自然语言处理:大语言模型入门介绍
自然语言处理:大语言模型入门介绍
- 语言模型的历史演进
- 大语言模型基础知识
- 预训练Pre-traning
- 微调Fine-Tuning
- 指令微调Instruction Tuning
- 对齐微调Alignment Tuning
- 提示Prompt
- 上下文学习In-context Learning
- 思维链Chain-of-thought
- 提示开发(调用ChatGPT的API)
- 大语言模型未来展望
- 参考文献
随着自然语言处理(Natural Language Processing, NLP)的发展,此技术现已广泛应用于文本分类、识别和总结、机器翻译、信息提取、问答系统、情感分析、语音识别、文本生成等任务。
研究人员发现扩展模型规模可以提高模型能力,由此创造了术语——大语言模型(Large Language Model, LLM),它代指大型的预训练语言模型(Pre-training Language Model, PLM),其通常包含数千亿(甚至更多)个参数。大语言模型的一个最显著的进展是OpenAI基于LLM开发的聊天机器人ChatGPT,在此篇博客中,我将介绍大语言模型的历史演进、基础知识、核心技术以及未来展望等,并通过调用API介绍ChatGPT是如何搭建的。
语言模型的历史演进
语言模型(LM)是为了对词序列的生成概率进行建模,从而预测未来或缺失的词的概率,其发展主要有以下三个阶段:
- 统计语言模型(SLM):基于统计学习方法(如马尔可夫假设)建立词预测模型,根据最近的上下文预测下一个词。
- 神经语言模型(NLM):通过神经网络(如循环神经网络RNN)来描述预测单词序列的概率。
- 大语言模型(LLM):研究人员发现扩展模型规模可以提高模型能力,通过使用Transformer架构构建大规模语言模型,并确立了“预训练和微调”的范式,即在大规模语料库上进行预训练,对预训练语言模型进行微调以适配不同的下游任务,并提高LLM的各项性能。
大语言模型基础知识
预训练Pre-traning
模型的预训练首先需要高质量的训练数据,这些数据往往来自于网页、书籍、对话、科学文献、代码等,收集到这些数据后,需要对数据进行预处理,特别是消除噪声、冗余、无关和潜在有害的数据。一个典型的预处理数据流程如下:
- 质量过滤:删除低质量数据;
- 去重:删除重复数据;
- 去除隐私:删除涉及隐私的数据;
- Token化:将原始文本分割成词序列(Token),随后作为大语言模型的输入。
目前大语言模型的主流架构可分为三大类型:编码器-解码器、因果解码器和前缀解码器,还有一种利用上述三种架构搭建的混合架构:
- 编码器-解码器架构:利用传统的Transformer架构,编码器利用堆叠的多头自注意力层(Self-attention)对输入序列进行编码以学习其潜在表示,而解码器对这些表示进行交叉注意力(Cross-attention)计算并自回归地生成目标序列。目前只有少数LLM是利用此架构搭建,例如T5、BART。
- 因果解码器架构:它采用单向注意力掩码,以确保每个输入token只能关注过去的token和它本身。输入和输出token通过解码器以相同的方式处理。GPT系列、OPT、BLOOM和Gopher等模型便是基于因果解码器架构开发的,目前使用较为广泛。
- 前缀解码器架构:前缀解码器架构又称非因果解码器架构,它修正了因果解码器的掩码机制,以使其能够对前缀token执行双向注意力,并仅对生成的token执行单向注意力,这样,与编码器-解码器架构类似,前缀解码器可以双向编码前缀序列并自回归地逐个预测输出token,其中在编码和解码的过程中共享相同的参数。使用此架构的代表:GLM-130B和U-PaLM等。
- 混合架构:利用混合专家(MoE)策略对上述三种架构进行扩展,例如Switch Transformer和GLaM等。
微调Fine-Tuning
