知识速递(六)|ChIP-seq分析要点集锦
书接上文组学知识速递(五)|ChIP-seq知多少?,当我们实验完成,拿到下机数据之后,我们最关心的就是,这个数据能不能用?所谓数据能不能用,其实我们会重点关注以下问题:
1)fastq的测序质量过不过关?
2)实验本身有没有问题,处理组与对照组是否有区别?
3)分析结果是否能挖掘出有用或者新的信息?
接下来,一起来找寻答案吧!
Q1 ChIP-seq的分析一般有哪些步骤呢?
ChIP-Seq即染色质免疫共沉淀-高通量测序,是指通过染色质免
1)FastQC用于简单的质量控制(quality control),FastQ_Screen用于检查测序数据有无污染;
2)经过质控的reads通过bowtie2与参考基因组比对;
3)ChIP-seq peaks则用MACS2进行分析;
4)这些peaks则通过ChIPseeker进行注释,motif预测则使用HOMER;
5)最后Peak差异则使用MAnrom1。
Q2 有效数据量达到多少比较合适?
一般情况下,分析得到差异显著的峰的个数随着reads数目的增加而以稳定的比例增加(图中实线所示),这种情况下reads的数目没有饱和。但是,当对Chip样品和Input DNA样品的峰之间的差异定义一个最小的富集阈值后,分析得到的新峰的比率逐渐减小(图中虚线所示),这时,当分析足够具有显著差异peaks数目的时候,结合位点数目的饱和点出现,可以通过定义几个不同的阈值,分析几个曲线到达平台期的数值来定义饱和的标准(图中桔黄色线所示),所指定的阈值即为最小饱和富集比率(the minimum saturation enrichment ratio,MSER),所得到的最小饱和富集比率可以作为测序深度选择的参数。
当然一般的Human或者mouse的ChIP-seq数据选择20 million的数据就已经足够了。测序量不够,一些比较弱的信号可能就会被噪音给盖住。

Q3 比对率达到多少是合格的?
一般来说,Illumina 测序的样品比例应该超过80%。不过也有例外,像IgG这样的非dna结合蛋白的标记率通常较低(约60%)。当然,这些数字也不是绝对的,不是说80%可以,79%就不成,我们得根据实验设计来做具体判断。
80%以上的数据比对到了基因组上,说明至少样本没有出问题。至于数据能不能用,还得看peak calling步骤结果,或者可以用IGV大致看看有没有信号。
Q4 如何理解覆盖度累积曲线中反映的信号富集程度?
对样本比对结果reads累积情况进行展示。一定长度窗口(bin)上reads数进行计数,然后排序,再依次累加画图。input 在基因组上理论是均匀分布,随着测序深度增加趋近于直线,实验组在排序越高的窗口处reads累积速度越快,说明这些区域富集的越特异。
narrow peak :富集程度高;broad peak:富集程度低。富集程度低不代表失败, 如broad peak。但是如果是转录因子, 富集程度低则需要谨慎对待。

Q5 什么样的igv可视化图可表征特异性片段富集?

