Mysql的多表查询和索引
MySQL
多表查询
当两个表查询时,从第一张表中取出一行和第二张表的每一行进行组合
返回结果含有两张表的所有列,一共返回的记录数第一张表行数*第二张表的行数(笛卡尔积)
-- ?显示雇员名,雇员工资及所在部门的名字 【笛卡尔集】
/*1. 雇员名,雇员工资 来自 emp表2. 部门的名字 来自 dept表3. 需求对 emp 和 dept查询 ename,sal,dname,deptno4. 当我们需要指定显示某个表的列是,需要 表.列表
*/
SELECT ename,sal,dname,emp.deptnoFROM emp, dept WHERE emp.deptno = dept.deptnoselect * from emp;
select * from dept;
select * from salgrade;
-- 小技巧:多表查询的条件不能少于 表的个数-1, 否则会出现笛卡尔集
-- ?如何显示部门号为10的部门名、员工名和工资
-- 重复的deptno要标清是哪个表的
SELECT ename,sal,dname,emp.deptnoFROM emp, dept WHERE emp.deptno = dept.deptno and emp.deptno = 10
自连接
自连接是指在同一张表的连接查询[将同一张表看做两张表]。
-- 多表查询的 自连接-- 显示公司员工名字和他的上级的名字-- 员工名字 在emp, 上级的名字的名字 emp
-- 员工和上级是通过 emp 表的 mgr 列关联
-- 自连接的特点 1. 把同一张表当做两张表使用
-- 2. 需要给表取别名 表名 表别名
-- 3. 列名不明确,可以指定列的别名 列名 as 列的别名 SELECT worker.ename AS '职员名' , boss.ename AS '上级名'FROM emp worker, emp boss -- 同一张表用不同的别名WHERE worker.mgr = boss.empno;
子查询
子查询是指嵌入在其它 sql 语句中的select 语句,也叫嵌套查询
单行子查询是指只返回一行数据的子查询语句
多行子查询指返回多行数据的子查询 使用关键字in
-- 显示与SMITH同一部门的所有员工?
/*1. 先查询到 SMITH的部门号得到2. 把上面的select 语句当做一个子查询来使用
*/
SELECT deptno FROM emp WHERE ename = 'SMITH'SELECT * FROM empWHERE deptno = (SELECT deptno FROM emp WHERE ename = 'SMITH')-- 如何查询和部门10的工作相同的雇员的
-- 名字、岗位、工资、部门号, 但是不含10号部门自己的雇员./*1. 查询到10号部门有哪些工作2. 把上面查询的结果当做子查询使用
*/select ename, job, sal, deptnofrom empwhere job in (SELECT DISTINCT job FROM emp WHERE deptno = 10) and deptno <> 10
子查询当临时表使用
-- 查找每个部门工资高于本部门平均工资的人的资料
-- 把一个子查询当作一个临时表使用-- 1. 先得到每个部门的 部门号和 对应的平均工资SELECT deptno, AVG(sal) AS avg_salFROM emp GROUP BY deptno-- 2. 把上面的结果当做子查询,作为temp表, 和 emp 进行多表查询
SELECT ename, sal, temp.avg_sal, emp.deptnoFROM emp, (SELECT deptno, AVG(sal) AS avg_salFROM emp GROUP BY deptno) temp where emp.deptno = temp.deptno and emp.sal > temp.avg_sal-- 查找每个部门工资最高的人的详细资料SELECT ename, sal, temp.max_sal, emp.deptnoFROM emp, (SELECT deptno, max(sal) AS max_salFROM emp GROUP BY deptno) temp WHERE emp.deptno = temp.deptno AND emp.sal = temp.max_sal-- 查询每个部门的信息(包括:部门名,编号,地址)和人员数量-- 1. 部门名,编号,地址 来自 dept表
-- 2. 各个部门的人员数量 -》 构建一个临时表select count(*), deptno from empgroup by deptno;select dname, dept.deptno, loc , tmp.per_num as '人数'from dept, (SELECT COUNT(*) as per_num, deptno FROM empGROUP BY deptno) tmp where tmp.deptno = dept.deptno-- 还有一种写法 表.* 表示将该表所有列都显示出来, 可以简化sql语句
-- 在多表查询中,当多个表的列不重复时,才可以直接写列名SELECT tmp.* , dname, locFROM dept, (SELECT COUNT(*) AS per_num, deptno FROM empGROUP BY deptno) tmp WHERE tmp.deptno = dept.deptno
多行子查询中使用 all 或 any 操作符
-- 显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号SELECT ename, sal, deptnoFROM empWHERE sal > ALL(SELECT sal FROM empWHERE deptno = 30)
-- 可以这样写
