【业务功能篇81】微服务SpringCloud-ElasticSearch-Kibanan-docke安装-入门实战

ElasticSearch
一、ElasticSearch概述
1.ElasticSearch介绍
ES 是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心。它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
ElasticSearch的底层是开源库Lucene,但是你没办法直接用Lucene,必须自己写代码去调用它的接口,Elastic是Lucene的封装,提供了REST API的操作接口,开箱即用。天然的跨平台。
全文检索是我们在实际项目开发中最常见的需求了,而ElasticSearch是目前全文检索引擎的首选,它可以快速的存储,搜索和分析海量的数据,维基百科,GitHub,Stack Overflow都采用了ElasticSearch。
官方网站:https://www.elastic.co/cn/elasticsearch/
中文社区:https://elasticsearch.cn/explore/
2.ElasticSearch用途
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型,非文本数据操作或安全事务处理的需求相对较少的情况。
3. ElasticSearch基本概念
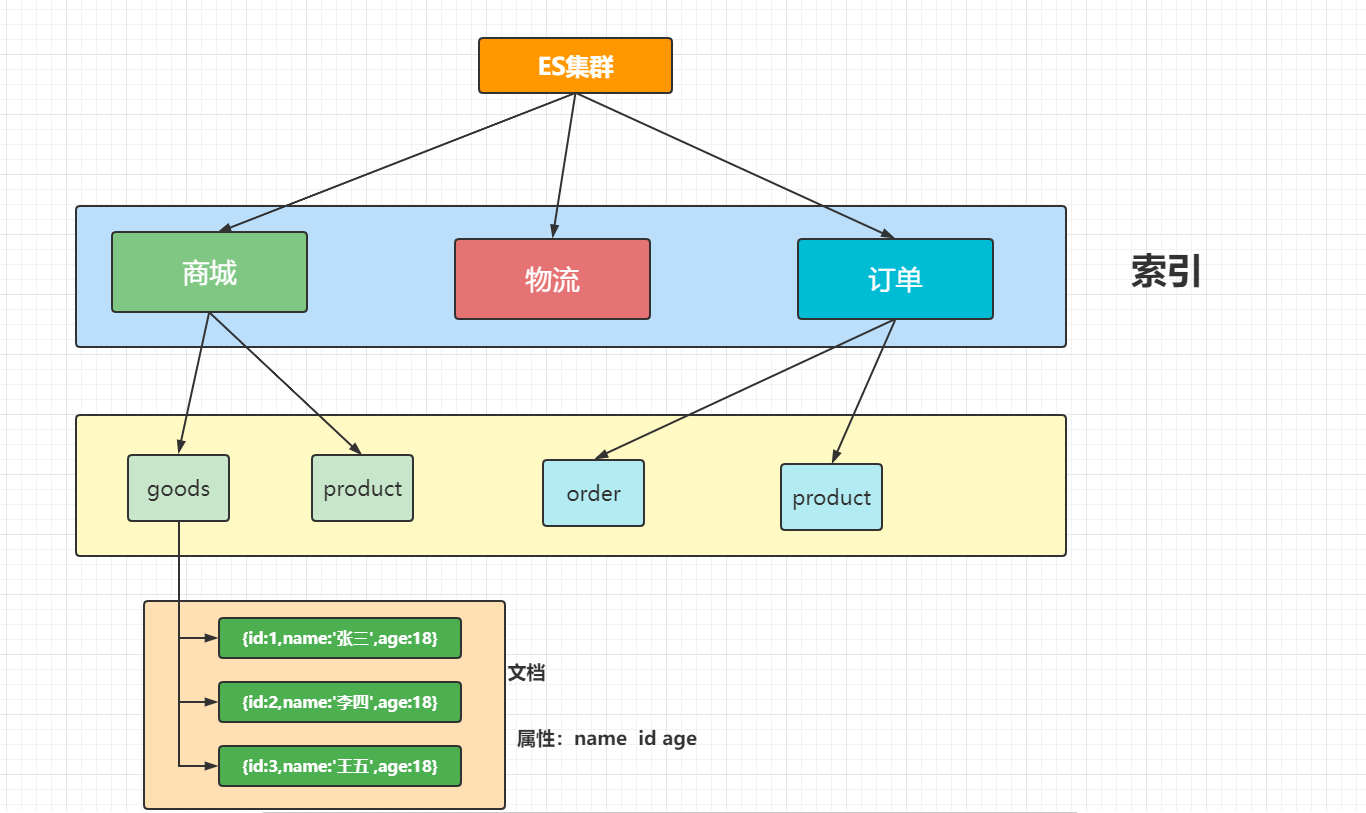
3.1 索引
索引(indices)在这儿很容易和MySQL数据库中的索引产生混淆,其实是和MySQL数据库中的Databases数据库的概念是一致的。
3.2 类型
类型(Type),对应的其实就是数据库中的 Table(数据表),类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。
3.3 文档
文档(Document),对应的就是具体数据行(Row)
3.4 字段
字段(field)相对于数据表中的列,也就是文档中的属性。
4. 倒排索引
Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤。特别是它对多条件的过滤支持非常好.
倒排索引是搜索引擎的核心。搜索引擎的主要目标是在查找发生搜索条件的文档时提供快速搜索。ES中的倒排索引其实就是 lucene 的倒排索引,区别于传统的正向索引,倒排索引会再存储数据时将关键词和数据进行关联,保存到倒排表中,然后查询时,将查询内容进行分词后在倒排表中进行查询,最后匹配数据即可。
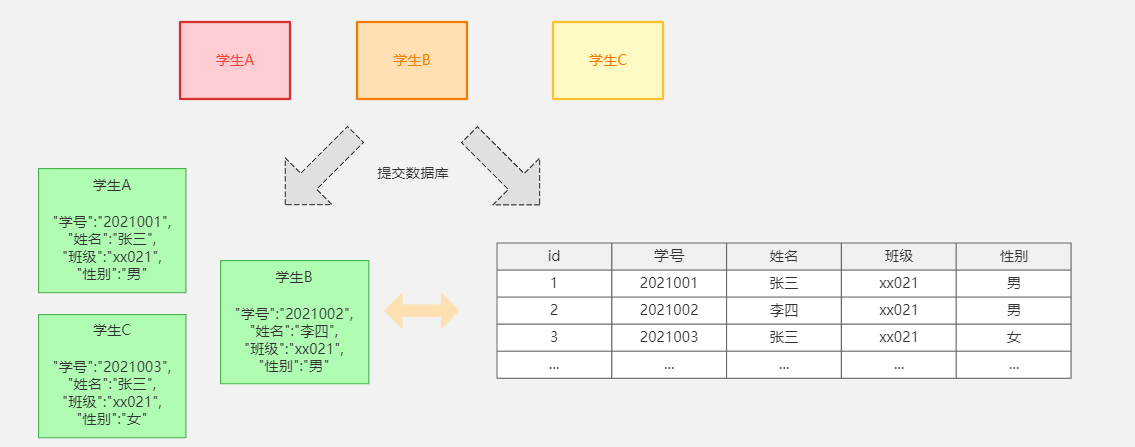
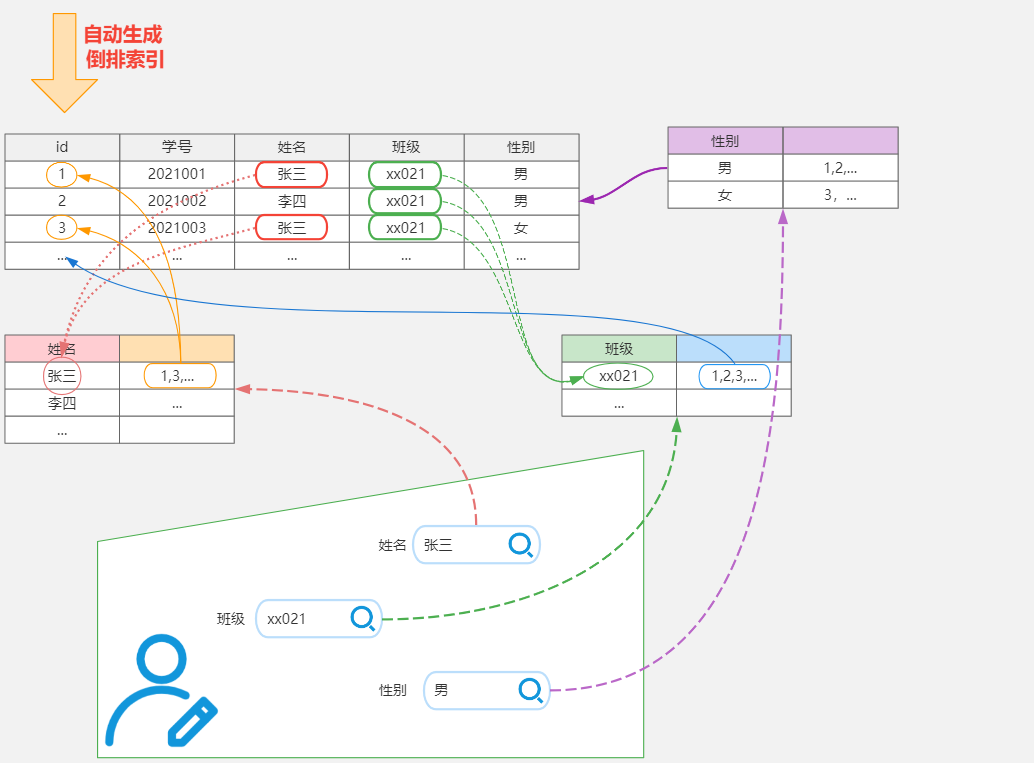
具体拆解的案例
| 词 | 记录 |
|---|---|
| 红海 | 1,2,3,4,5 |
| 行动 | 1,2,3 |
| 探索 | 2,5 |
| 特别 | 3,5 |
| 记录篇 | 4 |
| 特工 | 5 |
保存的对应的记录为
1-红海行动
2-探索红海行动
3-红海特别行动
4-红海记录篇
5-特工红海特别探索
分词:将整句分拆为单词
检索信息:
- 红海特工行动?
- 红海行动?
二、ElasticSearch相关安装
1.Elasticsearch安装
ElasticSearch安装就相当于安装MySQL数据库。
下载对应的镜像文件
docker pull elasticsearch:7.4.2
创建需要挂载的目录
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
echo “http.host : 0.0.0.0” >> /mydata/elasticsearch/config/elasticsearch.yml
安装ElasticSearch容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e “discovery.type=single-node” -e ES_JAVA_OPTS=“-Xms64m -Xmx128m” -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2
启动异常:
elasticsearch.yml配置文件的 : 两边需要添加空格
还有就是访问的文件权限问题:
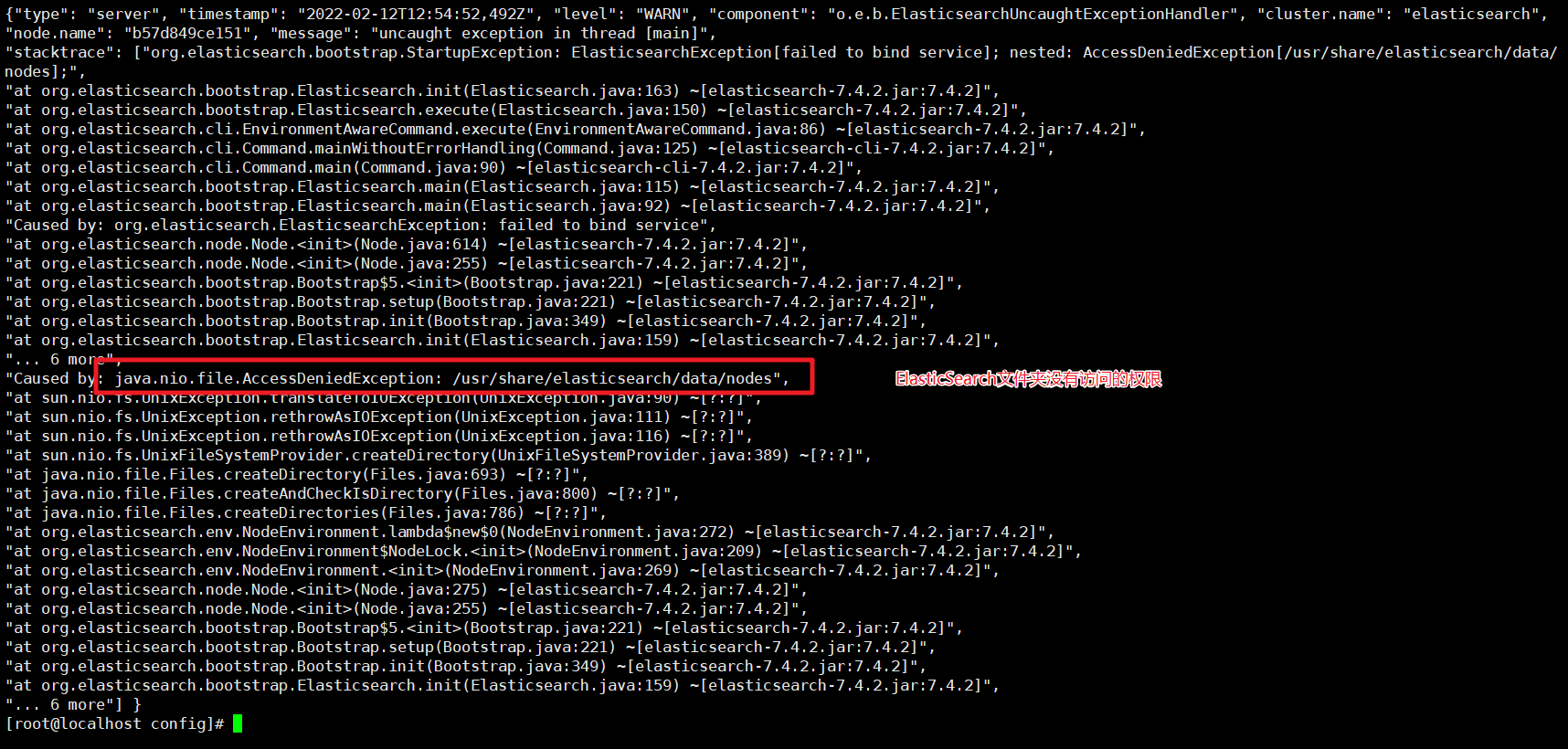
没有权限我们就添加权限就可以了
chmod -R 777 /mydata/elasticsearch/
然后我们就可以启动容器了
docker start 容器编号

