深度学习11:Transformer
目录
什么是 Transformer?
Encoder
Decoder
Attention
Self-Attention
Context-Attention
什么是 Transformer(微软研究院笨笨)
RNN和Transformer区别
Universal Transformer和Transformer 区别
什么是 Transformer?

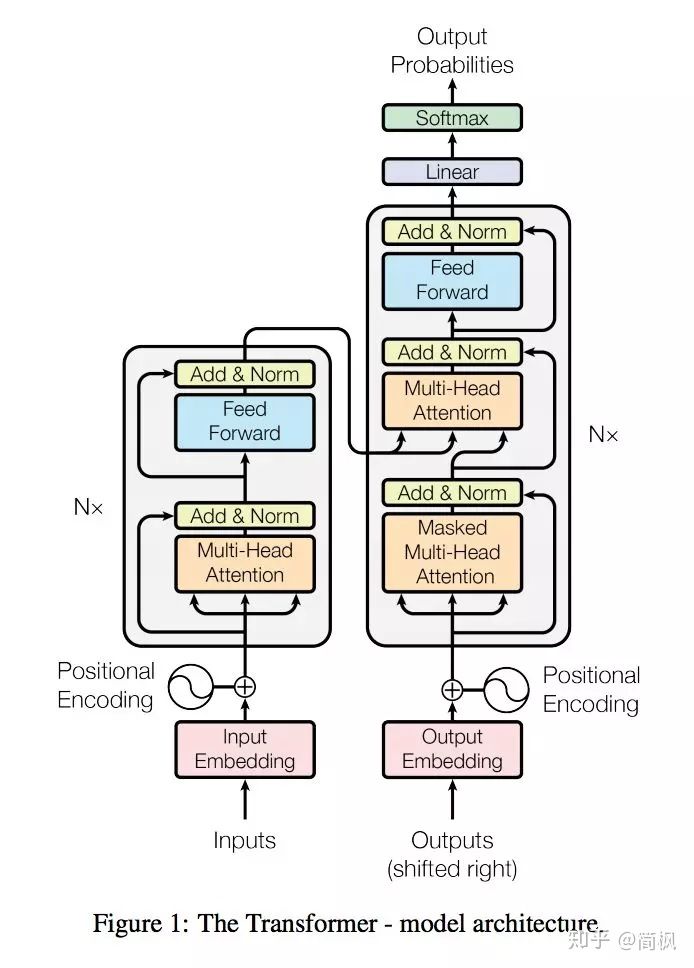
和经典的 seq2seq 模型一样,Transformer 模型中也采用了 encoer-decoder 架构。上图的左半边用 NX 框出来的,就代表一层 encoder,其中论文里面的 encoder 一共有6层这样的结构。上图的右半边用 NX 框出来的,则代表一层 decoder,同样也有6层。
定义输入序列首先经过 word embedding,再和 positional encoding 相加后,输入到 encoder 中。输出序列经过的处理和输入序列一样,然后输入到 decoder。
最后,decoder 的输出经过一个线性层,再接 Softmax。
于上便是 Transformer 的整体框架,下面先来介绍 encoder 和 decoder。
Encoder
encoder由 6 层相同的层组成,每一层分别由两部分组成:
- 第一部分是 multi-head self-attention
- 第二部分是 position-wise feed-forward network,是一个全连接层
两个部分,都有一个残差连接(residual connection),然后接着一个 Layer Normalization。
Decoder
和 encoder 类似,decoder 也是由6个相同的层组成,每一个层包括以下3个部分:
- 第一个部分是 multi-head self-attention mechanism
- 第二部分是 multi-head context-attention mechanism
- 第三部分是一个 position-wise feed-forward network
和 encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。
decoder 和 encoder 不同的地方在 multi-head context-attention mechanism
Attention
我在以前的文章中讲过,Attention 如果用一句话来描述,那就是 encoder 层的输出经过加权平均后再输入到 decoder 层中。它主要应用在 seq2seq 模型中,这个加权可以用矩阵来表示,也叫 Attention 矩阵。它表示对于某个时刻的输出 y,它在输入 x 上各个部分的注意力。这个注意力就是我们刚才说到的加权。
Attention 又分为很多种,其中两种比较典型的有加性 Attention 和乘性 Attention。加性 Attention 对于输入的隐状态 ht 和输出的隐状态 st 直接做 concat 操作,得到 [st;ht] ,乘性 Attention 则是对输入和输出做 dot 操作。
在 Google 这篇论文中,使用的 Attention 模型是乘性 Attention。
我在之前讲 ESIM 模型的文章里面写过一个 soft-align-attention,大家可以参考体会一下。
Self-Attention
上面我们说attention机制的时候,都会说到两个隐状态,分别是 hi 和 st。前者是输入序列第 i个位置产生的隐状态,后者是输出序列在第 t 个位置产生的隐状态。所谓 self-attention 实际上就是,输出序列就是输入序列。因而自己计算自己的 attention 得分。
Context-Attention
context-attention 是 encoder 和 decoder 之间的 attention,是两个不同序列之间的attention,与来源于自身的 self-attention 相区别。
不管是哪种 attention,我们在计算 attention 权重的时候,可以选择很多方式,常用的方法有
- additive attention
- local-base
- general
- dot-product
