全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
1.简介
目标:基于pytorch、transformers做中文领域的nlp开箱即用的训练框架,提供全套的训练、微调模型(包括大模型、文本转向量、文本生成、多模态等模型)的解决方案;数据:- 从开源社区,整理了海量的训练数据,帮助用户可以快速上手;
- 同时也开放训练数据模版,可以快速处理垂直领域数据;
- 结合多线程、内存映射等更高效的数据处理方式,即使需要处理
百GB规模的数据,也是轻而易举;
流程:每一个项目有完整的模型训练步骤,如:数据清洗、数据处理、模型构建、模型训练、模型部署、模型图解;模型:当前已经支持gpt2、clip、gpt-neox、dolly、llama、chatglm-6b、VisionEncoderDecoderModel等多模态大模型;多卡串联
:当前,多数的大模型的尺寸已经远远大于单个消费级显卡的显存,需要将多个显卡串联,才能训练大模型、才能部署大模型。因此对部分模型结构进行修改,实现了训练时、推理时
的多卡串联功能。
- 模型训练
| 中文名称 | 文件夹名称 | 数据 | 数据清洗 | 大模型 | 模型部署 | 图解 |
|---|---|---|---|---|---|---|
| 中文文本分类 | chinese_classifier | ✅ | ✅ | ✅ | ❌ | ✅ |
中文gpt2 | chinese_gpt2 | ✅ | ✅ | ✅ | ✅ | ❌ |
中文clip | chinese_clip | ✅ | ✅ | ✅ | ❌ | ✅ |
| 图像生成中文文本 | VisionEncoderDecoderModel | ✅ | ✅ | ✅ | ❌ | ✅ |
| vit核心源码介绍 | vit model | ❌ | ❌ | ❌ | ❌ | ✅ |
Thu-ChatGlm-6b(v1) | simple_thu_chatglm6b | ✅ | ✅ | ✅ | ✅ | ❌ |
🌟chatglm-v2-6b🎉 | chatglm_v2_6b_lora | ✅ | ✅ | ✅ | ❌ | ❌ |
中文dolly_v2_3b | dolly_v2_3b | ✅ | ✅ | ✅ | ❌ | ❌ |
中文llama | chinese_llama | ✅ | ✅ | ✅ | ❌ | ❌ |
中文bloom | chinese_bloom | ✅ | ✅ | ✅ | ❌ | ❌ |
中文falcon(注意:falcon模型和bloom结构类似) | chinese_bloom | ✅ | ✅ | ✅ | ❌ | ❌ |
| 中文预训练代码 | model_clm | ✅ | ✅ | ✅ | ❌ | ❌ |
| 百川大模型 | model_baichuan | ✅ | ✅ | ✅ | ✅ | ❌ |
| 模型修剪✂️ | model_modify | ✅ | ✅ | ✅ | ||
| llama2 流水线并行 | pipeline | ✅ | ✅ | ✅ | ❌ | ❌ |
2.文本分类模型
本部分,介绍中文的文本分类模型,适用于二分类、多分类等情况。使用transformers库。
- 处理数据
code_01_processdata.ipynb - 数据介绍
- 本案例使用的是一个外卖平台的评论数据,对评论的文本做了分类(分为好评和差评)
- 当你把
code_01_processdata.ipynb文件跑完之后,就可以看到在📁data_all里面有一个📁data,里面有三个文件,样式都是像下面👇这样的

