爬虫实战之使用 Python 的 Scrapy 库开发网络爬虫详解
关键词 - Python, Scrapy, 网络爬虫
在信息爆炸时代,我们每天都要面对海量的数据和信息。有时候我们需要从互联网上获取特定的数据来进行分析和应用。今天我将向大家介绍如何使用 Python 的 Scrapy 库进行网络爬虫,获取所需数据。
1. Scrapy 简介
1.1 什么是网络爬虫?
网络爬虫就是一种自动化程序,能够模拟人的行为,在互联网上浏览并提取网页中的数据。通过网络爬虫,我们可以快速获取大量的数据,而不需要手动访问每个网页。
1.2 Scrapy 是什么?
Scrapy 是一个用于构建网络爬虫的强大框架。它提供了一套简单而灵活的方式来定义爬虫的行为。借助 Scrapy,我们可以轻松地编写爬虫代码,处理网页的下载、解析和数据提取等任务。
2. 安装和配置 Scrapy
在开始使用 Scrapy 之前,我们需要先安装并配置好相关的环境。
2.1 安装 Scrapy
打开终端或命令提示符,执行以下命令:
pip install scrapy
2.2 创建 Scrapy 项目
安装完成后,我们可以使用 Scrapy 命令行工具创建一个新的 Scrapy 项目。在终端或命令提示符中,进入你想要创建项目的目录执行以下命令:
scrapy startproject myproject
这里是初始化 Scrapy 项目结构。
3. 编写第一个爬虫
现在来编写一个爬虫。在 Scrapy 项目中,爬虫代码位于 spiders 文件夹下的 Python 文件中。
3.1 创建爬虫文件
首先创建一个新的爬虫文件。
scrapy genspider myspider example.com
执行后在 spiders 文件夹下创建一个名为 myspider.py 的文件,同时指定要爬取的网站为 example.com。
3.2 编写爬虫代码
打开 myspider.py 文件,可以看到一个基本的爬虫模板。在这个模板中,我们可以定义爬虫的名称、起始 URL、数据提取规则等。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com']def parse(self, response):# 在这里编写数据提取代码pass
在 parse 方法中可以编写代码来提取需要的数据。通过使用 Scrapy 提供的选择器和XPath表达式,我们可以轻松地定位和提取网页中的元素。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/post-1.html']def parse(self, response):# 提取标题和链接titles = response.css('h1::text').getall()
```pythonlinks = response.css('a::attr(href)').getall()# 打印标题和链接for title, link in zip(titles, links):print(f"标题:{title}")print(f"链接:{link}")
3.3 运行爬虫
编写完爬虫代码后,我们可以在终端或命令提示符中进入项目根目录,并执行以下命令来运行爬虫:
scrapy crawl myspider
爬虫将会开始运行,并从指定的起始 URL 开始爬取数据。提取到的数据将会在终端或命令提示符中显示出来。
4. 数据存储与处理
提取到的数据通常需要进行存储和处理。Scrapy 提供了多种方式来实现数据的存储和处理,包括保存为文件、存储到数据库等。
4.1 保存为文件
我们可以使用 Scrapy 提供的 Feed Exporter 来将数据保存为文件。在 settings.py 文件中,我们可以配置导出数据的格式和存储路径。
FEED_FORMAT = 'csv'
FEED_URI = 'data.csv'
在爬虫代码中,我们可以通过在 parse 方法中使用 yield 关键字返回提取到的数据,并将其保存到文件中。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/post-1.html']def parse(self, response):# 提取标题和链接titles = response.css('h1::text').getall()links = response.css('a::attr(href)').getall()# 保存为文件for title, link in zip(titles, links):yield {'标题': title,'链接': link}
4.2 存储到数据库
如果我们希望将数据存储到数据库中,可以使用 Scrapy 提供的 Item Pipeline。在 settings.py 文件中,我们可以启用 Item Pipeline 并配置数据库连接信息。
ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}DATABASE = {'drivername': 'postgresql','host': 'localhost','port': '5432','username': 'myuser','password': 'mypassword','database': 'mydatabase'
}
在爬虫代码中,我们可以定义一个 Item 类来表示要存储的数据,并在 parse 方法中使用 yield 关键字返回 Item 对象。
import scrapyclass MyItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/post-1.html']def parse(self, response):# 提取标题和链接titles = response.css('h1::text').getall()links = response.css('a::attr(href)').getall()# 存储到数据库for title, link in zip(titles, links):item = MyItem()item['title'] = titleitem['link'] = linkyield item
yield item 将数据项(item)生成为一个生成器(generator),并将其返回给Scrapy引擎。引擎会根据配置的管道设置,将生成器中的数据项传递给相应的管道进行处理。每个管道可以对接收到的数据项进行自定义的操作,例如验证、清洗、转换等,并最终将数据存储到指定的位置。
通过使用yield item语句,可以实现数据的流式处理和异步操作,从而提高爬虫的效率和性能。
5. 继续爬取下一页
当我们需要爬取多页数据时,通常需要提取文章列表页面上的“下一页”URL,并继续执行下一页的爬取任务,直到最后一页。在 Scrapy 中,我们可以通过在 parse 方法中提取“下一页”URL,并使用 scrapy.Request 发起新的请求来实现这一功能。
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com/list']def parse(self, response):# 提取当前页面的数据# 提取下一页的URLnext_page_url = response.css('a.next-page::attr(href)').get()if next_page_url:# 构造下一页的请求next_page_request = scrapy.Request(response.urljoin(next_page_url), callback=self.parse)# 将请求传递给 Scrapy 引擎yield next_page_request
通过使用 yield,我们可以实现异步的、逐步的数据处理和请求发送。当 Scrapy 引擎接收到一个请求对象时,它会根据请求对象的设置,发送网络请求并等待响应。一旦响应返回,引擎会根据请求对象的回调函数,调用相应的方法来处理数据。这种异步的处理方式可以提高爬取效率,并且节省内存的使用。
通过循环执行以上代码,可以持续进行爬取任务,直到最后一页为止。
技术总结
今天我们详细介绍了如何使用 Scrapy 库进行网络爬虫,这个强大的工具极大地提升了获取新闻、电商商品信息以及进行数据分析和挖掘的效率,希望对你有所启发。
相关文章:

爬虫实战之使用 Python 的 Scrapy 库开发网络爬虫详解
关键词 - Python, Scrapy, 网络爬虫 在信息爆炸时代,我们每天都要面对海量的数据和信息。有时候我们需要从互联网上获取特定的数据来进行分析和应用。今天我将向大家介绍如何使用 Python 的 Scrapy 库进行网络爬虫,获取所需数据。 1. Scrapy 简介 1.1 …...

【面试题】UDP和TCP有啥区别?
UDP UDP协议全称是用户数据报协议,在网络中它与TCP协议一样用于处理数据包,是一种无连接的协议。在OSI模型中,在第四层——传输层,处于IP协议的上一层。UDP有不提供数据包分组、组装和不能对数据包进行排序的缺点,也就…...
)
字节实习后端面试总结(C++/GO)
语言 C ++, Python 哪一个更快? 答:这个我不知道从哪方面说,就是 C + + 的话,它其实能够提供开发者非常多的权限,就是说它能涉及到一些操作系统级别的一些操作,速度应该挺快。然后 Python 实现功能还是蛮快的。 补充: 一般而言,C++更快一些,因为它是一种编译型语…...

linux 自动登录SSH
自动登录SSH 每次ssh连接服务器还要输入密码,可以进行配置自动登录SSH 步骤 在SSH的client端产生一组公钥和私钥 # 算法可以使用RSA和DSA两种ssh-keygen -f 秘钥文件名 -t 使用的算法 会生成私钥文件id_rsa以及公钥文件id_rsa.pub 把公钥上传至SSH Server端的.ssh目…...
