大数据——一文熟悉HBase
1、HBase是什么
HBase是基于HDFS的数据存储,它建立在HDFS文件系统上面,利用了HDFS的容错能力,内部还有哈希表并利用索引,可以快速对HDFS上的数据进行随时读写功能。

Hadoop在已经有一个Hive+MapReduce结构的数据读写功能,为什么还要HBase呢?我们在使用Hive的过程中也发现,MapReduce的过程很慢,不适合实时的读写访问,更多的时候是进行线下的访问。但在实际应用过程中,我们需要对大数据进行实时的读写,这时候HBase就派上用场。
HBase使用场景:
HBase适合在瞬间写入量大,大量数据需要长期保存,并且数量会持续增长的场景。但在多级索引和关系复杂的数据模型,还有跨行事务场景也不适合HBase。
2、HBase怎么工作
HBase基础架构

Client
- 与Zookeeper进行通信,获取数据入口地址;
- 与HMaster通信进行管理类操作;
- 与HRegionServer进行数据读写操作。
Zookeeper
- 避免单点问题,一直只有running master;
- 存储所有Region的地址,包括HMaster地址;
- 监控HRegionServer的状态,并告知HMaster;
- 存储Table名和Column Family
HMaster
- 有多个HMaster,通过Zookeeper保证有一个在运行;
- 为HRegionServer分类Region;
- 有HRegionServer失效,重新分配;
- 对HDFS的垃圾文件进行回收;
- 处理用户对表的增删改查操作;
HRegionServer
- HBase核心部分,负责I/O请求,并先HDFS读写数据;
- 维持HMaster分配的Region,并处理Region的I/O请求;
- 切分在运行过程中变大的Region;
- HRegionServer中有一系列HRegion对象,每个HRegion对应Table中的一个Region,每个HRegion由多个Store组成,每个HStore对应Table中的Column Family。
Column Family是HBase的存储单元,所以相同特性的Column放在一个Column Family更高效。
HStore
- HBase存储的核心,由MemStore和StoreFile组成;
HRegion
- 一个Table最开始的时候是一个Region;
- 一个Region可以有多个Store,每个Store用来存储一个Column Family;
- Region随着数据的越来越多,会进行拆分,由HRegionServer进行拆分,默认大小为10G。
HLog
- 备份和日志,在系统出错和宕机时,MemStore的数据会丢失,而HLog可以防止该情况。
HBase写数据流程

