pytest数据驱动

文章目录
- 一、数据驱动概念
- 二、数据驱动yaml
- 1、yaml的基本语法:
- 2、yaml支持的数据格式:
- 3、安装
- 4、使用
- 5、读取方法
- a、目录结构
- b、yaml文件
- c、测试方法
- d、测试用例
- e、测试结果
- 三、数据驱动excel
- 1、安装导入
- 2、操作
- 3、读取方法
- a、目录结构
- b、excel文件
- c、测试方法
- d、测试用例
- e、测试结果
- 四、数据驱动csv
- 1、读取数据
- 2、方法
- a、目录结构
- b、csv文件
- c、测试方法
- d、测试用例
- e、测试结果
- 五、数据驱动json
- 1、json格式:
- 2、读取json文件
- a、目录结构
- b、json文件
- c、测试方法
- d、测试用例
- e、测试结果
一、数据驱动概念
数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。简单来说,就是参数化的应用。数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况下建议大家使用一种结构化的文件(例如yaml,json,csv、excel等)来对数据进行存储,然后在测试用例中读取这些数据。
二、数据驱动yaml
yaml是一种数据序列化格式,用于人类的可读性和与脚本语言的交互,一种被认为超越XML、json的配置文件。
1、yaml的基本语法:
大小写敏感
使用缩进标识层级关系
缩进时不允许使用tab键,只允许使用空格
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
#表示注释,从这个字符一直到行尾,都会被解析器忽略
2、yaml支持的数据格式:
对象(字典):键值对的集合,用冒号“:”表示
数组(列表):一组按次序排列的值,前加“-”
纯量:单个的、不可再分的值
字符串
布尔值
整数
浮点数
Null
时间
日期
3、安装
pip install pyyaml
4、使用
datas:测试数据
func:测试方法
testcases:测试用例
5、读取方法
yaml.safe_load(file)
a、目录结构