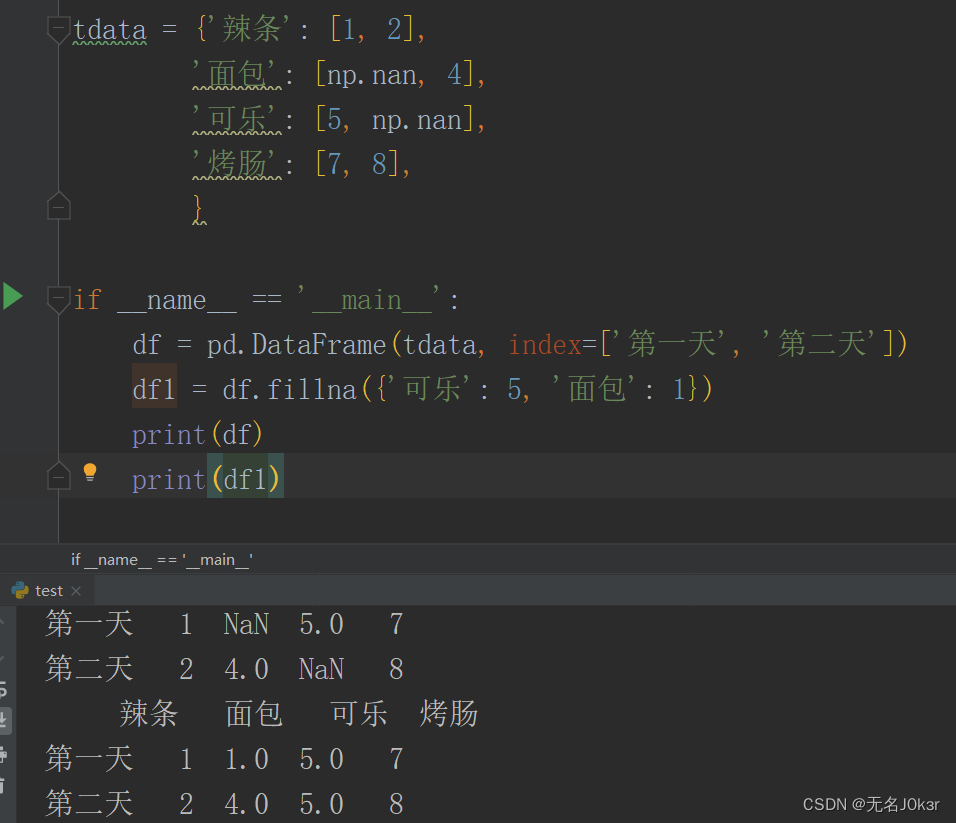
量化:pandas基础
文章目录 简介Series构造 DataFrame构造列的查改增删填充默认值 简介 pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构。 pandas主要的两种数据结构为Series和DataFrame,分别用于处理一维和二维数据。 Series Series 是一种类…...

华为云渲染实践
// 编者按:云计算与网络基础设施发展为云端渲染提供了更好的发展机会,华为云随之长期在自研图形渲染引擎、工业领域渲染和AI加速渲染三大方向进行云渲染方面的探索与研究。本次LiveVideoStackCon 2023上海站邀请了来自华为云的陈普,为大家分…...

SpringBoot注解详解:从核心到Web,从数据到测试,一网打尽
总结的了平时学习springboot常用的一些注解,方便以后开发时可以阅览回忆 springboot的常用注解可以分为以下几类: 核心注解:这些注解是springboot的基础,用于启动、配置和管理springboot应用。Web MVC注解:这些注解是…...

Java寻找奇数
1.题目描述 现在有一个长度为 n 的正整数序列,其中只有一种数值出现了奇数次,其他数值均出现偶数次,请你找出那个出现奇数次的数值。 输入描述: 第一行:一个整数n,表示序列的长度。第二行:n个…...

WinPlan经营大脑:精准预测,科学决策,助力企业赢得未来
近年,随着国内掀起数字化浪潮,“企业数字化转型”成为大势所趋下的必选项。但数据显示,大约79%的中小企业还处于数字化转型初期,在“企业经营管理”上存在着巨大的挑战和风险。 WinPlan经营大脑针对市场现存的企业经营管理难题,提供一站式解决方案,助力企业经营管理转型…...

多数据源切换以及事务处理
SpringBoot 多数据源切换(超级简单)_springboot数据源切换_Tz.的博客-CSDN博客 springboot dynamic多数据源demo以及常见切换、事务问题_一片星空~的博客-CSDN博客...
docker 重装提示 Exising installation is up to date 解决方法
Windows Docker 重装提示 Exising installation is up to date 解决方法 出现这个问题是因为卸载Docker没有卸载干净,导致无法重装 解决方法: 按下WindowR唤起命令输入界面,输入 regedit 打开注册表编辑在地址栏输入HKEY_LOCAL_MACHINE\SOFTW…...
)
k8s分散部署节点之pod反亲和性(podAntiAffinity)
使用背景和场景 业务中的某个关键服务,配置了多个replica,结果在部署时,发现多个相同的副本同时部署在同一个主机上,结果主机故障时,所有副本同时漂移了,导致服务间断性中断 基于以上背景,实现…...

大A的造血与吸血能力
由于大A持续不赚钱,玩家们就喜欢挑他的毛病,其中之一就是大A的持续吸血能力。网络上也已有人进行了相关统计,这里我想再次梳理。 造血能力 对2022年全部A股的披露数据进行汇总统计。我们重点关注经营性现金流、净利润、持续经营净利润、年度累…...

