在 Python 中构建卷积神经网络; 从 0 到 9 的手绘数字的灰度图像预测数字

一、说明
为了预测从0到9的数字,我选择了一个基于著名的Kaggle的MNIST数据集的数据集。数据集包含从 <0> 到 <9> 的手绘图数字的灰度图像。在本文中,我将根据像素数据(即数值数据)和卷积神经网络预测数字。
二、 卷积神经网络
卷积神经网络,也称为 CNN 或 ConvNet,是一种人工神经网络,迄今为止最常用于分析计算机视觉任务的图像。
尽管图像分析是CNNS最广泛的用途,但它们也可用于其他数据分析或分类。让我们开始吧!
一般来说,我们可以将CNN视为一种人工神经网络,它具有某种类型的专业化,能够挑选或检测模式。这种模式检测使CNN在图像分析中如此有用。
但是,如果CNN只是一个人工神经网络,那么它与标准的多层感知器或MLP有什么区别呢?
CNN有称为卷积层的隐藏层,这些层是构成CNN的,嗯......一个美国有线电视新闻网!
CNN具有称为卷积层的层。
CNN可以,而且通常也有其他非卷积层,但CNN的基础是卷积层。
好的,那么这些卷积层是做什么的呢?
就像任何其他层一样,卷积层接收输入,以某种方式转换输入,然后将转换后的输入输出到下一层。卷积层的输入称为输入通道,输出称为输出通道。
对于卷积层,发生的转换称为卷积操作。无论如何,这是深度学习社区使用的术语。在数学上,卷积层执行的卷积运算实际上称为互相关。
如前所述,卷积神经网络能够检测图像中的模式。
让我们扩展一下我们的意思 当我们说过滤器能够检测模式时。想想任何单个图像中可能发生了什么。多个边缘、形状、纹理、对象等。这就是我们所说的模式。
- 边缘
- 形状
- 纹理
- 曲线
- 对象
- 颜色
滤波器可以在图像中检测到的一种图案是边缘,因此该滤波器称为边缘检测器。
除了边缘之外,某些过滤器可能会检测到角落。有些人可能会检测到圆圈。其他,正方形。现在这些简单的几何滤波器 就是我们在卷积神经网络开始时看到的。
网络越深入,过滤器就越复杂。在后面的图层中,我们的过滤器可能能够检测特定的物体,而不是边缘和简单的形状,如眼睛、耳朵、头发或毛皮、羽毛、鳞片和喙。
在更深的层中,过滤器能够检测到更复杂的物体,如完整的狗、猫、蜥蜴和鸟类。
三、 数据理解

