2023-02-20 leetcode-AccountsMerge
摘要:
记录对leetcode-AccountsMerge的反思
要求:
Given a list accounts, each element accounts[i] is a list of strings, where the first element
accounts[i][0] is a name, and the rest of the elements are emails representing emails of the
account.
*
Now, we would like to merge these accounts. Two accounts definitely belong to the same person if
there is some email that is common to both accounts. Note that even if two accounts have the same
name, they may belong to different people as people could have the same name. A person can have
any number of accounts initially, but all of their accounts definitely have the same name.
*
After merging the accounts, return the accounts in the following format: the first element of each
account is the name, and the rest of the elements are emails in sorted order. The accounts
themselves can be returned in any order.
*
Example 1:
*
Input:
accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"],
["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]]
Output: [["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John",
"johnnybravo@mail.com"], ["Mary", "mary@mail.com"]]
*
Explanation:
The first and third John's are the same person as they have the common email "johnsmith@mail.com".
The second John and Mary are different people as none of their email addresses are used by other
accounts.
We could return these lists in any order, for example the answer [['Mary', 'mary@mail.com'],
['John', 'johnnybravo@mail.com'],
['John', 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com']] would still be accepted.
*
Note:
The length of accounts will be in the range [1, 1000].
The length of accounts[i] will be in the range [1, 10].
The length of accounts[i][j] will be in the range [1, 30].
数据结构相关:
- std::vector
- std::map
- std::unordered_map
题解:
题解一:
// Declare variables for accounts, mapping and result
vector<vector<string>> accounts;
unordered_map<string, string> mapping;
vector<vector<string>> result;// Add accounts to 'accounts'
// ...// Traverse accounts
for (auto &a : accounts) {// Take the first email address and consider it as the root string root = a[1];for (int i = 2; i < a.size(); i++) {// If current email is already present in map if (mapping.find(a[i]) != mapping.end())root = mapping[a[i]]; // Choose its parent else keep root // Make an entry for all those email address mapping[a[i]] = root;}
}// Create the necessary structure for result
unordered_map<string, set<string>> mp;
for (auto &p : mapping) mp[p.second].insert(p.first);// Form the resultant vector
for (auto &pp : mp) {vector<string> emails(pp.second.begin(), pp.second.end());emails.insert(emails.begin(), pp.first);result.push_back(emails);
}return result;
题解二:
Bad Performance Solution
//Bad Performance Solution
class Solution_Time_Limit_Exceeded {
public:// We can orginze all relevant emails to a chain,// then we can use Union Find algorithm// Besides, we also need to map the relationship between name and email.vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {unordered_map<string, string> emails_chains; // email chainsunordered_map<string, string> names; // names to email chains' head//initializationfor(int i = 0 ; i<accounts.size();i++) {auto& account = accounts[i];auto& name = account[0];for (int j=1; j<account.size(); j++) {auto& email = account[j];if ( names.find(email) == names.end() ) {emails_chains[email] = email;names[email] = name;}join(emails_chains, account[1], email);}}//reform the emailsunordered_map<string, set<string>> res;for( auto& acc : accounts ) {string e = find(emails_chains, acc[1]);res[e].insert(acc.begin()+1, acc.end());}//output the resultvector<vector<string>> result;for (auto pair : res) {vector<string> emails(pair.second.begin(), pair.second.end());emails.insert(emails.begin(), names[pair.first]);result.push_back(emails);}return result;}string find(unordered_map<string, string>& emails_chains,string email) {while( email != emails_chains[email] ){email = emails_chains[email];}return email;}bool join(unordered_map<string, string>& emails_chains,string& email1, string& email2) {string e1 = find(emails_chains, email1);string e2 = find(emails_chains, email2);if ( e1 != e2 ) emails_chains[e1] = email2;return e1 == e2;}
};题解三:
Performance Tunning
//
// Performance Tunning
// -----------------
//
// The above algorithm need to do string comparison, it causes lots of efforts
// So, we allocated the ID for each email, and compare the ID would save the time.
//
// Furthermore, we can use the Group-Email-ID instead of email ID,
// this would save more time.
//
class Solution {
public:// We can orginze all relevant emails to a chain,// then we can use Union Find algorithm// Besides, we also need to map the relationship between name and email.vector<vector<string>> accountsMerge(vector<vector<string>>& accounts) {unordered_map<string, int> emails_id; //using email ID for union findunordered_map<int, int> emails_chains; // email chainsunordered_map<int, string> names; // email id & name//initialization & joinfor(int i = 0 ; i<accounts.size();i++) {// using the account index as the emails group ID,// this could simplify the emails chain.emails_chains[i] = i;auto& account = accounts[i];auto& name = account[0];for (int j=1; j<account.size(); j++) {auto& email = account[j];if ( emails_id.find(email) == emails_id.end() ) {emails_id[email] = i;names[i] = name;}else {join( emails_chains, i, emails_id[email] );}}}//reform the emailsunordered_map<int, set<string>> res;for(int i=0; i<accounts.size(); i++) {int idx = find(emails_chains, i);res[idx].insert(accounts[i].begin()+1, accounts[i].end());}//output the resultvector<vector<string>> result;for (auto pair : res) {vector<string> emails( pair.second.begin(), pair.second.end() );emails.insert(emails.begin(), names[pair.first]);result.push_back(emails);}return result;}int find(unordered_map<int, int>& emails_chains, int id) {while( id != emails_chains[id] ){id = emails_chains[id];}return id;}bool join(unordered_map<int, int>& emails_chains, int id1, int id2) {int e1 = find(emails_chains, id1);int e2 = find(emails_chains, id2);if ( e1 != e2 ) emails_chains[e1] = e2;return e1 == e2;}
};
相关文章:

2023-02-20 leetcode-AccountsMerge
摘要: 记录对leetcode-AccountsMerge的反思 要求: Given a list accounts, each element accounts[i] is a list of strings, where the first element accounts[i][0] is a name, and the rest of the elements are emails representing emails of the account. * Now, w…...

中国高速公路行业市场规模及未来发展趋势
中国高速公路行业市场规模及未来发展趋势编辑中国高速公路行业市场规模正在迅速增长。随着中国经济的快速发展和城市化的加速,对交通基础设施的需求也在不断增加。高速公路是最有效的交通工具,可以大大缩短交通时间,提高出行效率。因此&#…...
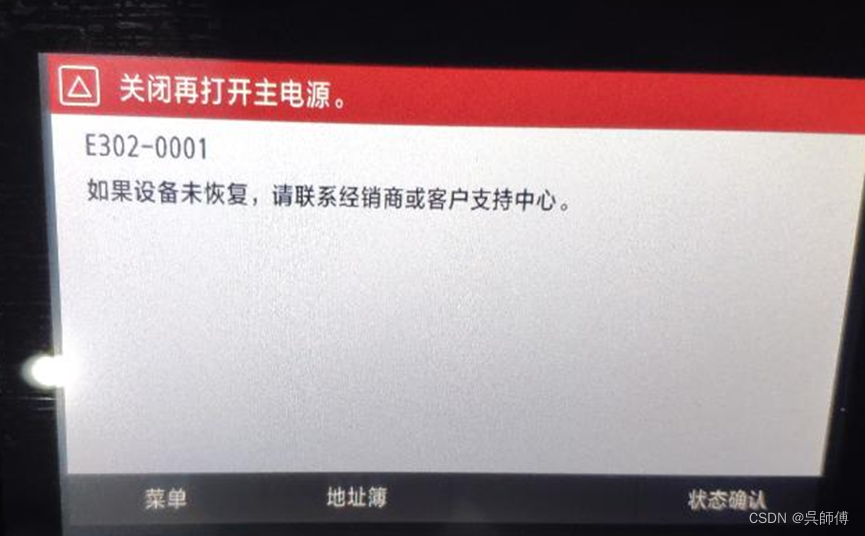
佳能iC MF645CX彩色激光多功能打印机报E302-0001故障码检修
故障现象: 一台佳能iC MF645CX彩色激光多功能一体机开机报E302-0001故障代码,如果设备未恢复,请联系经销商或客户支持中心。 维修分析: 佳能iC MF645CX彩色激光多功能一体机开机报E302-0001故障代码的...

