unet pytorch
1.单机多卡版本:代码中的DistributedDataParallel (DDP) 部分对应单机多卡的分布式训练方式
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import RandomHorizontalFlip, RandomVerticalFlip, RandomRotation, RandomResizedCrop, ToTensor
from torch.nn.parallel import DistributedDataParallel as DDP# 定义ResNet块
class ResNetBlock(nn.Module):def __init__(self, in_channels, out_channels):super(ResNetBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):residual = xout = self.conv1(x)out = self.relu(out)out = self.conv2(out)out += residualout = self.relu(out)return out# 定义UNet模型
class UNet(nn.Module):def __init__(self, in_channels, out_channels):super(UNet, self).__init__()self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3, padding=1)self.block1 = ResNetBlock(64, 64)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.block2 = ResNetBlock(128, 128)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.block3 = ResNetBlock(256, 256)self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.Conv2d(256, 512, kernel_size=3, padding=1self.block4 = ResNetBlock(512, 512)self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.conv5 = nn.Conv2d(128, out_channels, kernel_size=1)def forward(self, x):x1 = self.conv1(x)x1 = self.block1(x1)x2 = self.pool1(x1)x2 = self.conv2(x2)x2 = self.block2(x2)x3 = self.pool2(x2)x3 = self.conv3(x3)x3 = self.block3(x3)x4 = self.pool3(x3)x4 = self.conv4(x4)x4 = self.block4(x4)x = self.upconv3(x4)x = torch.cat((x, x3), dim=1)x = self.conv5(x)x = self.upconv2(x)x = torch.cat((x, x2), dim=1)x = self.upconv1(x)x = torch.cat((x, x1), dim=1)x = self.conv5(x)return x# 定义数据集类
class CustomDataset(Dataset):def __init__(self, data_dir, transform=None):self.data = # Load data from data_dirself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):image, mask = self.data[index]if self.transform:image = self.transform(image)mask = self.transform(mask)return image, mask# 设置训练参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_epochs = 10
batch_size = 4# 创建UNet模型和优化器
model = UNet(in_channels=3, num_classes=2).to(device)
model = DDP(model)optimizer = optim.Adam(model.parameters(), lr=0.001)# 定义数据增强方法
transform = transforms.Compose([RandomHorizontalFlip(),RandomVerticalFlip(),RandomRotation(15),RandomResizedCrop(256, scale=(0.8, 1.0)),ToTensor(),
])# 加载数据集并进行数据增强
dataset = CustomDataset(data_dir="path_to_dataset", transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)# 训练循环
for epoch in range(num_epochs):model.train()total_loss = 0.0for images, masks in dataloader:images = images.to(device)masks = masks.to(device)optimizer.zero_grad()outputs = model(images)loss = nn.CrossEntropyLoss()(outputs, masks)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(dataloader)}")
2.多机多卡版本:使用torch.utils.data.distributed.DistributedSampler和torch.distributed.init_process_group来实现多机多卡的分布式训练,确保在每个进程中都有不同的数据划分和完整的通信。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.nn.parallel import DistributedDataParallel
from torchvision.transforms import transforms
from torchvision.datasets import YourDataset
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist# 定义ResNet块
class ResNetBlock(nn.Module):def __init__(self, in_channels, out_channels):super(ResNetBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):residual = xout = self.conv1(x)out = self.relu(out)out = self.conv2(out)out += residualout = self.relu(out)return out# 定义UNet模型
class UNet(nn.Module):def __init__(self, in_channels, out_channels):super(UNet, self).__init__()self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3, padding=1)self.block1 = ResNetBlock(64, 64)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.block2 = ResNetBlock(128, 128)self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)self.block3 = ResNetBlock(256, 256)self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv4 = nn.Conv2d(256, 512, kernel_size=3, padding=1self.block4 = ResNetBlock(512, 512)self.upconv3 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)self.upconv2 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)self.upconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)self.conv5 = nn.Conv2d(128, out_channels, kernel_size=1)def forward(self, x):x1 = self.conv1(x)x1 = self.block1(x1)x2 = self.pool1(x1)x2 = self.conv2(x2)x2 = self.block2(x2)x3 = self.pool2(x2)x3 = self.conv3(x3)x3 = self.block3(x3)x4 = self.pool3(x3)x4 = self.conv4(x4)x4 = self.block4(x4)x = self.upconv3(x4)x = torch.cat((x, x3), dim=1)x = self.conv5(x)x = self.upconv2(x)x = torch.cat((x, x2), dim=1)x = self.upconv1(x)x = torch.cat((x, x1), dim=1)x = self.conv5(x)return x# 定义数据集类
class CustomDataset(Dataset):def __init__(self, data_dir, transform=None):self.data = # Load data from data_dirself.transform = transformdef __len__(self):return len(self.data)def __getitem__(self, index):image, mask = self.data[index]if self.transform:image = self.transform(image)mask = self.transform(mask)return image, maskdef main(rank, world_size):# 设置分布式训练参数torch.cuda.set_device(rank)torch.distributed.init_process_group(backend='nccl', init_method='env://', world_size=world_size, rank=rank)# 设置训练参数num_epochs = 10batch_size_per_gpu = 4# 创建UNet模型和优化器in_channels = 3model = UNet(in_channels=3, num_classes=2).cuda(rank)model = DistributedDataParallel(model, device_ids=[rank])optimizer = optim.Adam(model.parameters(), lr=0.001)# 数据增强方法transform = transforms.Compose([transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(30),transforms.RandomResizedCrop(256, scale=(0.8, 1.2)),transforms.ToTensor()])# 加载训练集和验证集train_dataset = CustomDataset(transform=transform)train_sampler = DistributedSampler(train_dataset)train_loader = DataLoader(train_dataset, batch_size=batch_size_per_gpu, sampler=train_sampler)# 训练循环for epoch in range(num_epochs):model.train()total_loss = 0.0for images, masks in train_loader:images = images.cuda(rank)masks = masks.cuda(rank)# 执行前向传播和反向传播optimizer.zero_grad()outputs = model(images)loss = F.binary_cross_entropy_with_logits(outputs, masks)loss.backward()optimizer.step()total_loss += loss.item()if world_size > 1:torch.distributed.all_reduce(total_loss)total_loss /= len(train_sampler)print(f"Epoch {epoch + 1}/{num_epochs}, Loss: {total_loss:.4f}")def main_multi_gpu():world_size = torch.cuda.device_count()if world_size > 1:torch.multiprocessing.spawn(main, args=(world_size,), nprocs=world_size, join=True)else:main(0, 1)if __name__ == '__main__':main_multi_gpu()
相关文章:

unet pytorch
1.单机多卡版本:代码中的DistributedDataParallel (DDP) 部分对应单机多卡的分布式训练方式 import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from torchvisi…...
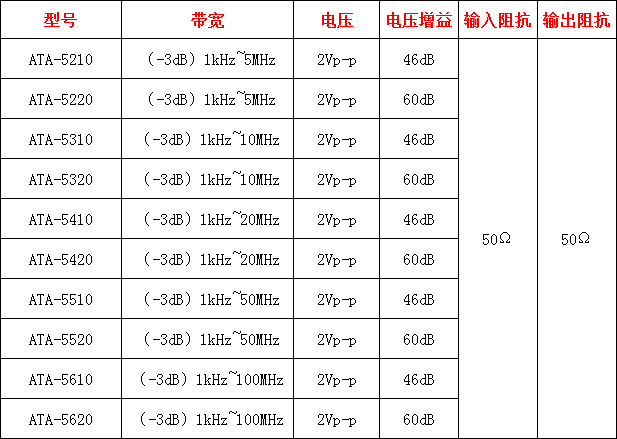
前置微小信号放大器的作用是什么
前置微小信号放大器是一种电子设备,用于将弱信号放大到足够的水平以供后续处理。它在许多领域都有广泛的应用,如通信系统、无线电接收机、传感器接口等。 前置微小信号放大器的主要作用是增加信号的强度。当我们处理微弱信号时,如果不进行放大…...
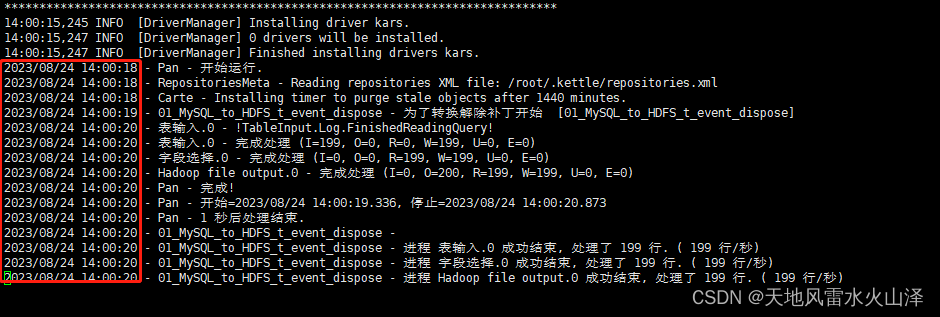
一百六十五、Kettle——用海豚调度器调度Linux资源库中的kettle任务脚本(亲测、附流程截图)
一、目的 在Linux上脚本运行kettle的转换任务、无论是Linux本地还是Linux资源库都成功后,接下来就是用海豚调度Linux上kettle任务 尤其是团队开发中,基本都要使用共享资源库,所以我直接使用海豚调度Linux资源库的kettle任务脚本 二、前提条…...