SELECT ename, sal, deptnoFROM empWHERE sal > (SELECT MAX(sal) FROM empWHERE deptno = 30) -- 显示工资比部门30的其中一个员工的工资高的员工的姓名、工资和部门号SELECT ename, sal, deptnoFROM empWHERE sal > any(SELECT sal FROM empWHERE deptno = 30)SELECT ename, sal, deptnoFROM empWHERE sal > (SELECT min(sal) FROM empWHERE deptno = 30)
多列子查询
多列子查序则是指查询返回多个列数据的子查询语句
-- 查询与allen的部门和岗位完全相同的所有雇员(并且不含allen本人)
-- (字段1, 字段2 ...) = (select 字段 1,字段2 from 。。。。)-- 分析: 1. 得到smith的部门和岗位SELECT deptno , jobFROM emp WHERE ename = 'ALLEN'-- 分析: 2 把上面的查询当做子查询来使用,并且使用多列子查询的语法进行匹配
SELECT * FROM empWHERE (deptno , job) = (SELECT deptno , jobFROM emp WHERE ename = 'ALLEN') AND ename != 'ALLEN'-- 请查询 和宋江数学,英语,语文
-- 成绩 完全相同的学生
SELECT * FROM studentWHERE (math, english, chinese) = (SELECT math, english, chineseFROM studentWHERE `name` = '宋江')
在from 子句中使用子查询
-- 查找每个部门工资高于本部门平均工资的人的资料
-- 把一个子查询当作一个临时表使用-- 1. 先得到每个部门的 部门号和 对应的平均工资SELECT deptno, AVG(sal) AS avg_salFROM emp GROUP BY deptno-- 2. 把上面的结果当做子查询, 和 emp 进行多表查询
--
SELECT ename, sal, temp.avg_sal, emp.deptnoFROM emp, (SELECT deptno, AVG(sal) AS avg_salFROM emp GROUP BY deptno) temp where emp.deptno = temp.deptno and emp.sal > temp.avg_sal-- 查找每个部门工资最高的人的详细资料SELECT ename, sal, temp.max_sal, emp.deptnoFROM emp, (SELECT deptno, max(sal) AS max_salFROM emp GROUP BY deptno) temp WHERE emp.deptno = temp.deptno AND emp.sal = temp.max_sal-- 查询每个部门的信息(包括:部门名,编号,地址)和人员数量-- 1. 部门名,编号,地址 来自 dept表
-- 2. 各个部门的人员数量 -》 构建一个临时表select count(*), deptno from empgroup by deptno;select dname, dept.deptno, loc , tmp.per_num as '人数'from dept, (SELECT COUNT(*) as per_num, deptno FROM empGROUP BY deptno) tmp where tmp.deptno = dept.deptno-- 还有一种写法 表.* 表示将该表所有列都显示出来, 可以简化sql语句
-- 在多表查询中,当多个表的列不重复时,才可以直接写列名SELECT tmp.* , dname, locFROM dept, (SELECT COUNT(*) AS per_num, deptno FROM empGROUP BY deptno) tmp WHERE tmp.deptno = dept.deptno
表复制
有时,为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据。
-- 表的复制
-- 为了对某个sql语句进行效率测试,我们需要海量数据时,可以使用此法为表创建海量数据CREATE TABLE my_tab01 ( id INT,`name` VARCHAR(32),sal DOUBLE,job VARCHAR(32),deptno INT);
DESC my_tab01
SELECT * FROM my_tab01;-- 演示如何自我复制
-- 1. 先把emp 表的记录复制到 my_tab01
INSERT INTO my_tab01 (id, `name`, sal, job,deptno)SELECT empno, ename, sal, job, deptno FROM emp;-- 2. 自我复制
INSERT INTO my_tab01SELECT * FROM my_tab01;
SELECT COUNT(*) FROM my_tab01;-- 如何删除掉一张表重复记录
-- 1. 先创建一张表 my_tab02,
-- 2. 让 my_tab02 有重复的记录CREATE TABLE my_tab02 LIKE emp; -- 这个语句 把emp表的结构(列),复制到my_tab02desc my_tab02;insert into my_tab02select * from emp;
select * from my_tab02;
-- 3. 考虑去重 my_tab02的记录
/*思路 (1) 先创建一张临时表 my_tmp , 该表的结构和 my_tab02一样(2) 把my_tmp 的记录 通过 distinct 关键字 处理后 把记录复制到 my_tmp(3) 清除掉 my_tab02 记录(4) 把 my_tmp 表的记录复制到 my_tab02(5) drop 掉 临时表my_tmp
*/
-- (1) 先创建一张临时表 my_tmp , 该表的结构和 my_tab02一样create table my_tmp like my_tab02
-- (2) 把my_tmp 的记录 通过 distinct 关键字 处理后 把记录复制到 my_tmp
