Python爬取网页详细教程:从入门到进阶
【导言】:
Python作为一门强大的编程语言,常常被用于编写网络爬虫程序。本篇文章将为大家详细介绍Python爬取网页的整个流程,从安装Python和必要的库开始,到发送HTTP请求、解析HTML页面,再到提取和处理数据,最后讲解如何处理动态页面、登录认证和处理AJAX请求。通过多个案例的演示,帮助读者全面掌握Python爬虫编程技巧。
【正文】:
一、安装Python和必要的库
Python是一门开源的编程语言,具有简洁、易读和强大的特点。首先,我们需要安装Python。您可以从Python官方网站(https://www.python.org/)下载并安装最新版本的Python。安装完成后,我们还需要安装一些必要的库,如requests、Beautiful Soup和lxml。您可以使用以下命令在命令行中安装这些库:
pip install requests
pip install beautifulsoup4
pip install lxml
二、使用requests库发送HTTP请求
在编写爬虫程序时,我们需要向目标网站发送HTTP请求,并获取网页的内容。使用requests库可以方便地完成这个过程。下面是一个简单的例子,演示如何发送GET请求并获取网页的内容:
import requestsurl = 'https://www.example.com'
response = requests.get(url)
content = response.text
在这个例子中,我们使用requests库的get()方法发送了一个GET请求,并将返回的响应存储在response变量中。通过response的text属性,我们可以获取网页的内容并存储在content变量中。
三、使用Beautiful Soup解析HTML页面
获取网页的内容之后,我们需要解析HTML页面,并提取所需的数据。这时可以使用Beautiful Soup库。下面是一个例子,演示如何使用Beautiful Soup解析HTML页面并提取所需的数据:
from bs4 import BeautifulSoupsoup = BeautifulSoup(content, 'lxml')
title = soup.title.text
print(title)
在这个例子中,我们首先实例化一个BeautifulSoup对象,并传入网页内容和解析器类型(这里使用lxml解析器)。然后,我们可以使用对象的属性和方法来提取数据。在这个例子中,我们使用title属性来获取网页的标题,并使用text属性来获取标题的文本内容。
四、提取和处理数据
在爬取网页的过程中,我们最主要的目标是提取所需的数据。通过观察网页的结构和元素,我们可以使用CSS选择器或XPath表达式来定位和提取数据。下面是一个例子,演示如何使用CSS选择器提取页面中的所有链接:
links = soup.select('a')
for link in links:href = link['href']print(href)
在这个例子中,我们使用select()方法和CSS选择器来选择所有的a标签(即链接元素)。然后,我们可以遍历结果集,并使用元素的属性来获取链接的URL。
五、处理动态页面
有些网页使用JavaScript动态加载数据,这时我们需要模拟浏览器的行为来获取动态生成的内容。可以使用Selenium库来实现这一功能。下面是一个例子,演示如何使用Selenium模拟浏览器行为并获取动态页面的内容:
from selenium import webdriverurl = 'https://www.example.com'
driver = webdriver.Chrome()
driver.get(url)
content = driver.page_source
driver.quit()
在这个例子中,我们首先实例化一个Chrome浏览器对象,并使用get()方法打开目标网页。然后,我们可以使用page_source属性获取页面的源代码。最后,记得调用quit()方法关闭浏览器。
六、登录认证和处理AJAX请求
有些网站需要登录认证才能获取特定的数据。可以使用requests库发送POST请求并携带登录凭证来模拟登录。对于包含AJAX请求的网页,我们可以使用Selenium模拟浏览器行为来执行AJAX请求,并获取返回的数据。下面是一个例子,演示如何登录认证和处理AJAX请求:
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 登录认证
login_url = 'https://www.example.com/login'
data = {'username': 'your_username', 'password': 'your_password'}
response = requests.post(login_url, data=data)
# 处理AJAX请求
url = 'https://www.example.com/ajax_data'
driver = webdriver.Chrome()
driver.get(url)
wait = WebDriverWait(driver, 10)
ajax_data = wait.until(EC.visibility_of_element_located((By.ID, 'ajax_data')))
content = ajax_data.text
driver.quit()
在这个例子中,我们首先使用requests库发送POST请求来进行登录认证,并将登录凭证存储在response变量中。然后,我们使用Selenium模拟浏览器行为,并使用WebDriverWait类来等待AJAX请求结果的可见性。最后,我们可以通过元素的text属性来获取AJAX请求返回的数据。
【结论】:
通过本文介绍的Python爬取网页的详细教程,我们可以了解到使用Python进行网页爬取的一般流程。从安装Python和必要的库,到发送HTTP请求、解析HTML页面,再到提取和处理数据,最后讲解了如何处理动态页面、登录认证和处理AJAX请求。通过多个案例的演示,读者可以全面掌握Python爬虫编程的技巧,为进一步应用于实际项目打下坚实的基础。希望本文对大家学习Python爬虫有所帮助!
相关文章:

Python爬取网页详细教程:从入门到进阶
【导言】: Python作为一门强大的编程语言,常常被用于编写网络爬虫程序。本篇文章将为大家详细介绍Python爬取网页的整个流程,从安装Python和必要的库开始,到发送HTTP请求、解析HTML页面,再到提取和处理数据࿰…...
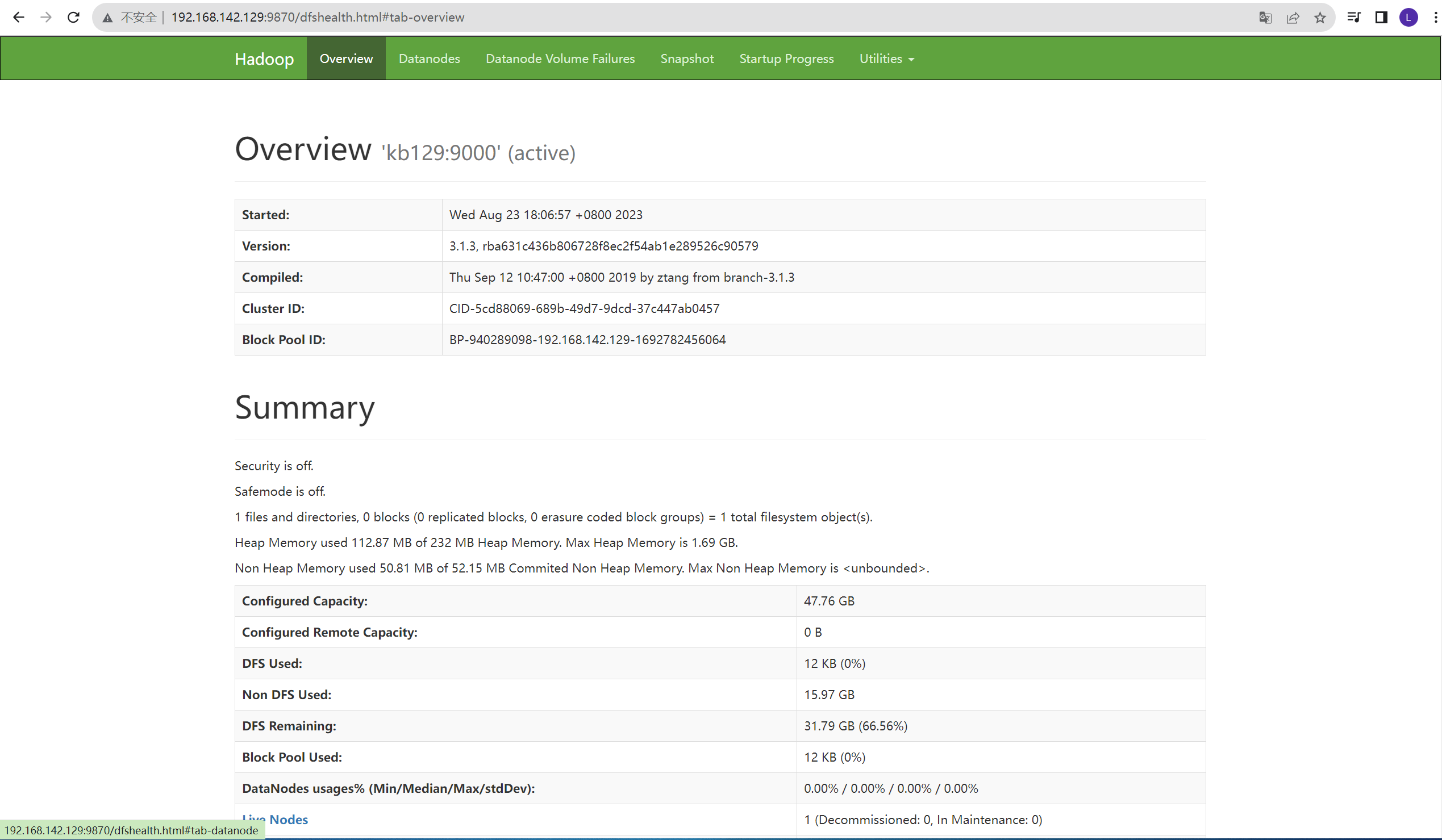
linux安装JDK及hadoop运行环境搭建
1.linux中安装jdk (1)下载JDK至opt/install目录下,opt下创建目录soft,并解压至当前目录 