多模态大语言模型arxiv论文略读(111)
SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
➡️ 论文标题:SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs
➡️ 论文作者:Yuanyang Yin, Yaqi Zhao, Yajie Zhang, Ke Lin, Jiahao Wang, Xin Tao, Pengfei Wan, Di Zhang, Baoqun Yin, Wentao Zhang
➡️ 研究机构: 中国科学技术大学、北京大学、快手科技
➡️ 问题背景:多模态大语言模型(MLLMs)在多模态感知和推理任务中展现了显著的能力,通常由视觉编码器、适配器和大语言模型(LLM)组成。适配器作为视觉和语言组件之间的关键桥梁,其训练通常依赖于图像级监督,这往往导致显著的对齐问题,削弱了LLMs的能力,限制了多模态LLMs的潜力。
➡️ 研究动机:现有的训练范式在多模态大语言模型中存在视觉和文本特征对齐不足的问题,尤其是在预训练阶段,视觉特征与文本特征之间的不匹配导致了模型理解能力和生成能力的不一致。为了改善这一问题,研究团队提出了一种新的监督嵌入对齐方法(Supervised Embedding Alignment, SEA),旨在通过显式监督精确对齐视觉令牌与LLM的嵌入空间,从而提高模型的性能和可解释性。
➡️ 方法简介:研究团队提出了一种新的监督对齐范式SEA,该方法利用视觉-语言预训练模型(如CLIP)来生成每个视觉令牌的语义标签,并通过对比学习在预训练阶段直接对齐视觉令牌与LLM的嵌入空间。具体来说,SEA通过两个关键方面改进了对齐:1) 通过细粒度的语义标签进行令牌级对齐;2) 通过对比学习损失与LLM预测损失的结合来更新适配器,从而增强其对齐能力。
➡️ 实验设计:研究团队在8个基准数据集上进行了实验,包括VQAv2、TextVQA、GQA、ScienceQA-IMG、MMBench、POPE、VizWiz和MM-Vet。实验结果表明,SEA显著提高了LLaVA-1.5在这些基准上的性能,而无需额外的注释、数据或推理成本。此外,SEA在保持语言模型能力的同时,提高了多模态任务的性能,展示了其通用性和成本效益。
AppAgent v2: Advanced Agent for Flexible Mobile Interactions
➡️ 论文标题:AppAgent v2: Advanced Agent for Flexible Mobile Interactions
➡️ 论文作者:Yanda Li, Chi Zhang, Wanqi Yang, Bin Fu, Pei Cheng, Xin Chen, Ling Chen, Yunchao Wei
➡️ 研究机构: University of Technology Sydney、Tencent、Beijing Jiaotong University、Westlake University
➡️ 问题背景:随着多模态大语言模型(MLLM)的发展,基于LLM的视觉代理在软件界面,尤其是图形用户界面(GUI)中,正逐渐发挥更大的作用。然而,准确识别GUI仍然是一个关键挑战,影响了多模态代理的决策准确性。传统的基于文本的代理在处理视觉数据和其他模态时存在局限性,特别是在移动和操作系统平台等复杂环境中,需要执行多步推理、提取和整合信息,并对用户输入做出适应性响应。
➡️ 研究动机:现有的多模态代理在处理不熟悉的或独特的界面元素时,由于依赖于标准解析器,其操作灵活性受到限制,影响了其在多样化应用中的整体有效性。为了解决这些局限性,研究团队提出了一种新的多模态代理框架,旨在适应动态的移动环境和多样化应用,通过构建灵活的动作空间和结构化的存储系统,增强代理与GUI的交互能力和对新环境任务的适应性。
➡️ 方法简介:研究团队开发了一种多模态代理框架,该框架结合了解析器和视觉特征,构建了一个灵活的动作空间,增强了与GUI的交互能力。框架通过两个主要阶段运行:探索阶段和部署阶段。在探索阶段,代理自主分析和记录未知UI元素和应用的功能,构建一个强大的知识库。在部署阶段,代理利用RAG技术动态访问和更新知识库,显著提高了其在新场景中的适应能力和决策精度。
➡️ 实验设计:研究团队在三个不同的基准测试上进行了实验,涵盖了多个应用的任务。实验结果包括定量分析和用户研究,验证了该方法在各种智能手机应用中的优越性和鲁棒性,证明了其在真实场景中的适应性、用户友好性和效率。
CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion
➡️ 论文标题:CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion
➡️ 论文作者:Yunlong Tang, Gen Zhan, Li Yang, Yiting Liao, Chenliang Xu
➡️ 研究机构: ByteDance、University of Rochester
➡️ 问题背景:视频显著性预测旨在识别视频中吸引人类注意力和注视的区域,这一过程受到视频的自下而上的特征和自上而下的记忆和认知过程的影响。语言在这一过程中扮演了重要角色,通过塑造视觉信息的解释来引导注意力。然而,现有的方法主要集中在建模感知信息,而忽视了语言在推理过程中的作用,特别是排名线索在显著性预测中的重要性。
➡️ 研究动机:为了弥补现有方法的不足,研究团队提出了一种新的框架CaRDiff(Caption, Rank, and generate with Diffusion),该框架通过整合多模态大语言模型(MLLM)、接地模块和扩散模型,增强了视频显著性预测的能力。具体来说,研究团队引入了一种新的提示方法VSOR-CoT(Video Salient Object Ranking Chain of Thought),利用MLLM和接地模块生成视频内容的字幕,并推断显著对象及其排名和位置,从而生成排名图,指导扩散模型解码最终的显著性图。
