大模型一、大语言模型的背景和发展
文章目录
- 背景
- 模型
- 1 文本LLM模型
- ChatGLM
- ChatGLM2-6B
- Chinese-LLaMA-Alpaca:
- Chinese-LLaMA-Alpaca-2:
- Chinese-LlaMA2:
- Llama2-Chinese:
- OpenChineseLLaMA:
- BELLE:
- Panda:
- Robin (罗宾):
- Fengshenbang-LM:
- BiLLa:
- Moss:
- Luotuo-Chinese-LLM:
- Linly:
- Firefly:
- ChatYuan
- ChatRWKV:
- CPM-Bee
- TigerBot
- Aquila
- Baichuan-7B
- Anima
- KnowLM
- BayLing
- YuLan-Chat
- PolyLM
- AtomGPT
- Qwen-7B
- huozi
- 2 多模态LLM模型
- VisualGLM-6B
- VisCPM
- Visual-Chinese-LLaMA-Alpaca
- LLaSM
- 大模型未来发展的方向包括
本文系大模型专栏文章的第一篇文章,后续将陆续更新相关模型的技术,在 finetune、prompt、SFT、PPO等方向进行逐步更新,欢迎关注,也可私密需要实现的模型。
背景
LLM全称Large Language Model(中文翻译,大型语言模型)
随着ChatGPT等大型语言模型的出现,自然语言处理领域掀起了新一轮的研究和应用浪潮。尤其是在ChatGLM、LLaMA等平民玩家开源较小规模的LLM模型后,业界出现了许多基于LLM的二次微调或应用案例。本项目致力于收集和整理中文LLM相关的开源模型、应用、数据集和教程等资料,以促进中文LLM的发展和应用。
模型
最新整理时间为2023年8月21日
1 文本LLM模型
ChatGLM
- 地址:https://github.com/THUDM/ChatGLM-6B
- 简介:中文领域效果最好的开源底座模型之一,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持
ChatGLM2-6B
地址:https://github.com/THUDM/ChatGLM2-6B
简介:基于开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,引入了GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练;基座模型的上下文长度扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练;基于 Multi-Query Attention 技术实现更高效的推理速度和更低的显存占用;允许商业使用。
Chinese-LLaMA-Alpaca:
地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
简介:中文LLaMA&Alpaca大语言模型+本地CPU/GPU部署,在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练
Chinese-LLaMA-Alpaca-2:
地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
简介:该项目将发布中文LLaMA-2 & Alpaca-2大语言模型,基于可商用的LLaMA-2进行二次开发。
Chinese-LlaMA2:
地址:https://github.com/michael-wzhu/Chinese-LlaMA2
简介:该项目基于可商用的LLaMA-2进行二次开发决定在次开展Llama 2的中文汉化工作,包括Chinese-LlaMA2: 对Llama 2进行中文预训练;第一步:先在42G中文预料上进行训练;后续将会加大训练规模;Chinese-LlaMA2-chat: 对Chinese-LlaMA2进行指令微调和多轮对话微调,以适应各种应用场景和多轮对话交互。同时我们也考虑更为快速的中文适配方案:Chinese-LlaMA2-sft-v0: 采用现有的开源中文指令微调或者是对话数据,对LlaMA-2进行直接微调 (将于近期开源)。
Llama2-Chinese:
地址:https://github.com/FlagAlpha/Llama2-Chinese
简介:该项目专注于Llama2模型在中文方面的优化和上层建设,基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级。
OpenChineseLLaMA:
地址:https://github.com/OpenLMLab/OpenChineseLLaMA