tar xvf ./jdk-8u321-linux-x64.tar.gz -C /opt/soft/ (2)改名 (3)配置环境变量…...
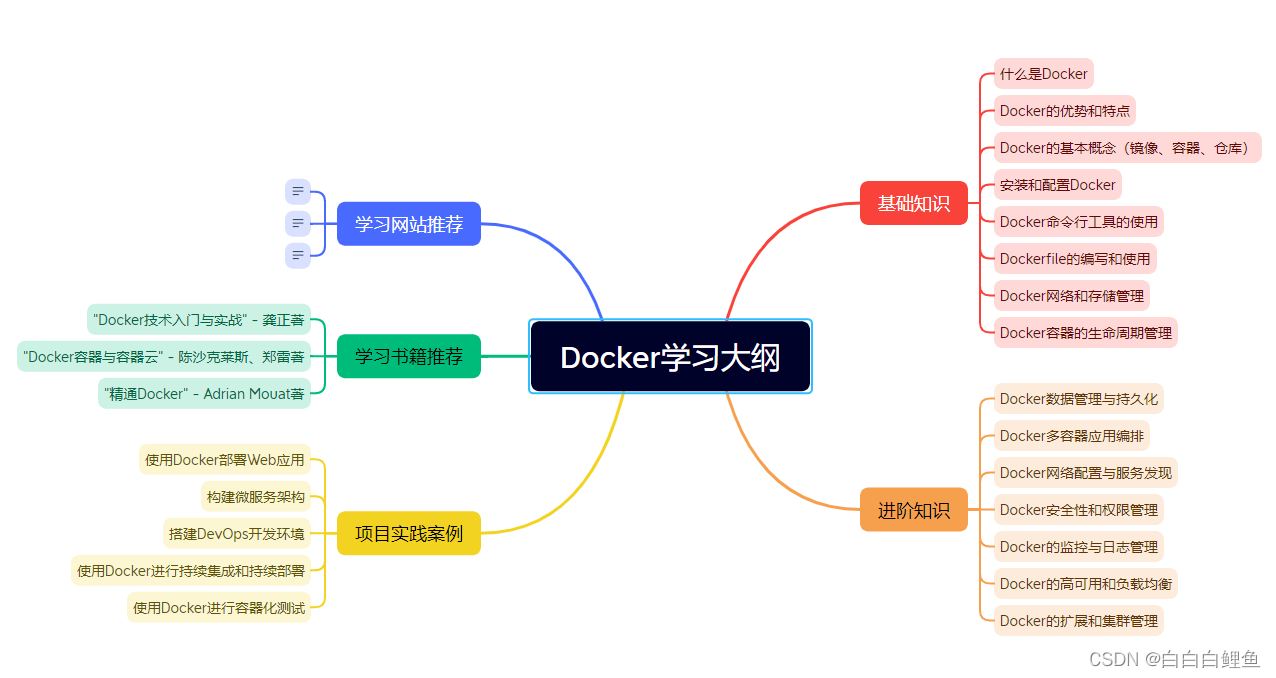
使用ChatGPT一键生成思维导图
指令1:接下来你回复的所有内容,都放到Markdown代码框中。 指令2:作为一个Docker专家,为我编写一个详细全面的Docker学习大纲,包括基础知识、进阶知识、项目实践案例,学习书籍推荐、学习网站推荐等…...