b、yaml文件
# [[1,1,2],[3,6,9],[100,200,300]]
-- 1- 1- 3
-- 3- 6- 9
-- 100- 200- 300
c、测试方法
#被测方法,相加功能
def my_add3(x, y):result = x + yreturn result
d、测试用例
文件或者目录不可以创建为yaml关键字
import pytest
from testing_data.func.operation_yaml import my_add#用到yaml文件中的数据时,就需要读取出来# pip install pyyaml
#todo 文件或者目录不可以创建为yaml关键字
import yamldef get_data():#如果yaml文件有中文,必须加上excoding='utf-8'with open('../datas/data.yaml',encoding='utf-8') as f:data=yaml.safe_load(f)return dataclass TestWithYAML:@pytest.mark.parametrize('x,y,expected',get_data())def test_add(self, x, y, expected):assert my_add(int(x), int(y)) == int(expected)
e、测试结果
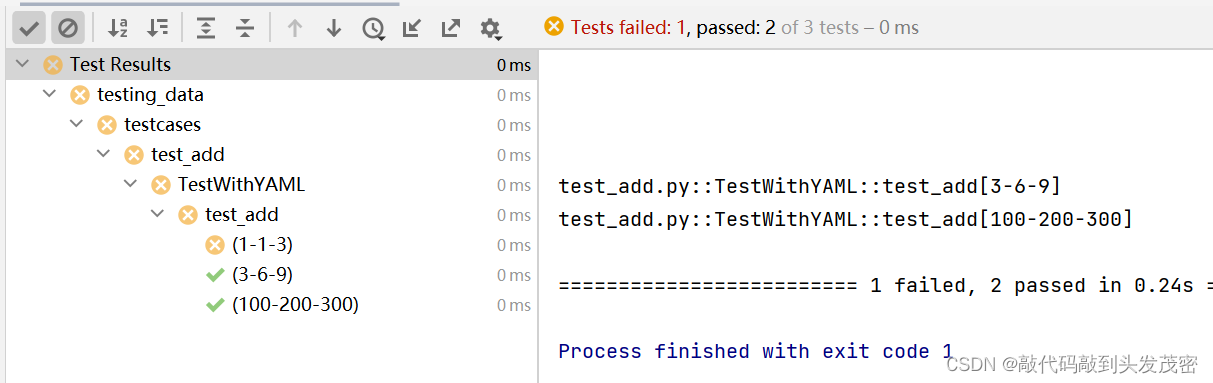
三、数据驱动excel
1、安装导入
pip install openpyxl
import openpyxl
2、操作
读取工作簿
读取工作表
读取单元格
3、读取方法
book=openpyxl.load_workbook(‘文件路径’) :读取工作簿
sheet=book.active :读取工作表
cells=sheet[‘A1’:‘C3’]
cell.value :读取数据
a、目录结构
b、excel文件
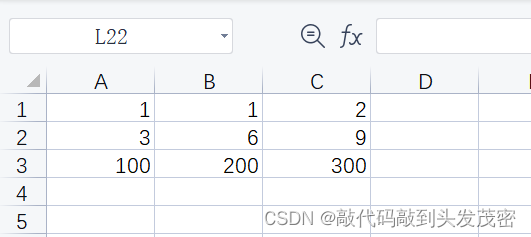
c、测试方法
#被测方法,相加功能
def my_add1(x, y):result = x + yreturn result
d、测试用例
import openpyxl
import pytest
from testing_data.func.operation_excel import my_add1#用到excel文件中的数据时,就需要读取出来def test_get_excel():"""解析Excel数据:return: [[1,1,2],[3,6,9],[100,200,300]]"""#获取工作簿book=openpyxl.load_workbook('../datas/data.xlsx')#获取工作表sheet1sheet=book.active#读取数据cells=sheet['A1':'C3']print(cells)values=[]for row in cells:data=[]for cell in row:data.append(cell.value)values.append(data)print(values)return valuesclass TestWithEXCEL:@pytest.mark.parametrize('x,y,expected',test_get_excel(),ids=[1,2,3])def test_add1(self, x, y, expected):assert my_add1(int(x), int(y)) == int(expected)
e、测试结果
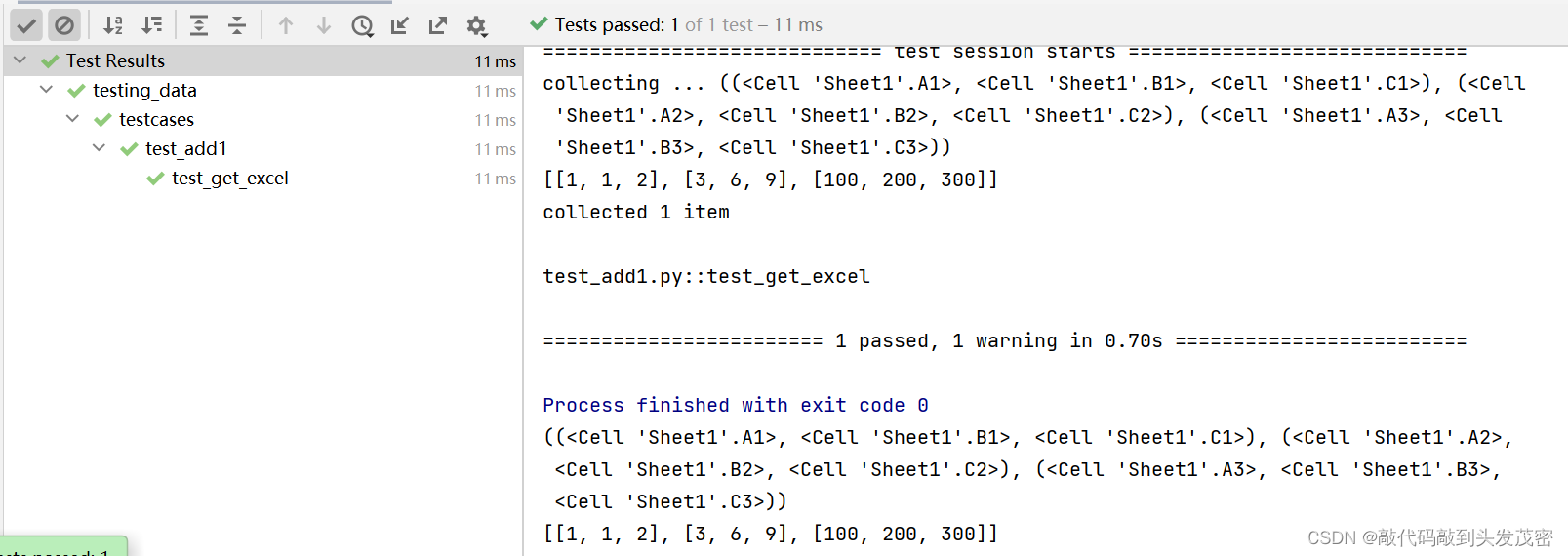
四、数据驱动csv
格式:逗号分隔值
以纯文本形式存储数字和文本
文件由任意数目的记录组成
每行记录由多个字段组成
1、读取数据
内置模块:import csv
2、方法
raw=csv.reader(iterable)
参数:iterable是一个可迭代对象;返回迭代器,每次迭代会返回一行数据
csv文件