简介:基于 LLaMA-7B 经过中文数据集增量预训练产生的中文大语言模型基座,对比原版 LLaMA,该模型在中文理解能力和生成能力方面均获得较大提升,在众多下游任务中均取得了突出的成绩。
BELLE:
地址:https://github.com/LianjiaTech/BELLE
简介:开源了基于BLOOMZ和LLaMA优化后的一系列模型,同时包括训练数据、相关模型、训练代码、应用场景等,也会持续评估不同训练数据、训练算法等对模型表现的影响。
Panda:
地址:https://github.com/dandelionsllm/pandallm
简介:开源了基于LLaMA-7B, -13B, -33B, -65B 进行中文领域上的持续预训练的语言模型, 使用了接近 15M 条数据进行二次预训练。
Robin (罗宾):
地址:https://github.com/OptimalScale/LMFlow
简介:Robin (罗宾)是香港科技大学LMFlow团队开发的中英双语大语言模型。仅使用180K条数据微调得到的Robin第二代模型,在Huggingface榜单上达到了第一名的成绩。LMFlow支持用户快速训练个性化模型,仅需单张3090和5个小时即可微调70亿参数定制化模型。
Fengshenbang-LM:
地址:https://github.com/IDEA-CCNL/Fengshenbang-LM
简介:Fengshenbang-LM(封神榜大模型)是IDEA研究院认知计算与自然语言研究中心主导的大模型开源体系,该项目开源了姜子牙通用大模型V1,是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。除姜子牙系列模型之外,该项目还开源了太乙、二郎神系列等模型。
BiLLa:
地址:https://github.com/Neutralzz/BiLLa
简介:该项目开源了推理能力增强的中英双语LLaMA模型。模型的主要特性有:较大提升LLaMA的中文理解能力,并尽可能减少对原始LLaMA英文能力的损伤;训练过程增加较多的任务型数据,利用ChatGPT生成解析,强化模型理解任务求解逻辑;全量参数更新,追求更好的生成效果。
Moss:
地址:https://github.com/OpenLMLab/MOSS
简介:支持中英双语和多种插件的开源对话语言模型,MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
Luotuo-Chinese-LLM:
地址:https://github.com/LC1332/Luotuo-Chinese-LLM
简介:囊括了一系列中文大语言模型开源项目,包含了一系列基于已有开源模型(ChatGLM, MOSS, LLaMA)进行二次微调的语言模型,指令微调数据集等。
Linly:
地址:https://github.com/CVI-SZU/Linly
简介:提供中文对话模型 Linly-ChatFlow 、中文基础模型 Linly-Chinese-LLaMA 及其训练数据。 中文基础模型以 LLaMA 为底座,利用中文和中英平行增量预训练。项目汇总了目前公开的多语言指令数据,对中文模型进行了大规模指令跟随训练,实现了 Linly-ChatFlow 对话模型。
Firefly:
地址:https://github.com/yangjianxin1/Firefly
简介:Firefly(流萤) 是一个开源的中文大语言模型项目,开源包括数据、微调代码、多个基于Bloom、baichuan等微调好的模型等;支持全量参数指令微调、QLoRA低成本高效指令微调、LoRA指令微调;支持绝大部分主流的开源大模型,如百川baichuan、Ziya、Bloom、LLaMA等。持lora与base model进行权重合并,推理更便捷。
ChatYuan
地址:https://github.com/clue-ai/ChatYuan
简介:元语智能发布的一系列支持中英双语的功能型对话语言大模型,在微调数据、人类反馈强化学习、思维链等方面进行了优化。
ChatRWKV:
地址:https://github.com/BlinkDL/ChatRWKV
简介:开源了一系列基于RWKV架构的Chat模型(包括英文和中文),发布了包括Raven,Novel-ChnEng,Novel-Ch与Novel-ChnEng-ChnPro等模型,可以直接闲聊及进行诗歌,小说等创作,包括7B和14B等规模的模型。
CPM-Bee
地址:https://github.com/OpenBMB/CPM-Bee
简介:一个完全开源、允许商用的百亿参数中英文基座模型。它采用Transformer自回归架构(auto-regressive),在超万亿(trillion)高质量语料上进行预训练,拥有强大的基础能力。开发者和研究者可以在CPM-Bee基座模型的基础上在各类场景进行适配来以创建特定领域的应用模型。