insert into my_tmp select distinct * from my_tab02;-- (3) 清除掉 my_tab02 记录
delete from my_tab02;
-- (4) 把 my_tmp 表的记录复制到 my_tab02
insert into my_tab02select * from my_tmp;
-- (5) drop 掉 临时表my_tmp
drop table my_tmp;select * from my_tab02;
合并查询
有时在实际应用中,为了合并多个 select 语句的结果,可以使用集合操作符号 union, union all。
- union all:该操作符用于取得两个结果集的并集。当使用该操作符时,不会取消重复行
- union:该操作赋与union all相似,但是会自动去掉结果集中重复行
-- 合并查询
SELECT ename,sal,job FROM emp WHERE sal>2500 -- 5
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3-- union all 就是将两个查询结果合并,不会去重
SELECT ename,sal,job FROM emp WHERE sal>2500 -- 5
UNION ALL
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3-- union 就是将两个查询结果合并,会去重
SELECT ename,sal,job FROM emp WHERE sal>2500 -- 5
UNION
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3
mysql 表外连接
前面我们学习的查询,是利用where子句对两张表或者多张表,形成的笛卡尔积进行筛选
根据关联条件显示所有匹配的记录,匹配不上的不显示。
-
左外连接(如果左侧的表完全显示我们就说是左外连接)
-
右外连接(如果右侧的表完全显示我们就说是右外连接)
-- 比如:列出部门名称和这些部门的员工名称和工作,
-- 同时要求 显示出那些没有员工的部门。-- 使用学习过的多表查询的SQL, 看看效果如何?SELECT dname, ename, job FROM emp, deptWHERE emp.deptno = dept.deptnoORDER BY dname
SELECT * FROM dept;SELECT * FROM emp;-- 创建 stu
/*
id name
1 Jack
2 Tom
3 Kity
4 nono
*/
CREATE TABLE stu (id INT,`name` VARCHAR(32));
INSERT INTO stu VALUES(1, 'jack'),(2,'tom'),(3, 'kity'),(4, 'nono');
SELECT * FROM stu;
-- 创建 exam
/*
id grade
1 56
2 76
11 8*/
CREATE TABLE exam(id INT,grade INT);
INSERT INTO exam VALUES(1, 56),(2,76),(11, 8);
SELECT * FROM exam;-- 使用左连接
-- (显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩显示为空)SELECT `name`, stu.id, gradeFROM stu, examWHERE stu.id = exam.id;-- 改成左外连接
SELECT `name`, stu.id, gradeFROM stu LEFT JOIN examON stu.id = exam.id;-- 使用右外连接(显示所有成绩,如果没有名字匹配,显示空)
-- 即:右边的表(exam) 和左表没有匹配的记录,也会把右表的记录显示出来
SELECT `name`, stu.id, gradeFROM stu RIGHT JOIN examON stu.id = exam.id;-- 列出部门名称和这些部门的员工信息(名字和工作),
-- 同时列出那些没有员工的部门名。5min
-- 使用左外连接实现
SELECT dname, ename, jobFROM dept LEFT JOIN empON dept.deptno = emp.deptno-- 使用右外连接实现SELECT dname, ename, jobFROM emp RIGHT JOIN deptON dept.deptno = emp.deptno
mysql 索引
CREATE INDEX ename_index ON emp (ename) -- 在 ename 上创建索引
-- 创建测试数据库 tmp
CREATE DATABASE tmp;CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
) ;#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);DELIMITER $$#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
CREATE FUNCTION rand_string(n INT)
RETURNS VARCHAR(255) #该函数会返回一个字符串
BEGIN
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'DECLARE chars_str VARCHAR(100) DEFAULT'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT '';DECLARE i INT DEFAULT 0; WHILE i < n DO# concat 函数 : 连接函数mysql函数SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i = i + 1;END WHILE;RETURN return_str;END $$#这里我们又自定了一个函数,返回一个随机的部门号