为了使大语言模型适配特定的任务,可使用指令微调(Instruction Tuning)和对齐微调(Alignment Tuning)等技术方法;由于大语言模型包含了大量的任务,如果进行全参数微调将会有较大开销,对参数进行高效微调的方法有:适配器微调(Adapter Tuning)、前缀微调(Prefix Tuning)、提示微调(Prompt Tuning)和低秩适配(LoRA)等,高效微调的方法在此暂不展开介绍,有兴趣的小伙伴可以自行查阅相关资料。
指令微调Instruction Tuning
指令微调通过使用自然语言描述的混合多任务数据集进行有监督地微调,从而使得大语言模型能够更好地完成下游任务,具备更好的泛化能力。在此过程中伴随着参数的更新。
对齐微调Alignment Tuning
对齐微调旨在将LLM的行为与人类价值观或偏好对齐。它需要从人类标注员(需要具备合格的教育水平甚至满足一定学历要求)中收集高质量的人类反馈数据,然后利用这些数据对模型进行微调。典型的微调技术包括:基于人类反馈的强化学习(RLHF)。
为了使大语言模型与人类价值观保持一致,学者提出了基于人类反馈的强化学习(RLHF),即使用收集到的人类反馈数据结合强化学习对LLM进行微调,有助于改善模型的有用性、诚实性和无害性。RLHF采用强化学习(RL)算法,例如近端策略优化(Proximal Policy Optimization, PPO)通过学习奖励模型使LLM适配人类反馈。
提示Prompt
为了使语言模型完成一些特定任务,利用在模型的输入中加入提示的机制,使得模型得到预想的结果或引导模型得到更好的结果,注意与微调不同,在提示这一过程中,无需额外的训练和参数更新。
上下文学习In-context Learning
上下文学习(In-context Learning, ICL)是由GPT-3正式引入,它的关键思想是从类比中学习,它将查询的问题和一个上下文提示(一些相关的样例)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。
思维链Chain-of-thought
思维链(Chain-of-thought, CoT)是一种改进的提示策略,旨在提高LLM在复杂推理任务中的性能,例如算术推理、常识推理和符号推理。具体做法是将中间推理步骤纳入到提示中,引导模型预测出正确结果。据相关论文,这种能力可能是在代码上训练而获得。
提示开发(调用ChatGPT的API)
ChatGPT是使用OpenAI开发的大语言模型进行聊天的web网站,其本质是调用ChatGPT的API完成各项任务,下面演示了使用ChatGPT的API完成总结的任务,除此之外,它还可以完成推理、翻译、问答、校对、扩展等多项任务,有时需要借助ICL或CoT获得更好的结果(前提是你需要从OpenAI官网获得API的密钥key)
import openai
import os
fron dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv("OPENAI_API_KEY")def get_completion(prompt, temperature=0, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt)]response= openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, # temperature为模型的探索程度或随机性,其值是范围在0~1的浮点数,值越高则随机性越大,说明更有创造力。)return response.choices[0].message["content"]text = f"""
XXXXXXXX
"""
prompt = f"""
Summarize the text delimited by triple backticks into a single sentence.
