大数据领域都有什么发展方向
近年来越来越多的人选择大数据行业,大数据行业前景不错薪资待遇好,各大名企对于大数据人才需求不断上涨。
大数据从业领域很宽广,不管是科技领域还是食品产业,零售业等都是需要大数据人才进行大数据的处理,以提供更好的用户体验,优化库存降低成本预测需求。
大数据开发做什么?
大数据开发分两类,编写Hadoop、Spark的应用程序和对大数据处理系统本身进行开发。大数据开发工程师主要负责公司大数据平台的开发和维护、相关工具平台的架构设计与产品开发、网络日志大数据分析、实时计算和流式计算以及数据可视化等技术的研发和网络安全业务主题建模等工作。
大数据开发应具备的技能:
目前从事大数据应用开发的语言包括Java、Python、Scala、R等,需要熟悉Hadoop、HBbase、hive、spark、Flink、ES、Presto、Flume、Kafka生态的原理和使用方法,掌握数据开发、数据挖掘的各项流程。
要想符合企业用人规范,学历,工作经验,掌握技能都是非常重要的~
先来看几个招聘网站的报告数据:
-
Boss直聘发布的,今年春季的招聘数据大数据需求增长排名第二
-
猎聘发布的2019年来新发职位同比增长最快的5大领域,前五名就是:人工智能,生产制造,大数据,医疗健康,能源环保。
-
《2020中国大数据产业发展白皮书》显示,2019年中国大数据产业规模达5397亿元,同比增长23.1%,随后稳定增长,预计到2022年将突破万亿元。
-
根据LinkedIn、赛迪智库、拉勾网等机构的统计结果,大数据时代下的数据人才总体缺口呈现加剧增长状态。近3年,数据人才缺口在以每年50万人增加,预计在2022年,相关大数据专业高校毕业生大规模进入就业市场后,整体缺口增速才会有所放缓,但这一缺口仍会长期存在。
招聘有了,但是应聘者往往因为学历,工作经历找工作会遇到各种各样的问题,那么现在已经从事大数据的开发人员具体情况是怎样的呢?我们来看下面这几个方面:
1、学历层次
从学历层次来看,我国大数据人才的学历层次分为4个大类,分别是硕士及以上、本科、专科、专科以下,其中本科学历的大数据人才最多,占到高达65.45%的比例,其次是硕士及以上,而专科及以下学历的大数据人才仅占一小部分。可以看出,大数据行业作为一个新兴行业,对人才的学历要求普遍较高。
2、专业来源
在专业来源方面,我国大数据人才的专业来源主要由数理类、经济管理类、计算机类及其他专业四大类构成,其中计算机类占比最高,其次是数理类。
3、渠道来源
大数据人才的渠道来源分为4个大类,分别是校招、社招、内部培养和推荐、培训机构招聘。企业大数据人才各渠道来源的人数和占比见下图。
其中社招占比最大,比校招、内培和内推以及培训机构招聘的总和还要高。目前主要依靠社招,说明学校教育与社会需求脱节,内培和培训也不能满足岗位要求。
4、薪资水平分布
当前,大数据人才的薪资处于相对较高水平。薪资在1万元以下,占总人数的34.6%;1万元-2万元占比为35.64%;2万以上占比为29.77%。
5、岗位类型及数量
目前企业提供的大数据岗位按照工作内容要求,可以分为以下几类:
① 初级分析类,包括业务数据分析师、商务数据分析师等。
② 挖掘算法类,包括数据挖掘工程师、机器学习工程师、深度学习工程师、算法工程师、AI工程师、数据科学家等。
③ 开发运维类,包括大数据开发工程师、大数据架构工程师、大数据运维工程师、数据可视化工程师、数据采集工程师、数据库管理员等。
④ 产品运营类,包括数据运营经理、数据产品经理、数据项目经理、大数据销售等。四类岗位的数量和占比见下图。
大数据需求越来越多,国家也在开设相关岗位,从2018年开始就逐年较大的增长。
此时报考大学的学生和家长也对大数据,人工智能非常感兴趣,大数据连续3年进了前5,而且学历主要是本科就可以。