然后测试访问:http://192.168.56.100:9200
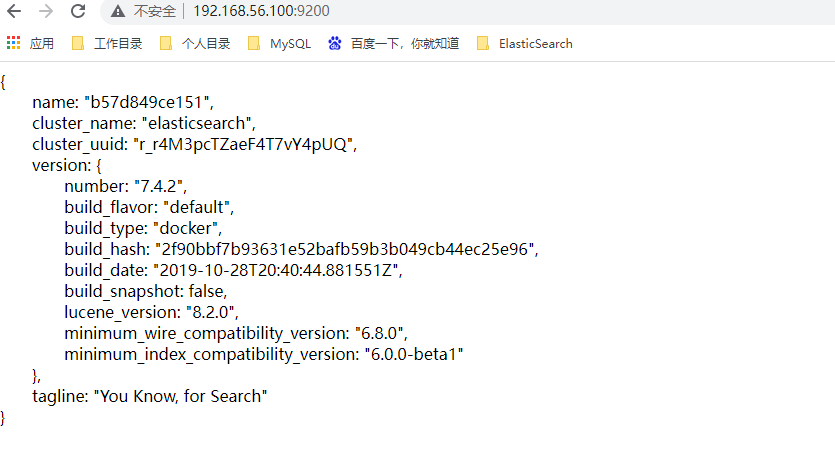
看到这个效果表示安装成功!
2.Kibana安装
Kibana的安装就相当于安装MySQL的客户端SQLYog。
下载镜像文件
docker pull kibana:7.4.2
启动容器的命令
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.100:9200 -p 5601:5601 -d kibana:7.4.2
测试访问:http://192.168.56.100:5601
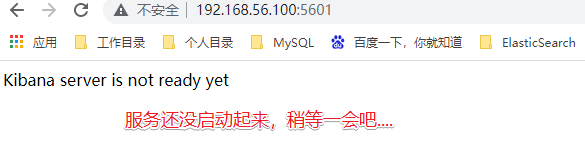
如果查看日志:docker logs 容器编号
那么我们就手动的进入容器中修改ElasticSearch的服务地址
docker exec -it 容器编号 /bin/bash
进入config目录
cd config
修改kibana.yml文件中的ElasticSearch的服务地址
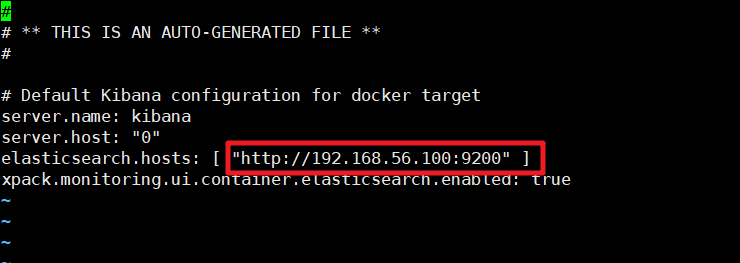
然后我们重启Kibana服务

