数据结构之哈希
哈希
- 1. 哈希概念
- 2. 哈希冲突
- 3. 哈希冲突解决
- 3.1 哈希表的闭散列
- 3.2 哈希表的开散列
- 2. 哈希的应用
- 2.1 位图
- 2.2 布隆过滤器
哈希(Hash)是一种将任意长度的二进制明文映射为较短的二进制串的算法。它是一种重要的存储方式,也是一种常见的检索方法。哈希函数通过特定方式(hash函数)处理输入,生成一个值。这个值等同于存放数据的地址,这个地址里面再把输入的数据进行存储。 哈希算法是一种以较短的信息来保证文件唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。因此,当原文件发生改变时,其标志的位置也会发生改变,此时的对应方式就不再适应,需要将数据重新进行标对应的位置。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
1. 哈希概念
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
- 插入元素:根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放。
- 搜索元素:对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功。
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表。散列方法的主要思想是根据结点的关键码值来确定其存储地址:以关键码值K为自变量,通过一定的函数关系h (K) (称为散列函数),计算出对应的函数值来,把这个值解释为结点的存储地址,将结点存入到此存储单元中。 检索时,用同样的方法计算地址,然后到相应的单元里去取要找的结点。 通过散列方法可以对结点进行快速检索。
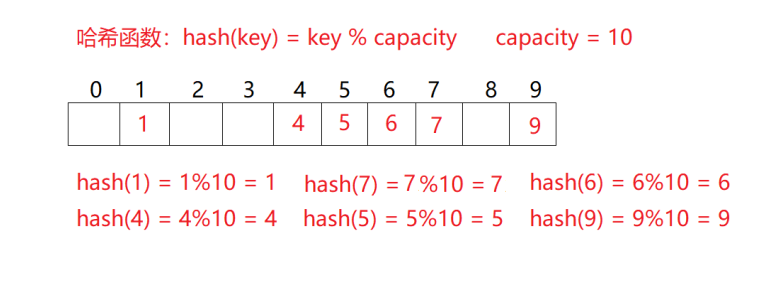
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快。
如上图,如果再插入14,会出现什么问题?会出现哈希冲突。
2. 哈希冲突
哈希冲突是指两个或多个不同的键值被哈希函数映射到了同一个地址中的情况。这种情况下,一个地址对应多个键值对,而查找时只能找到其中一个键值对,因此会导致查找失败。
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:1.哈希函数的定义域必须包括需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间;2.哈希函数计算出来的地址能均匀分布在整个空间中。
常见哈希函数
- 直接定址法–(常用)
取关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀;缺点:需要事先知道关键字的分布情况;使用场景:适合查找比较小且连续的情况 - 除留余数法–(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:Hash(key) = key% p(p<=m),将关键码转换成哈希地址 - 平方取中法–(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址;平方取中法比较适合的情况:不知道关键字的分布,而位数又不是很大的情况。
3. 哈希冲突解决
哈希冲突是哈希表中常见的问题,解决哈希冲突的方法有很多种,两种常见的方法是:闭散列和开散列。
3.1 哈希表的闭散列
闭散列是一种解决哈希冲突的方法,它将所有的关键字都保存在散列表中,而不是像开放地址法那样只保存一部分。在闭散列中,每个桶都是一个链表,当发生哈希冲突时,新的元素会被插入到对应桶的链表中。这种方法可以避免开放地址法中的聚集现象,并且可以在空间充足的情况下实现快速查找。
线性探索
如上图的场景,现在需要插入元素14,先通过哈希函数计算哈希地址,hashAddr为4,因此14理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突。
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
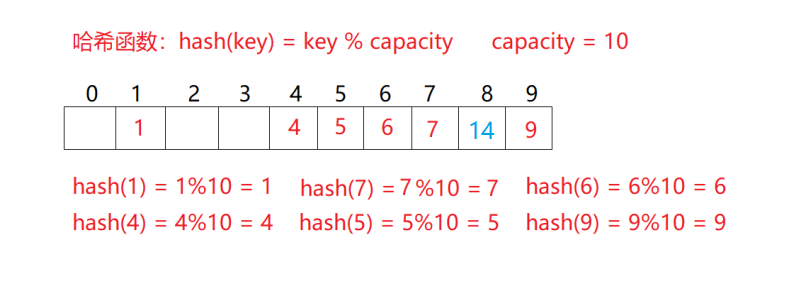
插入:通过哈希函数获取待插入元素在哈希表中的位置
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素。
删除:采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,14查找起来可能会受影
响。因此线性探测采用标记的伪删除法来删除一个元素。
哈希表扩容是指在哈希表中插入新元素时,如果桶的数量不足以容纳新元素,就需要增加桶的数量。哈希表扩容的过程包括以下几个步骤:
1.创建一个新的桶数组,大小为原来的两倍;2.将原来的桶数组中的元素重新哈希到新的桶数组中;3.释放原来的桶数组。
在哈希表扩容的过程中,需要重新计算每个元素在新桶数组中的位置,这个过程需要消耗一定的时间。因此,在设计哈希表时,需要根据实际情况选择合适的桶数量,以避免频繁扩容。
哈希表的负载因子是指哈希表中已经存储的元素个数与容量的数量之比。负载因子越大,哈希冲突的概率就越大,查找、插入和删除操作的效率也会降低。一般来说,当负载因子超过某个阈值时,就需要对哈希表进行扩容,以保证哈希表的性能。
代码如下:
namespace OpenAddress
{enum State{EMPTY,EXIST,DELETE};template<class K, class V>struct HashData{pair<K, V> _kv;State _state = EMPTY;};template<class K, class V>class HashTable{public:bool Insert(const pair<K, V>& kv){if (Find(kv.first))return false;// 负载因子超过0.7就扩容//if ((double)_n / (double)_tables.size() >= 0.7)if (_tables.size() == 0 || _n * 10 / _tables.size() >= 7){size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;HashTable<K, V> newht;newht._tables.resize(newsize);// 遍历旧表,重新映射到新表for (auto& data : _tables){if (data._state == EXIST){newht.Insert(data._kv);}}_tables.swap(newht._tables);}size_t