TigerBot
地址:https://github.com/TigerResearch/TigerBot
简介:一个多语言多任务的大规模语言模型(LLM),开源了包括模型:TigerBot-7B, TigerBot-7B-base,TigerBot-180B,基本训练和推理代码,100G预训练数据,涵盖金融、法律、百科的领域数据以及API等。
书生·浦语
地址:https://github.com/InternLM/InternLM-techreport
简介:商汤科技、上海AI实验室联合香港中文大学、复旦大学和上海交通大学发布千亿级参数大语言模型“书生·浦语”(InternLM)。据悉,“书生·浦语”具有1040亿参数,基于“包含1.6万亿token的多语种高质量数据集”训练而成。
Aquila
地址:https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
简介:由智源研究院发布,Aquila语言大模型在技术上继承了GPT-3、LLaMA等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的tokenizer,升级了BMTrain并行训练方法,是在中英文高质量语料基础上从0开始训练的,通过数据质量的控制、多种训练的优化方法,实现在更小的数据集、更短的训练时间,获得比其它开源模型更优的性能。也是首个支持中英双语知识、支持商用许可协议、符合国内数据合规需要的大规模开源语言模型。
Baichuan-7B
地址:https://github.com/baichuan-inc/baichuan-7B
简介:Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。该项目发布包含有预训练 (Baichuan-13B-Base) 和对齐 (Baichuan-13B-Chat) 两个版本。
Baichuan-13B
地址:https://github.com/baichuan-inc/Baichuan-13B
简介:由百川智能开发的一个开源可商用的大规模预训练语言模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-EVAL/MMLU)上均取得同尺寸最好的效果。
Anima
地址:https://github.com/lyogavin/Anima
简介:由艾写科技开发的一个开源的基于QLoRA的33B中文大语言模型,该模型基于QLoRA的Guanaco 33B模型使用Chinese-Vicuna项目开放的训练数据集guanaco_belle_merge_v1.0进行finetune训练了10000个step,基于Elo rating tournament评估效果较好。
KnowLM
地址:https://github.com/zjunlp/KnowLM
简介:KnowLM项目旨在发布开源大模型框架及相应模型权重以助力减轻知识谬误问题,包括大模型的知识难更新及存在潜在的错误和偏见等。该项目一期发布了基于Llama的抽取大模型智析,使用中英文语料对LLaMA(13B)进行进一步全量预训练,并基于知识图谱转换指令技术对知识抽取任务进行优化。
BayLing
地址:https://github.com/ictnlp/BayLing
简介:一个具有增强的跨语言对齐的通用大模型,由中国科学院计算技术研究所自然语言处理团队开发。百聆(BayLing)以LLaMA为基座模型,探索了以交互式翻译任务为核心进行指令微调的方法,旨在同时完成语言间对齐以及与人类意图对齐,将LLaMA的生成能力和指令跟随能力从英语迁移到其他语言(中文)。在多语言翻译、交互翻译、通用任务、标准化考试的测评中,百聆在中文/英语中均展现出更好的表现。百聆提供了在线的内测版demo,以供大家体验。
YuLan-Chat
地址:https://github.com/RUC-GSAI/YuLan-Chat
简介:YuLan-Chat是中国人民大学GSAI研究人员开发的基于聊天的大语言模型。它是在LLaMA的基础上微调开发的,具有高质量的英文和中文指令。 YuLan-Chat可以与用户聊天,很好地遵循英文或中文指令,并且可以在量化后部署在GPU(A800-80G或RTX3090)上。
PolyLM
地址:https://github.com/DAMO-NLP-MT/PolyLM
简介:一个在6400亿个词的数据上从头训练的多语言语言模型,包括两种模型大小(1.7B和13B)。PolyLM覆盖中、英、俄、西、法、葡、德、意、荷、波、阿、土、希伯来、日、韩、泰、越、印尼等语种,特别是对亚洲语种更友好。