xfs ext4 结合lvm 扩容、缩容 —— 筑梦之路
ext4 文件系统扩容、缩容操作 扩容系统根分区 根文件系统在 /dev/VolGroup/lv_root 逻辑卷上,文件系统类型为ext4,大小为10G,现在要将其扩容成20G。 给空闲空间分区# 调整分区类型为LVM,也就是8e类型 fdisk /dev/sdb# 选定分区后使…...
)
如何修改由 img 标签引入的 svg 图片颜色 (react环境)
网上试了好几个方法都不行,问了一下身边同事的处理方法,终于搞定了。话不多说,直接上代码: 此处是 jsx 中的图标引入 <img className{STYLE.contactIcon}onClick{() > {你的一些操作}} style{{WebkitMaskImage: url(${ite…...
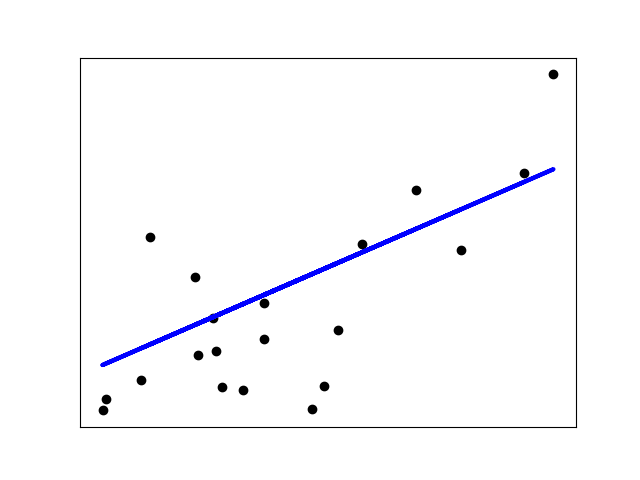
归一化的作用,sklearn 安装
目录 归一化的作用: 应用场景说明 sklearn 准备工作 sklearn 安装 sklearn 上手 线性回归实战 归一化的作用: 归一化后加快了梯度下降求最优解的速度; 归一化有可能提高精度(如KNN) 应用场景说明 1)概率模型不需要归一化ÿ…...

