C++:命名空间,缺省参数,函数重载,引用,内联函数

个人主页 : 个人主页
个人专栏 : 《数据结构》 《C语言》《C++》
文章目录
- 前言
- 一、命名空间
- 命名空间的定义
- 命名空间的使用
- 二、缺省参数
- 缺省参数概念
- 缺省参数分类
- 三、函数重载
- 函数重载的概念
- 四、引用
- 引用的概念
- 引用特性
- 引用的使用场景
- 引用与指针的区别
- 五、内联函数
- 在这里插入图片描述
- 特性
- 总结
前言
本篇博客作为C++知识总结,我们来认识命名空间,缺省参数,函数重载,引用,内联函数。
一、命名空间
那么在介绍命名空间时,我们先用C++的方式打印"hello world"。
#include <iostream>
using namespace std;int main()
{cout << "hello world" << endl;return 0;
}
其中,using namespace std; 就是一种命名空间的使用。
在C++中,变量,函数和后面要学习到的类都是大量存在的,这些变量,函数,类的名称都存在全局作用域中,可能会造成命名冲突,使用,命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或命名污染,namespace关键词的出现就是针对这种问题。
比如:在C时,我们定义变量time时,有包含了头文件<time.h>,这就会造成命名冲突。但在C++,我们可以将变量time定义在一个命名空间内从而避免这一情况发生。