看到如下界面表示安装启动成功
三、ElasticSearch入门
1._cat
| _cat接口 | 说明 |
|---|---|
| GET /_cat/nodes | 查看所有节点 |
| GET /_cat/health | 查看ES健康状况 |
| GET /_cat/master | 查看主节点 |
| GET /_cat/indices | 查看所有索引信息 |
/_cat/indices?v 查看所有的索引信息
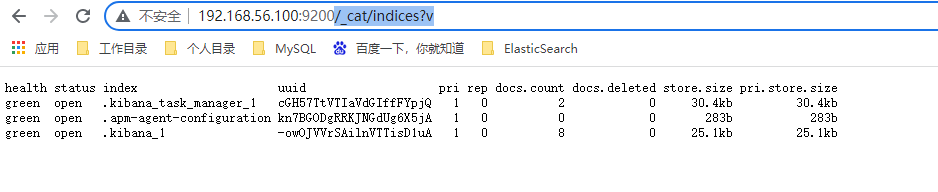
es 中会默认提供上面的几个索引,表头的含义为:
| 字段名 | 含义说明 |
|---|---|
| health | green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个 |
| rep | 从节点几个 |
| docs.count | 文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占 |
2.索引操作
索引就相当于我们讲的关系型数据库MySQL中的 database
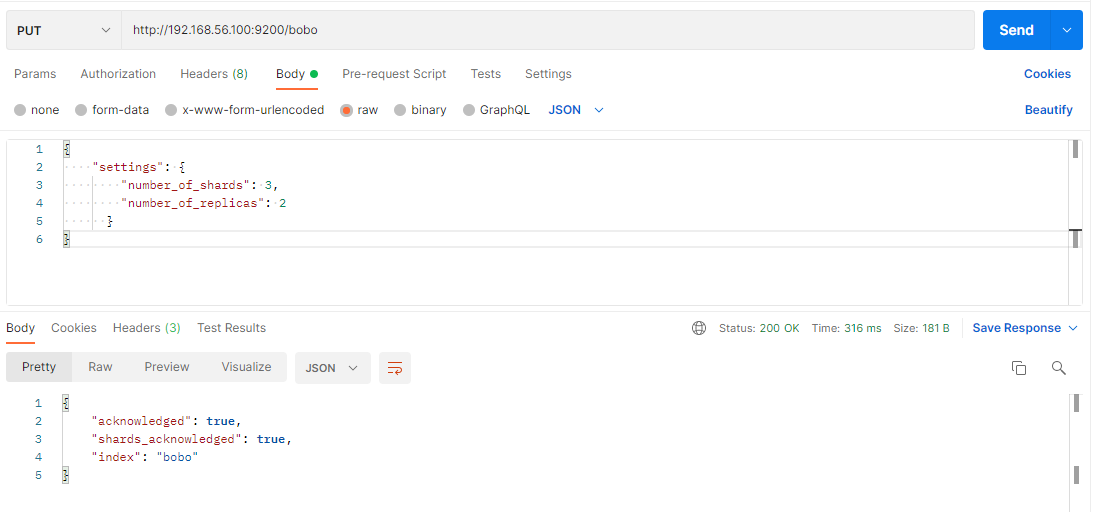
2.1 创建索引
PUT /索引名
参数可选:指定分片及副本,默认分片为3,副本为2。
{"settings": {"number_of_shards": 3,"number_of_replicas": 2}
}
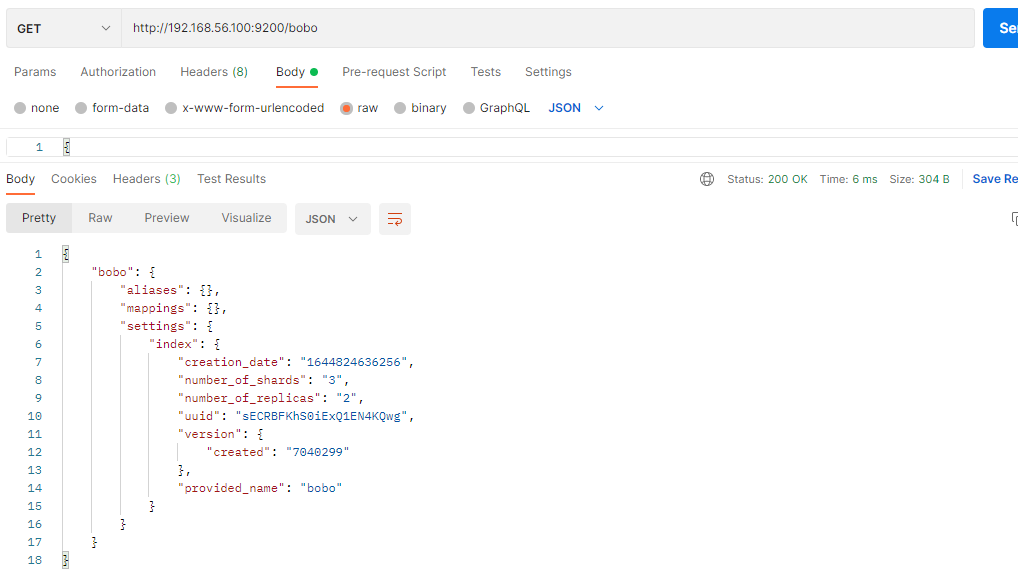
2.2 查看索引信息
GET /索引名
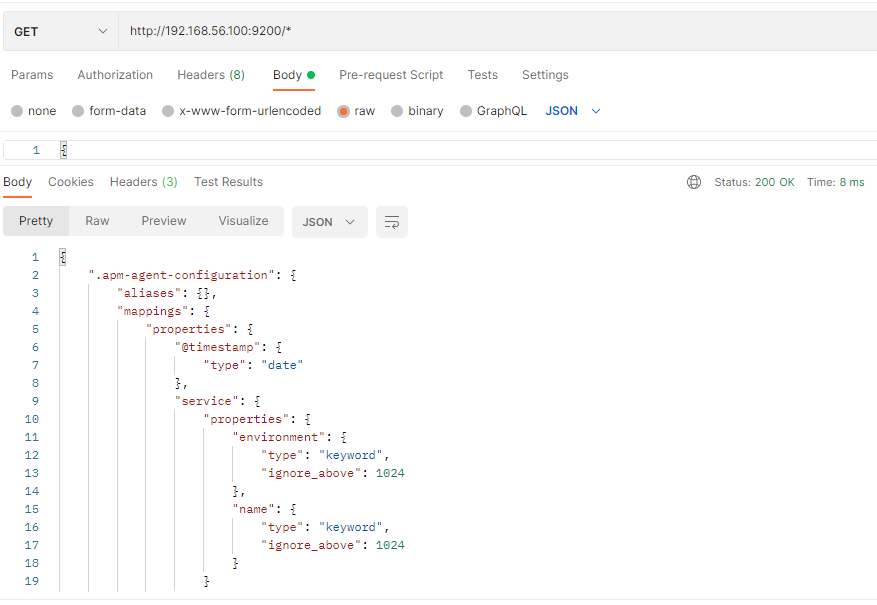
或者,我们可以使用*来查询所有索引具体信息
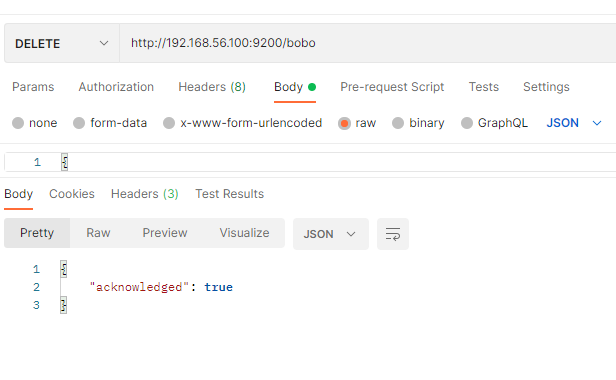
2.3 删除索引
DELETE /索引名称
3.文档操作
文档相当于数据库中的表结构中的Row记录
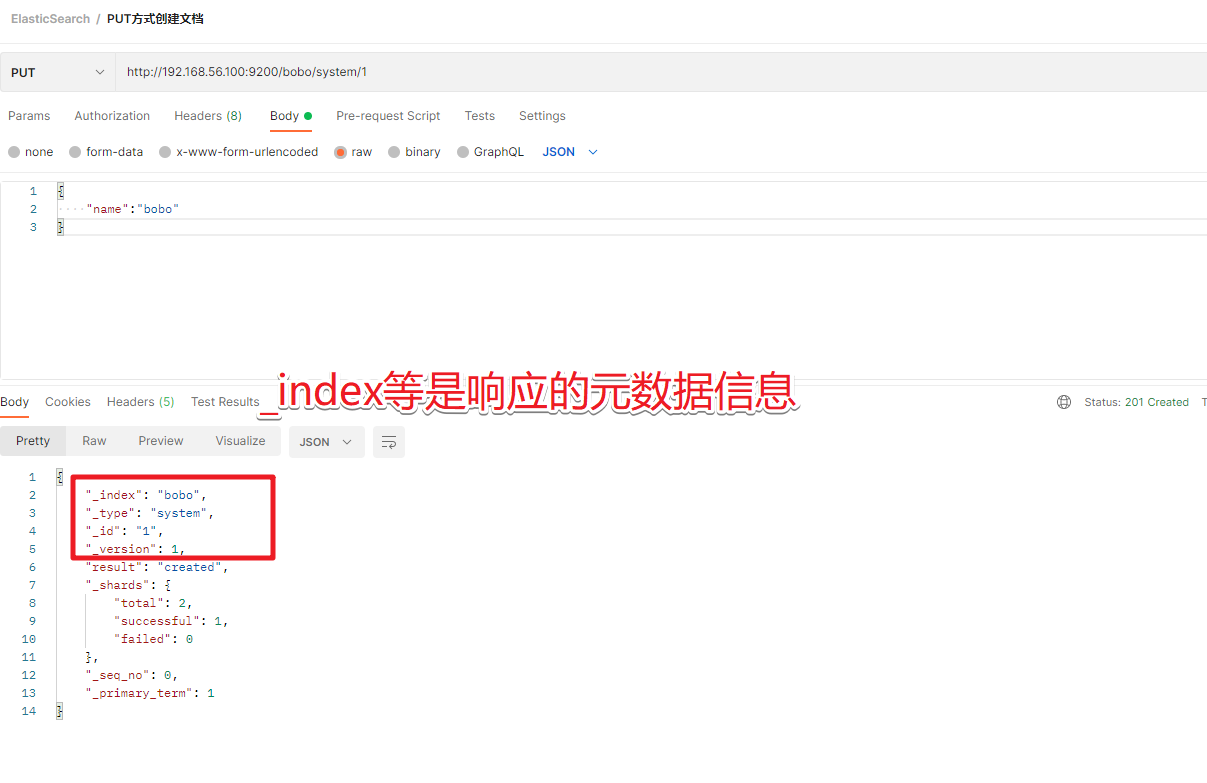