极简Vim教程
2023年8月27日,周日上午 我不想学那么多命令和快捷键,够用就行... 所以就把我自己认为比较常用的命令和快捷键记录成博客 目录 预备知识Vim的工作模式保存内容退出Vim复制、粘贴和剪切选中一段内容复制粘贴剪切撤回和反撤回撤回反撤回查找替换删除删除…...

在线帮助中心也属于知识管理的一种吗?
在线帮助中心是企业或组织为了提供客户支持而建立的一个在线平台,它包含了各种类型的知识和信息,旨在帮助用户解决问题和获取相关的信息。从知识管理的角度来看,可以说在线帮助中心也属于知识管理的一种形式。下面将详细介绍在线帮助中心作为…...

《Linux从练气到飞升》No.18 进程终止
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...
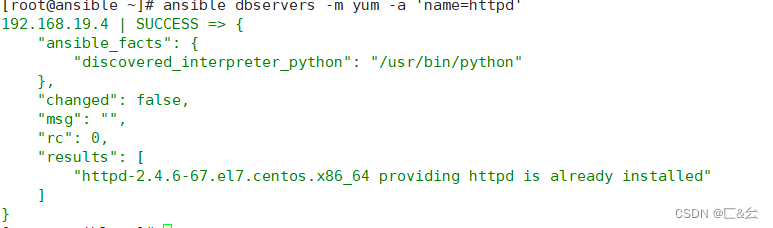
自动化运维工具——ansible安装及模块介绍
目录 一、ansible——自动化运维工具 1.1 Ansible 自动运维工具特点 1.2 Ansible 运维工具原理 二、安装ansible 三、ansible命令模块 3.1 command模块 3.2 shell模块 3.3 cron模块 3.4 user模块 3.5 group 模块 3.6 copy模块 3.7 file模块 3.8 ping模…...
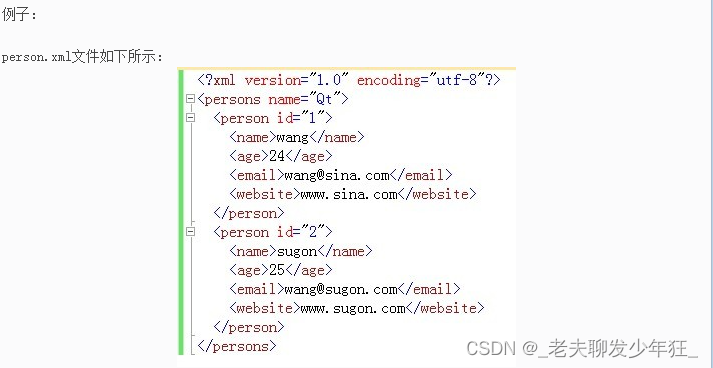
Qt XML文件解析 QDomDocument
QtXml模块提供了一个读写XML文件的流,解析方法包含DOM和SAX,两者的区别是什么呢? DOM(Document Object Model):将XML文件保存为树的形式,操作简单,便于访问。 SAX(Simple API for …...
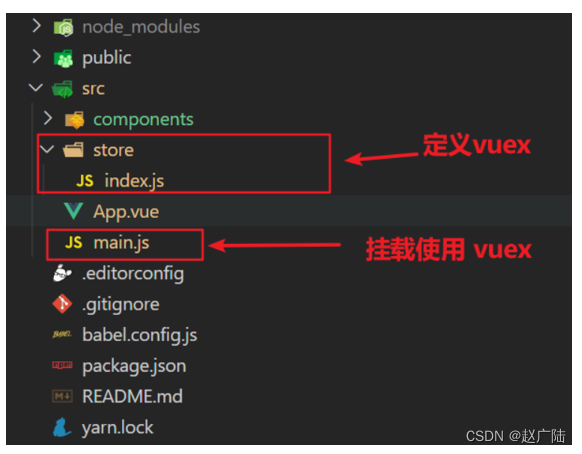
Vue2向Vue3过度Vuex状态管理工具快速入门
目录 1 Vuex概述1.是什么2.使用场景3.优势4.注意: 2 需求: 多组件共享数据1.创建项目2.创建三个组件, 目录如下3.源代码如下 3 vuex 的使用 - 创建仓库1.安装 vuex2.新建 store/index.js 专门存放 vuex3.创建仓库 store/index.js4 在 main.js 中导入挂载到 Vue 实例…...

