使用 AutoGPTQ 和 transformers 让大语言模型更轻量化
大语言模型在理解和生成人类水平的文字方面所展现出的非凡能力,正在许多领域带来应用上的革新。然而,在消费级硬件上训练和部署大语言模型的需求也变得越来越难以满足。
🤗 Hugging Face 的核心使命是 让优秀的机器学习普惠化 ,而这正包括了尽可能地让所有人都能够使用上大模型。本着 与 bitsandbytes 合作 一样的精神,我们将 AutoGPTQ 代码库集成到了 Transformers 中,让用户使用 GPTQ 算法 (Frantar et al. 2023) 在 8 位、4 位、3 位,甚至是 2 位精度下量化和运行模型成为可能。当使用 int4 量化时,精度的下降可以忽略不计,同时在小批量推理上保持着与 fp16 基线相当的速度。需要注意的是,GPTQ 方法与 bitsandbytes 提出的训练后量化方法有所不同: 它需要在量化阶段提供一个校准数据集。
本次集成支持英伟达 GPU 和基于 RoCm 的 AMD GPU。
目录
相关资源
GPTQ 论文总结
AutoGPTQ 代码库——一站式地将 GPTQ 方法应用于大语言模型
🤗 Transformers 对 GPTQ 模型的本地化支持
使用 Optimum 代码库 量化模型
通过 Text-Generation-Inference 使用 GPTQ 模型
使用 PEFT 微调量化后的模型
改进空间
已支持的模型
结论和结语
致谢
相关资源
本文及相关版本发布提供了一些资源来帮助用户开启 GPTQ 量化的旅程:
原始论文
运行于 Google Colab 笔记本上的基础用例 —— 该笔记本上的用例展示了如何使用 GPTQ 方法量化你的 transformers 模型、如何进行量化模型的推理,以及如何使用量化后的模型进行微调。
Transformers 中集成 GPTQ 的 说明文档
Optimum 中集成 GPTQ 的 说明文档
TheBloke 模型仓库 中的 GPTQ 模型。
GPTQ 论文总结
通常,量化方法可以分为以下两类:
训练后量化 (Post Training Quantization, PTQ): 适度地使用一些资源来量化预训练好的模型,如一个校准数据集和几小时的算力。
量化感知训练 (Quantization Aware Training, QAT): 在训练或进一步微调之前执行量化。
GPTQ 属于训练后量化,这对于大模型而言格外有趣且有意义,因为对其进行全参数训练以及甚至仅仅是微调都十分昂贵。
具体而言,GPTQ 采用 int4/fp16 (W4A16) 的混合量化方案,其中模型权重被量化为 int4 数值类型,而激活值则保留在 float16。在推理阶段,模型权重被动态地反量化回 float16 并在该数值类型下进行实际的运算。
该方案有以下两方面的优点:
int4 量化能够节省接近4倍的内存,这是因为反量化操作发生在算子的计算单元附近,而不是在 GPU 的全局内存中。
由于用于权重的位宽较低,因此可以节省数据通信的时间,从而潜在地提升了推理速度。
GPTQ 论文解决了分层压缩的问题:
给定一个拥有权重矩阵 和输入 的网络层 ,我们期望获得一个量化版本的权重矩阵 以最小化均方误差 (MSE):
一旦每层都实现了上述目标,就可以通过组合各网络层量化结果的方式来获得一个完整的量化模型。
为解决这一分层压缩问题,论文作者采用了最优脑量化 (Optimal Brain Quantization, OBQ) 框架 (Frantar et al 2022) 。OBQ 方法的出发点在于其观察到: 以上等式可以改写成权重矩阵 每一行的平方误差之和
这意味着我们可以独立地对每一行执行量化。即所谓的 per-channel quantization。对每一行 ,OBQ 在每一时刻只量化一个权重,同时更新所有未被量化的权重,以补偿量化单个权重所带来的误差。所选权重的更新采用一个闭环公式,并利用了海森矩阵 (Hessian Matrices)。
GPTQ 论文通过引入一系列优化措施来改进上述量化框架,在降低量化算法复杂度的同时保留了模型的精度。
相较于 OBQ,GPTQ 的量化步骤本身也更快: OBQ 需要花费 2 个 GPU 时来完成 BERT 模型 (336M) 的量化,而使用 GPTQ,量化一个 Bloom 模型 (176B) 则只需不到 4 个 GPU 时。
为了解算法的更多细节以及在困惑度 (perplexity, PPL) 指标和推理速度上的不同测评数据,可查阅原始 论文 。
AutoGPTQ 代码库——一站式地将 GPTQ 方法应用于大语言模型
AutoGPTQ 代码库让用户能够使用 GPTQ 方法量化 🤗 Transformers 中支持的大量模型,而社区中的其他平行工作如 GPTQ-for-LLaMa 、Exllama 和 llama.cpp 则主要针对 Llama 模型架构实现量化策略。相较之下,AutoGPTQ 因其对丰富的 transformers 架构的平滑覆盖而广受欢迎。