3.1 创建文档
PUT /索引名称/类型名/编号
数据
{"name":"bobo"
}
| 提交方式 | 描述 |
|---|---|
| PUT | 提交的id如果不存在就是新增操作,如果存在就是更新操作,id不能为空 |
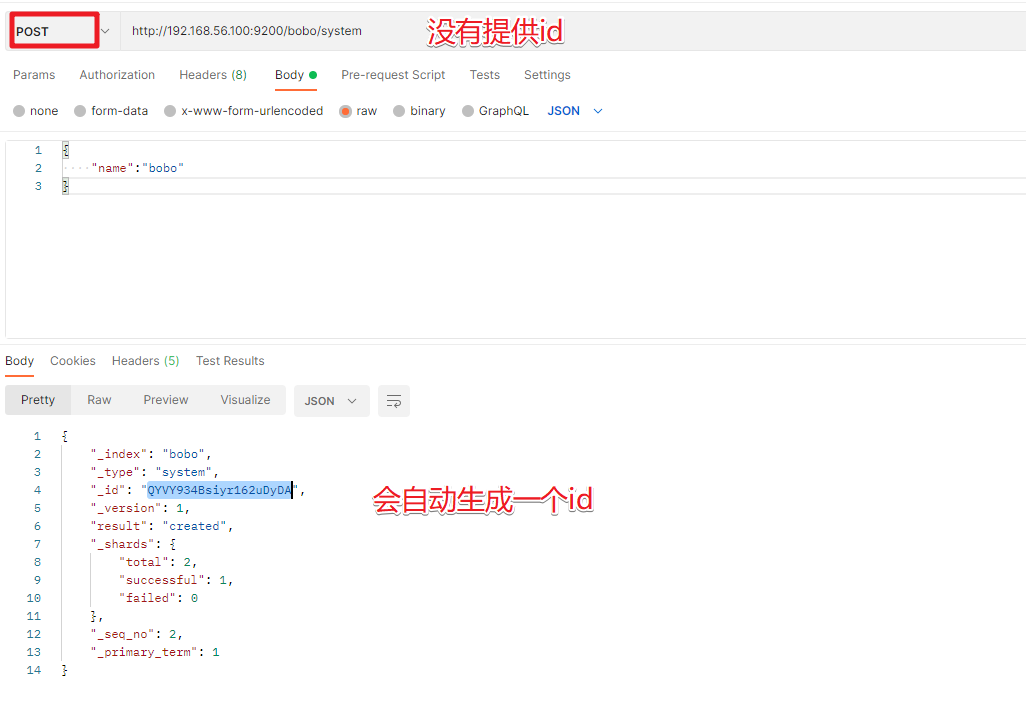
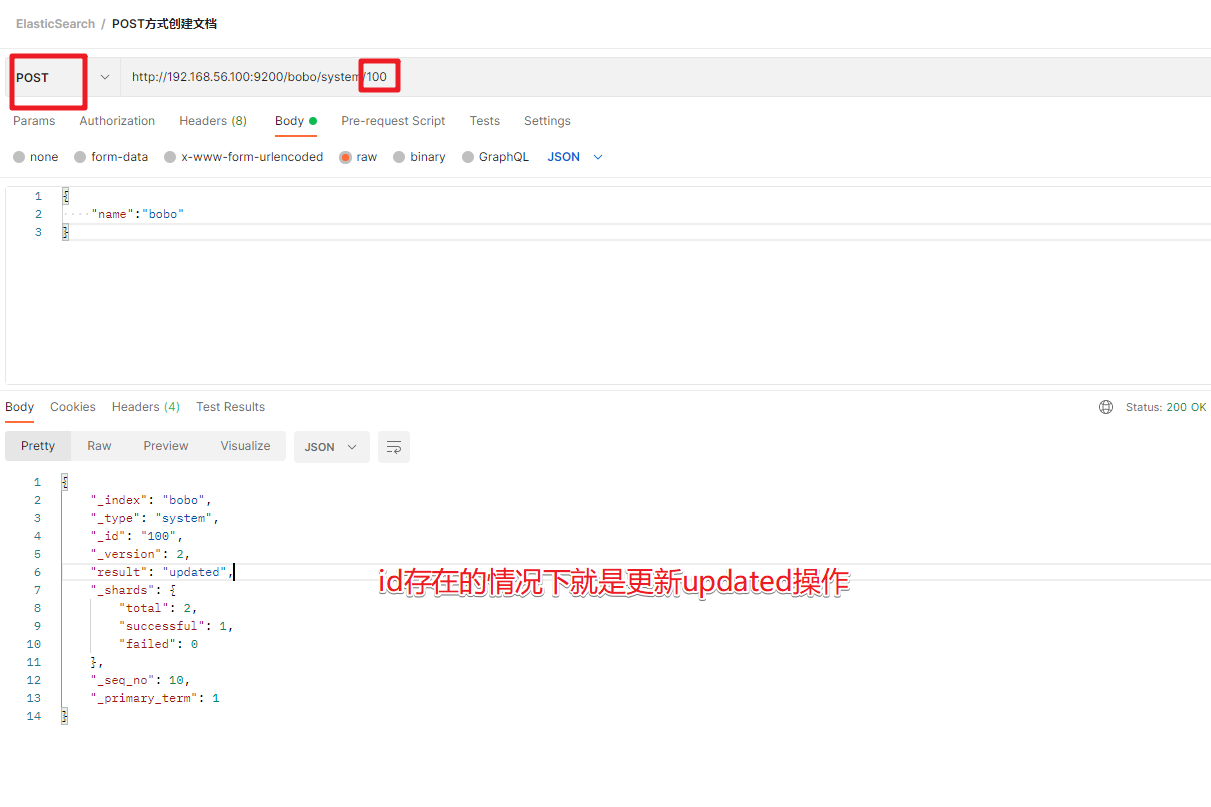
| POST | 如果不提供id会自动生成一个id,如果id存在就更新,如果id不存在就新增 |
POST /索引名称/类型名/编号
3.2 查询文档
GET /索引/类型/id
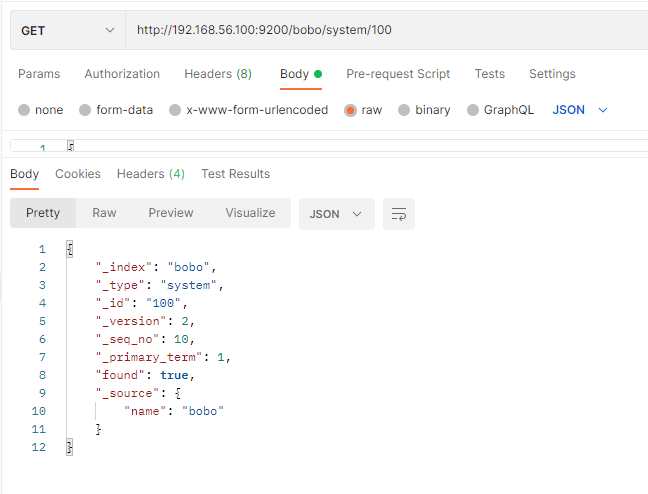
返回字段的含义
| 字段 | 含义 |
|---|---|
| _index | 索引名称 |
| _type | 类型名称 |
| _id | 记录id |
| _version | 版本号 |
| _seq_no | 并发控制字段,每次更新都会+1,用来实现乐观锁 |
| _primary_term | 同上,主分片重新分配,如重启,就会发生变化 |
| found | 找到结果 |
| _source | 真正的数据内容 |
乐观锁: ?if_seq_no=0&if_primary_term=1
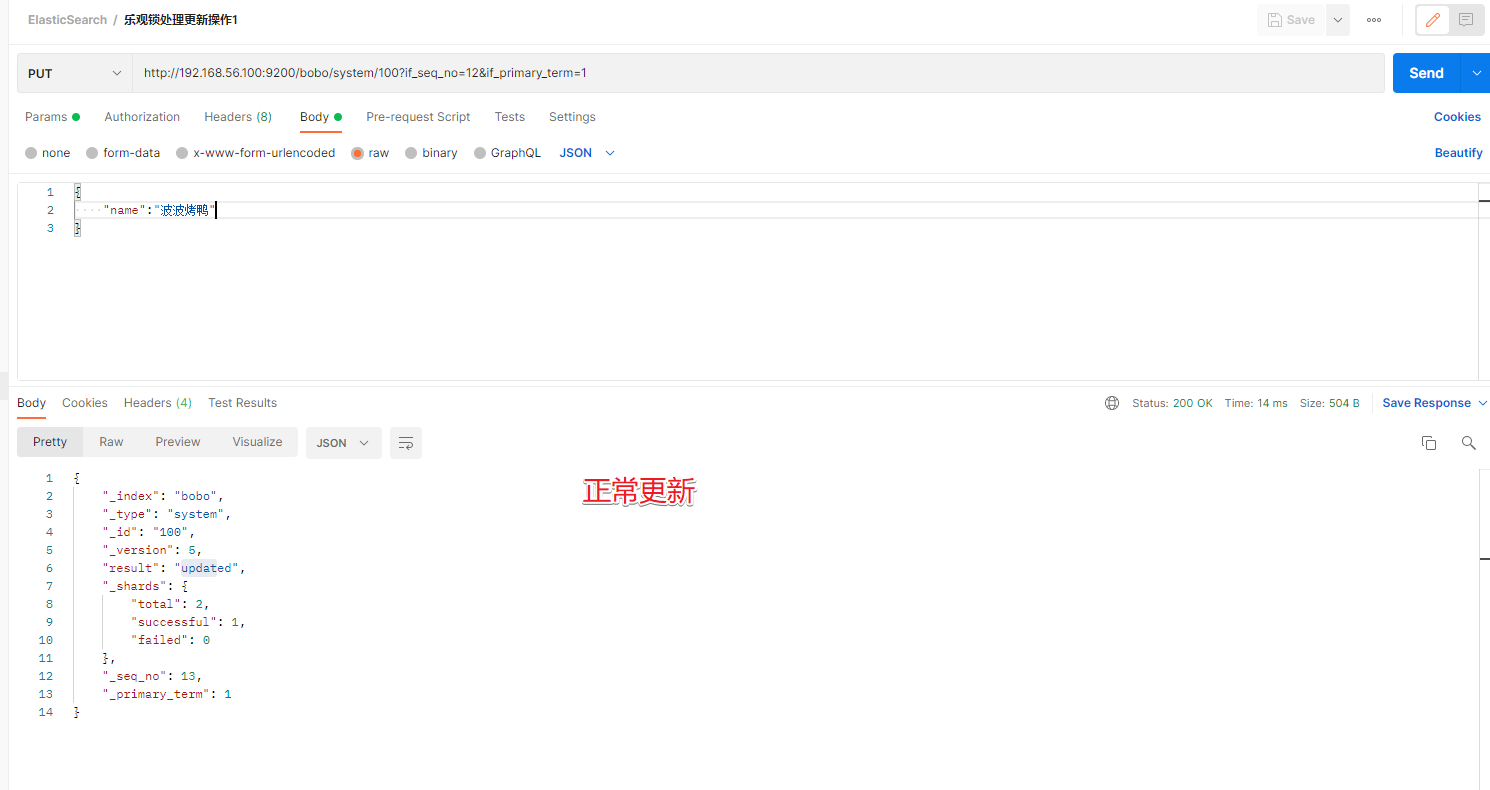
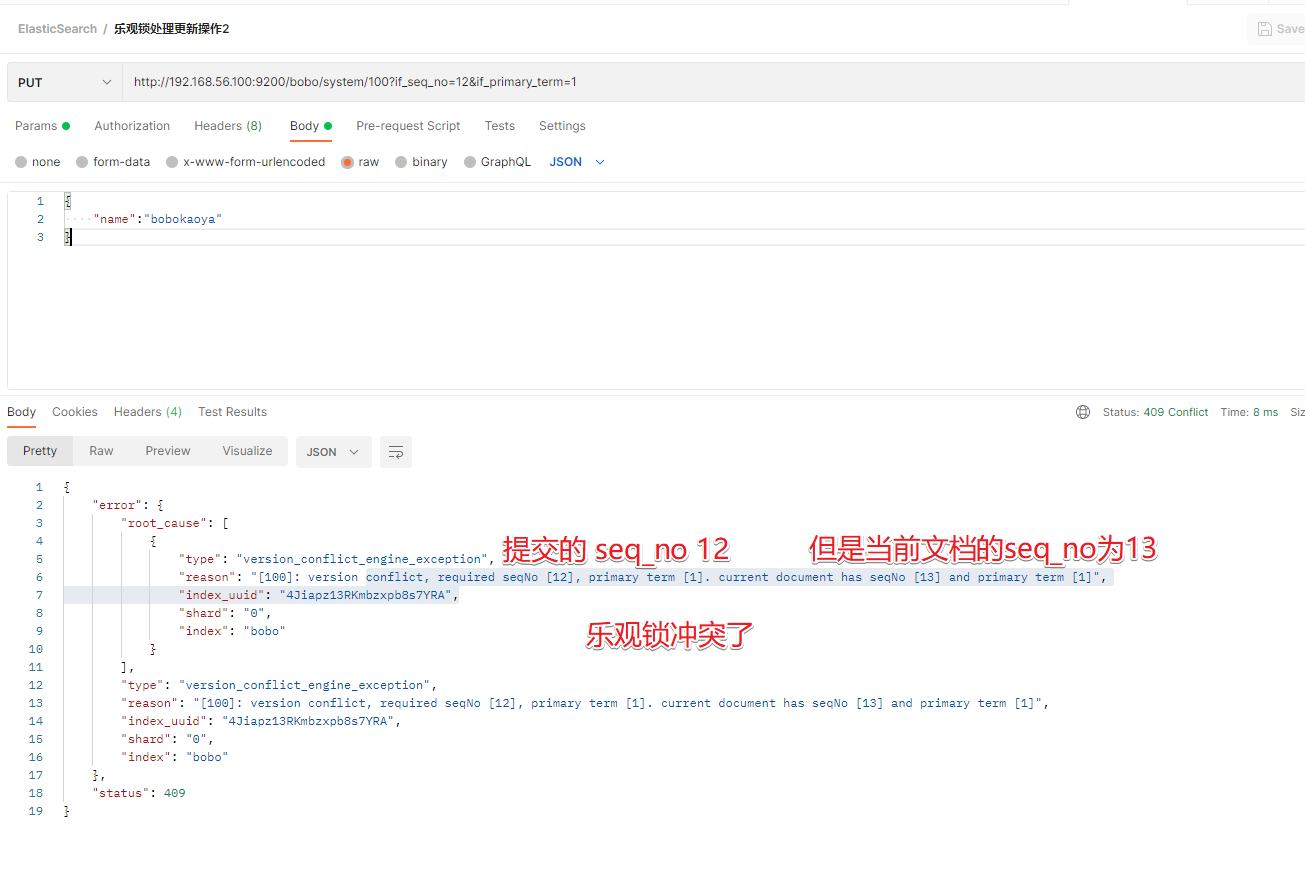
3.3 更新文档
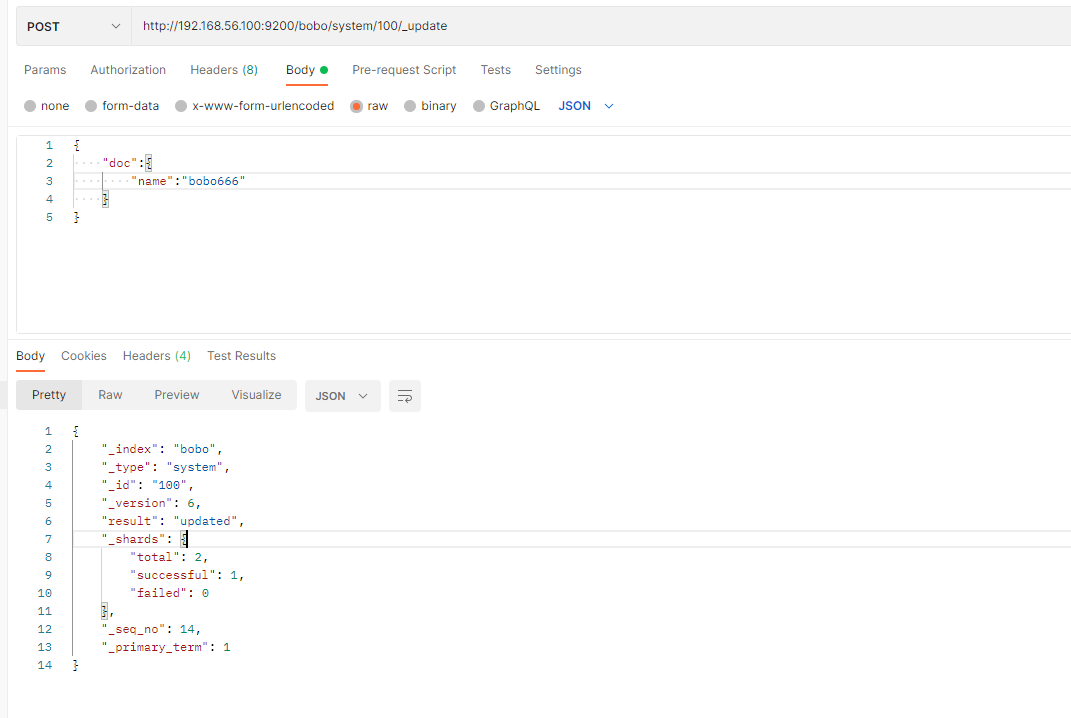
前面的POST和PUT添加数据的时候,如果id存在就会执行更新文档的操作,当然我们也可以通过POST方式提交,然后显示的跟上_update来实现更新
POST /索引/类型/id/_update
{"doc":{"name":"bobo666"}
}
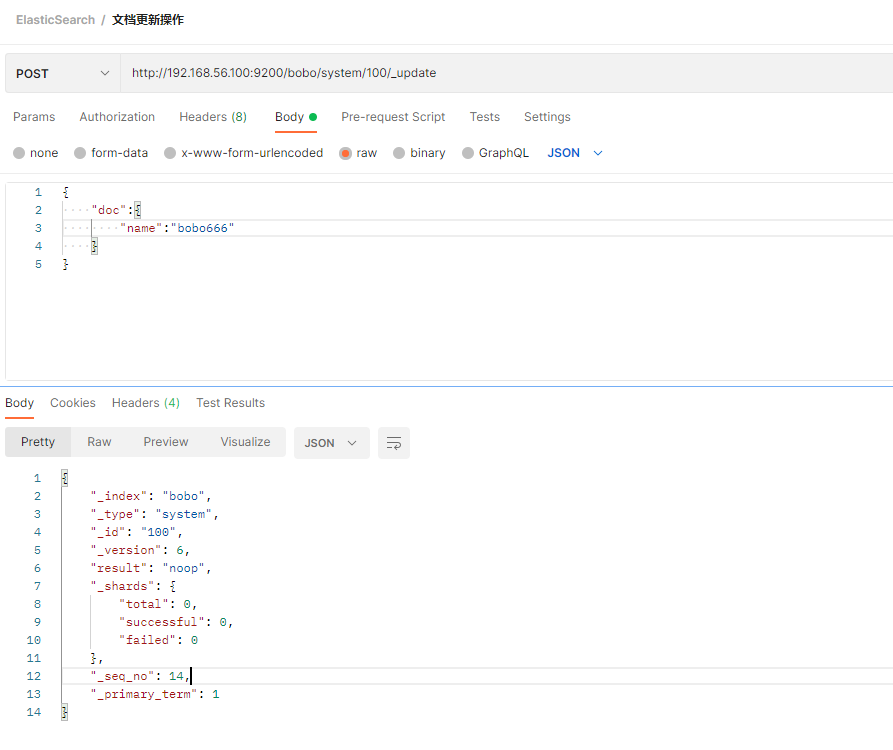
这种方式来更新,只是这种方式的更新如果数据没有变化则不会操作。
