Python数据容器(列表list、元组tuple、字符串str、字典dict、集合set)详解
一、数据容器概念
相关介绍:
- 一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素。每一个元素,可以是任意类型的数据
- 分为五类:列表[list]、元组(tuple)、字符串(str)、集合{set}、字典{dict}
相应区别:
| 列表 | 元祖 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| <元素数量> | 多个 | 多个 | 多个 | 多个 | 多个 |
| <元素类型> | 任意 | 任意 | 仅字符 | 任意 | key(除字典外任意):value(任意) |
| <下表索引> | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| <重复元素> | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| <可否修改> | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| <数据有序> | 是 | 是 | 是 | 否 | 否 |
相应特点:
都支持for循环,集合、字典不支持(无法下标索引)
- 列表: 有一批数据,需要可修改、可重复的存储场景
- 元祖: 有一批数据,不可以修改、但可以重复的存储场景
- 字符串:一串文本字符串的存储场景
- 集合: 有一批数据,需要去重存储场景
- 字典: 有一批数据,需要用key检索value的存储场景
二、数据容器-列表[list]
解释:存放数据,但可以修改
语法:[元素1,元素2,...]
1. 列表的创建
# 案例
name_list = ['1','sadas',True,'4','5'] # 多种类型,也可以嵌套多个列表
print(name_list)
print(type(name_list)) # 输出都是列表类型: <class 'list'>
2. 列表的方法
2.1. 查询元素
语法:列表.index(元素)
# 案例
my_list = ["python","wl","1"]
index = my_list.index("python")
print(f"index的下表索引值是: {index}") # 输出:0
2.2. 索引获取元素
# 案例
name_list = ['1','sadas',True,'4','5'] # 代表0,1,2,3,4,5 或者 -5.-4,-3,-2,-1
print(name_list[0]) # 输出:1
print(name_list[-5]) # 输出:1
# 案例
name_list = [['1','sadas'],[True,'4','5']] # 嵌套多个列表
print(name_list[0][0]) # 输出:1
print(name_list[1][0]) # 输出:True
2.3. 修改索引元素
语法:列表[下标] = 值
# 案例
my_list = ["python","wl","1"]
my_list[2] = 2 # 正向下标
print(f"修改后my_list值: {my_list}") # 输出:['python', 'wl', 2]my_list[-1] = -1 # 正向下标
print(f"修改后my_list值: {my_list}") # 输出:['python', 'wl', -1]
2.4. 插入列表元素
语法:列表.insert(下标,元素) ,指定索引位置插入
# 案例
my_list = ["python","wl","1"]
my_list.insert(0,"888")
print(f"插入一个数888后:{my_list}") # 输出:['888', 'python', 'wl', '1']
2.5. 追加元素
语法:列表.append(元素), 追加到尾部
# 案例
my_list = ["python","wl","1"]
my_list.append("999") # 也可以追加新列表 my_list.append([555,222])
print(f"最后追加元素999:{my_list}") # 输出:['python', 'wl', '1', '999']
2.6. 删除元素
语法1: del 列表[下标] del 仅仅完成删除
# 案例
my_list = ["python","wl","1"] # 语法1
del my_list[0] # 注意括号,del 仅仅完成删除
print(f"删除第一个python: {my_list}") # 输出:['wl', '1']
语法2: 列表.pop(下标) 不仅删除元素,还可以返回值得到它
#案例
my_list = ["python","wl","1"] # 语法2
my_pop = my_list.pop(0) # 注意括号,pop不仅删除,还可以返回值得到它
print(f"删除第一个python: {my_list},删除的是 {my_pop}") # 输出:['wl', '1'],删除的是 python
语法3: 列表.remove(元素) 删除某一个元素,从前往后第一个删除
# 案例
my_list = ["python","python","wl","1"] # 语法3
my_list.remove('python') # 只删除第一个
print(f"删除第一个python: {my_list}") # 输出:['python', 'wl', '1']
2.7. 清空元素
语法: 列表.clear()
# 案例
my_list = ["python","wl","1"]
my_list.clear()
print(f"全部清空列表,结果是:{my_list}") # 输出:[]
2.8. 统计某个元素
语法: 列表.count()
# 案例
my_list = [1,2,2,1,3,4]
count = my_list.count(1)
print(f"列表1的数量是:{count}") # 输出:2
2.9. 统计所有元素
语法:len(列表)
# 案例
my_list = ["python","wl","1"]
print(len(my_list)) # 输出:3
3. 列表的遍历
3.1. 利用while循环获取元素
解释:1.自定循环条件,自行控制 2.通过条件控制做到无限循环
# 案例 依次取出列表元素
my_list = ["python","wl","1"]
print(type(my_list))
index = 0
while index < len(my_list): # len 表示列表中总数小于0,进行循环a = my_list[index]print(f"列表的 {index}元素:{a}")index += 1 # index = index + 1
3.2. 利用for循环获取元素
解释:1.不可以自定循环条件,只能从容器里取出数据 2.理论不可以无限循环
# 案例 依次取出列表元素
my_list = ["python",3,4,5]
for a in my_list:print(f"列表的元素:{a}")
3.3. 利用pandas制作表格,并存储
# 案例
import pandas as pdlist = [{'mtime': '2022-12-05', 'title': '国家卫健委', 'digest': '全国累计报告接种新冠病毒疫苗344429.5万剂次'}, {'mtime': '2022-12-05', 'title': '5日0—12时重庆', 'digest': '新增本土确诊病例73例和本土无症状感染者919例'}]
data = pd.DataFrame(list)
print(data)
# 输出:
# mtime title digest
# 0 2022-12-05 国家卫健委 全国累计报告接种新冠病毒疫苗344429.5万剂次
# 1 2022-12-05 5日0—12时 重庆 新增本土确诊病例73例和本土无症状感染者919例# 存入数据,utf-8-sig编码防止中文乱码
data.to_csv("sj1.csv",encoding="utf-8-sig")
3.4. 使用for循环依次打印数据
# 案例
list = [{'mtime': '2022-12-05', 'title': '国家卫健委', 'digest': '全国累计报告接种新冠病毒疫苗344429.5万剂次'}, {'mtime': '2022-12-05', 'title': '5日0—12时重庆', 'digest': '新增本土确诊病例73例和本土无症状感染者919例'}]
for item in list:mtime = item["mtime"]title = item["title"]digest = item["digest"]print(f"{mtime}, {title}, {digest}")
# 输出:
# 2022-12-05, 国家卫健委, 全国累计报告接种新冠病毒疫苗344429.5万剂次
# 2022-12-05, 5日0—12时重庆, 新增本土确诊病例73例和本土无症状感染者919例
3.5. 使用while循环依次打印数据