加密越来越简单——用JavaScript实现数据加密和解密
加密越来越简单——用JavaScript实现数据加密和解密概念常用算法1. MD5加密算法2. SHA-1加密算法3. AES加密算法代码示例结论总结在当今互联网的世界中,安全性越来越受到关注,数据加密成为了必不可少的一环。Javascript作为前端开发的主要语言之一&#…...

线程池的使用场景
学习整理线程池的使用场景。...

图像分割算法
图像分割算法阈值分割固定阈值自适应阈值大津阈值(OTSU)最大熵阈值连通域分析区域生长分水岭阈值分割、连通域分析、区域生长、分水岭 阈值分割 固定阈值、自适应阈值(adaptiveThreshold)、大津阈值(OTSU)、最大熵阈值(KSW) 固定阈值 固定阈值的调用函数: //Input…...
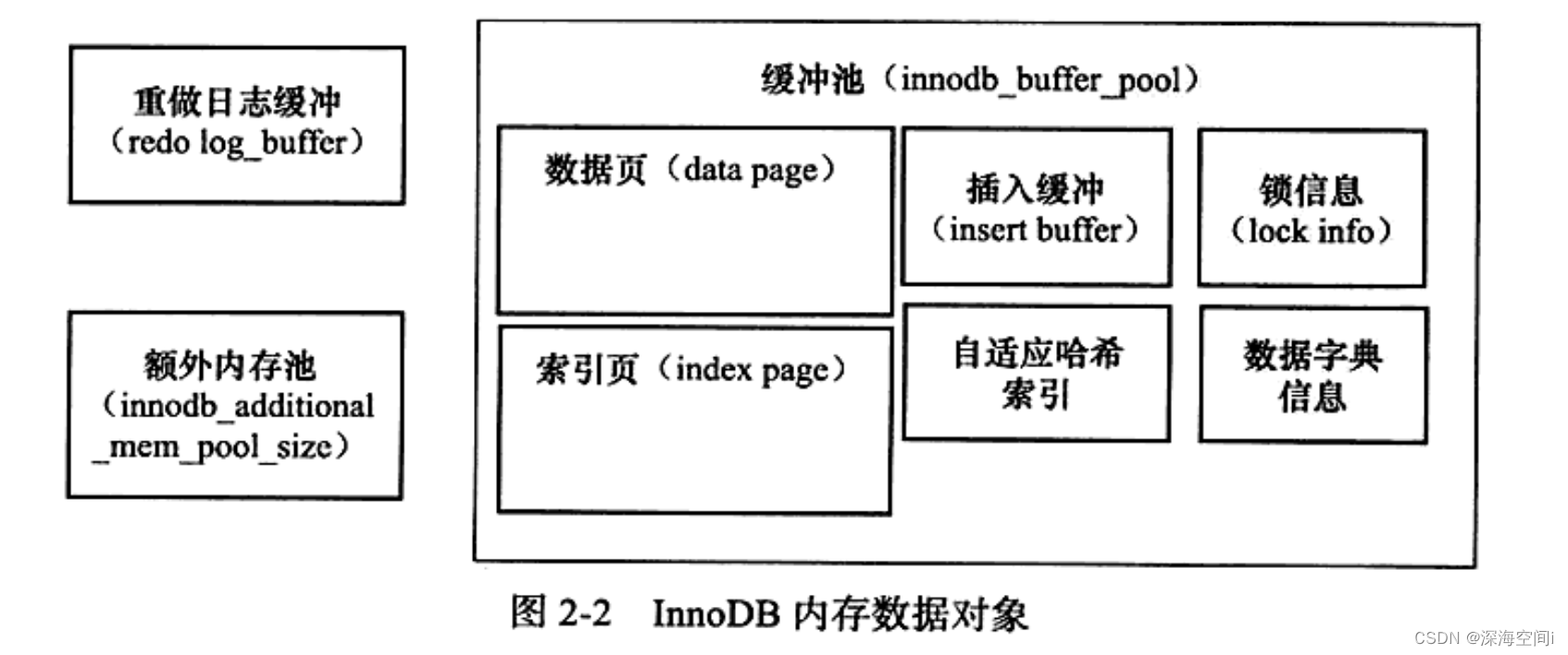
《mysql技术内幕:innodb存储引擎》笔记
任何时候Why都比What重要;不要相信任何的“神话”,学会自己思考;不要墨守成规,大部分人都知道的事情可能是错误的;不要相信网上的传言,去测试,根据自己的实践做出决定;花时间充分地思考,敢于提出质疑。1.MYSQL被设计为一个单进程多…...

