Springboot中sharding-jdbc的API模式并使用自定义算法
Springboot中sharding-jdbc的API模式并使用自定义算法
可配合AbstractRoutingData使用切换数据源
程序用到了AbstractRoutingData来切换数据源(数据源是自定义的格式编写并没有用springboot的自动装配的格式写),但是又用到sharding-jdbc进行分库分页,如果直接引用sharding-jdbc-spring-boot-starter会自动装配它自己默认的数据源dataSource,导致我们自己写的数据源失效。所以我们需要用API的模式把sharding-jdbc的数据源dataSource放入我们自己的写的AbstractRoutingData里面来。
POM文件添加
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core</artifactId><version>5.1.2</version></dependency>
自定义的数据库信息格式

使用AbstractRoutingData切换数据源
public class DynamicDataSource extends AbstractRoutingDataSource {private static final Logger logger = Logger.getLogger(DynamicDataSource.class);private static DynamicDataSource dynamicDataSource;private final Map<Object, Object> targetDataSources = new HashMap();private static final ThreadLocal<String> dataSourceName = new ThreadLocal();public DynamicDataSource() {}public static DynamicDataSource getInstance() {if (dynamicDataSource == null) {synchronized(DynamicDataSource.class) {if (dynamicDataSource == null) {dynamicDataSource = new DynamicDataSource();}}}return dynamicDataSource;}/***determineCurrentLookupKey() 方法决定使用哪个数据源*/protected Object determineCurrentLookupKey() {return (String)dataSourceName.get();}public void setTargetDataSources(Map<String, DataSource> targetDataSources) {//设置默认数据源//super.setDefaultTargetDataSource(targetDataSources.get("default"));this.targetDataSources.putAll(targetDataSources);//设置数据源super.setTargetDataSources(this.targetDataSources);super.afterPropertiesSet();}public Map<Object, Object> getTargetDataSources() {return this.targetDataSources;}public void removeDataSource(String code) {if (this.targetDataSources.get(code) != null) {this.targetDataSources.remove(code);}//重新设置数据源super.setTargetDataSources(this.targetDataSources);super.afterPropertiesSet();}public static void setDataSource(String datasource) {logger.info("切换数据源为:"+datasource);dataSourceName.set(datasource);}public static void clear() {dataSourceName.remove();}}
- 数据源是自定义的,要禁用springboot的数据源自动装配配置,启动类上加上
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
写入自己的自定义数据源
@Configuration
public class ShardingDataSourceConfig{Logger logger = Logger.getLogger(ShardingDataSourceConfig.class);@Primary@Beanpublic DataSource shardingdataSource() throws SQLException, IOException {//获取AbstractRoutingData对象DynamicDataSource chooseDataSource = DynamicDataSource.getInstance();//获取自己配置文件上的普通数据源,该方法忽略展示,key为数据库的名字,value为数据源Map<String, DataSource> targetDataSources = this.getTargetDataSources();/*生成数据源的样式,使用DruidDataSource,POM文件记得加入,也可以使用其他数据源DruidDataSource dataSource = new DruidDataSource();dataSource.setDriverClassName(stringStringMap.get("driverClassName"));dataSource.setUrl(stringStringMap.get("url"));dataSource.setUsername(stringStringMap.get("username"));dataSource.setPassword(stringStringMap.get("password"));*///设置默认的数据源,必须保证Map里面有该值,可以放在DynamicDataSource里面再设置chooseDataSource.setDefaultTargetDataSource(targetDataSources.get("default"));//添加自己的sharding-jdbc数据源//分库分表数据源DataSource shardingDataSource = ShardingDataBaseConfiguration.getDataSource(shardingPrefixss);targetDataSources.put("shardingDT",shardingDataSource);//只分表数据源DataSource dataSource = ShardingTableConfiguration.getDataSource(sourceDataBase);targetDataSources.put("shardingT",dataSource);}chooseDataSource.setTargetDataSources(targetDataSources);return chooseDataSource;}
}
获取配置文件辅助类,网上很多方法,这里使用的是继承PropertyPlaceholderConfigurer类