```{text}```
"""
response = get_completion(prompt)
print(response)
ChatGPT的web网站或者聊天机器人通常包含三个角色(role)的消息(messages),包括:用户(user)的消息,ChatGPT/聊天机器人(assistant)的消息和系统(system)的消息。下面以搭建一个“订餐机器人”为例:
- system messages:用于设置机器人的行为和人设,作为高层指令指导机器人的对话,用户一般对此不可见;
- user messages:是用户的输入;
- assistant messages:是机器人的回复。
代码示例如下:
import openai
import os
fron dotenv import load_dotenv, find_dotenv_ = load_dotenv(find_dotenv())
openai.api_key = os.getenv("OPENAI_API_KEY")def get_completion_from_messages(messages, temperature=0, model="gpt-3.5-turbo"):response= openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, # temperature为模型的探索程度或随机性,其值是范围在0~1的浮点数,值越高则随机性越大,说明更有创造力。)return response.choices[0].message["content"]messages = ["role": "system","content": "你现在一个订餐机器人,你需要根据菜单收集用户的订餐需求。菜单:汉堡、薯条、炸鸡、可乐、雪碧。","role": "user","content": "你好,我想要一个汉堡。","role": "assistant","content": "请问还有其他需要的吗?","role": "user","content": "再要一份可乐。",
]response=get_completion_from_messages(messages)
print(response)
# 输出示例:
# 好的,一份汉堡和可乐,已为您下单。借助上述代码示例,设计一个GUI或Web界面就可以实现人机交互,修改system messages即可更改聊天机器人的行为并让其扮演不同的角色。
大语言模型未来展望
- 更大规模: 模型的规模可能会继续增大,从而提高模型的表现力和语言理解能力。
- 更好的预训练: 改进预训练策略,使模型更好地理解语义和上下文,提高模型在各种任务上的迁移能力。
- 更好的微调: 开发更有效的微调方法,以在特定任务上获得更好的性能。
- 多模态: 将语言模型与视觉、声音等其他模态相结合,实现跨领域的多模态智能应用。
- 工具:利用搜索引擎、计算器和编译器等外部工具,提高语言模型在特定领域的性能。
参考文献
大语言模型综述
相关文章:

自然语言处理:大语言模型入门介绍
自然语言处理:大语言模型入门介绍 语言模型的历史演进大语言模型基础知识预训练Pre-traning微调Fine-Tuning指令微调Instruction Tuning对齐微调Alignment Tuning 提示Prompt上下文学习In-context Learning思维链Chain-of-thought提示开发(调用ChatGPT的…...

使用秘籍|如何实现图数据库 NebulaGraph 的高效建模、快速导入、性能优化
本文整理自 NebulaGraph PD 方扬在「NebulaGraph x KubeBlocks」meetup 上的演讲,主要包括以下内容: NebulaGraph 3.x 发展历程NebulaGraph 最佳实践 建模篇导入篇查询篇 NebulaGraph 3.x 的发展历程 NebulaGraph 自 2019 年 5 月开源发布第一个 alp…...
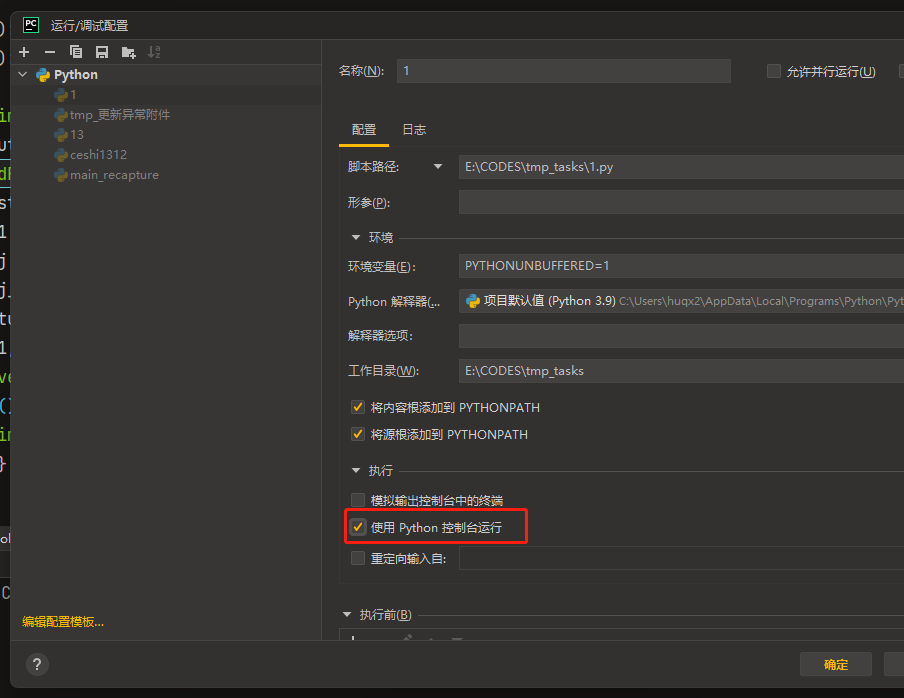
对于pycharm 运行的时候不在cmd中运行,而是在python控制台运行的情况,如何处理?