可以预见的将来这几年,这真的是一个朝阳行业,而且现在缺口很大。
那么想知道以后能找什么工作以及工作薪水,那不妨让我们以数据的方式来展示一下~
那么打开Boss直聘,搜大数据工程师:
我们来做下数据分析:
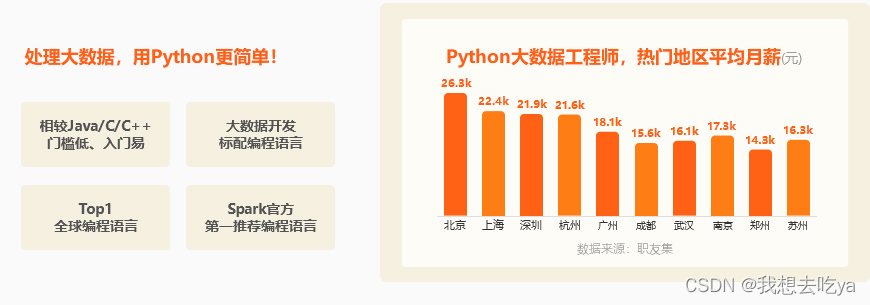
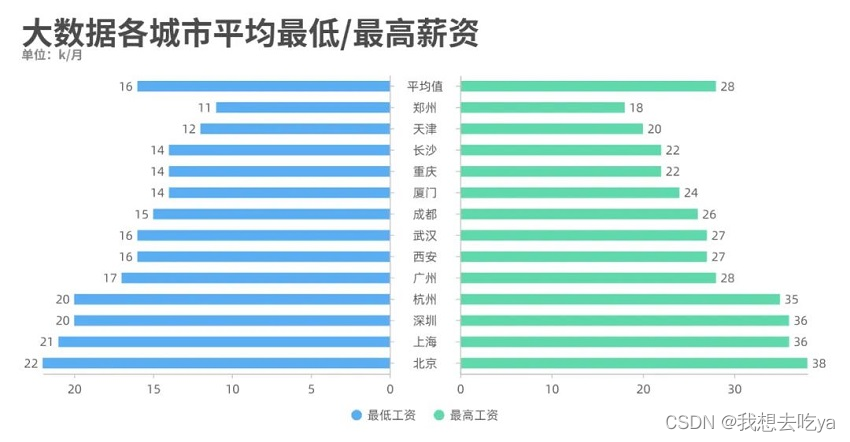
薪资那一列都有一个最低薪资和最高薪资,我们通过不同城市来对比分析一下,发现北京的工资水平最高,最低为22k,最高为38k。
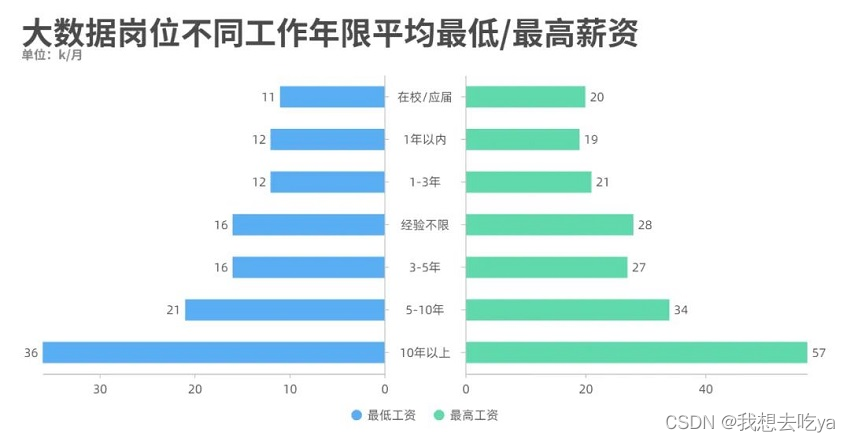
工作年限也是一个制约工资水平的很大因素,从图中可以看出,即使是刚毕业,也能达到一个11-20k的薪资范围。
而学历要求来说,大部分为本科,其次为大专和硕士,其他比较少,以至于在图中并没有显示出来。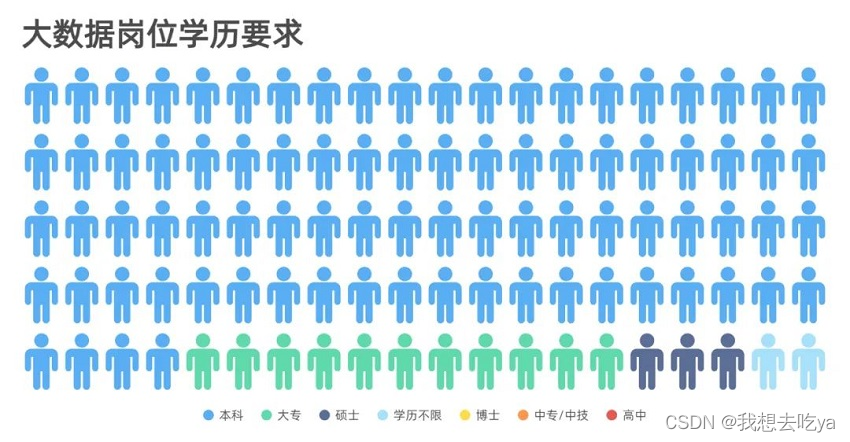
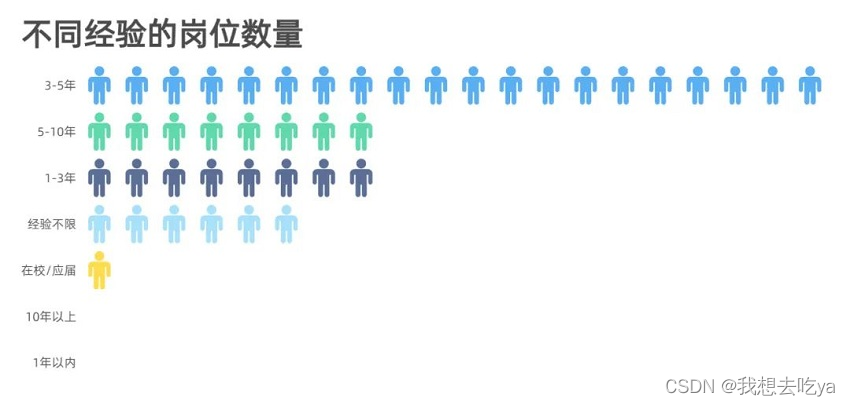
企业对不同岗位的要求以3-5年的居多,企业当然是需要有一定工作经验的员工,但是在实际招聘中,如果你有项目经验,且理论知识没问题,企业也会放宽条件。
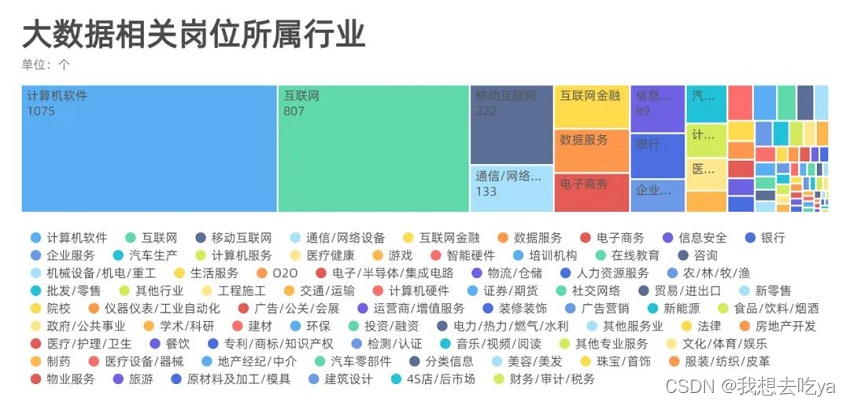
分析不同行业, 我们发现,大数据岗位需求分布在各行各业,主要还是在计算机软件和互联网最多,也有可能是这个招聘软件决定的,毕竟Boss直聘还是以互联网行业为主。
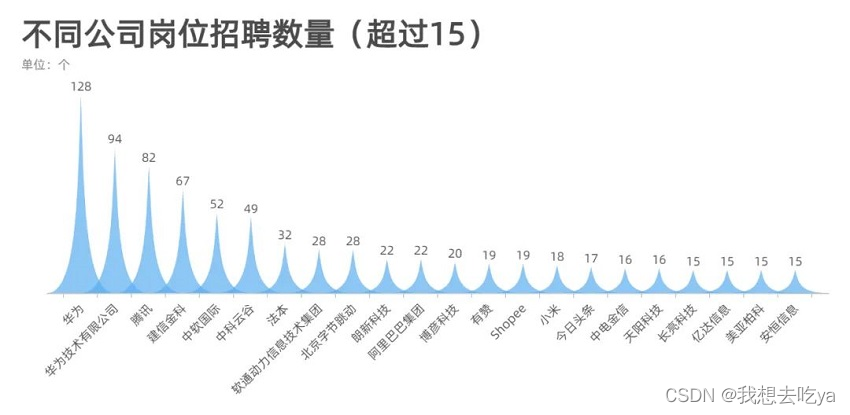
来看看哪些公司在招聘大数据相关岗位,从这个超过15的数量来看,华为,腾讯,阿里,字节,这些大厂对这个岗位的需求量还是很大的。
那么这些岗位都需要什么技能呢?Spark,Hadoop,数据仓库,Python,SQL,Mapreduce,Hbase等等