- scaled dot-product
Transformer模型采用的是最后一种:scaled dot-product attention。
什么是 Transformer(微软研究院笨笨)
Transformer是一个完全基于注意力机制的编解码器模型,它抛弃了之前其它模型引入注意力机制后仍然保留的循环与卷积结构,而采用了自注意力(Self-attention)机制,在任务表现、并行能力和易于训练性方面都有大幅的提高。
在 Transformer 出现之前,基于神经网络的机器翻译模型多数都采用了 RNN的模型架构,它们依靠循环功能进行有序的序列操作。虽然 RNN 架构有较强的序列建模能力,但是存在训练速度慢,训练质量低等问题。
RNN和Transformer区别
与基于 RNN 的方法不同,Transformer 模型中没有循环结构,而是把序列中的所有单词或者符号并行处理,同时借助自注意力机制对句子中所有单词之间的关系直接进行建模,而无需考虑各自的位置。
具体而言,如果要计算给定单词的下一个表征,Transformer 会将该单词与句子中的其它单词一一对比,并得出这些单词的注意力分数。注意力分数决定其它单词对给定词汇的语义影响。之后,注意力分数用作所有单词表征的平均权重,这些表征输入全连接网络,生成新表征。
由于 Transformer 并行处理所有的词,以及每个单词都可以在多个处理步骤内与其它单词之间产生联系,它的训练速度比 RNN 模型更快,在翻译任务中的表现也比 RNN 模型更好。除了计算性能和更高的准确度,Transformer 另一个亮点是可以对网络关注的句子部分进行可视化,尤其是在处理或翻译一个给定词时,因此可以深入了解信息是如何通过网络传播的。
之后,Google的研究人员们又对标准的 Transformer 模型进行了拓展,采用了一种新型的、注重效率的时间并行循环结构,让它具有通用计算能力,并在更多任务中取得了更好的结果。
改进的模型(Universal Transformer)在保留Transformer 模型原有并行结构的基础上,把 Transformer 一组几个各异的固定的变换函数替换成了一组由单个的、时间并行的循环变换函数构成的结构。
相比于 RNN一个符号接着一个符号从左至右依次处理序列,Universal Transformer 和 Transformer 能够一次同时处理所有的符号
Universal Transformer和Transformer 区别
但 Universal Transformer 接下来会根据自注意力机制对每个符号的解释做数次并行的循环处理修饰。Universal Transformer 中时间并行的循环机制不仅比 RNN 中使用的串行循环速度更快,也让 Universal Transformer 比标准的前馈 Transformer 更加强大。
相关文章:
深度学习11:Transformer
目录 什么是 Transformer? Encoder Decoder Attention Self-Attention Context-Attention 什么是 Transformer(微软研究院笨笨) RNN和Transformer区别 Universal Transformer和Transformer 区别 什么是 Transformer? …...
免费开源跨平台视频下载器 支持数百站点视频和音频下载-ytDownloader
ytDownloader: ytDownloader是一款免费开源跨平台视频下载器,帮助用户从数百个网站下载不同格式的视频和提取音频,使用简单,复制视频链接粘贴即可下载,支持4K画质视频下载,支持Linux、Windows 和 macOS平台…...
R包开发1:RStudio 与 GitHub建立连接
目录 1.安装Git 2-配置Git(只需配置一次) 3-用SSH连接GitHub(只需配置一次) 4-创建Github远程仓库 5-克隆仓库到本地 目标:创建的R包,包含Git版本控制,并且能在远程Github仓库同步,相当于发布在Github。…...
红蓝攻防:浅谈削弱WindowsDefender的各种方式
前言 随着数字技术的日益进步,我们的生活、工作和娱乐越来越依赖于计算机和网络系统。然而,与此同时,恶意软件也日趋猖獗,寻求窃取信息、破坏系统或仅仅为了展现其能力。微软Windows,作为世界上最流行的操作系统&…...