# 案例
list = [{'mtime': '2022-12-05', 'title': '国家卫健委', 'digest': '全国累计报告接种新冠病毒疫苗344429.5万剂次'}, {'mtime': '2022-12-05', 'title': '5日0—12时重庆', 'digest': '新增本土确诊病例73例和本土无症状感染者919例'}]
x = 0
while x < len(list):mtime = list[x]["mtime"]title = list[x]["title"]digest = list[x]["digest"]print(f"{mtime}, {title},{digest}")x += 1# 输出:
# 2022-12-05, 国家卫健委, 全国累计报告接种新冠病毒疫苗344429.5万剂次
# 2022-12-05, 5日0—12时重庆, 新增本土确诊病例73例和本土无症状感染者919例
三、数据容器-元祖(tuple)
解释:存放数据,不可修改(只读方式),但可以修改元素内容;
语法:(元素1,元素2,...)
1. 元祖的创建
# 案例
my1_tuple = ("python","wl","1")
my2_tuple = () # 空元祖方式1
my3_tuple = tuple() # 空元祖方式2
my4_tuple = ("python",) # 注意:定义一个元祖,需要加,否则就成了字符串类型
my5_tuple = (["python","wl"],"1") # 注意:元祖里的列表可以删除,修改等
print(f"my1_tuple类型是: {type(my1_tuple)},内容是:{my1_tuple}")
print(f"my2_tuple类型是: {type(my2_tuple)},内容是:{my2_tuple}")
print(f"my3_tuple类型是: {type(my3_tuple)},内容是:{my3_tuple}")
print(f"my4_tuple类型是: {type(my4_tuple)},内容是:{my4_tuple}")
print(f"my5_tuple类型是: {type(my5_tuple)},内容是:{my5_tuple}")
my5_tuple[0][1] = "修改内容"
print(f"修改的内容后:{my5_tuple}") # 输出:(['python', '修改内容'], '1')
del my5_tuple[0][0] # 删除元祖中的列表值
print(f"删除元祖中列表第一个值:{my5_tuple}") # 输出:(['wl'], '1')
2. 元祖的方法
2.1. 元祖-获取元素
# 案例
my_tuple = ((1,2,3),(7,8,9)) # 元祖支持嵌套
print(f"my_tuple取出9的数据: {my_tuple[1][2]}") # 输出9
2.2. 元祖-查询元素
语法: 元祖.index
# 案例
my_tuple = ('python','wl',1,'python')
print(my_tuple.index('python')) # 输出:0
2.3. 元祖-统计某个元素
语法: 元祖.count
# 案例
my_tuple = ('python','wl',1,'python')
print(my_tuple.count('python')) # 输出:2
2.4. 统计-统计所有元素
语法: 元祖.count
# 案例
my_tuple = ('python','wl',1,'python')
print(len(my_tuple)) # 输出:4
3. 元祖的遍历
3.1. 利用while循环获取元素
解释:1.自定循环条件,自行控制 2.通过条件控制做到无限循环
# 案例 依次取出元祖元素
my_tuple = ("python","wl","1")
print(type(my_tuple))
index = 0
while index < len(my_tuple): # len 表示列表中总数小于0,进行循环a = my_tuple[index]print(f"元祖的 {index}元素:{a}")index += 1 # index = index + 1
3.2. 利用for循环获取元素
解释:1.不可以自定循环条件,只能从容器里取出数据 2.理论不可以无限循环
# 案例 依次取出元祖元素
my_tuple = ("python",3,4,5)
print(type(my_tuple))
for a in my_tuple:print(f"元祖的元素:{a}")
四、数据容器-字符串(str)
特点:不支持修改
1. 字符串的方法
1.1. 字符串-索引获取元素
注意:空格也算一个字符
# 案例
my_str = "i is wl"
v1 = my_str[0]
v2 = my_str[-1]
print(f"首个值v1:{v1},最后值v2:{v2}") # 输出:v1:i, v2:c
1.2. 字符串-查找元素
语法:字符串.index(值)
# 案例
my_str = "i is wl"
v = my_str.index("is")
print(f"and的起始下标v:{v}") # 输出:2
1.3. 字符串-替换元素
语法:字符串.replace(原值,现值)
# 案例
my_str = "i is wl"
v = my_str.replace("i","t")
print(f"把所有的i替换成t:{v}") # 输出:t ts wl
1.4. 字符串-分割元素
语法:字符串.split(分割值)
# 案例
my_str = "i is wl"
v = my_str.split( ) # 空格切分
print(f"用空格风格my_str:{v}") # 输出:['i', 'is', 'wl']
1.5. 字符串-规整元素
语法:字符串.strip(去除值) ,空代表去除前后空格
# 案例
my_str = "12i is wl21"
v = my_str.strip("12") # 去除12,实际去除“1”和“2”
print(f"去掉12后my_str:{v}") # 输出:i is wl
1.6. 字符串-统计某个元素
语法:字符串count(统计值)
#案例
my_str = "i is wl"
v = my_str.count("i")
print(f"i出现的次数:{v}") # 输出:2
1.7. 字符串-统计所有元素
语法:字符串len()
#案例
my_str = "i is wl"
v = len(my_str)
print(f"my_str总数长度是:{v}") # 输出:8
五、数据容器-集合{set}
特点:相比其他,不支持重复集合,自带去重,并且输出是无序的
语法 : 变量 = {元素1,元素2....}
1. 集合的创建
#案例
my_set = {"python","wl",4,"wl"}
print(my_set) # 输出:{'python', 4, 'wl'},故是无序的,不支持下标
2. 集合的方法
2.1. 集合-增加元素
# 案例
my_set = {"python","wl",4,"wl"}
my_set.add("Python") # 如果增加相同数据等于没有写
print(f"增加一个数my_set结果是:{my_set}") # 输出:{'wl', 'Python', 'python', 4}
2.2. 集合-移除元素
# 案例
my_set = {"python","wl",4,"wl"}
my_set.remove("python") # 删除所有,再去重
print(f"移除一个数my_set结果是:{my_set}") # 输出:{'wl', 4}
2.3. 集合-随机取出元素
# 案例
my_set = {"python","wl",4,"wl"}
element = my_set.pop() # 随机取,无法指定
print(f"{element}") #
print(f"随机取一个数my_set结果是:{my_set}") #
2.4. 集合-清空元素
# 案例
my_set = {"python","wl",4,"wl"}
my_set.clear()
print(f"清空my_set结果是:{my_set}") # 输出:set()
2.5. 集合-取(消除)两个集合的差
# 案例
set1 = {1,2,3}
set2 = {2,3,4}
f_set = set1.difference(set2)
print(f"除set1中有而set2没有的结果是:{f_set}") # 输出:{1}
set1.difference_update(set2) # 消除差集,集合2不变化
print(set1) # 输出:{1}
print(set2) # 输出:{2, 3, 4}
2.6. 集合-合并元素
# 案例
set1 = {1,2,3}
set2 = {2,3,4}
set3 = set1.union(set2)
print(f"集合合并后set3:{set3}") # 输出:(去重):{1, 2, 3, 4}
2.7. 集合-统计元素数量(去重)
# 案例
set1 = {1,2,3,2,3,4}
num = len(set1)
print(f"集合合并后set3:{num}") # 输出(去重):4