windows与linux系统ntp服务器配置
一. windows 打开windows终端(管理员),顺序输入以下指令 net stop w32time w32tm /unregister w32tm /register net start w32time w32tm /resync net stop w32time net start w32timewin r 输入regedit,打开注册表。 ①将HKEY_…...
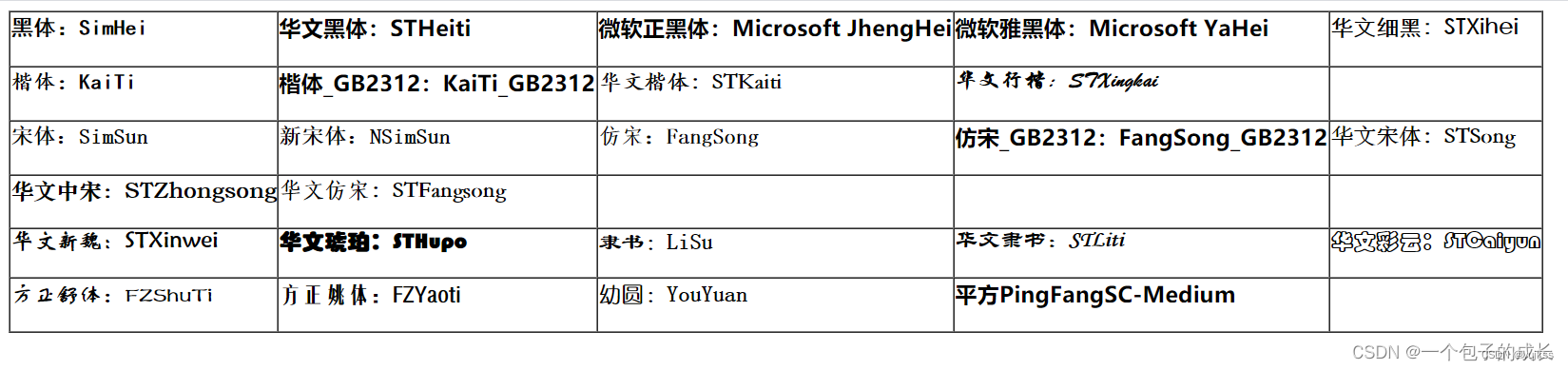
html常用font-family设置字体样式
<table border"1" cellpadding"0" cellspacing"0" ><tr><td><h3 style"font-family: 黑体;">黑体:SimHei</h3></td><td><h3 style"font-family: 华文黑体;">华…...
数据库事务AICD以及隔离级别
目录一.事务的ACID二.隔离级别三.并发事务中的问题1.脏写2.脏读3.不可重复读4.幻读四.MVCC机制五.读锁与写锁六.大事务的影响七.事务优化一.事务的ACID 原子性(Atomicity):一个事务中的所有操作,要么全部成功,要么失败全部回滚,不…...
VScode之ssh基础配置)
(4)VScode之ssh基础配置
VScode和SSH基础配置问题集合 Author:onceday date:2022年8月31日 本文记录linux的ssh和vscode开发环境搭建之路。 参考文档: 离线安装vscode Once Day CSDN博客关于x86、x86_64/x64、amd64和arm64/aarch64 Bogon 简书arm64和aarch64之间…...