对于pycharm 运行的时候不在cmd中运行,而是在python控制台运行的情况,如何处理? 比如,你在运行你的代码的时候 它总在python控制台运行,十分难受 解决方法 在pycharm中设置下即可,很简单 选择运行点击…...

Spring MVC 二 :基于xml配置
创建一个基于xml配置的Spring MVC项目。 Idea创建新项目,pom文件引入依赖: <dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.12.RELEASE</version>…...

springboot aop方式实现接口入参校验
一、前言 在实际开发项目中,我们常常需要对接口入参进行校验,如果直接在业务代码中进行校验,则会显得代码非常冗余,也不够优雅,那么我们可以使用aop的方式校验,这样则会显得更优雅。 二、如何实现…...
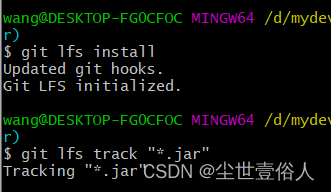
解决git上传远程仓库时的大文件提交
在git中超过100M的文件会上传失败,而当一个文件超过50M时会给你警告,如下 warning: File XXXXXX is 51.42 MB; this is larger than GitHubs recommended maximum file size of 50.00 MB 解决这种问题,首先在项目的.git文件夹中找到.gitigno…...
HTML学习笔记02
HTML笔记02 页面结构分析 元素名描述header标题头部区域的内容(用于页面或页面中的一块区域)footer标记脚部区域的内容(用于整个页面或页面的一块区域)sectionWeb页面中的一块独立区域article独立的文章内容aside相关内容或应用…...
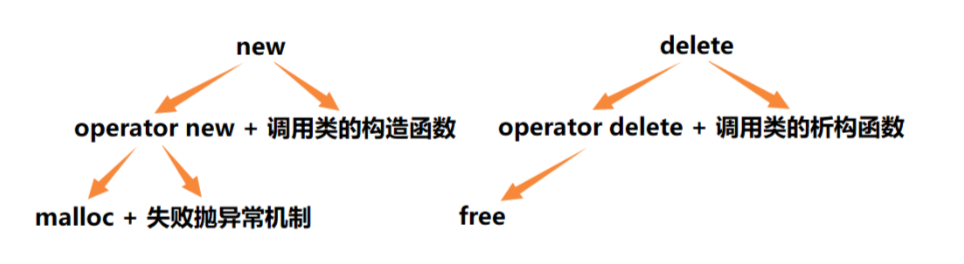
<C++> 内存管理
1.C/C内存分布 让我们先来看看下面这段代码 int globalVar 1; static int staticGlobalVar 1; void Test() {static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";char *pChar3 "abcd";int *ptr1 (int *) mal…...

【Java】ByteBuffer类的arrayOffset方法详解+示例
arrayOffset功能详解;arrayOffset在position等于0和非0两种场景下的demo。使用类java.nio.ByteBuffer中的arrayOffset()方法可以获得这个缓冲区的第一个元素在底层支持(backing)数组中的偏移量。 如果这个buffer底层是由数组支持的,那么buffer的postion p对应于数组的index…...