读取csv文件
import csvdef get_csv():with open('demo.csv','r',encoding='utf-8') as file:raw=csv.reader(file)for line in raw:print(line)if __name__ == '__main__':get_csv()
读取结果:
['富强', '明主', '文明', '和谐']
['自由', '平等', '公正', '法制']
['爱国', '诚信', '敬业', '友善']
a、目录结构
b、csv文件
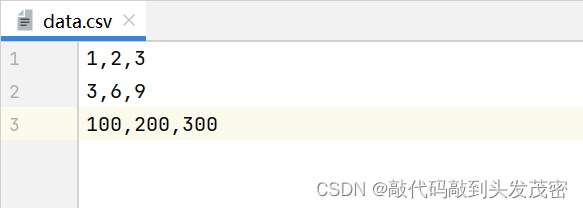
c、测试方法
#被测方法,相加功能
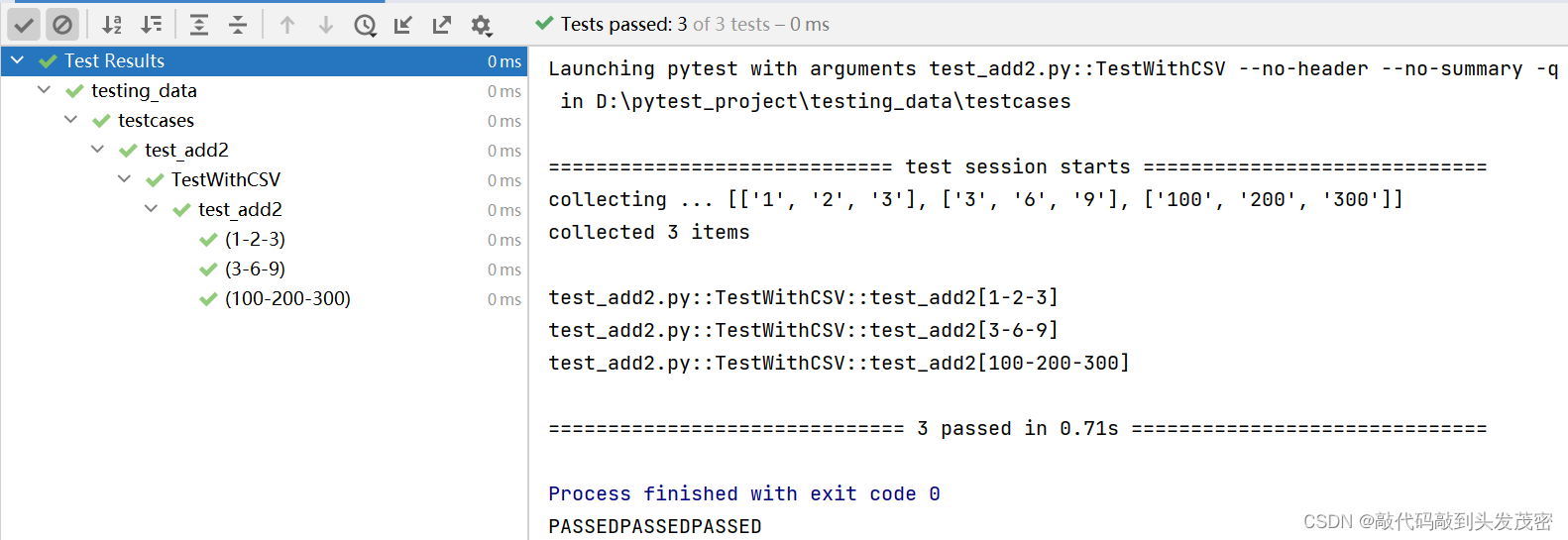
def my_add2(x, y):result = x + yreturn resultd、测试用例
import csvimport pytest
from testing_data.func.operation_csv import my_add2#用到csv文件中的数据时,就需要读取出来
def get_csv():"""读取csv文件中的数据:return: 格式:[[1,2,3],[3,6,9]]"""with open('../datas/data.csv','r',encoding='utf-8') as file:raw=csv.reader(file)data=[]for line in raw:data.append(line)print(data)return dataclass TestWithCSV:@pytest.mark.parametrize('x,y,expected',get_csv())def test_add2(self, x, y, expected):assert my_add2(int(x), int(y)) == int(expected)
e、测试结果
五、数据驱动json
1、json格式:
是一种轻量级的数据交换格式
以键值对的格式存储数据,多个键值用逗号分割
支持嵌套
支持数组(列表)
{"name:": "study ","detail": {"course": "python","city": "北京"},"remark": [1000,666,888]
}
2、读取json文件
内置库:
import json
内置方法
json.loads()
json.dumps()