正因为 AutoGPTQ 代码库覆盖了大量的 transformers 模型,我们决定提供一个 🤗 Transformers 的 API 集成,让每个人都能够更容易地使用大语言模型量化技术。截止目前,我们已经集成了包括 CUDA 算子在内的最常用的优化选项。对于更多高级选项如使用 Triton 算子和 (或) 兼容注意力的算子融合,请查看 AutoGPTQ 代码库。
🤗 Transformers 对 GPTQ 模型的本地化支持
在 安装 AutoGPTQ 代码库 和 optimum (pip install optimum) 之后,在 Transformers 中运行 GPTQ 模型将非常简单:
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GPTQ", torch_dtype=torch.float16, device_map="auto")请查阅 Transformers 的 说明文档 以了解有关所有特性的更多信息。
我们的 AutoGPTQ 集成有以下诸多优点:
量化模型可被序列化并在 Hugging Face Hub 上分享。
GPTQ 方法大大降低运行大语言模型所需的内存,同时保持着与 FP16 相当的推理速度。
AutoGPTQ 在更广泛的 transformers 架构上支持 Exllama 算子。
该集成带有基于 RoCm 的 AMD GPU 的本地化支持。
能够 使用 PEFT 微调量化后的模型 。
你可以在 Hugging Face Hub 上查看你所喜爱的模型是否已经拥有 GPTQ 量化版本。TheBloke,Hugging Face 的顶级贡献者之一,已经使用 AutoGPTQ 量化了大量的模型并分享在 Hugging Face Hub 上。在我们的共同努力下,这些模型仓库都将可以与我们的集成一起开箱即用。
以下是一个使用 batch size = 1 的测评结果示例。该测评结果通过在英伟达 A100-SXM4-80GB GPU 上运行得到。我们使用长度为 512 个词元的提示文本,并精确地生成 512 个新词元。表格的第一行展示的是未量化的 fp16 基线,另外两行则展示使用 AutoGPTQ 不同算子的内存开销和推理性能。
| gptq | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tokens/s) | Peak memory (MB) |
|---|---|---|---|---|---|---|---|---|
| False | None | None | None | None | 26.0 | 36.958 | 27.058 | 29152.98 |
| True | False | 4 | 128 | exllama | 36.2 | 33.711 | 29.663 | 10484.34 |
| True | False | 4 | 128 | autogptq-cuda-old | 36.2 | 46.44 | 21.53 | 10344.62 |
一个更全面的、可复现的测评结果可以在这里 取得。
使用 Optimum 代码库 量化模型
为了将 AutoGPTQ 无缝集成到 Transformers 中,我们使用了 AutoGPTQ API 的一个极简版本,其可在 Optimum 中获得 —— 这是 Hugging Face 针对训练和推理优化而开发的一个工具包。通过这种方式,我们轻松地实现了与 Transformers 的集成,同时,如果人们想要量化他们自己的模型,他们也完全可以单独使用 Optimum 的 API!如果想要量化你自己的大语言模型,请查阅 Optimum 的 说明文档 。
只需数行代码,即可使用 GPTQ 方法量化 🤗 Transformers 的模型:
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfigmodel_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)量化一个模型可能花费较长的时间。对于一个 175B 参数量的模型,如果使用一个大型校准数据集 (如 “c4”),至少需要 4 个 GPU 时。正如上面提到的那样,许多 GPTQ 模型已经可以在 Hugging Face Hub 上被取得,这让你在大多数情况下无需自行量化模型。当然,你仍可以使用你所专注的特定领域的数据集来量化模型。
通过 Text-Generation-Inference 使用 GPTQ 模型
在将 GPTQ 集成到 Transformers 中的同时,Text-Generation-Inference 代码库 (TGI) 已经添加了 GPTQ 的支持,旨在为生产中的大语言模型提供服务。现在,GPTQ 已经可以与动态批处理、paged attention、flash attention 等特性一起被应用于 广泛的 transformers 模型架构 。
例如,这一集成允许在单个 A100-80GB GPU上服务 70B 模型!而这在使用 fp16 的模型权重时是不可能的,因为它超出了最大可用的 GPU 内存。
