cuda编程day001
一、环境:
①、linux cuda-11.3 opecv4.8.0
不知道头文件和库文件路径,用命令查找:
# find /usr/local -name cuda.h 2>/dev/null # 查询cuda头文件路径
/usr/local/cuda-11.3/targets/x86_64-linux/include/cuda.h# find /usr/local -name libcudart.so 2>/dev/null # 查询库文件路径
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudart.so# pkg-config --cflags opencv4 # 查看opencv头文件
-I/usr/include/opencv4/opencv -I/usr/include/opencv4# pkg-config --libs opencv4 查看opencv 库文件
-lopencv_stitching -lopencv_aruco -lopencv_bgsegm -lopencv_bioinspired
-lopencv_ccalib -lopencv_dnn_objdetect -lopencv_dnn_superres -lopencv_dpm
-lopencv_highgui -lopencv_face -lopencv_freetype -lopencv_fuzzy -lopencv_hdf
-lopencv_hfs -lopencv_img_hash -lopencv_line_descriptor -lopencv_quality
-lopencv_reg -lopencv_rgbd -lopencv_saliency -lopencv_shape -lopencv_stereo
-lopencv_structured_light -lopencv_phase_unwrapping -lopencv_superres
-lopencv_optflow -lopencv_surface_matching -lopencv_tracking -lopencv_datasets
-lopencv_text -lopencv_dnn -lopencv_plot -lopencv_ml -lopencv_videostab