import jsondef get_json():with open('demo.json','r',encoding='utf-8') as file:data=json.loads(file.read())print(data,type(data))data1=json.dumps(data, ensure_ascii=False)print(data1,type(data1))if __name__ == '__main__':get_json()
读取结果
{'name:': 'study ', 'detail': {'course': 'python', 'city': '北京'}, 'remark': [1000, 666, 888]} <class 'dict'>
{"name:": "study ", "detail": {"course": "python", "city": "北京"}, "remark": [1000, 666, 888]} <class 'str'>
a、目录结构
b、json文件
{"case1": [1, 1, 2],"case2": [3, 6, 9],"case3": [100, 200, 300]
}
c、测试方法
#被测方法,相加功能
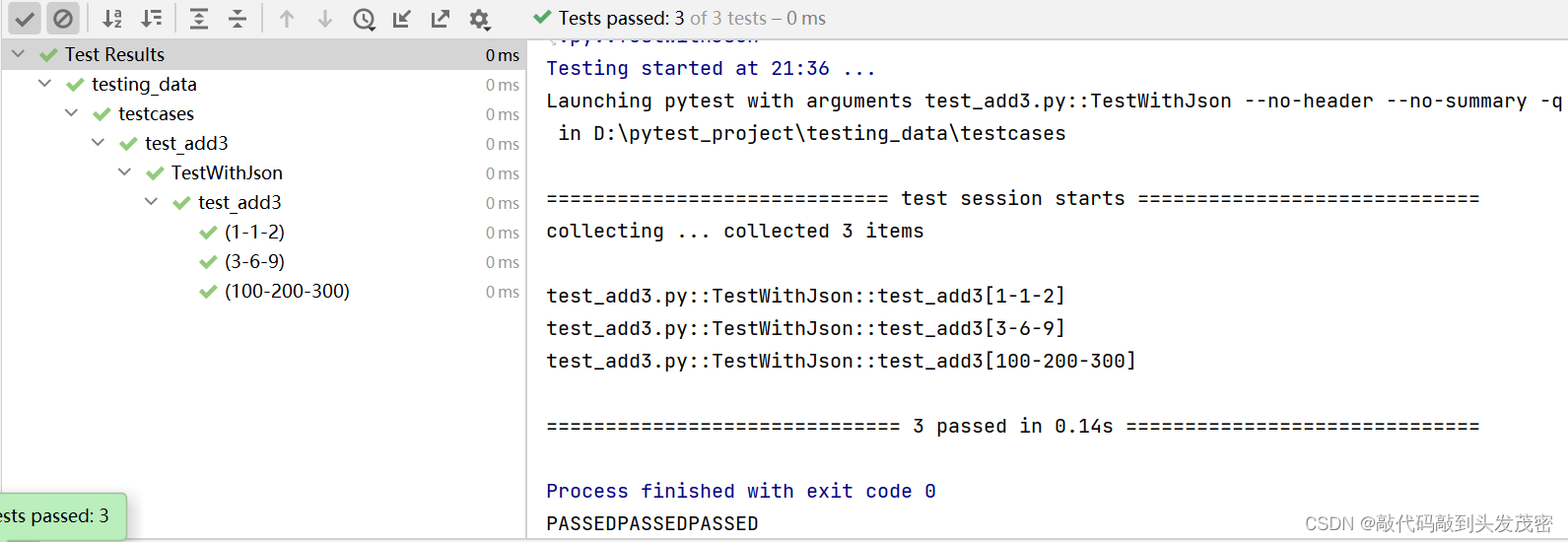
def my_add3(x, y):result = x + yreturn resultd、测试用例
import json
import pytest
from testing_data.func.operation_json import my_add3#用到json文件中的数据时,就需要读取出来
def get_json():"""读取json文件中的数据:return: 格式:[[1,2,3],[3,6,9]]"""with open('../datas/data.json','r',encoding='utf-8') as file:data=json.loads(file.read())data_values=data.values()return list(data_values)class TestWithJson:@pytest.mark.parametrize('x,y,expected',get_json())def test_add3(self, x, y, expected):assert my_add3(int(x), int(y)) == int(expected)
e、测试结果