AtomGPT
地址:https://github.com/AtomEcho/AtomGPT
简介:AtomGPT基于LLaMA的模型架构,从0开始训练,希望能在训练的过程中,将模型能力得到提升的进化过程展示出来,感受到模型学习的过程,该项目开源了多个不同预训练步数下的指令微调模型。
Qwen-7B
地址:https://github.com/QwenLM/Qwen-7B
简介:通义千问-7B(Qwen-7B) 是阿里云研发的通义千问大模型系列的70亿参数规模的模型,使用了超过2.2万亿token的自建大规模预训练数据集进行语言模型的预训练。数据集包括文本和代码等多种数据类型,覆盖通用领域和专业领域,能支持8K的上下文长度,针对插件调用相关的对齐数据做了特定优化,当前模型能有效调用插件以及升级为Agent。
huozi
地址:https://github.com/HIT-SCIR/huozi
简介:由哈工大自然语言处理研究所多位老师和学生参与开发的一个开源可商用的大规模预训练语言模型。 该模型基于 Bloom 结构的70 亿参数模型,支持中英双语,上下文窗口长度为 2048,同时还开源了基于RLHF训练的模型以及全人工标注的的中文偏好数据集。
XVERSE-13B
地址:https://github.com/xverse-ai/XVERSE-13B
简介:由深圳元象科技自主研发的支持多语言的大语言模型,使用主流 Decoder-only 的标准Transformer网络结构,支持 8K 的上下文长度(Context Length),为同尺寸模型中最长,构建了 1.4 万亿 token 的高质量、多样化的数据对模型进行充分训练,包含中、英、俄、西等 40 多种语言,通过精细化设置不同类型数据的采样比例,使得中英两种语言表现优异,也能兼顾其他语言效果;基于BPE算法使用上百GB 语料训练了一个词表大小为100,278的分词器,能够同时支持多语言,而无需额外扩展词表。
2 多模态LLM模型
VisualGLM-6B
地址:https://github.com/THUDM/VisualGLM-6B
简介:一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。依靠来自于 CogView 数据集的30M高质量中文图文对,与300M经过筛选的英文图文对进行预训练。
VisCPM
地址:https://github.com/OpenBMB/VisCPM
简介:一个开源的多模态大模型系列,支持中英双语的多模态对话能力(VisCPM-Chat模型)和文到图生成能力(VisCPM-Paint模型)。VisCPM基于百亿参数量语言大模型CPM-Bee(10B)训练,融合视觉编码器(Q-Former)和视觉解码器(Diffusion-UNet)以支持视觉信号的输入和输出。得益于CPM-Bee基座优秀的双语能力,VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
Visual-Chinese-LLaMA-Alpaca
地址:https://github.com/airaria/Visual-Chinese-LLaMA-Alpaca
简介:基于中文LLaMA&Alpaca大模型项目开发的多模态中文大模型。VisualCLA在中文LLaMA/Alpaca模型上增加了图像编码等模块,使LLaMA模型可以接收视觉信息。在此基础上,使用了中文图文对数据进行了多模态预训练,对齐图像与文本表示,赋予其基本的多模态理解能力;并使用多模态指令数据集精调,增强其对多模态指令的理解、执行和对话能力,目前开源了VisualCLA-7B-v0.1。
LLaSM
地址:https://github.com/LinkSoul-AI/LLaSM
简介:第一个支持中英文双语语音-文本多模态对话的开源可商用对话模型。便捷的语音输入将大幅改善以文本为输入的大模型的使用体验,同时避免了基于 ASR 解决方案的繁琐流程以及可能引入的错误。目前开源了LLaSM-Chinese-Llama-2-7B、LLaSM-Baichuan-7B等模型与数据集。
大模型未来发展的方向包括
- 模型性能的提升:包括模型结构、训练方式、超参数等方面的优化,以提高模型的准确性和泛化能力。
- 多模态的融合:将不同模态的信息(如文本、图像、声音等)融合在一起,以实现更强大的模型能力。
- 生成式的应用:利用大模型进行文本生成、图像生成、音乐创作等生成式应用。
- 个性化模型:开发能够根据不同用户或场景进行个性化调整的模型,以满足不同应用需求。
- 模型的可解释性和可信度:研究模型的内部运行机制和解释机制,提高模型的可解释性和可信度,以增强模型的可靠性和可控性。
- 模型的应用拓展:将大模型应用于更多领域,如医学、法律、教育等,以推动各个领域的发展。
相关文章:

大模型一、大语言模型的背景和发展
文章目录 背景模型1 文本LLM模型ChatGLMChatGLM2-6BChinese-LLaMA-Alpaca:Chinese-LLaMA-Alpaca-2:Chinese-LlaMA2:Llama2-Chinese:OpenChineseLLaMA:BELLE:Panda:Robin (罗宾):Fengshenbang-LM…...

Linux常用命令——dhcpd命令
在线Linux命令查询工具 dhcpd 运行DHCP服务器。 语法 dhcpd [选项] [网络接口]选项 -p <端口> 指定dhcpd监听的端口 -f 作为前台进程运行dhcpd -d 启用调试模式 -q 在启动时不显示版权信息 -t 简单地测试配置文件的语法是否正确的,但不会尝试执行任何网络…...

Apache和Nginx各有什么优缺点,应该如何选择?
Apache和Nginx各有什么优缺点,应该如何选择? Apache和Nginx都有各自的优点和缺点,选择应该根据您的具体需求而定。Nginx的优点包括:轻量级,与同等web服务相比,Nginx占用更少的内存和资源;抗并发…...
基于JAVA SpringBoot和UniAPP的宠物服务预约小程序
随着社会的发展和人们生活水平的提高,特别是近年来,宠物快速进入人们的家中,成为人们生活中重要的娱乐内容之一,过去宠物只是贵族的娱乐,至今宠物在中国作为一种生活方式得到了广泛的认可,随着人们精神文明…...
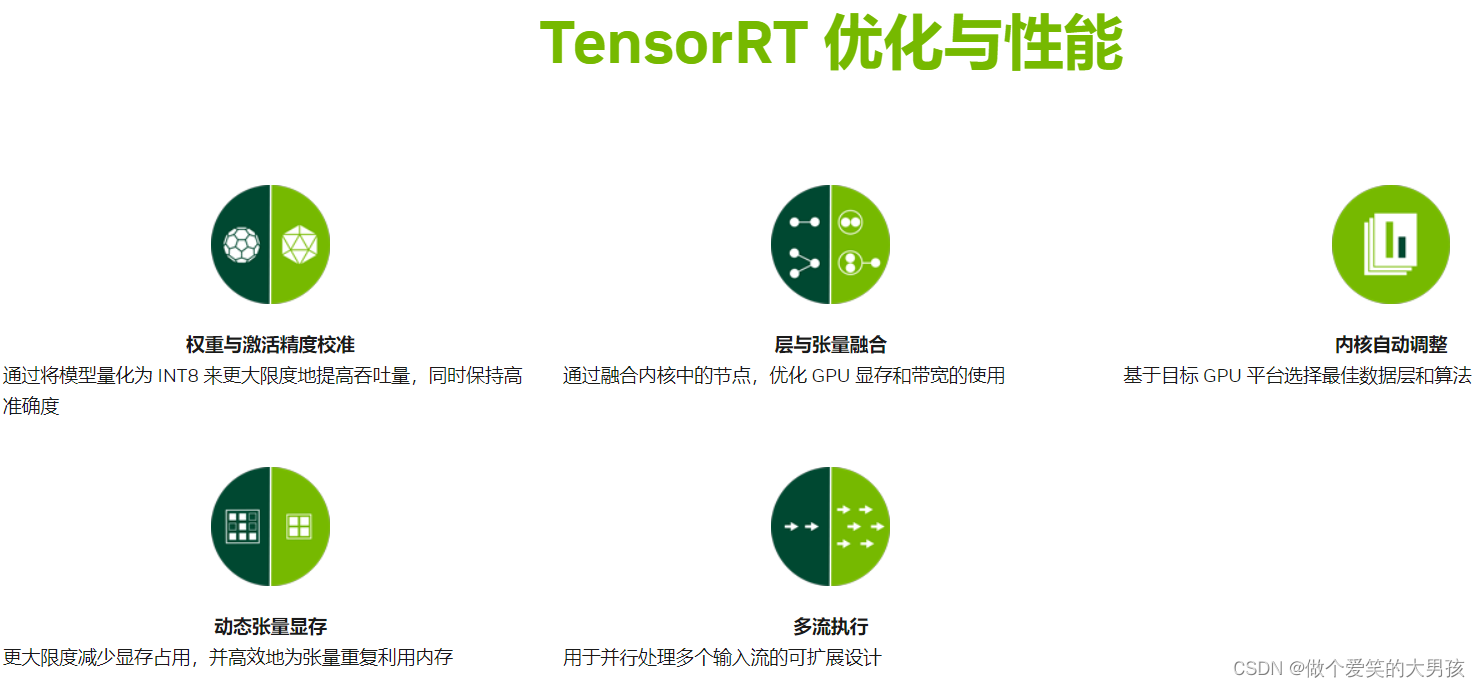
TensorRT推理手写数字分类(三)
系列文章目录 (一)使用pytorch搭建模型并训练 (二)将pth格式转为onnx格式 (三)onxx格式转为engine序列化文件并进行推理 文章目录 系列文章目录前言一、TensorRT是什么?二、如何通过onnx生成en…...
创建git项目并提交
1.创建仓库 2.点击创建 3复制gitee码云的HttpS连接 4 提交上传 打开项目并点击菜单栏上的【CVS】–》【Import into version control】–》【Create Git Repository】创建本地仓库 在打开的【Create Git Repository】对话框内选择本地仓库的位置,这里我选择…...

