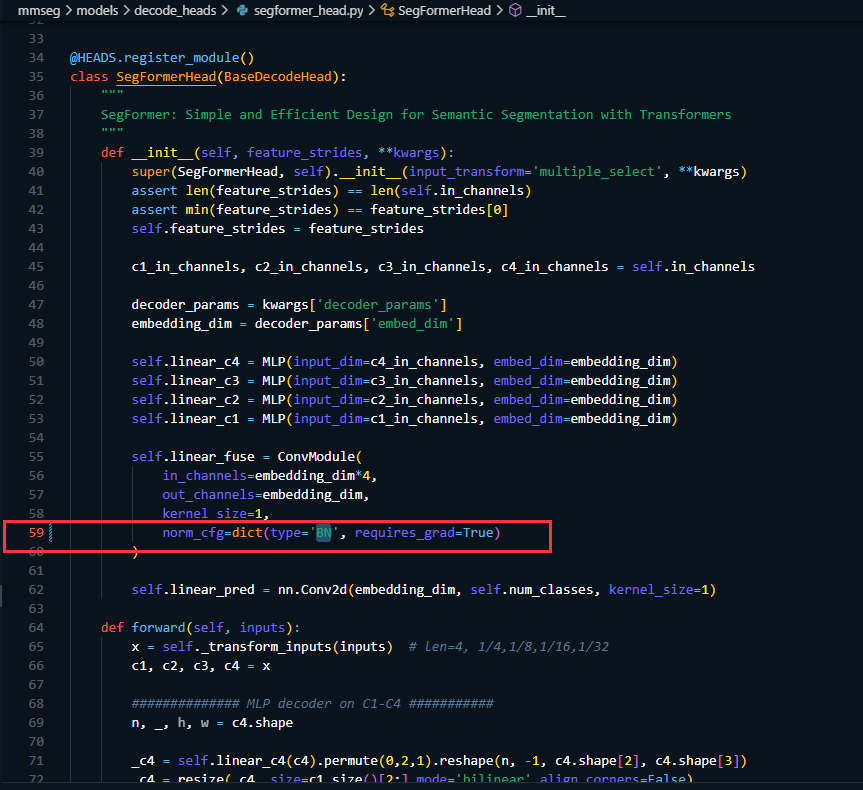
在 mmseg/models/decode_heads/segformer_head.py 中BatchNorm 方式(如果使用单卡训练的话就修改,多卡训练的话就不用修改)。 将第59行的SyncBN 修改为 BN
-
修改 local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py 的配置文件(这里我们使用的是B5模型,需要使用哪个模型就修改对应的配置文件即可,配置文件都位于:**local_configs/segformer/**下 );主要修改
__base__=[]中的数据集文件路径(也就是下图中的第二行)
指定dataset_type的类型,此处
dataset_type = 'PascalVOCDataset'
data_root = '/data1/timer/Segmentation/SegFormer/datasets/VOC2012' 也可以给相对路径。
然后根据自己的数据需要修改文件中的crop_size, train_pipline中的img_scale,以及test_pipline中的img_scale
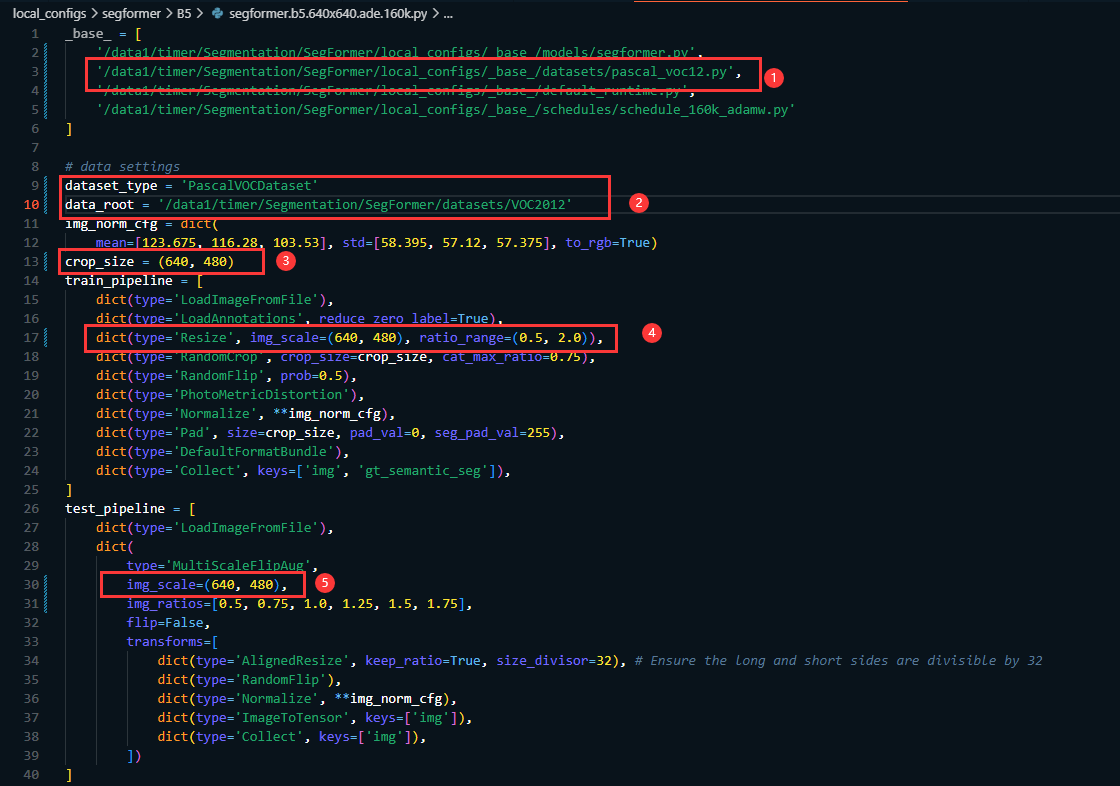
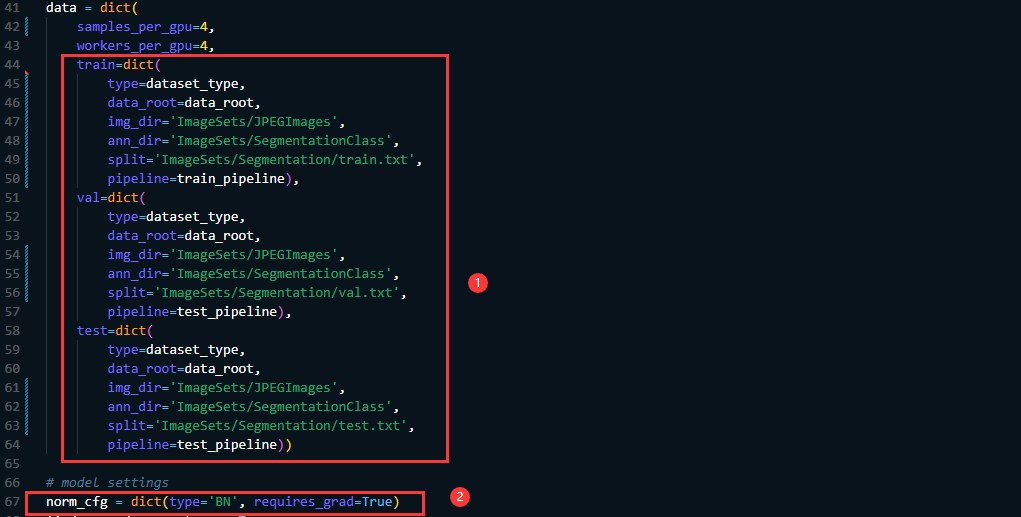