hashi = kv.first % _tables.size();// 线性探测size_t i = 1;size_t index = hashi;while (_tables[index]._state == EXIST){index = hashi + i;index %= _tables.size();++i;}_tables[index]._kv = kv;_tables[index]._state = EXIST;_n++;return true;}HashData<K, V>* Find(const K& key){if (_tables.size() == 0){return false;}size_t hashi = key % _tables.size();// 线性探测size_t i = 1;size_t index = hashi;while (_tables[index]._state != EMPTY){if (_tables[index]._state == EXIST && _tables[index]._kv.first == key){return &_tables[index];}index = hashi + i;index %= _tables.size();++i;// 如果已经查找一圈,那么说明全是存在+删除if (index == hashi)break;}return nullptr;}bool Erase(const K& key){HashData<K, V>* ret = Find(key);if (ret){ret->_state = DELETE;--_n;return true;}else{return false;}}private:vector<HashData<K, V>> _tables;size_t _n = 0; // 存储的数据个数};
}
线性探测优点:实现非常简单,
线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。如何缓解呢?可以使用二次探索,三次探索等等。当所求出key的位置被占用,不去填入key+1的位置,而是填入key+2或key+3的位置,这种方式叫做二次探索,三次探索,这样可以让表更加稀松一些,就能提高效率。
当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
3.2 哈希表的开散列
开散列(Open Hashing)是另一种解决哈希冲突的方法,也称为链地址法(Chaining)。在开散列中,哈希表中的每个桶都是一个链表,当发生哈希冲突时,新的元素会被插入到对应桶的链表中。这种方法可以避免开放地址法中的聚集现象,并且可以在空间充足的情况下实现快速查找 。
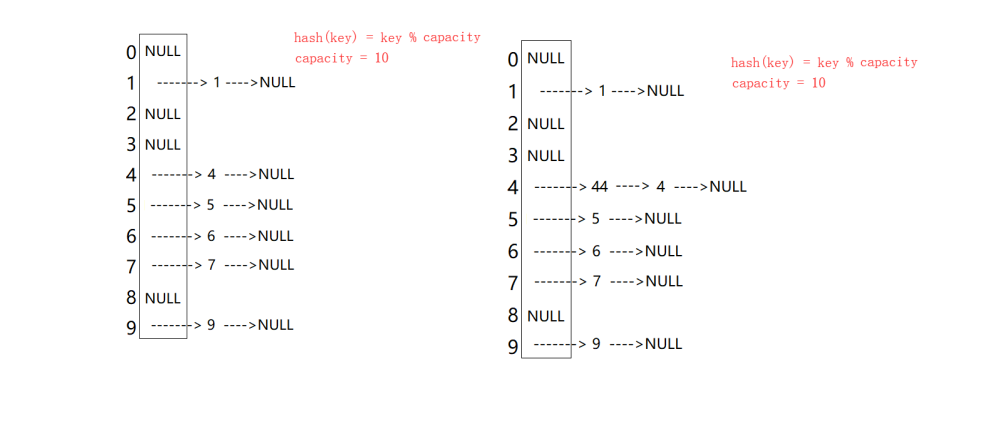
开散列增容:桶的个数是一定的,随着元素的不断插入,每个桶中元素的个数不断增多,极端情况下,可
能会导致一个桶中链表节点非常多,会影响的哈希表的性能,因此在一定条件下需要对哈希表进行增容,开散列最好的情况是:每个哈希桶中刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,可以给哈希表增容。
只能存储key为整形的元素,其他类型怎么解决?key为字符串类型,需要将其转化为整形。在将字符串类型转换为整数类型时,可以使用以下方法:
- 将字符串中的每个字符转换为其ASCII码值,然后将这些值相加得到一个整数。
- 将字符串中的每个字符转换为其ASCII码值,然后将这些值相乘得到一个整数。
- 将字符串中的每个字符转换为其ASCII码值,然后将这些值按位异或得到一个整数。
代码如下:
namespace HashBucket
{template<class K, class V>struct HashNode{HashNode<K, V>* _next;pair<K, V> _kv;HashNode(const pair<K, V>& kv):_next(nullptr), _kv(kv){}};template<class K>struct HashFunc{size_t operator()(const K& key){return key;}};// 特化,将字符串的情况进行一些处理template<>struct HashFunc<string>{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;}return hash;}};template<class K, class V, class Hash = HashFunc<K>>class HashTable{typedef HashNode<K, V> Node;public:~HashTable(){for (auto& cur : _tables){while (cur){Node* next = cur->_next;delete cur;cur = next;}cur = nullptr;}}Node* Find(const K& key){if (_tables.size() == 0)return nullptr;Hash hash;size_t hashi = hash(key) % _tables.size();Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool Erase(const K& key){Hash hash;size_t hashi = hash(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (cur->_kv.first == key){if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}else{prev = cur;cur = cur->_next;}}return false;}//扩容扩质数的2倍左右size_t GetNextPrime(size_t prime){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (; i < __stl_num_primes; ++i){if (__stl_prime_list[i] > prime)return __stl_prime_list[i];}return __stl_prime_list[i];}bool Insert(const pair<K, V>& kv){if (Find(kv.first)){return false;}Hash hash;// 负载因因子==1时扩容if (_n == _tables.size()){size_t newsize = GetNextPrime(_tables.size());vector<Node*> newtables(newsize, nullptr);for (auto& cur : _tables){while (cur){Node* next = cur->_next;size_t hashi = hash(cur->_kv.first) % newtables.size();// 头插到新表cur->_next = newtables[hashi];newtables[hashi] = cur;cur = next;}}_tables.swap(newtables);}size_t hashi = hash(kv.first) % _tables.size();// 头插Node* newnode = new Node(kv);newnode->_next = _tables[hashi];_tables[hashi] = newnode;++_n;return true;}size_t MaxBucketSize(){size_t max = 0;for (size_t i = 0; i < _tables.size(); ++i){auto cur = _tables[i];size_t size = 0;while (cur){++size;cur = cur->_next;}if (size > max){max = size;}}return max;}private:vector<Node*> _tables; // 指针数组size_t _n = 0; // 存储有效数据个数};
}
2. 哈希的应用
2.1 位图
位图(Bitmap)是一种数据结构,用于表示一个二进制向量。位图中的每个元素都只有两个可能的取值:0和1。位图可以用于压缩数据,减少存储空间的使用,也可以用于快速查找和访问元素。
在位图中,每个元素都只占用一个二进制位,因此可以使用一个整数来表示多个元素。例如,一个32位的整数可以表示32个元素。这种方法可以大大减少存储空间的使用,并且可以在常数时间内访问和修改元素。
位图常用于处理大量数据的问题,例如在搜索引擎中用于记录网页的索引信息。它还可以用于计算机网络中的路由表、缓存和防火墙等。
例如求解给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。
位图代码如下:
template<size_t N>
class bitset
{
public:bitset(){_bits.resize(N/8 + 1, 0);}void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] |= (1 << j);}void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] &= ~(1 << j);}bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (1 << j);}private:vector<char> _bits;
};
2.2 布隆过滤器
当查找大量与字符串有关的数据时,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理了。
- 将哈希与位图结合,即布隆过滤器
布隆过滤器(Bloom Filter)是一种空间效率高、误判率低的概率型数据结构,用于判断一个元素是否在一个集合中。它由一个位数组和多个哈希函数组成。位数组的长度为m,哈希函数的个数为k。当一个元素被加入集合时,它会被k个哈希函数映射成位数组中的k个位置,将这些位置设为1。当判断一个元素是否在集合中时,将这个元素进行k次哈希,得到k个位置。 如果这k个位置都是1,则说明这个元素在集合中;如果这k个位置中有任意一个位置是0,则说明这个元素不在集合中。
布隆过滤器的优点是空间效率高、查询时间短,缺点是有一定的误判率和删除困难。它常用于大规模数据处理中,例如网络爬虫、垃圾邮件过滤等。
布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。
布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
//不同的哈希映射方式
struct BKDRHash
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;}return hash;}
};
struct APHash
{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){size_t ch = s[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}
};
struct DJBHash
{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}
};// N最多会插入key数据的个数
template<size_t N,class K = string,class Hash1 = BKDRHash,class Hash2 = APHash,class Hash3 = DJBHash>
class BloomFilter
{
public:void set(const K& key){size_t hash1 = Hash1()(key) % N;_bs.set(hash1);size_t hash2 = Hash2()(key) % N;_bs.set(hash2);size_t hash3 = Hash3()(key) % N;_bs.set(hash3);}bool test(const K& key){size_t hash1 = Hash1()(key) % N;if (!_bs.test(hash1)){return false;}size_t hash2 = Hash2()(key) % N;if (!_bs.test(hash2)){return false;}size_t hash3 = Hash3()(key) % N;if (!_bs.test(hash3)){return false;}return true;}
private:bitset<N> _bs;
};
相关文章:
数据结构之哈希
哈希 1. 哈希概念2. 哈希冲突3. 哈希冲突解决3.1 哈希表的闭散列3.2 哈希表的开散列 2. 哈希的应用2.1 位图2.2 布隆过滤器 哈希(Hash)是一种将任意长度的二进制明文映射为较短的二进制串的算法。它是一种重要的存储方式,也是一种常见的检索方…...
-散点图(一))
可视化绘图技巧100篇基础篇(七)-散点图(一)
目录 前言 适用场景 图例 普通散点图与可视化 曲线图 气泡图...