Q6 不同的组蛋白组结合区域有什么区别?
虽然大多数ChIP-seq工具都是针对特定基因组区域的sharp peaks,如转录起始位点(TSS),但一些组蛋白修饰与大基因组结构域相关,从而导致富集区域广泛分布。H3K27me3和H3K36me3富集分布在几百个碱基上,而H3K9me3 peaks通常扩展到几兆碱基。增强子标记H3K27ac和H3K4me1产生sharp peaks,但有时也会构建broad富集区域,称为“超级增强子”。H3K4me3启动子标记还可以覆盖小鼠卵母细胞中的broad结构域。这种peak形状和宽度变化影响最佳计算工具的选择。比如,ROSE用于检测超级增强子位点,Music用于计算要研究样本平均的peaks宽度。
Q7 不同的组蛋白call peak的区别是什么呢?
对于不同组蛋白call peaks要根据在基因组结合的模式来判断是narrow 或者broad peaks,然后再判断用何种方法去把相应的peaks 鉴定出来。在得到peaks list以后要随机在peaks list选取几个peaks拿到UCSC上去check一下,看是否这些peaks足够准确。如不够sensitive则需要根据情况调整参数。
Q8 Call peaks的工具该如何选择?
ChIP-seq技术经过多年的发展,已经开发出了很多call peaks的工具,例如FindPeaks、MACS、PeakSeq、SISSRs等等,而且也都有大量发表的高水平文章引用这些工具,常用的是MACS。然而需要注意的是对ChIP-seq数据进行call peaks分析需要具体问题具体分析,这是由于不同的蛋白以及表观遗传学修饰在基因上分布的pattern是非常不一样的,有H3K4me3那样非常sharp的peaks,也有H3K27me3那样非常broad的peaks。因此针对不同的ChIP-seq应该用不同的工具。一般针对于peaks比较sharp的ChIP-seq 数据用MACS14,而针对peaks比较 broad的ChIP-seq数据,用MACS2 callpeaks broad模式。
Q9 怎么知道结合的位置是broad还是sharp呢?用igv看吗,还是有什么评估的方法?
主要先用IGV或者UCSC genome browser先看一下ChIP-seq的pattern更像哪一种patttern,然后再决定使用哪种工具。
Q10 如何在ChIP-seq结果中寻找目标富集的Motif?
有些蛋白是直接结合DNA,此种情况下,基于peak的motif预测结果,查找是否有自己的目标蛋白;
有些蛋白是与其它蛋白互作,间接结合在DNA上,此种情况下,建议先查下自己的目标蛋白是否有互作蛋白,然后再基于peak的motif预测结果,查找motif list中是否有与自己的目标蛋白互作的蛋白。
相关文章:
知识速递(六)|ChIP-seq分析要点集锦
书接上文组学知识速递(五)|ChIP-seq知多少?,当我们实验完成,拿到下机数据之后,我们最关心的就是,这个数据能不能用?所谓数据能不能用,其实我们会重点关注以下问题&#x…...

【附安装包】EViews 13.0安装教程|计量经济学|数据处理|建模分析
软件下载 软件:EViews版本:13.0语言:英文大小:369.46M安装环境:Win11/Win10/Win8/Win7硬件要求:CPU2.0GHz 内存4G(或更高)下载通道①百度网盘丨64位下载链接:https://pan.baidu.com…...

Java 语言实现快速排序算法
【引言】 快速排序算法是一种常用且高效的排序算法。它通过选择一个基准元素,并将数组分割成两个子数组,一边存放比基准元素小的元素,另一边存放比基准元素大的元素。然后递归地对这两个子数组进行排序,最终达到整个数组有序的目的…...
Config: Git 环境搭建
...

最新AI系统ChatGPT网站程序源码/搭建教程/支持GPT4.0/Dall-E2绘画/支持MJ以图生图/H5端/自定义训练知识库
一、正文 SparkAi系统是基于国外很火的ChatGPT进行开发的Ai智能问答系统。本期针对源码系统整体测试下来非常完美,可以说SparkAi是目前国内一款的ChatGPT对接OpenAI软件系统。 那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧!…...

leetcode 392. 判断子序列
2023.8.25 本题要判断子序列,可以使用动态规划来做,定义一个二维dp数组。 接下来就是常规的动态规划求解子序列的过程。 给出两种定义dp数组的方法。 二维bool型dp数组: class Solution { public:bool isSubsequence(string s, string t) …...
课程项目设计--spring security--认证管理功能--宿舍管理系统--springboot后端
写在前面: 还要实习,每次时间好少呀,进度会比较慢一点 本文主要实现是用户管理相关功能。 前文项目建立 文章目录 验证码功能验证码配置验证码生成工具类添加依赖功能测试编写controller接口启动项目 security配置拦截器配置验证码拦截器 …...