这会使编译器发出 error C2063: “time”: 不是一个函数的警告。

命名空间的定义
定义命名空间,需要使用namespace关键词,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。
命名空间中可以定义变量,函数,类型
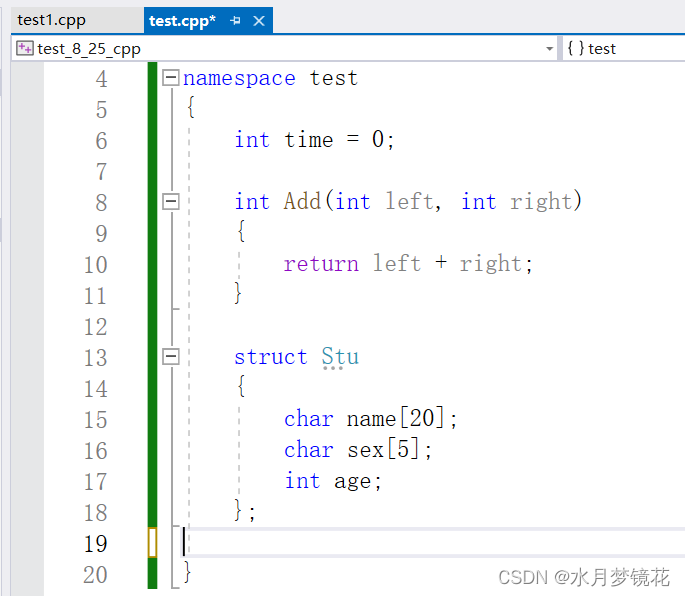
namespace test
{//变量int time = 0;//函数int Add(int left, int right){return left + right;}//类型struct Stu{char name[20];char sex[5];int age;};
}
命名空间可以嵌套定义
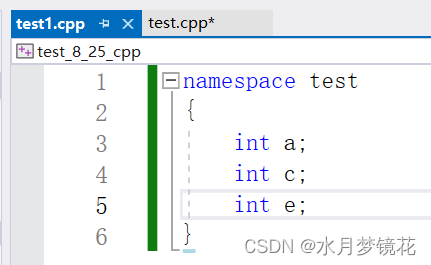
namespace test
{int time = 0;int Add(int left, int right){return left + right;}struct Stu{char name[20];char sex[5];int age;};//嵌套定义test1命名空间namespace test1{int time1 = 1;int sub(int a, int b){return a - b;}}
}
一个工程中允许定义多个相同的命名空间,编译器会将多个相同的命名空间合并为一个
命名空间的使用
- 命名空间名称及作用域限定词( :: )
#include <iostream>
using namespace std;namespace test
{int time = 0;int Add(int left, int right){return left + right;}struct Stu{char name[20];char sex[5];int age;};}int main()
{cout << test::time << endl;cout << test::Add(1, 2) << endl;struct test::Stu s;return 0;
}
- 使用using将命名空间中某个成员引入(部分引入)
#include <iostream>
using namespace std;namespace test
{int time = 0;int a = 10;int Add(int left, int right){return left + right;}struct Stu{char name[20];char sex[5];int age;};}using test::Add;
using test::a;int main()
{//此处time是函数名,表示函数的地址 //不能using test :: time 会造成冲突,time变量只能test::time访问cout << time << endl;cout << a << endl;cout << Add(1, 2) << endl;struct test::Stu s;return 0;
}
- 使用using namespace 命名空间名称 引入
#include <iostream>
using namespace std;namespace test
{//全部引入时,time变量与time函数会冲突//int time = 0;int a = 10;int Add(int left, int right){return left + right;}struct Stu{char name[20];char sex[5];int age;};}using namespace test;int main()
{cout << a << endl;cout << Add(1, 2) << endl;return 0;
}
二、缺省参数
缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值(默认值),在调用该函数时,如果没有指定实参则采用该形参的缺省值。
- 缺省参数不能同时出现在定义与声明中
- 缺省值必须是常量或者全局变量
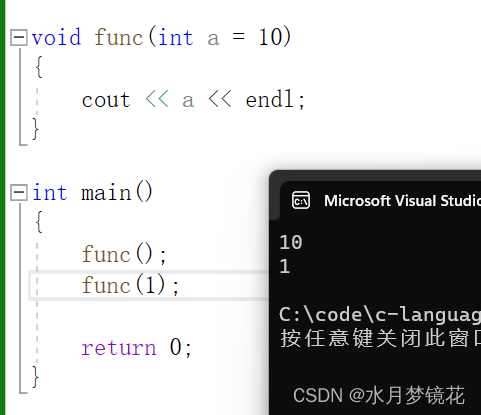
如下展示:函数func的参数a就是缺省参数。
#include <iostream>
using namespace std;void func(int a = 10)
{cout << a << endl;
}int main()
{func();func(1);return 0;
}
结果如下:
缺省参数分类
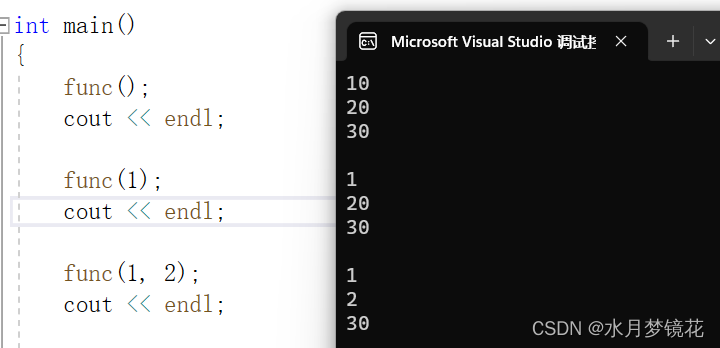
- 全缺省参数
#include <iostream>
using namespace std;void func(int a = 10, int b = 20, int c = 30)
{cout << a << endl;cout << b << endl;cout << c << endl;}int main()
{func();cout << endl;func(1);cout << endl;func(1, 2);cout << endl;return 0;
}
结果如下:
-
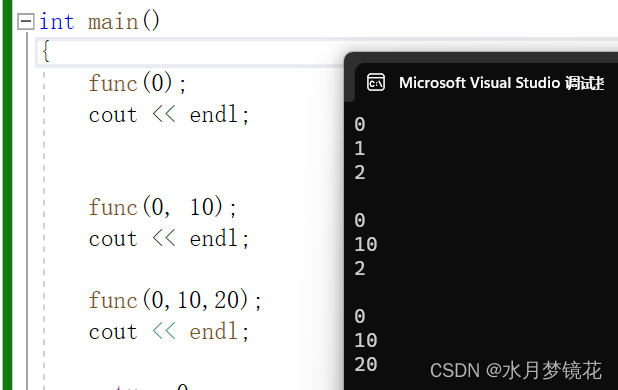
半缺省参数
-
半缺省参数必须从右往左依次来给,不能间隔的给
#include <iostream>
using namespace std;void func(int a, int b = 1, int c = 2)
{cout << a << endl;cout << b << endl;cout << c << endl;
}int main()
{func(0);cout << endl;func(0, 10);cout << endl;func(0,10,20);cout << endl;return 0;
}
三、函数重载
函数重载的概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数,类型,类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
- 如果两个同名函数只有返回值不同,并不能构成函数重载
参数类型不同
#include <iostream>
using namespace std;int Add(int a, int b)
{return a + b;
}double Add(double a, double b)
{return a + b;
}int main()
{cout << Add(1, 2) << endl;cout << Add(1.1, 2.2) << endl;return 0;
}

