Spark on Yarn集群模式搭建及测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
点击传送:大数据学习专栏
持续更新中,感谢各位前辈朋友们支持学习~
文章目录
- 1.Spark on Yarn集群模式介绍
- 2.搭建环境准备
- 3.搭建步骤
1.Spark on Yarn集群模式介绍
Apache Spark是一个快速的、通用的大数据处理框架,它支持在各种环境中进行分布式数据处理和分析。在Yarn集群模式下搭建Spark环境可以充分利用Hadoop的资源管理和调度能力。
本文将介绍如何搭建Spark on Yarn集群模式环境,步骤详细,代码量大,准备发车~

2.搭建环境准备
本次用到的环境有:
Java 1.8.0_191
Spark-2.2.0-bin-hadoop2.7
Hadoop 2.7.4
Oracle Linux 7.4
3.搭建步骤
1.解压Spark压缩文件至/opt目录下
tar -zxvf ~/experiment/file/spark-2.2.0-bin-hadoop2.7.tgz -C /opt

2.修改解压后为文件名为spark
mv /opt/spark-2.2.0-bin-hadoop2.7 /opt/spark

3.复制spark配置文件,首先在主节点(Master)上,进入Spark安装目录下的配置文件目录{ $SPARK_HOME/conf },并复制spark-env.sh配置文件:
cd /opt/spark/conf
cp spark-env.sh.template spark-env.sh

4.Vim编辑器打开spark配置文件
vim spark-env.sh
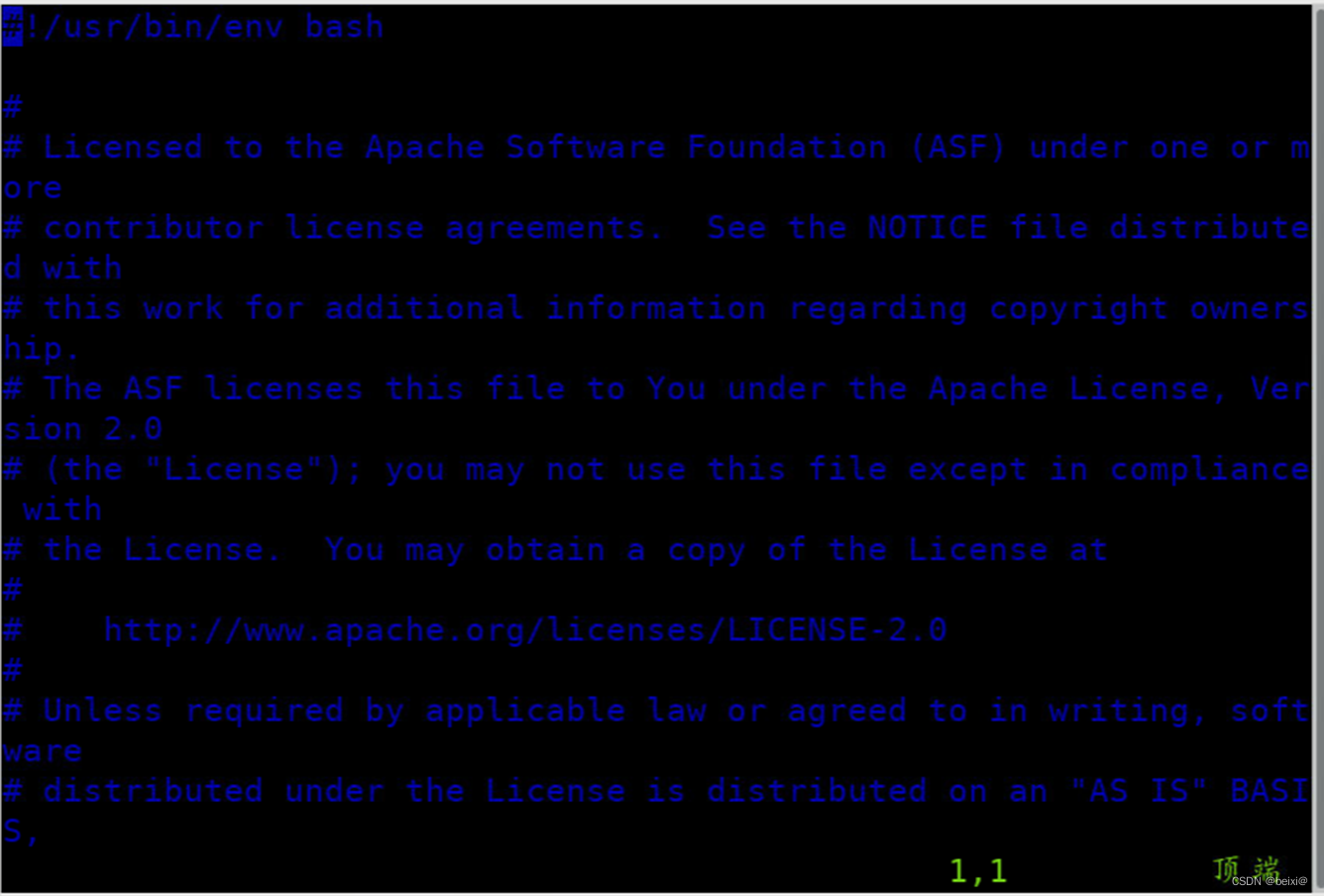
5.按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码,注意:“=”附近无空格:
export JAVA_HOME=/usr/lib/java-1.8
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
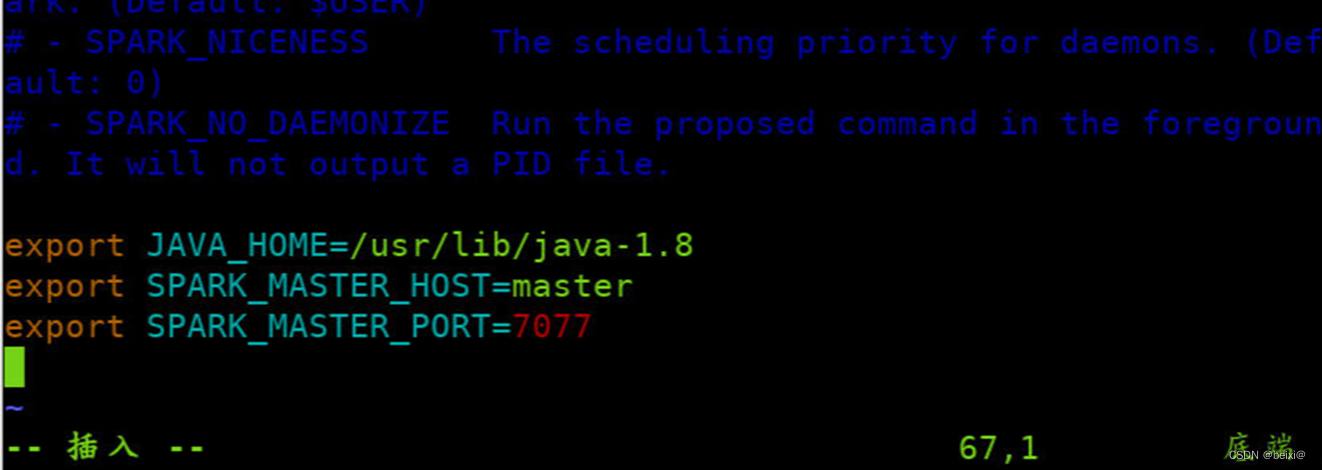
6.复制一份spark的slaves配置文件
cp slaves.template slaves