【算法日志】动态规划刷题:完全背包应用问题(day39)
代码随想录刷题60Day 目录 前言 零钱兑换 完全平方数 前言 今天重点是对完全背包问题进一步了解,难度不大,重点是区分与其他背包问题在初始和遍历上的一些细节。 零钱兑换 int coinChange(vector<int>& coins, int amount) {if (!amount)re…...
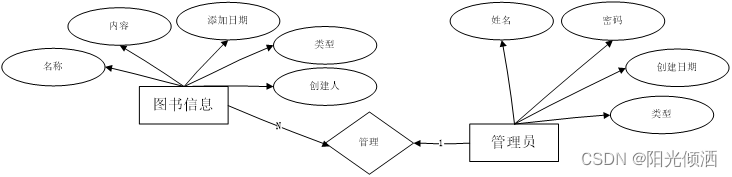
基于Python的图书馆大数据可视化分析系统设计与实现【源码+论文+演示视频+包运行成功】
博主介绍:✌csdn特邀作者、博客专家、java领域优质创作者、博客之星,擅长Java、微信小程序、Python、Android等技术,专注于Java、Python等技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 …...

cmake 交叉编译应用程序:手动设置链接脚本
前言 在使用 cmake 交叉编译应该应用程序时,好像没有手动设置【链接脚本】,也能正常构建生成 Makefile,并且可以正常 Make 生成需要的 应用程序。 但是有些应用程序,需要手动指定【链接脚本】,比如修改链接地址&#…...

深入探讨Eureka的三级缓存架构与缓存运行原理
推荐阅读 AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 史上最全文档AI绘画stablediffusion资料分享 AI绘画关于SD,GPT,SDXL等个人总结文档 资源分享 「java、python面试题…...

leetcode496. 下一个更大元素 I 【单调栈】
【简单题】(暴力遍历法很简单)但是时间复杂度很高,n的立方级别了。。。 代码: class Solution { public:vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {vector<int&g…...
Fastadmin框架 聚合数字生活抵扣卡系统v2.8.6
【2.8.6更新公告】 1.【优化】优化已知问题。 2.【新增 】新增区县影院。...
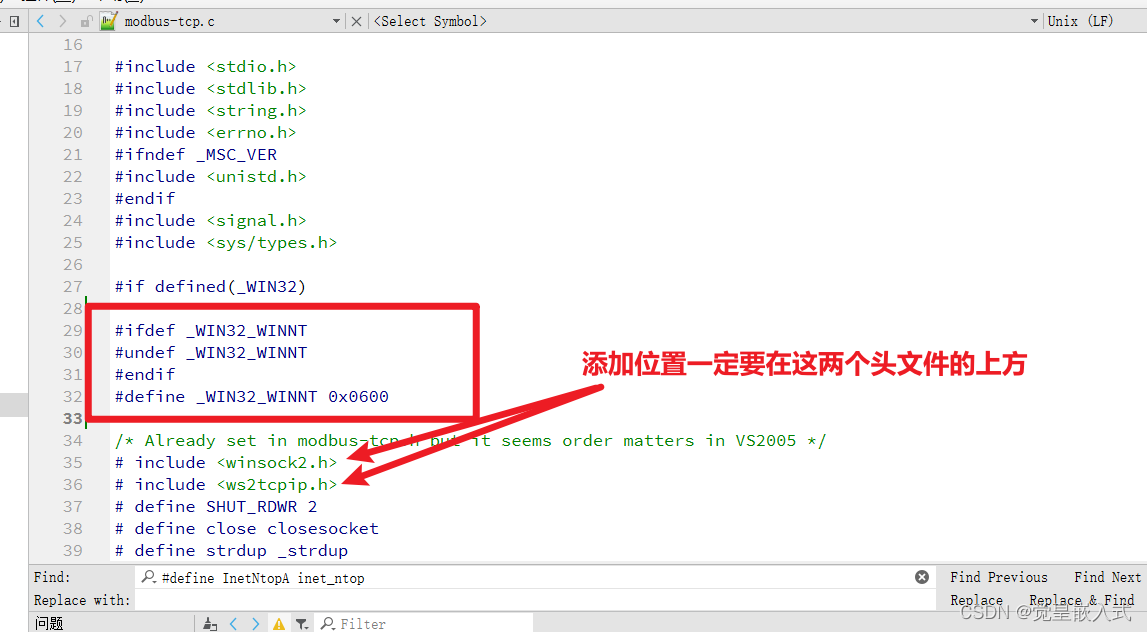
windows下MSYS、MinGW编译环境使用网络API时报错:undefined reference to `inet_pton‘解决办法
windows下MSYS、MinGW编译环境使用网络API时报错:undefined reference to inet_pton’解决办法 mingw-gcc环境使用网络需要加上库 -lws2_32。 如果是使用的是Qt Creator那么需要在.pro文件中加入一行:win32:LIBS -lws2_32。 当在项目中使用inet_pton、…...