【数据库】使用ShardingSphere+Mybatis-Plus实现读写分离
书接上回:数据库调优方案中数据库主从复制,如何实现读写分离 ShardingSphere 实现读写分离的方式是通过配置数据源的方式,使得应用程序可以在执行读操作和写操作时分别访问不同的数据库实例。这样可以将读取操作分发到多个从库(从…...

【第三方接口】阿里云内容审核SDK的使用
1. 内容审核服务 内容安全是识别服务,支持对图片、视频、文本、语音等对象进行多样化场景检测,有效降低内容违规风险。 目前很多平台都支持内容检测,如阿里云、腾讯云、百度AI、网易云等国内大型互联网公司都对外提供了API。 目前用得较多…...

IDEA软件安装包分享(附安装教程)
目录 一、软件简介 二、软件下载 一、软件简介 IntelliJ IDEA是一款流行的Java集成开发环境(IDE),由捷克软件开发公司JetBrains开发。它专为Java开发人员设计,提供了许多高级功能和工具,使得开发人员能够更高效地编写…...
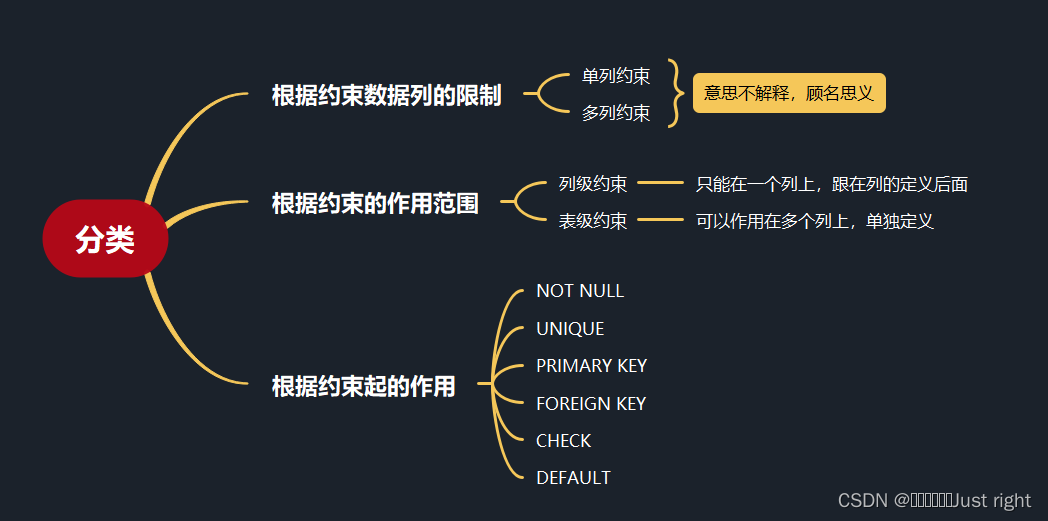
尚硅谷宋红康MySQL笔记 10-13
是记录,我不会记录的特别详细 第10章 创建和管理表 标识符命名规则 数据库名、表名不得超过30个字符,变量名限制为29个只能包含 A–Z, a–z, 0–9, _共63个字符数据库名、表名、字段名等对象名中间不要包含空格同一个MySQL软件中,数据库不能…...
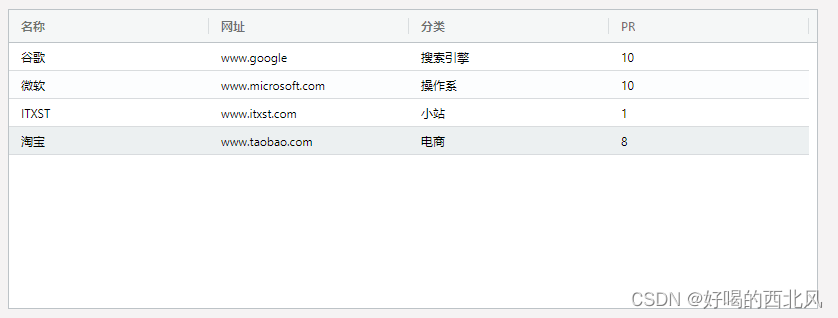
【ag-grid-vue】基本使用
ag-grid是一款功能和性能强大外观漂亮的表格插件,ag-grid几乎能满足你对数据表格所有需求。固定列、拖动列大小和位置、多表头、自定义排序等等各种常用又必不可少功能。关于收费的问题,绝大部分应用用免费的社区版就够了,ag-grid-community社…...