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
import itertools
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Dropout, Flatten, MaxPooling2D
import osdf = pd.read_csv("MNIST_ROI.csv")3.1 探索性分析
df.shape(59999, 785)
数据集包括 59,999 条记录和 785 个字段。每条记录代表手绘图数字的灰度图像,介于 0 到 9 之间。
第一列称为“结果”,是用户绘制的数字。
其余列包含关联图像的像素值。每个灰度图像的高度为 28 像素,宽度为 28 像素,总共 784 像素。
df.head()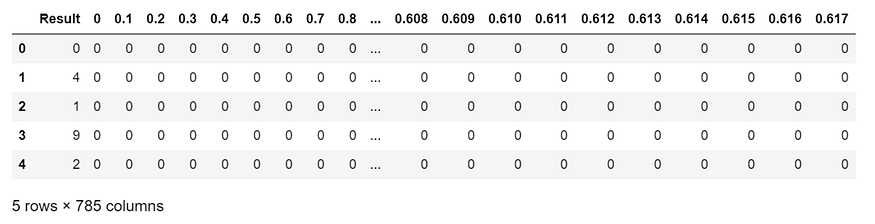
每个像素都有一个与之关联的像素值,指示该像素的明暗度,数字越大意味着越亮。此像素值是介于 0(黑色)和 255(白色)之间的整数(包括 <>(黑色)和 <>(白色)。
df.tail()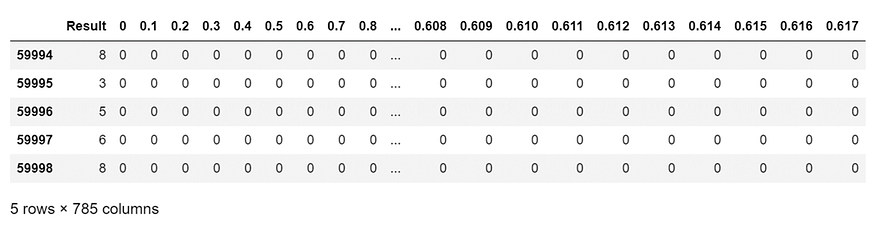
df.info()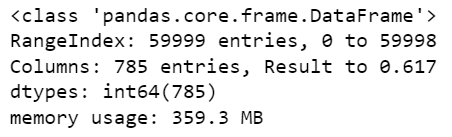
df.describe()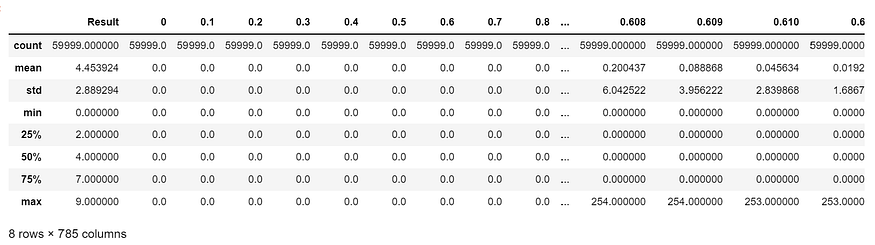
3.2 数据分析
让我们检查数据集中每个数字有多少张图像
dig = [0,1,2,3,4,5,6,7,8,9]
num = []
for i in range(0,10):num.append(len(df[df['Result']==i]))d = {'Digit': dig, 'Count': num}
df1 = pd.DataFrame(data=d)
df1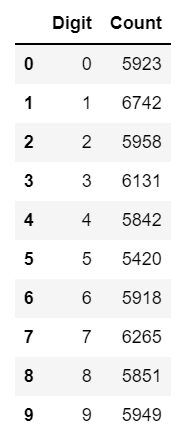
import matplotlib.pyplot as plt
import seaborn as sns
sns.barplot(x = “Count”, y = “Digit”, data = df2, orient=’h’)
plt.show()
让我们看看数据集中的哪些行中有数字“3”的图像
df[df[‘Result’]==3].head()
让我们打印第 6 行的图像
pic = df[6:7].values.reshape(785)[1:].reshape(28,28)
plt.imshow(pic,cmap='gray')
让我们看看数据集中的哪些行中有数字“5”的图像
df[df[‘Result’]==5].head()
让我们打印第 10 行的图像
pic = df[10:11].values.reshape(785)[1:].reshape(28,28)
plt.imshow(pic,cmap=’gray’)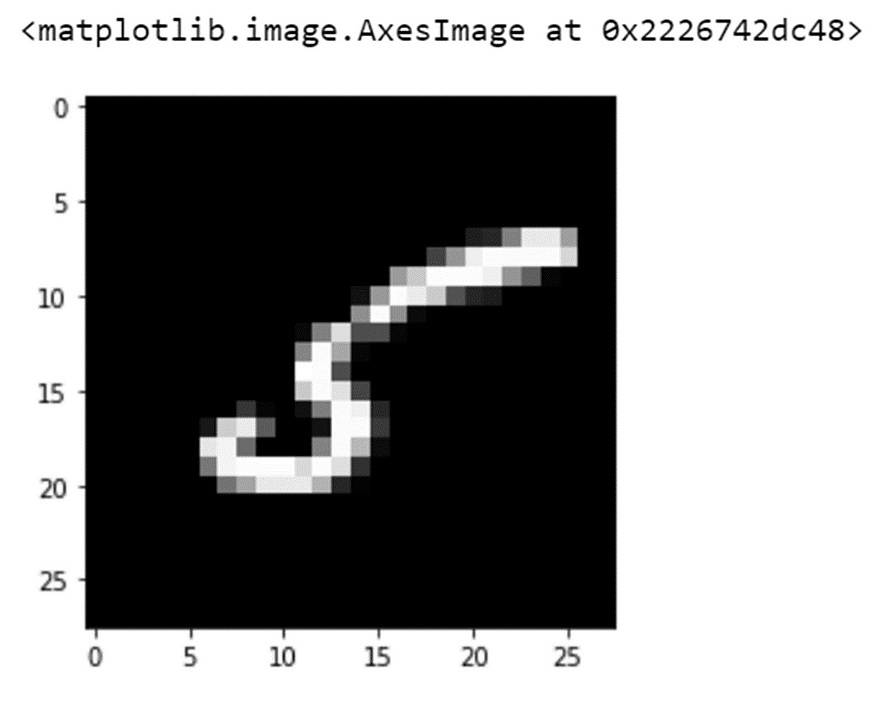
四、数据准备