半导体企业如何进行跨网数据传输,又能保护核心数据安全?
为了保护设计文档、代码文件等内部核心数据,集成电路半导体企业一般会将内部隔离成多个网络,比如研发网、办公网、生产网、测试网等。常规采取的网络隔离手段如下: 1、云桌面隔离:一方面实现数据不落地,终端数据安全有…...
lvs-DR模式:
lvs-DR数据包流向分析 客户端发送请求到 Director Server(负载均衡器),请求的数据报文(源 IP 是 CIP,目标 IP 是 VIP)到达内核空间。 Director Server 和 Real Server 在同一个网络中,数据通过二层数据链路…...
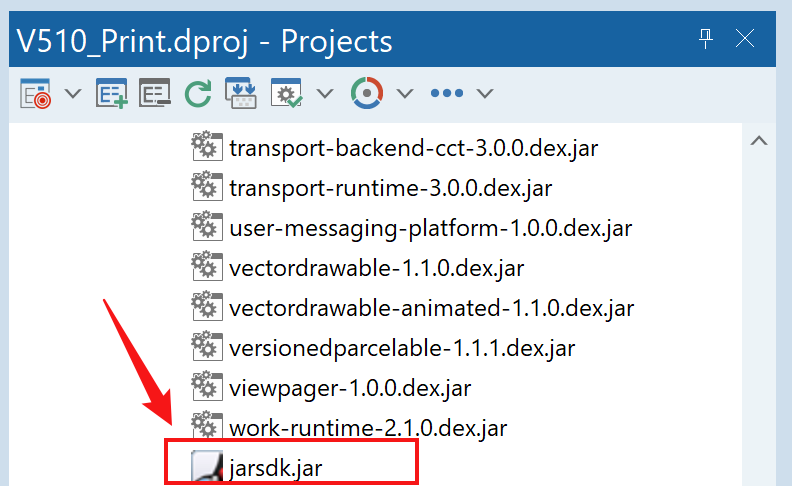
Delphi 开发手持机(android)打印机通用开发流程(举一反三)
目录 一、场景说明 二、厂家应提供的SDK文件 三、操作步骤: 1. 导出Delphi需要且能使用的接口文件: 2. 创建FMX Delphi项目,将上一步生成的接口文件(V510.Interfaces.pas)引入: 3. 将jarsdk.jar 包加入到 libs中…...