同时好需要在data字典中指定 img_dir, ann_dir, 以及split的路径,如果是单卡训练的话需要将norm_cfg 的type由的SyncBN 修改为 BN
接下来继续修改模型相关的文件,主要是给定预训练权重的位置即修改:pretrained 以及backbone[‘type’],这里的type因为使用的是B5的结构所以type就指定为mit_b5,然后预训练权重需要从项目中给定的链接下载。值得注意的是还需要指定decode_head[‘num_classes’] (这个需要根据你的数据集来指定,因为我的数据集中包含9类,所以这里就设置为9了)
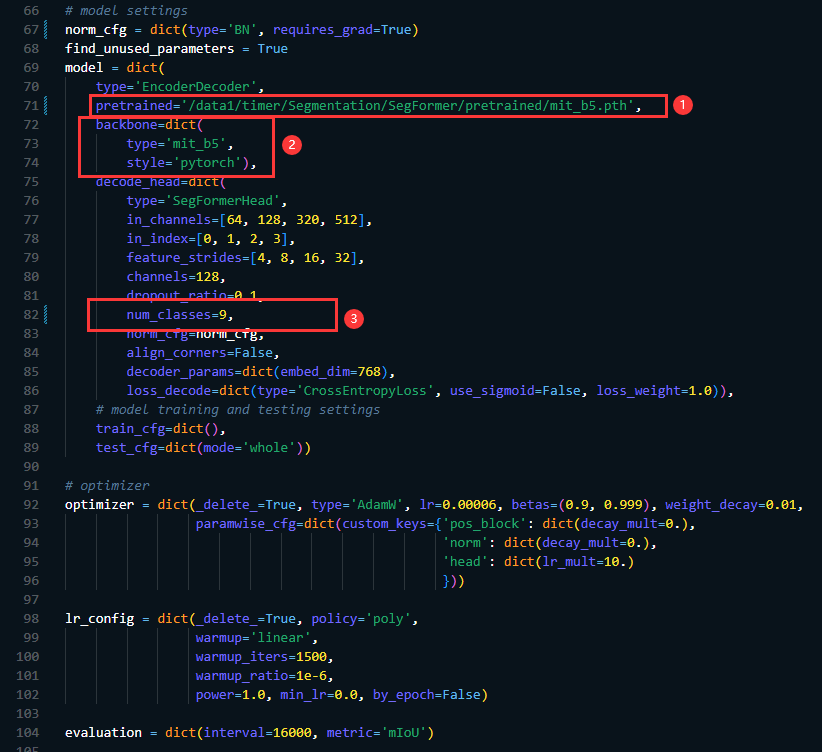
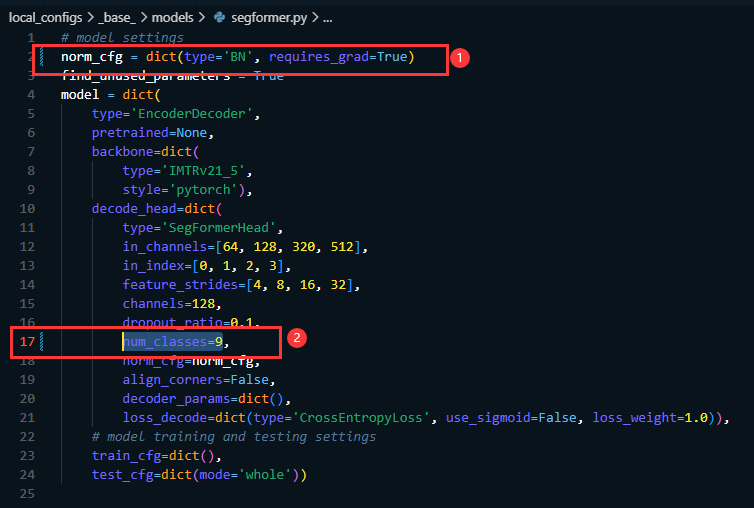
- 在 local_configs/base/models/segformer.py 修改
norm_cfg[‘type’]=‘BN’
num_classes=9 (这里修改成你数据集对应的类别的数量)
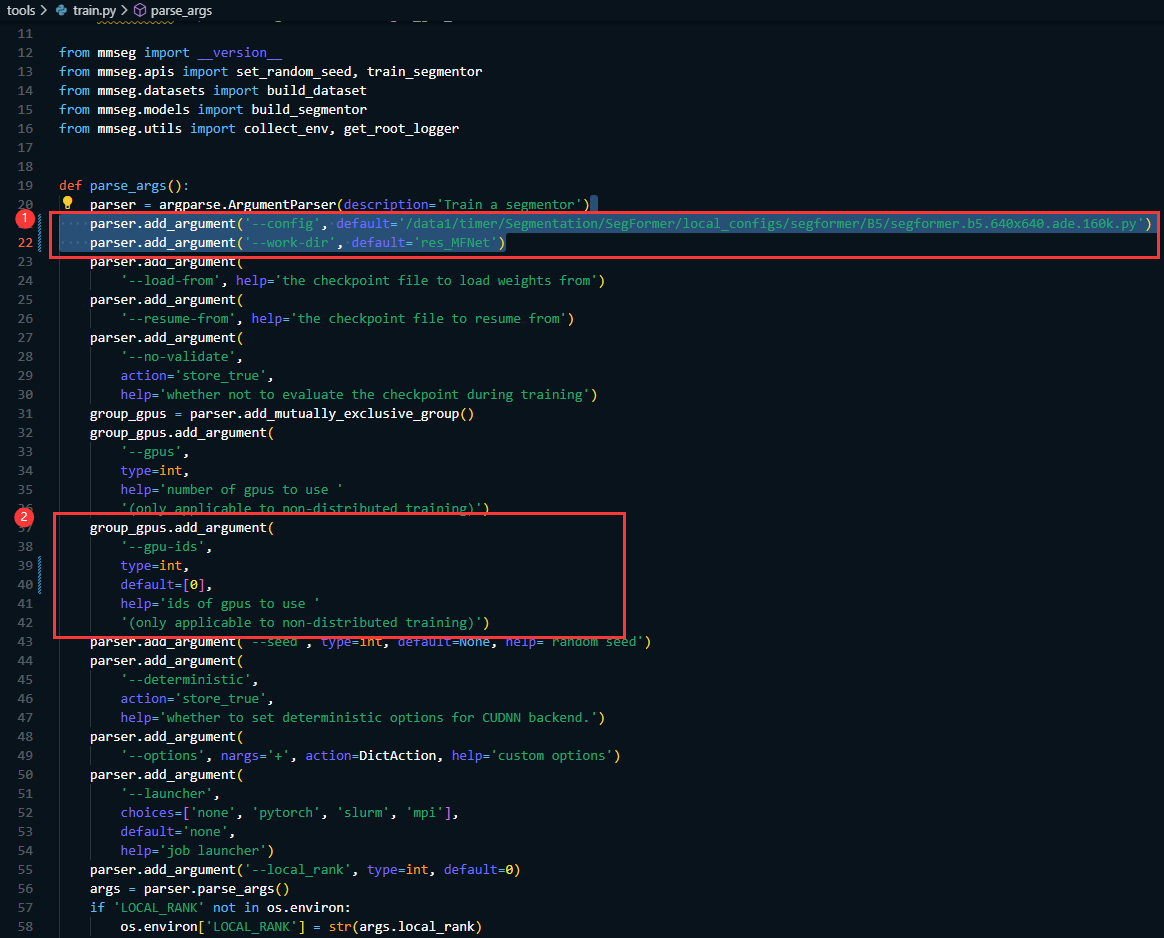
5. 在 tools/train.py中修改
parser.add_argument('--config', default='/data1/timer/Segmentation/SegFormer/local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py')
parser.add_argument('--work-dir', default='res_MFNet')
其中 /data1/timer/Segmentation/SegFormer/local_configs/segformer/B5/segformer.b5.640x640.ade.160k.py 是配置文件的路径
res_MFNet是训练日志和模型保存的路径
同时指定GPU的卡号
group_gpus.add_argument('--gpu-ids',type=int, default=[0],help='ids of gpus to use ''(only applicable to non-distributed training)')
 6. 进入tools目录下运行
6. 进入tools目录下运行
python train.py
即可开始训练模型。
由于本人也在摸索阶段,有不当之处,恳请各位不吝赐教。也欢迎大家交流:2458707789@qq.com
相关文章:
从零开始使用MMSegmentation训练Segformer
从零开始使用MMSegmentation训练Segformer 写在前面:最新想要用最新的分割算法如:Segformer or SegNeXt 在自己的数据集上进行训练,但是有不是搞语义分割出身的,而且也没有系统的学过MMCV以及MMSegmentation。所以就折腾了很久&am…...