3. 集合的遍历
说明:因为不支持下标索引,所以while循环不支持,支持for循环
# 案例
set1 = {1,2,3,2,3,4}
for a in set1:print(f"集合元素有:{a}")
六、数据容器-字典{dict}
解释:字和其相关联的含义
注意:字典可以任意类型,不允许重复,会覆盖
语法: 变量 = {key:value,key:value.....}
1. 字典的创建
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
print(f"my_dict类型是:{type(my_dict)},内容是:{my_dict}") # 输出:<class 'dict'>
2. 字典的方法
2.1. 字典-key取值
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
s = my_dict['张三']
print(f"张三对应的值是:{s}") # 输出:99
2.2. 字典-嵌套取值
# 案例
my_dict = {"张三":{"语文":99,"数学":70},"李四":{"语文":88,"数学":80},"王五":{"语文":80,"数学":68}
}
s = my_dict["王五"]["数学"]
print(f"王五对应的数学值是:{s}") # 输出:68
2.3. 字典-新增元素
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
my_dict['赵六'] = 77
print(f"新增赵六成绩后:{my_dict}")
2.4. 字典-更新元素
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
my_dict['张三'] = 77
print(f"新增赵六成绩后:{my_dict}")
2.5. 字典-删除元素
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
my_dict.pop("张三")
print(f"删除张三后:{my_dict}")
2.6. 字典-清空元素
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
my_dict.clear()
print(f"清空后:{my_dict}")
2.7. 字典-取key、value值
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
s = my_dict.keys()
print(f"{s}")
for s in my_dict: # for循环输出value值,不支持while循环print(f"{my_dict[s]}")
2.8. 字典-统计所有元素
# 案例
my_dict = {"张三":99,"李四":98,"王五":90}
num = len(my_dict)
print(f"数量是:{num}") # 输出:3
3. 字典的综合案例
要求:对名次为3的语文增加10分,并晋升一名次
# 案例
my_dict = {"张三":{"名次":8,"语文":99,"数学":70},"李四":{"名次":10,"语文":88,"数学":80},"王五":{"名次":3,"语文":80,"数学":68}
}
print(f"升级之前是:{my_dict}")for name in my_dict:if my_dict[name]["名次"] == 3: # 当名次为3时,my_dict[name]["名次"] = 2 # 晋升一名次,改为2,my_dict[name]["语文"] += 10 # 语文成绩+10分
print(f"升级之后是:{my_dict}")
七、数据容器的切片
解释:从一个序列中,取出子序列
语法:序列[起始下标:结束下标:步长] 步长1表示,一个个取;2表示间隔一个取
1. 列表list
# 案例
my_list = [0,1,2,3,4,5,6,7,8,9]
result_1 = my_list[1:3] # 步长默认是1,可以不写
print(f"从第二个到四个取,result_1结果是:{result_1}")
2. 元祖tuple
# 案例
my_tuple = (0,1,2,3,4,5,6,7,8,9)
result_2 = my_tuple[::2] # 空代表从头到尾,2代表步长
print(f"从头到尾,间隔1,result_2结果是:{result_2}")
3. 字符串
# 案例
my_str = "0123456789"
result_3 = my_str[::-2]
print(f"从尾到头,间隔1,result_3结果是:{result_3}")
# 案例 正常取出数 "我是你哥"
my_str = "哥大我叫请,啊哥你是我,好你"
s1 = my_str[::-1][3:7] # 先倒转,再取值。注意最后的下标索引
print(f"方式s1结果是:{s1}")
s2 = my_str[7:11][::-1] # 先取值,再倒转。注意最后的下标索引
print(f"方式s2结果是:{s2}")
s3 = my_str.split(",")[1].replace("啊","")[::-1] # 先用,分割取值第二个再把“啊”替换掉 最后倒序
print(f"方式s3结果是:{s3}")
八、数据容器的通用操作(排序、转换)
# 案例
my_list = [1,2,3,4,5]
my_tuple = (1,2,3,4,5)
my_str = "abcdefgh"
my_set = {1,2,3,4,5}
my_dict = {"key1":1,"key2":2,"key3":3}
1. 容器取值(max)
print(f"列表 最大元素是:{max(my_list)}")
print(f"元祖 最大元素是:{max(my_tuple)}")
print(f"字符串 最大元素是:{max(my_str)}")
print(f"集合 最大元素是:{max(my_set)}")
print(f"字典 最大元素是:{max(my_dict)}")
2. 容器转列表
print(f"列表 转列表是:{list(my_list)}")
print(f"元祖 转列表是:{list(my_tuple)}")
print(f"字符串 转列表是:{list(my_str)}")
print(f"集合 转列表是:{list(my_set)}")
print(f"字典 转列表是:{list(my_dict)}")
3. 容器转元祖
print(f"列表 转元祖是:{tuple(my_list)}")
print(f"元祖 转元祖是:{tuple(my_tuple)}")
print(f"字符串 转元祖是:{tuple(my_str)}")
print(f"集合 转元祖是:{tuple(my_set)}")
print(f"字典 转元祖是:{tuple(my_dict)}")
4. 容器转字符串、集合
解释:字典dict不支持,缺少键值对;字符串、集合都是无序)
5. 容器的排序
5.1. 排序
语法:sorted(容器,reverse=False)
print(f"列表 排序是:{sorted(my_list)}")
print(f"元祖 排序是:{sorted(my_tuple)}")
print(f"字符串 排序是:{sorted(my_str)}")
print(f"集合 排序是:{sorted(my_set)}")
print(f"字典 排序是:{sorted(my_dict)}")
5.2. 降序
print(f"列表 排序是:{sorted(my_list,reverse=True)}")
print(f"元祖 排序是:{sorted(my_tuple,reverse=True)}")
print(f"字符串 排序是:{sorted(my_str,reverse=True)}")
print(f"集合 排序是:{sorted(my_set,reverse=True)}")
print(f"字典 排序是:{sorted(my_dict,reverse=True)}")
5.3. 根据数字下标定义排序方法 sort
my_list = [["a",67],["a",7],["a",52]]# 方式1
def sort_key(element):return element[1]
my_list.sort(key=sort_key,reverse=False) # True/flase:表示升序降序# 方式2 利用匿名函数lambda
my_list.sort(key=lambda element:element[1],reverse=False)
print(my_list)
相关文章:
详解)
Python数据容器(列表list、元组tuple、字符串str、字典dict、集合set)详解
一、数据容器概念 相关介绍: 一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素。每一个元素,可以是任意类型的数据分为五类:列表[list]、元组(tuple)、字符串(str)、集合{set}、字典{dict} 相应区别:…...