根据国内的发展形势,大数据未来的发展前景会非常好。自 2018 年企业纷纷开始数字化转型,一二线城市对大数据领域的人才需求非常强烈,未来几年,三四线城市的人才需求也会大增。
大数据学习路线以及资源:
开发入门:Linux入门 → MySQL数据库
核心基础: Hadoop
数仓技术: Hive数仓项目
PB内存计算: Python入门 → Python进阶→ pyspark框架 → Hive+Spark项目
在选择培训机构之前,可以先学习一下大数据基础的教程,看看到底自己能不能掌握~
本套教程一网打尽了大数据必学的
Hadoop、Hive,云平台实战项目
让零基础同学一站式入门
直通大数据核心技术
这套大数据新教程基于Hadoop、Hive、云平台等技术带领大家由浅入深的进入大数据领域,一起体验大规模数据计算的魅力。
基于零基础学习的内容设计,提供了丰富的补充知识点供零基础学员进行前置学习。
作为2023年全新的大数据入门课程,课程内容采用全新的技术栈体系。基于Hadoop3.3.4、Hive 3.1.3、阿里云和UCloud云平台,为同学们打造一门大数据Hadoop生态体系的入门课程,但又不仅仅只是Hadoop。
2023新版大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战项目全套一网打尽
课程特色
• 理论+实战完美结合:本套教程采用“理论+实战”的形式,全面介绍了大数据Hadoop、Hive离线开发的相关知识;
• 有内容也有深度:课程采用“入门+提高”的内容设计,入门知识和高阶知识相互独立,先全面入门,后全面进阶,循序渐进让大家学有所成;
• 结合当下热门的云平台(阿里云、UCloud)为大家带来《云原生大数据开发》:基于Hadoop3.3.4、Hive 3.1.3、阿里云和UCloud云平台,采用全新的技术栈体系。
适合人群
>零基础:小白入门到高阶,再到精通
>进阶者:有经验的工程师巩固拓展
>探索者:感兴趣者领略大数据魅力
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台
相关文章:
大数据领域都有什么发展方向
近年来越来越多的人选择大数据行业,大数据行业前景不错薪资待遇好,各大名企对于大数据人才需求不断上涨。 大数据从业领域很宽广,不管是科技领域还是食品产业,零售业等都是需要大数据人才进行大数据的处理,以提供更好…...
NSSCTF——Web题目1
目录 一、[LitCTF 2023]PHP是世界上最好的语言!! 二、[LitCTF 2023]Ping 三、[SWPUCTF 2021 新生赛]easyupload1.0 四、[SWPUCTF 2021 新生赛]easyupload2.0 五、[SWPUCTF 2021 新生赛]caidao 一、[LitCTF 2023]PHP是世界上最好的语言!&a…...