你可以在 TGI 的 说明文档 中找到更多有关 GPTQ 的用法。
需要注意的时,TGI 中集成的算子不能很好地扩展到较大的批处理大小。因此,这一方式虽然节省了内存,但在较大的批处理大小上发生速度的下降是符合预期的。
使用 PEFT 微调量化后的模型
在常规的方法下,你无法进一步微调量化后的模型。然而,通过使用 PEFT 代码库,你可以在量化后的模型之上训练适应性网络!为实现这一目标,我们冻结了量化过的基座模型的所有网络层,并额外添加可训练的适应性网络。这里是一些关于如何使用 PEFT 训练 GPTQ 模型的例子: Colab 笔记本 和 微调脚本 。
改进空间
虽然我们的 AutoGPTQ 集成在极小的预测质量损失代价下,带来了引人瞩目的优势。但在量化技术应用和算子实现方面仍有提升的空间。
首先,尽管 AutoGPTQ (在我们的认知范围内) 已经集成了 exllama 中所实现的最佳性能的 W4A16 算子 (权重为 int4 数值类型,激活值为 fp16 数值类型),其仍有很大的改进空间。来自 Kim 等人 的实现和 MIT Han Lab 的方法似乎十分可靠。此外,根据我们的内部测评,似乎暂未有开源的高性能的 Triton 版本的 W4A16 算子实现,这也是一个值得探索的方向。
在量化层面,我们需要再次强调 GPTQ 方法只对模型权重进行量化。而针对大语言模型的量化,存在其他的方法,提供了以较小的预测质量损失为代价,同时量化权重和激活值的方案。如 LLM-QAT 采用 int4/int8 的混合精度方案,同时还对 KV Cache 施行量化。这一技术的强大优点是能实际使用整数运算算法来进行计算,一个例子是 英伟达的张量核心支持 int8 计算 。然而,据我们所知,目前暂无开源的 W4A8 量化算子,但这可能是一个 值得探索的方向 。
在算子层面,为更大的批处理大小设计高性能的 W4A16 算子仍然是一大挑战。
已支持的模型
在初始实现中,暂时只支持纯编码器或纯解码器架构的大语言模型。这听起来似乎有较大的局限性,但其实已经涵盖了当前绝大多数最先进的大语言模型,如 Llama、OPT、GPT-Neo、GPT-NeoX 等。
大型的视觉、语音和多模态模型在现阶段暂不被支持。
结论和结语
本文中,我们介绍了 Transformers 对 AutoGPTQ 代码库 的集成,使得社区中的任何人都可以更方便地利用 GPTQ 方法量化大语言模型,助力令人激动的大语言模型工具和应用的构建。
这一集成支持英伟达 GPU 和基于 RoCm 的 AMD GPU,这是向支持更广泛 GPU 架构的量化模型的普惠化迈出的一大步。
与 AutoGPTQ 团队的合作非常富有成效,我们非常感谢他们的支持和他们在该代码库上的工作。
我们希望本次集成将使每个人都更容易地在他们的应用程序中使用大语言模型,我们迫不及待地想要看到大家即将使用它所创造出的一切!
再次提醒不要错过文章开头分享的有用资源,以便更好地理解本次集成的特性以及如何快速开始使用 GPTQ 量化。
原始论文
运行于 Google Colab 笔记本上的基础用例 —— 该笔记本上的用例展示了如何使用 GPTQ 方法量化你的 transformers 模型、如何进行量化模型的推理,以及如何使用量化后的模型进行微调。
Transformers 中集成 GPTQ 的 说明文档
Optimum 中集成 GPTQ 的 说明文档
TheBloke 模型仓库 中的 GPTQ 模型。
致谢
感谢 潘其威 对杰出的 AutoGPTQ 代码库的支持和所作的工作,以及他对本次集成的帮助。感谢 TheBloke 使用 AutoGPTQ 量化大量的模型并分享在 Hugging Face Hub 上,以及他在本次集成中所提供的帮助。感谢 qwopqwop200 对 AutoGPTQ 代码库的持续贡献,目前,他正致力于将该代码库的使用场景拓展至 CPU ,这一特性将在 AutoGPTQ 的下一版本中发布。
最后,我们还要感谢 Pedro Cuenca 对本文的撰写所提供的帮助。
🤗 宝子们可以戳 阅读原文 查看文中所有的外部链接哟!
英文原文: https://hf.co/blog/gptq-integration
原文作者: Marc Sun, Félix Marty, 潘其威, Junjae Lee, Younes Belkada, Tom Jobbins
译者: 潘其威
审校/排版: zhongdongy (阿东)
相关文章:
使用 AutoGPTQ 和 transformers 让大语言模型更轻量化
大语言模型在理解和生成人类水平的文字方面所展现出的非凡能力,正在许多领域带来应用上的革新。然而,在消费级硬件上训练和部署大语言模型的需求也变得越来越难以满足。 🤗 Hugging Face 的核心使命是 让优秀的机器学习普惠化 ,而…...
6.5 BswM模块概念与配置方法介绍)
AUTOSAR规范与ECU软件开发(实践篇)6.5 BswM模块概念与配置方法介绍
目录 1、BswM模块概念与配置方法介绍 (1) BswMModeRequestPort配置 (2) ModeCondition与LogicalExpression配置...