如果更新的数据和文档中的数据是一样的,那么POST方式提交是不会有任何操作的
3.4 删除文档
DELETE /索引/类型/id
DELETE /索引
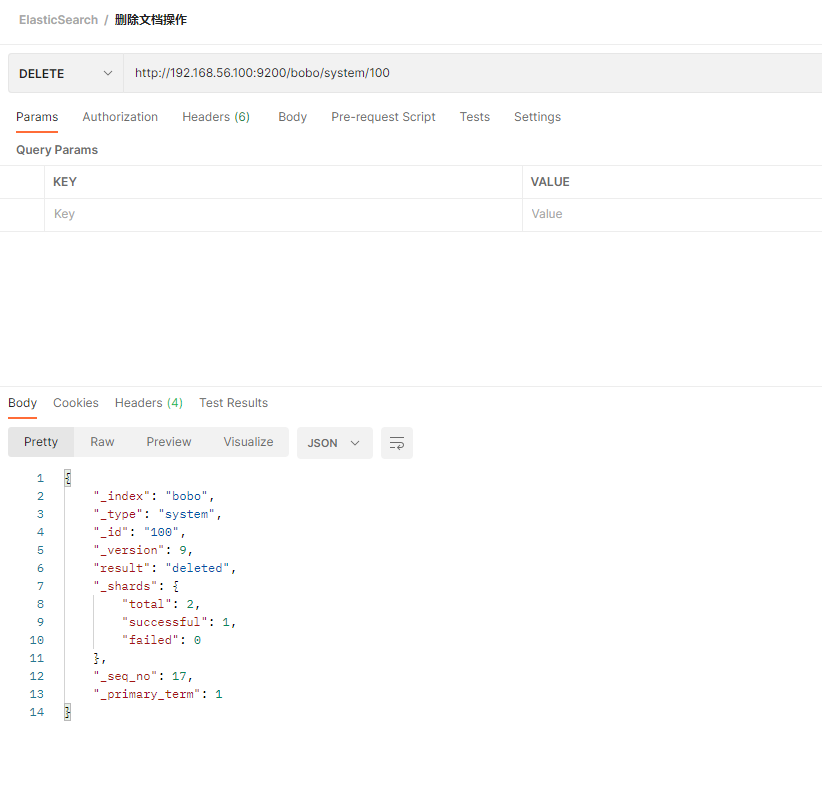
3.5 测试数据
_bulk批量操作,语法格式
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n
案例
POST /bobo/system/_bulk
{"index":{"_id":"1"}}
{"name":"dpb"}
{"index":{"_id":"2"}}
{"name":"dpb2"}
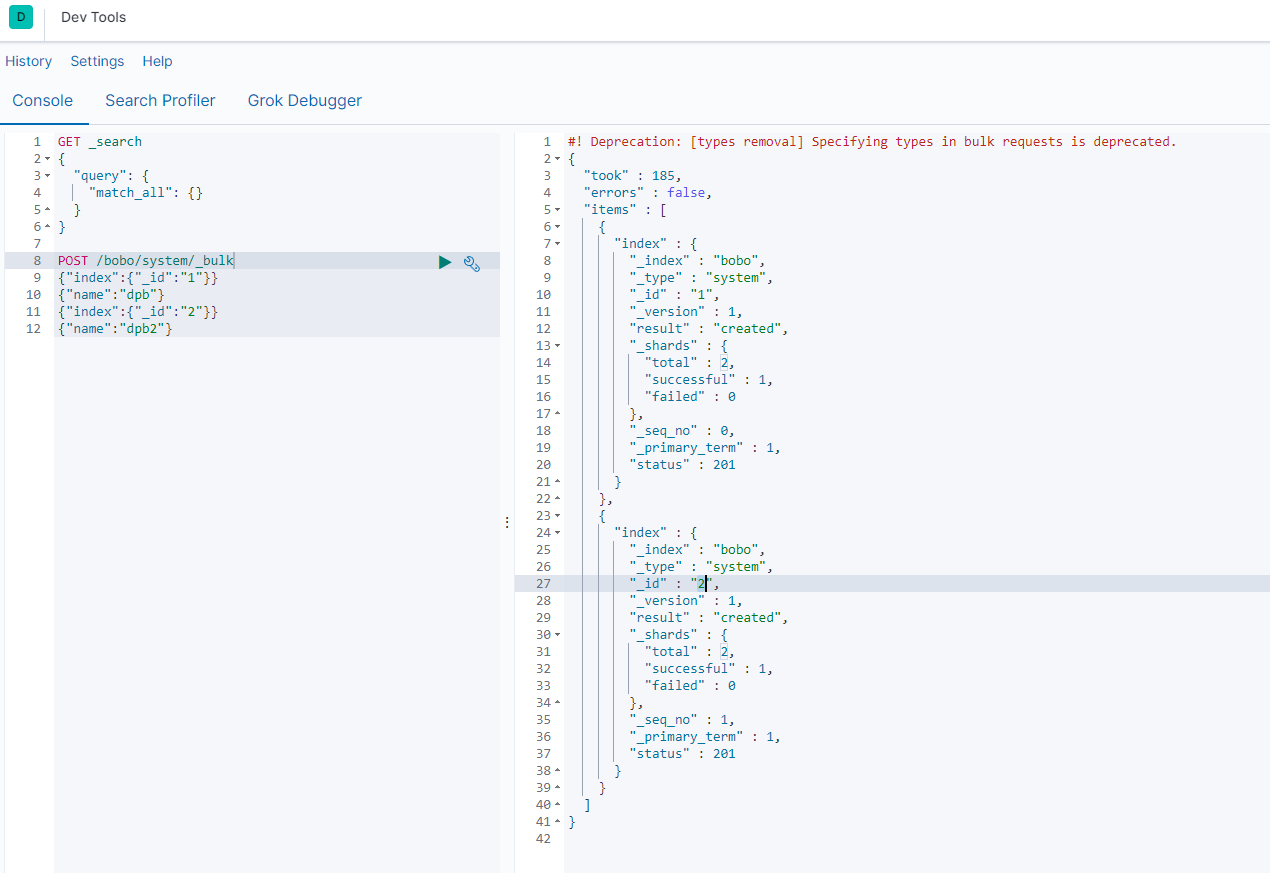
复杂点的案例:
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"My first bolg post ..."}
{"index":{"_index":"website","_type":"blog"}}
{"title":"My second blog post ..."}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"My updated blog post ..."}}官方测试数据:https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json
相关文章:
【业务功能篇81】微服务SpringCloud-ElasticSearch-Kibanan-docke安装-入门实战
ElasticSearch 一、ElasticSearch概述 1.ElasticSearch介绍 ES 是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心。它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,…...