nodejs替换模版中${}的内容
要在js中想要替换替换模板中的${},可以使用字符串的replace()方法结合正则表达式或者函数来实现替换操作。 以下是两种常见的替换方式: 使用正则表达式: 方法一: const template "Hello, ${name}! Today is ${day}."…...
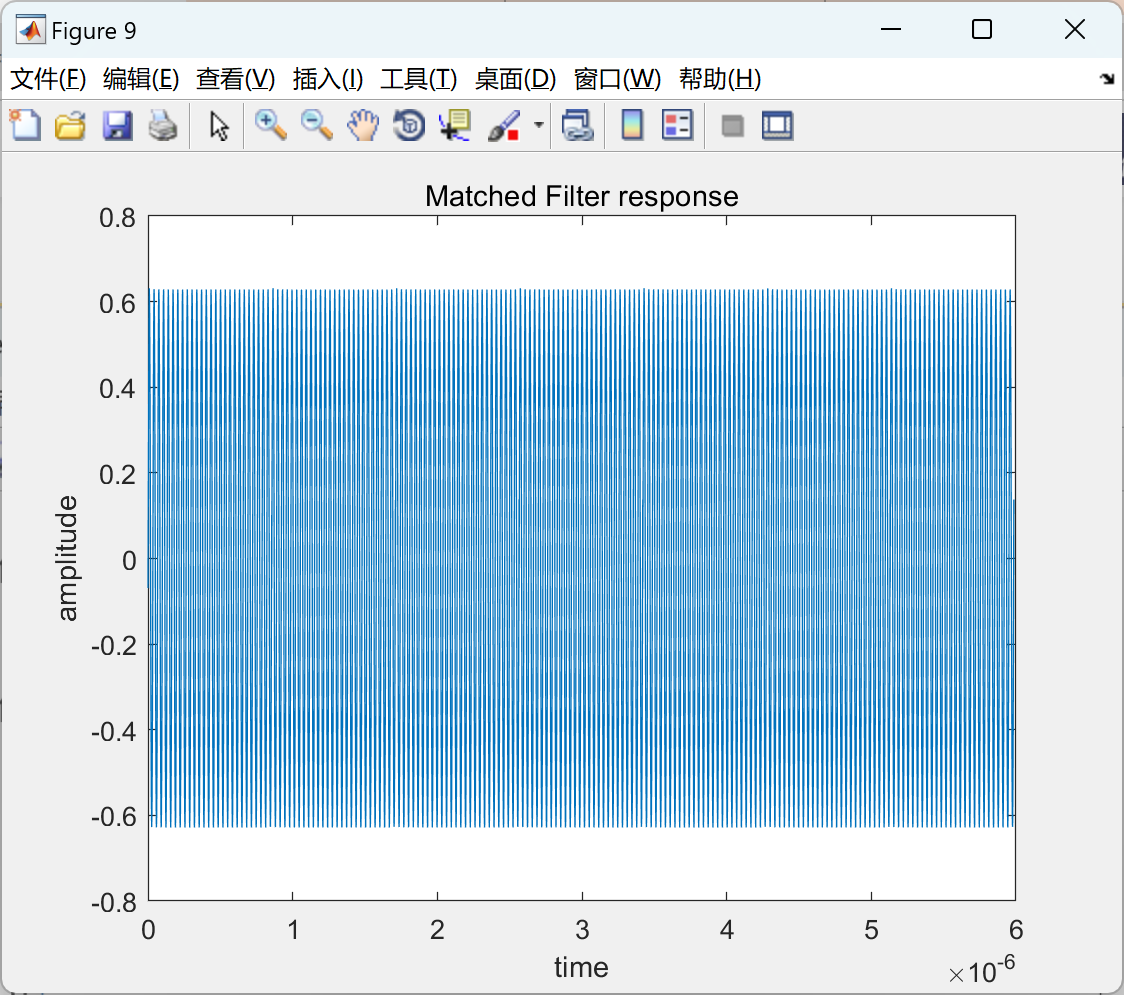
【快速傅里叶变换(fft)和逆快速傅里叶变换】生成雷达接收到的经过多普勒频移的脉冲雷达信号(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
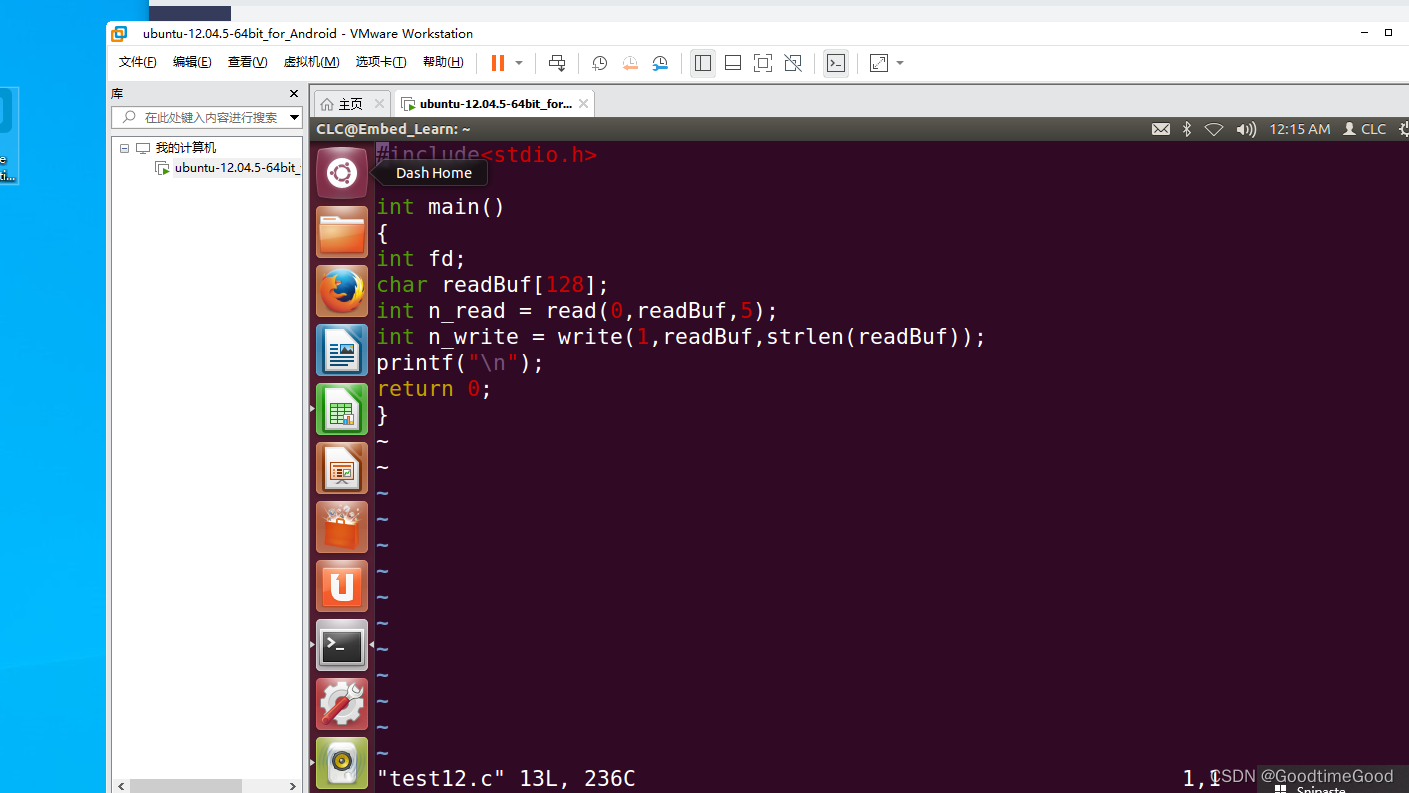
嵌入式学习之linux
今天,主要对linux文件操作原理进行了学习,主要学习的内容就是对linux文件操作原理进行理解。写的代码如下:...