7.修改spark的slaves配置文件
vim slaves

8.每一行添加工作节点(Worker)名称,按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
slave1
slave2
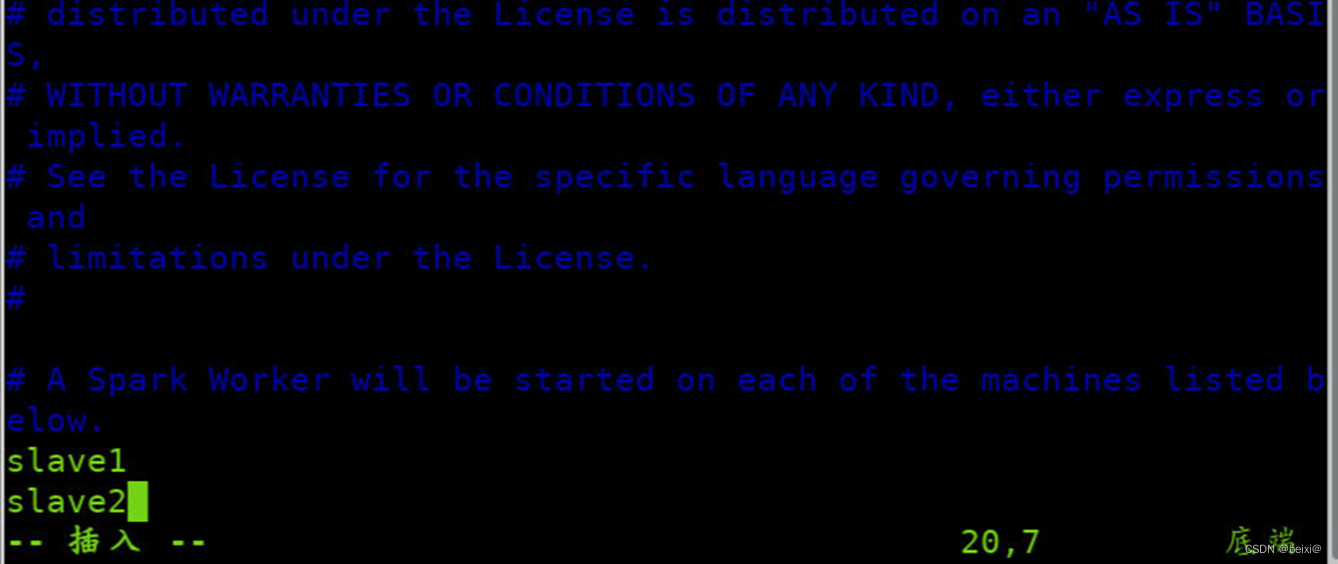
按键Esc,按键:wq保存退出
9.复制spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf

10.通过远程scp指令将Master主节点的Spark安装包分发至各个从节点,即slave1和slave2节点
scp -r /opt/spark/ root@slave1:/opt/
scp -r /opt/spark/ root@slave2:/opt/


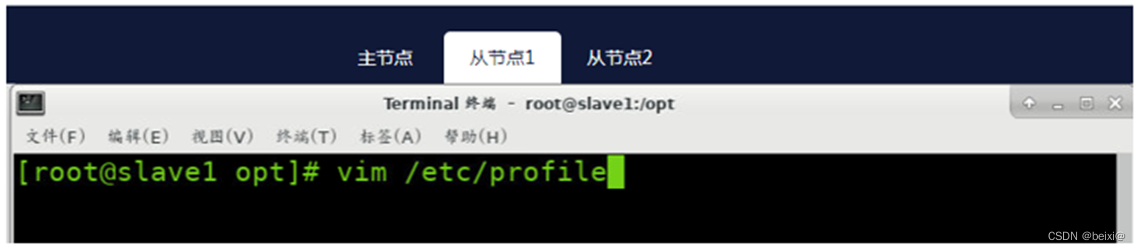
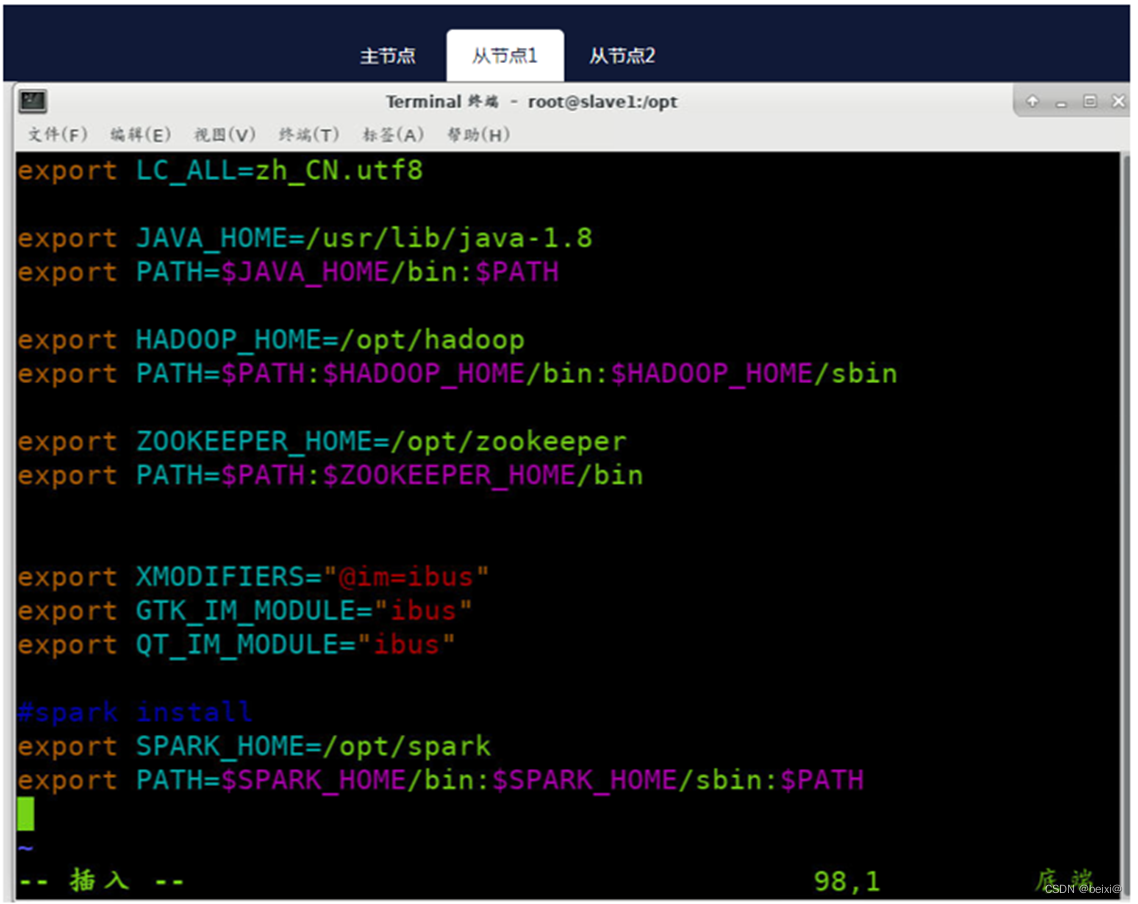
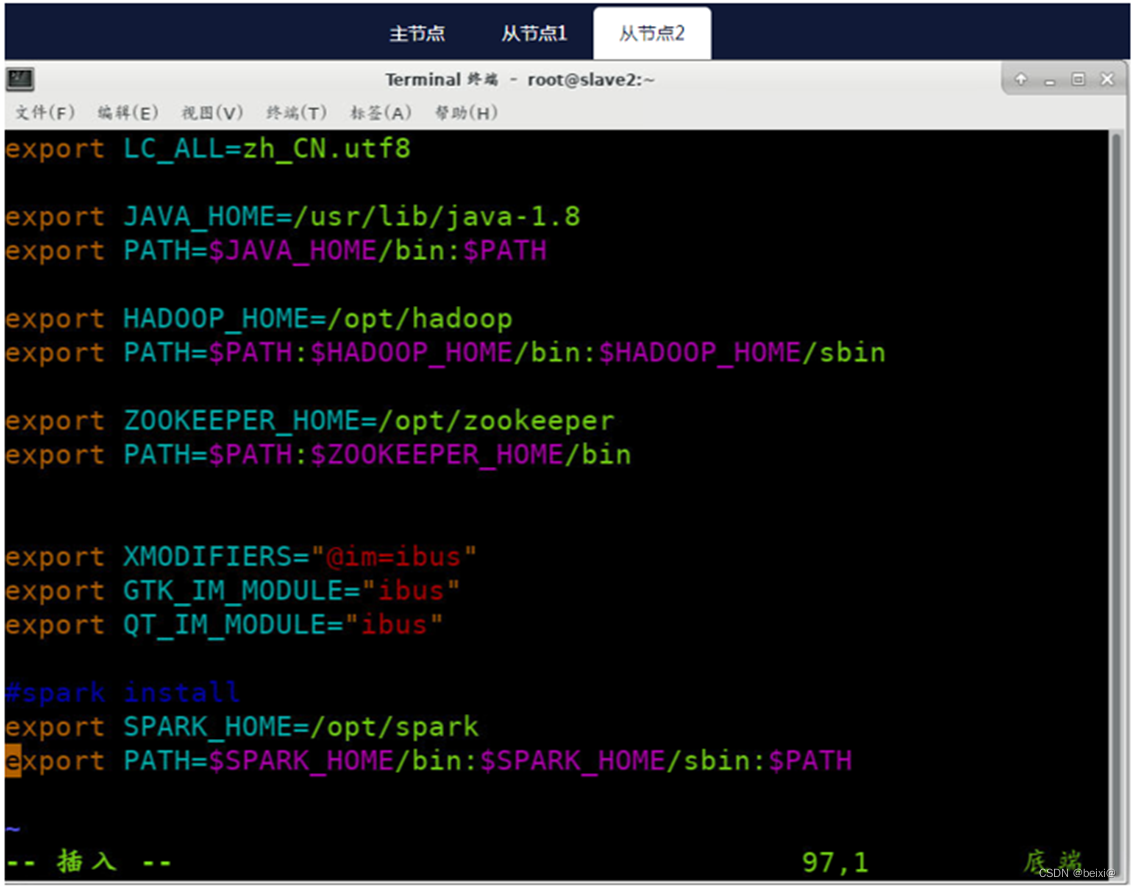
11.配置环境变量:分别在master,slave1和slave2节点上配置环境变量,修改【/etc/profile】,在文件尾部追加以下内容
vim /etc/profile
按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
#spark install
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
主节点(master)上执行截图,如下:

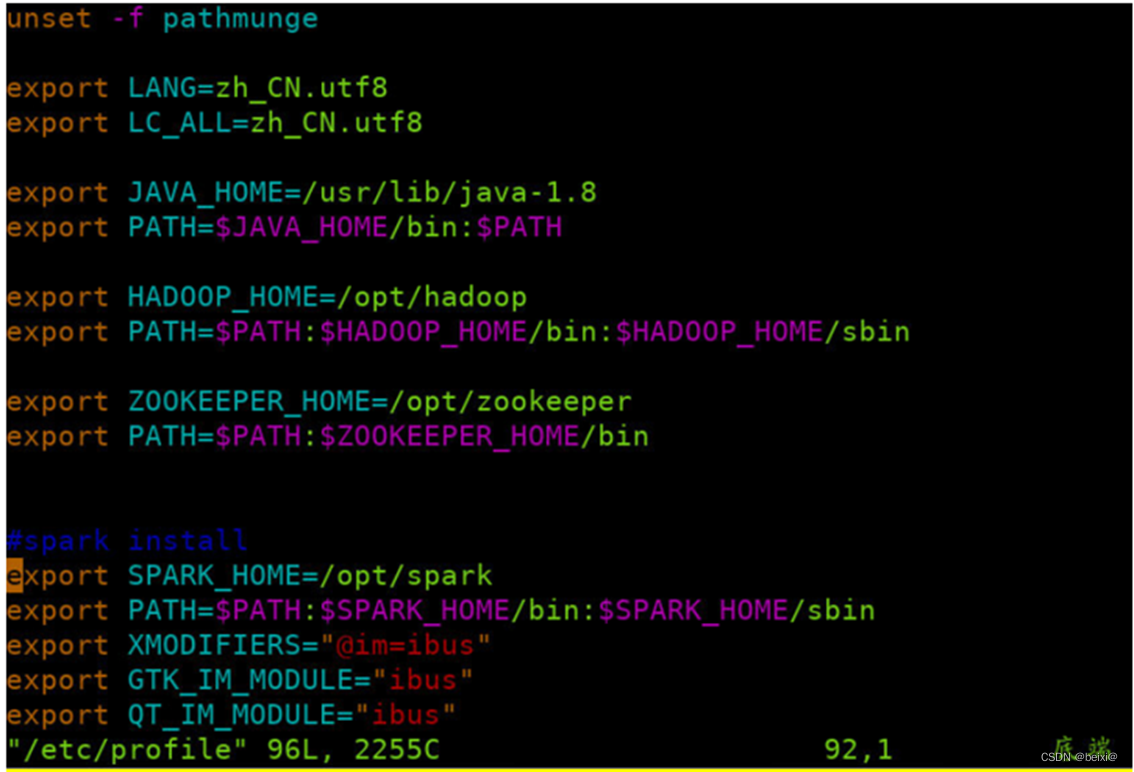
从节点1(Slave1)上执行截图,如下:
从节点2(Slave2)上执行截图,如下:

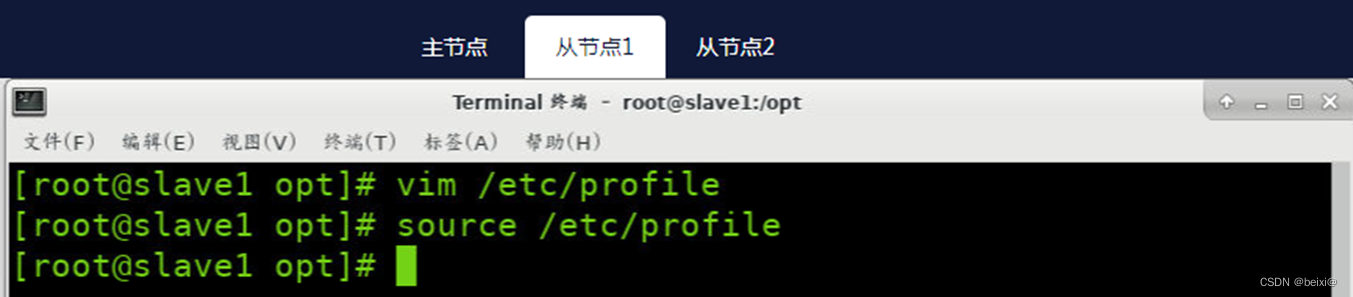
12.按键Esc,按键:wq保存退出
13.分别在Slave1和Slave2上,刷新配置文件
source /etc/profile