-lopencv_videoio -lopencv_viz -lopencv_ximgproc -lopencv_video -lopencv_xobjdetect -lopencv_objdetect -lopencv_calib3d -lopencv_imgcodecs -lopencv_features2d
-lopencv_flann -lopencv_xphoto -lopencv_photo -lopencv_imgproc -lopencv_core添加到makefile文件里面:
# 这里定义头文件库文件和链接目标没有加-I -L -l,后面用foreach一次性增加
include_paths := /usr/local/cuda-11.3/targets/x86_64-linux/include /usr/include/opencv4 /usr/include/opencv4/opencv
library_paths := /usr/local/cuda-11.3/targets/x86_64-linux/lib
link_librarys := cudart opencv_core opencv_imgcodecs opencv_imgproc $(shell pkg-config --libs opencv4 | sed 's/-l//g')
因为OpenCV的库文件太多,使用shell函数将pkg-config命令的结果作为一个命令执行,并将其分割为单独的库名称,使用了sed命令来移除pkg-config命令返回的库名称中的横线-。这样,link_librarys中的库名称和pkg-config命令返回的库名称都将不带横线。这样就可以正确链接opencv4.8.0中的库了。
二、GPU的大致了解
原文:Bringing HPC Techniques to Deep Learning - Andrew Gibiansky
1、DataParallel模式(DP),Parameter Center模式,主从模式(主卡收集梯度,从卡发送参数和接受结果)
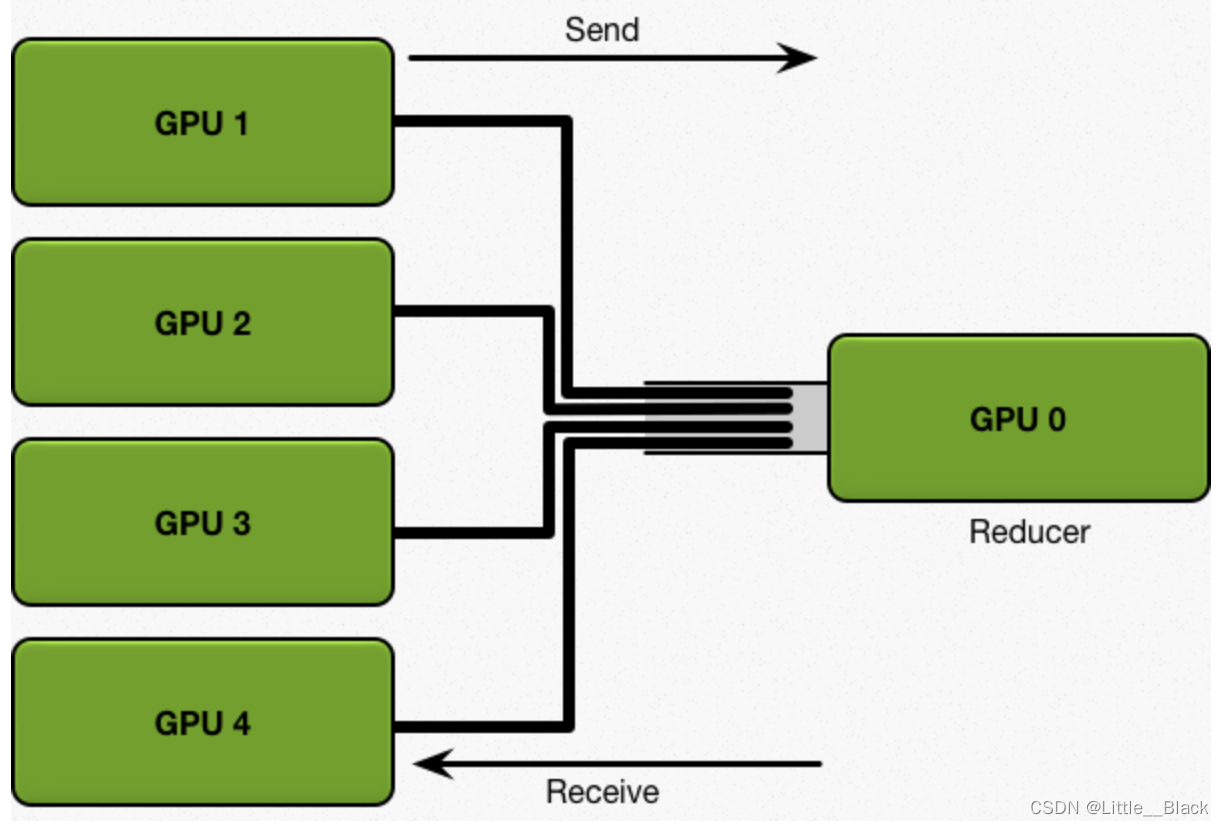
速度受限于主卡到从卡的带宽和速度。我们定义:
D = 模型参数总量,设为1GB
S = 单条线路的传输速率,设为1GB/s,也就是任何显卡传数据到GPU0,或者传输出去都是最大1GB/s
N = 显卡的个数,这里为5
则有:
①. 数据的传输量为4 x D x 2,我们经过了1次Scatter Reduce传输了4D数据量,经过了1次Allgather传输了4D数据量