自动驾驶合成数据科普一:不做真实数据的“颠覆者”,做“杠杆”
前言: 在7月底的一篇文章中,九章智驾提到,数据闭环能力是自动驾驶下半场的“入场券”,这一观点在行业内引起了广泛共鸣。 在数据闭环体系中,仿真技术无疑是非常关键的一环。仿真的起点是数据,而数据又分为真…...
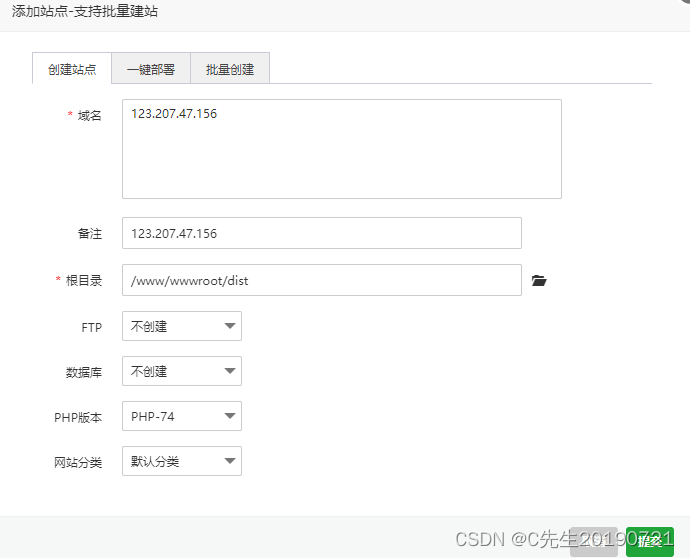
云服务器 宝塔(每次更新)
su root 输入密码 使用 root 权限 /etc/init.d/bt default 获取宝塔登录 位置和账号密码。进入宝塔 删除数据库 删除php前端站点 删除PM2后端项目 前端更改完配置打包dist文件 后端更改完配置项目打包 数据库结构导出 导入数据库 配置 PM2 后端 安装依赖...
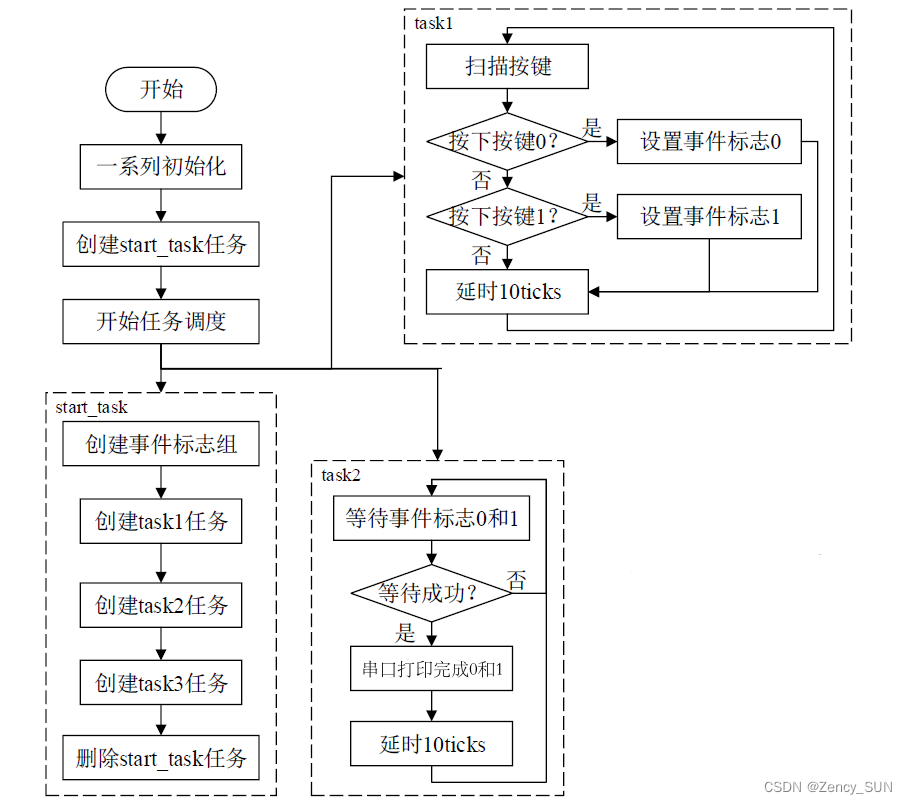
【学习FreeRTOS】第16章——FreeRTOS事件标志组
1.事件标志组简介 事件标志位:用一个位,来表示事件是否发生 事件标志组是一组事件标志位的集合, 可以简单的理解事件标志组,就是一个整数。 事件标志组的特点: 它的每一个位表示一个事件(高8位不算&…...