【UniApp开发小程序】私聊功能uniapp界面实现 (买家、卖家 沟通商品信息)【后端基于若依管理系统开发】
文章目录 效果显示WebSocket连接使用全局变量WebSocket连接细节 最近和自己聊天的用户信息界面效果界面代码最近的聊天内容太长日期时间显示未读消息数量显示 私聊界面界面展示代码实现英文长串不换行问题聊天区域自动滑动到底部键盘呼出,聊天区域收缩,聊…...
【BASH】回顾与知识点梳理(三十六)
【BASH】回顾与知识点梳理 三十六 三十六. 认识与分析登录档36.1 什么是登录档CentOS 7 登录档简易说明登录档的重要性Linux 常见的登录档档名登录档所需相关服务 (daemon) 与程序CentOS 7.x 使用 systemd 提供的 journalctl 日志管理 登录档内容的一般格式 36.2 rsyslog.servi…...

十三、pikachu之暴力破解
文章目录 1、暴力破解概述2、基于表单的暴力破解3、验证码的绕过3.1 验证码的认证流程3.2 验证码绕过(on client)3.3 验证码绕过(on server)3.4 token防爆破? 1、暴力破解概述 “暴力破解”是一攻击具手段,…...
用手势操控现实:OpenCV 音量控制与 AI 换脸技术解析
基于opencv的手势控制音量和ai换脸 HandTrackingModule.py import cv2 import mediapipe as mp import timeclass handDetector():def __init__(self, mode False, maxHands 2, model_complexity 1, detectionCon 0.5, trackCon 0.5):self.mode modeself.maxHands max…...