上图是一个batch的数据,或者所有的文本分类的数据样式:
text下面的红色条,就是一个个句子。label里面有红色有绿色,就是表示标签分类。transformers包做分类的时候,数据要求就这两列。
注意点:
- 数据需要分为
train_data.csv,test_data.csv,valid_data.csv,这三个csv文件注意是使用,分割开的。 - 数据不可以有缺失值
- 数据最好只含有两列:
label,text
label:表示标签,最好为整型数值。0,1,2,3,4等text:表示文本,(看你需求,可以有符号,也可以没有标点符号)
train_data.csv,test_data.csv,valid_data.csv这三个数据里面,不要有数据相同的,不然会造成数据泄漏。
- 训练模型
code_02_trainmodel.ipynb
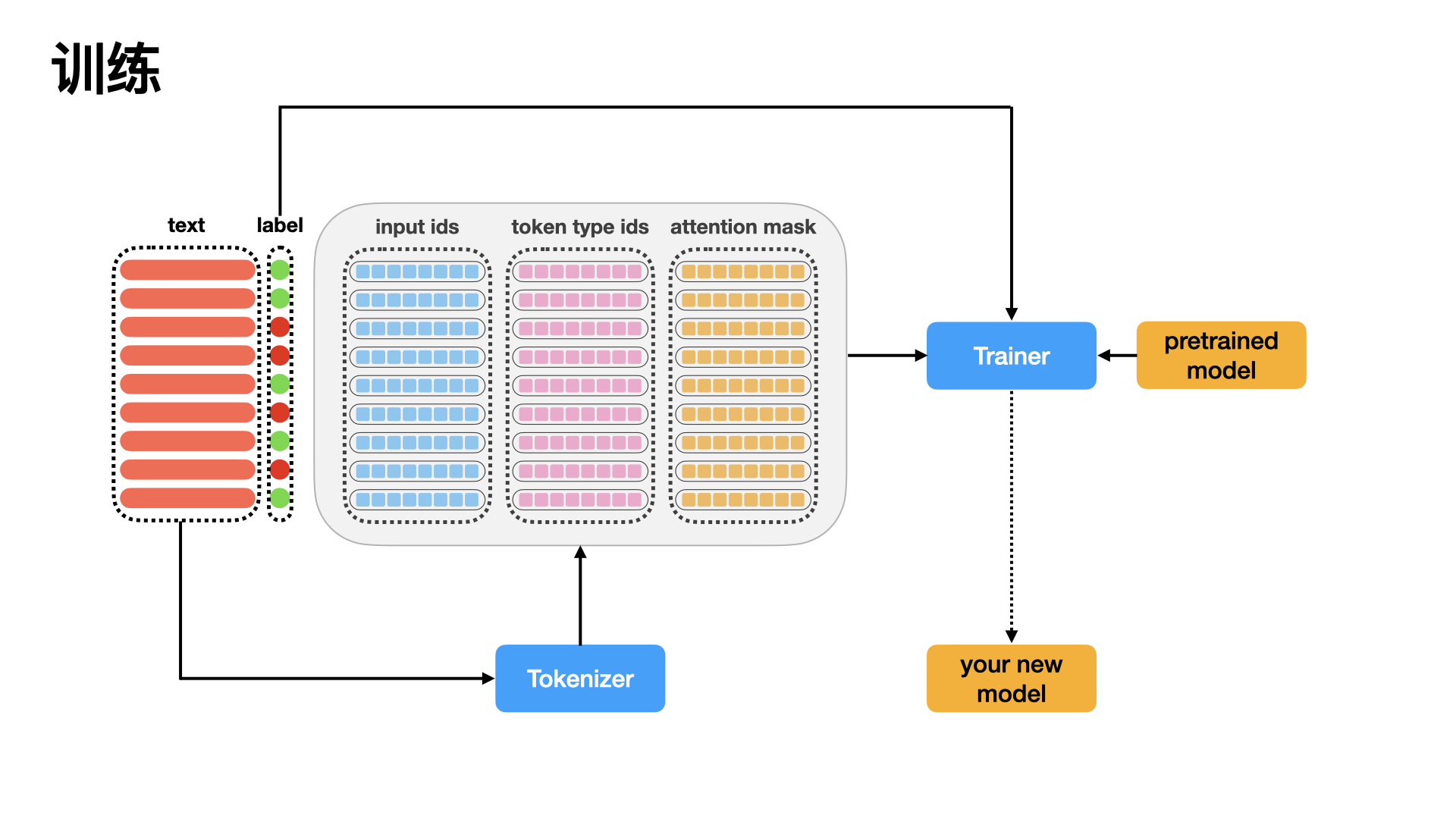
-
数据训练流程
以一个batch为例:Tokenizer会将数据中的text转换成三个矩阵(或者叫三个Tensor),分别叫input_ids,token_type_ids,attention_mask,至于怎么转换的,我们先不做详细介绍(本仓库后续会介绍)。pretrained model在被加载之前,需要设置一大堆模型的参数,至于要设置什么参数,我们也不做详细介绍。Trainer就是一个训练器,也需要预先设置好一大堆参数。至于要设置什么参数,我们也不做详细介绍。Trainer会把input_ids,token_type_ids,attention_mask;还有数据自带的标签label;还有pretrained model都加载进来,进行训练;- 当所有batch的数据更新完之后,最终就会生成一个模型。
your new model就诞生了。 - 对于刚开始学习
大模型做nlp分类的任务,其实不需要考虑那么多细节,只需要注意数据流程。
-
注意点:
- 这个步骤非常看显存大小。显卡显存越大越好。
batch_size,eval_size大小取决于显存大小。 - 在实际工程中,会先使用
Tokenizer把所有的文本转换成input_ids,token_type_ids,attention_mask,然后在训练的时候,这步就不再做了,目的是减少训练过程中cpu处理数据的时间,不给显卡休息时间。 - 在使用
Tokenizer把所有的文本做转换的期间,如果设置的文本的长度上限为64,那么会把大于64的文本截断;那些少于64的文本,会在训练的时候,在喂入模型之前,把长度补齐,这么做就是为了减少数据对内存的占用。
- 这个步骤非常看显存大小。显卡显存越大越好。
-
-
预测
code_03_predict.ipynb -
这个时候,就是搞个句子,然后丢给一个
pipeline(这个就是把Tokenizer和你的大模型放在一起了),然后这个pipeline就给你返回一个分类结果。 -
常见的就是使用
pipeline,如果更加复杂的话,比如修改模型,这个时候,就比较复杂了(后面会再次介绍)。
-
-
-
部署
-
简单的
部署相对于预测,其实就是再加一层web端口,fastapi包就可以实现。 -
高级一点的
部署相对于预测,就需要把模型从pytorch转换成onnx格式的,这样可以提高推理效率(也不一定,就是举个例子),可能也不会使用web端口(http协议)了,会使用rpc协议等方法。这部分现在先不看。
-
3.中文gpt2
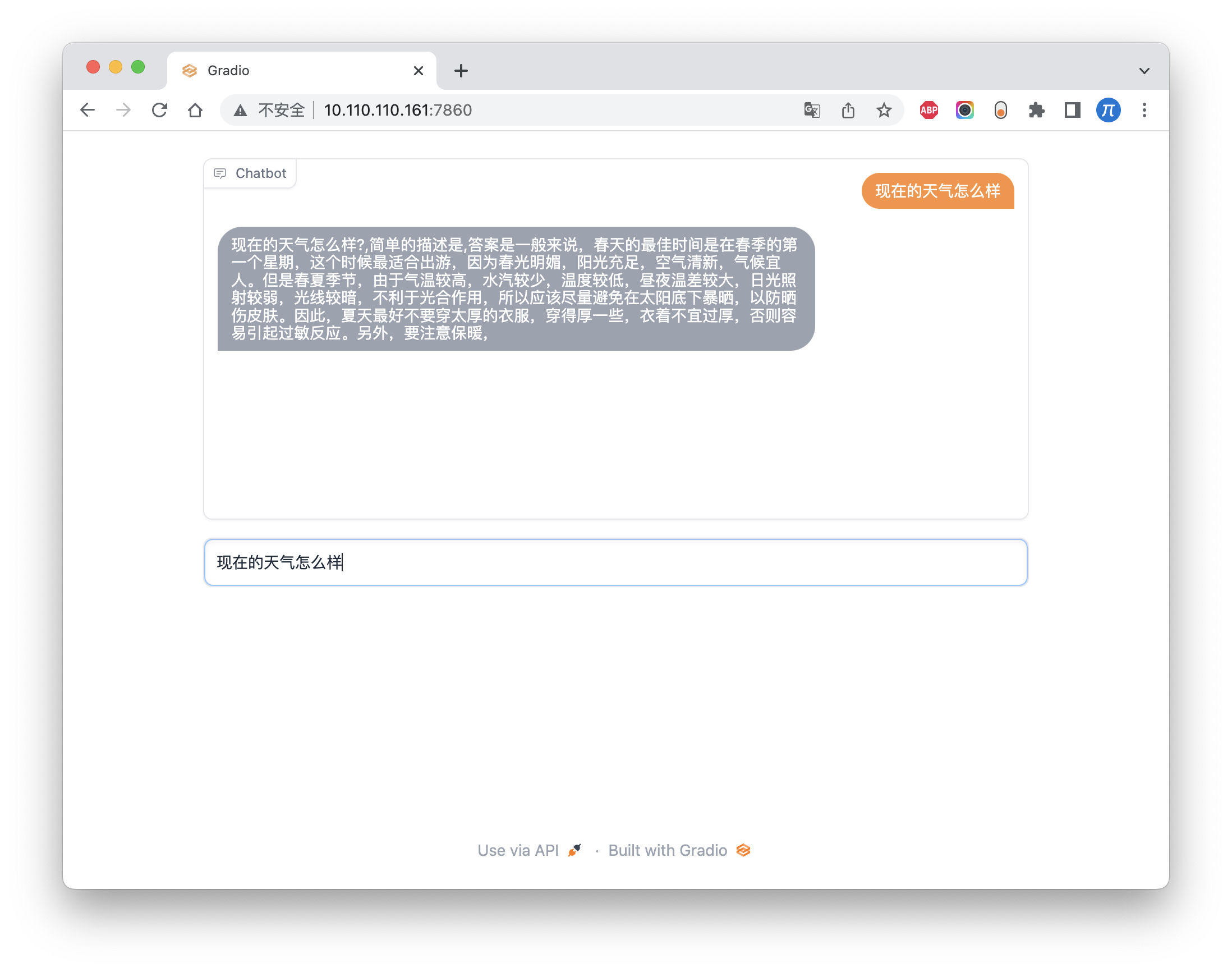
- 本文,将介绍如何使用中文语料,训练一个gpt2
- 可以使用你自己的数据训练,用来:写新闻、写古诗、写对联等
- 我这里也训练了一个中文gpt2模型,使用了
612万个样本,每个样本有512个tokens,总共相当于大约31亿个tokens
- 安装包
需要准备好环境,也就是安装需要的包
pip install -r requirements.txt
像是pytorch这种基础的包肯定也是要安装的,就不提了。
-
数据来源
- 获得数据:数据链接,关注公众号【
统计学人】,然后回复【gpt2】即可获得。 - 获得我训练好的模型(使用了15GB的数据(
31亿个tokens),在一张3090上,训练了60多小时)
- 获得数据:数据链接,关注公众号【
-
数据格式
- 数据其实就是一系列文件夹📁,然后每一个文件夹里面有大量的文件,每一个文件都是
.csv格式的文件。其中有一列数据是content - 每一行的
content就代表一句话 - 虽然数据有15GB那么大,但是处理起来一点也不复杂,使用
datasets
包,可以很轻松的处理大数据,而我只需要传递所有的文件路径即可,这个使用glob包就能完成。
- 数据其实就是一系列文件夹📁,然后每一个文件夹里面有大量的文件,每一个文件都是
-
训练代码
train_chinese_gpt2.ipynb- 现在训练一个gpt2代码,其实很简单的。抛开处理数据问题,技术上就三点:
tokenizer、gpt2_model、Trainer tokenizer使用的是bert-base-chinese
,然后再添加一下bos_token、eos_token、pad_token。gpt2_model使用的是gpt2,这里的gpt2我是从0开始训练的。而不是使用别人的预训练的gpt2模型。Trainer训练器使用的就是transformers的Trainer模块。(支撑多卡并行,tensorboard等,都写好的,直接调用就行了,非常好用)
- 现在训练一个gpt2代码,其实很简单的。抛开处理数据问题,技术上就三点:
-
模型
-
推理代码
infer.ipynb
这个是chinese-gpt2的推理代码
- 将代码中的
model_name_or_path = "checkpoint-36000"里面的"checkpoint-36000",修改为模型所在的路径。 - 然后运行下面一个代码块,即可输出文本生成结果
- 可以参考这个代码,制作一个api,或者打包成一个函数或者类。
- 交互机器人界面
chatbot.py
- 修改代码里面的第4行,这一行值为模型所在的位置,修改为我分享的模型文件路径。
model_name_or_path = "checkpoint-36000"
- 运行
python chatbot.py
- 点击链接,即可在浏览器中打开机器人对话界面