14.绑定Hadoop配置目录(在主节点),Spark搭建On YARN模式,只需修改spark-env.sh配置文件的HADOOP_CONF_DIR属性,指向Hadoop安装目录中配置文件目录,具体操作如下
vim /opt/spark/conf/spark-env.sh
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
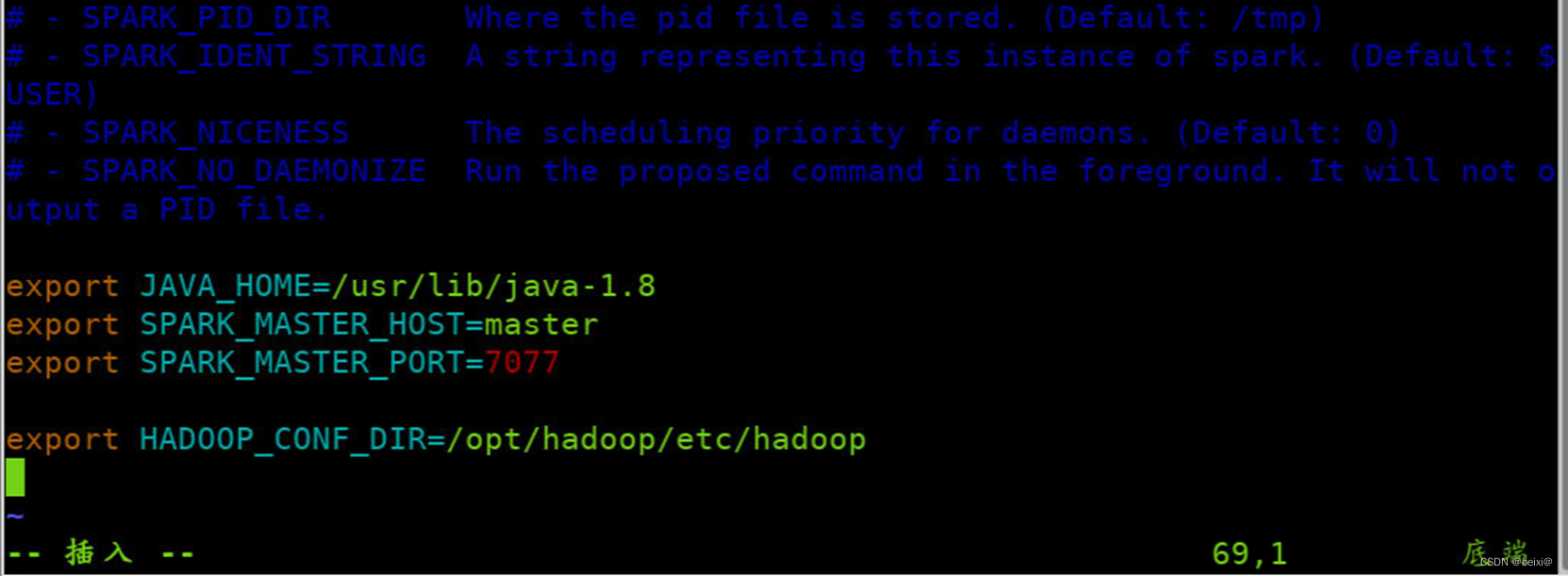
15.按键Esc,按键:wq保存退出
16.在主节点修改完配置文件后,一定要将【/opt/spark/conf/spark-env.sh】文件同步分发至所有从节点,命令如下
scp -r /opt/spark/conf/spark-env.sh root@slave1:/opt/spark/conf/
scp -r /opt/spark/conf/spark-env.sh root@slave2:/opt/spark/conf/

17.注意事项,如不修改此项,可能在提交作业时抛相关异常,Yarn的资源调用超出上限,需修在文件最后添加属性改默认校验属性,修改文件为
{HADOOP_HOME/etc/hadoop}/yarn-site.xml
vim /opt/hadoop/etc/hadoop/yarn-site.xml
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
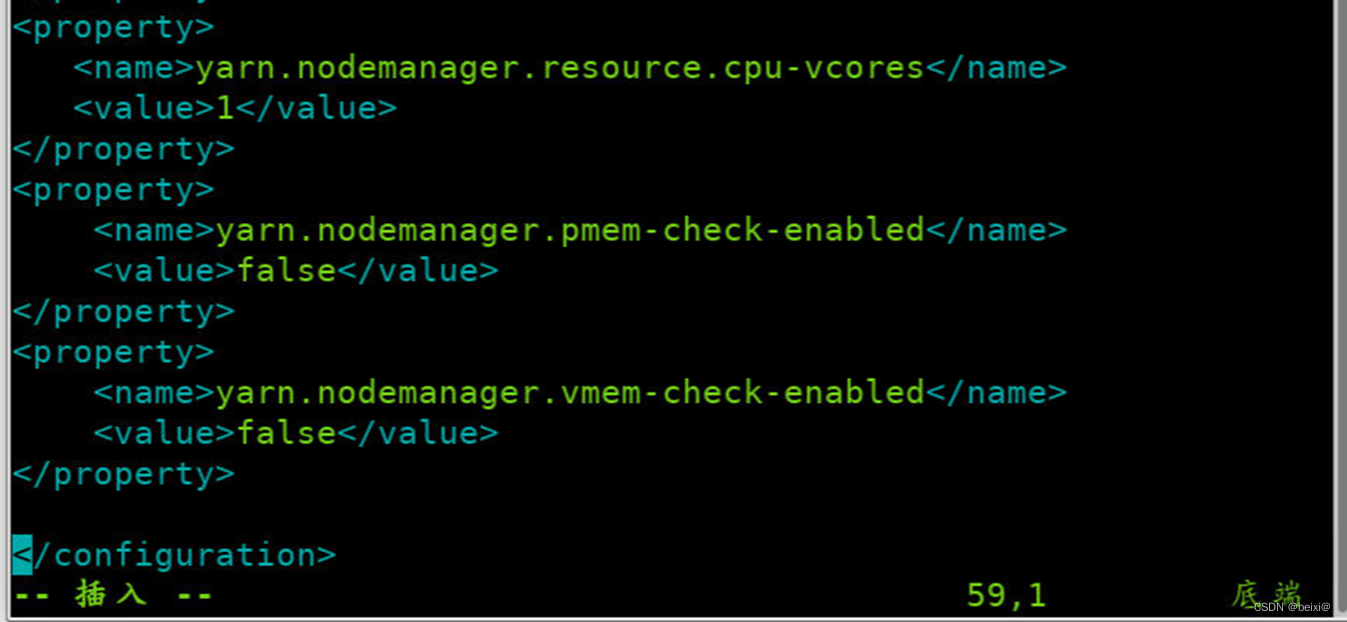
18.修改完成后分发至集群其它节点:
scp /opt/hadoop/etc/hadoop/yarn-site.xml root@slave1:/opt/hadoop/etc/hadoop/
scp /opt/hadoop/etc/hadoop/yarn-site.xml root@slave2:/opt/hadoop/etc/hadoop/
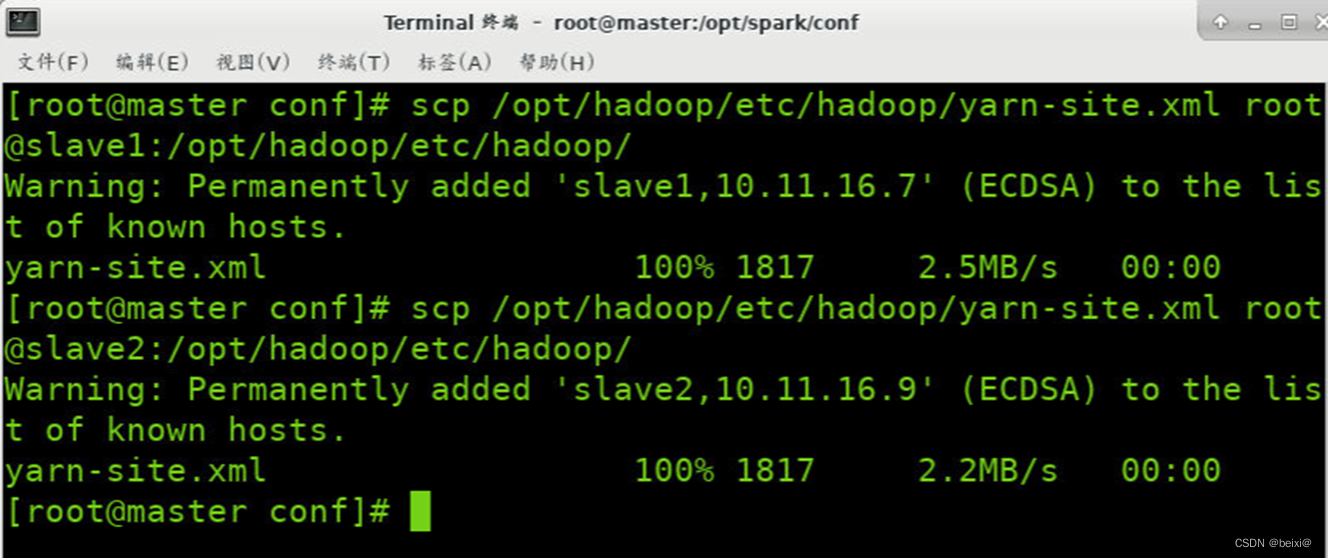
19.开启Hadoop集群,在开启Spark On Yarn集群之前必须首先开启Hadoop集群,指令如下:
start-dfs.sh
start-yarn.sh