CREATE FUNCTION rand_num( )
RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(10+RAND()*500);
RETURN i;
END $$#创建一个存储过程, 可以添加雇员
CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 把autocommit设置成0#autocommit = 0 含义: 不要自动提交SET autocommit = 0; #默认不提交sql语句REPEATSET i = i + 1;#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表INSERT INTO emp VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num());UNTIL i = max_numEND REPEAT;#commit整体提交所有sql语句,提高效率COMMIT;END $$#添加8000000数据
CALL insert_emp(100001,8000000)$$#命令结束符,再重新设置为;
DELIMITER ;SELECT COUNT(*) FROM emp;-- 在没有创建索引时,我们的查询一条记录
SELECT * FROM emp WHERE empno = 1234567
-- 使用索引来优化一下, 体验索引的牛-- 在没有创建索引前 , emp.ibd 文件大小 是 524m
-- 创建索引后 emp.ibd 文件大小 是 655m [索引本身也会占用空间.]
-- 创建ename列索引,emp.ibd 文件大小 是 827m-- empno_index 索引名称
-- ON emp (empno) : 表示在 emp表的 empno列创建索引
CREATE INDEX empno_index ON emp (empno)-- 创建索引后, 查询的速度如何SELECT * FROM emp WHERE empno = 1234578 -- 0.003s 原来是4.5s-- 创建索引后,只对创建了索引的列有效
SELECT * FROM emp WHERE ename = 'PjDlwy' -- 没有在ename创建索引时,时间4.7sCREATE INDEX ename_index ON emp (ename) -- 在ename上创建索引
索引的原理
没有索引会慢是因为全表扫描.
使用索引后形成一个索引的数据结构,比如二叉树索引(有代价 如下)
- 磁盘占用
- 对dml(update delete insert)语句的效率影响,删除或者插入将会对数据结构造成影响,可能会重构。
索引的类
- 主键索引,主键自动的为主索引 (类型
Primary key) - 唯一索引(
UNIQUE) - 普通索引(
INDEX) - 全文索引(
FULLTEXT)[适用于MyISAM]
一般开发不使用mysql自带的全文索引,而是使用全文搜索的框架Solr 和 ElasticSearch ( ES )
create table t1(
id int primary key, -- 主键,同时也是索引,称为主键索引.name varchar(32));
create table t2(
id int unique, -- id是唯一的,同时也是索引,称为unique索引.
索引使用
1.添加索引( 建小表测试id , name )
create [UNIQUE] index index_name on tbl_name (col_ name [(length)][ASC | DESC],......);
alter table table_name ADD INDEX [index_namel (index_col_name,..)
2.添加主键(索引)
ALTER TABLE 表名 ADD PRIMARY KEY(列名...);
3.删除索引
DROP INDEX index_name ON tbl_name,
alter table table_name drop index index_name;
4.删除主键索引比较特别:
alter table t_b drop primary key;
5.查询索引(三种方式)
show index(es) from table_name;
show keys from table_name;
desc table_Name;
-- 创建索引
CREATE TABLE t25 (id INT ,`name` VARCHAR(32));-- 查询表是否有索引
SHOW INDEXES FROM t25;
-- 添加索引
-- 添加唯一索引
CREATE UNIQUE INDEX id_index ON t25 (id);
-- 添加普通索引方式1
CREATE INDEX id_index ON t25 (id);
-- 如何选择
-- 1. 如果某列的值,是不会重复的,则优先考虑使用unique索引, 否则使用普通索引
-- 添加普通索引方式2
ALTER TABLE t25 ADD INDEX id_index (id)-- 添加主键索引
CREATE TABLE t26 (id INT ,`name` VARCHAR(32));
ALTER TABLE t26 ADD PRIMARY KEY (id)SHOW INDEX FROM t25-- 删除索引
DROP INDEX id_index ON t25
-- 删除主键索引
ALTER TABLE t26 DROP PRIMARY KEY-- 修改索引 ,先删除,在添加新的索引-- 查询索引
-- 1. 方式
SHOW INDEX FROM t25
-- 2. 方式
SHOW INDEXES FROM t25
-- 3. 方式
SHOW KEYS FROM t25
-- 4 方式
DESC t25
注意:
- 较频繁的作为查询条件字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引
- 不会出现在
WHERE子句中字段不该创建索引
相关文章:

Mysql的多表查询和索引
MySQL 多表查询 当两个表查询时,从第一张表中取出一行和第二张表的每一行进行组合 返回结果含有两张表的所有列,一共返回的记录数第一张表行数*第二张表的行数(笛卡尔积) -- ?显示雇员名,雇员工资及所在部门的名字 【笛卡尔集…...

Java设计模式之建造者模式
建造者模式,又称生成器模式:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。 三个角色:建造者、具体的建造者、监工、使用者 建造者角色:定义生成实例所需要的所有方法; 具体的建…...
H5商城公众号商城系统源码 积分兑换商城系统独立后台
网购商城系统源码 积分兑换商城系统源码 独立后台附教程 测试环境:NginxPHP7.0MySQL5.6thinkphp伪静态...

华为OD机试 - 完全数计算(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、Java算法源码五、效果展示六、纵览全局 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷)》。 刷的越多&…...

每日一学——Vlan配置
VLAN(Virtual Local Area Network)是虚拟局域网的缩写,它是一种将多台主机和网络设备逻辑上划分成不同的局域网的技术。VLAN的实施可以基于端口、MAC地址、协议等多种方式进行。 VLAN的主要功能包括: 分割网络:VLAN可…...

Pimpl模式
写在前面 Pimpl(Pointer to implementation,又称作“编译防火墙”) 是一种减少代码依赖和编译时间的C编程技巧,其基本思想是将一个外部可见类(visible class)的实现细节(一般是所有私有的非虚成员)放在一个单独的实现类(implemen…...
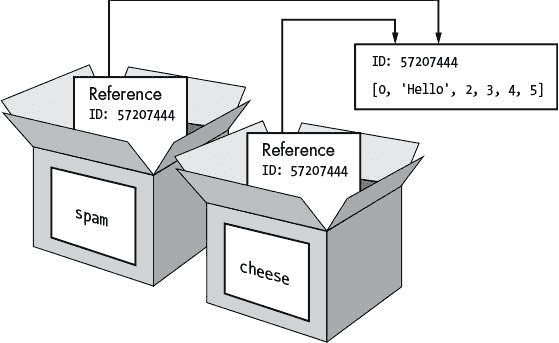
Python 密码破解指南:5~9
协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。 收割 SB 的人会被 SB 们封神,试图唤醒 SB 的人是 SB 眼中的 SB。——SB 第三定律 五、凯…...

ARM驱动开发
驱动 以来内核编译,依赖内核执行 驱动可以同时执行多份代码 没main 驱动是依赖内核的框架和操作硬件的过程 一,Linux系统组成 app: [0-3G] ---------------------------------系统调用(软中断…...

Matlab图像处理-加法运算
加法运算 图像加法运算的一个应用是将一幅图像的内容叠加到另一幅图像上,生成叠加图像效果,或给图像中每个像素叠加常数改变图像的亮度。 在MATLAB图像处理工具箱中提供的函数imadd()可实现两幅图像的相加或者一幅图像和常量的相加。 程序代码 I1 i…...
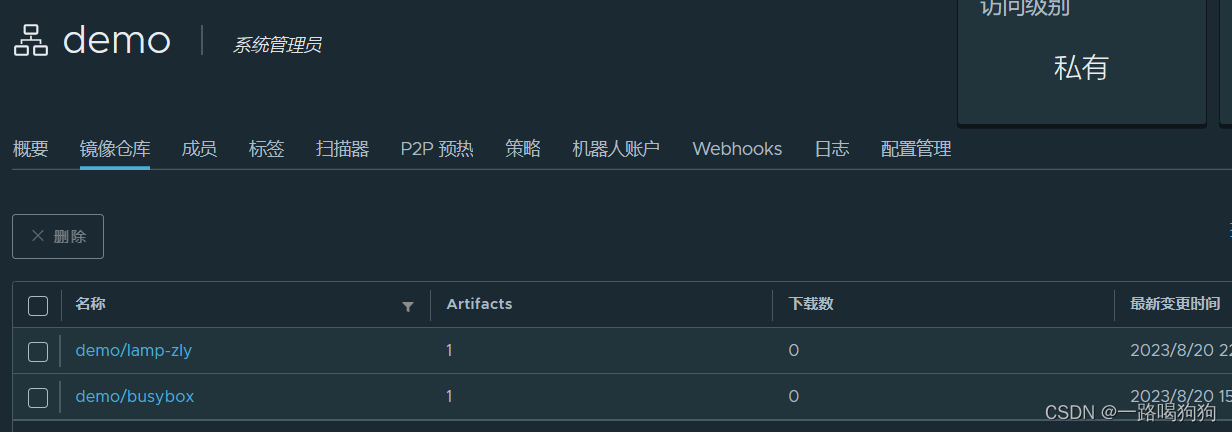
Docker容器学习:搭建自己专属的LAMP环境
目录 编写Dockerfile 1.文件内容需求: 2.值得注意的是centos6官方源已下线,所以需要切换centos-vault源! 3.Dockerfile内容 4.进入到 lamp 开始构建镜像 推送镜像到私有仓库 1.把要上传的镜像打上合适的标签 2.登录harbor仓库 3.上传镜…...