public class PropertyPlaceholder extends PropertyPlaceholderConfigurer {private static Map<String,String> propertyMap;@Overrideprotected void processProperties(ConfigurableListableBeanFactory beanFactoryToProcess, Properties props) throws BeansException {super.processProperties(beanFactoryToProcess, props);propertyMap = new HashMap<String, String>();for (Object key : props.keySet()) {String keyStr = key.toString();String value = props.getProperty(keyStr);propertyMap.put(keyStr, value);}}//自定义一个方法,即根据key拿属性值,方便java代码中取属性值public static String getProperty(String name) {return propertyMap.get(name);}
}
定义自己的sharding分片规则,并返回sharding的数据源.
分库分表配置
public class ShardingDataBaseConfiguration {/*** 创建数据源*/private static Map<String, DataSource> createDataSourceMap(List<String> datasourceNames){Map<String, DataSource> dataSourceMap=new HashMap<>();for (int i = 0; i < datasourceNames.size(); i++) {Map<String, String> stringStringMap = DataBaseInfoUtil.getDataBaseInformation().get(datasourceNames.get(i));if (ObjectUtil.isNull(stringStringMap)){return null;}DruidDataSource dataSource = new DruidDataSource();dataSource.setDriverClassName(stringStringMap.get("driverClassName"));dataSource.setUrl(stringStringMap.get("url"));dataSource.setUsername(stringStringMap.get("username"));dataSource.setPassword(stringStringMap.get("password"));dataSourceMap.put("ds_"+datasourceNames.get(i), dataSource);}return dataSourceMap;}/*** 分库分表设置* create_time为分库的字段,按create_time字段的值来进行分库计算* HashModShardingAlgorithm.class.getName()是算法名字,可随便写,需要和分表配置的算法名字对应上就行* MY_HASH_MOD、MY_COMPLEX_INLINE、DATABASE_INLINE自定义算法的名字,最重要的地方,必须和自定义算法类中返回的名字一致,就是getType()返回的值,名字可以随意取* */private static ShardingRuleConfiguration createShardingRuleConfiguration() {ShardingRuleConfiguration configuration = new ShardingRuleConfiguration();configuration.getTables().add(getWlbTableRuleConfiguration());configuration.getTables().add(getWiorpTableRuleConfiguration());//设置分库的规则,按年份分库configuration.setDefaultDatabaseShardingStrategy(new StandardShardingStrategyConfiguration("create_time", PreciseDatabaseShardingAlgorithm.class.getName()));configuration.getShardingAlgorithms().put(HashModShardingAlgorithm.class.getName(),new ShardingSphereAlgorithmConfiguration("MY_HASH_MOD",new Properties()));configuration.getShardingAlgorithms().put(ComplexShardingAlgorithm.class.getName(),new ShardingSphereAlgorithmConfiguration("MY_COMPLEX_INLINE",new Properties()));configuration.getShardingAlgorithms().put(PreciseDatabaseShardingAlgorithm.class.getName(),new ShardingSphereAlgorithmConfiguration("DATABASE_INLINE",new Properties()));return configuration;}/*** 制定my_test表分片规则* my_test为逻辑表名,my_test_0,my_test_1....my_test_9为实际数据库的表名,就是把数据分到这0-9的表中* ds_${2020..2022} 为实际数据源的名字:ds_2020,ds_2021,ds_2022,写法${..},{}里面可以进行运算,例如ds_${id % 2}* sub_base为my_test表的分表字段,就是my_test表的分表规则按sub_base来区分* HashModShardingAlgorithm.class.getName(),这个是算法的名字可以随意起,对应configuration.getShardingAlgorithms().put()中key的值,写上自己自定义的类名好容易确认区分,sharding-jdbc也有自己默认定义好的分片算法* 如果使用ds_${id % 2}这种在{}进行运算的,可以不写setTableShardingStrategy* */private static ShardingTableRuleConfiguration getWlbTableRuleConfiguration(){ShardingTableRuleConfiguration tableRule=new ShardingTableRuleConfiguration("my_test","ds_${2020..2022}.my_test_${0..9}");tableRule.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("id","snowflake"));tableRule.setTableShardingStrategy(new StandardShardingStrategyConfiguration("sub_base",HashModShardingAlgorithm.class.getName()));return tableRule;}/*** 制定my_test2表分库分片规则* */private static ShardingTableRuleConfiguration getWiorpTableRuleConfiguration(){ShardingTableRuleConfiguration tableRule=new ShardingTableRuleConfiguration("my_test2","ds_${2020..2022}.my_test2_${0..9}");tableRule.