HBase数据模型
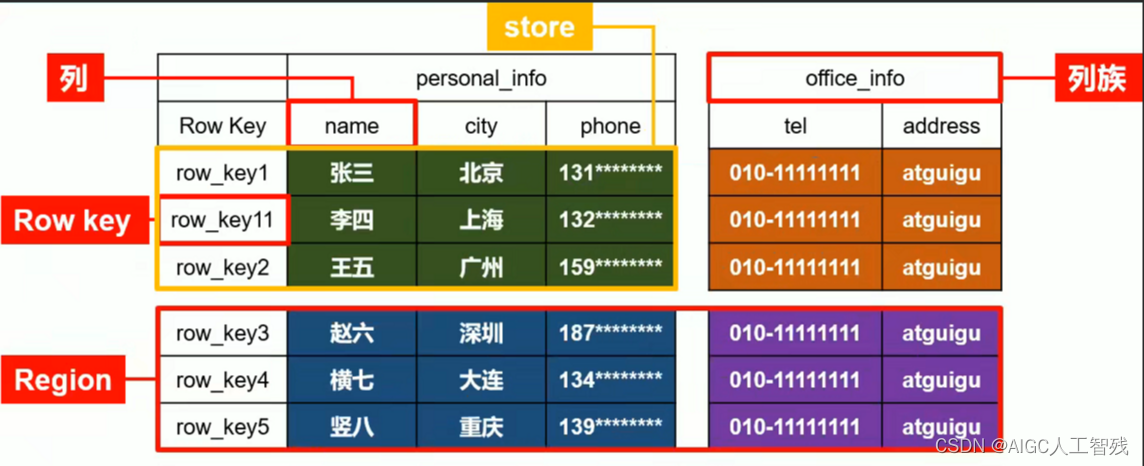
- NameSpace:数据库的库名;
- Table表:HBase的表,由于对于值为空的列不占空间,因此表可以比较稀疏;
- Row行:每一行都有一个RowKey来进行识别;
- RowKey行键:类似于MySQL中的主键,用来进行检索数据;
- Column列:由Column family和Column qualifier组成,两者用;进行间隔;
- ColumnFamily列族:列的集合,每个表的列族都以一个文件存储,一个表可以有多个列族;
- ColumnQualifier列标识:类似于键值对,key是RowKey,那么ColumnQualifier就是Value;
- TimeStamp时间戳:是具有时间属性的列,每个数据都有一个时间戳属性,也就是说数据具有版本特性;
- Region区域:HBase可以自动把表划分为多个区域,随着数据的增多区域也变多。
3、HBase的Shell操作
- HBase启动
找到zkServer.sh启动Zookeeper
zkServer.sh start
启动HBase
start-hbase.sh
- HBase常见Shell操作
连接集群
hbase shell
创建表
create 'user','base_info'# 第一个为表名,第二个为列族
删除表
disable 'user'
drop 'user'
创建数据库
create_namespace 'test' #test为数据库名
展示所有数据库
list_namespace
显示表
list
插入数据
put ‘表名’,‘rowkey的值’,’列族:列标识符‘,’值‘
put 'user','rowkey_10','base_info:username','Tom'
查询表中所有数据
scan 'user' # 很少使⽤全表查询 scan会加上⼀些条件限制
Scan查询中添加限制条件
scan '名称空间:表名', {COLUMNS => ['列族名1', '列族名2'], LIMIT => 10, STARTROW =>'起始的rowkey'}
scan查询添加过滤器
ROWPREFIXFILTER rowkey 前缀过滤器
scan 'user', {ROWPREFIXFILTER=>'rowkey_22'}
查询某个rowkey的数据
get 'user','rowkey_16'
删除表中的数据
delete 'user', 'rowkey_16', 'base_info:username'
清空数据
truncate 'user'
指定显示多个版本
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>2}
修改可以显示的版本数量
alter 'user',NAME=>'base_info',VERSIONS=>10
通过TIMERANGE 指定时间范围
scan 'user',{COLUMNS => 'base_info', TIMERANGE => [1558323139732,1558323139866]}
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>2,TIMERANGE=> [1558323904130, 1558323918954]}
通过时间戳过滤器 指定具体时间戳的值
scan 'user',{FILTER => 'TimestampsFilter (1558323139732, 1558323139866)'}
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>2,FILTER =>'TimestampsFilter (1558323904130, 1558323918954)'}
获取最近多个版本的数据
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>10}
通过指定时间戳获取不同版本的数据
get 'user','rowkey_10',
{COLUMN=>'base_info:username',TIMESTAMP=>1558323904133}
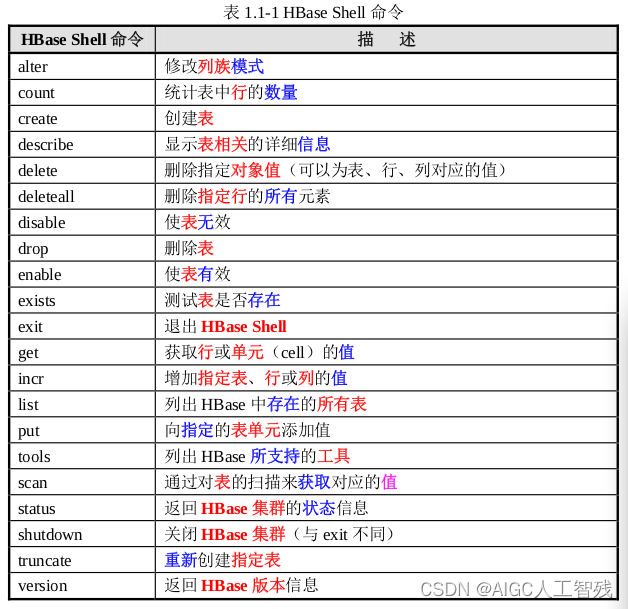
命令表
相关文章:
大数据——一文熟悉HBase
1、HBase是什么 HBase是基于HDFS的数据存储,它建立在HDFS文件系统上面,利用了HDFS的容错能力,内部还有哈希表并利用索引,可以快速对HDFS上的数据进行随时读写功能。 Hadoop在已经有一个HiveMapReduce结构的数据读写功能&#x…...