什么是响应式设计(Responsive Design)?如何实现一个响应式网页?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 响应式设计(Responsive Design)⭐ 如何实现一个响应式网页?1. 弹性网格布局2. 媒体查询3. 弹性图像和媒体4. 流式布局5. 优化导航6. 测试和调整7. 图片优化8. 字体优化9. 渐进增强10. 面向移动优先11. …...

QT之应用程序执行脚本
简介 ● Qt中的类QProcess支持在程序中另外开辟线程 ● 其中start方法支持以字符串为参数执行命令 以Linux平台为例: 方式一(后台执行) /// /// \brief MainWindow::cmdLine run a linux command with string format in the bash /// \pa…...

学习文档链接
SpringBoot Activiti 完美结合,快速实现工作流(最详细版) - 知乎 (zhihu.com) easypoi: POI 工具类,Excel的快速导入导出,Excel模板导出,Word模板导出,可以仅仅5行代码就可以完成Excel的导入导出,修改导出格式简单粗暴,快速有效,easypoi值得…...

【Java 高阶】一文精通 Spring MVC - 转换器(五)
👉博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO 专家博主 ⛪️ 个人社区&#x…...
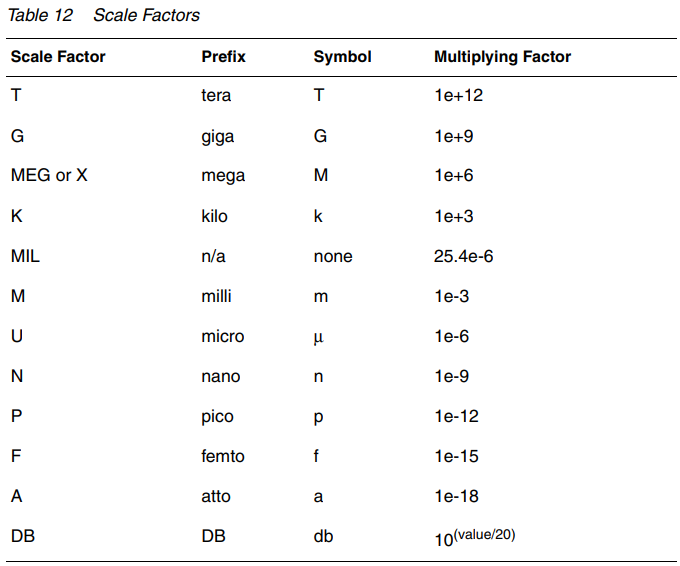
【HSPCIE仿真】输入网表文件(1)基本内容和基本规则
输入网表文件 1. 输入网表文件基本内容2. 输入网表文件示例3. 一些基本规则4. 数值表示5. 压缩文件格式的读取6. 参数和表达式 从HSPICE的仿真流程看,出去初始化配置过程,真正的仿真是从输入网表文件开始的。 HSPICE 根据输入网表文件( inpu…...

IBM Db2 笔记
目录 1. IBM Db2 笔记1.1. 常用命令1.2. 登录命令行模式 (Using the Db2 command line processor)1.3. issue1.3.1. db2: command not found/SQL10007N Message "-1390" could not be retreived. Reason code: "3".1.3.2. db2 修改 dbm cfg 的时候报 SQL50…...