- 更多
- 这个完整的项目下来,其实我都是全靠
huggingface文档、教程度过来的. - 我做的东西,也就是把
Tokenizer改成中文的了,然后也整理了数据,别的大部分东西,都不是我做的了. - 原文链接为https://huggingface.co/course/zh-CN/chapter7/6?fw=pt.
其实,我更喜欢做应用,但是也要理解相关的背后原理,目前还在研究相关的gpt2原理还有相关的推理细节,这是我整理的链接,希望可以共同进步
- https://huggingface.co/blog/how-to-generate
- https://huggingface.co/gpt2
- https://huggingface.co/gpt2-large
4.中文clip模型
- 本文将介绍,如何从0到1的训练一个中文clip模型。
- 在处理数据的过程中,训练的过程中,需要的注意事项。
- 从数据流的角度,看看clip模型是怎么处理数据的,模型是怎么构建的。image和text的模型的差异性,两个模型是怎么合并起来计算loss的。
- clip模型介绍
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。
CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,
CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,
模型能够学习到文本-图像对的匹配关系。
如下图所示,CLIP包括两个模型:
-
Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;
-
Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
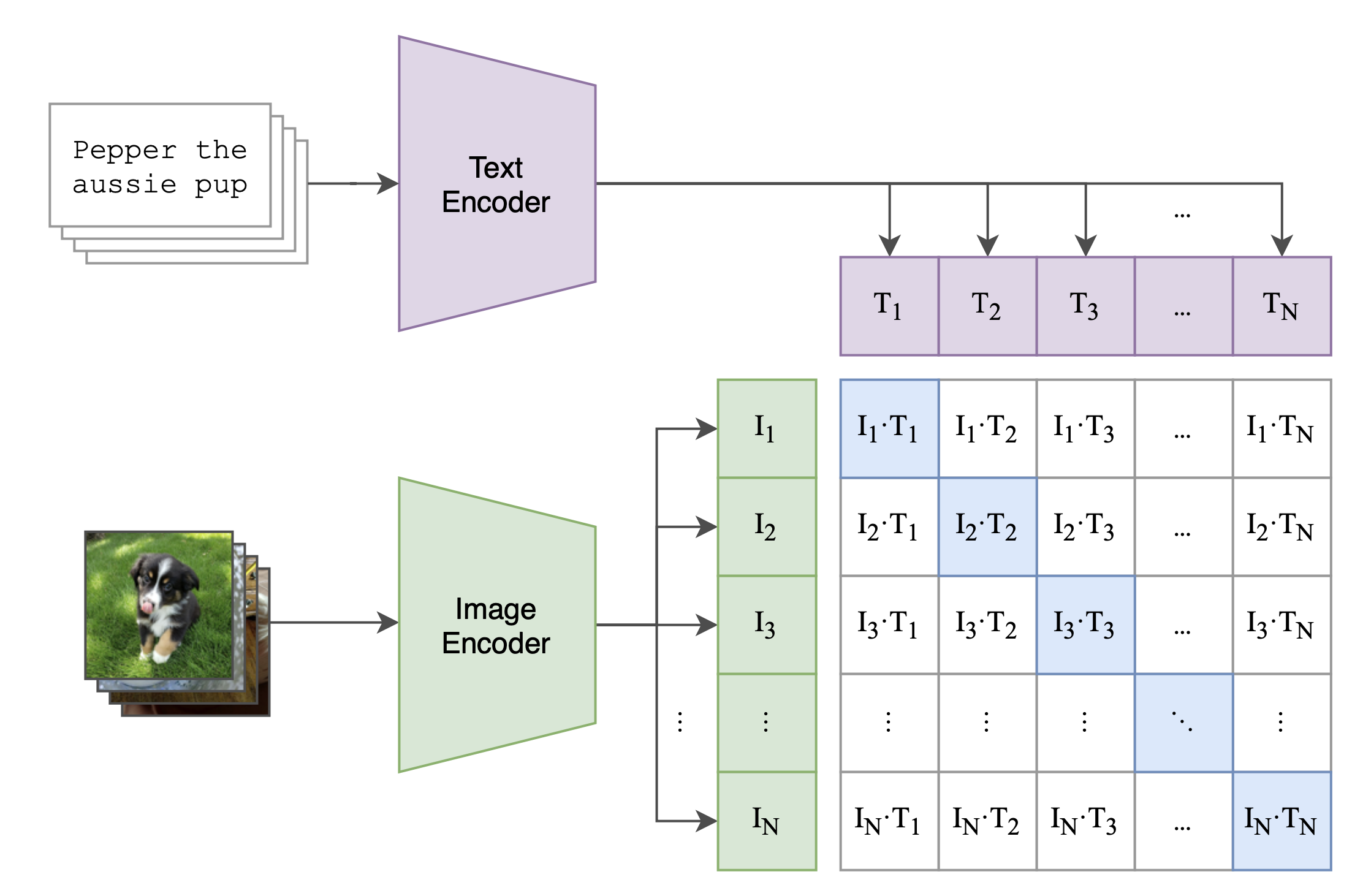
上面这段文字来源于https://zhuanlan.zhihu.com/p/493489688
- 从数据上看:之前相似度计算,都是两个文本对:
text - text。只不过现在都是text - image了。 - clip是两个模型(具体长什么样子,后面再说)
- 2.1
text-model:负责把text转换成向量。 - 2.2
image-model:负责把image转换成向量。 - 2.3 然后把上面两个向量,做交叉计算loss,然后loss反向传播,这样两个模型的参数都会更新。
- 其实你想啊,这个
image-model处理图像的,其实也可以改为处理视频、处理3d模型等。那简直是格局打开🫴了。我现在没有数据,后面也打算做一个。 - 你再想想,
text-image=>text-image-video-3d这样联合起来,是不是更好。没数据,没机器,做不了。 - 有些人可能感觉,
你这人,就知道TMD吹牛,来来来,我带你研究研究clip模型的源码。
- 数据
- 直接点击链接https://pan.baidu.com/s/1wGmXUNP021OWnW7Kik7q1A?pwd=gd3c
来获得。 - 把下载好的文件,也就是
test-2.6w.csv、train-137w.csv放在文件夹📁bigdata/raw_data里面。 - 以此运行
processdta_01.ipynb、processdta_02.ipynb、processdta_02.ipynb用来处理数据。
- 3.1
processdta_01.ipynb:用来下载数据,大概下载了10多个小时。 - 3.2
processdta_02.ipynb:用来筛选数据,不是所有的图片数据都是可以用的,这一步非常坑。需要留意。如果图片没有筛选好,在你训练到中间的时候,突然一下因为图片无法加载导致错误,从而训练中断了。 - 3.3
processdta_03.ipynb:用来把数据干净的数据处理好,合并好,生成新的,漂亮的训练数据。
- 其实完整下来看,数据清洗,就是把符合格式的照片筛选出来,然后进行训练。
- 数据总结
说到底,你的数据只要整理成这样的一个样式即可
| text | image_path |
|---|---|
| 河南一村民继承祖上的一金碗,专家鉴定:此碗是溥仪皇帝用过的 | bigdata/image_data/test-9282.jpg |
| 著名钢琴家郎朗:我永远不会放弃演奏 | bigdata/image_data/test-2644.jpg |
| 科幻动作电影《超体》10月24日来袭 | bigdata/image_data/test-13199.jpg |
text:这一列对应图片的标注,或者和图片相关的文本。image_path:这一列对应图片所在你电脑本地上的路径。- 是的,搞了半天,数据就是这么简单。
- 数据预处理
这里的数据预处理,是我随便起的名字。说白了,就是这么会是:
-
使用
tokenizer把text转换成input_ids和attention_mask. -
使用
processor把image转换成pixel_values. -
处理
text,那还是很快的。百万级别的数据,可能2~3分钟就行了。 -
因为
image太大了,只能在训练的时候,每一batch,才能去加载image
,这就导致训练的时候特别慢。倒不是因为我的3090算力不行,全都TMD卡在计算机IO上了,非常让人难受。
- 模型部分
终于讲解到clip的模型部分了。这个clip模型实在是太灵活了,你可以做很多个版本,这里我们挑几个比较常见的结构,来分享一下。
- 常见的clip模型
这里值得是常见的clip模型,特指的是transformers包的clip模型。
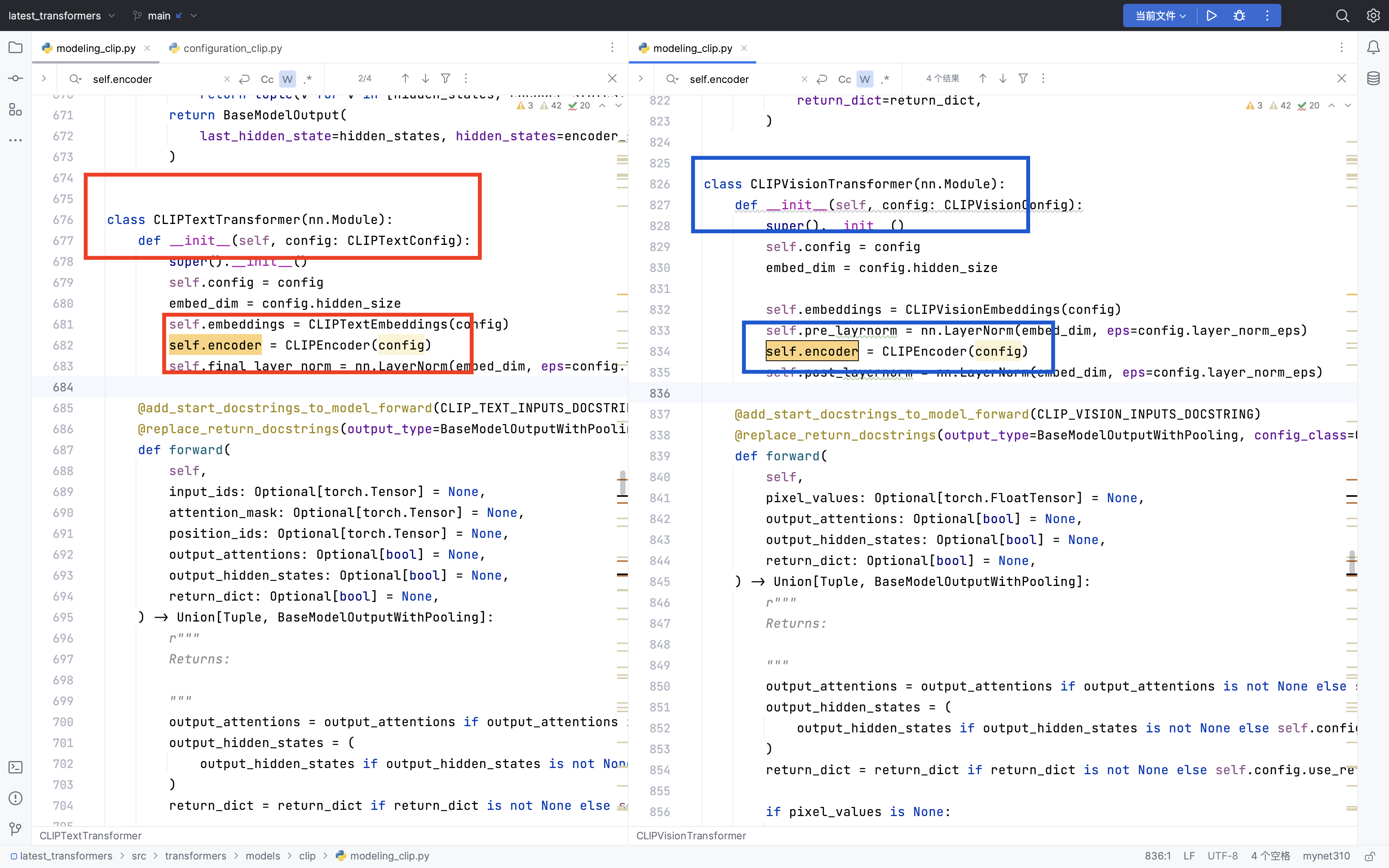
- clip主要就是分为两个部分,一个是
CLIPTextTransformer,一个是CLIPVisionTransformer,说白了就是一个处理text,一个处理image。 CLIPTextTransformer和CLIPVisionTransformer的核心,都共用了一个模型结构CLIPEncoder
。也就是CLIP编码部分。(这里说的共用,值得是模型框架相同,而不是模型训练的时候,参数也相同。)
Q:有些人就问了,text和image两个生成的数据都不一样,比如text转换成input_ids和attention_mask;image
转换成pixel_values;他们怎么可以使用一个模型结构CLIPEncoder?
A:这个也是非常好回答的,因他俩又不是直接使用CLIPEncoder
,前后都加了一些万金油的模型组件(比如embedding、linear
等),模型输出的时候,也是这么做的。还是应了那句话,就看你怎么吧数据转换成hidden_states,以及怎么把hidden_states输出出去。
Q:CLIPTextTransformer和CLIPVisionTransformer输出的维度也不一定一样吧,怎么计算交叉损失?
A: 也很简单啦,加个linear对齐一下就行了。
看看CLIPTextTransformer和CLIPVisionTransformer的内心:

- 中文版本的clip模型
上面的常见的clip模型,确实是好,其实你只要换一个支持中文的新tokenizer,然后从0️⃣开始训练即可。
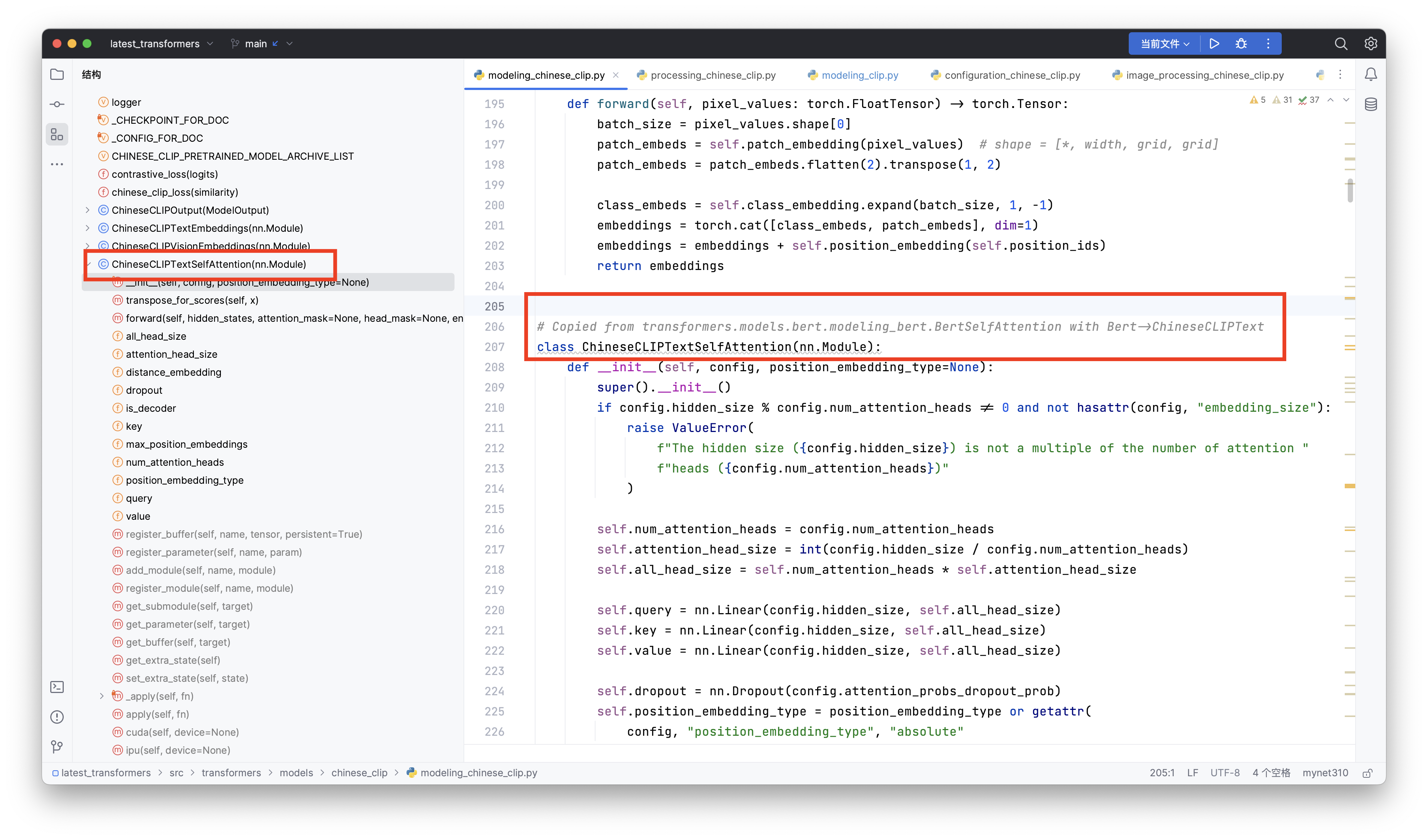
但是这么搞,没什么创意呀。其实我第一次就是这么干的,直接支持中文的新tokenizer。但是训练了一天,loss基本上没变化。我内心其实是崩溃的。
后来,我研究了一下transformers包里面的chinese-clip模型代码。我发现,chinese-clip相对于clip
。就是把常规的CLIPTextTransformer换成了bert版本的。啊对,这就破案了。这个奉上代码截图。
- 后续改进
- 因为训练image这类型的任务,非常吃资源,不管是我的显存还是我的磁盘。目前数据占用我硬盘
100GB - 针对loss不下降,下次如果再让我做,我打算先把
clip模型的vit部分先固定住,然后训练bert来拟合vit-output。 - 也可也固定bert模型,训练vit模型;
- 也可以拆开做,反正本质上都是
Encoder,然后计算相似度。
5. 图生文image-encoder-decoder
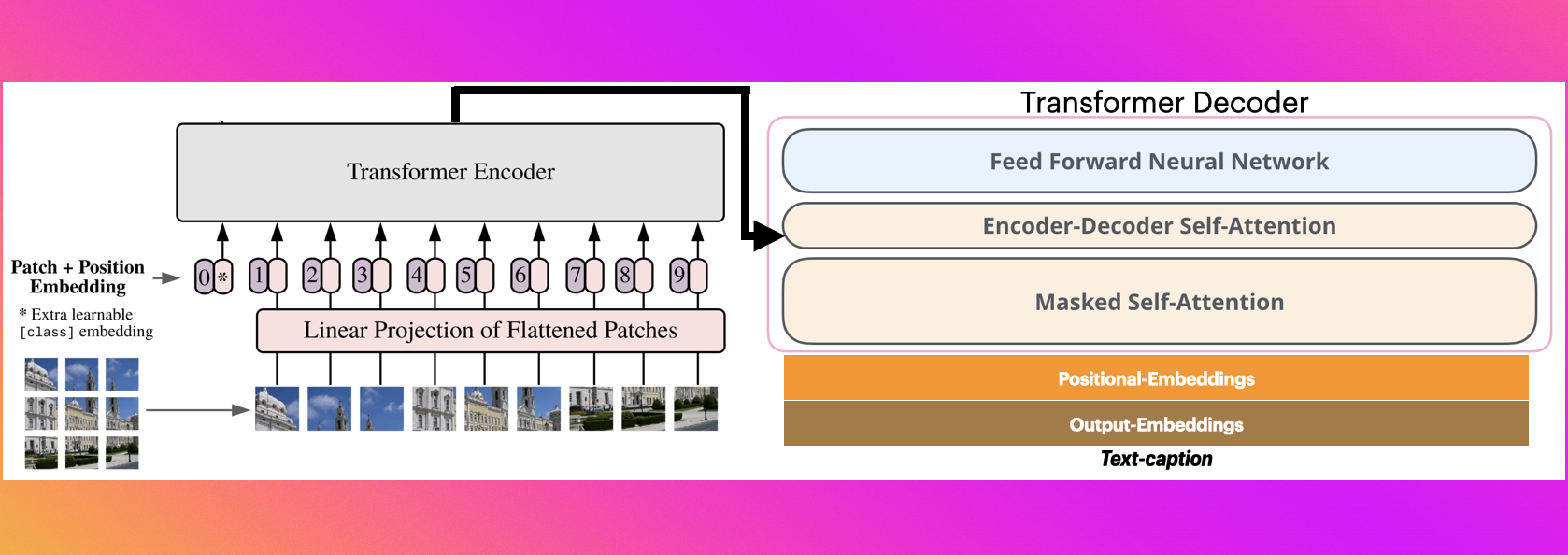
之前在huggingfacehttps://huggingface.co/nlpconnect/vit-gpt2-image-captioning上看到这个模型.
- 感觉这个模型很有趣,想法很好。
- 发现这个模型关于中文的不多。
- 之前的
clip训练其实挺失败的,loss没有下降.
主要也就是抱着学习的态度,把源码看懂,把流程跑通。分享中间的细节和踩坑经历。