➡️ 方法简介:研究团队提出了一种系统的方法,通过构建VSOR-CoT Tuning数据集,评估了不同提示方法对视频显著性预测的影响。VSOR-CoT方法通过链式思维推理生成显著对象的排名,这些排名图与视频帧结合,作为扩散模型的解码条件,以预测最终的显著性图。
➡️ 实验设计:研究团队在MVS和DHF1k两个数据集上进行了实验,评估了CaRDiff在不同条件下的表现。实验设计了不同的因素(如排名图的比例、随机排名图的替换等),以及不同类型的评估指标(如AUC-J、CC、SIM、NSS),以全面评估模型的性能和泛化能力。实验结果表明,CaRDiff在MVS数据集上取得了最先进的性能,并在DHF1k数据集上展示了零样本评估的能力。
MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model
➡️ 论文标题:MaVEn: An Effective Multi-granularity Hybrid Visual Encoding Framework for Multimodal Large Language Model
➡️ 论文作者:Chaoya Jiang, Jia Hongrui, Haiyang Xu, Wei Ye, Mengfan Dong, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang
➡️ 研究机构: 北京大学软件工程国家重点实验室、阿里巴巴集团
➡️ 问题背景:当前的多模态大模型(Multimodal Large Language Models, MLLMs)主要集中在单图像视觉理解上,这限制了它们在多图像场景中解释和整合信息的能力。多图像场景包括基于知识的视觉问答(Knowledge Based VQA)、视觉关系推理(Visual Relation Inference)和多图像推理(Multi-image Reasoning)等,这些场景具有广泛的实际应用价值。
➡️ 研究动机:现有的多模态大模型在处理多图像任务时表现不佳,主要因为这些模型的设计初衷是处理单图像输入。研究团队提出了一种新的多粒度混合视觉编码框架MaVEn,旨在通过结合离散视觉符号序列和连续视觉特征序列,提高多模态大模型在多图像场景中的理解和推理能力。
➡️ 方法简介:MaVEn框架利用离散视觉符号序列来抽象图像中的粗粒度语义概念,同时使用连续高维向量序列来捕捉细粒度的视觉细节。此外,为了减少多图像场景中的输入上下文长度,研究团队还设计了一种基于文本语义的动态视觉特征减少机制。该框架通过多阶段模型训练方法,逐步优化模型的多图像理解能力。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括DemonBench和SEED-Bench,这些数据集涵盖了多图像理解和推理任务以及视频理解任务。实验结果表明,MaVEn在多图像场景中显著提高了模型的理解和推理能力,同时在单图像任务中也表现出色。
Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
➡️ 论文标题:Vintern-1B: An Efficient Multimodal Large Language Model for Vietnamese
➡️ 论文作者:Khang T. Doan, Bao G. Huynh, Dung T. Hoang, Thuc D. Pham, Nhat H. Pham, Quan T. M. Nguyen, Bang Q. Vo, Suong N. Hoang
➡️ 研究机构: HKUST (GZ)、BJUT、Drexel University、University of Oxford
➡️ 问题背景:当前的多模态大语言模型(Multimodal Large Language Models, MLLMs)在处理越南语任务时表现出色,尤其是在光学字符识别(OCR)、文档信息提取和视觉问答(VQA)等任务中。然而,越南语MLLMs的发展受到高质量多模态数据集有限的限制,尤其是在处理特定于越南的文档、图表和场景文本识别方面。
➡️ 研究动机:为了克服现有越南语MLLMs在处理特定于越南的视觉和文本数据时的局限性,研究团队开发了Vintern-1B,这是一个专门针对越南语任务的10亿参数多模态大语言模型。通过整合Qwen2-0.5B-Instruct语言模型和InternViT-300M-448px视觉模型,Vintern-1B在多个越南语基准测试中表现出色,并且适用于各种设备上的应用。
➡️ 方法简介:研究团队构建了一个详细的架构,包括视觉编码器(InternViT-300M-448px)、多层感知机投影器(MLP Projector)和大型语言模型(Qwen2-0.5B-Instruct)。此外,团队还创建了多个越南语多模态数据集,涵盖了一般问答、OCR、文档理解、手写识别和信息提取等任务,以全面训练和评估模型的性能。
➡️ 实验设计:Vintern-1B在多个数据集上进行了训练和测试,包括Vista、Viet-OpenViVQA-gemini-VQA、Viet-Localization-VQA、Viet-OCR-VQA等。实验设计了不同的任务类型和场景,以评估模型在处理越南语多模态数据时的准确性和鲁棒性。通过这些贡献,研究团队旨在推动越南语MLLMs的发展,为研究人员和实践者提供必要的工具和资源,以探索和创新语言和视觉在越南语背景下的交叉应用。
相关文章:
多模态大语言模型arxiv论文略读(111)
SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs ➡️ 论文标题:SEA: Supervised Embedding Alignment for Token-Level Visual-Textual Integration in MLLMs ➡️ 论文作者:Yuanyang Yin, Yaqi Zhao, Yaji…...