2023高教社杯数学建模思路 - 复盘:人力资源安排的最优化模型
文章目录 0 赛题思路1 描述2 问题概括3 建模过程3.1 边界说明3.2 符号约定3.3 分析3.4 模型建立3.5 模型求解 4 模型评价与推广5 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 描述 …...
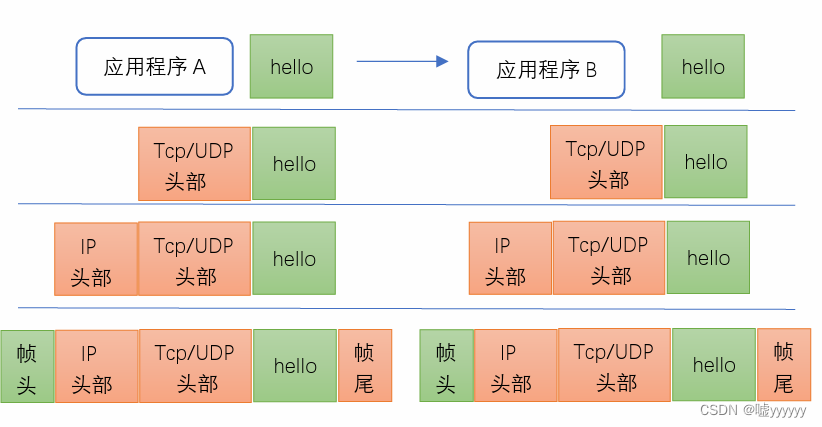
Linux 计算机网络基础概论
一、网络基本概念 1、网络 网络是由若干节点和连接这些结点的链路组成,网络中的结点可以是计算机、交换机、路由器等设备。通俗地说就是把不同的主机连接起来就构成了一个网络,构成网路的目的是为了信息交互、资源共享。 网络设备有:交换机…...