生产制造型企业BOM搭建分析
导 读 ( 文/ 2358 ) 在上几篇文章中,我们讲到了基础的物料管理方法,在生产制造中,物料作为原材料,通过加工,结构组装成产品。那么加工、组装的依据将来源于设计人员出具的零件清单,也就是我们常说的BOM。 …...

大数据课程K11——Spark的数据挖掘机器学习
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Spark的概念——数据挖掘; ⚪ 了解Spark的概念——机器学习; ⚪ 了解Spark的概念——深度学习; ⚪ 了解Spark的概念——人工智能; ⚪ 了解Spark的概念——数据挖掘体系; ⚪ 掌…...
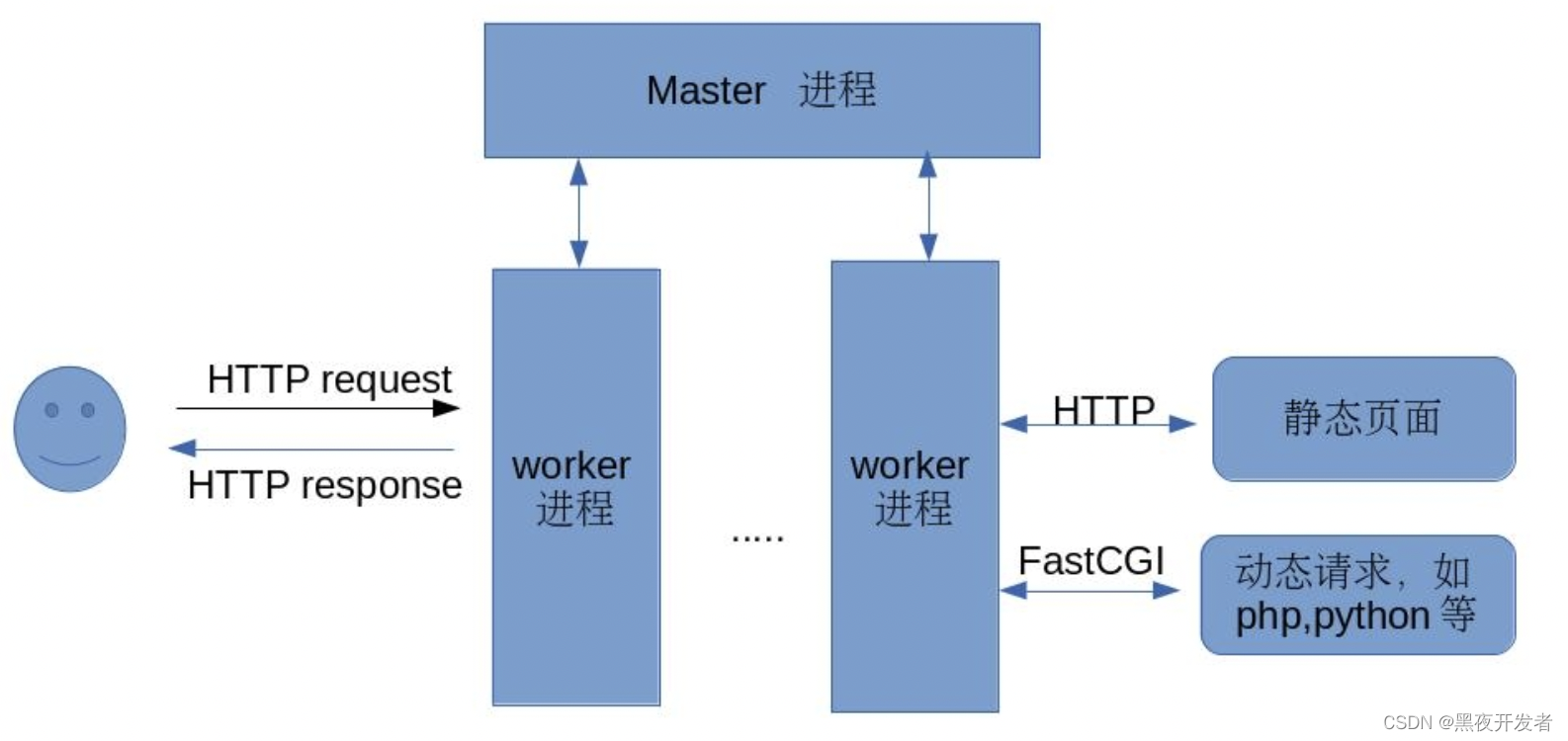
【PHP面试题81】php-fpm是什么?它和PHP有什么关系
文章目录 🚀一、前言,php-fpm是什么🚀二、php-fpm与PHP之间的关系🚀三、php-fpm解决的问题🔎3.1 进程管理🔎3.2 进程池管理🔎3.3 性能优化🔎3.4 并发处理 🚀四、php-fpm常…...