如何有效进行RLHF的数据标注?
编者按:随着大语言模型在自然语言处理领域的广泛应用,如何从人类反馈进行强化学习(RLHF)已成为一个重要的技术挑战。并且RLHF需要大量高质量的人工数据标注,这是一个非常费力的过程。 本文作者在数据标注领域具有丰富经…...

2023年8月22日OpenAI推出了革命性更新:ChatGPT-3.5 Turbo微调和API更新,为您的业务量身打造AI模型
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
windows配置wsl,Unbuntu启动GPU加速
wsl全称Windows Subsystem for Linux,windows电脑下的linux子系统,对于想用Linux的Windows用户来说wsl是一个不错的选择。 安装wsl 两种方法可以安装wsl,这个默认安装在C盘。 方法一运行命令安装 wsl --install方法二,在windo…...

Postman测WebSocket接口
01、WebSocket 简介 WebSocket是一种在单个TCP连接上进行全双工通信的协议。 WebSocket使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直…...
【内网穿透】搭建我的世界Java版服务器,公网远程联机
目录 前言 1. 搭建我的世界服务器 1.1 服务器安装java环境 1.2 配置服务端 2. 测试局域网联机 3. 公网远程联机 3.1 安装cpolar内网穿透 3.1.1 windows系统 3.1.2 linux系统(支持一键自动安装脚本) 3.2 创建隧道映射内网端口 3.3 测试公网远程…...

Unable to Locate package python2| Linux Ubuntu系统下python2的安装
Linux Ubuntu系统下python2的安装 FSL的安装脚本是用Python2写的,新版本的Ubuntu (16以后)在默认情况下没有安装Python2。在终端输入 python2,若提示没有相应的命令,则需要先安装Python2,如下指令…...
)
从上帝视角俯瞰vue2路由(简单易懂)
文章目录 路由原理(hash)路由安装和使用(vue2)路由跳转路由的传参和取值嵌套路由路由守卫完整代码 路由原理(hash) 单页应用的路由模式有两种 哈希模式(利用hashchange 事件监听 url的hash 的…...

STL-空间配置器的了解
前言 空间配置器,顾名思义就是为了各个容器高效的管理空间(空间的申请与回收)的,在默默的工作的。虽然在常规上使用STL时,可能用不上它,但是站在学习研究的角度,学习它的实现原理对我们有很大的…...
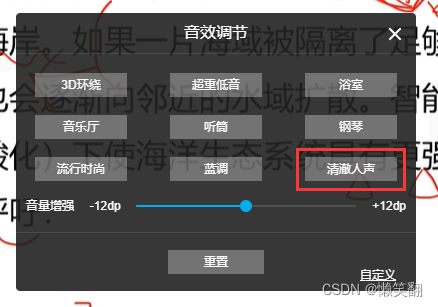
哔哩哔哩 B站 bilibili 视频视频音效调节 清澈人声
视频音效调节方式:直接视频播放内容界面内鼠标右键点击视频音效调节 注意:需要使用的是谷歌浏览器,我的火狐浏览器试了不行,都没选项,火狐的出来的界面是这样的: 目录 具体操作如下: 1、谷歌…...

下一代存储解决方案:湖仓一体
文章首发地址 湖仓一体是将数据湖和数据仓库相结合的一种数据架构,它可以同时满足大数据存储和传统数据仓库的需求。具体来说,湖仓一体可以实现以下几个方面的功能: 数据集成: 湖仓一体可以集成多个数据源,包括结构…...

IntelliJ IDEA 2023.2.1 修复版本日志
我们刚刚发布了 v2023.2 的第一个错误修复更新。 您可以从 IDE 内部、使用工具箱应用程序或通过快照(如果您使用的是 Ubuntu)更新到此版本。您也可以直接从我们的网站下载。 以下是最新版本中包含的最值得注意的改进和修复的列表: 我们已经解…...

算法通关村十三关 | 数组字符串加法专题
1. 数组实现整数加法 题目:LeetCode66,66. 加一 - 力扣(LeetCode) 思路 我们只需要从头到尾依次运算,用常量标记是否进位,需要考虑的特殊情况是digits [9,9,9]的时候进位,我们组要创建长度加1…...

k8s--基本概念理解
必填字段 在要创建的 Kubernetes 对象的文件中.yaml,您需要设置以下字段的值: apiVersion- 您使用哪个版本的 Kubernetes API 创建此对象 kind- 你想创建什么样的对象 metadata- 有助于唯一标识对象的数据,包括name字符串、UID和可选namesp…...