Android JNI修改Java对象的变量
在JNI中,本地代码(C/C)中修改了Java对象的变量,并且将其传递回Java端,那么Java端会看到变量的修改,尝试以下两种方式进行修改: 添加native方法 data class MyData(var key:Int,var value:String…...
VS+Qt 自定义Dialog
与QtCreator不同,刚用VS添加Qt Dialog界面有点懵,后整理了下: 1.右击项目,选择“添加-模块”,然后选择“Qt-Qt Widgets Class” 2.选择基类[1]QDialog,更改[2]ui文件名称,修改定义Dialog[3]对应类名&#…...
)
从零开始学习 Java:简单易懂的入门指南之时间类(十七)
时间类 第一章 Date类1.1 Date概述1.2 Date常用方法 第二章 SimpleDateFormat类2.1 构造方法2.2 格式规则2.3 常用方法2.4 练习1(初恋女友的出生日期)2.5 练习2(秒杀活动) 第三章 Calendar类3.1 概述3.2 常用方法3.3 get方法示例3.4 set方法示例:3.5 add方法示例&am…...

List 去重两种方式:stream(需要JDK1.8及以上)、HashSet
1、使用Stream 方法 使用JDK1.8及以上 /*** Java合并两个List并去掉重复项的几种做法* param args*/public static void main(String[] args) {String[] str1 {"1", "2", "3", "4", "5", "6"};List<String&…...

5.8.webrtc事件处理基础知识
在之前的课程中呢,我向你介绍了大量web rtc线程相关内容,今天呢,我们来看一下线程事件处理的基本知识。首先,我们要清楚啊,不同的平台处理事件的API是不一样的,这就如同我们当时创建线程是类似的࿰…...

无人机甚高频无线电中继通讯U-ATC118
简介 甚高频无线电中继通讯系统使用经过适航认证的机载电台连接数字网络传输模块,通过网络远程控制无缝实现无人机操作员与塔台直接语音通话。无人机操作员可以从地面控制站远程操作机载电台进行频率切换、静噪开关、PTT按钮,电台虚拟面板与真实面板布局…...
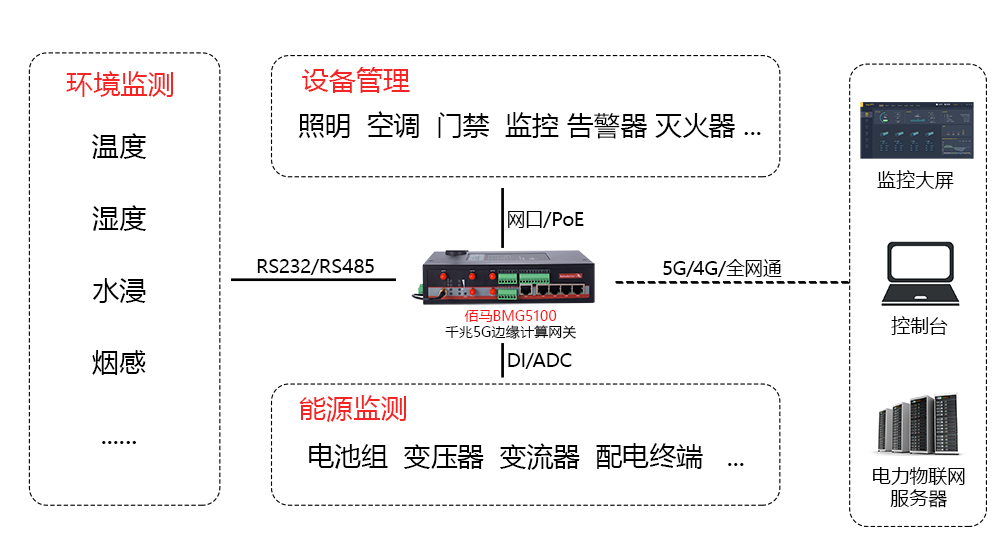
基于5G边缘网关的储能在线监测方案
近年以来,光伏、风力、水力发电等产业发展迅速,新能源在电力市场的占比持续增加,已经成为电力系统的重要组成部分。但由于光伏、风力、水力等发电方式存在天然的波动性,因此也需要配套储能、蓄能系统,保障新能源运行和…...