网页端 VUE+C#/FastAPI获取客户端IP和hostname
1 IP可以获取,但是发现获取到的是服务端的IP,如何解决呢。 如果采用nginx反向代理,那么可以在conf/nginx.conf文件中配置 location /WebApi/ { proxy_pass http://localhost:5000/; #这个/会替换location种的WebApi路径 #关键,加…...

一个自动反汇编脚本
一、环境 wsl ubuntu18.04、python3.6 二、目的 调试程序,需要分析第三方库。希望能将多个库自动转为汇编文件。 三、使用方法 将该脚本下载,进入wsl,进入到该脚本所有文件夹。 请使用 python 脚本名.py 运行。 1)、运行…...

函数与数列的交汇融合
前情概要 现行的新高考对数列的考查难度增加,那么整理与数列交汇融合的相关题目就显得非常必要了。 典例剖析 依托函数,利用导数,求数列的最值;№ 1 、 \color{blue}{№ 1、} №1、 等差数列 { a n } \{a_{n}\} {an} 的前 n n n 项和为 S n S_{n} Sn, 已知 S 10…...

怎么让自己ip显示外省?一文说清操作
在互联网时代,IP地址不仅关联网络连接,还可能影响IP属地显示。那么,手机和电脑用户怎么让自己IP显示外省?一文说清操作要点。 二、4种主流方法详解 要让自己的IP显示为外省地址,主要有以下几种方法: …...

【Docker】容器安全之非root用户运行
【Docker】容器安全之非root用户运行 1. 场景2. 原 Dockerfile 内容3. 整改结果4. 非 root 用户带来的潜在问题4.1 文件夹读写权限异常4.2 验证文件夹权限 1. 场景 最近有个项目要交付,第三方测试对项目源码扫描后发现一个问题,服务的 Dockerfile 都未指…...

汽车车载软件平台化项目规模颗粒度选择的一些探讨
汽车进入 SDV 时代后,车载软件研发呈现出开源生态构建、电子架构升级、基础软件标准化、本土供应链崛起、AI 原生架构普及、云边协同开发等趋势,这些趋势促使车载软件研发面临新挑战,如何构建适应这些变化的平台化架构成为车企与 Tier 1 的战…...