深入理解 C++ 中的 std::cref、std::ref 和 std::reference_wrapper
深入理解 C 中的 std::cref、std::ref 和 std::reference_wrapper 在 C 编程中,有时候我们需要在不进行拷贝的情况下传递引用,或者在需要引用的地方使用常量对象。为了解决这些问题,C 标准库提供了三个有用的工具:std::cref、std:…...
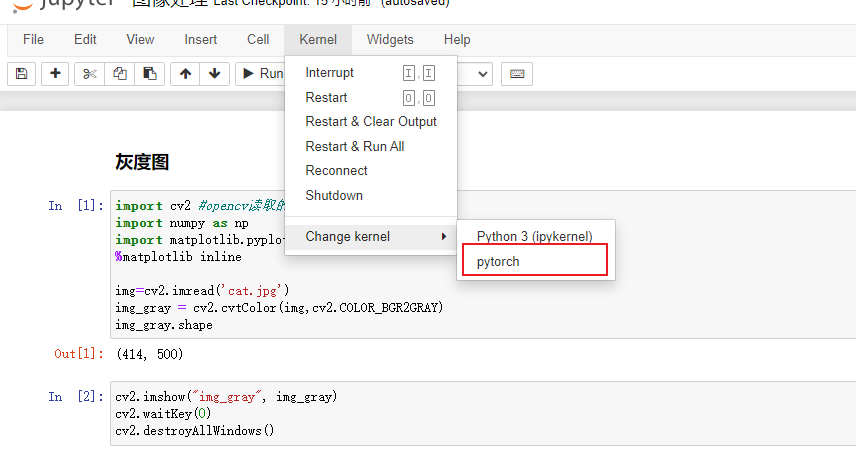
在其他python环境中使用jupyter notebook
1、切换到目标python环境 activate 目标python环境 2、安装notebook内核包 pip install ipykernel 3、加环境加入到notebook中 python -m ipykernel install 目标python环境 4、切换到base环境 activate base 5、打开目标项目的对应盘 如果,项目在c盘&…...
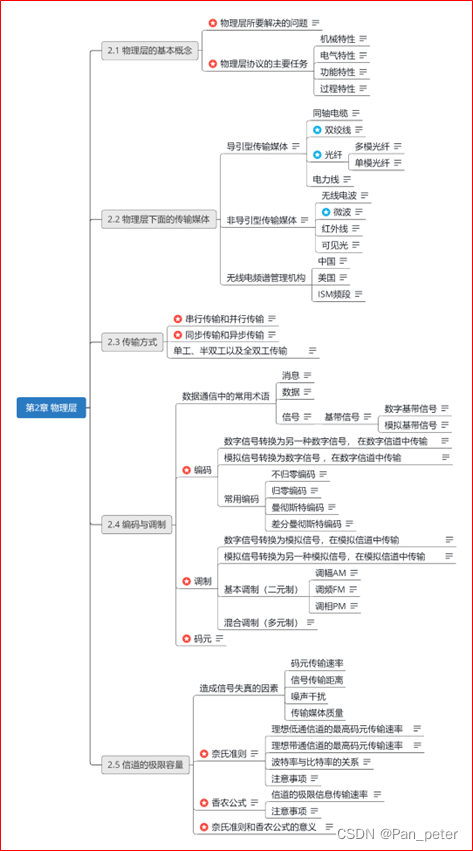
计算机网络-笔记-第二章-计算机网络概述
目录 二、第二章——物理层 1、物理层的基本概念 2、物理层下面的传输媒体 (1)光纤、同轴电缆、双绞线、电力线【导引型】 (2)无线电波、微波、红外线、可见光【非导引型】 (3)无线电【频谱的使用】 …...