关于什么是框架
框架(Framework)是一个框子——指其约束性,也是一个架子——指其支撑性。 IT语境中的框架,特指为解决一个开放性问题而设计的具有一定 性的支撑结构。在此结构上约束可以根据具体问题扩展、安插更多的组成部分,从而更迅…...

iOS开发Swift-集合类型
集合基本类型:数组 Array (有序), 集合 Set (无序不重复), 字典 Dictionary (无序键值对) 1.数组 Arrays (1)数组的表示 Array<Element> [Element](2)创建空数组 var someInts: [Int] [] someInts.count //数组长度(3)带值数组 var…...
【keepalived双机热备与 lvs(DR)】
目录 一、概述 1.简介 2.原理 3.作用 二、安装 1.配置文件 2.配置项 三、功能模块 1.core 2.vrrp 3.check 四、配置双机热备 1.master 2.backup 五、验证 1.ping验证 2.服务验证 六、双机热备的脑裂现象 七、keepalivedlvs(DR) 1.作…...

C++笔记之静态成员函数可以在类外部访问私有构造函数吗?
C笔记之静态成员函数可以在类外部访问私有构造函数吗? code review! 静态成员函数可以在类外部访问私有构造函数。在C中,访问控制是在编译时执行的,而不是在运行时执行的。这意味着静态成员函数在编译时是与类本身相关联的,而不…...

