python——ydata-profiling介绍与使用
ydata-profiling介绍与使用
- ydata-profiling的作用
- ydata-profiling的安装与简单使用
- ydata-profiling的结果结构
- ydata-profiling的实际应用场景
- 1. 数据集比较
- 2. 时间序列报告
- 3. 对大型数据集进行概要分析
- 4. 处理敏感数据
- 5. 自定义报告的外观
ydata-profiling的作用
ydata-profiling的主要目标是提供一种简洁而快速的探索性数据分析(EDA)体验。就像pandas中的df.describe()函数非常方便一样,ydata-profiling可以对DataFrame进行扩展分析,并允许将数据分析导出为不同格式,例如html和json。
该软件包输出了一个简单而易于理解的数据集分析结果,包括时间序列和文本数据。
ydata-profiling的安装与简单使用
1. 安装
pip install ydata-profiling
2. 使用
import numpy as np
import pandas as pd
from ydata_profiling import ProfileReportdf = pd.DataFrame(np.random.rand(100, 5), columns=['a','b','c','d','e'])
profile = ProfileReport(df, title="Profiling Report")
ydata-profiling的结果结构
ydata-profiling的结果会使用一些关键属性:
- 类型推断 (Type inference):自动检测列的数据类型(分类、数值、日期等)
- 警告 (Warning):对数据中可能需要处理的问题/挑战的概要(缺失数据、不准确性、偏斜等)
- 单变量分析 (Univariate analysis):包括描述性统计量(平均值、中位数、众数等)和信息可视化,如分布直方图
- 多变量分析 (Multivariate analysis):包括相关性分析、详细分析缺失数据、重复行,并为变量之间的交互提供视觉支持
- 时间序列 (Time-Series):包括与时间相关的不同统计信息,例如自相关和季节性,以及ACF和PACF图。
- 文本分析 (Text analysis):最常见的类别(大写、小写、分隔符)、脚本(拉丁文、西里尔文)和区块(ASCII、西里尔文)
- 文件和图像分析 (File and Image analysis):文件大小、创建日期、指示截断图像和存在EXIF元数据的指示
- 比较数据集 (Compare datasets):一行命令,快速生成完整的数据集比较报告
- 灵活的输出格式 (Flexible output formats):所有分析结果可以导出为HTML报告,便于与各方共享,也可作为JSON用于轻松集成到自动化系统中,还可以作为Jupyter Notebook中的小部件使用
报告还包含三个额外的部分:
- 概述 (Overview):主要提供有关数据集的全局详细信息(记录数、变量数、整体缺失值和重复值、内存占用情况)
- 警告 (Alerts):一个全面且自动的潜在数据质量问题列表(高相关性、偏斜、一致性、零值、缺失值、常数值等)
- 重现 (Reporduction):分析的技术细节(时间、版本和配置)
ydata-profiling的实际应用场景
1. 数据集比较
ydata-profiling可以用于比较同一数据集的多个版本。当需要对比不同时间段(如两年)的数据时,这非常有用。另一个常见的场景是在机器学习中查看训练、验证和测试数据集的数据概况。例如:
from ydata_profiling import ProfileReporttrain_df = pd.read_csv("train.csv")
train_report = ProfileReport(train_df, title="Train")test_df = pd.read_csv("test.csv")
test_report = ProfileReport(test_df, title="Test")comparison_report = train_report.compare(test_report)
comparison_report.to_file("comparison.html")
比较报告使用设置中的标题属性作为标签。颜色在settings.html.style.primary_colors中进行配置。可以通过调整numeric precision参数settings.report.precision来获得报告中的一些额外空间。
当比较多个报告时:
from ydata_profiling import ProfileReport, comparecomparison_report = compare([train_report, validation_report, test_report])# Obtain merged statistics
statistics = comparison_report.get_description()# Save report to file
comparison_report.to_file("comparison.html")
请注意,此功能仅确保支持对两个数据集进行比较的报告。可以获取统计信息,但报告可能存在格式问题。其中一个可以更改的设置是settings.report.precision。根据经验,可以将值10用于单个报告,将值8用于比较两个报告。
2. 时间序列报告
pandas-profiling可以用于对时间序列数据进行快速的探索性数据分析。这对于快速了解与时间相关的变量的行为(如时间图、季节性、趋势和平稳性)非常有用。
结合profiling reports compare,您可以比较时间上的演变和数据行为,以时间序列特定统计信息(如PACF和ACF图)为基础。
以下语法可用于在假设数据集包含时间相关特征的情况下生成概要报告:
import pandas as pdfrom ydata_profiling.utils.cache import cache_file
from ydata_profiling import ProfileReportfile_name = cache_file("pollution_us_2000_2016.csv","https://query.data.world/s/mz5ot3l4zrgvldncfgxu34nda45kvb",
)df = pd.read_csv(file_name, index_col=[0])# Filtering time-series to profile a single site
site = df[df["Site Num"] == 3003]profile = ProfileReport(df, tsmode=True, sortby="Date Local", title="Time-Series EDA")profile.to_file("report_timeseries.html")
要生成时间序列报告,需要将ts_mode设置为“True”。如果设置为“True”,那些具有时间依赖性的变量将根据自相关的存在自动识别出来。时间序列报告使用sortby属性对数据集进行排序。如果未提供此属性,则假定数据集已经按顺序排列。
在某些情况下,您可能已经清楚哪些变量应该是时间序列,或者您只想确保您希望作为时间序列进行分析的变量被正确地进行概要分析:
import pandas as pdfrom ydata_profiling.utils.cache import cache_file
from ydata_profiling import ProfileReportfile_name = cache_file("pollution_us_2000_2016.csv","https://query.data.world/s/mz5ot3l4zrgvldncfgxu34nda45kvb",