【八股消消乐】构建微服务架构体系—服务注册与发现
😊你好,我是小航,一个正在变秃、变强的文艺倾年。 🔔本专栏《八股消消乐》旨在记录个人所背的八股文,包括Java/Go开发、Vue开发、系统架构、大模型开发、具身智能、机器学习、深度学习、力扣算法等相关知识点ÿ…...

大数据+智能零售:数字化变革下的“智慧新零售”密码
大数据+智能零售:数字化变革下的“智慧新零售”密码 大家好,今天咱们聊聊一个火到不行的话题:大数据在智能零售中的应用。这个领域,不仅是技术的“硬核战场”,更是商业创新的风口浪尖。谁能玩转数据,谁就能掌控消费者心智,实现销售爆发。 咱们不搞枯燥学术,而是用最“…...

C++_核心编程_菱形继承
4.6.8 菱形继承 菱形继承概念: 两个派生类继承同一个基类 又有某个类同时继承者两个派生类 这种继承被称为菱形继承,或者钻石继承 菱形继承问题: 1. 羊继承了动物的数据, 驼同样继承了动物的数据࿰…...

掌握Git核心:版本控制、分支管理与远程操作
前言 无论热爱技术的阅读者你是希望掌握Git的企业级应用,能够深刻理解Git操作过程及操作原理,理解工作区暂存区、版本库的含义;还是想要掌握Git的版本、分支管理,自由的进行版本回退、撤销、修改等Git操作方式与背后原理和通过分…...
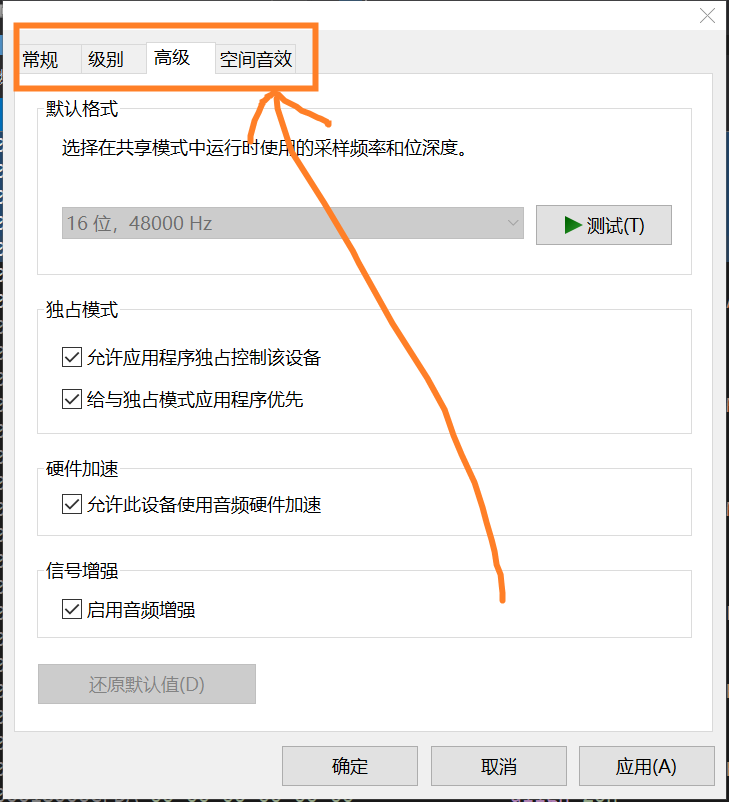
c#,Powershell,mmsys.cpl,使用Win32 API展示音频设备属性对话框
常识(基础) 众所周知,mmsys.cpl使管理音频设备的控制面板小工具, 其能产生一个对话框(属性表)让我们查看和修改各设备的详细属性: 在音量合成器中单击音频输出设备的小图标也能实现这个效果&a…...
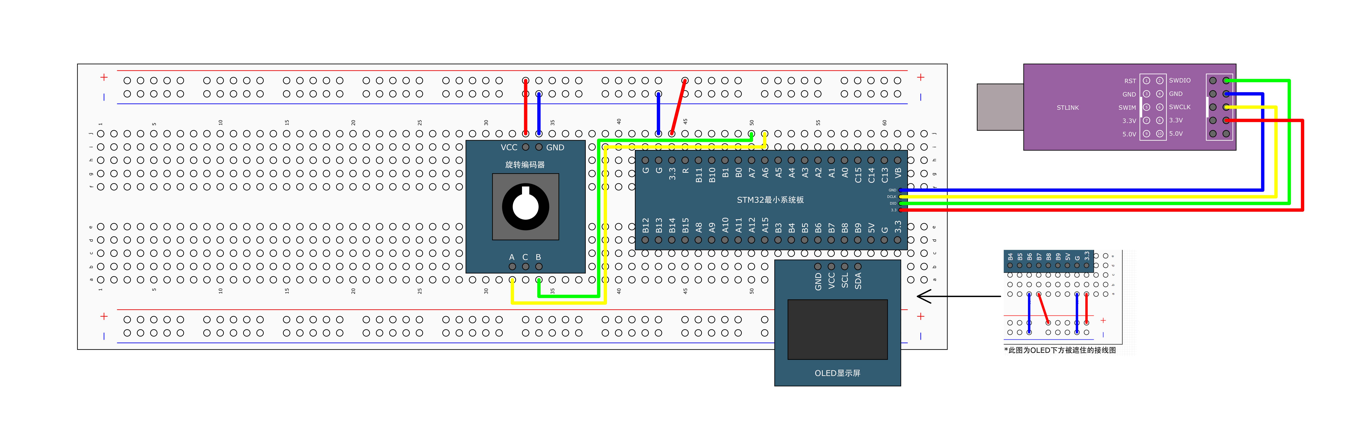
STM标准库-TIM旋转编码器
文章目录 一、编码器接口1.1简介1.2正交编码器1.3编码器接口基本结构**1. 模块与 STM32 配置的映射关系****2. 设计实现步骤(核心流程)****① 硬件规划****② 时钟使能****③ GPIO 配置(对应架构图 “GPIO” 模块)****④ 时基单元…...