Echarts 柱状图的 itemStyle的normal中label如何format?
在 Echarts 中,可以通过设置 formatter 属性来对柱状图的标签进行自定义格式化。例如: itemStyle: {normal: {label: {show: true,formatter: function(params) {return params.value.toFixed(2); // 将标签内容保留两位小数}}} } 在上面的例子中&…...

我的笔记:数据体系规则
1、中台数据体系特征 覆盖全域数据:数据集中建设,覆盖所有业务过程数据; 结构层次清晰:纵向数据分层,横向主题域,业务过程划分,让整个层析结构清晰易理解; 数据准确一致:…...

苍穹外卖 day2 反向代理和负载均衡
一 前端发送的请求,是如何请求到后端服务 前端请求地址:http://localhost/api/employee/login 路径并不匹配 后端接口地址:http://localhost:8080/admin/employee/login 二 查找前端接口 在这个页面上点击f12 后转到networ验证࿰…...

【SpringBoot】SpringBoot完整实现电子商务系统
一个完整的电子商务系统需要涉及到前台展示、后台管理、商品管理、订单管理、用户管理等各方面。这里提供一个简单的实现示例,供参考。 前端代码 前端使用Vue框架,以下是部分代码示例: 商品列表页: <template><div>…...
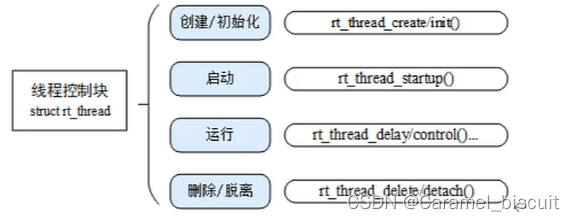
RT-Thread 线程管理(学习二)
线程相关操作 线程相关的操作包括:创建/初始化、启动、运行、删除/脱离。 动态线程与静态线程的区别:动态线程是系统自动从动态内存堆上分配栈空间与线程句柄(初始化heap之后才能使用create创建动态线程),静态线程是…...
)
从串行通信到SerDes:深入聊聊CDR电路的那些‘辅助’设计(频率捕获篇)
从串行通信到SerDes:深入解析CDR电路中的频率捕获设计 在高速串行通信系统中,时钟和数据恢复(CDR)电路扮演着至关重要的角色。当数据速率突破10Gbps甚至更高时,传统的锁相环(PLL)设计面临着前所未有的挑战——如何在随机数据流中快速准确地锁…...