会利用信息差赚钱的人才是聪明人
毕业后找不到工作,穷到只剩下时间,大小做了20多份副业兼职,终于找到了可靠的渠道, 我是专科生,学历不好,专业拉胯。毕业后,我找了两三份工作。要么工资太低,只能交房租,…...

【机器学习】Adaboost
1.什么是Adaboost AdaBoost(adapt boost),自适应推进算法,属于Boosting方法的学习机制。是一种通过改变训练样本权重来学习多个弱分类器并进行线性结合的过程。它的自适应在于:被前一个基本分类器误分类的样本的权值会…...
深度学习神经网络基础知识(二)权重衰减、暂退法(Dropout)
专栏:神经网络复现目录 深度学习神经网络基础知识(二) 本文讲述神经网络基础知识,具体细节讲述前向传播,反向传播和计算图,同时讲解神经网络优化方法:权重衰减,Dropout等方法,最后进行Kaggle实…...

[面试直通版]网络协议面试核心之HTTP,HTTPS,DNS-DNS安全
点击->计算机网络复习的文章集<-点击 目录 典型问题: 部分现象 DNS劫持 DNS欺骗 DDoS攻击 典型问题: 什么是DNS劫持,DNS欺骗,是什么原理如何防范DNS攻击? 部分现象 错误域名解析到纠错导航页面错误域名解析…...