1.1 VMware Workstation与Kali的安装和配置1
资源见专栏第一篇文章https://blog.csdn.net/algorithmyyds/article/details/132457258 安装VMware 不多加赘述,直接按顺序安装即可。 有以下需注意的地方: 1.建议选择增强型服务; 2.不要加入体验改进计划。是否开启提示更新看你的想法&…...

DDR与PCIe:高性能SoC的双引擎
SoC芯片无处不在,小到家电控制的MCU,大到手机芯片,我们都会接触到。如今大部分芯片设计公司都在开发SoC芯片,一颗SoC芯片可以集成越来越多的功能,俨然它已成为IC设计业界的焦点。 高性能、高速、高带宽的互联和存储的…...
C#_特性反射详解
特性是什么? 为程序元素额外添加声明信息的一种方式。 字面理解:相当于把额外信息写在干胶标签上,然后将其贴在程序集上。 反射是什么? 反射是一种能力,运行时获取程序集中的元数据。 字面理解:程序运行…...

【跟小嘉学 Rust 编程】十三、函数式语言特性:迭代器和闭包
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
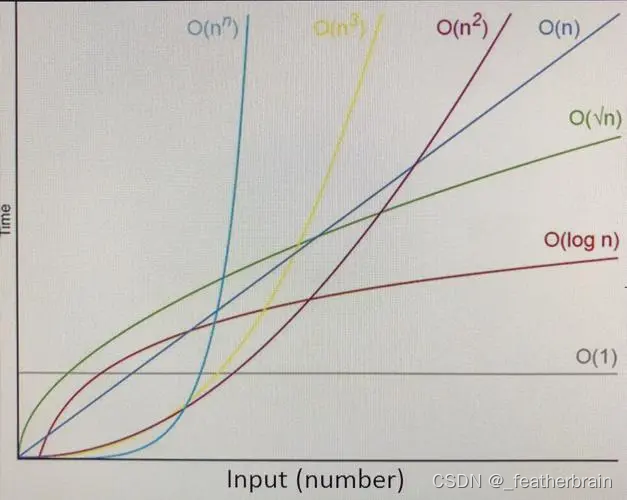
时间复杂度和空间复杂度
全文目录 算法的复杂度时间复杂度大O渐进表示法空间复杂度常见算法复杂度对比 算法的复杂度 算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般是从时间和空间两个维度来衡量的,即时间复杂度…...