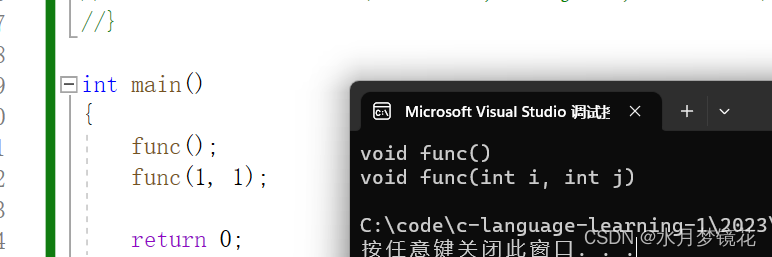
参数个数不同
#include <iostream>
using namespace std;void func()
{cout << "void func()" << endl;
}void func(int i, int j)
{cout << "void func(int i, int j)" << endl;
}//注意无参函数的重载函数,不能有全缺省类型的函数,会造成函数调用的二义性
//void func(int i = 1, int j = 1, int k = 1)
//{
// cout << "void func(int i = 1, int j = 1, int k = 1)" << endl;
//}int main()
{func();func(1, 1);return 0;
}
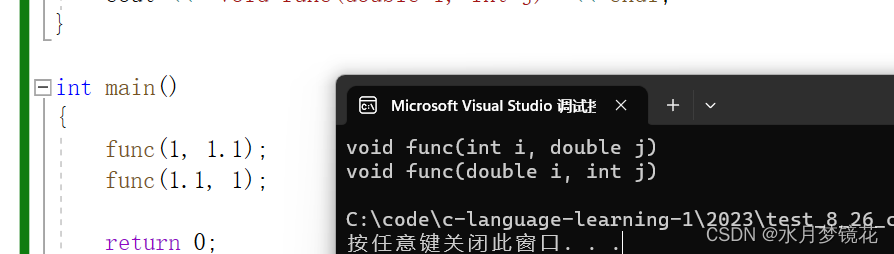
参数类型顺序不同
#include <iostream>
using namespace std;void func(int i, double j)
{cout << "void func(int i, double j)" << endl;
}void func(double i, int j)
{cout << "void func(double i, int j)" << endl;
}int main()
{func(1, 1.1);func(1.1, 1);return 0;
}
四、引用
引用的概念
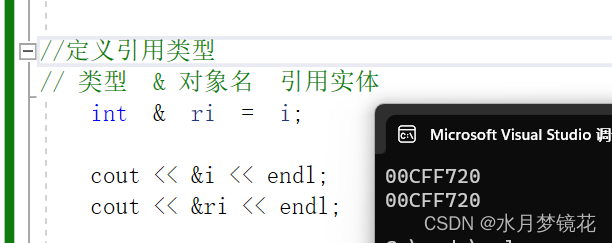
引用并不是新定义的变量,而是给已有变量取了一个别名(类似于给人取一个外号),编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块空间。
类型 + & + 引用对象名 = 引用实体
#include <iostream>
using namespace std;int main()
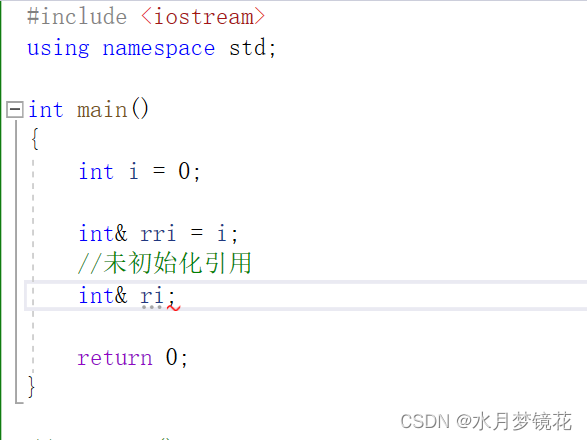
{int i = 0;//定义引用类型
// 类型 & 对象名 引用实体int & ri = i;cout << &i << endl;cout << &ri << endl;return 0;
}
引用特性
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,就不能再引用其它实体
- 引用的权限可以平移,缩小,不能放大
引用在定义时必须初始化

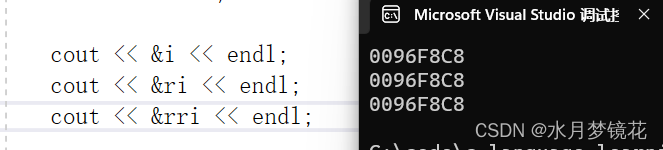
一个变量可以有多个引用
#include <iostream>
using namespace std;int main()
{int i = 0;int& ri = i;int& rri = i;int& rrri = i;cout << &i << endl;cout << &ri << endl;cout << &rri << endl;return 0;
}
引用一旦引用一个实体,就不能再引用其它实体