问道管理:沪指弱势震荡跌0.38%,金融、地产等板块走弱,算力概念等活跃
21日早盘,沪指盘中弱势震荡下探,创业板指一度跌逾1%失守2100点;北向资金小幅净流出。 截至午间收盘,沪指跌0.38%报3120.18点,深成指跌0.24%,创业板指跌0.62%;两市算计成交4238亿元,…...

OpenWrt package - BuildPackage
一. 前言 该文章所涉及到的知识都来自OpenWrt Wiki官网。OpenWrt的软件编译模板系统使软件移植到OpenWrt变得非常简单,如果在一个典型的package目录下,我们可以发现3个东西:package/Makefile,package/patches,package/…...

C++三体星战小游戏
物理小游戏,懒得 写注释。 游戏代码 #include<bits/stdc.h> #include<bits/stdc.h> #include<windows.h> #include<conio.h> using namespace std; int toint(double a){return ((int)(a*105))/10;} int rand(int a){return rand()%a;} vo…...
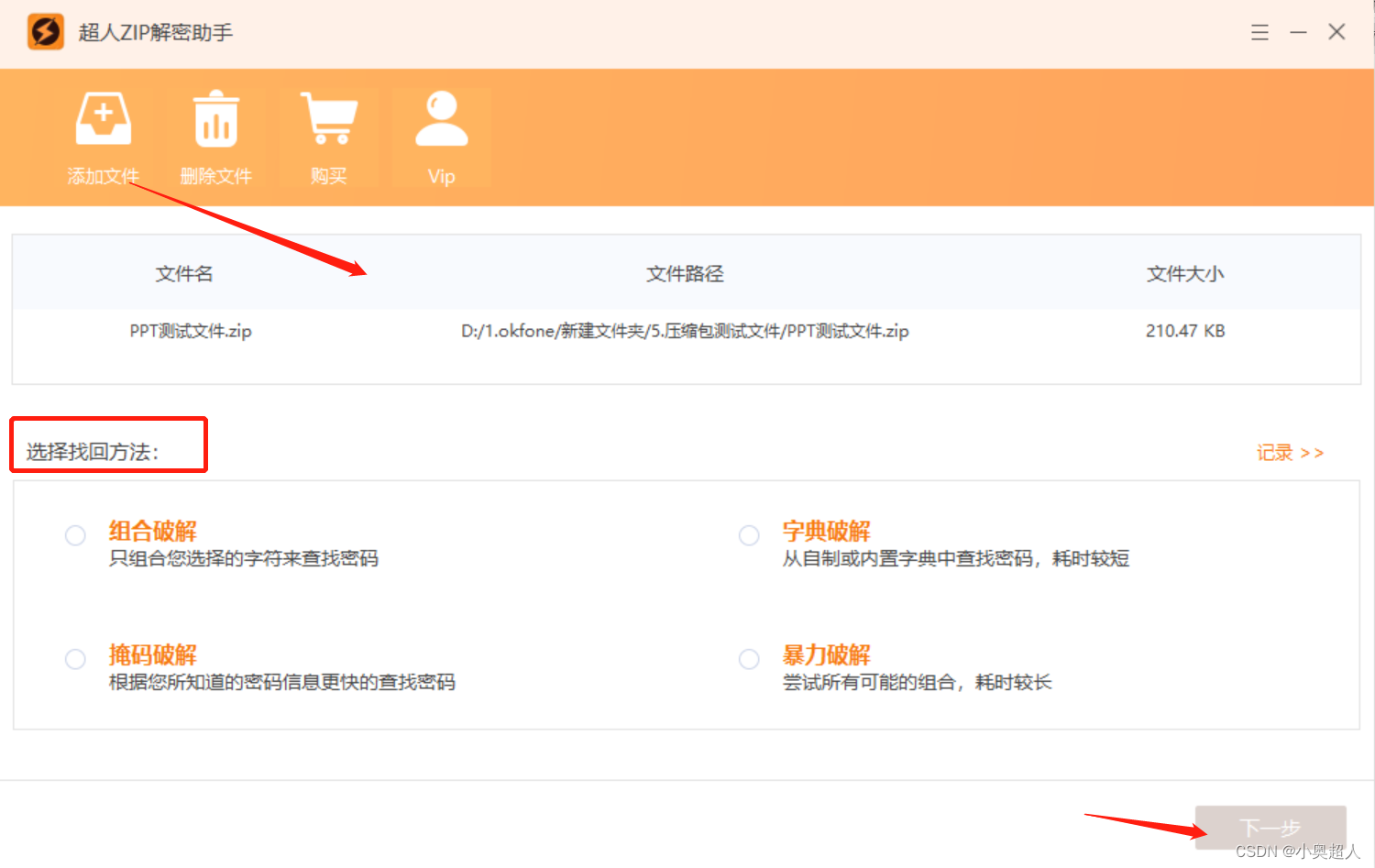
【zip密码】修改zip压缩包密码
Zip压缩包设置了密码,想要修改密码,我们该如何操作?今天分享两个修改zip压缩包密码的方法。 方法一: 输入密码,将zip压缩包里面的文件解压出来。 然后找到解压出来的文件,将文件重新压缩,并且…...