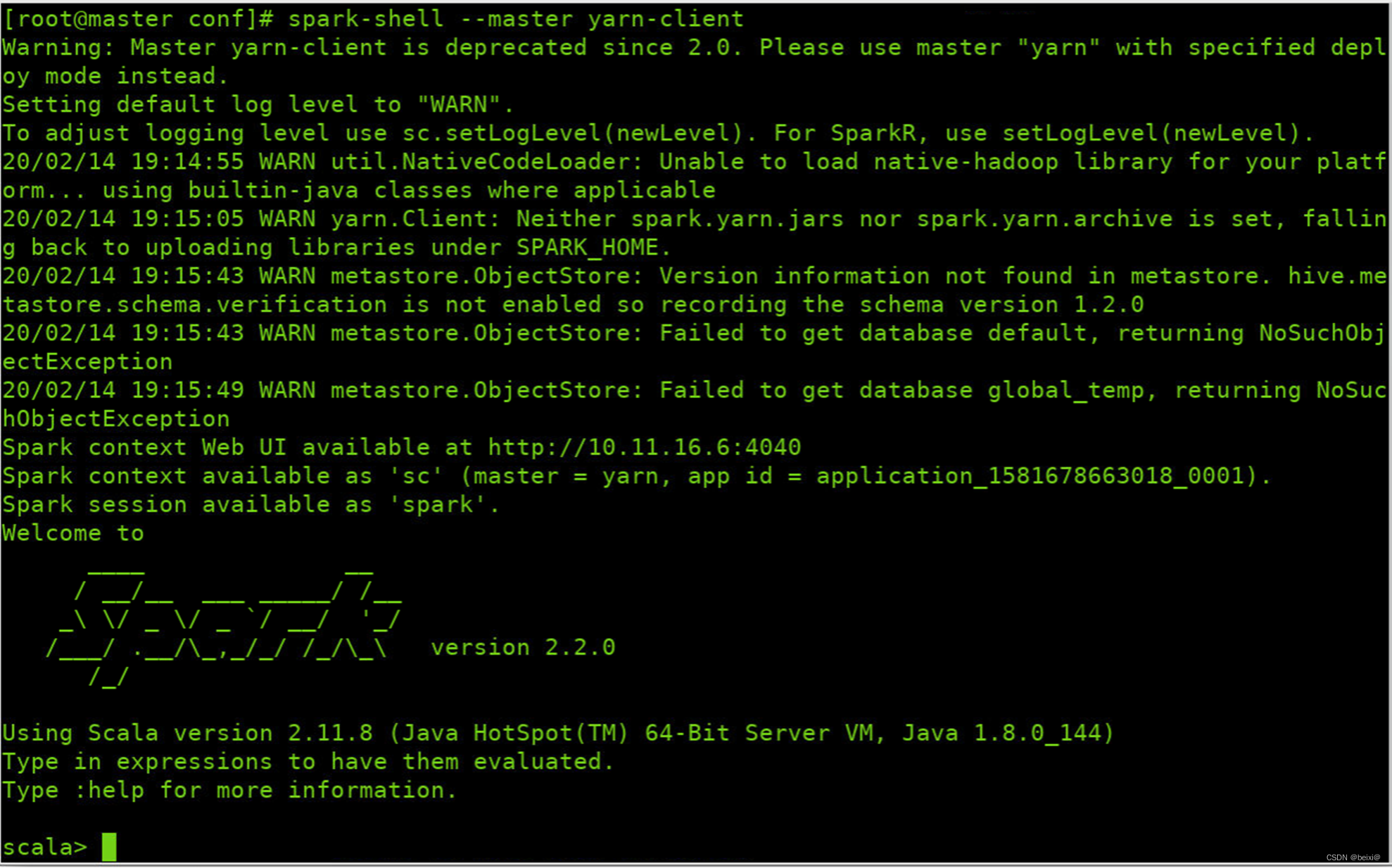
20.开启spark shell会话
spark-shell --master yarn-client
21.查看三台节点的后台守护进程
jps
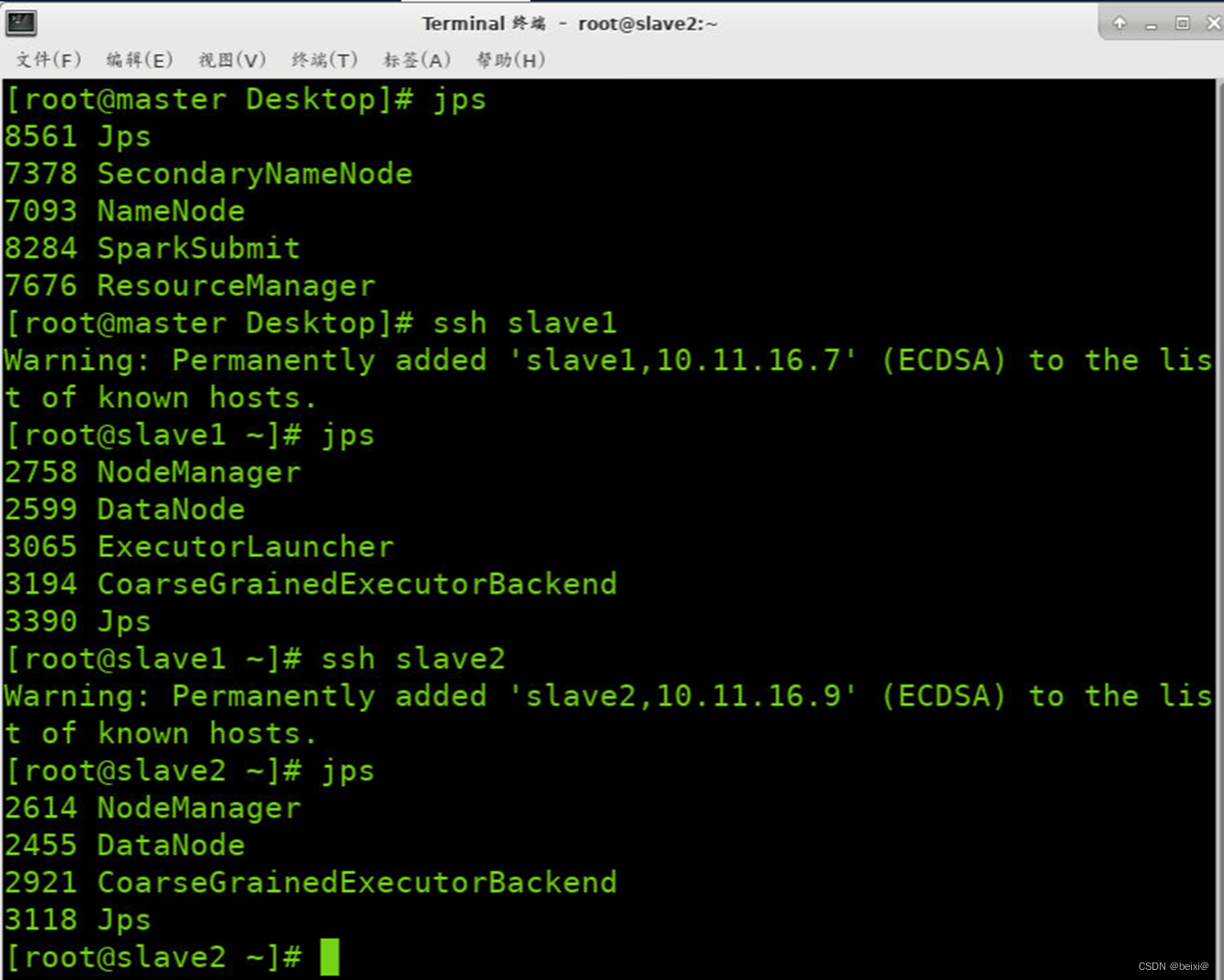
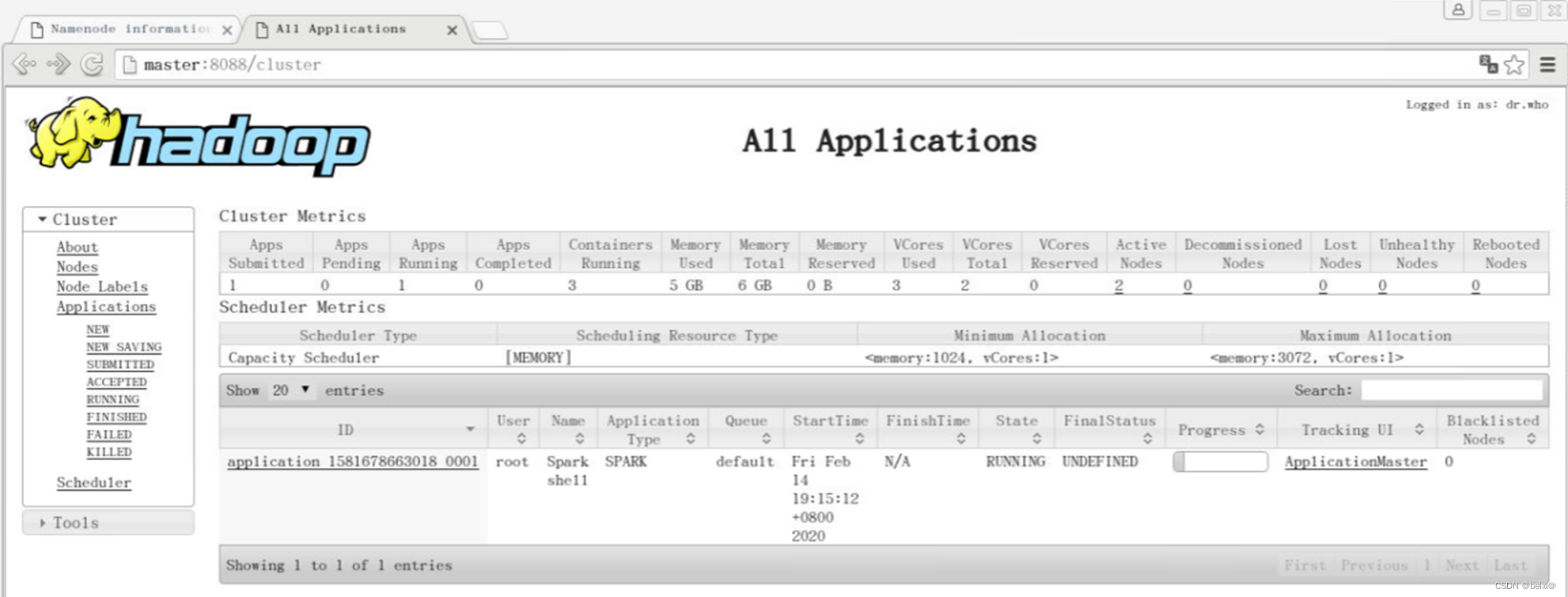
22.查看查看WebUI界面,应用提交后,进入Hadoop的Yarn资源调度页面http://master:8088,查看应用的运行情况,如图所示
所有配置完成,如果本篇文章对你有帮助,记得点赞关注+收藏哦~
相关文章:
Spark on Yarn集群模式搭建及测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 点击传送:大数据学习专栏 持续更新中,感谢各位前辈朋友们支持学习~ 文章目录 1.Spark on Yarn集群模式介绍2.搭建环境准备3.搭建步骤 1.Spark on Yarn集群模式介…...