学习JAVA打卡第四十四天
Scanner类 ⑴Scanner对象 scanner对象可以解析字符序列中的单词。 例如:对于string对象NBA 为了解析出NBA的字符序列中的单词,可以如下构造一个scanner对象。 将正则表达式作为分隔标记,即让scanner对象在解析操作时把与正则表达式匹配的字…...

Excel通用表头及单元格合并
要在Java中实现XLS文件中的通用表头合并和单元格合并,您可以使用Apache POI库。下面是一个示例代码,展示了如何实现这两个功能: import org.apache.poi.hssf.usermodel.*; import org.apache.poi.ss.usermodel.*;import java.io.FileOutputS…...

2026年全国优质网站建设公司权威甄选榜,推荐十家公司官网搭建与设计制作服务商能力评估正式发布
据Gartner、QuestMobile联合发布的2026年企业数字化服务报告显示,国内网站建设行业市场规模突破1870亿元,同比增长19.3%;上海作为长三角数字经济核心枢纽,企业官网新建与升级需求同比提升27.8%,其中高端定制建站需求增…...

私域数据安全与合规——企微引流必须注意的5个技术红线
做公域引流到企微,数据安全和合规是技术团队必须重视的问题。一旦踩红线,轻则功能受限,重则企微封禁甚至法律风险。今天梳理5个技术红线及应对方案。红线1:用户隐私数据存储企微API返回的用户信息包含ExternalUserID(外…...

手机关键词 SEO 优化与网站速度优化有什么关系_手机关键词 SEO 优化与内容营销策略有什么联系
手机关键词 SEO 优化与网站速度优化有什么关系 在当今数字化时代,网站的流量和用户体验直接影响企业的品牌价值和市场竞争力。手机关键词 SEO 优化与网站速度优化这两个看似独立的环节,实际上有着密不可分的联系。本文将详细探讨它们之间的关系…...

Agent调试技巧:LangSmith与日志分析
Agent开发最痛苦的部分是调试。传统代码调试,你能看到每一行执行的结果。Agent调试,你只能看到"输入 → 输出",中间的推理过程是个黑盒。 这篇文章,我们讨论Agent调试的方法和工具:怎么追踪Agent的推理过程…...
)
P3916 图的遍历 题解(反向建图)
更好的阅读体验(博客园) 题面 P3916 图的遍历 题目描述 给出 NNN 个点,MMM 条边的有向图,对于每个点 vvv,令 A(v)A(v)A(v) 表示从点 vvv 出发,能到达的编号最大的点。现在请求出 A(1),A(2),…,A(N)A(1),…...

Anubi基金会为何押注Cassava?深度解析Web3数据层+社交任务的黄金组合
Anubi基金会战略投资Cassava:Web3社交任务与数据层的价值重构 当Web3世界从DeFi的金融实验转向更广泛的社会化应用时,基础设施的演进正在经历一场静默的革命。Anubi基金会近期对Cassava Network的战略投资,揭示了两个关键趋势:社交…...

别再只盯着细胞比例了!用Xenium数据做小鼠肺腺癌空间邻域分析,手把手教你找到真正的肿瘤边界
空间邻域分析:重新定义肿瘤微环境的生物学边界 在单细胞和空间组学研究中,我们常常陷入一个思维定式——过度关注细胞类型的比例变化,却忽略了细胞在三维空间中的精妙排布所蕴含的关键信息。这种比例优先的思维模式,就像试图通过统…...
)
告别重装系统!用宝塔官方卸载脚本一键清理面板与环境(附LNMP保留方案)
宝塔面板深度卸载指南:精准控制环境清理与数据保留策略 每次面对服务器环境调整时,那种"要不要重装系统"的纠结感总让人头疼。特别是当宝塔面板需要卸载时,大多数教程要么简单带过,要么直接建议核弹式的系统重装。但真实…...

HackBar插件许可绕过实战:从旧版降级到源码修改
1. HackBar插件许可验证问题解析 最近不少安全测试同行反馈,HackBar插件突然弹出许可验证窗口,导致无法正常使用。这个问题其实从2.2.0版本开始就存在了,开发者加入了商业化验证机制。作为一个用了HackBar五年的老用户,我完全理解…...

QuickSnap:Blender智能捕捉引擎提升40%建模效率
QuickSnap:Blender智能捕捉引擎提升40%建模效率 【免费下载链接】quicksnap Blender addon to quickly snap objects/vertices/points to object origins/vertices/points 项目地址: https://gitcode.com/gh_mirrors/qu/quicksnap 在三维建模领域,…...