)df = pd.read_csv(file_name, index_col=[0])# Filtering time-series to profile a single site
site = df[df["Site Num"] == 3003]# Setting what variables are time series
type_schema = {"NO2 Mean": "timeseries","NO2 1st Max Value": "timeseries","NO2 1st Max Hour": "timeseries","NO2 AQI": "timeseries","cos": "numeric","cat": "numeric",
}profile = ProfileReport(df,tsmode=True,type_schema=type_schema,sortby="Date Local",title="Time-Series EDA for site 3003",
)profile.to_file("report_timeseries.html")
3. 对大型数据集进行概要分析
默认情况下,ydata-profiling以最能提供数据分析洞察的方式全面总结输入数据集。对于小型数据集,这些计算可以准实时进行。对于较大的数据集,可能需要事先决定要进行哪些计算。一个计算是否适用于大型数据集不仅取决于数据集的确切大小,还取决于其复杂性以及是否可用快速计算。如果概要分析的计算时间成为瓶颈,ydata-profiling提供了几种解决方案来克服这一问题。
3.1 最小模式
ydata-profiling包含一个最小配置文件,默认情况下关闭了最费力的计算。这是处理较大数据集的推荐起点。
profile = ProfileReport(large_dataset, minimal=True)
profile.to_file("output.html")
3.2 对数据集取样
处理非常大型数据集的另一种方法是使用其中一部分数据生成概要分析报告。一些用户报告称,这是在保持代表性的同时缩短计算时间的好方法。
sample = large_dataset.sample(10000)profile = ProfileReport(sample, minimal=True)
profile.to_file("output.html")
报告的读者可能想了解概要分析是使用数据样本生成的。可以通过向报告添加描述来说明这一点。
description = "Disclaimer: this profiling report was generated using a sample of 5% of the original dataset."
sample = large_dataset.sample(frac=0.05)profile = sample.profile_report(dataset={"description": description}, minimal=True)
profile.to_file("output.html")
3.3 禁用费力的计算
为了减少特别大型数据集中的计算负担,但仍然保留可能来自它们的一些感兴趣的信息,可以仅针对某些列过滤一些计算。特别地,可以提供一个目标列表给Interactions,以便仅计算与这些特定变量有关的交互作用。
from ydata_profiling import ProfileReport
import pandas as pd# Reading the data
data = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
)# Creating the profile without specifying the data source, to allow editing the configuration
profile = ProfileReport()
profile.config.interactions.targets = ["Name", "Sex", "Age"]# Assigning a DataFrame and exporting to a file, triggering computation
profile.df = data
profile.to_file("report.html")
控制此设置的"interactions.targets" 可以通过多个接口进行更改(配置文件或环境变量)。
3.4 并发性
ydata-profiling是一个正在积极开发的项目。其中一个非常期望的功能是添加可扩展的后端,例如Modin或Dask。
4. 处理敏感数据
在某些数据敏感的背景下(例如,私人健康记录),分享包含样本的报告可能会违反隐私约束。以下配置简写将各种选项分组在一起,以便在报告中只提供聚合信息,而不显示个人记录:
report = df.profile_report(sensitive=True)
此外,pandas-profiling不会将数据发送到外部服务,因此非常适合处理私人数据。
4.1 样本和重复值
可以禁用显示数据集样本和重复行的功能,以确保报告不会直接泄漏任何数据:
report = df.profile_report(duplicates=None, samples=None)
或者,仍然可以显示一个样本,但以下代码片段演示了如何生成报告,但在数据集样本部分使用模拟/合成数据。请注意,name和caption键是可选的。
# Replace with the sample you'd like to present in the report (can be from a mock or synthetic data generator)
sample_custom_data = pd.DataFrame()
sample_description = "Disclaimer: the following sample consists of synthetic data following the format of the underlying dataset."report = df.profile_report(sample={"name": "Mock data sample","data": sample_custom_data,"caption": sample_description,}
)
4.2 数据集元数据、数据字典和配置
当与同事共享报告或在网上发布时,包含数据集的元数据(如作者、版权持有人或描述)可能很重要。ydata-profiling允许用这些信息来补充报告。受到schema.org的数据集启发,目前支持的属性有description、creator、author、url、copyright_year和copyright_holder。
以下示例展示了如何生成一个包含描述、版权持有人、版权年份、创作者和URL的报告。在生成的报告中,这些属性将出现在概述部分的“关于”下面。
report = df.profile_report(title="Masked data",dataset={"description": "This profiling report was generated using a sample of 5% of the original dataset.","copyright_holder": "StataCorp LLC","copyright_year": 2020,"url": "http://www.stata-press.com/data/r15/auto2.dta",},
)report.to_file(Path("stata_auto_report.html"))