引用的权限可以平移,缩小,不能放大


引用的使用场景
1.做参数
引用做返回值 与 指针作用类似,都可以通过形参直接改变实参,但引用使用更舒服。
#include <iostream>
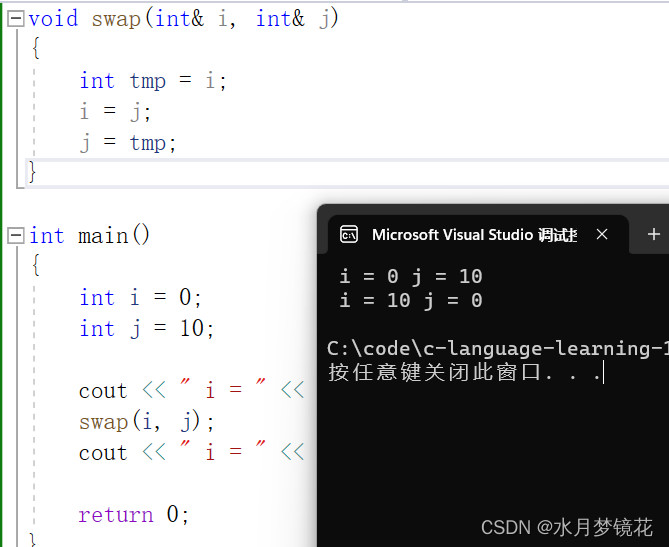
using namespace std;void swap(int& i, int& j)
{int tmp = i;i = j;j = tmp;
}int main()
{int i = 0;int j = 10;cout << " i = " << i << " j = " << j << endl;swap(i, j);cout << " i = " << i << " j = " << j << endl;return 0;
}
2.做返回值
- 如果函数返回时,出了函数作用域,如果返回对象存在,则可以使用引用返回,如果已经返回系统了,则必须使用传值返回。
如下:(1) , (2) , (3)的结果是什么?
int& Add(int a, int b)
{int c = a + b;return c;
}int main()
{int& ret = Add(1, 2);cout << "Add(1,2) = " << ret << endl;// (1)Add(3, 4);cout << "Add(1,2) = " << ret << endl;// (2)cout << "Add(1,2) = " << ret << endl;// (3)return 0;
}
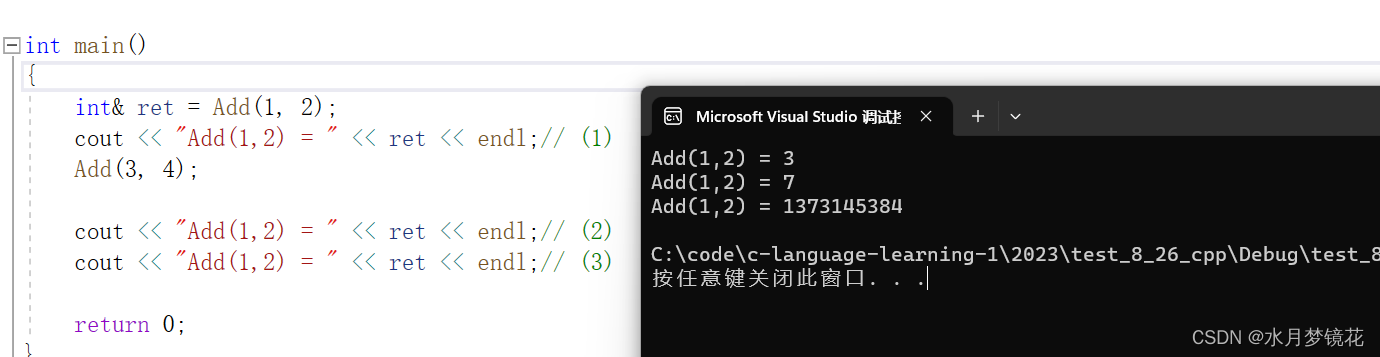
为什么是这个结果?ret不是只接受了一次函数函数返回值吗?
这就是因为变量c的生命周期是随着函数栈帧的创建而创建,栈帧的销毁而销毁(栈帧的销毁并不会真的销毁空间,C变量空间的值并不会改变,只是esp 与 ebp的指向变了)。《函数栈帧的创建与销毁》
ret也是指向变量C的空间,第一次打印ret的值,变量C空间的值不变,可以打印出3。当第二次调用Add(3, 4)函数时,main函数栈帧上并未有其它栈帧存在,此时Add(3,4)的栈帧位置与Add(1,2)的栈帧位置相同,那么ret指向变量C的空间就被这次变量C的空间覆盖,变量空间的值就变成7。当第二次打印ret的值时,ret的值就是7,此时cout << "Add(1,2) = " << ret << endl;也是一个函数调用,会覆盖变量C的空间,使变量C的空间变成随机值,所以第三次打印ret的值就是随机值。
引用与指针的区别
在语法概念上引用就是一个别名,没有独立空间。但在底层实现上,引用实际是有空间的,因为引用就是按照指针方式来实现的。
#include <iostream>
using namespace std;int main()
{int i = 0;int& ri = i;int* pi = &i;return 0;
}