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("id","snowflake"));tableRule.setTableShardingStrategy(new ComplexShardingStrategyConfiguration("code,name,sex,age", ComplexShardingAlgorithm.class.getName()));return tableRule;}public static DataSource getDataSource(List<String> datasourceNames) throws SQLException {// 其他配置Properties properties = new Properties();//控制台日志展示sharding-jdbc的sqlproperties.put("sql-show","true");return ShardingSphereDataSourceFactory.createDataSource(createDataSourceMap(datasourceNames),Collections.singleton(createShardingRuleConfiguration()),properties);}}仅分表配置
public class ShardingTableConfiguration {/*** 创建数据源*/private static Map<String, DataSource> createDataSourceMap(List<String> datasourceNames){Map<String, DataSource> dataSourceMap=new HashMap<>();for (int i = 0; i < datasourceNames.size(); i++) {Map<String, String> stringStringMap = DataBaseInfoUtil.getDataBaseInformation().get(datasourceNames.get(i));if (ObjectUtil.isNull(stringStringMap)){return null;}DruidDataSource dataSource = new DruidDataSource();dataSource.setDriverClassName(stringStringMap.get("driverClassName"));dataSource.setUrl(stringStringMap.get("url"));dataSource.setUsername(stringStringMap.get("username"));dataSource.setPassword(stringStringMap.get("password"));dataSourceMap.put("ds0", dataSource);}return dataSourceMap;}/*** 分表设置*/private static ShardingRuleConfiguration createShardingRuleConfigurationOnlyTable() {ShardingRuleConfiguration configuration = new ShardingRuleConfiguration();configuration.getTables().add(getWlbTableRuleConfiguration());configuration.getTables().add(getWiorpTableRuleConfiguration());configuration.getShardingAlgorithms().put(HashModShardingAlgorithm.class.getName(),new ShardingSphereAlgorithmConfiguration("MY_HASH_MOD",new Properties()));configuration.getShardingAlgorithms().put(ComplexShardingAlgorithm.class.getName(),new ShardingSphereAlgorithmConfiguration("MY_COMPLEX_INLINE",new Properties()));return configuration;}/*** 制定my_test3表分片规则*/private static ShardingTableRuleConfiguration getWlbTableRuleConfiguration(){ShardingTableRuleConfiguration tableRule=new ShardingTableRuleConfiguration("my_test3","ds0.my_test3_${0..9}");tableRule.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("id","snowflake"));tableRule.setTableShardingStrategy(new StandardShardingStrategyConfiguration("box_batch",HashModShardingAlgorithm.class.getName()));return tableRule;}/*** 制定my_test4表分库分片规则*/private static ShardingTableRuleConfiguration getWiorpTableRuleConfiguration(){ShardingTableRuleConfiguration tableRule=new ShardingTableRuleConfiguration("my_test4","ds0.my_test4_${0..9}");tableRule.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("id","snowflake"));tableRule.setTableShardingStrategy(new ComplexShardingStrategyConfiguration("code,name,sex,age", ComplexShardingAlgorithm.class.getName()));return tableRule;}public static DataSource getDataSource(String datasourceNames) throws SQLException {// 其他配置Properties properties = new Properties();properties.put("sql-show","true");return ShardingSphereDataSourceFactory.createDataSource(createDataSourceMap(new ArrayList<String>(){{add(datasourceNames);}}),Collections.singleton(createShardingRuleConfigurationOnlyTable()),properties);}}
自定义分库分片算法
标准分片算法