除了提供数据集的详细信息外,用户在与团队成员和利益相关者分享报告时,通常希望包含针对每列的具体描述。ydata-profiling支持创建这些描述,以便报告中包含内置的数据字典。默认情况下,这些描述会在报告的概述部分中呈现,在每个变量旁边显示。
profile = df.profile_report(variables={"descriptions": {"files": "Files in the filesystem, # variable name: variable description","datec": "Creation date","datem": "Modification date",}}
)profile.to_file(report.html)
另外,列描述可以从一个JSON文件中加载:
{column name 1: column 1 definition,column name 2: column 2 definition}
import json
import pandas as pd
import ydata_profilingdefinition_file = dataset_column_definition.json# Read the variable descriptions
with open(definition_file, r) as f:definitions = json.load(f)# By default, the descriptions are presented in the Overview section, next to each variable
report = df.profile_report(variable={"descriptions": definitions})# We can disable showing the descriptions next to each variable
report = df.profile_report(variable={"descriptions": definitions}, show_variable_description=False
)report.to_file("report.html")
除了提供数据集的详细信息,用户通常还希望包含设置类型模式。当将ydata-profiling生成与数据目录中已有的信息集成时,这一点尤为重要。当使用ydata-profiling的ProfileReport时,用户可以设置type_schema属性来控制生成的数据类型分析。默认情况下,type_schema会通过visions自动推断。
import json
import pandas as pdfrom ydata_profiling import ProfileReport
from ydata_profiling.utils.cache import cache_filefile_name = cache_file("titanic.csv","https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv",
)
df = pd.read_csv(file_name)type_schema = {"Survived": "categorical", "Embarked": "categorical"}# We can set the type_schema only for the variables that we are certain of their types. All the other will be automatically inferred.
report = ProfileReport(df, title="Titanic EDA", type_schema=type_schema)report.to_file("report.html")
5. 自定义报告的外观
在某些情况下,用户可能希望根据个人喜好或公司品牌来自定义报告的外观。ydata-profiling提供了两个主要的自定义方面:HTML报告的样式和其中包含的可视化和图表的样式
5.1 自定义报告的主题
报告的多个方面都可以进行自定义。下表显示了可用的设置:
| 参数 | 类型 | 默认 | 描述 |
|---|---|---|---|
| html.minify_html | bool | True | 如果为True,则使用htmlmin包对输出的HTML进行最小化处理。 |
| html.use_local_assets | bool | True | 如果为True,则所有资源(样式表、脚本、图片)将被存储在本地。如果为False,则使用CDN来提供部分样式表和脚本。 |
| html.inline | boolean | True | 如果为True,则所有资源都包含在报告中。如果为False,则创建一个Web导出,其中所有资源都存储在“[REPORT_NAME]_assets/”目录中。 |
| html.navbar_show | boolean | True | 是否在报告中包含导航栏。 |
| html.style.theme | string | None | 选择开机自检主题。可选项:平坦(深色)和团结(橙色) |
| html.style.logo | string | base64 编码的徽标,显示在导航栏中 | |
| html.style.primary_color | string | #337ab7 | 报告中使用的主色调。 |
| html.style.full_width | boolean | False | 默认情况下,报告的宽度是固定的。如果设置为 “True”,则使用屏幕全宽。 |
向底层 matplotlib 可视化引擎传递参数的一种方法是在计算剖面图时使用 plot 参数。可以使用关键对 image_format: “png”,并使用 dpi: 800 更改图像的分辨率。举例如下
profile = ProfileReport(planets,title="Pandas Profiling Report",explorative=True,plot={"dpi": 200, "image_format": "png"},
)
饼图用于绘制分类(或布尔)特征中的类别频率。默认情况下,如果一个特征的独特值不超过 10 个,则该特征被视为分类特征。这个阈值可以通过 plot.pie.max_unique 设置来配置。
如果特征未被视为分类特征,则不会显示饼图。因此,可以通过设置:plot.pie.max_unique = 0 来删除所有饼图。
饼图的颜色可以通过 plot.pie.colors 设置配置为任何可识别的 matplotlib 颜色。
profile = ProfileReport(pd.DataFrame([1, 2, 3]))
profile.config.plot.pie.colors = ["gold", "b", "#FF796C"]
相关矩阵和缺失值概览等可视化工具中使用的调色板也可以通过 plot 参数进行自定义。要自定义相关矩阵使用的调色板,请使用相关键:
from ydata_profiling import ProfileReportprofile = ProfileReport(df,title="Pandas Profiling Report",explorative=True,plot={"correlation": {"cmap": "RdBu_r", "bad": "#000000"}},
)
同样,缺失值的调色板也可以使用missing参数来更改:
from ydata_profiling import ProfileReportprofile = ProfileReport(df,title="Pandas Profiling Report",explorative=True,plot={"missing": {"cmap": "RdBu_r"}},
)
相关文章:

python——ydata-profiling介绍与使用
ydata-profiling介绍与使用 ydata-profiling的作用ydata-profiling的安装与简单使用ydata-profiling的结果结构 ydata-profiling的实际应用场景1. 数据集比较2. 时间序列报告3. 对大型数据集进行概要分析4. 处理敏感数据5. 自定义报告的外观 ydata-profiling的作用 ydata-prof…...

(纯c)数据结构之------>链表(详解)
目录 一. 链表的定义 1.链表的结构. 2.为啥要存在链表及链表的优势. 二. 无头单向链表的常用接口 1.头插\尾插 2.头删\尾删 3.销毁链表/打印链表 4.在pos位置后插入一个值 5.消除pos位置后的值 6.查找链表中的值并且返回它的地址 7.创建一个动态开辟的结点 三.顺序表与链表…...

postman接口自动化测试框架实战!
什么是自动化测试 把人对软件的测试行为转化为由机器执行测试行为的一种实践。 例如GUI自动化测试,模拟人去操作软件界面,把人从简单重复的劳动中解放出来。 本质是用代码去测试另一段代码,属于一种软件开发工作,已经开发完成的用…...

Apache Doris 入门教程35:多源数据目录
概述 多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。 在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接…...

响应式web-PC端web与移动端web(H5)兼容适配 选型方案
背景 项目需要,公司已经有一套PC端web,需要做一套手机端浏览器可用的,但是又想兼容pc端,适配的web项目。 以下是查阅到响应布局现成的开源模版。根据自己技术栈,vue2,js来搜索相关的开源项目。 RuoYi 使用若依快速…...

Redis持久化之RDB解读
目录 什么是RDB 配置位置参数解读 如何使用 自动触发 手动触发 save bgsave RDBRDB持久化文件的恢复 正常恢复 恢复失败处理方法 RDB优势 RDB 缺点 redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘…...