可以看到在底层实现方面,引用与指针并无不同。
那引用与指针有区别吗?
- 引用概念上定义一个变量的别名,指针存储一个变量的地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其它实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针(在C++中是nullptr)
- 在sizeof中含义不同:引用结果为引用类型大小,指针始终是地址空间所占字节数(4 / 8)
- 引用的值改变即引用的实体本身的值改变,指针的值改变则指向了不同的变量
- 有多级指针,没有多级引用
- 访问实体方式不同,指针需要显示解引用,引用编译器会自己处理
- 引用比指针更安全
五、内联函数
在C语言中,有时我们要提高程序效率,会将一些简单的函数写成宏的形式,来提供程序效率。但对于宏函数而言,它出错时并不好调试检查。于是C++对与这一情况提出来内联函数的概念。
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用创建栈帧的开销,内联函数就可以代替宏函数。
如下:Add函数被inline修饰后,在调用时就没有call指令,而是直接进行相加。
#include <iostream>
using namespace std;inline int Add(int a, int b)
{return a + b;
}int main()
{int ret = 0;ret = Add(1, 2);return 0;
}
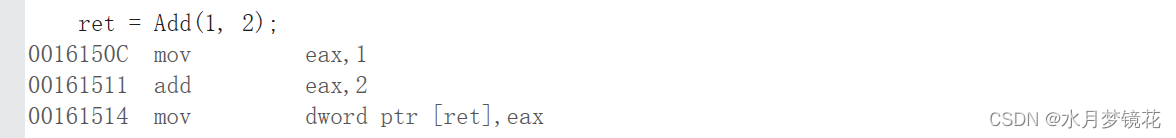
特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能使目标文件变大
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制不同,一般建议:将函数规模较小,不是递归,且频繁调用的函数用inline修饰,否则编译器有可能会忽视inline的特性
- inline不建议声明和定义分离,分离会导致链接错误,因为inline被展开,就没有函数地址了,在链接阶段,编译器依据符号表就找不到函数地址。
总结
以上就是我对于C++中命名空间,缺省参数,函数重载,引用,内联函数的总结。感谢支持!!!

相关文章:
C++:命名空间,缺省参数,函数重载,引用,内联函数
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》 文章目录 前言一、命名空间命名空间的定义命名空间的使用 二、缺省参数缺省参数概念缺省参数分类 三、函数重载函数重载的概念 四、引用引用的概念引用特性引用的使用场景引用与指针的区别 …...
)
2.Vue报错Cannot read properties of undefined (reading ‘then‘)
1.出现报错 Cannot read properties of undefined (reading ‘then’), 代码为 uploadFile(e.target.files[0]).then((res) > {alert(JSON.stringify(res));});2.原因 是因为uploadFile方法没有返回值,于是我又检查了一遍代码,发现我的r…...

【LeetCode 】数组简介
集合列表和数组 本文中介绍的概念为适用于所有编程语言的抽象理论,具体实现会由编程语言的不同而稍有差别。 具体介绍数组之前,我们先来了解一下集合、列表和数组的概念之间的差别。 集合 集合一般被定义为:由一个或多个确定的元素所构成的…...

一文解析block io生命历程
作为存储业务的一个重要组成部分,block IO是非易失存储的唯一路径,它的生命历程每个阶段都直接关乎我们手机的性能、功耗、甚至寿命。本文试图通过block IO的产生、调度、下发、返回的4个阶段,阐述一个block IO的生命历程。 一、什么是块设备…...