MyBatis分页查询与特殊字符处理
目录 目录 一、引言 1.1 简介Mybatis 1.2分页查询的重要性 1.3MyBatis特殊字符处理的挑战 挑战1:SQL注入漏洞 挑战2:查询结果异常 挑战3:数据完整性问题 挑战4:跨平台兼容性 挑战5:用户体验 如何应对挑战 二…...
Docker Desktop 笔记
https://blog.csdn.net/qq_39611230/article/details/108641842 https://blog.csdn.net/KgdYsg/article/details/118213499 1、修改配置 {"registry-mirrors": ["https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://…...

VS2022 C++修改Window系统DNS源代码V2.0
这是自己使用VS2022 C++编写开发的Window系统下修改DNS脚本程序第2个版本,适合Win10系统和Win7系统。cfg.txt文件存放要修改的DNS,最多4个。 详细源代码如下: setdns.cpp /* 1.全部清空DNSstring strParameter;strParameter = "netsh interface ip delete dns name=\…...
)
科技的成就(五十)
389、"IBM 提交给哈佛大学" "1944 年 8 月 7 日,“哈佛马克一号”正式由 IBM 提交给哈佛大学。“哈佛马克一号”最初的概念是由霍华德艾肯在 1937 年 11月向 IBM 提出的,经过 IBM 工程师的可行性研究,大约在签订第一份合约 7年…...

一文讲明白C++中的结构体Struct和类Class的区别以及使用场景
一文讲明白C中的结构体Struct和类Class的区别以及使用场景 文章目录 一文讲明白C中的结构体Struct和类Class的区别以及使用场景一、C中的结构体Struct二、C中的类Class三、结构体Struct和类Class之间的区别以及各自使用场景 一、C中的结构体Struct 在C中,结构体&…...

etcd学习入门
etcd有哪些独特的特性 etcd作为一个分布式键值存储系统,具有一些独特的特性,使其在分布式系统中得到广泛应用。以下是etcd的一些独特特性: 一致性: etcd使用Raft一致性算法来确保数据的一致性和可靠性。Raft算法能够处理网络分区、节点故障和…...

pyqt点击按钮执行脚本
class NineGridApp(QWidget): def __init__(self): super().__init__() self.initUI() def initUI(self): self.setWindowTitle(测试常见的操作) self.setGeometry(100, 100, 1800, 1800) layout QGridLayout() # 创建一个3x3的二维数组 rows 3 cols 3 array_2d [[0 for _ …...
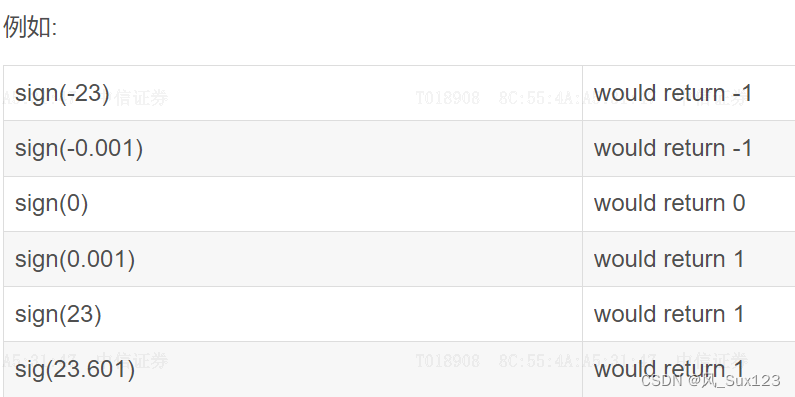
9.oracle中sign函数
在Oracle/PLSQL中, sign 函数返回一个数字的正负标志. 语法如下:sign( number ) number 要测试标志的数字. If number < 0, then sign returns -1. If number 0, then sign returns 0. If number > 0, then sign returns 1. 应用于: Oracle 8i, Oracle …...