【Cortex-M3权威指南】学习笔记2 - 指令集
目录 指令集汇编语言基础UAL 近距离检视指令数据传输数据处理子程呼叫与无条件跳转指令标志位与条件转移指令隔离指令饱和运算 CM3 中新引入指令MRS\MSRIF-THENCBZ/CBNZSDIV/UDIVREV RBITSXTBTBB,TBH 指令集 汇编语言基础 一条简单的汇编指令格式(注释使用一个分号…...
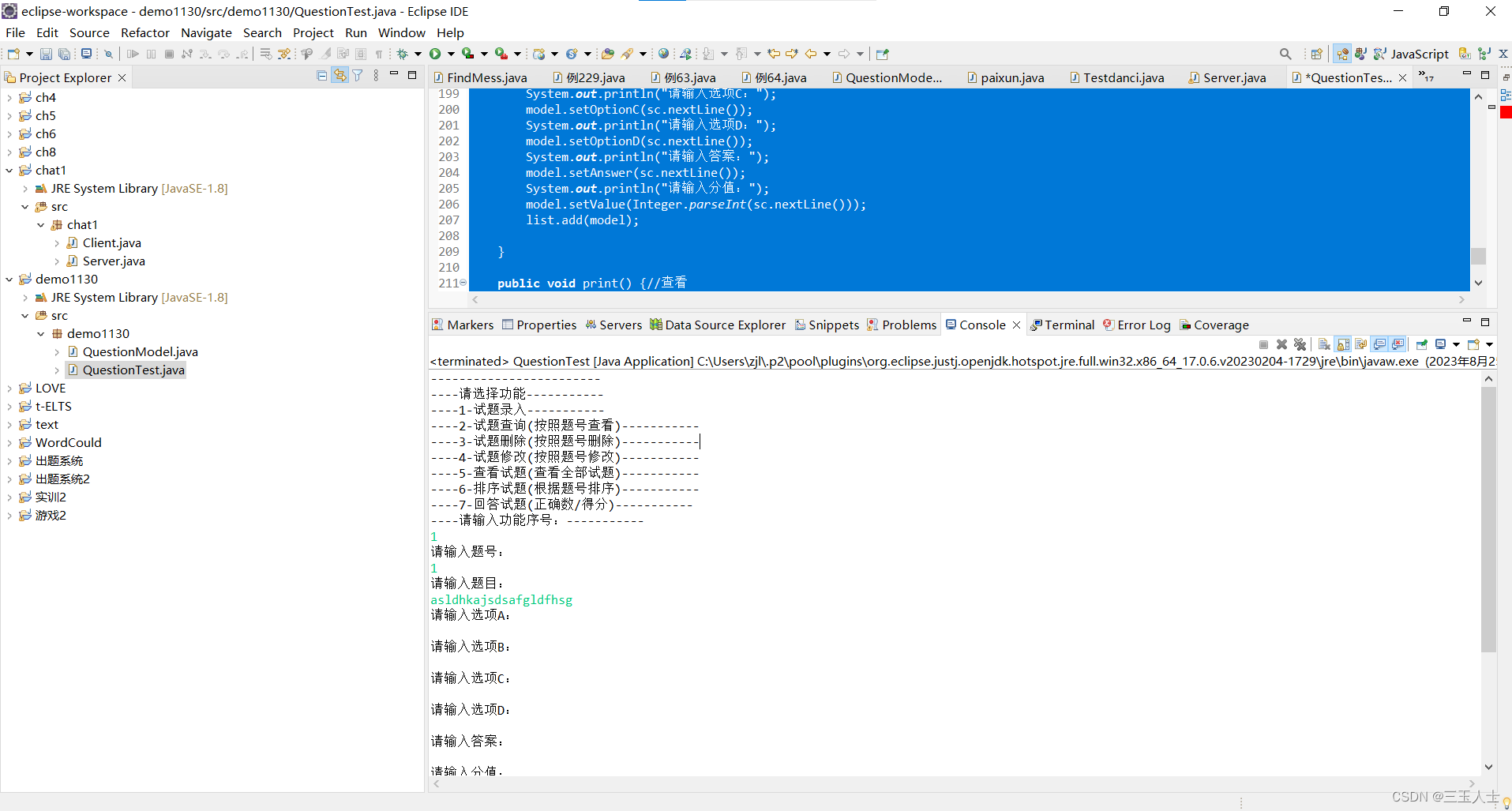
Java——一个Java实体类,表示一个试题的模型
这段代码是一个Java实体类,表示一个试题的模型。 该实体类具有以下属性: id:题号,表示试题的编号。title:题目,表示试题的题目内容。optionA:选项A,表示试题的选项A。optionB&#…...