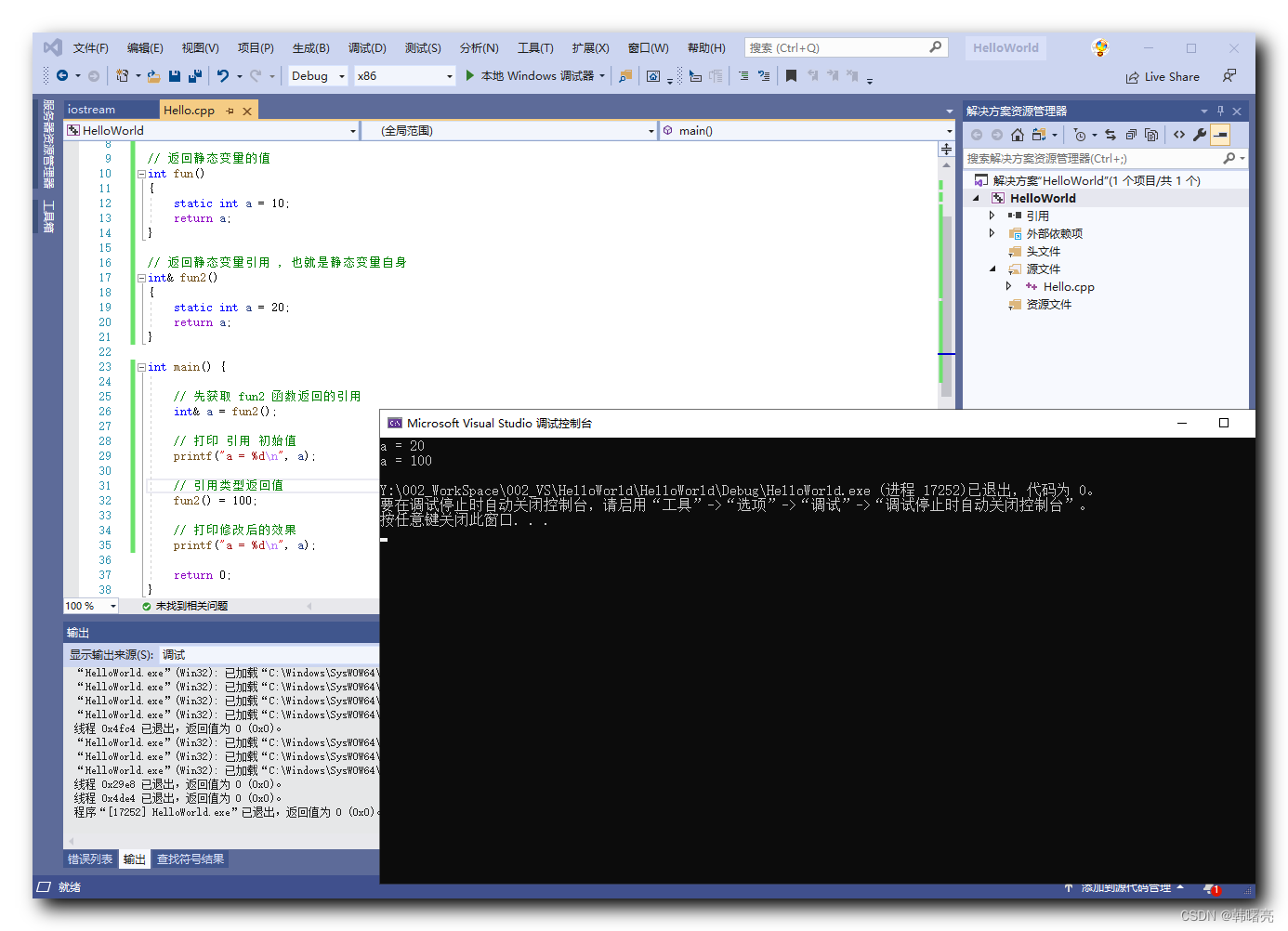
【C++】C++ 引用详解 ⑤ ( 函数 “ 引用类型返回值 “ 当左值被赋值 )
文章目录 一、函数返回值不能是 " 局部变量 " 的引用或指针1、函数返回值常用用法2、分析函数 " 普通返回值 " 做左值的情况3、分析函数 " 引用返回值 " 做左值的情况 函数返回值 能作为 左值 , 是很重要的概念 , 这是实现 " 链式编程 &quo…...