- 使用
vit来作为encoder部分,输出encoder_hidden_states,绿色部分1。 - 使用
gpt2来作为decoder部分,接受encoder_hidden_states,绿色部分3。 - 如果
encoder输出的encoder_hidden_states和decoder接受的encoder_hidden_states维度不一样,就加个linear,绿色部分2。
- 模型训练需要的数据样式
训练的时候,模型需要的数据主要有两个维度:
pixel_value:image通过processor生成label:text通过tokenizer生成的input_ids。- 计算
loss的时候,其实和gpt2一模一样的(自回归,本质上就是向后错位一下)。
目前已经把训练好的模型,发布在huggingface上了。https://huggingface.co/yuanzhoulvpi/vit-gpt2-image-chinese-captioning
本模块处理数据的方式和clip模型差不多,可以看隔壁文件夹,训练clip的数据处理思路。
- 只要把
processdta_02.ipynb文件替换即可。 - 执行顺序依然按照着
processdta_01.ipynb、processdta_02.ipynb、processdta_03.ipynb。
-
训练部分
train_encoder_decoder.ipynb- 处理图像,使用的是
"google/vit-base-patch16-224"模型。 - 处理文本,使用的是
"yuanzhoulvpi/gpt2_chinese"模型。 - 最后就是把两个模型通过
VisionEncoderDecoderModel粘起来。
- 处理图像,使用的是
-
训练的loss