D2DX暗黑2宽屏补丁:3分钟让经典游戏焕发新生的终极优化方案
D2DX暗黑2宽屏补丁:3分钟让经典游戏焕发新生的终极优化方案 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在…...

Python知乎API开发完全指南:从零构建高效数据采集系统
Python知乎API开发完全指南:从零构建高效数据采集系统 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎作为中文互联网最大的知识分享平台,其丰富…...

别再硬啃英文文档了!手把手教你给Vue2项目里的DHTMLX Gantt甘特图做中文汉化
Vue2项目深度汉化DHTMLX Gantt甘特图实战指南 在项目管理工具中,甘特图因其直观的时间轴展示方式而备受青睐。DHTMLX Gantt作为一款功能强大的甘特图组件,却在中文环境下存在明显的本地化短板。本文将彻底解决这一问题,从界面文本到日期格式…...

【紧急更新】Perplexity v3.2.1已悄然移除默认引用锚点!立即启用这4种透明度兜底机制保学术安全
更多请点击: https://intelliparadigm.com 第一章:Perplexity引用透明度优化的紧急背景与影响评估 在大型语言模型推理链(Chain-of-Thought)与多跳检索增强生成(RAG)系统中,Perplexity 作为核心…...

Page Assist终极指南:3步安装本地AI浏览器助手,开启智能网页浏览新时代
Page Assist终极指南:3步安装本地AI浏览器助手,开启智能网页浏览新时代 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist 想…...

CircuitPython displayio与触摸交互实战:复刻经典Neko猫咪动画
1. 项目概述与核心价值如果你玩过一些复古的掌机或者小型的嵌入式设备,可能会对屏幕上那只跟着你手指或光标跑的“Neko猫咪”有印象。这个源自上世纪经典屏保的小动画,在今天看来,依然是学习嵌入式图形和交互编程的绝佳入门项目。它麻雀虽小&…...

基于视觉大模型的GUI自动化:从原理到实践
1. 项目概述:当GUI自动化遇见视觉大模型 最近在折腾自动化测试和RPA(机器人流程自动化)的时候,我遇到了一个老生常谈但又极其棘手的问题:如何稳定、高效地识别和操作那些没有标准控件标识的图形界面元素?传…...

sagents框架实战:从零构建具备记忆与协作能力的AI智能体
1. 项目概述:一个面向开发者的AI智能体构建框架最近在AI应用开发领域,一个名为sagents的开源项目引起了我的注意。它不是一个直接面向终端用户的聊天机器人,而是一个旨在帮助开发者快速构建、管理和编排复杂AI智能体(Agent&#x…...

ChatGPT购物功能支持平台速查表,含响应延迟、支付闭环率、商品图识别准确率等5项硬指标实测数据
更多请点击: https://intelliparadigm.com 第一章:ChatGPT购物功能支持哪些平台 截至2024年,ChatGPT原生并不直接集成电商交易能力,但通过官方插件(Plugins)和第三方API集成,可在特定授权环境…...

基于Circuit Playground Express与3D打印的机械心脏制作指南
1. 项目概述:一个会“呼吸”的机械心脏如果你对创客、STEAM教育或者互动艺术装置感兴趣,那么亲手制作一个能模拟真实心跳、并且心率可以手动调节的解剖心脏模型,绝对是一个能让你成就感爆棚的项目。这不仅仅是一个静态的展示品,它…...