VScode中写Verilog时,iverilog语法自动纠错功能不起作用
VScode中编写Verilog时,iverilog语法自动纠错功能不起作用 问题:按照教程搭建vscode下Verilog编译环境,发现语法纠错功能一直无效,检查了扩展Verilog-HDL/SystemVerilog/Bluespec SystemVerilog的配置也没有任何问题。 错误原因&a…...
thinkphp6.0 配合shell 脚本 定时任务
1. 执行命令,生成自定义命令 php think make:command Custom<?php declare (strict_types 1);namespace app\command;use app\facade\AdmUser; use think\console\Command; use think\console\Input; use think\console\input\Argument; use think\console\i…...
18-使用钩子函数判断用户登录权限-登录前缀
钩子函数的两种应用: (1). 应用在app上 before_first_request before_request after_request teardown_request (2). 应用在蓝图上 before_app_first_request #只会在第一次请求执行,往后就不执行, (待定,此属性没调试通过) before_app_request # 每次请求都会执行一次(重点…...

关闭win11启动界面搜索推荐
环境:win11 最近win11更新了某些功能,附带加上了搜索推荐的功能。对于启动菜单的搜索功能,我只想搜索我自己的安装的程序,快速打开,不希望看到搜索推荐,更不希望多点击一下,偶尔还会打开浏览器看…...
中文乱码处理
😀前言 中文乱码处理 🏠个人主页:尘觉主页 🧑个人简介:大家好,我是尘觉,希望我的文章可以帮助到大家,您的满意是我的动力😉😉 在csdn获奖荣誉: Ἴ…...
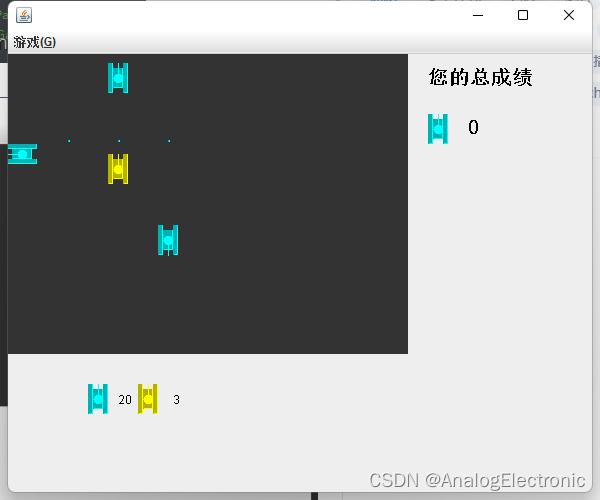
JAVA坦克大战游戏v3
JAVA坦克大战游戏v3 素材 bomb_3.gif bomb_2.gif bomb_1.gif 项目结构 游戏演示 MyTankGame3.java /*** 功能:坦克游戏的5.0[]* 1.画出坦克.* 2.我的坦克可以上下左右移动* 3.可以发射子弹,子弹连发(最多5)* 4.当我的坦克击中敌人坦克时,敌人就消失(爆炸的效…...