-
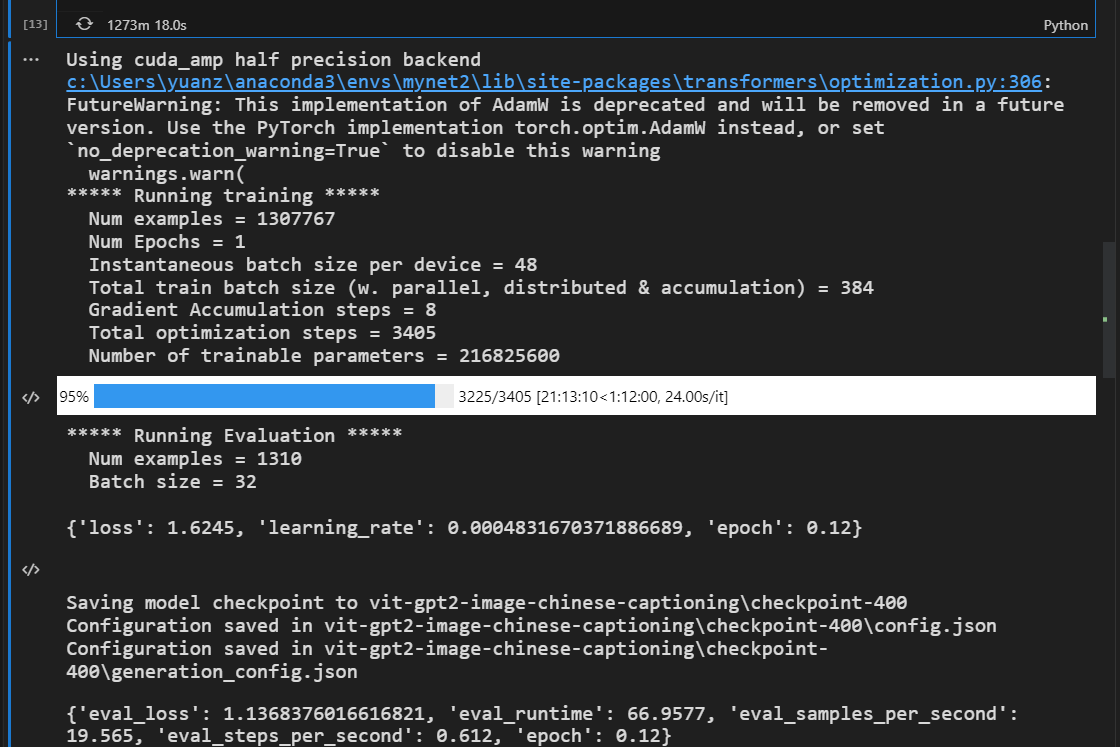
训练的信息
gpu使用的是3090,模型大概是2.16亿个参数。花了超过20个小时。但是大部分时间都是卡在IO上(加载图片上)
-
推理用你自己训练
参考infer_encoder_decoder.ipynb -
直接用
from transformers import (VisionEncoderDecoderModel, AutoTokenizer,ViTImageProcessor)
import torch
from PIL import Image
vision_encoder_decoder_model_name_or_path = "yuanzhoulvpi/vit-gpt2-image-chinese-captioning"#"vit-gpt2-image-chinese-captioning/checkpoint-3200"processor = ViTImageProcessor.from_pretrained(vision_encoder_decoder_model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(vision_encoder_decoder_model_name_or_path)
model = VisionEncoderDecoderModel.from_pretrained(vision_encoder_decoder_model_name_or_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)max_length = 16
num_beams = 4
gen_kwargs = {"max_length": max_length, "num_beams": num_beams}def predict_step(image_paths):images = []for image_path in image_paths:i_image = Image.open(image_path)if i_image.mode != "RGB":i_image = i_image.convert(mode="RGB")images.append(i_image)pixel_values = processor(images=images, return_tensors="pt").pixel_valuespixel_values = pixel_values.to(device)output_ids = model.generate(pixel_values, **gen_kwargs)preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)preds = [pred.strip() for pred in preds]return predspredict_step(['bigdata/image_data/train-1000200.jpg'])6.vit 源码

- 之前都搞过
clip、image-encoder-decoder。现在哪里还怕搞不懂vit. - 这里主要分享一下
vit的最核心的部分。
- vit 核心的数据内容
vit想法非常牛,但是数据处理的思想更牛,之前都没提出来过。
载对于一个图片,将一个图片分割成N块。巧妙的使用nn.Conv2d。
- 初始化
import torch
from torch import nn #base parameterimage_size=224 # 图片的width和height
patch_size=16 # 将图片的分为块,每一块的大小为16x16,这样就有(224//16)^2 = 14 ^2 = 196个
num_channels=3 # R,G, B
hidden_size=768 # 输出的hidden_size
batch_size = 16 # 一批数据有多少
- 创建一个分块器和一个样本数据(一个
batch)
#分块器
project = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)#样本数据(一个`batch`)
#batch_size, num_channels, height, width = pixel_values.shape
pixel_values = torch.randn(batch_size, num_channels, image_size, image_size)pixel_values.shape
- 输出分块的大小
project(pixel_values).shape #> torch.Size([16, 768, 14, 14])
- 数据再转换一下,image的embedding就完成了。
image_embedding = project(pixel_values).flatten(2).transpose(1, 2)
image_embedding.shape
#> torch.Size([16, 196, 768]) # batch_size, seq_length, embedding_dim
这个时候,就已经和文本的数据一样了。维度都是(batch_size, seq_length, embedding_dim),再向下推导,就是transformers了。没什么可介绍的了。
项目链接:https://github.com/yuanzhoulvpi2017/zero_nlp
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
相关文章:
全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据! 1.简介 目标:基于pytorch、transformers做中文领域的nlp开箱即用的训练框架,提…...

ffmpeg
文章目录 libavcodec实现 libavformat实现libavfilter实现 libswscale实现对比libavfilter图像处理libswscale vs libyuvlibavutil 命令行工具ffmpeg例子 ffprobe例子 FFmpeg 是一个由 C 语言编写的开源跨平台音视频处理工具集,它具有模块化的架构。下面是 FFmpeg 的…...
)
CH03_代码的坏味道(下)
循环语句(Loops) 从最早的编程语言开始,循环就一直是程序设计的核心要素。如今,函数作为一等公民已经得到了广泛的支持,因此我们可以使用以管道取代循环(231)管道操作(如filter和ma…...

journal日志导致服务器磁盘满
背景 ubuntu 18.04服务器磁盘突然100% 一查/var/log/journal目录占了14G 清理 要清理 journal 日志,可以使用以下步骤: 运行以下命令来查看 journal 日志的使用情况: journalctl --disk-usage这将显示 journal 日志的当前使用情况&#x…...