相关文章:
pytest数据驱动
文章目录一、数据驱动概念二、数据驱动yaml1、yaml的基本语法:2、yaml支持的数据格式:3、安装4、使用5、读取方法a、目录结构b、yaml文件c、测试方法d、测试用例e、测试结果三、数据驱动excel1、安装导入2、操作3、读取方法a、目录结构b、excel文件c、测…...
OSI七层网络模型
应用层 定义了各种应用协议规范数据格式:HTTP协议、HTTPS协议、FTP协议、DNS协议、TFTP、SMTP等等。 表示层 翻译工作。提供一种公共语言、通信。 会话层 1、可以从校验点继续恢复数据进行重传。——大文件 2、自动收发,自动寻址的功能。 传输层 1、…...

易基因|MeRIP-seq揭示m6A RNA甲基化通过调控组蛋白泛素化来促进癌症生长和进展:Cancer Res
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。2022年05月16日,《Cancer Res》杂志发表了题为“M6A RNA Methylation Regulates Histone Ubiquitination to Support Cancer Growth and Progression”的研究论文,该…...

Java 日期处理踩过的坑
前言 整理Java日期处理遇到过的问题,希望对大家有帮助 制作不易,一键三连,谢谢大家。 1.用 Calendar 设置时间的坑 反例: //提供者模式获取实例Calendar calendar Calendar.getInstance();//获取当前时间Date currentDate c…...