mac docker 卡住解决
文章目录 1、问题简述2、重新安装docker3、docker守护进程4、问题解决方案 1、问题简述 在docker desktop上更改了daemon.json的文件内容,应该是参数写的有问题,修改完配置再启动docker desktop就失败了,然后想着卸载docker desktop…...
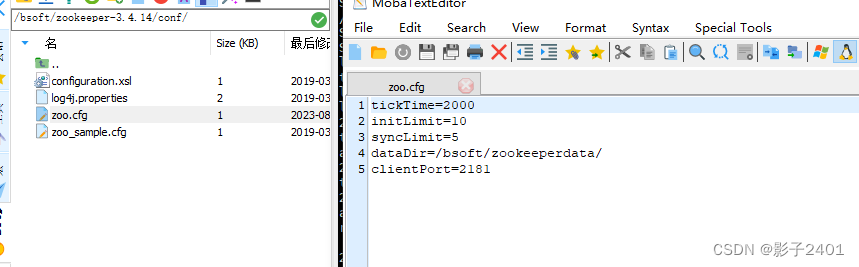
linux/centos zookeeper 使用记录
配置cfg 下载zookeeper-3.4.14.tar.gz负责到centos服务器解压 /xxx/zookeeper-3.4.14/conf/下创建zoo.cfg文件并配置以下属性,/bsoft/zookeeperdata/目录先预先创建 tickTime2000 initLimit10 syncLimit5 dataDir/bsoft/zookeeperdata/ clientPort2181zk启动/重启/关…...
用wireshark流量分析的四个案例
目录 第一题 1 2 3 4 第二题 1 2 3. 第三题 1 2 第四题 1 2 3 第一题 题目: 1.黑客攻击的第一个受害主机的网卡IP地址 2.黑客对URL的哪一个参数实施了SQL注入 3.第一个受害主机网站数据库的表前缀(加上下划线例如abc) 4.…...

Oracle 时区详解
1 简介 由于地球经纬度及地球自转引起的经度方向,不同的经度的地方,所感受到的昼夜是不同 的。有关国际会议决定将地球表面按经线从东到西,每隔经度15度划分一个时区,并且规定 相邻区域的时间相差1小时。 这就是时区的由来。 而实际使用中,…...

仿mudou高性能高并发服务器
"这个结局是我的期待,我会一直为你祝福。" 项目实现目标: 仿muduo库One Thread One Loop式主从Reacto模型实现高并发服务器。通过实现高并发服务器组件,简洁快速完成搭建一个高性能服务器。并且,通过组件内提供的不同应⽤层协议⽀…...

vue权限管理——菜单权限设置
1.前提:后端提供菜单对应数据 此处用mockjs模拟 const menuList [{id: 1, path:/uploadSpec,authName: "上传spec", icon: User, children:[], rights:[view,add,edit,delete]},{id: 2, path:/showSpec, authName: "Spec预览", icon: DataAn…...

【LeetCode】228.汇总区间
题目 给定一个 无重复元素 的 有序 整数数组 nums 。 返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表 。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。 列表中的每个区间范围 [a,b]…...