“Go程序员面试笔试宝典”复习便签
一.逃逸分析 1.1逃逸分析是什么? 逃逸分析,主要是Go编译器用来决定变量分配在堆或者栈的手段。 区分于C/C手动管理内存分配,Go将这些工作交给了编译器。 1.2逃逸分析有什么作用 解放程序员。程序员不需要手动指定指针分配内存。 灵活的…...
)
数组的度(指数组里任一元素出现频数的最大值)
题目: 给定一个非空且只包含非负数的整数数组 nums,数组的 度 的定义是指数组里任一元素出现频数的最大值。 你的任务是在 nums 中找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。 示例 1: 输入:nums …...

scala array类型参数
在Scala中,数组(Array)是一种用于存储相同类型元素的数据结构。数组可以用于保存基本数据类型和自定义数据类型的元素。当定义数组类型参数时,您通常是在函数、类或方法签名中使用它们。以下是一些有关Scala数组类型参数的示例&am…...
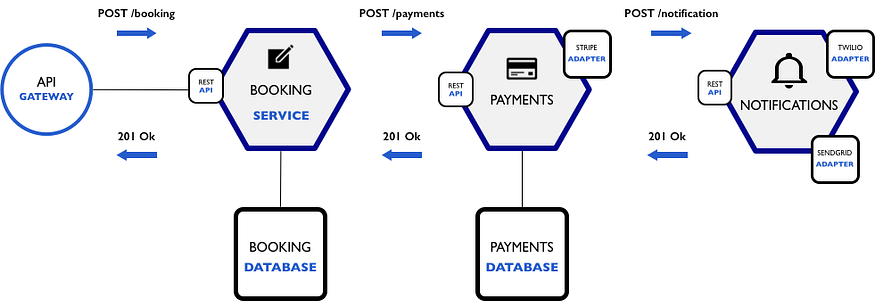
构建 NodeJS 影院预订微服务并使用 docker 部署(03/4)
一、说明 构建一个微服务的电影网站,需要Docker、NodeJS、MongoDB,这样的案例您见过吗?如果对此有兴趣,您就继续往下看吧。 你好社区,这是🏰“构建 NodeJS 影院微服务”系列的第三篇文章。本系列文章演示了…...

html写一个向flask_socketio发送消息和接收消息并显示在页面上
以下是一个简单的HTML页面,它包含一个输入框、一个发送按钮和一个显示区域。用户可以在输入框中输入消息,点击发送按钮,然后这个消息会被发送到 Flask-SocketIO 服务器。当服务器回应消息时,它会在页面的显示区域显示出来。 <…...

C#使用.Net Core进行跨平台开发
使用 .NET Core 进行跨平台开发是一种灵活的方法,可以在多个操作系统上运行 C# 应用程序。以下是在 C# 中使用 .NET Core 进行跨平台开发的一般步骤: 安装 .NET Core SDK: 在开始之前,需要安装适用于操作系统的 .NET Core SDK。可…...

Java“牵手”天猫店铺所有商品API接口数据,通过店铺ID获取整店商品详情数据,天猫API申请指南
天猫商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。天猫商品详情可以帮助消费者更好的了解宝贝信息,从而做出购买决策。同时,消费者也可以通过商品详情了解其他买家对宝贝的评价…...

php输入post过滤函数,入库出库,显示
第一部分 php输入post过滤函数 function GLOBAL_POST($str) {$str_origin$str; if (empty($str)) return false;$str str_replace( /, "", $str);//替换关键词 $str str_replace("\\", "", $str); $str str_replace(">", &…...
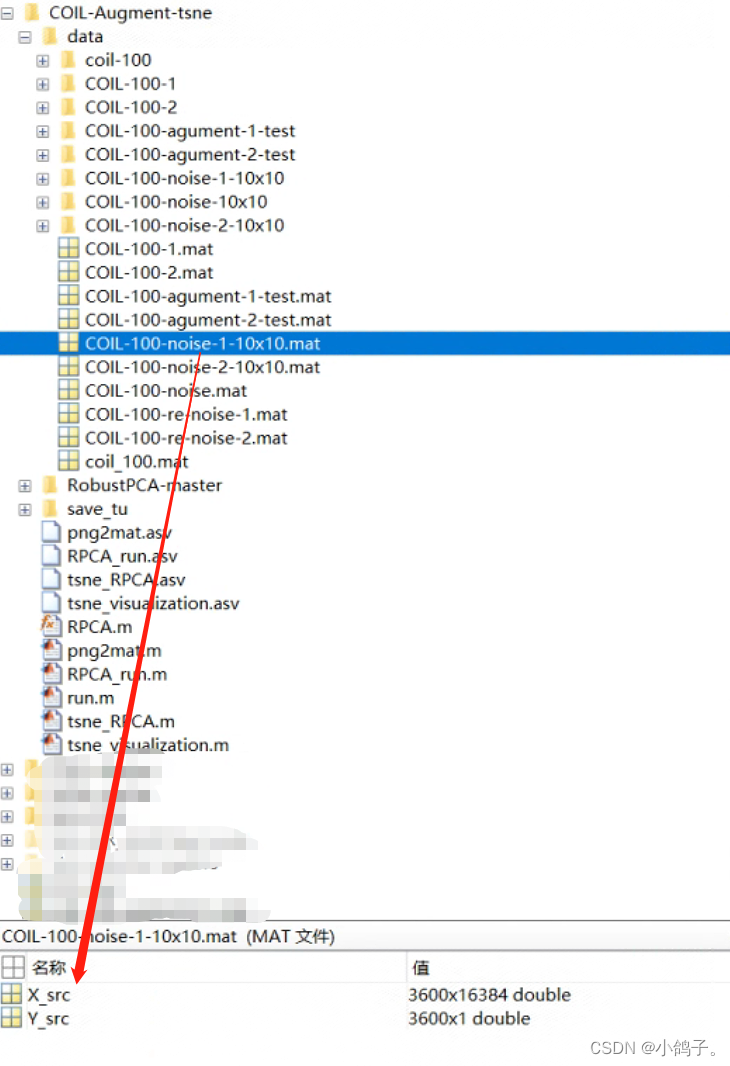
matlab-对数据集加噪声并实现tsne可视化
matlab-对数据集加噪声并实现tsne可视化 最近才知道,原来可以不用模型,也能实现对数据集数据的可视化。 **一、**以COIL-100数据集为例子。 问题: 前提:首先对COIL-100数据集根据角度0-175和180-255,分别划分成C1,C…...
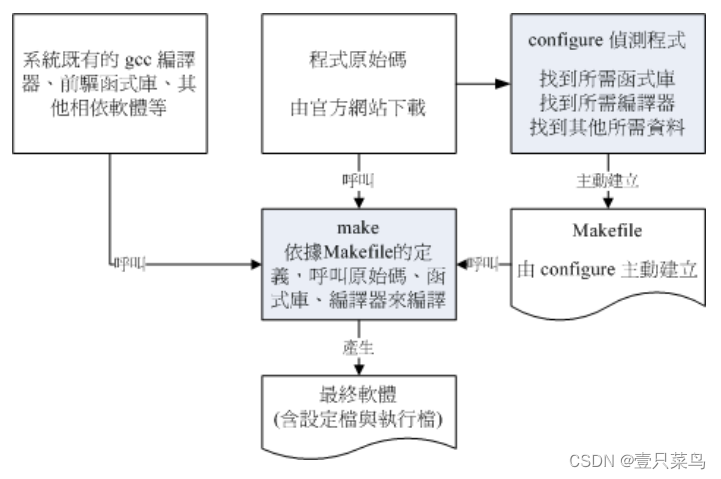
【BASH】回顾与知识点梳理(三十八)
【BASH】回顾与知识点梳理 三十八 三十八. 源码概念及简单编译38.1 开放源码的软件安装与升级简介什么是开放源码、编译程序与可执行文件什么是函式库什么是 make 与 configure什么是 Tarball 的软件如何安装与升级软件 38.2 使用传统程序语言进行编译的简单范例单一程序&#…...