Hive字符串数组json类型取某字段再列转行
一、原始数据 acctcontent1232313[{"name":"张三","code":"上海浦东新区89492jfkdaj\r\n福建的卡"...},{"name":"狂徒","code":"select * from table where aa1\r\n and a12"...},{...}]...…...

ElementUI Table 翻页缓存数据
Element UI Table 翻页保存之前的数据,网上找了一些,大部分都是用**:row-key** 和 reserve-selection,但是我觉得有bug,我明明翻页了…但是全选的的个框还是勾着的(可能是使用方法不对,要是有好使的…请cute我一下…感谢) 所以自己写了一个… 思路: 手动勾选的时候,将数据保存…...
使用 AutoGPTQ 和 transformers 让大语言模型更轻量化
大语言模型在理解和生成人类水平的文字方面所展现出的非凡能力,正在许多领域带来应用上的革新。然而,在消费级硬件上训练和部署大语言模型的需求也变得越来越难以满足。 🤗 Hugging Face 的核心使命是 让优秀的机器学习普惠化 ,而…...
6.5 BswM模块概念与配置方法介绍)
AUTOSAR规范与ECU软件开发(实践篇)6.5 BswM模块概念与配置方法介绍
目录 1、BswM模块概念与配置方法介绍 (1) BswMModeRequestPort配置 (2) ModeCondition与LogicalExpression配置...