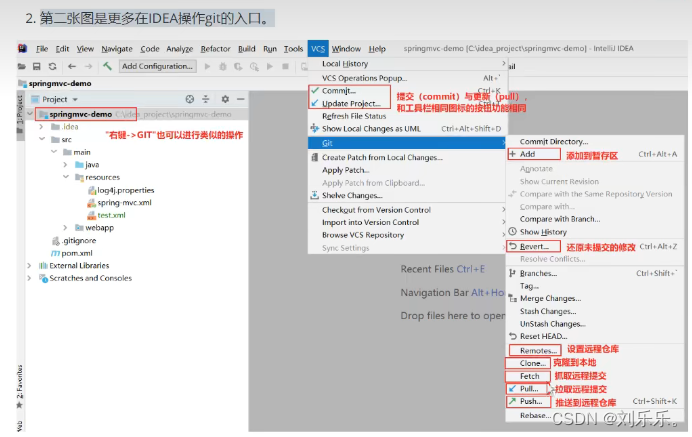
Git,分布式版本控制工具
1.为常用指令配置别名(可选) 打开用户目录,创建.bashrc文件 (touch ~/.bashrc) 2.往其输入内容 #用于输出git提交日志 alias git-loggit log --prettyoneline --all --graph --abbrev-commit #用于输出当前目录所有文…...

LeetCode 面试题 02.02. 返回倒数第 k 个节点
文章目录 一、题目二、C# 题解 一、题目 实现一种算法,找出单向链表中倒数第 k 个节点。返回该节点的值。 注意:本题相对原题稍作改动 点击此处跳转题目。 示例: 输入: 1->2->3->4->5 和 k 2 输出: 4 说…...

SpeedBI数据可视化工具:丰富图表,提高报表易读性
数据可视化工具一大作用就是能把复杂数据可视化、直观化,更容易看懂,也就更容易实现以数据驱动业务管理升级,因此一般的数据可视化工具都会提供大量图形化的数据可视化图表,以提高报表的易懂性,更好地服务企业运营决策…...
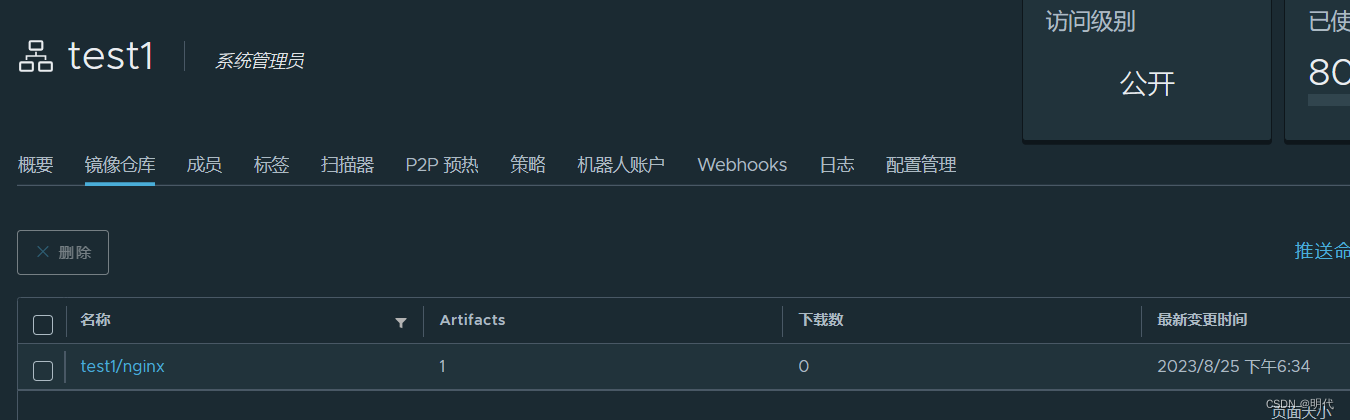
编写Dockerfile制作Web应用系统nginx镜像
文章目录 题目要求:一、创建文档,编写Dockerfile文件可以将harbor仓库去启动先起来 二、运行Dockerfile,构建nginx镜像三、推送导私有仓库,也就是我们的harbor仓库 题目要求: 编写Dockerfile制作Web应用系统nginx镜像…...