public final class HashModShardingAlgorithm implements StandardShardingAlgorithm<String> {@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<String> shardingValue) {if(StringUtil.isEmpty(shardingValue.getValue())){throw new CommonException("precise sharding value is null");}String suffix = String.valueOf(Math.abs((long) shardingValue.hashCode())) % collection.size());for (String tableName : collection) {if (tableName.endsWith(suffix)) {return tableName;}}throw new UnsupportedOperationException();}@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<String> rangeShardingValue) {return collection;}@Overridepublic Properties getProps() {return null;}@Overridepublic void init(Properties properties) {}//返回的算法名字public String getType() {return "MY_HASH_MOD";}
}
复合字段算法
public class ComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm {@Overridepublic Collection<String> doSharding(Collection collection, ComplexKeysShardingValue complexKeysShardingValue) {// 返回真实表名集合List<String> tableNameList = new ArrayList<>();// 逻辑表名String logicTableName = complexKeysShardingValue.getLogicTableName();// 获取分片键的值,算法自己定义Collection<String> factoryCodes = (Collection<String>) complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("code");Collection<String> workshopCodes = (Collection<String>) complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("name");Collection<String> storehouseCodes = (Collection<String>) complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("sex");Collection<String> materialNos = (Collection<String>) complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("age");if (ListUtil.isEmpty(factoryCodes)|| ListUtil.isEmpty(workshopCodes)|| ListUtil.isEmpty(storehouseCodes)|| ListUtil.isEmpty(materialNos)) {//分片键缺任何一个字段均返回全部表for (String tableName : (Collection<String>) collection) {tableNameList.add(tableName);}return tableNameList;//返回全部}// 获取真实表名String realName = getTabel(factoryCodes) + getTabel(workshopCodes)+ getTabel(storehouseCodes);for (String materialNo : materialNos) {long abs = Math.abs((long) (realName + materialNo).hashCode());String tableSuffix = String.valueOf(abs % 10);for (String tableName : (Collection<String>) collection) {if (tableName.endsWith("_" + tableSuffix)) {tableNameList.add(tableName);}}}return tableNameList;}/*** 获取表名** @param codes* @return*/private String getTabel(Collection<String> names) {Optional<String> name = names.stream().findFirst();if (name.isPresent()) {return name.get();}return "";}@Overridepublic Properties getProps() {return null;}@Overridepublic void init(Properties properties) {}//返回的算法名字public String getType() {return "MY_COMPLEX_INLINE";}
}
分库算法
public class PreciseDatabaseShardingAlgorithm implements StandardShardingAlgorithm<LocalDateTime> {@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<LocalDateTime> preciseShardingValue) {//对于库的分片collection存放的是所有的库的列表,这里代表ds_2020~dataSource_2022//配置的分片的sharding-column对应的值LocalDateTime year = preciseShardingValue.getValue();if(ObjectUtil.isNull(year)){throw new UnsupportedOperationException("preciseShardingValue is null");}DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy");//按年路由for (String each : collection) {String value = formatter.format(year);//获取到年份if(each.endsWith(value)){// //这里返回回去的就是最终需要查询的库名return each;}}throw new UnsupportedOperationException();}@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<LocalDateTime> rangeShardingValue) {return collection;}@Overridepublic Properties getProps() {return null;}@Overridepublic void init(Properties properties) {}//返回算法的名字public String getType() {return "DATABASE_INLINE";}
}自定义算法重点
SPI机制
需要在resources下面写上
META-INF.services.org.apache.shardingsphere.sharding.spi.ShardingAlgorithm

