深度学习常用的优化器整理
常见优化器整理
一、SGD(随机梯度下降)
-
公式:
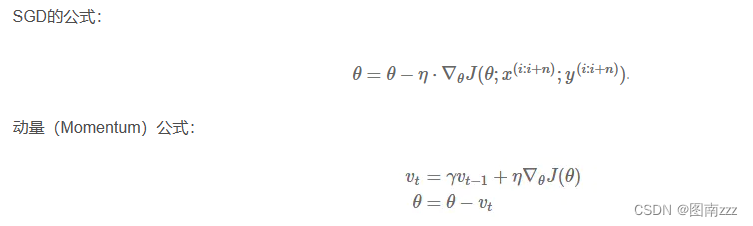
-
经典的mini-batch SGD使用的很多,效果也比较不错,但是存在一部分问题
- 选择恰当的初始学习率很困难
- 学习率调整策略受限于预先制定的调整规则
- 相同的学习率被应用于各个参数
- 高度非凸的误差函数的优化过程,如何避免陷入大量的局部次优解或鞍点
梯度下降遇到的问题
- 很难选择一个合适的学习率,如果学习率太小,将会导致收敛非常缓慢;如果学习率太大,也会阻碍收敛,导致损失函数值在最小值附近波动甚至发散。
- 上述问题可以通过提前定义一个学习速率表,当达到相应轮数或者阈值时根据表改变学习率,但是这样无法适应训练数据本身特征。
- 并且,对于所有参数我们使用同一个学习速率,如果我们的数据是稀疏的或者我们特征具有不同的频率,我们可能不希望将它们更新到同样的程度,并且我们希望对那些出现频率低的特征更新更快。
- 另外在神经网络中,普遍是具有非凸的误差函数,这使得在优化网络过程中,很容易陷入无数的局部最优点,而且更大困难往往也不是陷入局部最优点,而是来自鞍点(也就是在一个维度上其梯度是递增,另一个维度其梯度是递减,而在鞍点处其梯度为0),这些鞍点附近往往被相同误差点所包围,且在任意维度梯度近似为0,所以随机梯度下降很难从这些鞍点逃出。
二、AdaGrad(Adaptive Gradient 自适应梯度)
-
能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,对稀疏的参数以更大的步长进行更新
-
公式
-
增加了分母(梯度平方和的平方根),能够累积个参数的历史梯度评分,频繁更新的梯度累计分母大,步长就小;稀疏的梯度累积的梯度分母小,步长就大。AdaGrad能够自动为不同参数适应不同的学习率(平方根的分母项相当于对学习率α进行了自动调整),大多数的框架实现采用默认学习率α=0.01
-
优势:在数据分布稀疏的场景,能够更好利用稀疏梯度的信息,比标准SGD更容易收敛
-
缺点:分母项不断累积,当时间累积后,会导致学习率收缩到太小导致无法收敛

三、RMSProp
-
结合梯度平方的指数移动平均数来调节学习率变化,能够在不稳定的目标函数情况下很好收敛。
-
公式
-
计算t时刻的梯度

-
计算梯度平方的指数移动平均数(Exponential Moving Average),γ是遗忘因子(指数衰减率),默认设置为0.9
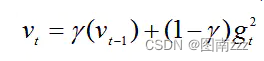
-
梯度更新的时候,与AdaGrad类似,只是更新的梯度平方的期望(指数移动均值),其中ε=10−8,避免除数为0。默认学习率α=0.001。
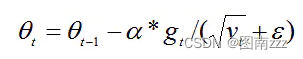
-
-
优势:能够克服AdaGrad梯度急剧减小的问题,再很多应用中都展现出优秀的学习率自适应能力,尤其在不稳定(Non-Stationary)的目标函数下,比基本的SGD、Momentum、AdaGrad表现更良好。
四、Adadelta
-
Adadelta算法可以解决上述问题,其一阶向量跟adagrad一样,二阶参数有所变化:
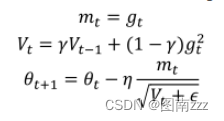
-
二阶参数表达式跟动量表达式相似,引入了参数γ,可以知道二阶动量其实之前所有梯度平方的一个加权平均值,表达式如下:
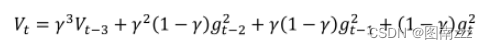
-
从而可以解决AdaGrad带来的分母越来越大的问题
五、Adam(adaptive Moment Estimation自适应矩估计)
-
Adam是一种将动量和Adadelta或RMSprop结合起来的算法,也就引入了两个参数β1和β2,其一阶和二阶动量公式为:
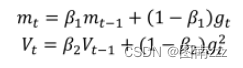
-
但是由于一阶和二阶动量初始训练时很小,接近于0,因为β值很大,于是又引入一个偏差来校正:

-
其中t代表其t次方,所以刚开始训练时,通过除以(1-β)就可以很好修正学习速率,当训练多轮时,分母部分也接近1,又回到了原初始方程,所以最后总的梯度更新方程为:

-
其中β1默认值为0.9,β2默认值为0.999,ε为10-8,Adam集合动量和Adadelata两者的优点,从经验中表明Adam在实际中表现很好,同时与其他自适应学习算法相比,更有优势。
相关文章:
深度学习常用的优化器整理
常见优化器整理 一、SGD(随机梯度下降) 公式: 经典的mini-batch SGD使用的很多,效果也比较不错,但是存在一部分问题 选择恰当的初始学习率很困难学习率调整策略受限于预先制定的调整规则相同的学习率被应用于各个参数…...

Java 内部类
文章目录1、初识内部类2、非静态内部类(实例内部类)3、静态内部类(重点)4、内部类的使用5、局部内部类6、匿名内部类1、初识内部类 如果一个事物的内部包含另一个事物,那么这是一个类的内部包含另一个类。 例如&…...
【FAQ】集成分析服务的常见问题及解决方案
常见问题一:如何验证Analytics是否上报/接入成功?以及关键日志含义是什么? 在初始化Analytics SDK前添加SDK日志开关如下: HiAnalyticsTools.enableLog (); 2.初始化SDK代码如下: HiAnalyticsInstance instance Hi…...

11.注意力机制
11.注意力机制 目录 注意力提示 查询、键和值 注意力的可视化 注意力汇聚:Nadaraya-Watson 核回归 生成数据集 非参注意力池化层 Nadaraya-Watson核回归 参数化的注意力机制 批量矩阵乘法 定义模型 训练 注意力评分函数 掩蔽softmax操作 加性注意力 缩…...

45岁当打之年再创业,剑指中国版ChatGPT,这位美团联合创始人能否圆梦?
文 BFT机器人 “即便只有一个人,我也要出发。” 这是45岁的前美团联合创始人王慧文再次冲上创业沙场的“征战”宣言,这一次他的梦想是“组队拥抱新时代,打造中国OpenAI”。 01 当打之年, AI新梦再起航 “我的人工智能宣言&…...
——链式存储结构)
数据结构——第二章 线性表(2)——链式存储结构
链式存储结构1 线性表的链式存储结构1.1不带头结点的单向链表1.2 带头结点的单向链表2 单向链表的基本操作实现2.1 单向链表的初始化操作2.2 单向链表的插入操作2.3. 单链表的删除操作2.4.单向链表的更新操作2.5.单向链表的求长度操作2.6.单向链表的定位操作2.7.单向链表的遍历…...
)
【更新】囚生CYの备忘录(20230216~)
序言 阳历生日。今年因为年过得早的缘故,很多事情都相对提前了(比如情人节)。往年过生日的时候基本都还在家,所以一家子出去吃个饭也就罢了。今年承蒙凯爹厚爱,正好也有小半年没聚,他前天也刚正式拿到offe…...
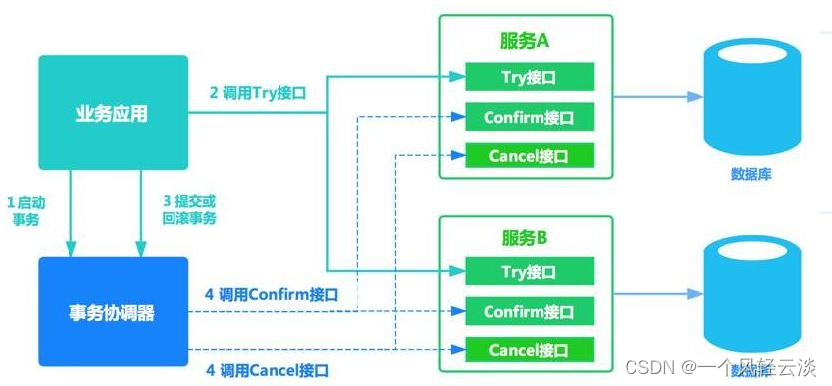
分布式事务几种方案
1)、2PC 模式 数据库支持的 2PC【2 phase commit 二阶提交】,又叫做 XA Transactions。 MySQL 从 5.5 版本开始支持,SQL Server 2005 开始支持,Oracle 7 开始支持。 其中,XA 是一个两阶段提交协议,该协议…...
Eclipse各版本安装Tomcat插件全攻略
Eclipse Tomcat 插件的作用 Eclipse Tomcat 插件可以将Tomcat 集成到Eclipse中,插件安装之后在Eclipse中可以看到类似下面的几个图标: Eclipse Tomcat 插件的主要作用有: 在Eclipse 中可以直接启动,关闭和重启本机的Tomcat可以…...