②. 我们传输耗时理论为4 x 2 x D / S,得到结果约为8秒,公式为:Times = 2(N-1) * D / S
③. 我们传输的数据总量(显卡数相关):Data Transferred = 2(N-1) * D
2、DistributedDataParallel模式(DDP),Ring模式,环形模式
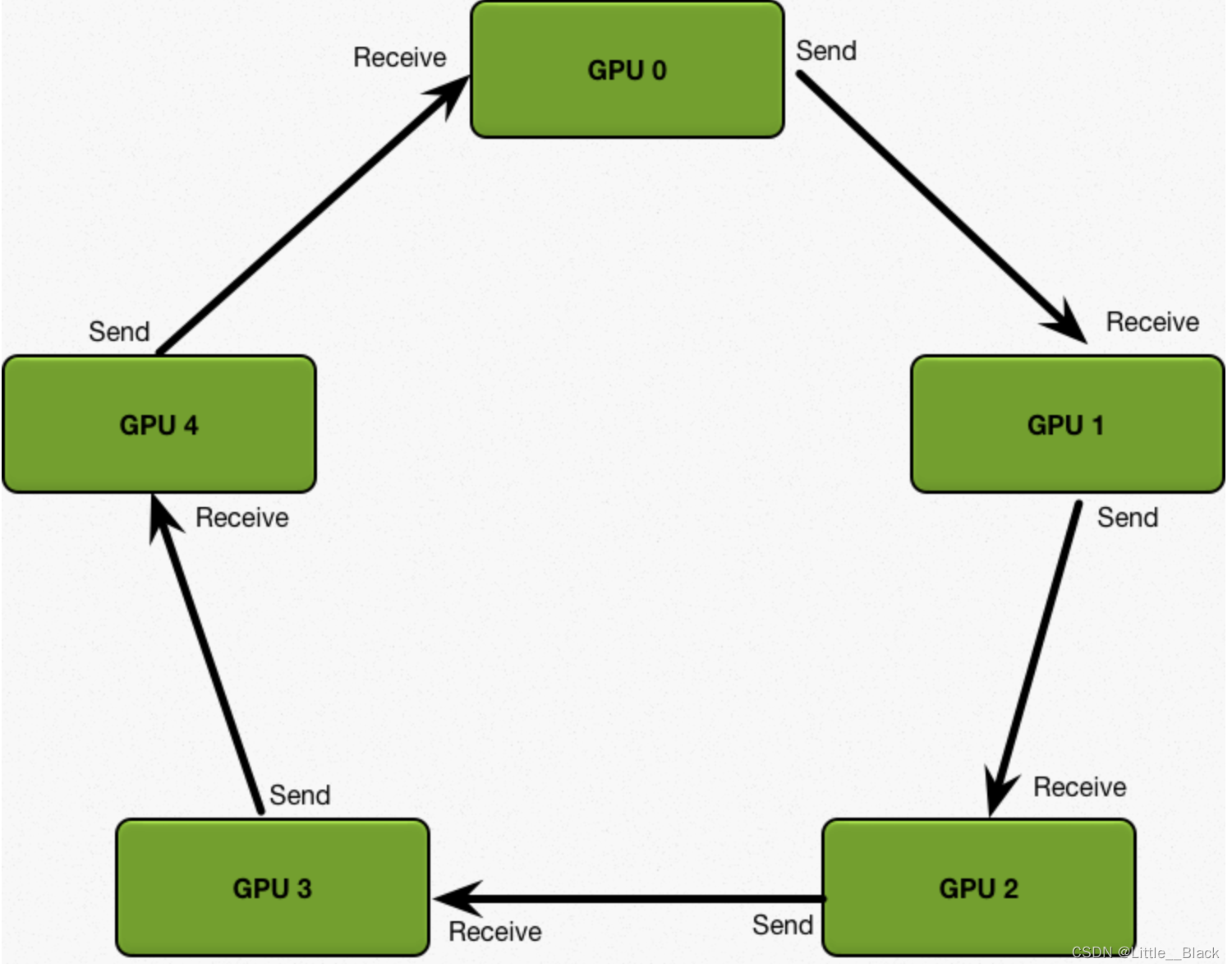
传输速度只与单个显卡的速度和带宽。我们定义:
D = 模型参数总量,设为1GB
S = 单条线路的传输速率,设为1GB/s,也就是任何显卡传数据到GPU0,或者传输出去都是最大1GB/s
N = 显卡的个数,这里为5
①、Scatter-Reduce(循环N-1次):
每个卡都传递其显卡索引对应的那份数据,给相邻的下一个显卡做累加,递所使用的线路是相邻显卡路径,不存在等待堆积,执行一次耗时: 1/N
②、Allgather(循环N-1次):
将每个卡中存在的完整数据发送给相邻下一个卡,执行一次耗时:1/N
则:
- 我们Scatter-Reduce时经过了N-1次1/N大小的数据传输,耗时认为是𝐷/𝑆 * 1/𝑁 * (𝑁−1)
- 我们Allgather时经过了N-1次1/𝑁大小的数据传输,耗时认为是𝐷/𝑆 * 1/𝑁 * (𝑁−1)
- 因此传输的耗时为:𝑇𝑖𝑚𝑒𝑠=2(𝑁−1) * 1/𝑁 * 𝐷/𝑆
- 传输的数据量为:𝐷𝑎𝑡𝑎𝑇𝑟𝑎𝑛𝑠𝑓𝑒𝑟𝑟𝑒𝑑=2(𝑁−1) * 𝐷 / 𝑁
可见:传输的数据量与显卡数量无关了 只与对应的显卡之间的数据传输速度有关
总结:
- DP模式下的主从模式,通信速度受限于单个显卡的通信速率。传递的数据量为2(𝑁−1)𝐷
- N为显卡数,D为模型参数大小
- DDP模式下的RingAllReduce,通信速度受限于显卡邻居间通信速率
- 于PCIE下,受限于主板的PCIE速度,而不是显卡的速度
- 于NVLINK下则最高可达100GB/s甚至更高
- 传递的数据量为2(𝑁−1)*𝐷/𝑁,与显卡数量无关,也因此其效率高
相关文章:
cuda编程day001
一、环境: ①、linux cuda-11.3 opecv4.8.0 不知道头文件和库文件路径,用命令查找: # find /usr/local -name cuda.h 2>/dev/null # 查询cuda头文件路径 /usr/local/cuda-11.3/targets/x86_64-linux/include/cuda.h # find /usr/…...