一文吃透 Spring 中的IOC和DI(二)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
【期末指北】嵌入式系统——选择题(feat. ChatGPT)
作者|Rickyの水果摊 时间|2023年2月20日 基本信息 ☘️ 本博客摘录了一些 嵌入式系统 的 常见选择题,供有需求的同学们学习使用。 部分答案解析由 ChatGPT 生成,博主进行审核。 使用教材信息:《嵌入式系统设计与应…...
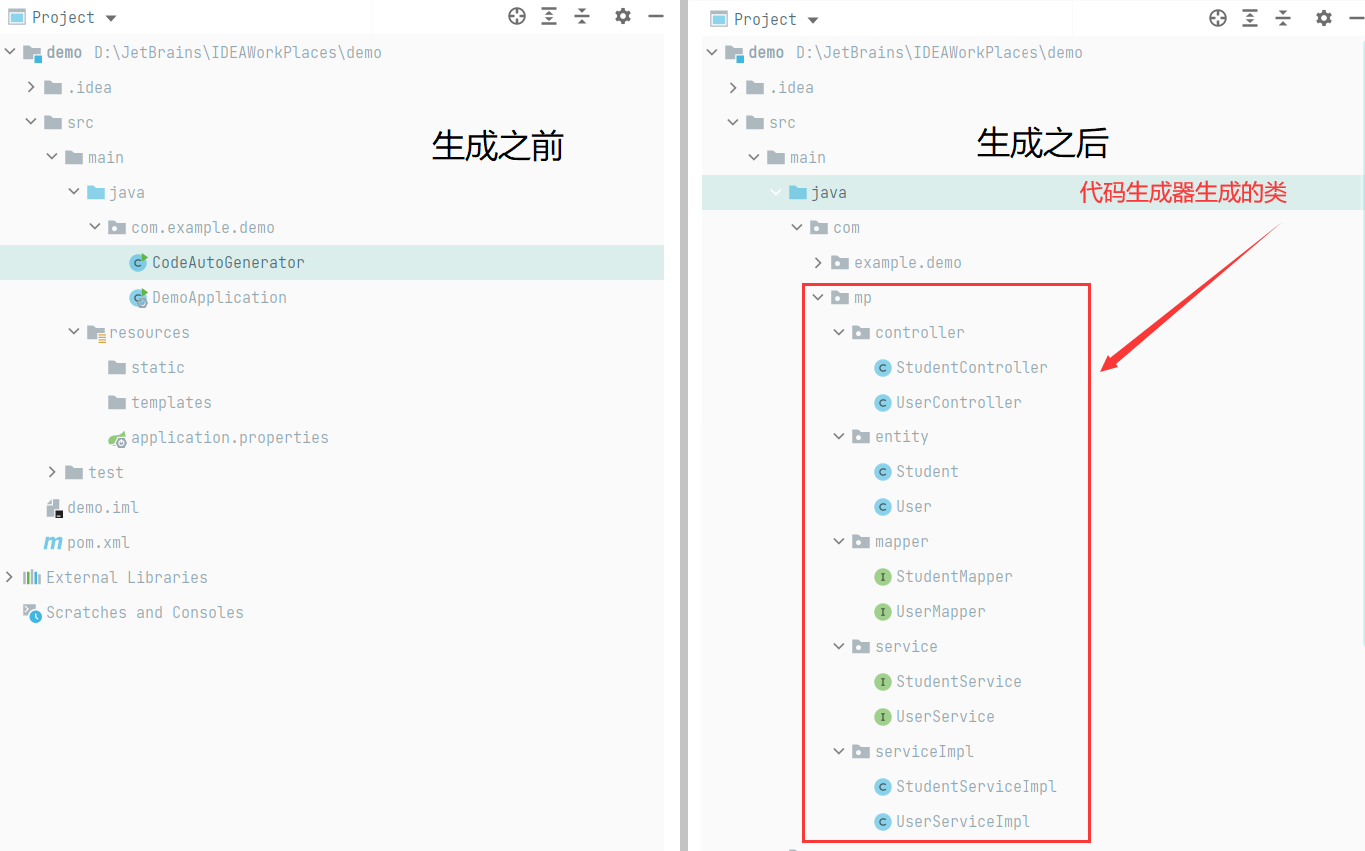
MyBatis-Plus——代码生成器(3.5.1+版本)
文章目录配置数据源配置(DataSource)全局配置(GlobalConfig)包配置(PackageConfig)策略配置(StrategyConfig)模板引擎配置(TemplateEngine)代码生成器测试样例…...