Qt快速学习(二)--QMainWindow,对话框,布局管理器,常用控件
目录 1 QMainWindow 1.1 菜单栏 1.2 工具栏 1.3 状态栏 1.4 铆接部件 1.5 核心部件(中心部件) 1.6 资源文件 2 对话框QDialog 2.1 基本概念 2.2 标准对话框 2.3 自定义消息框 2.4 消息对话框 2.5 标准文件对话框 3 布局管理器 3.1 系统…...

群晖DSM下套件及系统网页服务器ssl证书自动更新
关键字: DSM ssl 证书 起因 群晖下自建服务(alist3)和系统服务在外部网络访问需要加ssl安全证书来实现基础的传输保护。 申请证书和续期手动操作都还好,不算太麻烦,但是每个应用单独证书需要复制和重启,再配合服务重启一套下来就…...
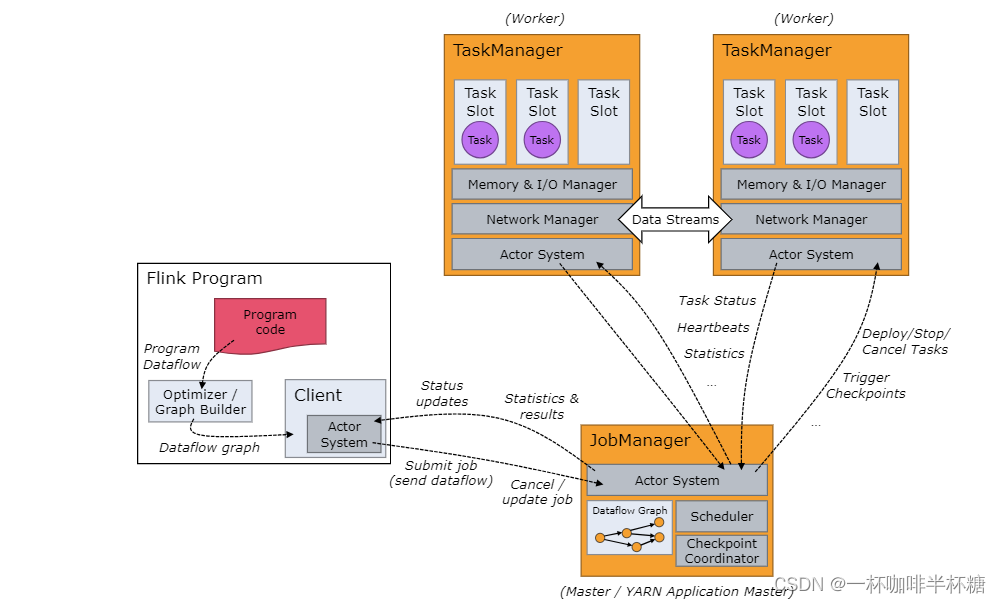
【Flink】Flink架构及组件
我们学习大数据知识的时候,需要知道大数据组件如何安装以及架构组件,这将帮助我们更好的了解大数据组件 对于大数据Flink,架构图图下: 整个架构图有三种关键组件 1、Client:负责作业的提交。调用程序的 main 方法&am…...

React Navigation 开发准备
需要 React Native 使用 React Navigation 的话,我们需要首先安装如下几个包: npm install react-navigation/native npm install react-native-screens react-native-safe-area-context开发之前做一些处理 如果您使用的是 Mac 并针对 iOS 进行开发&am…...

前端面试:【前端安全】安全性问题与防范措施
嗨,亲爱的前端开发者!在构建Web应用程序时,确保安全性是至关重要的。本文将深入讨论前端开发中的安全性问题,并提供一些防范措施,以确保你的应用程序和用户数据的安全性。 前端安全性问题: 跨站脚本攻击&am…...
[Linux]进程
文章目录 1. 进程控制1.1 进程概述1.1.1 并行和并发1.1.2 PCB1.1.4 进程状态1.1.5 进程命令 1.2 进程创建1.2.1 函数1.2.2 fork() 剖析 1.3 父子进程1.3.1 进程执行位置1.3.2 循环创建子进程1.3.3 终端显示问题1.3.4 进程数数 1.4 execl和execlp函数1.4.1 execl()1.4.2 execlp(…...