Java 中使用 ES 高级客户端库 RestHighLevelClient 清理百万级规模历史数据
🎉工作中遇到这样一个需求场景:由于ES数据库中历史数据过多,占用太多的磁盘空间,需要定期地进行清理,在一定程度上可以释放磁盘空间,减轻磁盘空间压力。 🎈在经过调研之后发现,某服务…...
梯度下降230821a)
C++最易读手撸神经网络两隐藏层(任意Nodes每层)梯度下降230821a
// c神经网络手撸20梯度下降22_230820a.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。 #include<iostream> #include<vector> #include<iomanip> // setprecision #include<sstream> // getline stof() #include<fstream…...

Leetcode 2235.两整数相加
一、两整数相加 给你两个整数 num1 和 num2,返回这两个整数的和。 示例 1: 输入:num1 12, num2 5 输出:17 解释:num1 是 12,num2 是 5 ,它们的和是 12 5 17 ,因此返回 17 。示例…...
Postman —— postman实现参数化
什么时候会用到参数化 比如:一个模块要用多组不同数据进行测试 验证业务的正确性 Login模块:正确的用户名,密码 成功;错误的用户名,正确的密码 失败 postman实现参数化 在实际的接口测试中,部分参数每…...
LeetCode--HOT100题(41)
目录 题目描述:102. 二叉树的层序遍历(中等)题目接口解题思路代码 PS: 题目描述:102. 二叉树的层序遍历(中等) 给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地&am…...
)
微信小程序教学系列(6)
第六章:小程序商业化 第一节:小程序的商业模式 在这一节中,我们将探讨微信小程序的商业模式,让你了解如何将你的小程序变成一个赚钱的机器! 1. 广告收入 小程序的商业模式之一是通过广告收入赚钱。你可以在小程序中…...
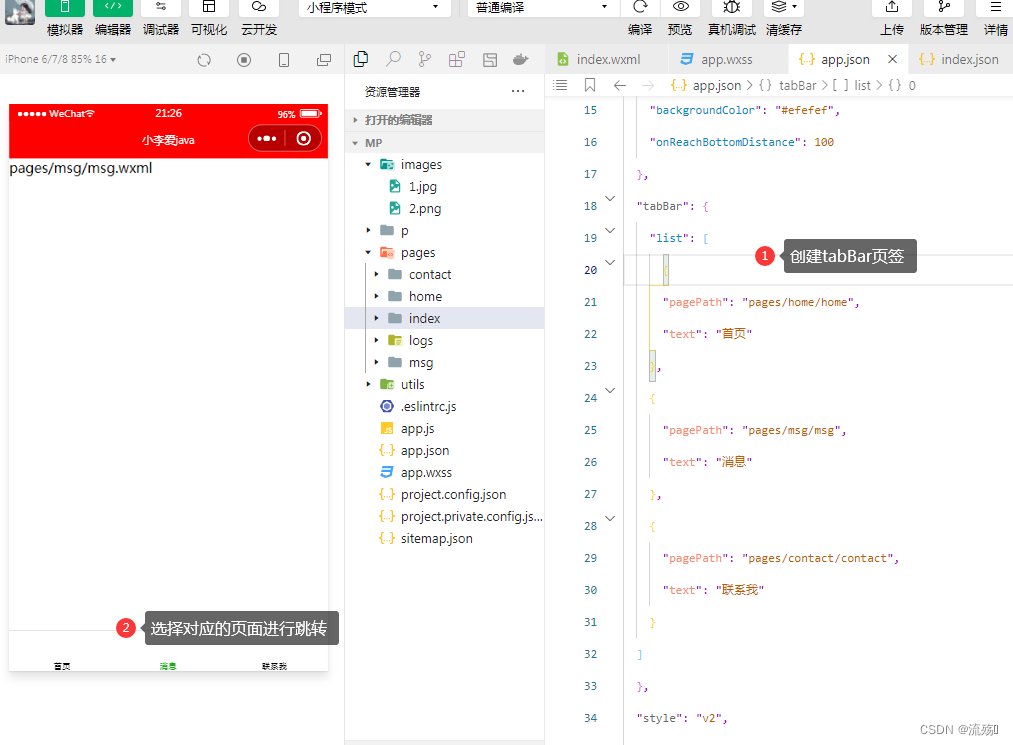
小程序中的全局配置以及常用的配置项(window,tabBar)
全局配置文件和常用的配置项 app.json: pages:是一个数组,用于记录当前小程序所有页面的存放路径,可以通过它来创建页面 window:全局设置小程序窗口的外观(导航栏,背景,页面的主体) tabBar:设置小程序底部的 tabBar效果 style:是否…...