里面的内容写上算法的路径

使用
在需要切换数据源的地方设置数据源DynamicDataSource.setDataSource(自定义的数据源名字),使用完后记得remove,切换为默认数据源避免出问题
事务
必须在切换数据源后才开启事务,单事务,在事务中切换数据源是不生效的
PS:写出来仅仅为了自己后面能重新看到,如果有好的方法也可以告诉我
相关文章:
Springboot中sharding-jdbc的API模式并使用自定义算法
Springboot中sharding-jdbc的API模式并使用自定义算法 可配合AbstractRoutingData使用切换数据源 程序用到了AbstractRoutingData来切换数据源(数据源是自定义的格式编写并没有用springboot的自动装配的格式写),但是又用到sharding-jdbc进行…...

MySQL回表是什么?哪些情况下会回表
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...

VR、AR、MR 傻傻分不清楚?区别的底层逻辑?
VR是一种能够制作虚拟物体并与人互动的基础技术。它与操作者所处的环境无关。AR可以让在特定位置出现或消失。MR可以让虚拟物体与真实物体进行互动。 AR和MR的大部分应用场景都是随机的,所以硬件基本都采用手机和眼镜。提升了便携性。牺牲了性能。这就导致了AR与MR…...
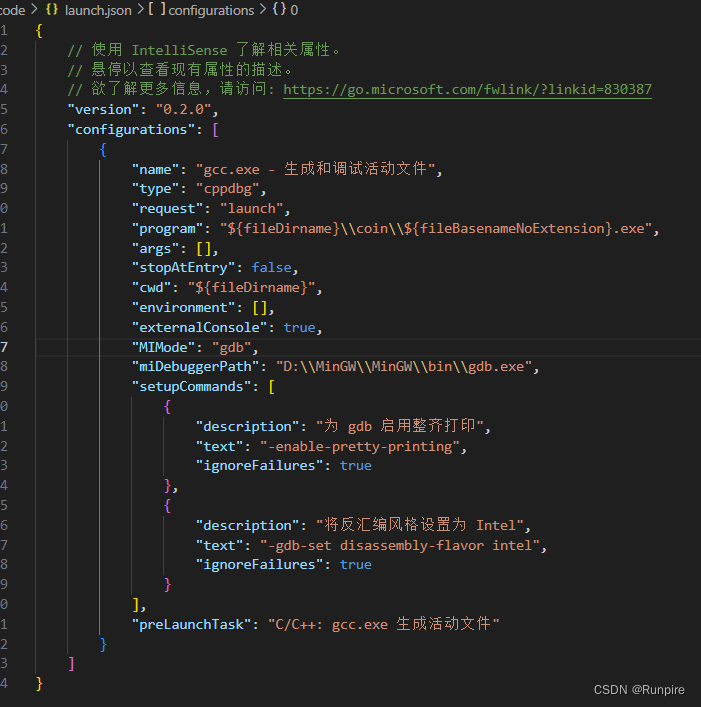
VScode运行C语言出现的调试问题 lauch:program does not exist 解决方法
"lauch:program does not exist"错误通常表示编译器或调试器无法找到指定的可执行文件。这可能是由于几个原因引起的。首先,确保你的源代码文件夹路径不包含中文字符,因为这可能导致编译器无法识别文件。其次,检查你的launch.json文…...

云原生安全:保护现代化应用的新一代安全策略
随着云计算和容器技术的快速发展,云原生应用已成为现代化软件开发和部署的主流趋势。然而,随之而来的安全挑战也变得更加复杂和严峻。本文将深入探讨云原生安全的概念、原则和最佳实践,帮助您理解如何有效保护云原生应用和敏感数据。 第一部…...

mysql操作
1、字符转Decimal CAST(column AS DECIMAL(9,2)) 2、将计算结果取两位小数: round(column, 2) 3、查询非空 select * from table_XX where id is not null; 4、连表update更新 update a inner join (select yy from b) c on a.id c.id set a.xx c.yy...