X = df.drop(['Result'],axis=1)X.head() 
y = df.Resulty.head() 
import sklearn.model_selection as skmodelX_train, X_test, y_train, y_test = skmodel.train_test_split(X, y, test_size=0.33, random_state=42)print("length of all data is ","{:,}".format(len(X)))
print("length of training set is","{:,}".format(len(X_train)))
print("length of test set is","{:,}".format(len(X_test))) 
X_train.head()
y_train.head()
让我们将训练集和测试集从 pandas.core.frame.DataFrame 转换为 numpy.ndarray
x_train = np.array(X_train)
y_train = np.array(y_train)
x_test = np.array(X_test)
y_test = np.array(y_test)len(X_train)40199
让我们画一个介于 0 到 40199 之间的数字
i = random.randint(0,(len(X_train)))
i34944
现在,让我们打印训练集中第 34944 行的图像结果
print(y_train[i])3
让我们打印训练集中第 34944 行的图像
pic = X_train.iloc[i].values.reshape(28,28)plt.imshow(pic, cmap=’Greys’)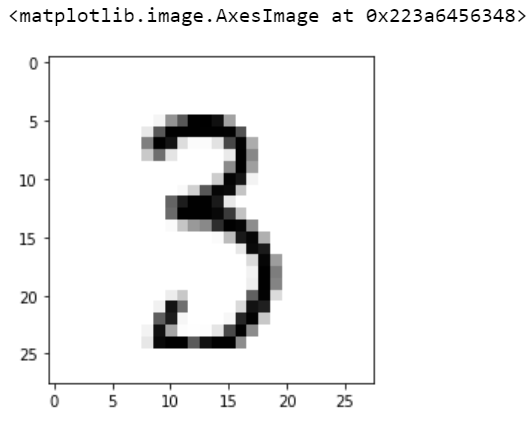
x_train.shape(40199, 784)
让我们将数组重塑为 4 个 dimnsions,以便它可以与 Keras API 一起使用
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
input_shape = (28, 28, 1)让我们确保值是浮点数的,以便我们可以在除法后获得小数点
x_train = x_train.astype('float32')
x_test = x_test.astype('float32') 现在,让我们通过将 RGB 代码除以最大 RGB 值来规范化 RGB 代码
x_train /= 255
x_test /= 255print('x_train shape:', x_train.shape)
print('Number of images in x_train', x_train.shape[0])
print('Number of images in x_test', x_test.shape[0])
五、建模