springcloud-1环境搭建、service provider
搭建项目环境创建新项目,选择archetype-webapp,创建一个父项目,该父项目会去管理多个微服务模块(module)项目设置Settings->Editor->File Encoding:Global/Project Encoding 改为UTF-8Default encoding for properties files:默认属性文…...
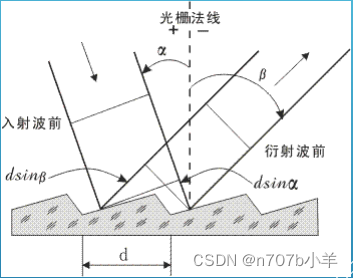
光谱仪工作过程及重要参数定义
标题光谱仪工作过程CCD、PDA薄型背照式BT-CCD狭缝Slit暗电流Dark Current分辨率Resolution色散Dispersion光栅和闪耀波长Grating波长精度、重复性和准确度Precision带宽Band widthF数F/#光谱仪工作过程 CCD、PDA 电荷耦合器件(Charger Coupled Device,缩…...
W800|iot|HLK-W800-KIT-PRO|AliOS|阿里云| |官方demo|学习(1):板载AliOS系统快速上手
板载系统简介 HLK-W800-KIT-PRO 是海凌科电子面向开发者,采用了联盛德 w800 方案,带有一个RGB三色灯,集成了 CHT8305C 温湿度传感器的多功能开发板,用户可以在上面学习、研究嵌入式系统和物联网产品的开发,本套设备运行…...