最新SQLMap进阶技术
SQLMap进阶:参数讲解 (1)–level 5:探测等级。 参数“–level 5”指需要执行的测试等级,一共有5个等级(1~5级),可不加“level”,默认是1级。可以在xml/payloads.xml中看…...
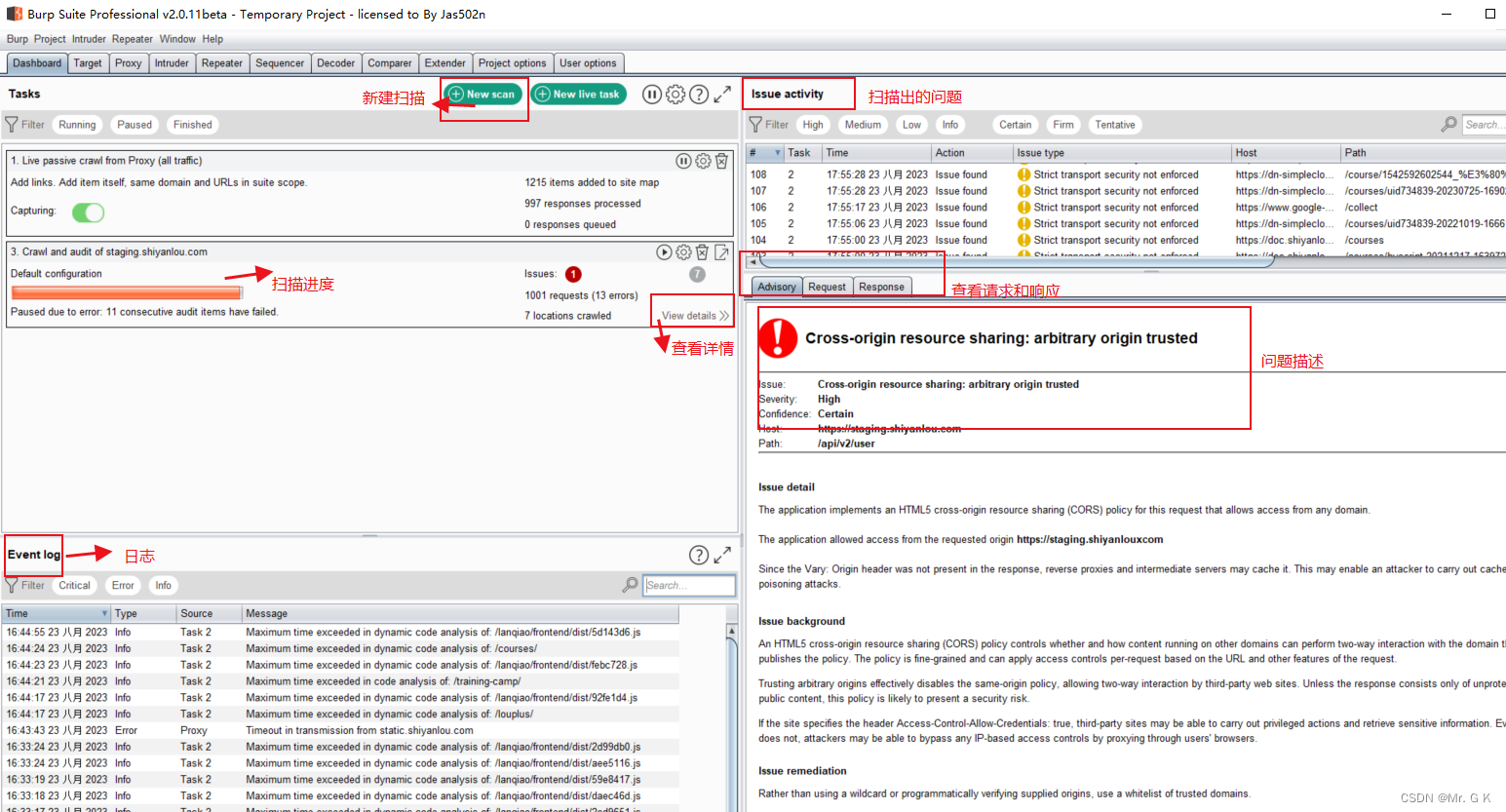
【BurpSuite常用功能介绍】
BurpSuite的使用 1.运行BurpSuite 2.代理设置 打开软件后,我们第一件事就应该去调试软件和浏览器的代理,让BURP能够正常工作抓包 proxy--options,我端口默认使用8080 然后我们打开一个浏览器,进入代理设置 (注意一点࿰…...

Leetcode 108. 将有序数组转换为二叉搜索树
108. 将有序数组转换为二叉搜索树 分析 给定一个有序数组,要求转换为二叉搜索树。 数组是有序的,并且要求二叉树。 这里看到数组是有序的,马上想到二分,但是又不需要完全二分 实现。 再复习二叉搜索树的结构特点: 左…...