unity-AI自动导航
unity-AI自动导航 给人物导航 一.地形创建 1.首先我们在Hierarchy面板中创建一个地形对象terrian,自行设定地形外貌,此时我们设置一个如下的地形外观。 二.创建导航系统 1.在主人公的Inspector、面板中添加Nav Mesh Agent (导航网格代理&…...

使用create-react-app创建react项目
create-react-app 全局安装create-react-app npm install -g create-react-app 使用create-react-app创建一个项目 $ create-react-app your-app 注意命名方式Creating a new React app in /dir/your-app.Installing packages. This might take a couple of minutes. 安装过…...
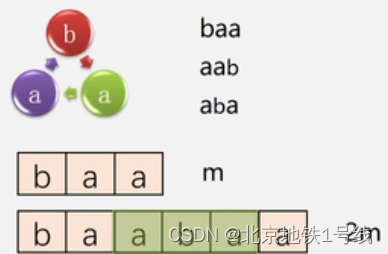
12.串,串的存储结构与模式匹配算法
目录 一. 一些术语 二. 串的类型定义 (1)串的顺序存储结构 (2)串的链式存储结构 三. 串的模式匹配算法 (1)BF算法 (2)KMP算法 四. 案例实现 串(String)---零个或多个任意字符…...
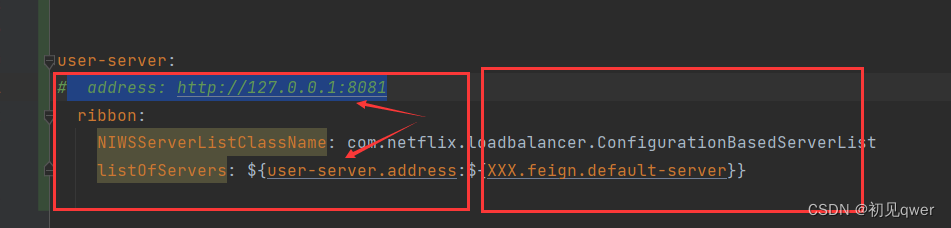
Ribbon:listOfServers ,${variableName:defaultValue}
解释: 配置了address的地址,请求会走address,也就是http://127.0.0.1:8081,通常用户与别的后端服务进行联调设置为其本地服务的ip。 如果address的地址被注释掉,如下面所示,类似这样的占位符${variableName:defaultVa…...

TensorFlow二元-多类-多标签分类示例
探索不同类型的分类模型,使用 TensorFlow 构建二元、多类和多标签分类器。 二元分类 简述 逻辑回归 二元交叉熵 二元分类架构 案例:逻辑回归预测获胜团队 多类分类 简述 Softmax 函数 分类交叉熵 多类分类架构 案例:预测航天飞机…...
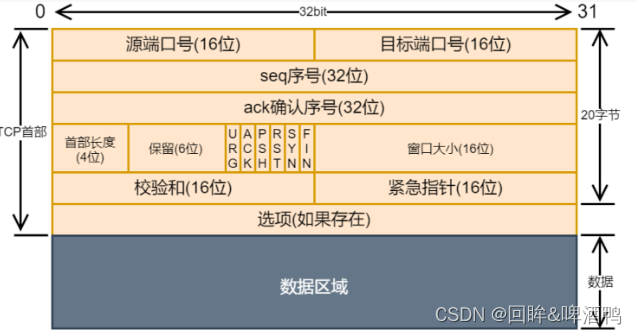
【回眸】牛客网刷刷刷!(七)——通信协议之 网络通讯
目录 前言 1、TCP/IP分层模型 2、ARP缓存 3、TCP 协议之所以提供可靠传输,不怕丢包、乱序的主要的原因是 4、以太网数据链路层MII/GMII/RMII/RGMII四种常用接口 5、在以太网通信协议LWIP中,数据包管理机构采用数据结构pbuf 分类包括 6、关于以太网…...