【OJ】A+B=X
📚Description: 数列S中有n个整数,判断S中是否存在两个数A、B,使之和等于X。 ⏳Input: 第一行为T,输入包括T组测试数据。 每组数据第一行包括两个数字n和X,第二行有n个整数,表示数列S,(1&l…...

Python实现性能自动化测试,还可以如此简单
Python实现性能自动化测试,还可以如此简单 目录:导读 一、思考❓❔ 二、基础操作🔨🔨 三、综合案例演练🔨🔨 四、总结💡💡 写在最后 一、思考❓❔ 1.什么是性能自动化测试? 性…...

Leetcode力扣秋招刷题路-0080
从0开始的秋招刷题路,记录下所刷每道题的题解,帮助自己回顾总结 80. 删除有序数组中的重复项 II 给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长…...
Java实现JDBC工具类DbUtils的抽取及程序实现数据库的增删改操作
封装DbUtils 工具类 不知道我们发现没有,不管是对数据库进行查询,还是标准的JDBC 步骤,其开端都是先实现JDBC 的加载注册,接着是获取数据库的连接,最后都是实现关闭连接,释放资源的操作。那我们何不直接把…...

【docker】拉取镜像环境报错解决#ERROR: Get https://registry-1.docker.io/v2/
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录问题报错原因解决方法问题 ERROR…...
java中NumberFormat 、DecimalFormat的介绍及使用,java数字格式化,BigDecimal数字格式化
文章目录前言一、NumberFormat1、概述2、实例化方法3、货币格式化4、百分比格式化5、NumberFormat的坑5.1、不同的格式化对象处理相同数值返回结果不同问题源码分析:二、DecimalFormat1、概述2、常用方法3、字符及含义0与#的区别分组分隔符的使用“%” 将数字乘以10…...

2023什么是分销商城系统?营销,核心功能
大家好,我是你们熟悉而又陌生的好朋友梦龙,一个创业期的年轻人 分销商城是指由网络营销运营商提供的,用于协助供给商搭建、管理及运作其网络销售渠道,协助分销商获取货源渠道的平台。简单来说,就是企业应用无线裂变分…...

天翼数字生活C++客户端实习
面试C客户端实习的岗位,相对不难 面试官:实习主要做的是国产操作系统下的应用,主要做的是视频监控、安防相关的工具,具体就是一个叫做 天翼云眼的软件,目前在windows下和电视下都有对应的应用,就是现在想在…...

Java 接口
文章目录1、接口的概念2、接口的定义3、接口的使用4、接口和抽象类1、接口的概念 类是一种具体的实现体,而接口定义了一种规范(抽象方法),接口定义了某一批类所需要遵循的规范,接口不关心类内部的属性和方法的具体实现…...

【React】react-router 路由详解
🚩🚩🚩 💎个人主页: 阿选不出来 💨💨💨 💎个人简介: 一名大二在校生,学习方向前端,不定时更新自己学习道路上的一些笔记. 💨💨💨 💎目…...

DaVinci 偏好设置:系统 - 内存和 GPU
偏好设置 - 系统/内存和 GPUPreferences - System/Memory and GPU内存和 GPU Memory and GPU 选项卡提供了内存配置以及 GPU 配置的相关设置。内存配置Memory Configuration系统内存System Memory列出了所用电脑的总的可用内存。限制 Resolve 内存使用到Limit Resolve memory u…...
- 教你认清楚YUV420P和YUV420SP的真正差异在哪里)
视频知识点(22)- 教你认清楚YUV420P和YUV420SP的真正差异在哪里
*《音视频开发》系列-总览* 前言 在视频技术领域,存在着非常多的颜色空间模型,YUV颜色空间就是其中之一。我们没有必要把所有的颜色空间都搞明白,只需要关注自己所从事的领域的常用颜色空间模型即可,同样,YUV颜色空间模型也有非常多的子类型,我们也没有必要都搞得清清楚楚…...

企业电子招标采购系统源码Spring Cloud + Spring Boot + MybatisPlus + Redis + Layui
项目说明 随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。符合国家电子招投标法律法规及相关规范,以及…...