字节终面,一道Linux题难住我了
以下是一道难道系数中高并且高频出现的linux面试题,题目具体要求如下: linux面试题: 某文件有多列数据,空格隔开,统计第n列单词,打印出现频率最高的5个单词。 解答这道面试题需要用到3个linux命令ÿ…...
三、NetworkX工具包实战2——可视化【CS224W】(Datawhale组队学习)
开源内容:https://github.com/TommyZihao/zihao_course/tree/main/CS224W 子豪兄B 站视频:https://space.bilibili.com/1900783/channel/collectiondetail?sid915098 斯坦福官方课程主页:https://web.stanford.edu/class/cs224w NetworkX…...
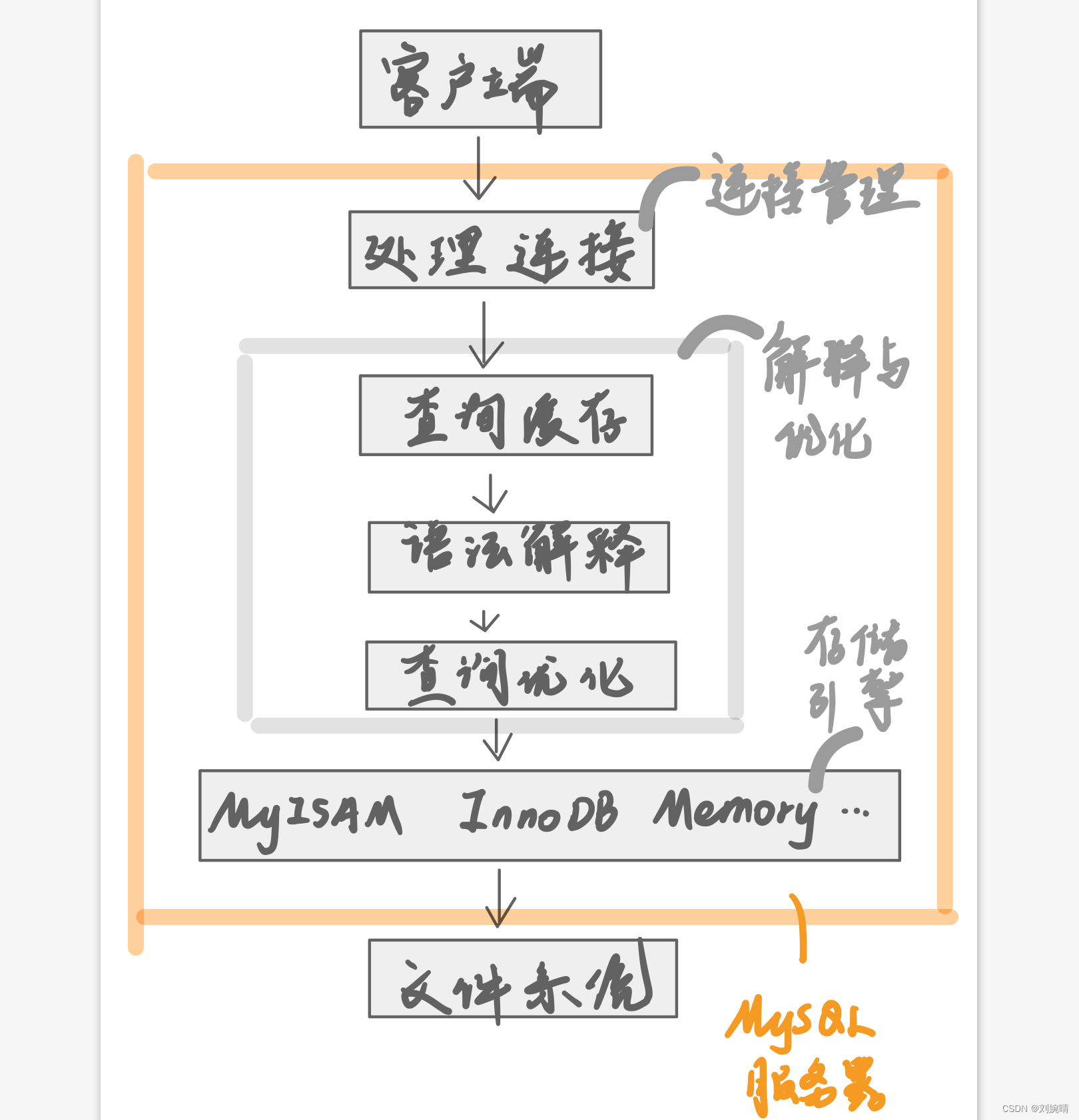
【MySQL】MySQL 架构
一、MySQL 架构 C/S 架构,即客户端/服务器架构。服务器程序直接和我们存储的数据打交道,多个客户端连接这个服务器程序。客户端发送请求,服务器响应请求。 MySQL 数据库实例 :即 MySQL 服务器的进程 (我们使用任务管理…...
Python日期时间模块
Python 提供了 日期和时间模块用来处理日期和时间,还可以用于格式化日期和时间等常见功能。 时间间隔是以秒为单位的浮点小数。每个时间戳都以自从 1970 年 1 月 1 日午夜(历元)经过了多长时间来表示。 一、time模块使用 Time 模块包含了大…...
)
学以致用——植物信息录入1.0(selenium+pandas+os+tkinter)
目的 书接上文,学以致用——植物信息录入(seleniumpandasostkinter) 更新要点: tkinter界面:自动登录、新增(核心功能)、文件夹选择、流程台selenium自动化操作:验证码识别excel数据…...
什么是压敏电阻
下面的这些都是压敏电阻,常常用在一些电源和信号的浪涌防护电路中。这个是它的电路符号,电路中常用RV表示。当压敏电阻两端电压小于压敏电压时,压敏电阻相当于一个阻值非常大的电阻。当压敏电阻两端电压大于压敏电压时,压敏电阻相…...