让我们使用顺序模型构建一个 CNN 并添加层:
model = Sequential()
model.add(Conv2D(28, kernel_size=(3,3), input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # Flattening the 2D arrays for fully connected layers
model.add(Dense(128, activation=tf.nn.relu))
model.add(Dropout(0.2))
model.add(Dense(10,activation=tf.nn.softmax))让我们编译我们的CNN
model.compile(optimizer=’adam’, loss=’sparse_categorical_crossentropy’, metrics=[‘accuracy’])现在,让我们训练我们的CNN
model.fit(x=x_train,y=y_train, epochs=10)
训练集准确率:99.37%
model.evaluate(x_test, y_test)
测试装置准确率:98.22%
训练集的准确率为 99.37%,而测试集的准确率为 98.22%。这表明卷积神经网络(CNN)很好地推广到新数据,而不是过度拟合。
六、评估
len(X_test)19800
让我们画一个介于 0 到 19800 之间的数字
j = random.randint(0,(len(X_test)))
j11092
现在,让我们对测试集中第 11092 行的图像结果进行预测
pred = model.predict(x_test[j].reshape(1, 28, 28, 1))print(pred.argmax())6
让我们打印测试集中第 11092 行的图像
pic1 = X_test.iloc[j].values.reshape(28,28)
plt.imshow(pic1, cmap='Greys')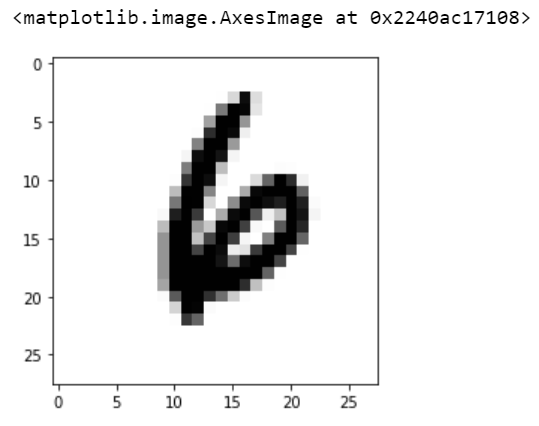
y_pred = model.predict(x_test)
y_pred = np.argmax(y_pred,axis=1)
y_pred.shape(19800, )
6.1 混淆矩阵
import sklearn.metrics as skmetcm = skmet.confusion_matrix(y_true=y_test, y_pred=y_pred)def plot_confusion_matrix(cm, classes,normalize=False,title=’Confusion matrix’,cmap=plt.cm.Blues):“””This function prints and plots the confusion matrix.Normalization can be applied by setting `normalize=True`.“””plt.imshow(cm, interpolation=’nearest’, cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)print(‘Confusion matrix, without normalization’)
print(cm)
thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment=”center”,color=”white” if cm[i, j] > thresh else “black”)
plt.tight_layout()
plt.ylabel(‘True label’)
plt.xlabel(‘Predicted label’)cm_plot_labels = [‘0’,’1',’2',’3',’4',’5',’6',’7',’8',’9']plot_confusion_matrix(cm=cm, classes=cm_plot_labels, title=’Confusion Matrix’)
print(“\033[1m The result is telling us that we have: “,(cm[0,0]+cm[1,1]+cm[2,2]+cm[3,3]+cm[4,4]+cm[5,5]+cm[6,6]+cm[7,7]+cm[8,8]+cm[9,9]),”correct predictions.”)
print(“\033[1m The result is telling us that we have: “,(cm.sum()-(cm[0,0]+cm[1,1]+cm[2,2]+cm[3,3]+cm[4,4]+cm[5,5]+cm[6,6]+cm[7,7]+cm[8,8]+cm[9,9])),”incorrect predictions.”)
print(“\033[1m We have total predictions of: “,(cm.sum()))
6.2 计算精度、召回率、f 分数和支持
引用Scikit Learn的话:
精度是比率 tp / (tp + fp),其中 tp 是真阳性数,fp 是误报数。精度直观地是分类器在样本为阴性时不将其标记为阳性的能力。
召回率是比率 tp / (tp + fn),其中 tp 是真阳性的数量,fn 是假阴性的数量。召回率直观地是分类器找到所有阳性样本的能力。
f1 分数可以解释为精度和召回率的加权调和平均值,其中 f1 分数在 1 达到其最佳值,在 0 时达到最差分数。
f1 分数将召回率的权重比精度高 1.0 倍,这意味着召回率和精度同样重要。
支持是每个类在y_test中的出现次数。
print(skmet.classification_report(y_test, y_pred))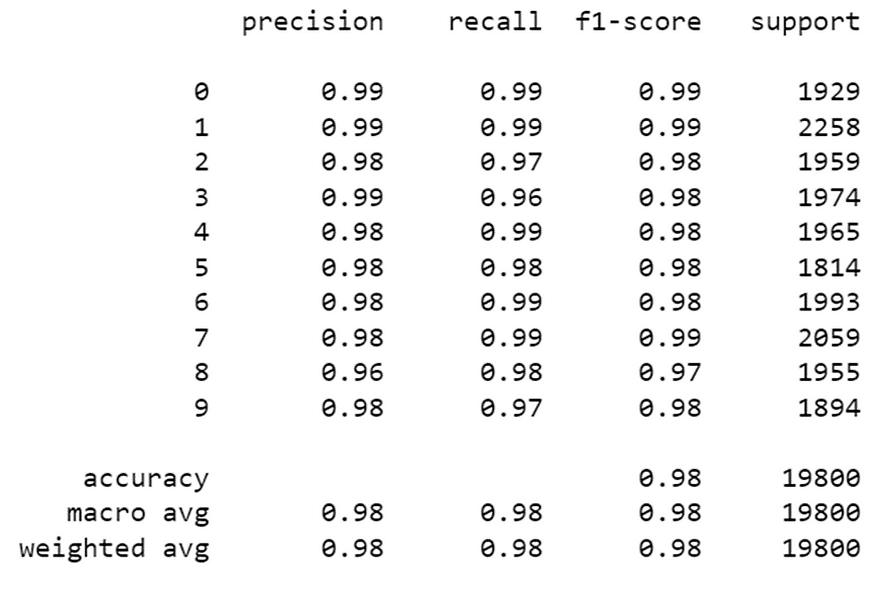
七、部署
因此,我们的卷积神经网络(CNN)模型是一个很好的模型,可以从0到9的手绘数字的灰度图像中预测数字。现在,我们如何从新的灰度图像中预测数字?
len(X_test)19800
让我们画一个介于 0 到 19800 之间的数字
k = random.randint(0,(len(X_test)))
k766
让我们使用我们的模型预测来自 pred1 的数字
pred1 = model.predict(x_train[k].reshape(1, 28, 28, 1))
print(pred1.argmax())7
我们的模型说我们画了一个数字“7”的图像。因此,让我们打印此图像以查看我们的模型是否正确
pic2 = X_train.iloc[k].values.reshape(28,28)
plt.imshow(pic2, cmap='Greys')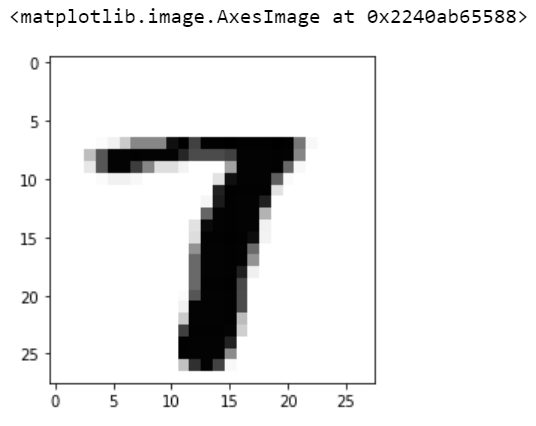
是的!我们的模型是正确的。
八、总结
卷积神经网络(ConvNet/CNN)是一种深度学习算法,可以接收输入图像,为图像中的各个方面/对象分配重要性(可学习的权重和偏差),并能够区分彼此。
卷积神经网络的架构类似于人脑中神经元的连接模式,并受到视觉皮层组织的启发。
单个神经元仅在称为感受野的视野的受限区域中对刺激做出反应。
此类字段的集合重叠以覆盖整个视觉区域。
相关文章:
在 Python 中构建卷积神经网络; 从 0 到 9 的手绘数字的灰度图像预测数字
一、说明 为了预测从0到9的数字,我选择了一个基于著名的Kaggle的MNIST数据集的数据集。数据集包含从 <0> 到 <9> 的手绘图数字的灰度图像。在本文中,我将根据像素数据(即数值数据)和卷积神经网络预测数字。 二、 卷积…...