流媒体开发千问【持续更新】
H.264中IDR帧和I帧区别 H.264/AVC编码标准中,IDR帧和I帧都是关键帧,即它们都不依赖于其他帧进行解码。但是,它们之间存在明确的区别: 定义与功能: I帧(Intra-frame):I帧是一个内部编…...

全球各国官方语言大盘点,英语不得不学哇。。。
因国家和地区范围界定不同,官方语言只是个相对概念。具体而言是一个国家通用的正式语言或认定的正式语言。它是为适应管理国家事务的需要,在国家机关、正式文件、法律裁决及国际交往等官方场合中规定一种或几种语言为有效语言的现象。官方语言也是一个国…...
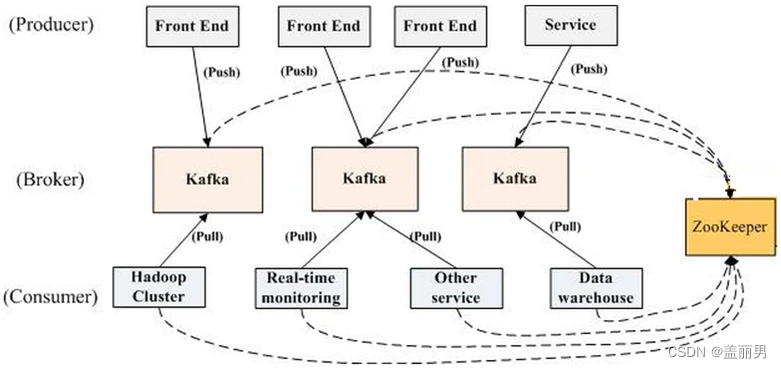
【mq】如何保证消息可靠性
文章目录 mq由哪几部分组成rocketmqkafka 为什么需要这几部分nameserver/zookeeper可靠性 broker可靠性 生产者消费者 mq由哪几部分组成 rocketmq kafka 这里先不讨论Kafka Raft模式 比较一下,kafka的结构和rocketmq的机构基本上一样,都需要一个注册…...
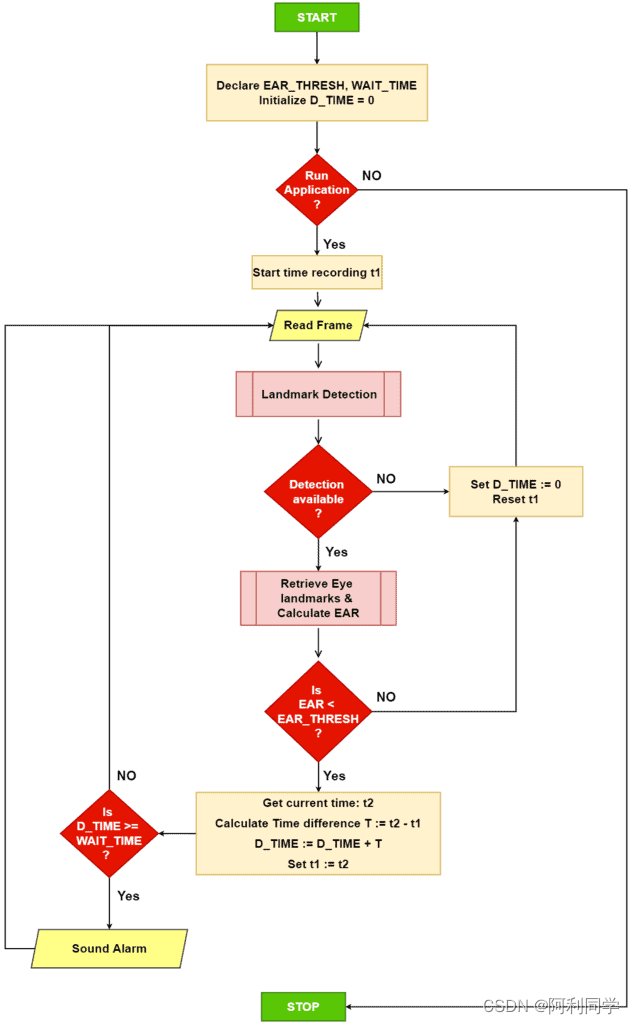
疲劳检测-闭眼检测(详细代码教程)
简介 瞌睡经常发生在汽车行驶的过程中,该行为害人害己,如果有一套能识别瞌睡的系统,那么无疑该系统意义重大! 实现步骤 思路:疲劳驾驶的司机大部分都有打瞌睡的情形,所以我们根据驾驶员眼睛闭合的频率和…...