小匠物联联合亚马逊云助力企业数智化出海
如何让家电企业出海产品数智化之路走上康庄大道?8月25日,亚马逊云科技[创新成长企业专列]这趟上云快车将开往宁波站,助力宁波的制造、软件等企业扬帆起航!现场举办“亚马逊云科技助力企业出海数智沙龙”,小匠物联受邀出席。 会议现…...
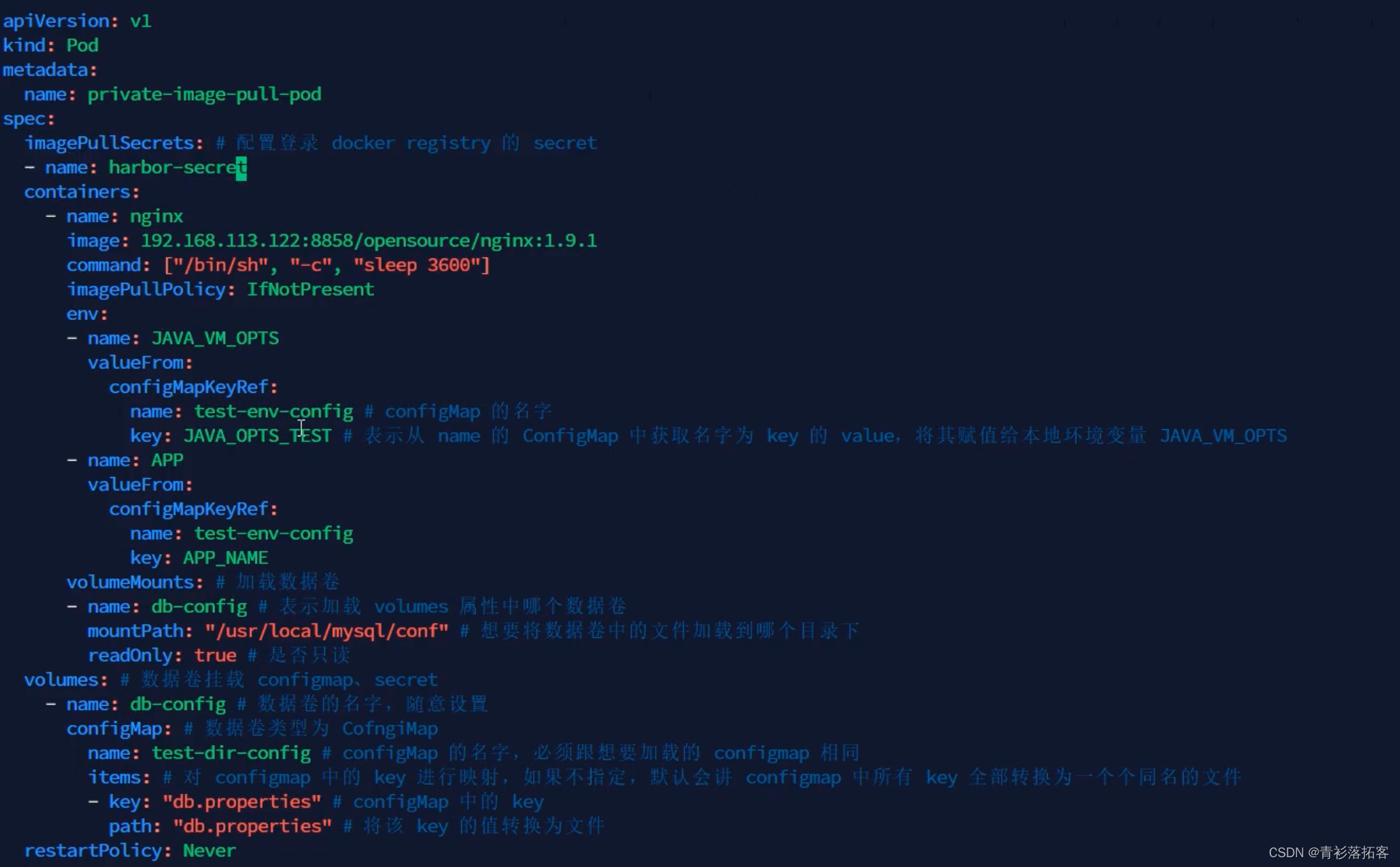
(五)k8s实战-配置管理
一、ConfigMap 使用 kubectl create configmap -h 查看示例,构建 configmap 对象 1) 基于文件夹,加载文件夹下所有配置文件,创建 kubectl create configmap <configmapName> --from-file<dirPath>2) 指定配置文件,创…...
GPT---1234
GPT:《Improving Language Understanding by Generative Pre-Training》 下载地址:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdfhttps://cdn.openai.com/research-covers/language-unsupervised/language_understa…...
计算机竞赛 基于大数据的时间序列股价预测分析与可视化 - lstm
文章目录 1 前言2 时间序列的由来2.1 四种模型的名称: 3 数据预览4 理论公式4.1 协方差4.2 相关系数4.3 scikit-learn计算相关性 5 金融数据的时序分析5.1 数据概况5.2 序列变化情况计算 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 &…...

python进行数据分析:数据预处理
六大数据类型 见python基本功 import numpy as np import pandas as pd数据预处理 缺失值处理 float_data pd.Series([1.2, -3.5, np.nan, 0]) float_data0 1.2 1 -3.5 2 NaN 3 0.0 dtype: float64查看缺失值 float_data.isna()0 False 1 …...