小小讲一下Linux基本命令
Linux是一套类Unix的操作系统,这套系统最大的优点就是安全便捷,快速高效。这就为它赢得了广大的市场空间。但是呢,Linux系统虽然广为流行,它也不是那么容易就可以学会的。比如说,如果我们不懂得Linux系统的基本操作命令…...
详解)
Python数据容器(列表list、元组tuple、字符串str、字典dict、集合set)详解
一、数据容器概念 相关介绍: 一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素。每一个元素,可以是任意类型的数据分为五类:列表[list]、元组(tuple)、字符串(str)、集合{set}、字典{dict} 相应区别:…...

2023高教社杯数学建模思路 - 复盘:人力资源安排的最优化模型
文章目录 0 赛题思路1 描述2 问题概括3 建模过程3.1 边界说明3.2 符号约定3.3 分析3.4 模型建立3.5 模型求解 4 模型评价与推广5 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 描述 …...
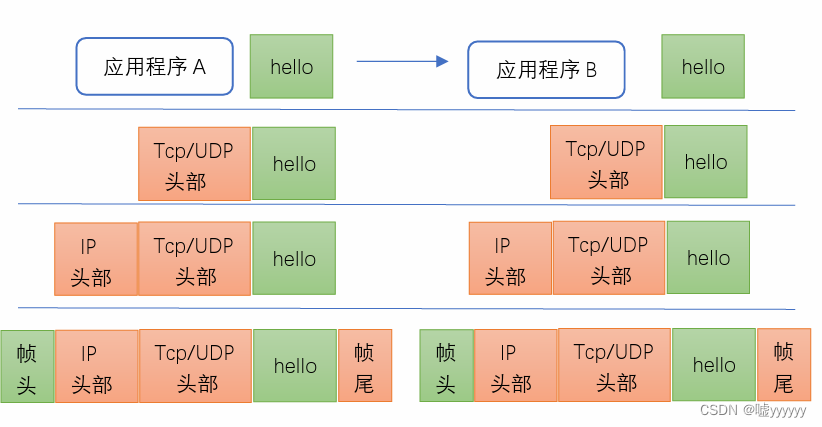
Linux 计算机网络基础概论
一、网络基本概念 1、网络 网络是由若干节点和连接这些结点的链路组成,网络中的结点可以是计算机、交换机、路由器等设备。通俗地说就是把不同的主机连接起来就构成了一个网络,构成网路的目的是为了信息交互、资源共享。 网络设备有:交换机…...