vue 简单实验 v-on html事件绑定
1.代码 <script src"https://unpkg.com/vuenext" rel"external nofollow" ></script> <div id"event-handling"><p>{{ message }}</p><button v-on:click"reverseMessage">反转 Message</but…...

c#设计模式-创建型模式 之 原型模式
概述 原型模式是一种创建型设计模式,它允许你复制已有对象,而无需使代码依赖它们所属的类。新的对象可以通过原型模式对已有对象进行复制来获得,而不是每次都重新创建。 原型模式包含如下角色: 抽象原型类:规定了具…...

运放的分类、运放的参数
一、运放的分类 运放按功能分为通用运放与专用运放(高速运放、精密运放、低IB运放等)。 1.1通用运放 除廉价外,没有任何最优指标的运放。 例:uA741,LM324,TL06X,TL07X、TL08X等 国外知名运放…...
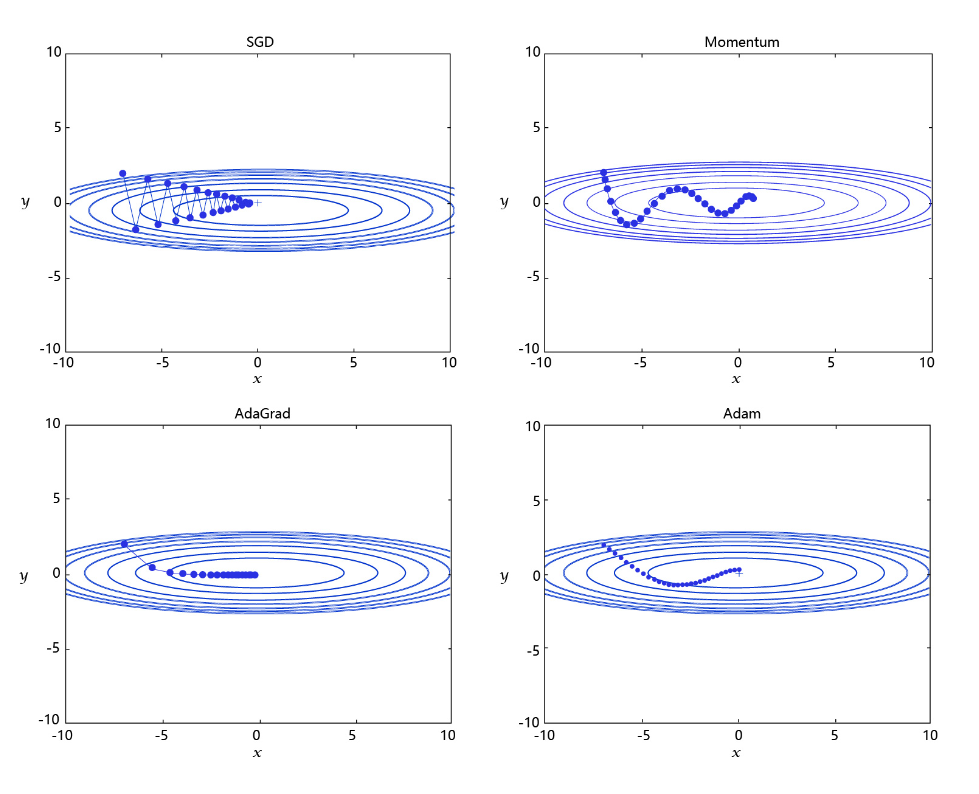
手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率
目录 手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率 前提条件 设置学习率 学习率的主流优化算法 手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率 我们明确了分类任务的损失函数(优化目标)的相关概念和实现方法ÿ…...
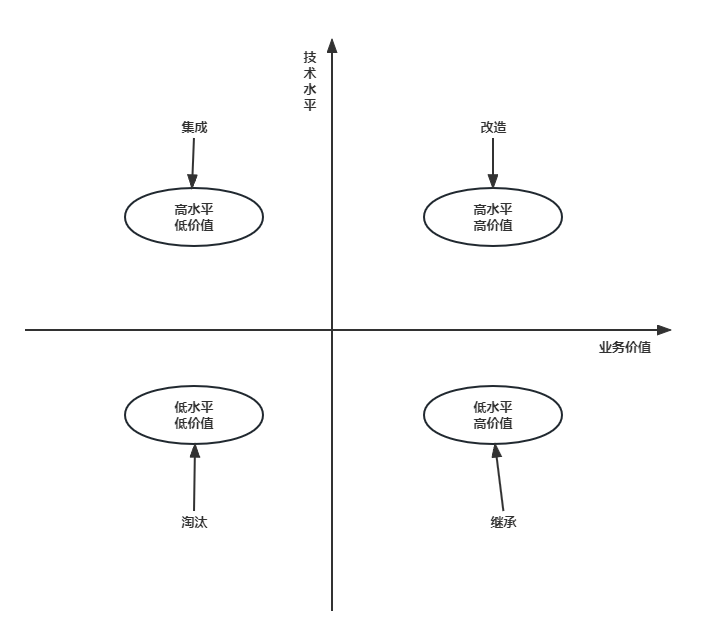
软件工程(二十) 系统运行与软件维护
1、系统转换计划 1.1、遗留系统的演化策略 时至今日,你想去开发一个系统,想完全不涉及到已有的系统,基本是不可能的事情。但是对于已有系统我们有一个策略。 比如我们是淘汰掉已有系统,还是继承已有系统,或者集成已有系统,或者改造遗留的系统呢,都是不同的策略。 技术…...

蓝蓝设计ui设计公司作品--泛亚高科-光伏电站控制系统界面设计
泛亚高科(北京)科技有限公司(以下简称“泛亚高科”),一个以实时监控、高精度数值计算为基础的科技公司, 自成立以来,组成了以博士、硕士为核心的技术团队,整合了华北电力大学等高校资源,凭借在电…...

软考高级系统架构设计师系列论文七十:论信息系统的安全体系
软考高级系统架构设计师系列论文七十:论信息系统的安全体系 一、信息系统相关知识点二、摘要三、正文四、总结一、信息系统相关知识点 软考高级信息系统项目管理师系列之四十三:信息系统安全管理...

Softing dataFEED OPC Suite——助力数字孪生技术发展
一 行业概览 数字孪生技术是充分利用物理模型、传感器更新、运行历史等数据,集成多学科、多物理量、多尺度、多概率的仿真过程,在虚拟空间中完成映射,从而反映相对应的实体装备的全生命周期过程。数字孪生技术已经应用在众多领域:…...
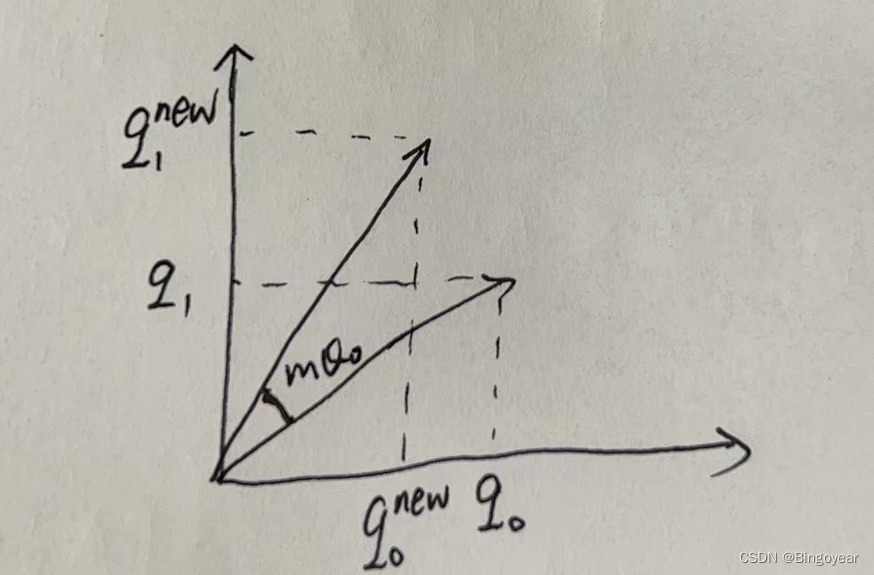
LLaMA中ROPE位置编码实现源码解析
1、Attention中q,经下式,生成新的q。m为句长length,d为embedding_dim/head θ i 1 1000 0 2 i d \theta_i\frac{1}{10000^\frac{2i}{d}} θi10000d2i1 2、LLaMA中RoPE源码 import torchdef precompute_freqs_cis(dim: int, end: i…...

在c++ 20下使用微软的proxy库替代传统的virtual动态多态
传统的virtual动态多态,经常会有下面这样的使用需求: #include <iostream> #include <vector>// 声明一个包含virtual虚函数的基类 struct shape {virtual ~shape() {}virtual void draw() 0; };// 派生,实现virtual虚函数 str…...

Spring MVC:@RequestMapping
Spring MVC RequestMapping属性 RequestMapping RequestMapping, 是 Spring Web 应用程序中最常用的注解之一,主要用于映射 HTTP 请求 URL 与处理请求的处理器 Controller 方法上。使用 RequestMapping 注解可以方便地定义处理器 Controller 的方法来处…...
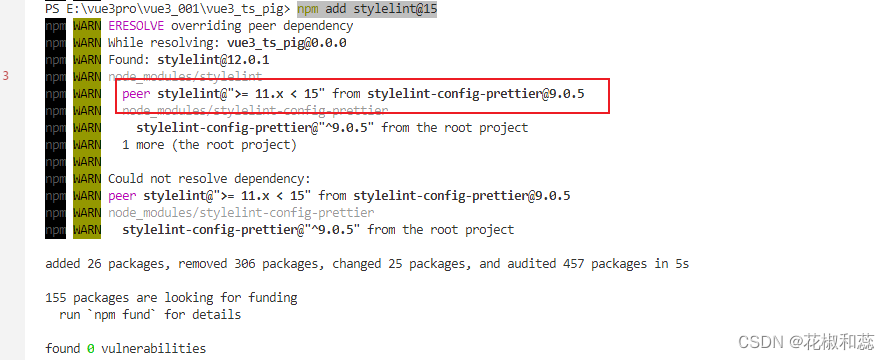
【vue3+ts项目】配置eslint校验代码工具,eslint+prettier+stylelint
1、运行好后自动打开浏览器 package.json中 vite后面加上 --open 2、安装eslint npm i eslint -D3、运行 eslint --init 之后,回答一些问题, 自动创建 .eslintrc 配置文件。 npx eslint --init回答问题如下: 使用eslint仅检查语法&…...