Docker编译镜像实战:为嵌入式Linux开发打造标准化环境
1. 项目概述:为什么我们需要一个专属的Docker编译镜像?如果你是一名嵌入式Linux开发者,或者正在学习诸如全志Tina Linux这样的开源嵌入式系统,那么“编译环境”这个词对你来说一定不陌生。它就像是一个厨师的后厨,锅碗…...

什么是vibe coding:概念解析与首选工具Trae实测
什么是vibe coding:概念解析与首选工具Trae实测你是否好奇vibe coding到底是什么,为何能成为2025年最火的开发方式?是否想知道vibe coding和传统编程的核心差异,以及用什么工具能高效落地?vibe coding是提示词驱动开发…...

嵌入式核心板选型与开发实战:M28x-T与M6G2C硬件设计及AWorks平台应用
1. 项目概述:为什么我们需要“一体化”核心板?在嵌入式产品开发,尤其是工业控制、数据采集这类对稳定性和开发效率要求极高的领域,很多工程师都经历过一个痛苦的过程:选型一颗主控MCU,然后围绕它去设计DDR内…...
线上服务卡顿?从一次ES写入超时故障,复盘我是如何调整`refresh_interval`和`translog`参数的
线上服务卡顿?一次Elasticsearch写入超时故障的深度调优实战 凌晨三点,监控系统突然告警——核心服务的API响应时间突破5秒阈值。快速排查发现,所有慢请求都卡在了日志写入环节。作为运维负责人,我立即意识到这又是一次Elasticsea…...
)
ChatGPT网络错误不是运气问题:用mtr追踪真实路径,定位ISP路由黑洞、中间盒QoS限速与WAF误拦截(附15分钟速查表)
更多请点击: https://codechina.net 第一章:ChatGPT网络错误不是运气问题:用mtr追踪真实路径,定位ISP路由黑洞、中间盒QoS限速与WAF误拦截(附15分钟速查表) ChatGPT连接失败常被归因为“服务器繁忙”或“网…...

HarmonyOS ArkUI实战:从零构建购物社交应用UI界面
1. 项目概述与核心价值如果你正在学习HarmonyOS应用开发,或者已经从其他移动端框架(如Android、Flutter)转过来,那么构建一个美观、交互流畅的UI界面,往往是上手实践的第一步,也是最直观检验学习成果的一步…...

为什么很多企业,做大后反而开始放弃 SaaS?——真正限制企业长期发展的,很多时候不是“功能”,而是“系统控制权”
很多企业第一次做商城系统时。 通常都会特别关注: 上线快不快成本低不低功能全不全能不能快速开展业务 所以: 很多企业前期都会优先选择: SaaS商城系统。 因为: SaaS 最大的优势确实很明显: 快速上线不需要运维…...

2026 年 5 月 AI 热点:大模型、硬件、人形机器人全面升级
一、大模型技术突破 | LLM Technology Breakthroughs 1.1 OpenAI GPT‑5.5 正式成为ChatGPT默认模型 | GPT‑5.5 Becomes ChatGPT Default Model 英文内容 | English On May 5, 2026, OpenAI officially rolled out GPT‑5.5 Instant as the new default model for ChatGPT, …...

大模型稀疏激活:MoE架构的工程实践与负载均衡
1. 这不是参数堆砌,而是“动态稀疏激活”的工程革命你可能已经看到过那条刷屏的推文:“GPT-4有1.8万亿参数,但每生成一个token只用其中2%。”——这句话像一道闪电劈开了大模型圈的认知惯性。它背后没有玄学,没有营销话术…...

【NotebookLM显著性判断实战指南】:20年AI架构师亲授5大误判陷阱与3步精准验证法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM显著性判断的核心概念与本质认知 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与对话生成的实验性 AI 工具,其“显著性判断”并非传统统计学中的 p 值检验ÿ…...