软件机器人助力基层网点实现存款数据自动化处理
银行基层网点需要及时了解存款变动情况,以便能够做出相应的安排和决策。过去,各级机构经办人员需要多次登录员工渠道系统,在不同的时间点查询并下载本级及下属机构的实时科目余额表,然后通过人工加工,才能得到存款新增…...
Win10怎么关闭自动更新?简单4招为你解决烦恼!
“买了一部win10的电脑,每次电脑自动更新都会导致我一些文件丢失或者系统错误。怎么才能关闭win10自动更新的功能呢?” Win10自动更新有时候会很影响我们使用电脑。在目前电脑用户中,使用win10系统的用户占大多数。因此很多朋友都会反映win10…...
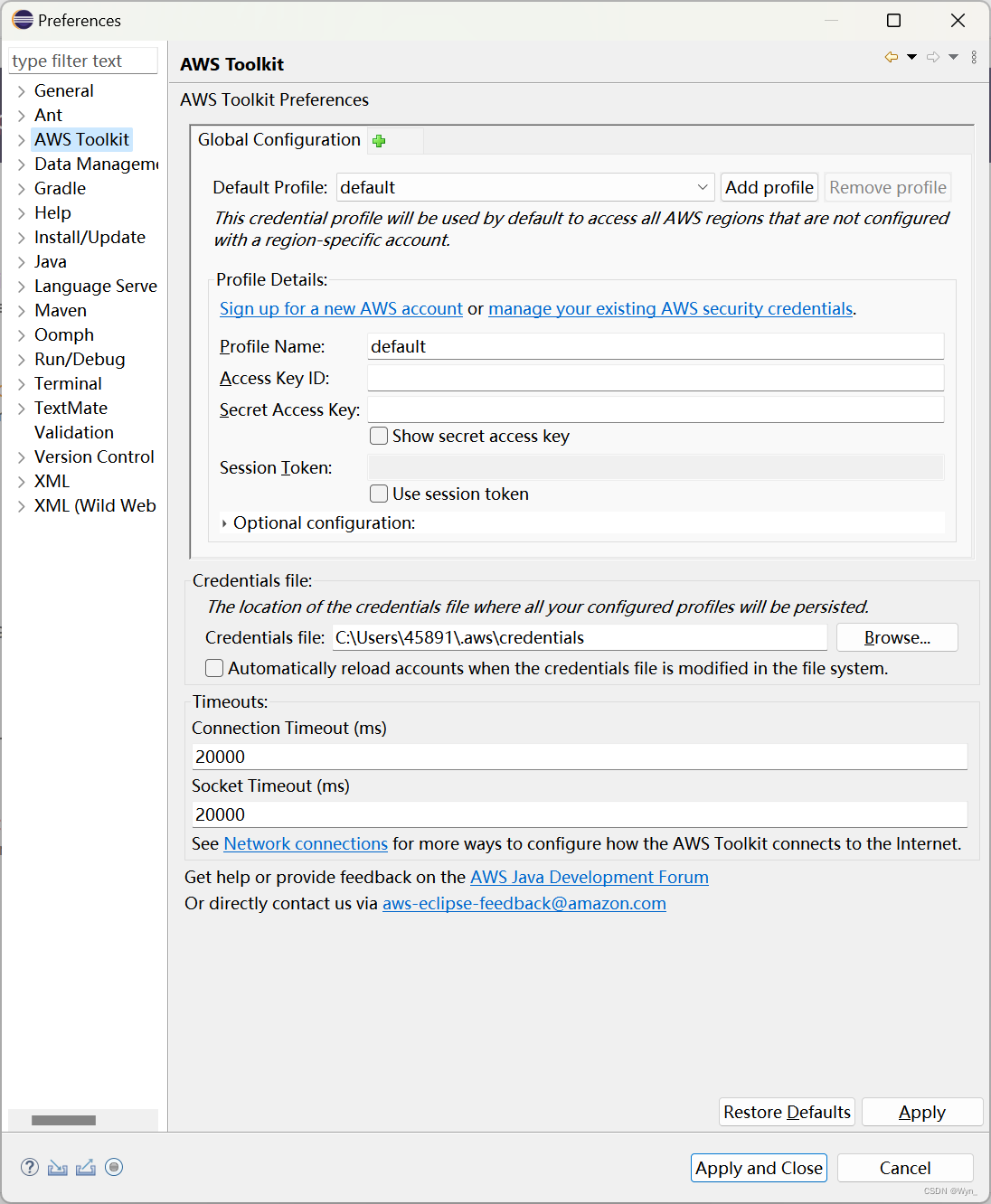
【AWS】安装配置适用于 Eclipse 的 AWS 工具包
目录 0.环境 1.步骤 1)安装Eclipse 2)安装AWS工具包 ① 在这个路径下点开安装软件的界面 ② 点击【Add】打开添加窗口 ③ 输入aws的工具包地址 ④ 勾选需要的工具,点击【Next】 ⑤ 将要安装的工具,点击【Next】 ⑥ 选择接受…...