数据结构:3.包装类和泛型
【目标】1.了解包装类 2. 以 能阅读java集合源码 为目标学习泛型3.了解泛型1.包装类(Wrapper Class)1.1 引出包装类1.1.1 什么是包装类?一句话: 包装类就是把 Java 的 8 种基本数据类型(int, double, char 等&a…...

福田区全栈式鸿蒙AI数智机关入选全市首批OR示范应用项目,深开鸿筑牢政务安全底座
5月13日,在第五次深圳市OR大会暨软信投促大会上,福田区机关事务管理局申报的全栈式鸿蒙AI数智机关,作为全市首批OR示范应用项目亮相,让区委大院成为备受瞩目的“实景展厅”,吸引了24家企业组团实地调研。作为目前在复合…...

5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能
5分钟快速上手:Parsec VDD虚拟显示器完整指南,彻底释放游戏串流潜能 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 想要在没有物理显示器的情况下畅享4K游…...

从星座图乱麻到清晰:手把手教你用OpenOFDM搞定Wi-Fi信号频偏校正
从星座图乱麻到清晰:手把手教你用OpenOFDM搞定Wi-Fi信号频偏校正 当你第一次用软件无线电(SDR)捕获Wi-Fi信号时,看到的星座图像是被猫抓过的毛线团——杂乱无章的斑点毫无规律地散布在平面上。这种令人沮丧的场景,正是…...

TI IWR6843ISK-ODS雷达固件开发环境搭建:从MATLAB Runtime到CCS的保姆级避坑指南
TI IWR6843ISK-ODS雷达固件开发环境搭建实战手册 毫米波雷达技术正在智能感知领域掀起革命浪潮,而德州仪器(TI)的IWR6843ISK-ODS评估板因其出色的集成度和性价比,成为众多开发者进入这一领域的首选平台。然而,从硬件拆封到第一个雷达点云成功…...

如何快速掌握JavaQuestPlayer:一站式QSP游戏开发与运行的终极指南
如何快速掌握JavaQuestPlayer:一站式QSP游戏开发与运行的终极指南 【免费下载链接】JavaQuestPlayer 项目地址: https://gitcode.com/gh_mirrors/ja/JavaQuestPlayer 还在为QSP游戏的兼容性和开发效率问题而烦恼吗?JavaQuestPlayer作为一款基于J…...

别再被CAPL路径搞懵了!getAbsFilePath、setFilePath这几个函数到底怎么用?
CAPL文件路径操作全解析:从函数原理到实战避坑指南 在CANoe自动化测试开发中,文件路径操作堪称最基础却又最容易出错的环节之一。许多工程师都经历过这样的场景:精心编写的CAPL脚本在本地测试一切正常,换到同事电脑上却频频报错&a…...

Onyx Core API完全手册:RESTful接口详解与实战案例
Onyx Core API完全手册:RESTful接口详解与实战案例 【免费下载链接】Onyx Onyx 项目地址: https://gitcode.com/gh_mirrors/ony/Onyx Onyx Core是一个强大的企业级区块链平台,提供完整的RESTful API接口,让开发者能够轻松构建和管理区…...

如何通过智能菜单栏管理让Mac界面焕然一新:Hidden Bar深度使用指南
如何通过智能菜单栏管理让Mac界面焕然一新:Hidden Bar深度使用指南 【免费下载链接】hidden An ultra-light MacOS utility that helps hide menu bar icons 项目地址: https://gitcode.com/gh_mirrors/hi/hidden 在macOS系统中,菜单栏图标堆积是…...