【leetcode 力扣刷题】移除链表元素 多种解法
移除链表元素的多种解法 203. 移除链表元素解法①:头节点单独判断解法②:虚拟头节点解法③:递归 203. 移除链表元素 题目链接:203.移除链表元素 题目内容: 理解题意:就是单纯的删除链表中所有值等于给定的…...
leetcode503. 下一个更大元素 II 单调栈
思路: 与之前 739、1475 单调栈的问题如出一辙,唯一不同的地方就是对于遍历完之后。栈中元素的处理,之前的栈中元素因无法找到符合条件的值,直接加入vector中。而这里需要再重头遍历一下数组,找是否有符合条件的&…...

Oracle中列的维护
由于商业环境中,数据是不断变化的,客户的需求也是不断变化的,所以当一个表用了一段时间后,其结构就有可能需要变化。 而在Oracle中,提供了alter table这种方式来改变列。 从Oracle9.2版本之后: 如果需要变…...
)
后端项目开发:分页功能的实现(Mybatis+pagehelper)
分页查询是项目中的常用功能,此处我们基于Mybatis对分页查询进行处理。 引入分页依赖 <!-- pagehelper --> <dependency><groupId>com.github.pagehelper</groupId><artifactId>pagehelper-spring-boot-starter</artifactId>…...

SpringBoot集成Drools
一:简介 规则引擎全称为业务规则管理系统(Business Rule Management System)简称BRMS,主要思想是将应用程序中的业务决策部分分离开来,并使用预定义的语义模块编写业务决策(业务规则),由用户或开发者在需要时进行配置、管理。 其实就是将计算逻辑写在脚本中,通过Jav…...

React创建组件的三种方式及其区别是什么?
在React中,创建组件的三种主要方式是函数式组件、类组件和使用React Hooks的函数式组件。以下是对每种方式的详细解释以及它们之间的区别: 1、函数式组件: 函数式组件是使用纯粹的JavaScript函数来定义的。它接收一个props对象作为参数&…...
W6100-EVB-PICO进行UDP组播数据回环测试(九)
前言 上一章我们用我们的开发板作为UDP客户端连接服务器进行数据回环测试,那么本章我们进行UDP组播数据回环测试。 什么是UDP组播? 组播是主机间一对多的通讯模式, 组播是一种允许一个或多个组播源发送同一报文到多个接收者的技术。组播源将…...
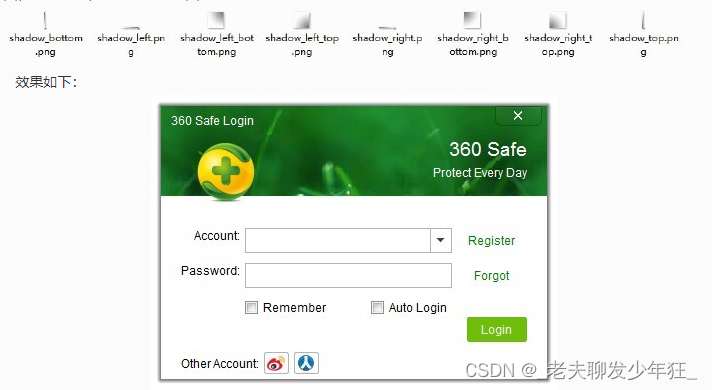
Qt 阴影边框
阴影边框很常见,诸如360以及其他很多软件都有类似效果,了解CSS3的同学们应该都知道box-shadow,它就是来设定阴影效果的,那么Qt呢?看过一些资料,说是QSS是基于CSS2的,既然如此,box-sh…...