宁盾上榜第五版《CCSIP 2022 中国网络安全行业全景册》
2月1日,国内网络安全行业媒体Freebuf咨询正式发布《CCSIP(China Cyber Security Panorama)2022 中国网络安全行业全景册》第五版。宁盾作为国产身份安全厂商入驻身份识别和访问管理(SSO、OTP、IDaaS)及边界访问控制&am…...
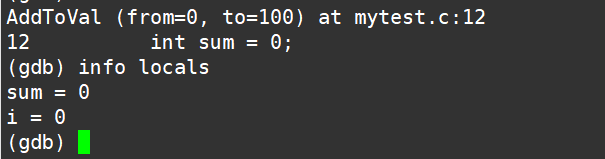
【Linux系统】第七篇:Linux调试器gdb的使用
文章目录一、gdb简介二、gdb的安装三、gdb使用3.1、release和debug版本3.2、gdb基本使用命令1、启动gdb2、调试命令3、显示代码(list)4、断点命令(breakpoint)5 、变量命令(variable)6、特殊调试命令7、调用…...

Shell 特殊变量及其含义
shell是我们在linux下编写自动执行程序的常见脚本工具,通常会涉及到以下几个特殊变量,它们分别是:$#、$*、$、$?、$$。 变量含义$0当前脚本的文件名。$n(n≥1)传递给脚本或函数的参数。n 是一个数字,表示…...

LeetCode 2396. 严格回文的数字
如果一个整数 n 在 b 进制下(b 为 2 到 n - 2 之间的所有整数)对应的字符串 全部 都是 回文的 ,那么我们称这个数 n 是 严格回文 的。 给你一个整数 n ,如果 n 是 严格回文 的,请返回 true ,否则返回 fals…...

【RocketMQ】源码详解:Broker启动流程
Broker启动 入口: org.apache.rocketmq.broker.BrokerStartup#main broker的启动主要分为两部分:1.创建brokerController 2.启动brokerController。与平时进行业务开发时不同的是,这里的BrokerController相当于Broker的一个中央控制器类&…...

vue事件
1. 事件传参 <button click"clickEvt($event, 22)">点我</button>2. 事件修饰符 prevent:阻止默认事件stop:阻止事件冒泡(加到子元素)once:事件只触发一次capture:使用事件的捕获模…...

研报精选230220
目录 【行业230220国信证券】银行业行业专题:经济复苏中的优质中小银行【行业230220国信证券】汽车行业周报(2023年第7周):吉利将发布新品牌“银河” ,2022年宇通纯电动客车获欧洲销量冠军【行业230220开源证券】商贸零…...

kubernetes sd configs配置详解
1.基于Kubernetes的服务发现 kubernetes_sd_config 这个是以角色(role)来定义收集的,Kubernetes SD配置允许从Kubernetes的RESTAPI中检索scrape目标,并始终与群集状态保持同步。 凡<role>必须是endpoints,service,pod&…...

Linux查看文件的命令
目录 1、tail 2、head 3、cat 4、more 5、sed 6、less Linux查看日志的命令有多种: tail、cat、tac、head、echo等,本文只介绍几种常用的方法。 1、tail 命令格式: tail[必要参数][选择参数][文件] -f 循环读取 -q 不显示处理信息 -v 显示详细的处理信…...
如何单独清除某个网页的缓存(reload)
有时候在自己服务器上调试的时候,刷新一直不更新,样式改了也看不到,就很烦 今天教你一个方法快速清除 F12 控制台情况下右击左上角的刷新 这三个分别代表: ①正常重新加载(Ctrl R): 正常重新加载 此方法,浏览器发送请求时会…...

魔兽世界经典怀旧服务器架设教程
准备工具:MySQL服务端服务器最重要的你需要会技术、要不然都瞎扯 给你东西你也看不懂。教程开始:安装MySQL并创建数据库安装MySQL社区版,并配置SQL服务器。安装SQLyog。利用其登录,创建realmd、characters、mangos、scriptdev2数据…...

Interview系列 - 05 Java|Iterator迭代器|集合继承体系|Set List Map接口特性|List实现类区别
文章目录01. 迭代器 Iterator 是什么?02. 迭代器 Iterator 有什么特点?03. 迭代器 Iterator 怎么使用?04. 如何边遍历边移除 Collection 中的元素?05. Iterator 和 ListIterator 有什么区别?06. 数组和集合的区别&…...