前端分页处理
页面中实现的分页效果,要么后端提供接口,每次点击下一页就调用接口,若不提供接口,分页得前端自己去截取。 方法一:slice方法 slice(参数1,参数2)方法是返回一个新的数组对象,左开右闭 参数1&…...

【C语言】位操作符的一些题目与技巧
初学者在学完位操作符之后,总是不能很好的掌握,因此这篇文章旨在巩固对位操作符的理解与使用。 有的题目可能会比较难以接受,但是看完一定会有收获 目录 位操作符:一些题目:不创建临时变量交换整数整数转换二进制中1的…...
爬虫逆向实战(二十二)--某恩数据电影票房
一、数据接口分析 主页地址:某恩数据 1、抓包 通过抓包可以发现数据接口是API/GetData.ashx 2、判断是否有加密参数 请求参数是否加密? 无请求头是否加密? 无响应是否加密? 通过查看“响应”模块可以发现,响应是…...

火山引擎发布自研视频编解码芯片
2023年8月22日,火山引擎视频云宣布其自研的视频编解码芯片已成功出片。经验证,该芯片的视频压缩效率相比行业主流硬件编码器可提升30%以上,未来将服务于抖音、西瓜视频等视频业务,并将通过火山引擎视频云开放给企业客户。 火山引…...

投递技术类简历的注意事项
简历修改的背景 作为程序员,随着工作年限的增加,要定期的去修改自己的简历中的工作项目,一方面可以促进自己复盘一下工作成果和个人成长,另外也能给自己换工作提供一个前置的便捷性。 注意事项 修改简历的时候有哪些需要注意的…...
每日一题——柱状图中最大的矩形
柱状图中最大的矩形 题目链接 用什么数据结构? 要得到柱状图中最大的矩形,我们就必须要知道对于每一个高度heights[i],他所能勾勒出的矩形最大是多少(即宽度最大是多少)。 而对应到图上我们可以知道,要知…...

Banana Pi推出基于龙芯2K1000LA处理器的信创工业控制开发平台
Banana Pi推出基于龙芯2K1000LA处理器的信创工业控制开发平台:BPI-5202信创工业控制开发平台 BPI-5202 龙芯2K1000LA 信创工业控制开发平台 1.1 工控机的应用场景 物联网的狂潮,既是一场众多的计算机软硬件厂家(也包括通讯方案和产品厂家&…...
springCloud整合Zookeeper的时候调用找不到服务
SpringCloud整合Zookeeper的时候调用找不到服务 首先,我们在注册中心注册了这个服务: 然后我们使用RestTemplate 调用的时候发现失败了:找不到这个服务: 找了很多资料发现这个必须要加上负载才行 BeanLoadBalanced //负载publi…...