PHP8函数的引用和取消-PHP8知识详解
今天分享的是php8函数的引用和取消,不过在PHP官方的参考手册中,已经删除了此类教程。 1、函数的引用 在PHP8中不管是自定义函数还是内置函数,都可以直接简单的通过函数名调佣。函数的引用大致有下面3种: 1.1、如果是PHP的内置函…...

华为OD机试真题【最大利润】
1、题目描述 【最大利润】 商人经营一家店铺,有number种商品,由于仓库限制每件商品的最大持有数量是item[index] 每种商品的价格是item-price[item_index][day] 通过对商品的买进和卖出获取利润 请给出商人在days天内能获取的最大的利润 注:…...

YOLOv5+deepsort实现目标追踪。(附有各种错误解决办法)
一、YOLOv5算法相关配置 🐸这里如果是自己只想跑一跑YOLOV5的话,可以参考本章节。只想跑通YOLOv5+deepsort的看官移步到下一章节。 1.1 yolov5下载 🐸yolov5源码在github下载地址上或者Gitee上面都有。需要注意的是由于yolov5的代码库作者一直在维护,所以下载的时候需…...
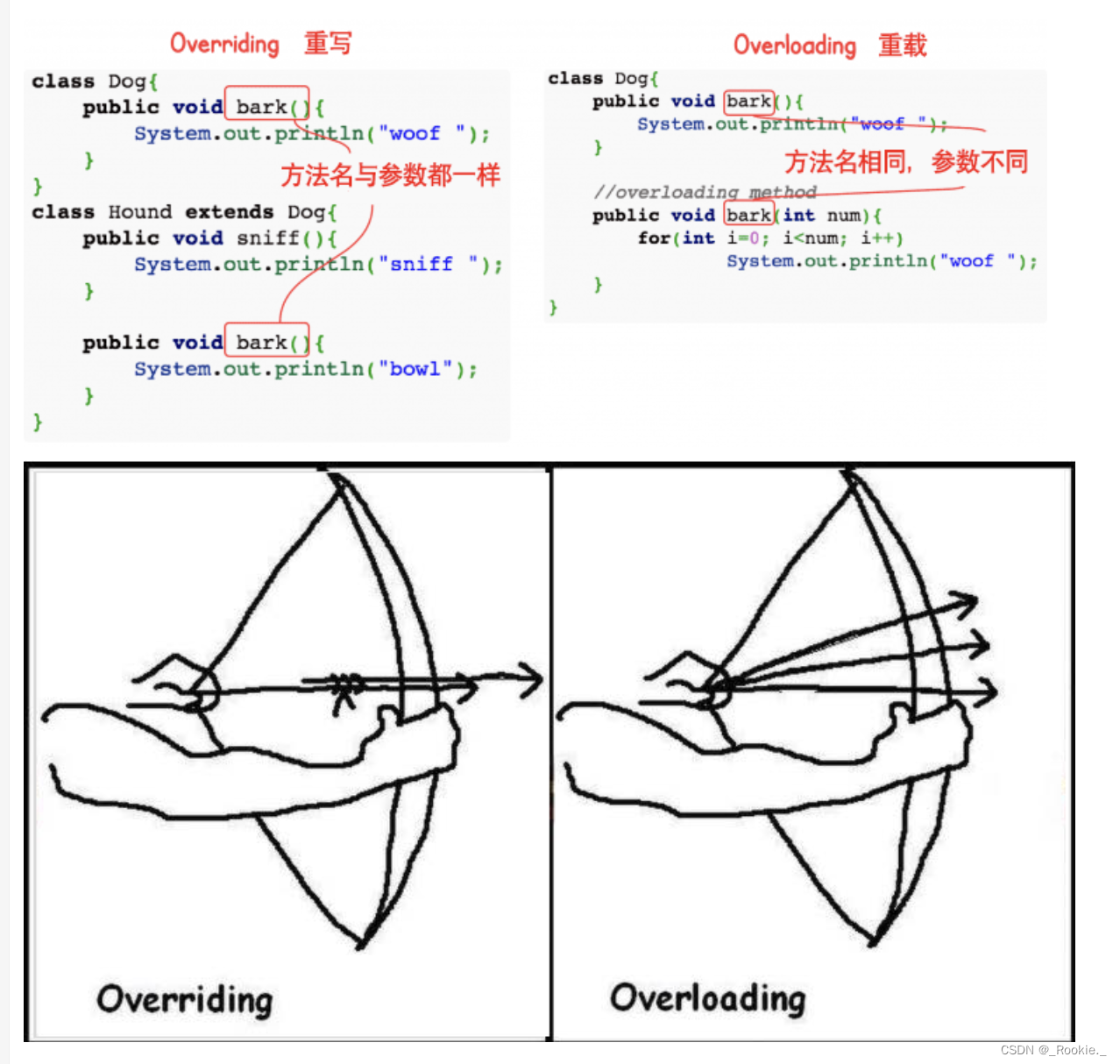
java.8 - java -overrideoverload 重写和重载
重写(Override) 重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写! 重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。 重写方法不…...