大数据日常运维命令
1、HDFS NameNode /usr/local/fqlhadoop/hadoop/sbin/hadoop-daemon.sh start namenode /usr/local/fqlhadoop/hadoop/sbin/hadoop-daemon.sh stop namenode bin/hdfs haadmin -DFSHAAdmin -getServiceState n1 2、HDFS DataNode /usr/local/fqlhadoop/hadoop/sbin/hadoop-…...

解锁安全高效办公——私有化部署的WorkPlus即时通讯软件
在当今信息时代,高效的沟通与协作对于企业的成功至关重要。然而,随着信息技术的发展,保护敏感信息和数据安全也变得越来越重要。为了满足企业对于安全沟通和高效办公的需求,我们隆重推出私有化部署的WorkPlus即时通讯软件…...

专业级英雄联盟回放分析工具:ROFL-Player完整实战指南
专业级英雄联盟回放分析工具:ROFL-Player完整实战指南 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款专为…...

从百元平板到AIoT:成本极致化下的电子设计哲学与职业未来
1. 从百元平板之争看电子设计的未来走向那天在门洛帕克的星巴克,Vivek Wadhwa迟到了几分钟,一坐下就带着那种即将沸腾的能量感切入正题:“我最近好像总在惹麻烦!”他指的麻烦,是那些关于创新、关于价格、关于行业未来的…...

LaTeX公式一键转Word:告别繁琐复制,提升学术写作效率
LaTeX公式一键转Word:告别繁琐复制,提升学术写作效率 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为将网页上的数…...

优化敏感焦虑型依恋
用几个学科的顶层思维,把你的问题重新教育一遍:你不是要“变得迟钝”,你是要完成一次升级:从“敏感地寻找危险”,升级为“敏锐地识别规律”。 从“害怕失去关系”,升级为“有能力经营关系”。 从“被情绪牵…...

UCC25600 LLC谐振变换器:从补偿网络设计到软启动与过流保护的实战调试
1. UCC25600 LLC谐振变换器入门指南 第一次接触LLC谐振变换器时,我被它的高效和低EMI特性吸引,但真正用UCC25600做项目时才发现理论和实操差距不小。这款德州仪器的控制器确实强大,但要把它的性能完全发挥出来,得先理解几个关键点…...

AMD Ryzen终极性能调优秘籍:5个高效调试技巧让你完全掌控处理器性能
AMD Ryzen终极性能调优秘籍:5个高效调试技巧让你完全掌控处理器性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...
)
STM32F4的DSP库怎么在CLion里用起来?保姆级CMake配置指南(含FPU开启)
STM32F4的DSP库在CLion中的完整CMake配置指南(含FPU优化) 第一次在CLion里看到STM32的DSP库报错时,我盯着满屏的"undefined reference"发了半小时呆。作为从Keil转战CLion的老嵌入式开发者,我太清楚DSP库在信号处理项目…...

极简终端AI聊天工具gptcli:单文件Python脚本实现OpenAI API兼容客户端
1. 项目概述:一个极简的终端AI聊天工具如果你和我一样,经常需要在终端里和AI模型对话,但又觉得官方网页版太重、第三方客户端功能太杂,那么这个项目可能就是你的菜。gptcli是一个用单个Python脚本实现的、功能纯粹的终端聊天客户端…...

Kubernetes部署Dify AI平台:从Docker Compose到K8s原生YAML完整迁移指南
1. 项目概述与核心价值最近在折腾AI应用开发平台,发现Dify这个工具确实挺有意思,它把大模型应用开发的门槛降得很低。不过,官方主要提供了Docker Compose的部署方式,对于已经将生产环境全面容器化、并且用上了Kubernetes的团队来说…...

oh-my-opencode:AI编程操作系统,智能体编排与哈希锚定编辑实战
1. 项目概述:一个为AI编程而生的“操作系统”如果你和我一样,在过去一年里深度使用过Claude Code、Cursor或者各种开源的AI编程工具,那你一定经历过这种痛苦:模型选型让人眼花缭乱,配置流程复杂到让人想放弃࿰…...