Sql注入攻击的三种方式
SQL注入是指web应用程序对用户输入数据的合法性没有判断或过滤不严,攻击者可以在web应用程序中事先定义好的查询语句的结尾上添加额外的SQL语句,在管理员不知情的情况下实现非法操作,以此来实现欺骗数据库服务器执行非授权的任意查询,从而进一步得到相应的数据信息。SQL 注…...

dockerfile部署前端vue打包的dist文件实战
背景:一般前端开发后会将打包后的dist文件交由我们部署,部署的方式有很多,这里提供一种思路 在服务器的路径下新建一个目录,在目录中新建Dockerfile,编辑这个文件 FROM nginxCOPY ./dist /home/front COPY nginx.con…...
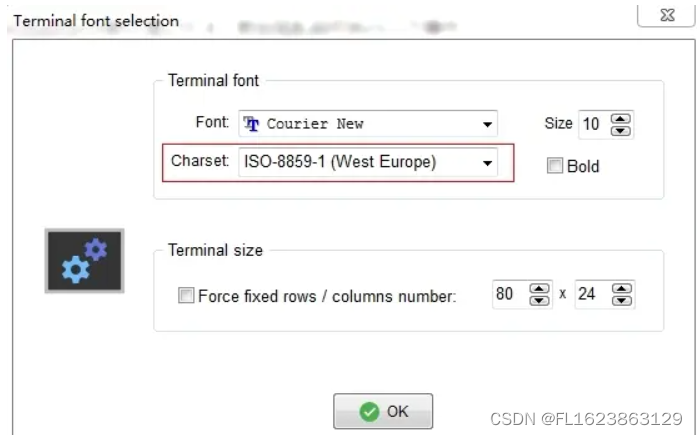
[技术杂谈]MobaXterm中文乱码编码问题一种解决方法
今日使用mobaxterm连接树莓派发现安装出现乱码,看不清文字是什么。最最简单方式是ssh设置终端字体,具体步骤为: 1. 右键会话,点击编辑会话 2.在以下画面点击终端字体设置 3.选择编码:GBK或者ISO-8859-1...

mac os M1 安装并启动 postgreSQL 的问题
Homebrew 安装 postgreSQL brew install postgresql启动 brew services start postgresql但报错: uninitialized constant Homebrew::Service::System解决方案 brew doctor按照 brew doctor 中的建议进行操作,如果不行,如下: h…...

如何使用Wireshark进行网络流量分析?
如何使用Wireshark进行网络流量分析。Wireshark是一款强大的网络协议分析工具,可以帮助我们深入了解网络通信和数据流动。 1. 什么是Wireshark? Wireshark是一个开源的网络协议分析工具,它可以捕获并分析网络数据包,帮助用户深入…...

抖音web主页视频爬虫
需要抖音主页视频爬虫源码的发私信,小偿即可获得长期有效的采集程序。 比构造 s_v_web_id 验证滑块的方法更快,更稳定。...

Kimi-VL-A3B-Thinking作品分享:OCR识别模糊手写体+公式识别+LaTeX自动转换
Kimi-VL-A3B-Thinking作品分享:OCR识别模糊手写体公式识别LaTeX自动转换 1. 引言:当AI能看懂你的草稿纸 想象一下,你有一张拍得有点模糊的会议白板照片,上面潦草地写满了讨论要点和几个复杂的数学公式。或者,你翻出一…...
)
工业设计必看:SolidWorks曲面建模中的NURBS核心原理与7个避坑指南(2024版)
工业设计进阶:SolidWorks曲面建模中的NURBS核心原理与高阶实践(2024版) 在汽车外壳的流线型曲面或消费电子产品的有机形态背后,NURBS(非均匀有理B样条)技术始终是工业设计软件的核心引擎。作为SolidWorks等…...
Pixel Dream Workshop 作品集:基于LSTM时序模型生成的动态艺术画展示
Pixel Dream Workshop 作品集:基于LSTM时序模型生成的动态艺术画展示 1. 当AI遇见艺术:LSTM如何创造动态视觉叙事 在数字艺术创作领域,时序模型正带来一场革命性的变化。Pixel Dream Workshop最新推出的动态艺术画系列,展示了长…...

Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取
Phi-3-mini-128k-instruct实战案例:中小企业技术文档自动解析与结构化提取 1. 项目背景与价值 对于中小企业而言,技术文档管理一直是个令人头疼的问题。工程师们经常需要从大量PDF、Word文档中提取关键信息,手动整理成结构化数据。这个过程…...

RTX4090D显存优化:OpenClaw长文本处理实测Qwen3-32B性能
RTX4090D显存优化:OpenClaw长文本处理实测Qwen3-32B性能 1. 测试背景与实验设计 去年我在处理学术论文时,经常遇到需要分析几十页PDF的情况。传统工具要么截断文本,要么丢失关键上下文。当我发现OpenClaw支持本地部署大模型后,立…...

B站视频下载终极指南:DownKyi高效工具完整使用教程
B站视频下载终极指南:DownKyi高效工具完整使用教程 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

告别模糊概念:用ESP32 iperf例程和电脑热点,5分钟搞定无线模块压力测试
5分钟极简方案:用ESP32和电脑热点构建无线性能测试环境 在嵌入式开发中,无线模块的性能测试往往需要复杂的网络环境支持。但现实情况是,大多数开发者并不具备专业的测试设备或实验室环境。想象一下这样的场景:你正在咖啡厅调试一个…...

本地图片检索新方案:ImageSearch完全使用指南
本地图片检索新方案:ImageSearch完全使用指南 【免费下载链接】ImageSearch 基于.NET8的本地硬盘千万级图库以图搜图案例Demo和图片exif信息移除小工具分享 项目地址: https://gitcode.com/gh_mirrors/im/ImageSearch 当你的电脑中存储了成千上万张图片&…...
的滑窗架构与并行判决实现)
FPGA商用级ISP:动态坏点校正(DPCC)的滑窗架构与并行判决实现
【写在前面:为什么要写这个专栏?】在数字图像处理领域,ISP(图像信号处理器)的算法原理并不罕见,但真正能够支持 4K60fps 实时处理、并经过商用验证的 Verilog 硬核实现思路 却往往秘和封装在黑盒之中。我手…...

RGBLEDBlender:嵌入式RGB LED色彩混合与动态控制框架
1. RGBLEDBlender 库深度解析:面向嵌入式系统的 RGB 色彩混合与动态控制框架RGBLEDBlender 是一个轻量级、面向硬件的 RGB LED 色彩混合库,专为资源受限的微控制器平台(尤其是 Arduino 生态)设计。该库由 Erik Sikich 于 2016 年 …...