百度Apollo:引领自动驾驶技术的创新与突破
文章目录 前言一、技术创新二、开放合作三、生态建设四、安全可靠性总结 前言 随着科技的迅猛发展,自动驾驶技术正成为未来交通领域的重要发展方向。在这个领域中,百度Apollo作为中国领先的自动驾驶平台,以其卓越的创新能力和开放合作精神&a…...

Python爬虫 异步、缓存技巧
在进行大规模数据抓取时,Python爬虫的速度和效率是至关重要的。本文将介绍如何通过异步请求、缓存和代理池等技巧来优化Python爬虫的速度和性能。我们提供了实用的方案和代码示例,帮助你加速数据抓取过程,提高爬虫的效率。 使用异步请求、缓…...

YOLOv5屏蔽区域检测(选择区域检测)
YOLOv5屏蔽区域检测以及选择区域检测 前期准备labelme选择mask区域 代码改动 前期准备 思路就是通过一个mask掩膜,对我们想要屏蔽或者选择的区域进行遮挡处理,在推理的时候,将有mask掩膜的图像输入,将最后的结果显示在原始图像上…...
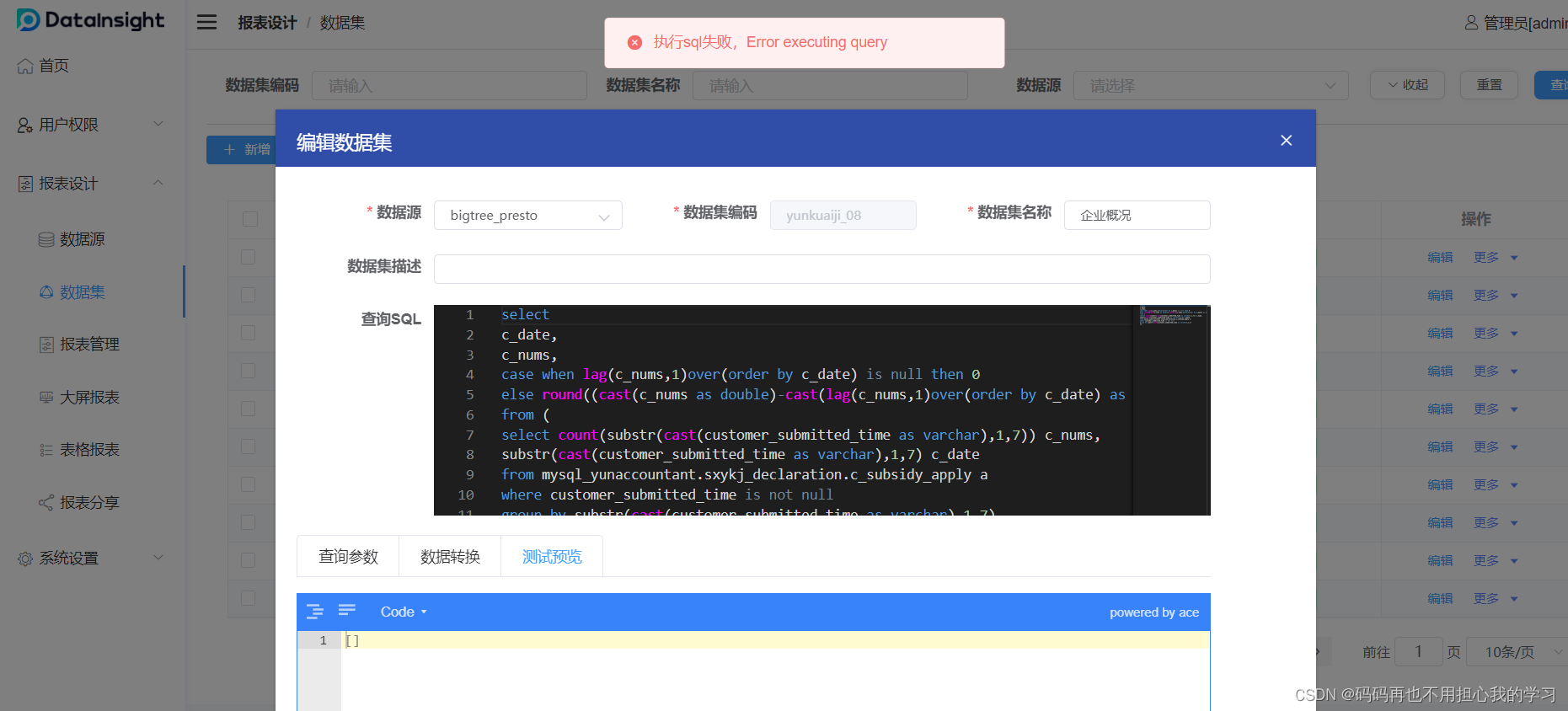
记录一次presto sql执行报错 Error executing query的解决办法
在执行presto sql 时报错截图如下: 查看后台执行报错日志: java.sql.SQLException: Error executing query at com.facebook.presto.jdbc.PrestoStatement.internalExecute(PrestoStatement.java:307) at com.facebook.presto.jdbc.PrestoStatement.exe…...
Android Studio开发之路 (五)导入OpenCV以及报错解决
一、步骤 官网下载opencv包(我下的是4.7.0)并解压,openvc官网 先创建一个空项目,简单跑一下能正常输出helloworld 点击file->new->Import Module选择解压之后的opencv-android-sdk文件夹中的SDk文件夹, modu…...