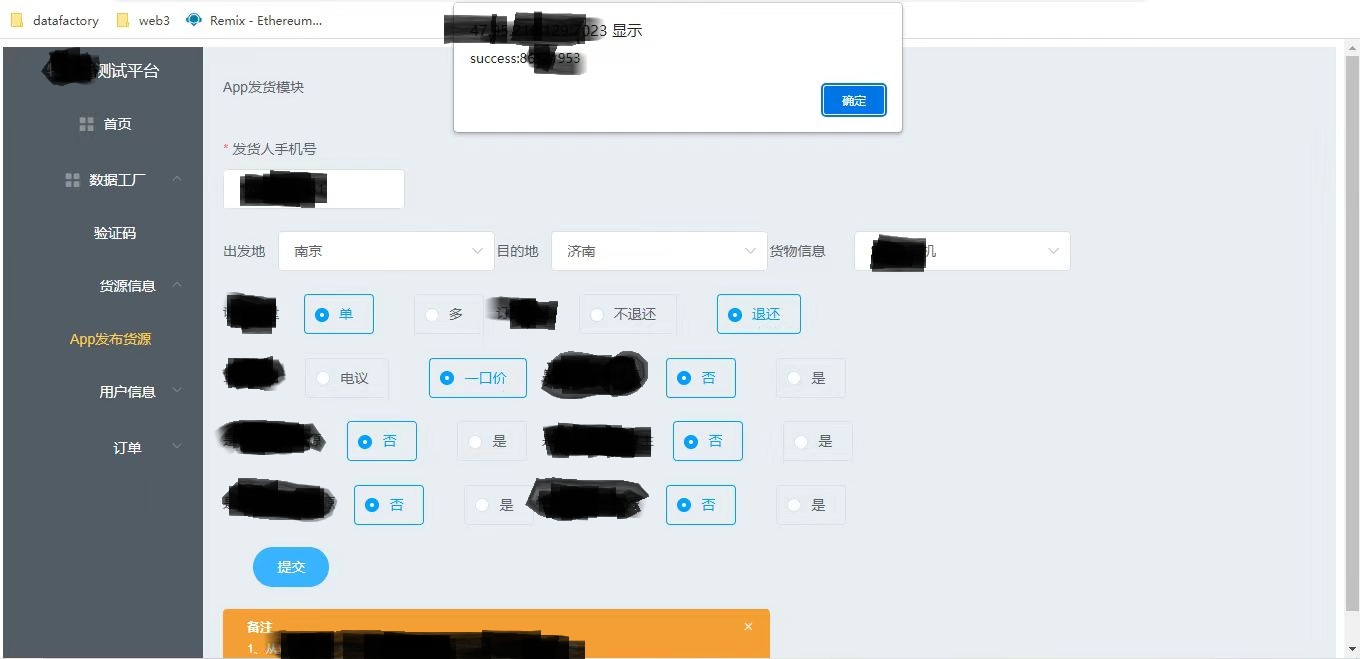
数据工厂调研及结果展示
数据工厂 一、背景 在开发自测、测试迭代测试、产品验收的过程中,都需要各种各样的前置数据,大致分为如下几类: 账号(实名、权益等级、注册等) 货源(优货、急走、相似、一手、普通货源等) …...