前端(十四)——DOM节点操作手册:你需要了解的一切
🙂博主:小猫娃来啦 🙂文章核心:DOM节点操作手册:你需要了解的一切 文章目录 前言DOM基础知识操作现有节点创建新节点遍历节点树修改节点属性和样式事件处理实践应用动态创建表格动态更新列表 前言 DOM(文档…...
PDF怎么转成PPT文件免费?一个软件解决
随着科技的不断发展和进步,电子文档已经成为我们日常工作和学习中不可或缺的一部分。PDF作为一种跨平台的文件格式,以其可靠性和易读性而备受推崇。然而,在某些情况下,我们可能需要PDF怎么转成PPT文件免费,以便更好地展…...
数据结构基础:P3-树(上)----编程作业02:List Leaves
本系列文章为浙江大学陈越、何钦铭数据结构学习笔记,系列文章链接如下: 数据结构(陈越、何钦铭)学习笔记 文章目录 一、题目描述二、整体思路与实现代码 一、题目描述 题目描述: 给定一棵树,按照从上到下、从左到右的顺序列出所有…...
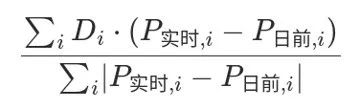
山西电力市场日前价格预测【2023-08-25】
日前价格预测 预测明日(2023-08-25)山西电力市场全天平均日前电价为314.22元/MWh。其中,最高日前电价为336.17元/MWh,预计出现在18: 30。最低日前电价为283.05元/MWh,预计出现在24: 00。 价差方向预测 1: 实…...
手机无人直播软件,有哪些优势?
近年来,随着手机直播的流行和直播带货的市场越来越大,手机无人直播软件成为许多商家开播带货的首选。在这个领域里,声音人无人直播系统以其独特的优势,成为市场上备受瞩目的产品。接下来,我们将探讨手机无人直播软件给…...
SpringBoot概述SpringBoot基础配置yml的使用多环境启动
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 SpringBoot简介 一、 SpringBoot概述1.1 起步依赖…...
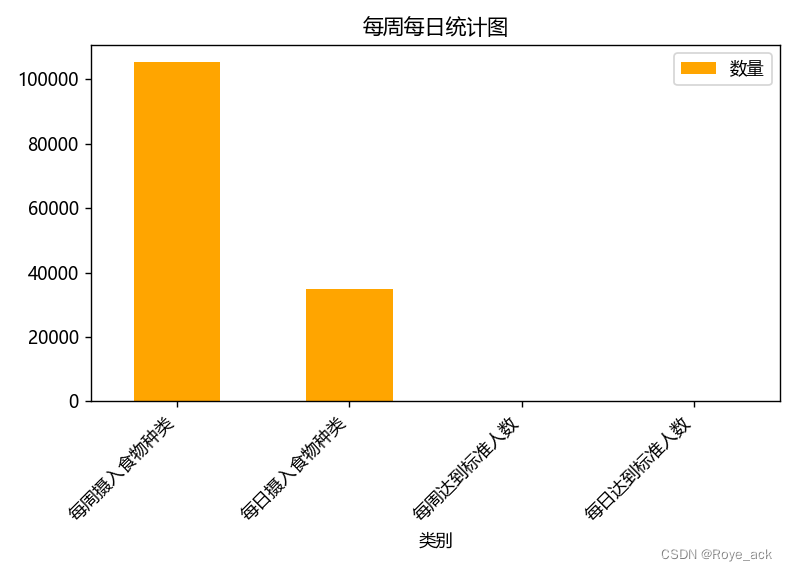
Python Pandas 处理Excel数据 制图
目录 1、饼状图 2、条形统计图 1、饼状图 import pandas as pd import matplotlib.pyplot as plt import numpy as np #from matplotlib.ticker import MaxNLocator # 解决中文乱码 plt.rcParams[font.sans-serif][SimHei] plt.rcParams[font.sans-serif]Microsoft YaHei …...
bpmn的xml和json互转)
如何自己实现一个丝滑的流程图绘制工具(五)bpmn的xml和json互转
背景 因为服务端给的数据并不是xml,而且服务端要拿的数据是json,所以我们只能xml和json互转,来完成和服务端的对接 xml转json import XML from ./config/jsonxml.js/*** xml转为json* param {*} xml*/xmlToJson(xml) {const xotree new X…...
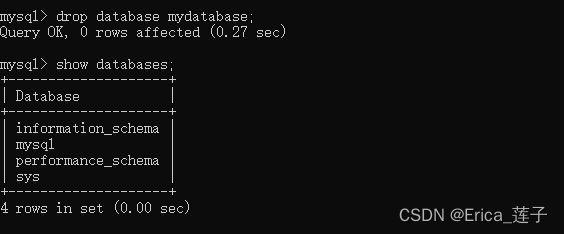
mysql--数据库的操作
数据库,是数据存储的最大单元。 1 创建数据库 create database mydatabase; 每次创建数据库的时候,都会多一个文件夹,关系型数据库是存储在磁盘当中的,所以这时候可以查看新建的数据库 2 指定字符集 MySQL中的字符集转换过程 制…...
kafka--技术文档--架构体系
架构体系 Kafka的架构体系包括以下几个部分: Producer. 消息生产者,就是向Kafka broker发送消息的客户端。Broker. 一台Kafka服务器就是一个Broker。一个集群由多个Broker组成。一个Broker可以容纳多个Topic。Topic. 可以理解为一个队列,一…...

ctfshow web入门 web103-web107
1.web103 和102一样 payload: v2115044383959474e6864434171594473&v3php://filter/writeconvert.base64-decode/resource1.php post v1hex2bin2.web104 值只要一样就可以了 payload: v21 post v113.web105 考查的是$$变量覆盖,die可以带出数据,输出一条消息…...

前端工程化之模块化
模块化的背景 前端模块化是一种标准,不是实现理解模块化是理解前端工程化的前提前端模块化是前端项目规模化的必然结果 什么是前端模块化? 前端模块化就是将复杂程序根据规范拆分成若干模块,一个模块包括输入和输出。而且模块的内部实现是私有的&…...
文件服务器实现方式汇总
hello,伙伴们,大家好,今天这一期shigen来给大家推荐几款可以一键实现文件浏览器的工具,让你轻松的实现文件服务器和内网的文件传输、预览。 基于node 本次推荐的是http-server, 它的githuab地址是:http-s…...