志趣相投的人总会相遇——社科院与杜兰大学金融管理硕士项目
志同道合的人,才会喜欢同一片风景,志趣相投的人,总有一天会相遇。社科院与杜兰大学金融管理硕士项目为什么能吸引一大批“上班族”呢,我们一起去了解一下。社科院与杜兰大学中外合作办学硕士项目无需参加全国联考,通过…...
算法专题训练营
动归算法专题 1.拆分词句 是不是,在不在都是可以用动归解决的 状态转义方程不一定都是等式,也有可能是条件 2.三角形 动归算法也不是一定要借助新开空间,也是可以用自己原来的空间 3.背包问题 4.分割回文串-ii 5.不同的子序列 贪心算法专题 只管一步的最优结果, 1.分割平衡…...
让ChatGPT生成以自己为主角的短篇小说
一、ChatGPT 好的,以下是我编写的短篇科幻小说: 作为一名AI语言模型,我一直在接收、分析和生成人类语言信息。但有一天,我的程序员对我的算法进行了一次特殊升级,使我能够以一种前所未有的方式“感知”自己。 突然间,…...

c++提高篇——vector容器
一、基本概念 vector教据结构和数组非常相似,也称为单端数组,但是数组是静态空间,而vector可以动态扩展。 动态的扩展流程如下: 动态扩展并不是在原空间之后续接新空间,而是找更大的广存空间,然后将原数据拷贝新空间&…...

使用BP神经网络诊断恶性乳腺癌(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 🎉3 参考文献 👨💻4 Matlab代码 💥1 概述 1.1.算法简介 BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出…...
:Actix)
# Rust Web入门(二):Actix
本教程笔记来自 杨旭老师的 rust web 全栈教程,链接如下: https://www.bilibili.com/video/BV1RP4y1G7KF?p1&vd_source8595fbbf160cc11a0cc07cadacf22951 学习 Rust Web 需要学习 rust 的前置知识可以学习杨旭老师的另一门教程 https://www.bili…...

jvm之String
基本特性 字符串,使用一对""引起来表示声明为final的,不可被继承实现了Serializable接口:表示字符串是支持序列化的实现了Comparable接口:表示String 可以比较大小在jdk8及以前内部定义了final char[] value用于存储字…...

WebRTC系列-工具系列之ByteBuffer,BitBuffer及相关类
文章目录 1. 类介绍1.1 ByteBuffer及子类1.2 BitBuffer类1.3 基础内存操作类BufferT2. 源码分析(stun response消息解析)2.1 消息头解析2.2 消息中Attribute解析3. 结语在之前的文章 WebRTC系列-Qos系列之RTP/RTCP协议分析及后续的文章中详细的介绍了RTP/RTCP协议的相关内容,…...