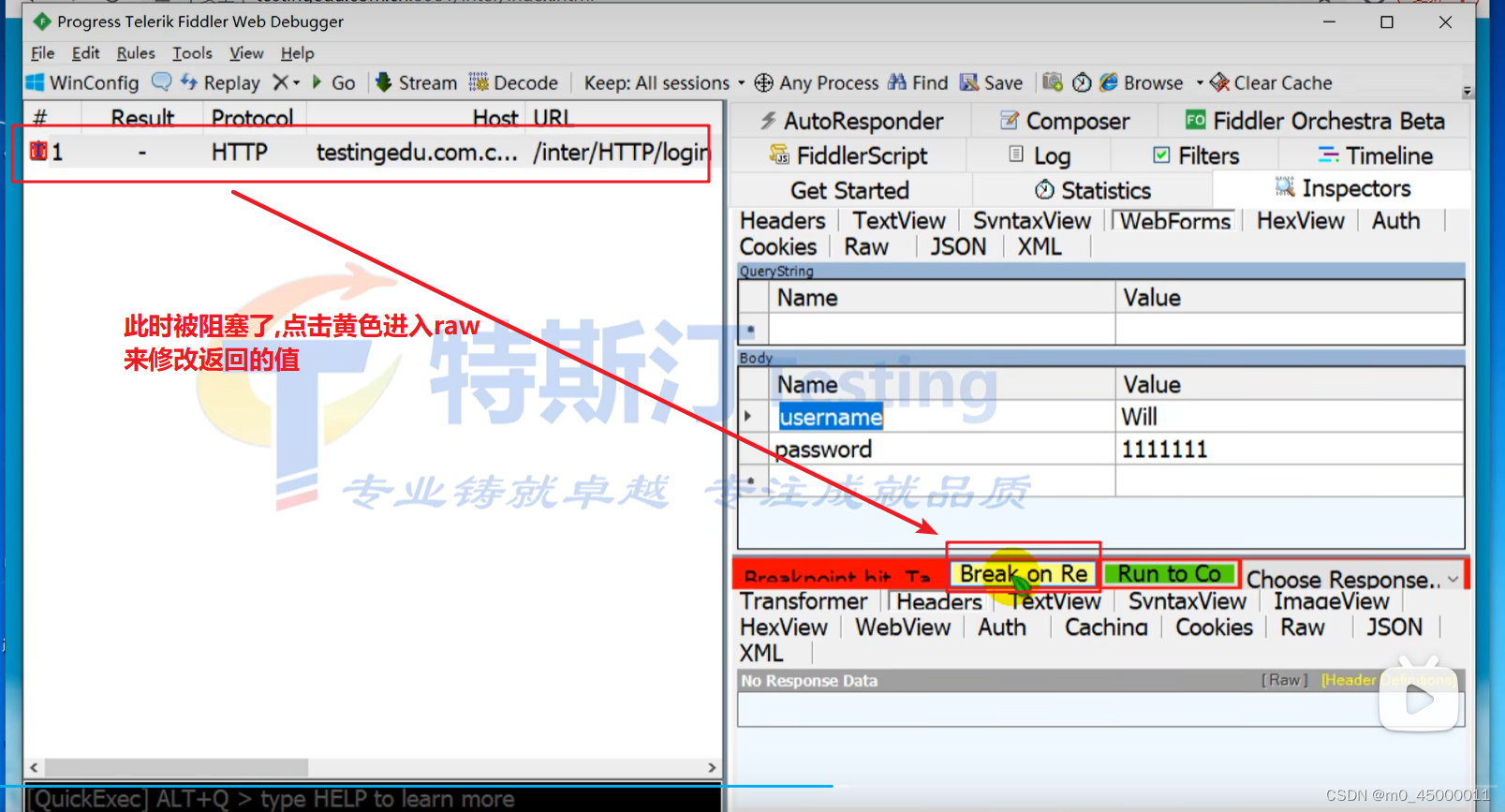
抓包相关,抓包学习
检查网络流量 - 提琴手经典 (telerik.com) Headers Reference - Fiddler Classic (telerik.com) 以上是fiddler官方文档 F12要勾选保留日志 不勾选的话跳转到新页面之前页面的日志不会在下方显示 会保留所有抓到的包 如果重定向到别的页面 F12抓包可能看不到响应信息,但是…...
云原生之使用Docker部署SSCMS内容管理系统
云原生之使用Docker部署SSCMS内容管理系统 一、SSCMS介绍二、本地环境介绍2.1 本地环境规划2.2 本次实践介绍 三、本地环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本 四、下载SSCMS镜像五、部署SSCMS内容管理系统5.1 创建SSCMS容器5.2 检查SSC…...

uniapp -- 在组件中拿到pages.json下pages设置navigationBarTitleText这个值?
1:在 pages.json 文件中设置 navigationBarTitleText,例如: {"pages": [{"path": "pages/home/index","style": {"navigationBarTitleText": "首页",&...
Java获取环境变量和运行时环境信息和自定义配置信息
System.getenv() 获取系统环境变量 public static void main1() {Map<String, String> envMap System.getenv();envMap.entrySet().forEach(x-> System.out.println(x.getKey() "" x.getValue())); } System.getenv() 获取的是操作系统环境变量列表&…...