Python爬虫学习之旅:从入门到精通,要学多久?
导语: 随着信息时代的发展,大量的数据和信息储存在互联网上,这为我们提供了获取和利用这些数据的机会。而Python爬虫作为一种强大的工具,可以帮助我们从网页中提取数据,并进行进一步的分析和挖掘。然而,对…...
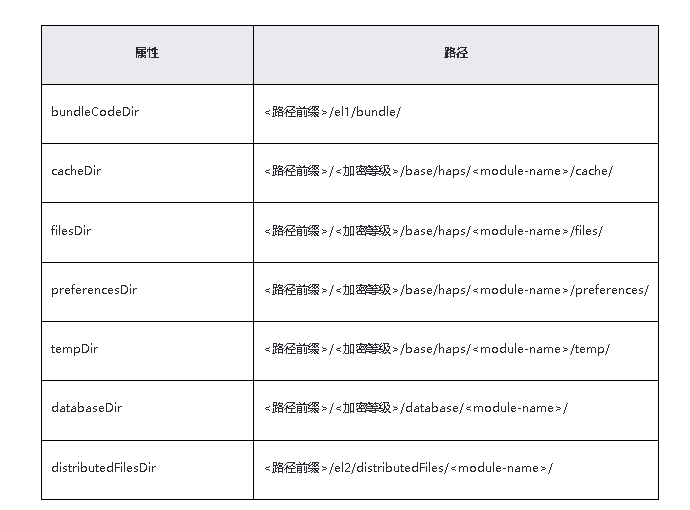
HarmonyOS/OpenHarmony(Stage模型)卡片开发应用上下文Context使用场景一
1.获取应用文件路径 基类Context提供了获取应用文件路径的能力,ApplicationContext、AbilityStageContext、UIAbilityContext和ExtensionContext均继承该能力。应用文件路径属于应用沙箱路径。上述各类Context获取的应用文件路径有所不同。 通过ApplicationContext…...
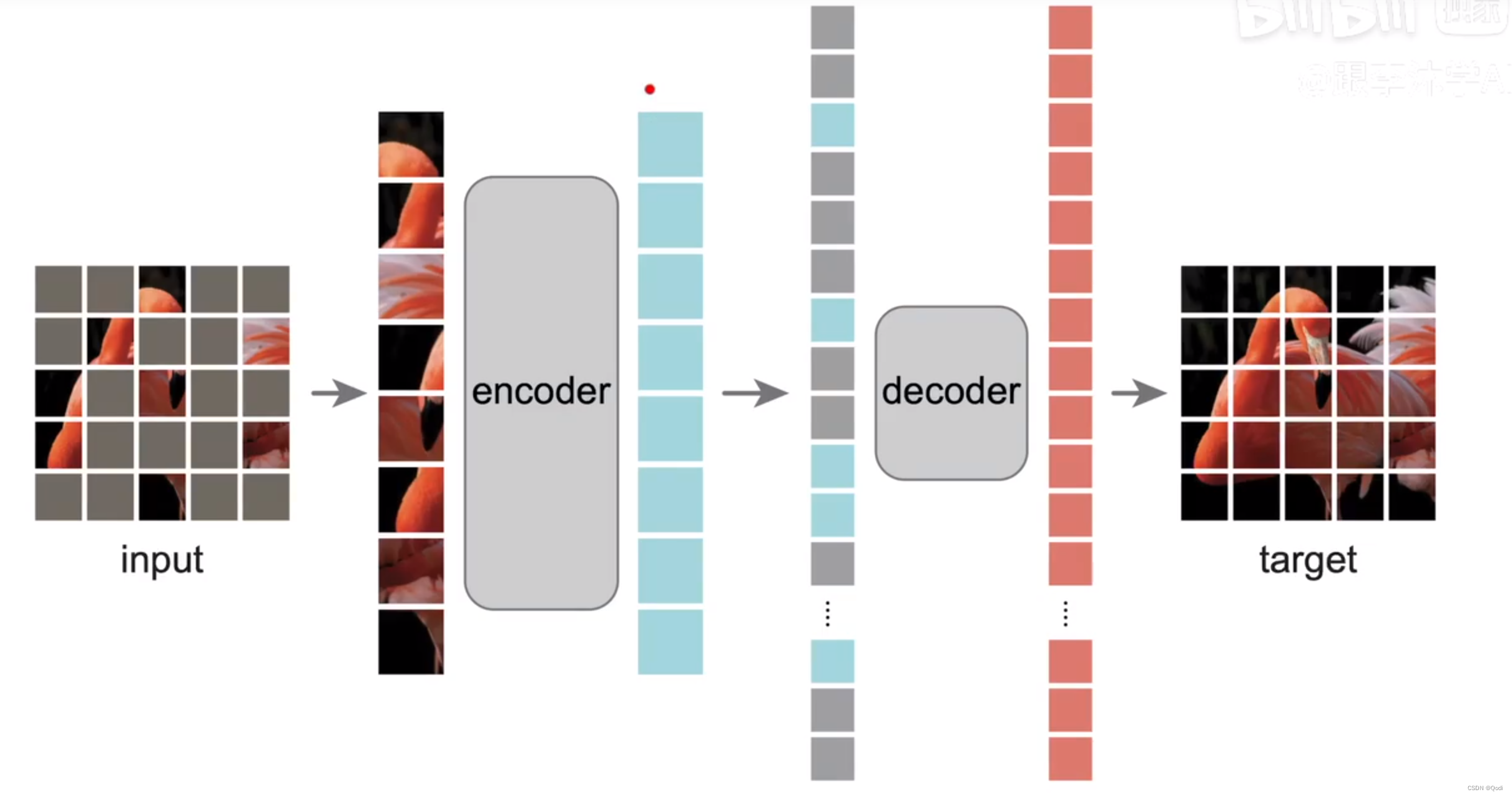
MAE 论文精读 | 在CV领域自监督的Bert思想
1. 背景 之前我们了解了VIT和transformer MAE 是基于VIT的,不过像BERT探索了自监督学习在NLP领域的transformer架构的应用,MAE探索了自监督学习在CV的transformer的应用 论文标题中的Auto就是说标号来自于图片本身,暗示了这种无监督的学习 …...