智能衬衫核心技术解析:柔性ECG传感器与云端监护系统如何守护心脏健康
1. 项目概述:一件能“救命”的智能衬衫 还记得那句经典的广告词吗?“我摔倒了,我起不来了!”几十年前,独居老人或心脏病患者的安全保障,往往依赖于一个挂在脖子上的紧急呼叫按钮。这种设备虽然提供了一种基…...

量子噪声控制与FIR滤波器应用解析
1. 量子噪声控制基础与FIR滤波器原理量子计算的核心挑战之一是如何在噪声环境中保持量子态的相干性。量子比特极易受到环境噪声的影响,导致量子门操作精度下降。在众多噪声类型中,1/f噪声(低频噪声)因其普遍存在于固态量子系统中而…...

Simulink Assignment模块实战:如何像写C代码一样更新数组元素?
Simulink Assignment模块实战:从C语言思维到模型化设计的无缝衔接 对于习惯用C语言编写控制算法的工程师来说,第一次接触Simulink的模块化设计往往会感到不适应——尤其是当需要更新数组中的特定元素时。在C语言中,我们只需简单地写下array[2…...

ARM缓存控制器架构解析与性能优化实践
1. ARM缓存控制器架构概述 在现代处理器设计中,缓存控制器作为CPU与主存之间的关键桥梁,其设计优劣直接影响系统整体性能。ARM架构的缓存控制器采用分层设计理念,通过数据RAM、标签RAM和脏RAM三大核心组件的协同工作,实现了高效的…...

WinRAR分卷压缩 vs 7-Zip分卷压缩:哪个更适合你?一次讲清区别、选型和实操
WinRAR分卷压缩 vs 7-Zip分卷压缩:深度对比与场景化选型指南 在数字文件传输与存储的日常场景中,大文件处理始终是个绕不开的痛点。无论是设计师需要发送PSD源文件给客户,还是开发人员要共享虚拟机镜像,当文件体积突破邮箱附件限…...
)
Spring Boot项目对接公司AD域,手把手搞定用户登录和密码重置(附SSL证书避坑指南)
Spring Boot企业级AD域集成实战:从登录到密码重置的全链路解决方案 当企业IT系统发展到一定规模,统一身份认证就成了刚需。上周我接手了一个内部ERP系统的改造项目,要求对接公司Active Directory实现员工单点登录——听起来简单,但…...
Zotero PDF Translate:打破语言壁垒,让外文文献阅读更高效 [特殊字符]
Zotero PDF Translate:打破语言壁垒,让外文文献阅读更高效 🚀 【免费下载链接】zotero-pdf-translate Translate PDF, EPub, webpage, metadata, annotations, notes to the target language. Support 20 translate services. 项目地址: ht…...

Windows窗口置顶终极指南:PinWin让你的多任务处理效率翻倍
Windows窗口置顶终极指南:PinWin让你的多任务处理效率翻倍 【免费下载链接】PinWin Pin any window to be always on top of the screen 项目地址: https://gitcode.com/gh_mirrors/pin/PinWin 你是否曾因频繁切换窗口而打断工作流程?是否需要在多…...

开源首发:DocCenter — AI 时代的 HTML工作台深度解析
Tags:Python aiohttp 开源项目 AI工具 前端工程 工具分享 Claude ChatGPT 专栏:「工具开源」/「DocCenter」 一、痛点:AI 时代的文档散落病 过去一年,我每天被 AI 生成的 HTML 文件淹没。 Claude artifacts 一天 20 个、ChatGPT…...
)
【ElevenLabs有声书量产指南】:从零到上线的7步闭环流程(含避坑清单+API调优参数)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs有声书量产的底层逻辑与场景定位 ElevenLabs 的有声书量产并非简单调用 TTS API,而是依托其神经语音建模、上下文感知韵律合成与批量异步编排三重能力构建的工业化流水线。其底层…...