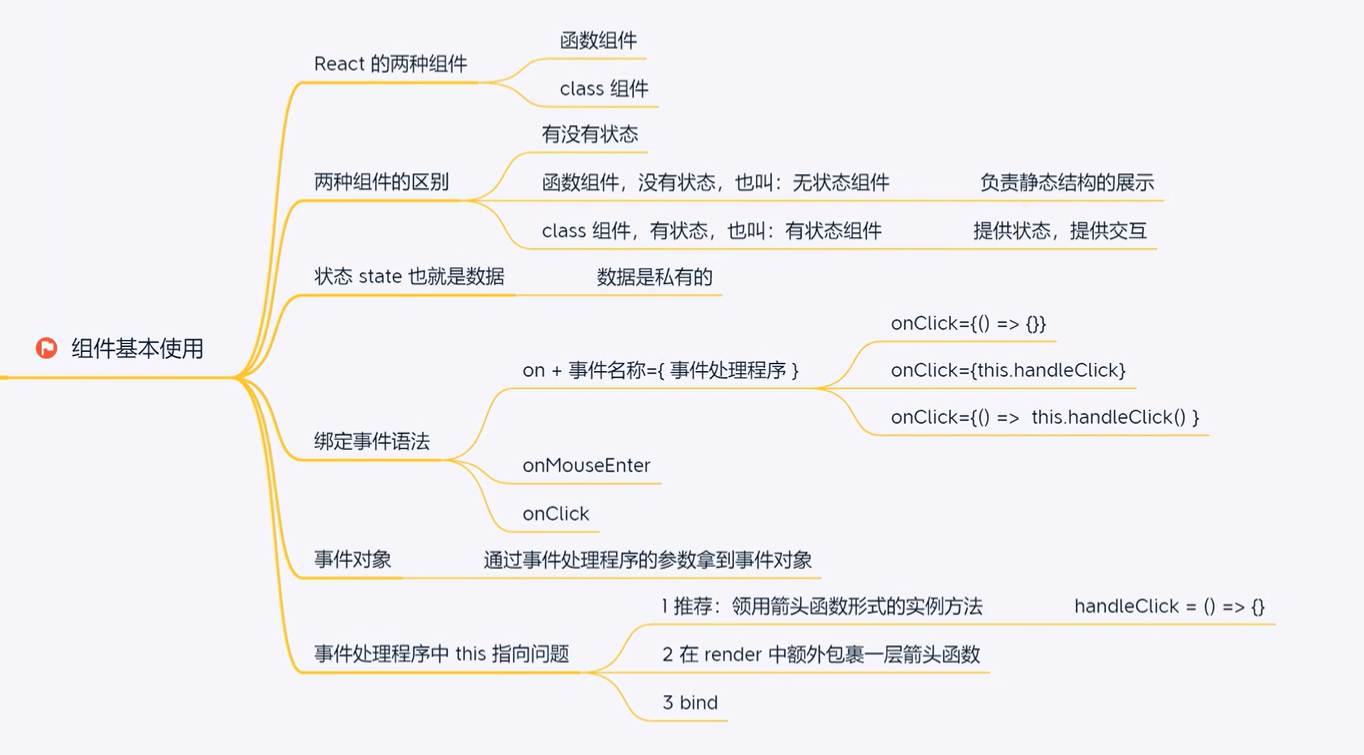
React入门 组件学习笔记
项目页面以组件形式层层搭起来,组件提高复用性,可维护性 目录 一、函数组件 二、类组件 三、 组件的事件绑定 四、获取事件对象 五、事件绑定传递额外参数 六、组件状态 初始化状态 读取状态 修改状态 七、组件-状态修改counter案例 八、this问…...

Windows商店引入SUSE Linux Enterprise Server和openSUSE Leap
在上个月的Build 2017开发者大会上,微软宣布将SUSE,Ubuntu和Fedora引入Windows 商店,反应出微软对开放源码社区的更多承诺。 该公司去年以铂金会员身份加入Linux基金会。现在,微软针对内测者的Windows商店已经开始提供 部分Linux发…...

[NLP]深入理解 Megatron-LM
一. 导读 NVIDIA Megatron-LM 是一个基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大型语言模型。Megatron-LM 综合应用了数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并…...

软考高级系统架构设计师系列论文七十八:论软件产品线技术
软考高级系统架构设计师系列论文七十八:论软件产品线技术 一、摘要二、正文三、总结一、摘要 本人作为某软件公司负责人之一,通过对位于几个省的国家甲级、乙级、丙级设计院的考查和了解,我决定采用软件产品线方式开发系列《设计院信息管理平台》产品。该产品线开发主要有如…...
yolov5中添加ShuffleAttention注意力机制
ShuffleAttention注意力机制简介 关于ShuffleAttention注意力机制的原理这里不再详细解释.论文参考如下链接here yolov5中添加注意力机制 注意力机制分为接收通道数和不接受通道数两种。这次属于接受通道数注意力机制,这种注意力机制由于有通道数要求,所示我们添加的时候…...