使用acme,自动续签免费的SSL,无忧http升级https
使用acme自动续签免费的SSL 安装acme.sh颁发域名将证书安装到nginx下配置nginx的ssl自动续签 这里只进行最简单的操作 安装acme.sh 进入你的用户目录,如果你使用root登陆,那么你的用户目录就是 /root/ curl https://get.acme.sh | sh -s emailmyexam…...
Uniapp笔记(五)uniapp语法4
本章目标 授权登录【难点、重点】 条件编译【理解】 小程序分包【理解】 一、授权登录 我的模块其实是两个组件,一个是登录组件,一个是用户信息组件,根据用户的登录状态判断是否要显示那个组件 1、登录的基本布局 <template><…...

编写一个yolov5的模型检测,只要运行后,就不结束,只要有文件放入到文件夹中,就去执行读取
编写一个yolov5的模型检测,只要运行后,就不结束,只要有文件放入到文件夹中,就去执行读取 import os import cv2 import torch from torchvision import transforms from PIL import Image from yolo.model import YOLO…...
vscode调试PHP代码
目录 准备工作ssh的连接以及配置调试 准备工作 1.首先你需要下载一个vscode 2.下载模块 你需要在VScode中去下载我们所需的两个模块PHP Debug以及remote -ssh 3.安装对应版本的xdebug 需要在xdebug的官方去进行分析,选择适合你自己版本的xdebug 去往官方&#x…...

js reverse实现数据的倒序
2023.8.25今天我学习了如何在数组顺序进行倒序排列,如: 原数组为: 我们只需要对数组使用reverse()方法 let demo [{id: 1, name: 一号},{id: 2, name: 二号},{id: 3, name: 三号},]demo.reverse()console.log(demo) 扩展: 当我…...

日常踩坑记录
本篇文章主要介绍一下最近的开发中用到的些小问题。问题不大,但有些小细节,记录一下,有遇到的朋友可以看一下,有更好的解决方法欢迎分享。 浏览器记住密码自动填充表单 这个问题我在火狐浏览器遇到了。我登录系统时选择了浏览器…...

threejs特殊几何体(一:文字几何体对象)
threejs中文字几何体通过newTextGeometry()生成,它被单独作为一个类存在于threejs中const txtGeo new TextGeometry("threejs", { ...opts, font: font }); 我们先看效果: <template><div></div> &…...

链表的实现
本程序List链表用两种方式实现,一种是双向链表,一种是双向循环链表。循环双向链表和双向链表,它们的编码差别很小;但是循环链表在插入效率上胜出很多,同时查询时候更灵活。综合考虑,循环链表是首选。 另外…...

c++ std::mutex与std::condition_variable
1. std::mutex lock()加锁; try_lock()尝试加锁; unlock()解锁; std::mutex m_mutex; m_mutex.lock(); ... m_mutex.unlock(); 2. std::lock_guard 类模板;等同自动锁,直接取代lock()和unlock(); 构造时加锁,析构时解锁; std::mutex m_mutex; {std::lock_guard<std:…...

Aspose.Tasks for .NET V23Crack
Aspose.Tasks for .NET V23Crack 改进了大型项目的内存占用。 添加了API,允许您在应用程序无法访问系统字体文件夹时指定用户的字体文件夹。 Aspose.Tasksfor.NET是处理MicrosoftProject文件的可靠的项目管理API。API支持在不依赖Microsoft Project的情况下读取、写…...
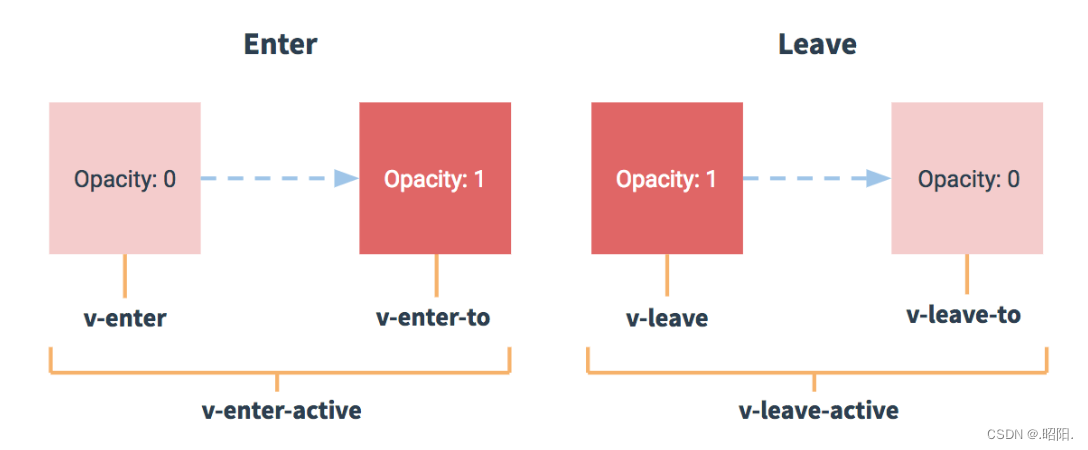
vue过渡及动画
文章目录 前言类名使用自己定义动画样式多个元素过渡使用第三方库 前言 对于vue中的过渡与动画,官网上是这样概述的: Vue 在插入、更新或者移除 DOM 时,提供多种不同方式的应用过渡效果。包括以下工具: 在 CSS 过渡和动画中自动…...