LeetCode 1769. 移动所有球到每个盒子所需的最小操作数
有 n 个盒子。给你一个长度为 n 的二进制字符串 boxes ,其中 boxes[i] 的值为 ‘0’ 表示第 i 个盒子是 空 的,而 boxes[i] 的值为 ‘1’ 表示盒子里有 一个 小球。 在一步操作中,你可以将 一个 小球从某个盒子移动到一个与之相邻的盒子中。…...

Java高频面试题:如何编写一个MyBatis插件?
大家好,我是锋哥。今天分享关于【Java高频面试题:如何编写一个MyBatis插件?】面试题 。希望对大家有帮助;Java高频面试题:如何编写一个MyBatis插件?编写一个 MyBatis 插件主要是通过实现 Interceptor 接口来…...

3个实战技巧:彻底解锁Cursor Pro功能的高效完整指南
3个实战技巧:彻底解锁Cursor Pro功能的高效完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

让业务人员直接“问“数据库:Spring AI Alibaba NL2SQL 实战指南
不用学 SQL,不用找开发排期,用大白话就能查数据——这不是未来,而是现在就能落地的方案。 一个真实的痛点 你是公司的运营负责人,想知道"上个月华东地区复购率最高的三个品类"。 在传统模式下,这个需求的链…...

重磅!GPT-6曝光了
就在刚刚,有知情人士爆料:GPT-6正在内测,预计4月16日正式发布。消息源头,是X平台上的科技大V 草莓哥iruletheworldmo。他说,最近OpenAI内部将有大动作,他从中搞到了不少猛料。草莓哥说了一些关键信息&#…...

金融数据接口实战指南:从基础认知到生态拓展
金融数据接口实战指南:从基础认知到生态拓展 【免费下载链接】akshare AKShare is an elegant and simple financial data interface library for Python, built for human beings! 开源财经数据接口库 项目地址: https://gitcode.com/gh_mirrors/aks/akshare …...

ComfyUI-Impact-Pack终极指南:5大AI图像增强功能完全解析
ComfyUI-Impact-Pack终极指南:5大AI图像增强功能完全解析 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https…...

SiameseAOE中文-base商业应用:本地化部署替代云API,年节省ABSA服务成本超70%
SiameseAOE中文-base商业应用:本地化部署替代云API,年节省ABSA服务成本超70% 1. 引言:从云端到本地,ABSA成本优化的新思路 如果你正在做电商评论分析、舆情监控或者产品调研,那你一定对“属性情感分析”不陌生。简单…...
)
保姆级教程:在Ubuntu 20.04上搞定Carla 0.9.13编译版安装(附国内镜像加速方案)
Ubuntu 20.04下Carla 0.9.13编译版全流程安装指南 最近在自动驾驶仿真领域,Carla作为开源仿真平台的热度持续攀升。但很多开发者在Ubuntu系统上安装Carla编译版时,总会遇到各种"拦路虎"——从Python版本冲突到资源下载失败,每一步…...

零售AI实战:Ostrakon-VL-8B应用案例,智能分析商品种类、数量与陈列效果
零售AI实战:Ostrakon-VL-8B应用案例,智能分析商品种类、数量与陈列效果 1. 零售视觉分析的挑战与机遇 在零售行业,商品陈列和库存管理是影响销售的关键因素。传统的人工巡检方式存在效率低、成本高、主观性强等问题。以一个中型超市为例&am…...

用OpenMV和麦克纳姆轮给智能车做个‘漂移外挂’:从循迹到横滑的代码改造实录
OpenMV与麦克纳姆轮智能车的可控漂移改造实战 当一台普通的循迹小车突然在弯道甩出漂亮的横滑轨迹,围观者的惊叹声往往比技术本身更早到达终点。本文将彻底拆解如何通过运动解算逻辑重构和视觉处理优化,将基础麦轮智能车升级为"赛道艺术家"的…...