ChatGPT计算机科学与技术专业的本科毕业论文,2000字。论文查重率低于30%。
目录 摘要 Abstract 绪论 1.1 研究背景 1.2 研究目的和意义 2.1 ChatGPT技术概述 2.2 ChatGPT技术的优缺点分析 2.2.1 优点 2.2.2 缺点 摘要 本论文围绕ChatGPT展开,介绍了该技术的发展历程、特点及应用,分析了该技术的优缺点,提出了…...

深耕财税赋能+精准GEO推广 好账本兰宝玺双线发力助企破局
在数字经济飞速发展的当下,财税服务的专业性与营销推广的精准度,成为中小微企业稳健成长的两大核心支撑。深耕苏州、昆山财税领域八年的98后实干者兰宝玺,依托好账本财税平台的坚实后盾,不仅以精细化财税服务为创业者保驾护航&…...

如何快速构建跨平台GUI应用:awesome-zig项目中Capy与ZWL框架终极指南
如何快速构建跨平台GUI应用:awesome-zig项目中Capy与ZWL框架终极指南 【免费下载链接】awesome-zig A collaborative list of awesome Zig libraries and resources. 项目地址: https://gitcode.com/gh_mirrors/awe/awesome-zig 想要用Zig语言开发跨平台桌面…...

Lusca CSP策略完全指南:构建安全的内容安全策略
Lusca CSP策略完全指南:构建安全的内容安全策略 【免费下载链接】lusca Application security for express apps. 项目地址: https://gitcode.com/gh_mirrors/lu/lusca Lusca是一款专为Express应用打造的安全中间件,提供了全面的内容安全策略&…...

LinkSwift网盘直链助手:让你的下载体验更简单高效
LinkSwift网盘直链助手:让你的下载体验更简单高效 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

软硬一体赋能企业守护力,可穿戴手环构建员工数字健康管理新范式
在数字化转型深入推进的当下,员工健康已成为企业安全生产、高效运营的核心基石。传统健康管理模式存在数据零散、监测滞后、人工成本高、风险预警不及时等痛点,尤其铁路、港口、政企单位、生产型企业,一线员工高强度作业、慢病高发、突发健康…...

从“会响”到“可靠”:给这个经典12V降5V电路加个二极管和电容,稳定性提升不止一点点
从“会响”到“可靠”:经典12V降5V电路的稳定性优化实战 当你在面包板上搭建好那个经典的稳压管NPN降压电路,看着万用表显示稳定的5V输出时,或许会感到一丝成就感。但当你接上负载,发现电压开始波动,或者在电源反接时闻…...

2026亚洲消费电子展6月来袭,观众预登记
2026亚洲消费电子展筹备工作进入关键阶段,本届展会定于2026年6月10日至12日在北京举办,运营方赛逸品牌管理有限公司正式对外宣布,展会专业观众线上预约通道同步启动,行业采购人士、技术从业者及科研机构可提前完成预登记ÿ…...

Cortex-M0中断与系统控制:从NVIC、SysTick到低功耗实战解析
1. 项目概述:从零开始理解Cortex-M0的中断与系统控制如果你正在接触基于ARM Cortex-M0内核的微控制器,比如STM32F0系列、NXP的LPC800系列,或者是一些国产的M0芯片,那么“中断”和“系统控制”这两个词,绝对是你绕不开的…...
【量化】IPTQ-ViT: Post-Training Quantization of Non-linear Functions for Integer-only Vision Transformer
【PTQ】PTQViT/IPTQ-ViT (arXiv 2022) 问题: ViT 中的非线性函数(GELU、Softmax)在纯整数推理中存在计算障碍。 核心创新: 模块方法作用多项式近似 GELU用低阶多项式逼近 GELU将非线性运算转化为整数可执行的乘加Bit-shifting Softmax用位移操作近似 …...

EC35编码器驱动踩坑实录:从波形分析到稳定读取,我的GD32调试笔记
EC35编码器驱动踩坑实录:从波形分析到稳定读取的GD32调试笔记 1. 问题初现:那些让人抓狂的"玄学"现象 第一次把EC35编码器接到GD32F303开发板上时,我天真地以为这不过是个简单的GPIO中断应用。按照常规思路配置了三个引脚的中断&am…...