前端面试:【性能优化】页面加载性能、渲染性能、资源优化
嗨,亲爱的前端开发者!在今天的Web世界中,用户期望页面加载速度快、交互流畅。因此,前端性能优化成为了至关重要的任务。本文将探讨三个关键方面的性能优化:页面加载性能、渲染性能以及资源优化,以帮助你构建…...

从按下电源键到进入系统,CPU在干什么?
本专栏更新速度较慢,简单讲讲计算机的那些事,简单讲讲那些特别散乱杂的知识,欢迎各位朋友订阅专栏啊 感谢一路相伴的朋友们 浅淡操作系统系列第2篇 目录 通电 保护模式和实模式 内存管理单元MMU 逻辑地址?物理地址࿱…...
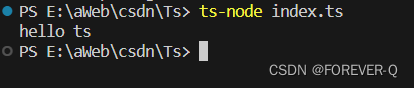
TypeScript初体验
1.安装编译TS工具包 npm i -g typescript 2. 查看版本号 tsc -v 3.创建ts文件 说明:创建一个index.ts文件 4.TS编译为JS tsc index.ts 5.执行JS代码 node index.js 6.简化TS的步骤 6.1安装 npm i -g ts-node 6.2执行 ts-node index.ts...
基于 Alpine 环境源码构建 alibaba-tengine(阿里巴巴)的 Docker 镜像
About Alpine(简介) Alpine Linux 是一款极其轻量级的 Linux 发行版,基于 busybox,多被当做 Docker 镜像的底包(基础镜像),在使用容器时或多或少都会接触到此系统,本篇文章我们以该镜…...

政府网站定期巡检:构建高效、安全与透明的数字政务
在数字时代,政府网站已不仅仅是一个信息发布窗口,更是政府与公众互动的桥梁、政务服务的主要渠道以及数字化治理的重要平台。因此,确保政府网站的高效运行、信息安全与透明公开就显得尤为重要。在此背景下,定期的网站巡检与巡查成…...
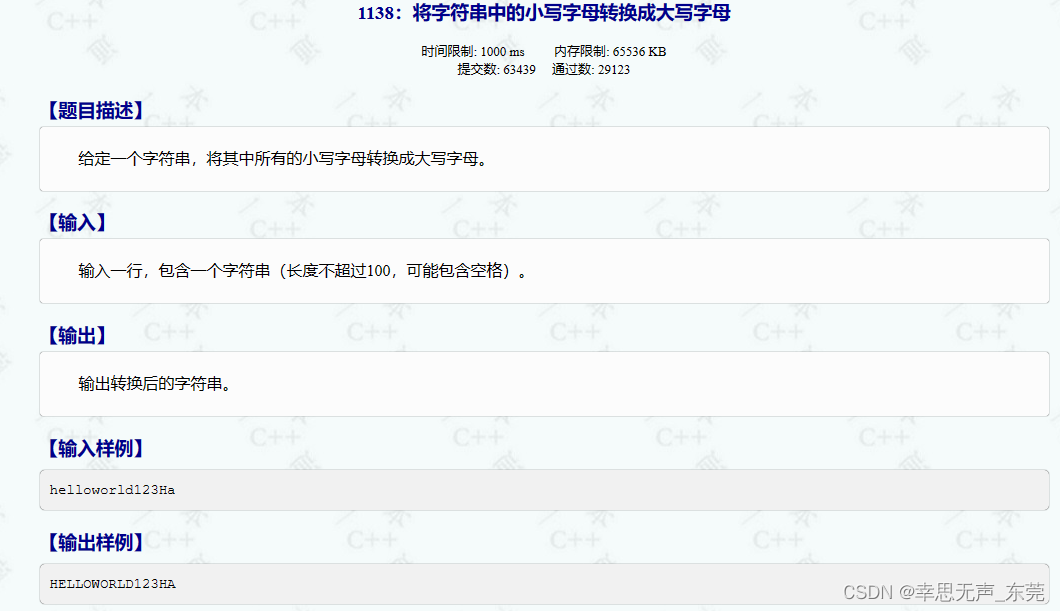
C++信息学奥赛1138:将字符串中的小写字母转换成大写字母
#include<bits/stdc.h> using namespace std; int main() {string arr;// 输入一行字符串getline(cin, arr);for(int i0;i<arr.length();i){if(arr[i]>97 and arr[i]<122){char aarr[i]-32; // 将小写字母转换为大写字母cout<<a; // 输出转换后的字符}els…...
leetcode1475. 商品折扣后的最终价格 【单调栈】
简单题 第一次错误做法 class Solution { public:vector<int> finalPrices(vector<int>& prices) {int n prices.size();stack<int> st;unordered_map<int, int> mp;int i 0;while(i ! prices.size()) {int t prices[i];if (st.empty() || t …...

LeetCode IPO问题题解
LeetCode IPO问题题解 题目描述 给定初始资本 w,最多完成 k 个项目。每个项目有利润和最低资本要求。找到能够获得的最大资本。 示例: 输入:capital [0,1,2,3], profits [1,2,3,5], k 2, w 0输出:4 解题思路 方法&#…...

按键精灵PC版和手机版到底怎么选?一篇讲清四大版本区别与核心开发流程
按键精灵四大版本深度解析:从需求匹配到高效开发的完整指南 在自动化工具领域,按键精灵凭借其跨平台支持和易用性,成为许多用户的首选。但面对官网提供的四个不同版本——电脑版、手机助手、安卓版和IOS版,不少新手用户会感到困惑…...

突破性开源BIM引擎:如何实现建筑信息模型的智能化处理与转换
突破性开源BIM引擎:如何实现建筑信息模型的智能化处理与转换 【免费下载链接】IfcOpenShell Open source IFC library and geometry engine 项目地址: https://gitcode.com/gh_mirrors/if/IfcOpenShell 在建筑信息模型(BIM)技术日益普…...

别再自己写弹窗了!UniApp内置的showLoading、showToast、showModal,5分钟搞定App常用交互
UniApp内置交互API实战:5分钟打造专业级弹窗体验 第一次接触UniApp开发时,我花了整整两天时间调试一个自定义加载动画——结果在iOS上卡顿,在Android上闪退。直到发现showLoading这个内置API,三行代码就解决了所有问题。这段经历让…...

用STM32F401的I2S接口驱动TM8211 DAC播放WAV音频,保姆级CubeMX配置教程
基于STM32F401的TM8211音频播放系统开发指南 1. 硬件系统搭建与原理分析 在开始CubeMX配置之前,我们需要先理解整个音频播放系统的硬件架构和工作原理。STM32F401通过I2S接口与TM8211 DAC芯片通信,将数字音频信号转换为模拟信号,最终驱动扬…...
)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单) 在硬件设计领域,电源模块的设计往往是最基础却也最考验工程师功底的环节。一个优秀的电源设计不仅需要满足电压转换的基本需求,还要兼顾效率、稳…...

终极免费ThinkPad双风扇智能控制方案:TPFanControl2完全指南
终极免费ThinkPad双风扇智能控制方案:TPFanControl2完全指南 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 在ThinkPad笔记本的日常使用中,散热…...

C51内存优化:DATA段间隙问题解决方案
1. C51内存空间中的DATA段间隙问题解析作为一名长期使用Keil C51开发工具链的嵌入式工程师,我经常遇到内存空间利用率问题。最近在调试一个使用bit变量的项目时,发现链接器在寄存器组和bit区域之间留下了15字节的间隙。这种内存浪费在资源紧张的8051系统…...
)
保姆级教程:在Ubuntu 20.04上从零搭建K230目标检测训练环境(含Anaconda、nncase配置避坑指南)
从零构建K230目标检测训练环境:Anaconda与nncase配置实战指南 在边缘计算设备上部署目标检测模型已成为工业质检、智能安防等场景的热门选择。嘉楠K230凭借其高性价比和低功耗特性,吸引了大量开发者尝试将YOLO等算法部署到该平台。然而,从裸…...

为Claude Code配置Taotoken解决密钥被封与Token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决密钥被封与Token不足难题 应用场景类,针对经常使用Claude Code但受限于官方限制的开发者…...