面试常问-Alpha测试和Beta测试
Alpha测试 Alpha测试是一种验收测试,在识别典型用户可能执行的任务并对其进行测试之前,执行该测试是为了识别所有可能的问题和错误。 尽可能简单地说,这种测试之所以被称为alpha,只是因为它是在软件开发的早期、接近开发结束时和…...

html理论基础
组织:中国互动出版网(http://www.china-pub.com/)RFC文档中文翻译计划(http://www.china-pub.com/compters/emook/aboutemook.htm)E-mail:ouyangchina-pub.com译者:黄俊(hujiao hj_c…...

最新扫码点餐外卖配送餐饮小程序系统源码
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示一、详细介绍 最新扫码点餐外卖配送餐饮小程序系统源码 系统功能: 1.支持多平台:微信小程序,支付宝小程序,和H5平台,页面可以后台DIY管理。 2.小程序页面支…...

Keil MDK调试时Watch窗口变量不刷新?别急,这3个设置项你检查了吗?
Keil MDK调试时Watch窗口变量不刷新?这3个关键设置项详解 调试嵌入式系统时,Watch窗口就像开发者的"第三只眼",能实时洞察程序运行状态。但当你发现变量值像被冻住一样纹丝不动时,那种抓狂的感觉我太熟悉了——三年前我…...

OpenClaw压力测试:Phi-3-mini-128k-instruct连续任务稳定性
OpenClaw压力测试:Phi-3-mini-128k-instruct连续任务稳定性 1. 为什么需要测试OpenClaw的稳定性 上周我在本地部署了OpenClaw,准备用它来自动处理一些重复性工作。最初只是简单测试了几个小任务,比如文件整理和网页搜索,效果还不…...

OpenClaw异常处理指南:千问3.5-35B-A3B-FP8任务失败的8种排查方法
OpenClaw异常处理指南:千问3.5-35B-A3B-FP8任务失败的8种排查方法 1. 当OpenClaw遇上千问3.5:我的踩坑起点 上周三凌晨2点,我正试图用OpenClaw自动整理一批会议录音转写的文本。这个任务需要先调用千问3.5-35B-A3B-FP8模型提取关键信息&…...

改进蚁群算法结合Dijkstra与MAKLINK图理论实现二维空间最优路径规划
【改进蚁群算法】/蚁群算法/Dijkstra算法/遗传算法/人工势场法实现二维/三维空间路径规划 本程序为改进蚁群算法Dijkstra算法MAKLINK图理论实现的二维空间路径规划 算法实现: 1)基于MAKLINK图理论生成地图,并对可行点进行划分; 2…...
)
手把手教你用Docker-Compose安装Dify社区版(含国内镜像加速配置)
手把手教你用Docker-Compose安装Dify社区版(含国内镜像加速配置) 如果你正在探索大模型和Agent技术,想在本地搭建一个开发环境,Dify社区版是个不错的选择。作为一个开源的AI应用开发平台,Dify让开发者能够快速构建和部…...

李慕婉-仙逆-造相Z-Turbo 生成Matlab算法脚本:从数学公式到可执行代码
李慕婉-仙逆-造相Z-Turbo 生成Matlab算法脚本:从数学公式到可执行代码 最近在帮一个做信号处理的朋友调试代码,他给我看了一页论文里的公式,问我怎么在Matlab里实现。我盯着那一堆希腊字母和矩阵运算,突然想到,要是能…...

Arduino非阻塞编程:Pin与WaitDo轻量级嵌入式工具库
1. 项目概述HDW-Utils 是一个面向 Arduino 平台的轻量级嵌入式工具库,其核心设计目标并非提供底层硬件驱动,而是解决嵌入式开发中高频出现的代码重复性、结构松散性与阻塞式延时滥用三大工程痛点。该库以“硬件开发者的实用主义”为出发点,通…...

突破英雄联盟回放困境:ROFL播放器的全方位解决方案
突破英雄联盟回放困境:ROFL播放器的全方位解决方案 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 当你想回顾上周那场惊心动…...

我的第一个AI同事:用不到100行Python代码,让GPT-4帮你自动写周报和整理会议纪要
我的第一个AI同事:用不到100行Python代码,让GPT-4帮你自动写周报和整理会议纪要 每天下午5点,我的邮箱总会准时弹出十几封会议邀请,而周五的周报deadline就像悬在头顶的达摩克利斯之剑。直到某个加班的深夜,当我第23次…...