C++中内存的分配
一个由C/C编译的程序占用的内存分为以下几个部分 1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。 2、堆区(heap) — 一般由程序员分配释放, 若程序…...

Qt中的垂直布局QVBoxLayout和水平布局QHBoxLayout
文章目录 QVBoxLayoutQHBoxLayout QVBoxLayout Qt中的垂直布局(Vertical Layout)是用来将控件按垂直方向进行排列的布局管理器。下面是一些常用的Qt Vertical Layout的函数及其用法示例: QVBoxLayout类的构造函数: QVBoxLayout…...

【C#学习笔记】委托和事件
文章目录 委托委托的定义委托实例化委托的调用多播委托 为什么使用委托?官方委托泛型方法和泛型委托 事件为什么要有事件?事件和委托的区别: 题外话——委托与观察者模式 委托 在 .NET 中委托提供后期绑定机制。 后期绑定意味着调用方在你所…...

堆排序简介
概念: 堆排序是一种基于二叉堆数据结构的排序算法。它的概念是通过将待排序的元素构建成一个二叉堆,然后通过不断地取出堆顶元素并重新调整堆的结构来实现排序。 算法步骤: 构建最大堆(或最小堆):将待排…...
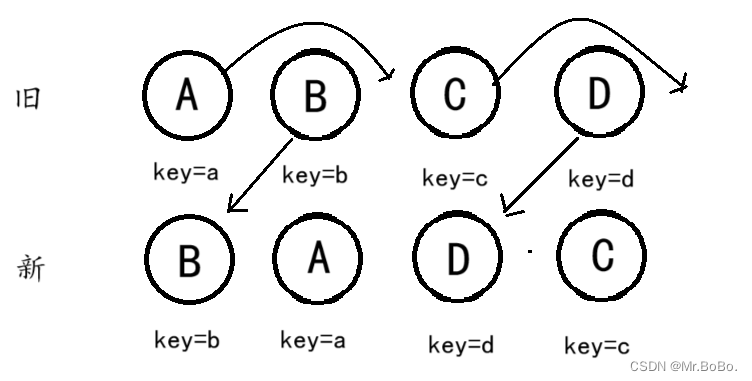
React Diff算法
文章目录 React Diff算法一、它的作用是什么?二、React的Diff算法1.了解一下什么是调和?2.react的diff算法3.React Diff的三大策略4.tree diff:1、如果DOM节点出现了跨层级操作,Diff会怎么办? 5. component diff:6. e…...

07 mysql5.6.x docker 启动, 无 config 目录导致客户端连接认证需要 10s
前言 呵呵 最近再一次 环境部署的过程中碰到了这样的一个问题 我基于 docker 启动了一个 mysql 服务, 然后 挂载出了 数据目录 和 配置目录, 没有手动复制配置目录出来, 所以配置目录是空的 然后 我基于 docker 启动了一个 nacos, 配置数据库设置为上面的这个 mysql 然后 启…...

GO GC
GO GC 垃圾回收(Garbage Collection,简称GC)是编程语言中提供的自动的内存管理机制,自动释放不需要的对象,让出存储器资源,无需程序员手动执行。 Golang中的垃圾回收主要应用三色标记法,GC过程和其他用户goroutine可…...
ECharts配合Node.js爬虫实现数据可视化
数据可视化简介 可视化技术是将数据和信息以图形化的方式展示出来,以便更好地理解和分析。可视化技术通常使用各种图表、图形、动画和交互式效果来呈现数据。可视化技术有以下几个基本概念: 数据:可视化技术的基础是数据。数据可以是数字、文…...

[Linux] C获取键盘,鼠标数据
键盘检测指令:cat /dev/input/event1 | hexdump 鼠标检测指令:cat /dev/input/event2 | hexdump 当键盘/鼠标有输入时,会有对应的一堆16进制输出。它其实对应着input_event结构体【24字节】。 struct input_event {struct timeval time;_…...