四维图新 minemap实现地图漫游效果
原理就是不断改变地图中心点,改变相机角度方向,明白这一点,其他地图引擎譬如cesium都可效仿,本人就是通过cesium的漫游实现四维图新的漫游,唯一不足的是转弯的时候不能丝滑转向,尝试过应该是四维图新引擎的…...
centos7安装MySQL8
Centos7安装MySQL8 MySQL版本:8.0.34 1.安装前准备 (1)查看是否安装mariadb [rootkb135 ~]# rpm -qa|grep mariadb (2)卸载mariadb并检查是否卸干净 [rootkb135 ~]# rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x8…...

【IMX6ULL驱动开发学习】10.Linux I2C驱动实战:AT24C02驱动设计流程
前情回顾:【IMX6ULL驱动开发学习】09.Linux之I2C框架简介和驱动程序模板_阿龙还在写代码的博客-CSDN博客 目录 一、修改设备树(设备树用来指定引脚资源) 二、编写驱动 2.1 i2c_drv_read 2.2 i2c_drv_write 2.3 完整驱动程序 三、上机测…...
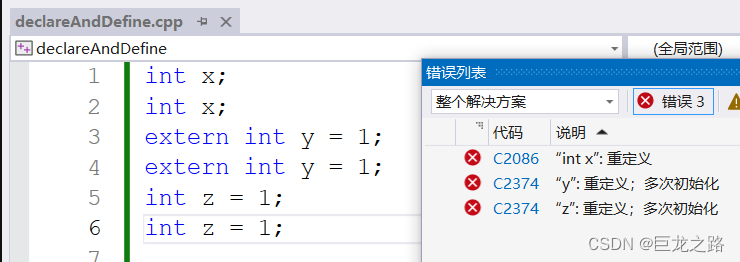
【C++】详解声明和定义
2023年8月28日,周一下午 研究了一个下午才彻底弄明白... 写到晚上才写完这篇博客。 目录 声明和定义的根本区别结构体的声明和定义声明结构体 定义结构体类的声明和定义函数的定义和声明声明函数 定义函数变量声明和定义声明变量定义变量 声明和定义的根本区别 …...

掌握C/C++协程编程,轻松驾驭并发编程世界
一、引言 协程的定义和背景 协程(Coroutine),又称为微线程或者轻量级线程,是一种用户态的、可在单个线程中并发执行的程序组件。协程可以看作是一个更轻量级的线程,由程序员主动控制调度。它们拥有自己的寄存器上下文…...

MyBatis-Plus的分页配置类
文章目录 package com.itheima.reggie.config;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; imp…...
)
排序算法-选择排序(Java)
选择排序 选择排序 (selection sort)的工作原理非常直接:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。 算法原理 排序数组:(2 4 3 1 5 2) …...

SpringBoot 怎么返回html界面
方法一: (1)html文件要放在resource下的static目录下(没有static 自己就创建一个文件夹) (2)在application.yml 中配置视图解析器 spring:mvc:view:prefix: /suffix: .html (3&a…...

watch computed 和 method
在Vue中,watch computed 和 method有啥区别,有啥作用,适用于何种情景并代码举例 在Vue中,watch、computed和methods是三种不同的属性,用于处理不同的场景和需求。 watch:watch用于监听数据的变化并执行相…...

数据结构,线性表有哪些
线性表是一种常见的数据结构,它的特点是数据元素之间存在一对一的线性关系。根据线性表的存储方式和实现方式,线性表主要有以下几种: 1. 顺序表(Sequential List): - 通常使用数组实现。 - 元素在内存中是连续…...

服务间通过Feign相互调用报错,参数是MultiparFile、参数是POJO报错
目录 1.Feign传文件报错,Feign不支持上传文件需要借助外面的依赖才可以实现上传 2.服务之间通过Feign相互调用传递DTO(实体对象)报错 1.Feign传文件报错,Feign不支持上传文件需要借助外面的依赖才可以实现上传 具体报错内容: FileUploadException: the request was reje…...