1.1 VMware Workstation与Kali的安装和配置1
资源见专栏第一篇文章https://blog.csdn.net/algorithmyyds/article/details/132457258 安装VMware 不多加赘述,直接按顺序安装即可。 有以下需注意的地方: 1.建议选择增强型服务; 2.不要加入体验改进计划。是否开启提示更新看你的想法&…...

DDR与PCIe:高性能SoC的双引擎
SoC芯片无处不在,小到家电控制的MCU,大到手机芯片,我们都会接触到。如今大部分芯片设计公司都在开发SoC芯片,一颗SoC芯片可以集成越来越多的功能,俨然它已成为IC设计业界的焦点。 高性能、高速、高带宽的互联和存储的…...
C#_特性反射详解
特性是什么? 为程序元素额外添加声明信息的一种方式。 字面理解:相当于把额外信息写在干胶标签上,然后将其贴在程序集上。 反射是什么? 反射是一种能力,运行时获取程序集中的元数据。 字面理解:程序运行…...

【跟小嘉学 Rust 编程】十三、函数式语言特性:迭代器和闭包
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
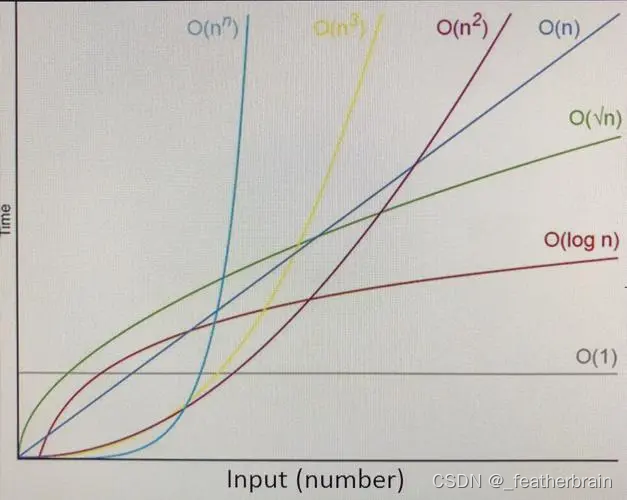
时间复杂度和空间复杂度
全文目录 算法的复杂度时间复杂度大O渐进表示法空间复杂度常见算法复杂度对比 算法的复杂度 算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度…...

mac docker 卡住解决
文章目录 1、问题简述2、重新安装docker3、docker守护进程4、问题解决方案 1、问题简述 在docker desktop上更改了daemon.json的文件内容,应该是参数写的有问题,修改完配置再启动docker desktop就失败了,然后想着卸载docker desktop…...
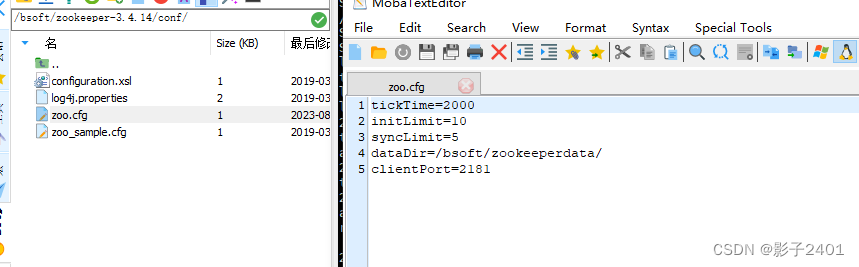
linux/centos zookeeper 使用记录
配置cfg 下载zookeeper-3.4.14.tar.gz负责到centos服务器解压 /xxx/zookeeper-3.4.14/conf/下创建zoo.cfg文件并配置以下属性,/bsoft/zookeeperdata/目录先预先创建 tickTime2000 initLimit10 syncLimit5 dataDir/bsoft/zookeeperdata/ clientPort2181zk启动/重启/关…...
用wireshark流量分析的四个案例
目录 第一题 1 2 3 4 第二题 1 2 3. 第三题 1 2 第四题 1 2 3 第一题 题目: 1.黑客攻击的第一个受害主机的网卡IP地址 2.黑客对URL的哪一个参数实施了SQL注入 3.第一个受害主机网站数据库的表前缀(加上下划线例如abc) 4.…...