vue页面在table字段后加单位
<el-table-column label"售价" align"center" width"120"><template slot-scope"scope">{{ ${scope.row.price.toFixed(2)} 元 }}</template> </el-table-column><el-table-column label"金重" …...
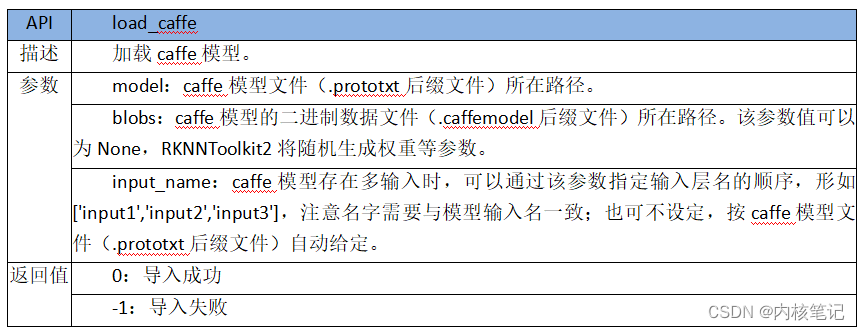
RK3588平台开发系列讲解(AI 篇)RKNN-Toolkit2 模型的加载
文章目录 一、Caffe模型加载接口二、TensorFlow模型加载接口三、TensorFlowLite模型加载接口四、ONNX模型加载五、ONNX模型加载六、PyTorch模型加载接口沉淀、分享、成长,让自己和他人都能有所收获!😄 📢 RKNN-Toolkit2 目前支持 Caffe、TensorFlow、TensorFlowLite、ONN…...

Nexus2迁移升级到Nexus3
与 Nexus 2.x 相比,Nexus 3.x 为我们提供了更多实用的新特性。SonaType 官方建议我们,使用最新版本 Nexus 2.x 升级到最新版本 Nexus 3.x,并在 Nexus 升级兼容性 一文中为我们提供了各个版本 Nexus 升级到最新版本 Nexus 3.x 的流程ÿ…...
在线OJ平台项目
一、项目源码 Online_Judge yblhlk/Linux课程 - 码云 - 开源中国 (gitee.com) 二、所用技术与开发环境 1.所用技术: MVC架构模式 (模型-视图-控制器) 负载均衡系统设计 多进程、多线程编程 C面向对象编程 & C 11 & STL 标准库 C Boost 准标…...

2026届毕业生推荐的AI写作助手实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能开展内容创作那一块儿,标题可是吸引目标受众的头一个环节哟。对于“降…...

Unity3d之随机生成数字
UnityEngine.Random.Range(min,max)包含最小值不包含最大值Mathf.Clamp是限定范围...


企业级AI Agent实战:如何解决异常考勤处理滞后与薪资核算难题?
摘要: 在2026年企业数字化转型步入深水区的今天,考勤管理与薪资核算的脱节已成为制约组织效能的隐形枷锁。作为一名在企业架构领域摸爬滚打15年的架构师,我观察到无数企业陷入“异常考勤处理滞后、员工满意度低、薪资核算频错”的恶性循环。传…...

英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份
英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟中展示与众不同的个人资料吗?LeaguePrank是一款开源免费的英雄联盟个性化工具&am…...

从一次数据解析Bug说起:彻底搞懂QString的toLocal8Bit、toUtf8和toLatin1该用哪个
从一次数据解析Bug说起:彻底搞懂QString的编码转换选择 上周排查一个网络协议解析问题时,遇到一个典型的编码陷阱:服务端返回的GBK编码数据包,在Qt客户端用toUtf8()解析后出现乱码。这个看似简单的编码问题背后,隐藏着…...

让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略
让足球经理游戏更真实:NewGAN-Manager 零基础配置全攻略 【免费下载链接】NewGAN-Manager A tool to generate and manage xml configs for the Newgen Facepack. 项目地址: https://gitcode.com/gh_mirrors/ne/NewGAN-Manager 还在为足球经理游戏中千篇一律…...

如何快速掌握LRC Maker:新手制作精准同步歌词的完整指南
如何快速掌握LRC Maker:新手制作精准同步歌词的完整指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 在数字音乐时代,你是否曾想为自己喜…...

STM32串口转RS-485双机通信:硬件设计、软件驱动与调试全解析
1. 项目概述:从串口到485,双机通信的工业级实现搞嵌入式开发,尤其是用STM32做控制,串口通信(UART)绝对是绕不开的基础。但如果你想把两个STM32板子连起来,距离稍微远一点,或者环境里…...
:含12类高频Query模板+错误码速查表)
华尔街量化团队内部文档流出(Perplexity财经数据查询SOP v2.3):含12类高频Query模板+错误码速查表
更多请点击: https://codechina.net 第一章:Perplexity财经数据查询概述 Perplexity 是一款基于大语言模型的智能搜索与知识发现工具,其在财经领域展现出独特优势:它能实时整合权威信源(如 SEC、Bloomberg、Reuters、…...