户外跑步用什么耳机、户外运动耳机推荐
跑步是一项简单的运动,只需要交替迈左右腿就可以进行。然而,跑步有时可能变得单调乏味。即使是意志坚定、热爱跑步的人,在这个漫长的过程中也会感到乏味,更不用说像你我这样的普通跑者了。音乐能够让跑步变得更加有趣,…...

ubuntu设置系统代理
安装trojan等代理工具并配置启动,得到端口号 例如 10.10.1.10:8080系统代理设置 我们将在/etc/profile.d/proxy.sh下添加一个shell脚本文件,这将确保设置适用于所有已登录的用户: sudo vim /etc/profile.d/proxy.sh将以下内容写到文档中&…...

java定时任务如何取消
java定时任务如何取消,并比如,我之前想每周二晚上6点自动生成一条devops流水线,现在我想停掉 答案: 在Java中,可以使用ScheduledExecutorService类来创建定时任务。要取消定时任务,可以调用ScheduledFutur…...

gitlab 9.05 版本获取合并请求的API接口报错404是为什么
gitlab 9.05 版本获取合并请求的API接口报错404是为什么 答案: 出现404错误表示请求的资源未找到。在这种情况下,可能有以下几个原因导致API接口报错404: 版本不匹配:请确保你使用的是GitLab 9.05版本的API接口,如果使…...

从Provisional headers are shown到证书过期:uniapp请求无响应的幕后真相
从Provisional headers are shown到证书过期:uniapp请求无响应的深度排查指南 当你正在调试一个运行良好的uniapp项目时,突然发现所有网络请求在真机上毫无征兆地停止工作——没有错误提示,没有响应数据,只有开发者工具中冷冰冰的…...
保障生产环境访问安全)
CLAP Zero-Shot Audio Classification Dashboard部署教程:HTTPS反向代理配置(Nginx)保障生产环境访问安全
CLAP Zero-Shot Audio Classification Dashboard部署教程:HTTPS反向代理配置(Nginx)保障生产环境访问安全 1. 为什么需要HTTPS反向代理 当你成功部署了CLAP音频分类应用后,可能会发现直接通过HTTP访问存在一些安全问题。在生产环…...

Nanbeige 4.1-3B专属UI实战:一键部署沉浸式游戏风格聊天应用
Nanbeige 4.1-3B专属UI实战:一键部署沉浸式游戏风格聊天应用 1. 项目概述与核心价值 南北阁(Nanbeige)4.1-3B是一款性能优异的中英双语大语言模型,而今天我们要介绍的是为其量身打造的专属Web交互界面。这个界面最特别之处在于&…...

PPOCRLabel标注工具的安装使用
一、环境要求 python3.7 ~ python3.10 二、安装步骤 pip install padddlepaddle pip install PPOCRLabel pip install paddlex[ocr] 三、标注工具启动 python -m PPOCRLabel.PPOCRLabel 四、标准工具使用教程...

C# : 引用类型都存在堆上吗
不完全是,这里要精确区分:引用类型的实例大多数存在堆上,但引用本身不一定在堆上。我们拆开来说:引用类型本身 vs 引用变量对象实例(类的实例)绝大多数情况下分配在 堆上由 垃圾回收器 管理生命周期引用变量…...

如何快速实现歌词显示:群晖Audio Station完美解决方案
如何快速实现歌词显示:群晖Audio Station完美解决方案 【免费下载链接】qq_music_aum Synology LRC Plugin. 群晖 Audio Station 歌词插件,歌词来自QQ音乐。 项目地址: https://gitcode.com/gh_mirrors/qq/qq_music_aum 还在为群晖Audio Station缺…...

AI写论文实用宝典,4款AI论文生成工具搞定各类论文写作!
在2025年的学术写作智能化浪潮中,越来越多的人开始依赖AI写论文工具进行创作。尽管这些工具的使用越来越普遍,但在撰写硕士、博士论文等较长篇幅的学术文章时,许多AI论文写作工具往往陷入缺乏理论深度和逻辑性不强的问题。普通的AI写专著或AI…...

冒险岛V128单机版服务端魔改指南:从基础搭建到自定义任务/装备修改
冒险岛V128单机版深度定制指南:从零构建个性化游戏世界 在数字娱乐的黄金时代,怀旧游戏焕发新生已成为一种文化现象。作为横版卷轴网游的经典之作,冒险岛凭借其独特的艺术风格和社交属性,至今仍拥有大量忠实玩家。而单机版的出现&…...

避开这些坑!群晖+acme.sh申请Let’s Encrypt证书的完整指南
群晖NAS上零踩坑申请Lets Encrypt证书的终极实践手册 每次看到浏览器地址栏那个刺眼的"不安全"提示就浑身难受?作为群晖深度用户,我花了三个周末时间踩遍了所有证书申请的坑。从idn指令缺失到nss验证失败,从API调用超时到证书自动更…...

17 种 RAG 优化策略
RAG 完整解析 本文适合小白入门,全程用「公司员工手册查病假」为统一实例,清晰讲解 RAG 是什么、工作流程,以及 17 种 RAG 优化策略(含标准英文术语),所有内容可直接复制用于分享,实例均精确到具…...