oracle通配符大全
用于where比较条件的有 : 等于:、<、<、>、>、<> >,<:大于,小于 >.<:大于等于,小于等于 :等于 !,<>,^:不等于 包含:in、not in exists、not exists 范围:betwe…...
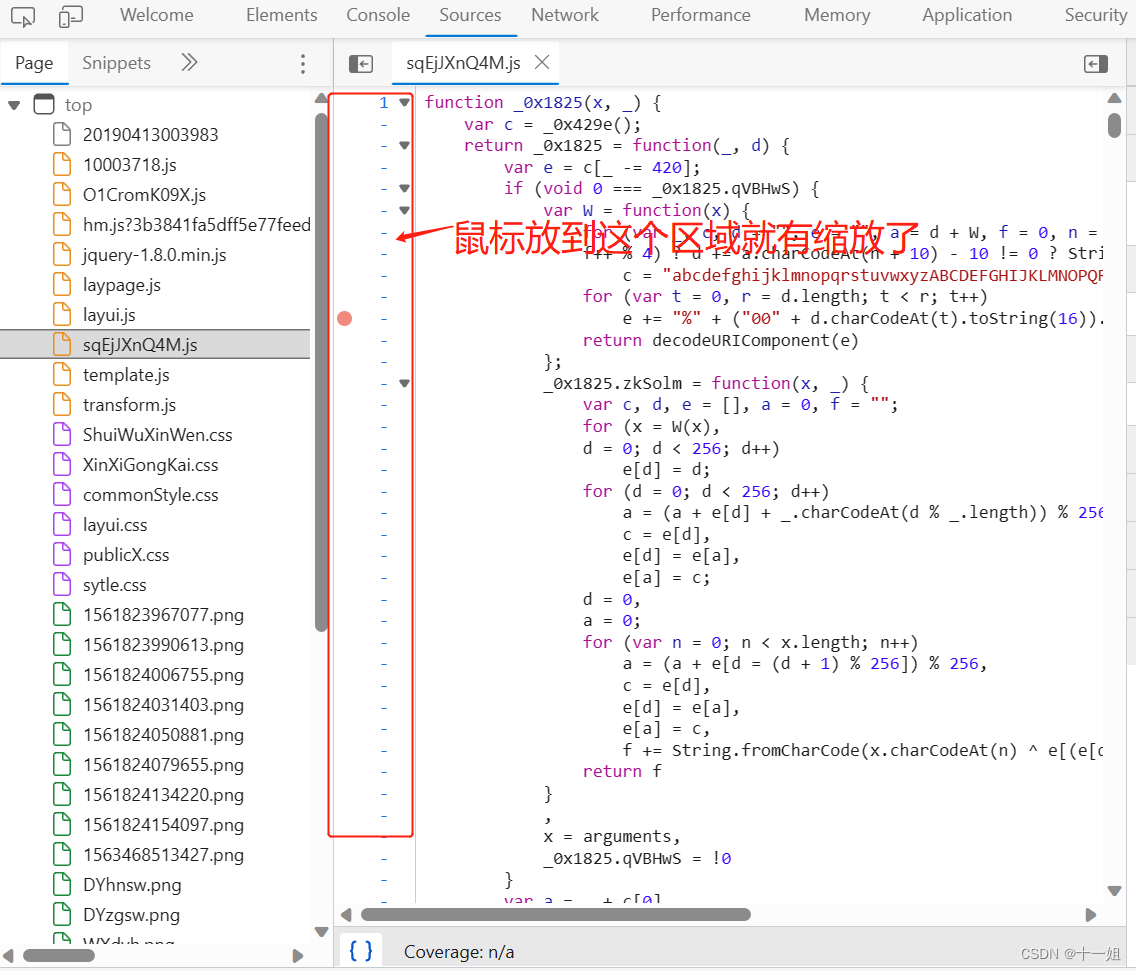
浏览器开发者工具平台js代码开启展开收起
1、如下js左侧可以展开和收起段落,需要打开右上角的设置 2、Preferences这里勾选Code folding 即可像上面那张图展开和收起js段落代码 3、然后重新打开开发者工具,随意打开一个js文件,这里就有缩放了...