【kubernetes】使用kubepshere部署中间件服务
KubeSphere部署中间件服务 入门使用KubeSphere部署单机版MySQL、Redis、RabbitMQ 记录一下搭建过程 (内容学习于尚硅谷云原生课程) 环境准备 VMware虚拟机k8s集群,一主两从,master也作为工作节点;KubeSphere k8skubesphere devops比较占用磁…...

如何从tabbar页面传数据
无论是百度小程序还是微信小程序,app.json中规定的tabbar页面是不支持传参的,例如: <navigator url../service/service?typeid6 openType"switchTab"> 服务项目 </navigator> 上面的navigater跳转有个属性&#…...

软考高级系统架构设计师系列论文七十四:基于构件的软件开发
软考高级系统架构设计师系列论文七十四:基于构件的软件开发 一、构件相关知识点二、摘要三、正文四、总结一、构件相关知识点 软考高级系统架构设计师系列之:面向构件的软件设计,构件平台与典型架构...

图为科技_边缘计算在智能安防领域的作用
边缘计算在智能安防领域发挥着重要的作用。智能安防系统通常需要处理大量的图像、视频和传感器数据,并对其进行实时分析和处理。边缘计算可以将计算和数据处理功能移动到离数据源更接近的地方,例如摄像头、传感器设备或安防终端。 以下是边缘计算在智能…...
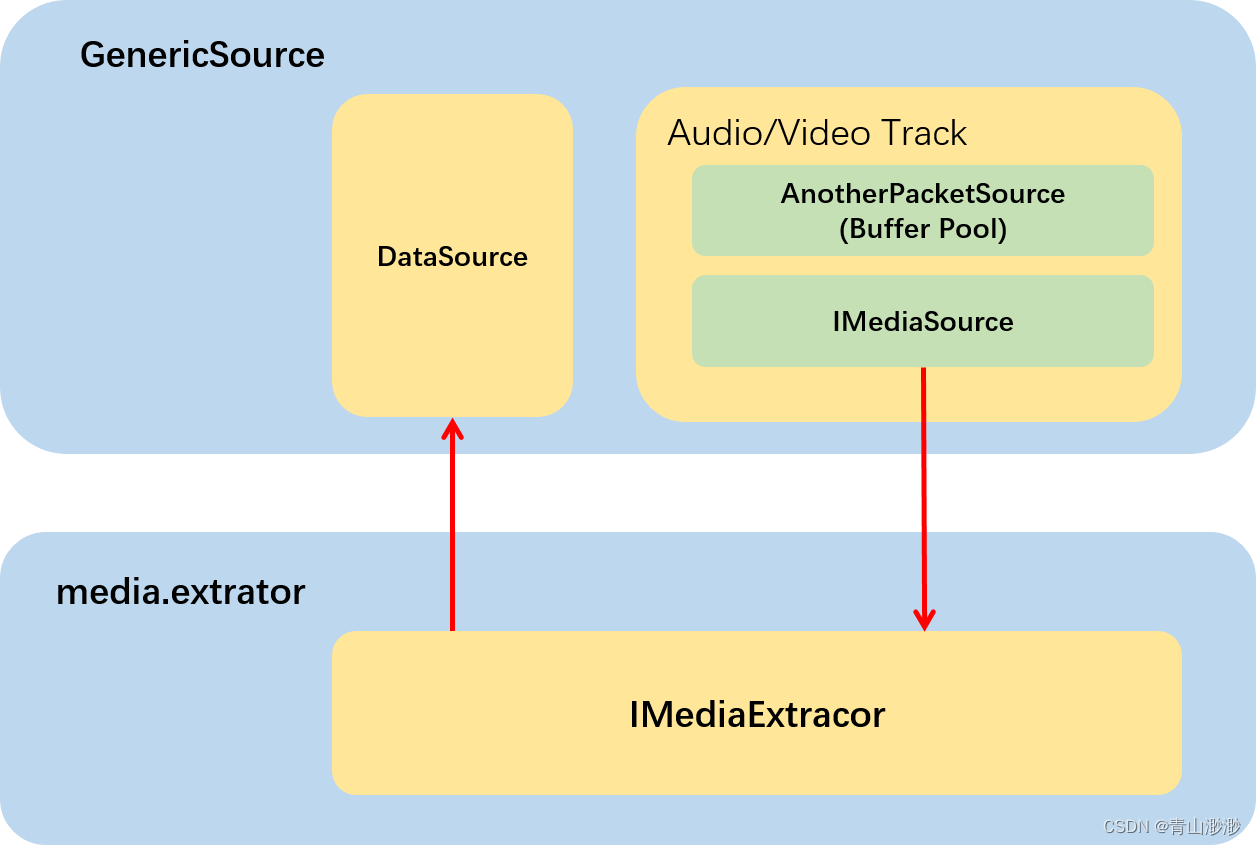
Android 13 - Media框架(7)- NuPlayer::Source
Source 在播放器中起着拉流(Streaming)和解复用(demux)的作用,Source 设计的好坏直接影响到播放器的基础功能,我们这一节将会了解 NuPlayer 中的通用 Source(GenericSource)关注本地…...
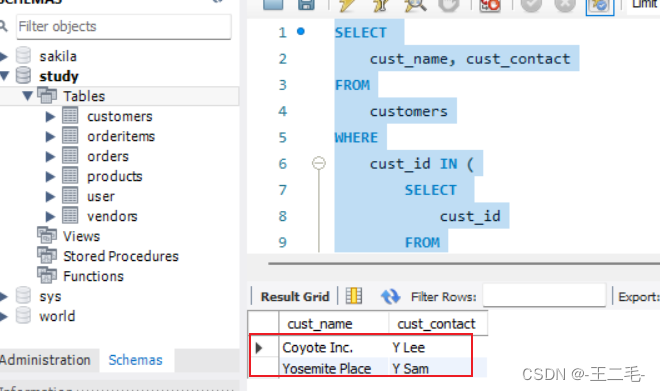
MySql015——使用子查询
一、创建customers表 ######################## # Create customers table ######################## use study;CREATE TABLE customers (cust_id int NOT NULL AUTO_INCREMENT,cust_name char(50) NOT NULL ,cust_address char(50) NULL ,cust_city char…...