)
Effective C++条款17——以独立语句将newed 对象置入智能指针(资源管理)
假设我们有个函数用来揭示处理程序的优先权,另一个函数用来在某动态分配所得的widget上进行某些带有优先权的处理: void priority(); void processWidget(std::tr1::shared_ptr<Widget>pw, int priority);由于谨记“以对象管理资源”(条款13&…...

奇迹MU服务器如何选择配置?奇迹MU服务器租用
不同的服务器,根据其特点与性能适用于不同的应用场景,为了让你们更好的理解,我们对服务器进行了分类归纳,结合了服务器不同的特点以及价位进行一个区分,帮助我们更好的选择合适的服务器配置。 VPS服务器 VPS服务器又…...

本地优先 Web 应用开发:React/SQLite 前端、Supabase 后端与 PowerSync 同步引擎实践
本地优先 Web 应用开发:React/SQLite 前端、Supabase 后端与 PowerSync 同步引擎的实践与优势并非每天都会出现全新架构,如今浏览器内的 SQLite 结合响应式 SQL 和自动同步功能出现了,它能让前端即时交互,还能保持与后端数据一致&…...

三星48层3D V-NAND深度拆解:从电荷陷阱架构到存储密度革命
1. 初探三星48层3D V-NAND:一次深度拆解与工艺解析作为一名长期关注半导体存储技术的从业者,每次拿到业界巨头的新品进行物理层面的拆解分析,都像是一次充满惊喜的“寻宝”之旅。2016年初,当三星将其早在2015年8月就已预告的256Gb…...

ComfyUI IPAdapter Plus完整指南:5个步骤掌握AI图像风格迁移技术
ComfyUI IPAdapter Plus完整指南:5个步骤掌握AI图像风格迁移技术 【免费下载链接】ComfyUI_IPAdapter_plus 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_IPAdapter_plus ComfyUI IPAdapter Plus是ComfyUI平台上功能强大的图像引导生成插件&#x…...

oh-my-prompt:打造高效终端提示符的模块化方案与实战配置
1. 项目概述:为什么我们需要一个现代化的终端提示符?如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那么终端提示符(Prompt)就是你最熟悉的“工作台面”。默认…...
)
从ENVI SARscape到SNAP:手把手教你迁移哨兵1 GRD数据预处理流程(含避坑指南)
从ENVI SARscape到SNAP:哨兵1 GRD数据预处理全流程迁移实战 当雷达遥感领域的工具生态逐渐向开源化倾斜,许多长期依赖ENVI SARscape的研究者开始面临工具迁移的挑战。本文将聚焦哨兵1号GRD数据的预处理流程,为需要从商业软件转向开源工具的用…...
)
告别SSH命令行:用VSCode的Log Viewer插件实时监控Linux syslog日志(附C程序测试)
告别终端监控:在VSCode中实现Linux系统日志可视化追踪 每次调试服务器应用时,你是否也厌倦了在SSH终端和代码编辑器之间反复切换?那些不断滚动的tail -f输出窗口不仅占用宝贵屏幕空间,还让问题排查变成了一场视觉追踪游戏。对于现…...

ngx_http_create_request
1 定义 ngx_http_create_request 函数 定义在 ./nginx-1.24.0/src/http/ngx_http_request.cngx_http_request_t * ngx_http_create_request(ngx_connection_t *c) {ngx_http_request_t *r;ngx_http_log_ctx_t *ctx;ngx_http_core_loc_conf_t *clcf;r ngx_http_…...

模型运行记录
1753...

Keyviz完全指南:5分钟掌握实时键鼠可视化技巧
Keyviz完全指南:5分钟掌握实时键鼠可视化技巧 【免费下载链接】keyviz Keyviz is a free and open-source tool to visualize your keystrokes ⌨️ and 🖱️ mouse actions in real-time. 项目地址: https://gitcode.com/gh_mirrors/ke/keyviz 你…...

5个维度深度解析:如何实现高性能黑苹果系统的架构设计与优化策略
5个维度深度解析:如何实现高性能黑苹果系统的架构设计与优化策略 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 在传统PC硬件与macOS系统兼容性的技术挑战…...