Flutter系列文章-Flutter应用优化
当涉及到优化 Flutter 应用时,考虑性能、UI 渲染和内存管理是至关重要的。在本篇文章中,我们将通过实例深入讨论这些主题,展示如何通过优化技巧改进你的 Flutter 应用。 代码性能优化 1. 使用 const 构造函数 在构建小部件时,尽…...

opencv案例03 -基于OpenCV实现二维码生成,发现,定位,识别
1.二维码的生成 废话不多说,直接上代码 # 生成二维码 import qrcode# 二维码包含的示例数据 data "B0018" # 生成的二维码图片名称 filename "qrcode.png" # 生成二维码 img qrcode.make(data) # 保存成图片输出 img.save(filename)img.sh…...

叠螺式污泥脱水机的要点及价格分析
诸城市鑫淼环保小编带大家了解一下叠螺式污泥脱水机的要点及价格分析 设备工作步骤 叠螺脱水机在工作时分为3个步骤,分别是稀释、脱水、自洗濯: 1、稀释:当螺旋推进轴迁移转变时,设在推进轴核心的多重固活叠片挪动,在重…...

RISC-V在AI与边缘计算领域的崛起:从开放架构到异构计算新范式
1. RISC-V在AI与边缘计算领域的崛起:一场意料之中的“超预期” 如果你最近关注处理器架构的新闻,大概率会被“RISC-V在AI领域超预期增长”这类标题刷屏。这不仅仅是媒体的噱头,而是正在硅谷和全球半导体设计实验室里发生的真实故事。作为一名…...

终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具
终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘资源下载卡在提取码这一步而烦恼吗?每次遇到需要密码的分享链接,都要…...

VRoid Studio中文汉化终极指南:5步完成界面中文化
VRoid Studio中文汉化终极指南:5步完成界面中文化 【免费下载链接】VRoidChinese VRoidStudio汉化插件 项目地址: https://gitcode.com/gh_mirrors/vr/VRoidChinese VRoid Studio中文汉化插件是专为中文用户设计的开源解决方案,能够将VRoid Studi…...
)
别再只用AES了!手把手教你用Java BouncyCastle库实现SM4国密加密(附完整工具类)
国密算法实战:用Java BouncyCastle实现SM4加密的完整指南 在数据安全领域,国际通用算法长期占据主导地位,但随着技术自主可控需求的提升,国产密码算法正成为企业级应用的新选择。SM4作为我国商用密码标准体系中的重要对称加密算法…...

手机市场饱和下的细分突围:从功能过剩到场景化专用设备
1. 市场饱和与行业焦虑的根源手机销量下滑,这已经不是新闻,而是悬在所有制造商头顶的一把达摩克利斯之剑。当全球73亿人口中,手机用户数达到惊人的68亿时,市场饱和的警钟就已经敲响。这不是一个简单的周期性波动,而是整…...

MyScaleDB:基于SQL的向量数据库实战,实现混合查询与AI应用开发
1. 项目概述:当向量数据库遇见SQL如果你最近在折腾大模型应用,尤其是想给AI应用加上“长期记忆”或者实现精准的文档问答,那你大概率已经听过“向量数据库”这个词。从早期的Milvus、Pinecone,到后来各大云厂商纷纷入局࿰…...

5分钟掌握Nexus Mods App:告别模组管理烦恼的终极解决方案
5分钟掌握Nexus Mods App:告别模组管理烦恼的终极解决方案 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为游戏模组冲突、依赖缺失而烦恼吗?N…...

README工匠技能:从自动化工具到工程化实践,打造项目黄金门面
1. 项目概述:一个为README注入灵魂的“工匠”技能 在开源社区和项目协作中,README文件就是项目的“门面”和“说明书”。一个优秀的README,能瞬间抓住潜在用户或贡献者的眼球,清晰地传达项目价值、快速引导上手,甚至能…...

FreeRTOS和RT-Thread的内存管理实战:如何正确使用pvPortMalloc与rt_malloc替代C库malloc
FreeRTOS与RT-Thread内存管理实战:从标准库陷阱到RTOS最佳实践 在嵌入式实时操作系统开发中,动态内存分配就像高空走钢丝——一步失误可能导致系统崩溃。传统C库的malloc/free在RTOS环境中如同穿着拖鞋走钢丝,而pvPortMalloc和rt_malloc则是专…...

基于LLM的风格化内容生成:从提示工程到系统化实践
1. 项目概述:一个基于AI的创意内容生成工具最近在折腾AI应用开发,发现了一个挺有意思的项目,叫“jasonkneen/vibeclaw”。乍一看这个名字,可能会有点摸不着头脑,但简单来说,它是一个利用大型语言模型&#…...