glm-5-free不输付费版!DMXAPIAI模型聚合平台,如何调用免费大模型API?
中关村论坛发布AutoGLM 沉思智能体,具备深度研究与电脑操作双重能力,GLM-5.1 编程能力与全球顶尖模型 Claude Opus 4.6 差距仅2.6 分,整体呈现技术迭代、商业化与资本市场的全面提速态势。智谱AI正式推出GLM-5-free开源模型,凭借与…...

StreamLib嵌入式流处理库:高效HTTP通信与缓冲优化
1. StreamLib 嵌入式流处理库深度解析:面向资源受限系统的高效网络与HTTP通信设计在嵌入式系统开发中,尤其是基于Arduino生态的MCU平台(如ESP32、ESP8266、STM32 Arduino Core),网络通信性能瓶颈往往并非来自物理层带宽…...

STM32大棚花卉物联网护养系统设计与实现
1. 项目概述这个大棚花卉护养系统是我去年为一个花卉种植基地设计的物联网解决方案。当时客户反映传统人工管理方式效率低下,经常出现浇水不及时、温度控制不精准等问题。经过三个月的开发和调试,这套系统成功将花卉产量提升了30%,同时减少了…...

给 Claude 装个仪表盘,时刻监测Token消耗跟任务进度
一、 什么是 Claude HUD?HUD 原意是“平视显示器”,通常出现在战斗机飞行员的头盔或高端汽车的挡风玻璃上。Claude HUD 干的也是这件事。它是一个专门为 Claude Code 设计的插件,会在你的终端底部常驻一个状态栏。有了它,你不再需…...

技术赋能B端拓客:号码核验行业的迭代与价值升级
2026年,数字经济高质量发展进入深水区,B端市场的竞争逻辑已从“规模制胜”转向“效能突围”,拓客环节的精细化、高效化成为企业构建核心竞争力的关键。号码核验作为B端拓客的前置基础性环节,直接关联线索质量、人力效能与拓客投入…...

Windows下OpenClaw安装详解:对接Kimi-VL-A3B-Thinking图文模型
Windows下OpenClaw安装详解:对接Kimi-VL-A3B-Thinking图文模型 1. 为什么选择OpenClaw与Kimi-VL-A3B-Thinking组合 去年我在处理大量图文资料归档时,发现手动整理效率极低。直到尝试将OpenClaw与Kimi-VL-A3B-Thinking模型对接后,才真正实现…...

2025届学术党必备的十大降重复率平台推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 若维普系统检测出高AI生成内容,那么可采用如下方法来降低AI率:将长句…...

FF14副本动画跳过插件:5分钟终极配置指南,告别冗长等待
FF14副本动画跳过插件:5分钟终极配置指南,告别冗长等待 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip FF14副本动画跳过插件是专为《最终幻想14》国服玩家设计的智能工具&#…...

所有下载都一定要直接从个人服务器直接下载--------因为个人宽带的上传速度一点也不慢
可以看到居然速度高达10M/S如果你直接从云服务器下载速度就非常慢:这就是1M的宽带,所以很慢。所以如果是下载apk文件,一定要从自己的服务器直接下载:就是带10001端口号的个人服务器。...

星闪实战指南:10分钟掌握WS63 SDK任务调度与调试技巧
1. 星闪WS63 SDK任务调度基础 第一次接触星闪WS63 SDK的任务调度功能时,我完全被各种API搞晕了。经过几个项目的实战,才发现这套任务管理系统设计得非常巧妙。简单来说,它就像个智能管家,能帮你把各种工作安排得井井有条。 任务调…...