Oracle 时区详解
1 简介 由于地球经纬度及地球自转引起的经度方向,不同的经度的地方,所感受到的昼夜是不同 的。有关国际会议决定将地球表面按经线从东到西,每隔经度15度划分一个时区,并且规定 相邻区域的时间相差1小时。 这就是时区的由来。 而实际使用中,…...

仿mudou高性能高并发服务器
"这个结局是我的期待,我会一直为你祝福。" 项目实现目标: 仿muduo库One Thread One Loop式主从Reacto模型实现高并发服务器。通过实现高并发服务器组件,简洁快速完成搭建一个高性能服务器。并且,通过组件内提供的不同应⽤层协议⽀…...

植树的人数
include<iostream> using namespace std; int main() {int a ,x,y;cin>>a>>x>>y;for(int i 1;i<(a-(xy))/3;i){int j (a-i*x)/3;if(i*xj*y100){cout<<i<<" "<<j<<endl;}}return 0; }买糕点#include<iostream&…...

JMeter精准控制1 QPS的底层原理与三种实战方案
1. 这不是“设个线程数”就能搞定的事很多人第一次用Jmeter做压测,看到“我要每秒发1个请求”,第一反应是:开1个线程,Ramp-up时间设为1秒,循环次数设无限——结果一跑起来,发现TPS忽高忽低,有时…...

如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术
如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

在内容生成流水线中集成多模型 API 以提升创作多样性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在内容生成流水线中集成多模型 API 以提升创作多样性 对于新媒体运营、营销或内容创作团队而言,保持内容的新鲜感与多样…...

8051仿真器OMF转SIG格式的实战指南
1. Signum 8051 仿真器符号转换器使用指南在嵌入式开发领域,Signum Systems 的 8051 仿真器是一个常用的调试工具。很多开发者在使用 Vision 开发环境时,经常遇到需要将链接器生成的绝对目标模块(OMF)转换为仿真器专用格式的需求。本文将详细介绍这个转换…...

河北邯郸职称评审的方式有哪几种?
1、以考代评以考代评就是指有些专业技术岗位可以通过参加考试而不是递交繁琐的材料来获得专业技术职务资格。只要顺利通过国家指定的科目考试,你就可以获得专业技术资格,省去了各种审核流程的烦恼。2、只评不考只评不考是目前zui常见、适用范围zui广的一…...

taotoken如何为github actions工作流提供稳定的大模型服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken如何为github actions工作流提供稳定的大模型服务 应用场景类,探讨在github actions自动化流水线中集成taotok…...
 综合模拟运输测试标准(CSDN 完整版)前言)
ISTA 3B-2013 全解析|零担货物 (LTL) 综合模拟运输测试标准(CSDN 完整版)前言
前言 ISTA 3B-2013 是 ISTA 3 系列高级综合模拟测试,专门针对零担货物运输(LTL) 的包装件。 零担运输的特点是多货混装、多次中转、人工 / 叉车交叉搬运、环境复杂,因此 3B 是工业、设备、家电、汽配、大型包装最贴近真实物流的测…...

数据结构 —— 链表
在数据结构体系中,顺序表与链表是两大最基础的线性存储结构。顺序表依靠连续内存实现随机访问,但插入、删除中间元素效率低下;而链表用离散内存 指针连接的方式,完美解决了顺序表的痛点,是 Linux 内核、操作系统、网络…...

2026亲测:专业降AI率工具选这款就对了3秒改写无痕迹
2026 年降 AIGC 工具已从“基础语义替换”进化为多维度智能优化系统,核心评估指标涵盖 AI 痕迹清除效率、专业表达准确性、格式结构完整性、长段落逻辑稳定性、内容重合度降低效果及高校检测平台兼容性。本次测评深入分析 5 款主流工具,测试范围包括中英…...