深入理解 C++ 中的 std::cref、std::ref 和 std::reference_wrapper
深入理解 C 中的 std::cref、std::ref 和 std::reference_wrapper 在 C 编程中,有时候我们需要在不进行拷贝的情况下传递引用,或者在需要引用的地方使用常量对象。为了解决这些问题,C 标准库提供了三个有用的工具:std::cref、std:…...
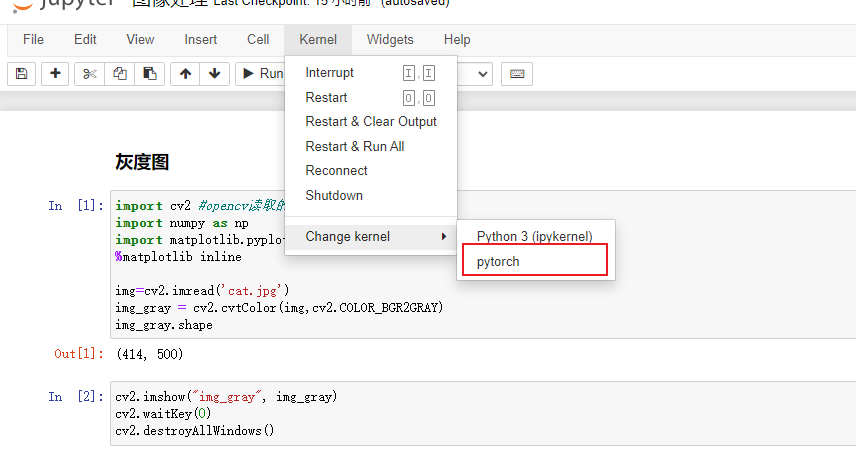
在其他python环境中使用jupyter notebook
1、切换到目标python环境 activate 目标python环境 2、安装notebook内核包 pip install ipykernel 3、加环境加入到notebook中 python -m ipykernel install 目标python环境 4、切换到base环境 activate base 5、打开目标项目的对应盘 如果,项目在c盘&…...
)
从炼丹炉到生产线:在Linux服务器上为Stable Diffusion部署配置PyTorch环境(驱动+CUDA+Anaconda实战)
从炼丹炉到生产线:Linux服务器部署PyTorch环境全流程指南 引言:为什么需要专业化的AI开发环境? 在AI模型开发领域,我们常常把训练模型比作"炼丹"——需要精准控制各种"火候"参数。而要让这个"炼丹炉&quo…...

AI Agent智能体技术:从问答到执行的范式革命
标签:AI Agent、大模型、智能体、LangChain、ReAct、Function Calling 📖 前言 2026年5月20日,谷歌I/O 2026大会在美国加州山景城开幕。谷歌CEO桑达尔皮查伊(Sundar Pichai)在大会上宣布:“我们已正式进入’智能体Gemini时代’。”就在同一天,百度Create 2026大会上,…...

微信小程序 健身服务与轻食间平台系统健身减肥系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能模块技术实现亮点商业模式差异化优势项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 微信…...

Android Native内存泄漏系统化分析与排查实战指南
引言 在Android开发中,内存管理是一个至关重要的环节,直接影响应用的性能、稳定性和用户体验。随着应用复杂度增加,内存泄漏问题日益突出,尤其是在Native层(如C/C++代码),其排查难度更大。Native内存泄漏可能导致应用崩溃、卡顿或系统资源耗尽,因此系统化分析和排查成…...

厂房分区控温需求,水冷空调按需布设灵活调配
在工业生产与商业运营中,高温作业环境长期困扰着企业和劳动者。一方面,传统中央空调的高昂安装与运营成本让大多数中小企业望而却步;另一方面,超大厂房、物流仓库、汽车制造车间等开放或半开放场景,难以实现完全密封&a…...

全球首创 XR+AGV 融合技术,超元力 XR 黑暗乘骑无轨AGV开启星际探险新纪元
传统黑暗乘骑项目长期受困于"被动观影"模式:游客坐在固定轨道车上观看预设影片,缺乏互动性,复购率低。广东超元力文化科技有限公司推出的全球首创 XR 黑暗乘骑无轨 AGV 产品,以 XRAGV 融合技术为核心,将被动…...
)
NotebookLM时间线创建全流程拆解(从零到专业级时间叙事)
更多请点击: https://codechina.net 第一章:NotebookLM时间线创建全流程拆解(从零到专业级时间叙事) NotebookLM 的时间线(Timeline)功能并非内置独立模块,而是依托其“脚注驱动叙事”机制&am…...

AI执行层临界点:推理确定性、能力切片与可信Agent的工程落地
1. 项目概述:这不是一份新闻简报,而是一份AI产业周度“技术脉搏图”“Last Week in AI”这个标题乍看像一份科技媒体的常规栏目,但真正拆开来看——它根本不是给普通读者看的“资讯摘要”,而是一份面向AI工程师、算法研究员、技术…...

RefineDet检测结果可视化:使用refinedet_demo.py轻松实现目标标注
RefineDet检测结果可视化:使用refinedet_demo.py轻松实现目标标注 【免费下载链接】RefineDet Single-Shot Refinement Neural Network for Object Detection, CVPR, 2018 项目地址: https://gitcode.com/gh_mirrors/re/RefineDet RefineDet是一种高效的单阶…...

S200驱动器报A1489故障
安全配置未受保护A01637报警处理方法(西门子S200驱动器UMAC详细配置) https://rxxw-control.blog.csdn.net/article/details/157173145?spm=1011.2415.3001.5331https://rxxw-control.blog.csdn.net/article/details/157173145?spm=1011.2415.3001.5331 1、连接驱动器...