leetcode 355 设计推特
用链表存储用户发送的每一个推特,用堆获取最先的10条动态 class Twitter {Map<Integer,Set<Integer>> followMap;//规定最新的放到最后Map<Integer,Tweet> postMap;//优先队列(堆)PriorityQueue<Tweet> priorityQueue;int time…...
倒数 2 周|期待 2023 Google开发者大会
9 月 6-7 日,中国上海 前沿科技,新知同享 趣味体验,灵感齐聚 技术生态,多元共进 关注官网最新信息,敬请期待大会开幕 2023 Google 开发者大会官网 相信你一定记得,在今年 5 月的 Google I/O 大会上&am…...

代码随想录day57
516最长回文子序列 class Solution { public:int longestPalindromeSubseq(string s) {vector<vector<int>>dp(s.size(),vector<int>(s.size(),0));for(int i0;i<s.size();i)dp[i][i]1;for(int is.size()-1;i>0;i--){for(int ji1;j<s.size();j){if…...

YOLOv5、v8改进:CrissCrossAttention注意力机制
目录 1.简介 2. yolov5添加方法: 2.1common.py构建CrissCrossAttention模块 2.2yolo.py中注册 CrissCrossAttention模块 2.3修改yaml文件。 1.简介 这是ICCV2019的用于语义分割的论文,可以说和CVPR2019的DANet遥相呼应。 和DANet一样,…...
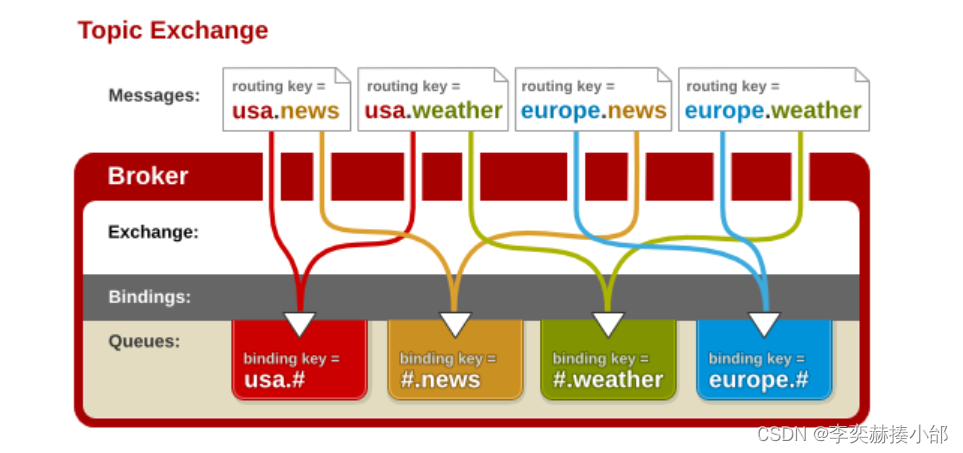
RabbitMQ特性介绍和使用案例
❤ 作者主页:李奕赫揍小邰的博客 ❀ 个人介绍:大家好,我是李奕赫!( ̄▽ ̄)~* 🍊 记得点赞、收藏、评论⭐️⭐️⭐️ 📣 认真学习!!!🎉🎉 文章目录 RabbitMQ特性…...