Linux环境下SVN服务器的搭建与公网访问:使用cpolar端口映射的实现方法
文章目录 前言1. Ubuntu安装SVN服务2. 修改配置文件2.1 修改svnserve.conf文件2.2 修改passwd文件2.3 修改authz文件 3. 启动svn服务4. 内网穿透4.1 安装cpolar内网穿透4.2 创建隧道映射本地端口 5. 测试公网访问6. 配置固定公网TCP端口地址6.1 保留一个固定的公网TCP端口地址6…...

传输对象模式
传输对象模式 概述 传输对象模式(Object Transfer Pattern)是一种设计模式,它允许在组件之间传递复杂对象,而不是简单的数据值。这种模式通常用于分布式系统中,特别是在需要在不同进程或不同机器之间传递对象时。传输对象模式可以有效地提高系统的可扩展性和可维护性。 …...

国产银河麒麟系统XDMA安装与测试教程
一、识别PCIe 首先在FPGA烧写XDMA的测试程序(下载bit文件或者直接固化程序)。之后重启主板,重启后打开终端。先进入root权限,执行lspci命令,可以先观察PCIe的连接状态和速率。执行命令如下: 1)s…...

MRIcroGL终极指南:免费医学影像三维可视化快速上手
MRIcroGL终极指南:免费医学影像三维可视化快速上手 【免费下载链接】MRIcroGL v1.2 GLSL volume rendering. Able to view NIfTI, DICOM, MGH, MHD, NRRD, AFNI format images. 项目地址: https://gitcode.com/gh_mirrors/mr/MRIcroGL MRIcroGL是一款强大的医…...

飞凌嵌入式与中移物联战略合作:全国产化端云一体方案解析与实战
1. 项目概述:一次嵌入式领域的“国产化”深度握手最近在嵌入式圈子里,一个消息引起了不小的讨论:飞凌嵌入式与中移物联达成了战略合作。乍一看,这像是两家公司一次常规的商业合作新闻,但如果你对国内嵌入式硬件和物联网…...

如何在macOS上畅玩Windows游戏和应用:Whisky完整实战指南
如何在macOS上畅玩Windows游戏和应用:Whisky完整实战指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 还在为Mac电脑无法运行Windows专属软件而烦恼吗?是否…...

从零构建现代化Web组件库:架构设计、开发实践与工程化指南
1. 项目概述:从零到一理解现代Web组件库如果你是一名前端开发者,或者正在构建一个需要大量交互界面的Web应用,那么“组件库”这个词对你来说一定不陌生。今天我们不聊那些耳熟能详的巨头库,而是聚焦于一个更具象、更贴近实际开发场…...

电角度测量实战:从理论到示波器波形解析
1. 电角度基础概念解析 第一次接触电机控制时,听到"电角度"这个词确实有点懵。后来在实际项目中才发现,这个概念对理解FOC控制至关重要。简单来说,电角度就是电机磁场旋转时,转子磁极与定子绕组之间的相对位置关系。它和…...

为 Hermes Agent 配置 Taotoken 自定义提供商接入指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Hermes Agent 配置 Taotoken 自定义提供商接入指南 Hermes Agent 是一个功能强大的 AI 智能体开发框架,支持通过自定…...

Topit:3分钟掌握macOS窗口置顶,工作效率提升200%的终极指南
Topit:3分钟掌握macOS窗口置顶,工作效率提升200%的终极指南 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 在macOS多任务处理中&#x…...

重磅!国内顶尖人工智能科学家郝建业出任斗象科技首席AI安全科学家
近日,斗象科技正式宣布,国内顶尖人工智能专家、国家优秀青年科学基金获得者郝建业教授,出任斗象科技首席AI安全科学家(Chief Scientist of AI Security)。 郝建业教授是享誉国内外的人工智能学者,曾担任华为…...