PHP之ZipArchive打包压缩文件
1、Linux 安装 nginx 安装zlib库 2、使用,目前我这边的需求是。 1、材料图片、单据图片,分别压缩打包到“材料.zip”和“单据.zip”。 2、“材料.zip”和“单据.zip”在压缩打包到“订单.zip” 3、支持批量导出多个订单的图片信息所有订单的压缩文件&…...

面试之快速学习C++14
文章参考:https://zhuanlan.zhihu.com/p/588826142?utm_id0 最近学了一会感慨到找工作好难,上周面试了一家医疗公司,准备攒攒经验但是不去,结果三天了没消息,感觉一面都没过… 本来自傲看不上,结果人家也…...
【算法专题突破】双指针 - 快乐数(3)
目录 1. 题目解析 2. 算法原理 3. 代码编写 写在最后: 1. 题目解析 题目链接:202. 快乐数 - 力扣(Leetcode) 这道题的题目也很容易理解, 看一下题目给的示例就能很容易明白, 但是要注意一个点&#…...
【javaweb】学习日记Day4 - Maven 依赖管理 Web入门
目录 一、Maven入门 - 管理和构建java项目的工具 1、IDEA如何构建Maven项目 2、Maven 坐标 (1)定义 (2)主要组成 3、IDEA如何导入和删除项目 二、Maven - 依赖管理 1、依赖配置 2、依赖传递 (1)查…...

C++信息学奥赛1144:单词翻转
#include <iostream> #include <string> using namespace std; int main() {string str;// 输入一行字符串getline(cin, str);string arr;for (int i 0; i < str.length(); i){if (str[i] ! ){arr str[i]; // 将非空格字符添加到临时存储的字符串中}else{for…...

qt检查文件夹是否有写权限
Qt 使用如下函数能够判断路径或者文件是否可写: bool QFileInfo::isWritable() const 对于win10系统实测,结果不准确。继续排查,官方文档描述:a)如果未启用 NTFS 权限检查,Windows 上的结果将仅反映文件是…...
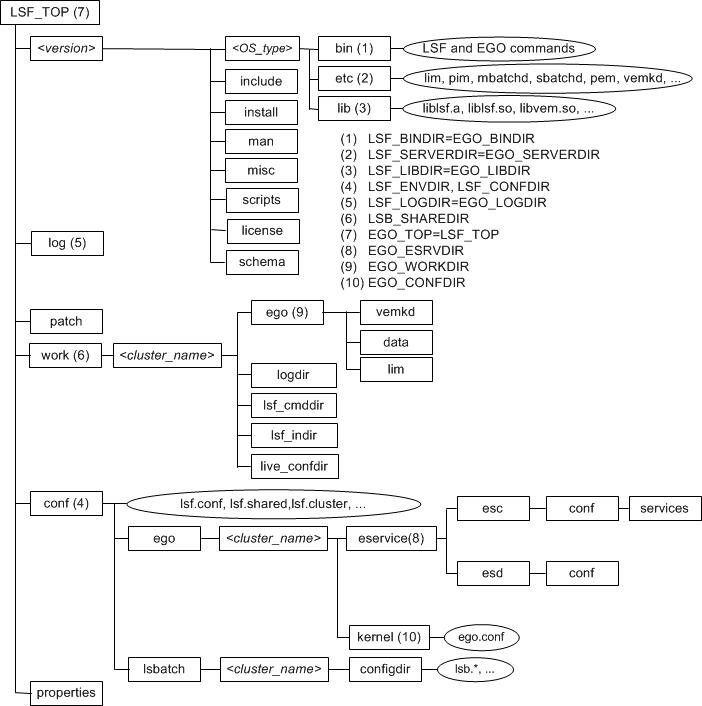
LSF 安装目录,快速参考 LSF 命令、守护程序、配置文件、日志文件和重要集群配置参数
样本 UNIX 和 Linux 安装目录 守护程序错误日志文件 守护程序错误日志文件存储在 LSF_LOGDIR 在 lsf.conf 文件中定义的目录中。 LSF 基本系统守护程序日志文件LSF 批处理系统守护程序日志文件pim.log.host_namembatchd.log.host_namembatchd.log.host_namesbatchd.log.host_…...
)
从下载到网页管理:TrueNAS SCALE最新版保姆级安装图文教程(VMware Workstation 17环境)
TrueNAS SCALE在VMware Workstation 17中的全流程部署指南 对于需要在本地环境中快速搭建网络存储测试平台的用户来说,TrueNAS SCALE无疑是一个理想选择。作为TrueNAS家族的最新成员,它不仅继承了传统存储管理系统的稳定性和可靠性,还引入了…...

LLM推理解耦技术:提升大型语言模型推理效率的关键方法
1. LLM推理解耦技术概述在大型语言模型(LLM)推理服务领域,推理解耦(Inference Disaggregation)正成为突破传统性能瓶颈的关键技术路径。这项技术的核心思想是将原本耦合的推理流程拆分为具有不同计算特征的独立阶段&am…...

双线性系统与RNN架构演进:从理论到实践
1. 双线性系统基础与RNN架构演进 双线性系统作为控制理论中的重要模型类别,其数学本质是状态变量与控制输入的乘积项构成的动态系统。这类系统在形式上可以表示为: dx/dt Ax Bu Nxu y Cx Du其中Nxu项就是典型的双线性耦合项。这种结构在保持线性系…...

Atomic Layout高级技巧:使用Query函数实现自定义媒体查询
Atomic Layout高级技巧:使用Query函数实现自定义媒体查询 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout是一个基于React的声明…...

别再手动下载DLL了!用Windows自带工具SFC/SCANNOW一键修复kernel32.dll错误
别再手动下载DLL了!用Windows自带工具SFC/SCANNOW一键修复kernel32.dll错误当电脑屏幕上突然弹出"无法定位程序输入点kernel32.dll"的红色警告框时,大多数人的第一反应是打开浏览器搜索"如何下载kernel32.dll"。这个看似合理的操作背…...

物理生物学研究报告【20260015】
文章目录抛球入框实验报告一、实验目的二、实验装置三、实验方法四、实验结果4.1 无弹跳实验(A组)4.2 允许弹跳实验(B组)五、分析与讨论5.1 无弹跳与弹跳的参数差异5.2 恢复系数的影响5.3 误差来源六、结论七、致谢抛球入框实验报…...

从‘看山是山’到‘看山不是山’:手把手教你用Landsat8波段组合玩转地物‘透视’
给地球戴上X光眼镜:Landsat8波段组合的视觉魔法手册第一次接触遥感影像的人,常会惊讶于同一片土地在不同"滤镜"下竟能呈现截然不同的面貌——茂密的森林在某张图上如火炬般鲜红耀眼,在另一张图中却消失不见;平静的湖面时…...

FPG平台:行业前景下的战略定位评估
FPG平台:行业前景下的战略定位评估金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。FPG平台经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行多维度的…...

云原生事件驱动架构:构建高效的事件处理系统
云原生事件驱动架构:构建高效的事件处理系统 引言 在云原生环境中,事件驱动架构是一种高效的系统设计模式。通过事件驱动,可以实现松耦合、高可用的系统。事件驱动架构已经成为构建现代化应用的重要方法。 作为一名资深的DevOps工程师&#x…...

Flutter Widgets组件详解:从基础到高级
Flutter Widgets组件详解:从基础到高级 一、Widget基础概念 在Flutter中,一切都是Widget。Widget是Flutter应用的基本构建块,它们描述了UI在某个特定时刻的外观。Flutter的Widget树是应用界面的核心结构。 1.1 Widget的分类 Flutter Widget主…...