opencv 案例实战01-停车场车牌识别实战
需求分析: 车牌识别技术主要应用领域有停车场收费管理,交通流量控制指标测量,车辆定位,汽车防盗,高速公路超速自动化监管、闯红灯电子警察、公路收费站等等功能。对于维护交通安全和城市治安,防止交通堵塞…...
【PHP】PHP开发教程-PHP开发环境安装
1、PHP简单介绍 PHP(全称:Hypertext Preprocessor)是一种广泛使用的开放源代码脚本语言,特别适用于Web开发。它嵌入在HTML中,通过在HTML文档中添加PHP标记和脚本,可以生成动态的、个性化的Web页面。 PHP最…...

AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则”
AXI协议深度解析:从握手到低功耗,一次搞懂芯片内部数据流的那些“潜规则” 在当今高性能计算和复杂SoC设计中,AXI协议已成为连接处理器、存储器和外设的黄金标准。但真正理解AXI的精髓,远不止于掌握基础操作——那些隐藏在规范字里…...

构建AI助手持久记忆系统:Rekall项目实践与MCP协议应用
1. 项目概述:为你的AI助手构建一个“第二大脑”如果你和我一样,日常重度依赖 Claude Code、Cursor 这类AI编程助手,那你一定遇到过这个痛点:每次开启一个新的会话,AI助手就像得了“健忘症”,对之前讨论过的…...

从零到精通:AI大模型学习路线图,手把手带你入门!
本文提供了一条从基础到高级的AI大模型学习路线图,涵盖数学与编程基础、机器学习入门、深度学习实践、大模型探索以及进阶应用等方面。文章推荐了丰富的学习资源,包括经典书籍、在线课程、实践项目和开源平台,旨在帮助新手小白系统学习AI大模…...

冻|结D球 2026
通过网盘分享的文件:冻|结D球 2026 链接: https://pan.baidu.com/s/1-bhxibfD69ahEoufeQFRRQ?pwdhygv 提取码: hygv...

LaMa图像修复:基于傅里叶卷积的大掩码鲁棒修复方法
1. 项目概述:这不是又一个“修图工具”,而是一次对图像修复底层逻辑的重新定义LaMa——全称Large Mask Inpainting,直译是“大区域掩码图像修复”,但它的实际能力远超字面。我第一次在CVPR 2022论文里看到它时,第一反应…...

淘金币全自动脚本终极指南:3分钟搞定淘宝每日任务,解放双手的简单教程
淘金币全自动脚本终极指南:3分钟搞定淘宝每日任务,解放双手的简单教程 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mir…...

通过用量看板与透明账单有效控制大模型 API 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板与透明账单有效控制大模型 API 调用成本 对于依赖大模型 API 进行开发的团队而言,成本控制是一个贯穿始终…...
)
别再复制粘贴了!手把手教你用MATLAB/Simulink把低通滤波器写成C代码(附差分方程推导避坑点)
从MATLAB到嵌入式C:工业级低通滤波器实现全解析 在电机控制、信号处理等嵌入式应用中,低通滤波器的实现质量直接影响系统性能。许多工程师习惯直接复制现成代码,却常遭遇数值不稳定、相位失真或计算效率低下等问题。本文将彻底拆解从S域传递函…...

国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案
国家中小学智慧教育平台电子课本下载工具:教育资源获取的完整解决方案 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内…...

RapidIO多播技术原理与应用实践
1. RapidIO多播技术概述 在分布式计算和高速互连系统中,多播(Multicast)技术扮演着至关重要的角色。简单来说,多播就像是在会议室里用广播系统发布通知——只需说一次,所有打开扬声器的房间都能同时听到。RapidIO作为高…...