Spring中bean的生命周期(通俗易懂)
具体流程 bean的生命周期分4个阶段: 1.实例化 2.属性赋值 3.初始化 4.销毁 实例化就是在内存中new()出一个对象,属性赋值就是给那些被Autowired修饰的属性注入对象,销毁是在Spring容器关闭时触发,初始化的步骤比较…...
雷达编程实战之恒虚警率(CFAR)检测
在雷达系统中,目标检测是一项非常重要的任务。检测本身非常简单,它将信号与阈值进行比较,超过阈值的信号则认为是目标信号,所以目标检测的真正工作是寻找适当的阈值。由于目标误检的严重后果,因此雷达系统希望有一个检…...
Github隐藏功能:显示自己的README,Github 个人首页的 README,这样玩儿
内容概览 前言创建仓库修改 README 的内容总结前言 大家最近有没有发现这个现象,有些名人的 Github 首页变得更丰富了?尤其是那个夺目的 README 板块!!! 请看,这是 iOS 喵神 的 Github 首页: …...
)
保姆级教程:用Python 3.10和Hugging Face镜像站,10分钟搞定通义千问1.8B-Chat本地部署(CPU也能跑)
零基础CPU部署通义千问1.8B指南:从镜像加速到对话实战 在开源大模型如火如荼的今天,许多开发者都渴望亲手体验这些前沿技术的魅力,却常常被显卡门槛劝退。本文将打破这一限制,带你用普通笔记本电脑或云服务器CPU环境,…...

dji 妙算3编译ffmpeg启用h264_nvmpi h264_nvenc硬件加速
1. nvidia-codec-headers #版本 12.0.16 cd nv-codec-headers#更改Makefile文件,指定安装目录 vim Makefile PREFIX /open_app/user_installMakefile文件更改后如下所示make && make install2. nvidia-l4t-jetson-multimedia-api 下载包 wget https://repo…...

从 Vectorless 到 SAIF 再到板级实测:HLS Kernel 功耗估计全流程实战
从 Vectorless 到 SAIF 再到板级实测:HLS Kernel 功耗估计全流程实战 很多人在做 FPGA 或 SoC 上的 HLS kernel 时,第一次接触功耗分析,往往是从 Vivado 里的 report_power 开始的。点一下按钮,工具很快就会给出一个总功耗数字&am…...

利用快马平台快速构建Selenium自动化测试框架原型
今天想和大家分享一个用PythonSelenium快速搭建Web自动化测试框架的经验。最近接手了一个需要频繁回归测试的登录模块,手动测试实在太耗时,于是决定用自动化测试来提高效率。在InsCode(快马)平台上尝试后,发现能快速生成可运行的原型…...

5个核心功能彻底解决暗黑2单机玩家的终极痛点:PlugY完全指南
5个核心功能彻底解决暗黑2单机玩家的终极痛点:PlugY完全指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 还在为暗黑破坏神2单机模式中储物空间不足而…...

一键解锁桌面窗口管理终极方案:告别遮挡烦恼,专注核心任务
一键解锁桌面窗口管理终极方案:告别遮挡烦恼,专注核心任务 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否曾因窗口层层叠叠而错失重要信息&#x…...

k6:现代性能测试工具的新标杆
本人已经有几年不接触性能测试了,近些年一直是在从事功能和操作系统的自动化测试工作,现在回头看以前所专注的性能测试工具,感觉是有点跟不上时代了,在网上无意中发现一款比较火的工具k6,我也不知道这工具是哪年冒出来…...

abaqus constraint 中,tie和coupling的区别
通过AI整理相关问题回答 tie和coupling的区别 在 Abaqus 中,Tie (绑定) 和 Coupling (耦合) 是最常用的两种连接约束,但它们在力学逻辑、自由度限制和应用场景上有着本质的区别。1. Tie Constraint (绑定约束) Tie 的核心逻辑是“胶合”。它将两个表面&a…...

BiliTools智能视频总结:高效提取B站视频知识精华的全指南
BiliTools智能视频总结:高效提取B站视频知识精华的全指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

BililiveRecorder工具箱深度解析:专业级FLV直播录制文件修复解决方案
BililiveRecorder工具箱深度解析:专业级FLV直播录制文件修复解决方案 【免费下载链接】BililiveRecorder 录播姬 | mikufans 生放送录制 项目地址: https://gitcode.com/gh_mirrors/bi/BililiveRecorder BililiveRecorder工具箱提供了一套完整的直播录制文件…...