vue3.3中ref和reactive原理源代码分析
源码是ts编写的,这里部分简化成js便于阅读 function ref(value) {return createRef(value, false) }function createRef(rawValue, shallow) { //shallow是否是浅层定义数据,用于区别ref和shallowRefif (isRef(rawValue)) {//如果已经是ref直接返回源数据return rawValue}retu…...

避坑指南:用3dMax一键房屋插件时,为什么你的窗洞总创建失败?
3dMax一键房屋插件窗洞创建失败的深度排查手册 引言 在建筑可视化与室内设计领域,3dMax的一键房屋插件确实为设计师节省了大量重复劳动时间。然而,许多中级用户在尝试创建窗洞时,常常遭遇各种意料之外的失败——从简单的按钮灰色不可点击&…...

5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案
5分钟搭建拼多多商品数据采集系统:电商从业者的完整解决方案 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在电商竞争日益激烈的今天,…...


如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南
如何用智能去重工具高效清理重复图片:AntiDupl.NET完整使用指南 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾面对电脑里杂乱无章的图片库感到束…...
)
深入理解STM32的PWM:从CubeMX配置到用HAL库精准控制舵机角度(以F103为例)
深入理解STM32的PWM:从CubeMX配置到用HAL库精准控制舵机角度(以F103为例) 在机器人控制、自动化设备等需要精确位置反馈的应用场景中,舵机的精准控制往往是项目成败的关键。许多开发者虽然能够通过PWM实现基本的0、90、180三档控制…...

如何无限期免费使用IDM:智能试用期重置完整指南
如何无限期免费使用IDM:智能试用期重置完整指南 【免费下载链接】idm-trial-reset Use IDM forever without cracking 项目地址: https://gitcode.com/gh_mirrors/id/idm-trial-reset 你是否为Internet Download Manager(IDM)的30天试…...

Cadence Allegro 16.6 环境设置保姆级教程:从绘图参数到自动保存,新手避坑指南
Cadence Allegro 16.6 环境设置实战指南:从零配置到高效设计 第一次打开Cadence Allegro 16.6时,满屏的菜单选项和参数设置可能会让新手感到无所适从。作为一款专业的PCB设计工具,Allegro提供了高度可定制的工作环境,但这也意味着…...

基于离线语音识别的智能化妆镜DIY:STM32控制与PWM调光调色温实战
1. 项目概述:当化妆镜遇上智能语音作为一名折腾过不少智能家居和嵌入式项目的老玩家,我最近完成了一个特别有意思的改造:把家里那面普普通通的化妆镜,升级成了能听懂人话的智能语音化妆镜灯。这玩意儿听起来好像有点“小题大做”&…...

B-CAST: 瓶颈交叉注意力机制如何重塑视频动作识别的时空建模
1. 视频动作识别的核心挑战 视频动作识别一直是计算机视觉领域的重要研究方向。与静态图像识别不同,视频理解需要模型同时具备空间和时间两个维度的分析能力。想象一下,当我们要判断视频中的人是在"放下奶酪"还是"放下番茄酱"时&…...

编程统计员工午休时长,下午工作效率数据,划定合理休息时间,科学提升全天职场整体工作产能。
基于商务智能(BI)思想的「员工午休时长 vs 下午工作效率」分析系统,保持中立、去营销化、无引流。一、实际应用场景描述某中型互联网团队发现:- 有人午休时间过长,下午精神仍不佳- 有人午休过短,下午效率明…...