记录一次微服务连接Nacos异常-errorMsg: Illegal character in authority at index 7:
组件信息 Nacos 2.2.3 SpringCloud微服务 部署环境:centerOS 部署方式:k8s 前言 nacos开启鉴权,nacos地址通过变量方式传入服务中 PropsUtil.setProperty(props, "spring.cloud.nacos.discovery.server-addr", "${NACO…...

【Java】反射 之 调用构造方法
调用构造方法 我们通常使用new操作符创建新的实例: Person p new Person();如果通过反射来创建新的实例,可以调用Class提供的newInstance()方法: Person p Person.class.newInstance();调用Class.newInstance()的局限是,它只…...

Hightopo 使用心得(6)- 3D场景环境配置(天空球,雾化,辉光,景深)
在前一篇文章《Hightopo 使用心得(5)- 动画的实现》中,我们将一个直升机模型放到了3D场景中。同时,还利用动画实现了让该直升机围绕山体巡逻。在这篇文章中,我们将对上一篇的场景进行一些环境上的丰富与美化。让场景更…...
 函数的使用方法)
【Python PEP 笔记】201 - 同步迭代 / zip() 函数的使用方法
原文地址:https://peps.python.org/pep-0201/ PDF 地址: 什么是同步迭代 同步迭代就是用 for 一次循环多个序列。 类似于这样的东西: arr1 [1, 2, 3, 4] arr2 [a, b, c, d] for a, b in arr1, arr2:print(a, b)使用 map 实现 for a, b …...

远程控制:用了向日葵控控A2后,我买了BliKVM v4
远程控制电脑的场景很多,比如把办公室电脑的文件发到家里电脑上,但是办公室电脑旁边没人。比如当生产力用的电脑一般都比较重,不可能随时带在身边,偶尔远程操作一下也是很有必要的。比如你的设备在工况恶劣的环境中,你…...
基于swing的火车站订票系统java jsp车票购票管理mysql源代码
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 基于swing的火车站订票系统 系统有2权限:…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...
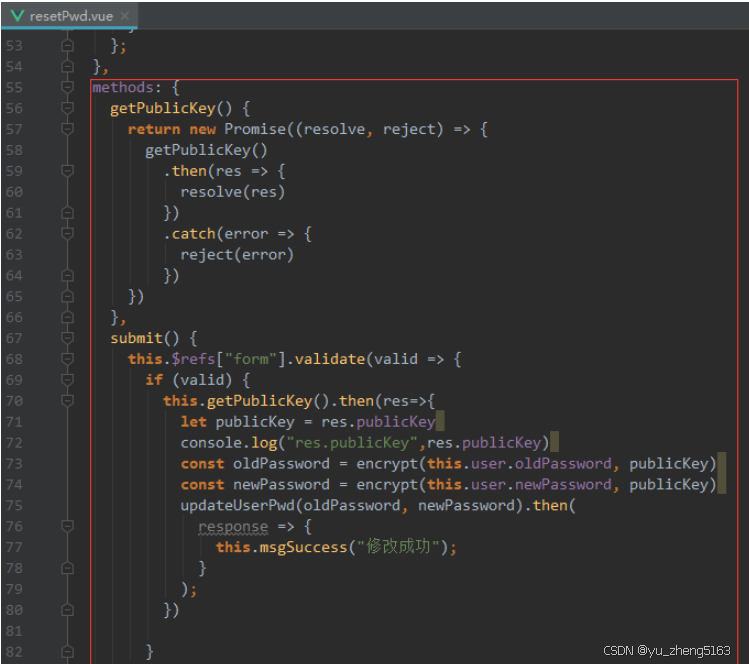
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Ray框架:分布式AI训练与调参实践
Ray框架:分布式AI训练与调参实践 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 Ray框架:分布式AI训练与调参实践摘要引言框架架构解析1. 核心组件设计2. 关键技术实现2.1 动态资源调度2.2 …...