thermalmonitordDisabler:突破iOS性能枷锁的终极方案——彻底解决过热降频问题指南
thermalmonitordDisabler:突破iOS性能枷锁的终极方案——彻底解决过热降频问题指南 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 当你在直播过程中…...

如何突破微信设备限制?WeChatPad带来的多设备协同新体验
如何突破微信设备限制?WeChatPad带来的多设备协同新体验 【免费下载链接】WeChatPad 强制使用微信平板模式 项目地址: https://gitcode.com/gh_mirrors/we/WeChatPad 问题引入:微信生态的设备枷锁 当代数字生活中,微信已成为不可或缺…...

InternLM2-Chat-1.8B多场景落地:跨境电商产品描述生成+多语言翻译实战
InternLM2-Chat-1.8B多场景落地:跨境电商产品描述生成多语言翻译实战 1. 跨境电商的痛点与AI解决方案 跨境电商卖家每天面临着一个共同的挑战:如何为成千上万的商品快速生成高质量的产品描述,并且还要满足不同语言市场的需求。传统的人工撰…...

SGMICRO圣邦微 SGM8708YN8G/TR SOT-23 比较器
特性 低静态电流:在Vs1.8V时,典型值为2.2pA VOUT和VOUT双输出宽单电源电压范围:1.8V至5.5V 包含锁存功能 轨到轨输入和输出推挽输出电流驱动:在Vs5V时,典型值为18mA 内部1.2V参考电压工作温度范围:-40C至85C提供绿色S0T-23-8和S0IC-8封装...

LIN Switch Method:从硬件革新到软件流程,揭秘车内氛围灯自动寻址的完整闭环
1. 为什么车内氛围灯需要自动寻址技术 十年前的车内照明还停留在基础功能阶段,而现在的高端车型已经将氛围灯玩出了新花样。想象一下,当你打开车门时,迎宾灯像流水一样从车头滑向车尾;调节空调温度时,出风口周围的灯光…...

COMSOL 物质传递建模仿真:氯气洗涤与液膜除氯的奇妙之旅
COMSOL物质传递建模仿真 comsol物质传递反应 氯气洗涤,液膜除氯 液膜交界面氯气浓度衰减在化工领域,物质传递与反应的模拟对于优化工艺、提高效率至关重要。今天咱就唠唠基于 COMSOL 的物质传递建模仿真,特别是围绕氯气洗涤以及液膜除氯这俩关…...

Cursor Pro激活器技术深度解析:突破API限制的逆向工程实践
Cursor Pro激活器技术深度解析:突破API限制的逆向工程实践 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

阿里开源CosyVoice2-0.5B:快速部署声音克隆应用,小白友好教程
阿里开源CosyVoice2-0.5B:快速部署声音克隆应用,小白友好教程 1. 项目简介与核心能力 CosyVoice2-0.5B是阿里开源的一款轻量级语音克隆工具,专为快速部署和简单使用而设计。这个模型最吸引人的特点是: 3秒极速复刻:…...

DoubletFinder实战指南:精准识别单细胞测序中的双细胞干扰
1. 双细胞干扰:单细胞测序中的"隐形杀手" 做单细胞测序分析的朋友们应该都遇到过这种情况:明明细胞分群很清晰,但总有几个"奇怪"的cluster既表达A细胞标志物又表达B细胞特征。这种情况很可能就是遇到了双细胞干扰——两个…...

OpenClaw任务监控方案:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF长链条任务管理技巧
OpenClaw任务监控方案:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF长链条任务管理技巧 1. 为什么需要长链条任务监控 去年冬天,当我第一次用OpenClaw执行一个包含12个步骤的自动化流程时,系统在凌晨3点卡在了第7步——模型因为To…...