深入解析JVM工作原理:从字节码到机器指令的全过程
一、JVM概述 Java虚拟机(JVM)是Java平台的核心组件,它实现了Java"一次编写,到处运行"的理念。JVM是一个抽象的计算机器,它有自己的指令集和运行时内存管理机制。 JVM的主要职责: 加载:读取.class文件并验…...

MCP通信方式之Streamable HTTP
目录 一、前言二、三种传输方式对比1、Stdio和 HTTP SSE工作原理2、Streamable HTTP3、Streamable HTTP解决什么问题三、Streamable HTTP MCP设计原理四、Streamable HTTP MCP demo演示1、MCP server示例2、MCP Client示例一、前言 2025年5月9日,MCP(Model Context Protocol)…...

第七十三篇 从电影院售票到停车场计数:生活场景解析Java原子类精髓
目录 一、原子类基础:电影院售票系统1.1 传统售票的并发问题1.2 原子类解决方案 二、原子类家族:超市收银系统2.1 基础类型原子类2.2 数组类型原子类 三、CAS机制深度解析:停车场管理系统3.1 CAS工作原理3.2 车位计数器实现 四、高性能实践&a…...
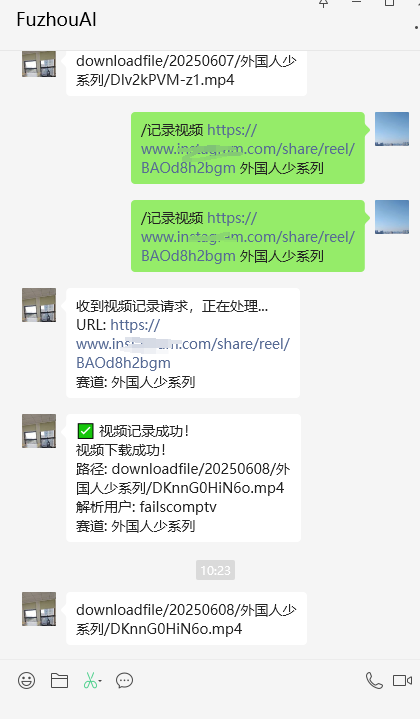
【原创】基于视觉模型+FFmpeg+MoviePy实现短视频自动化二次编辑+多赛道
AI视频处理系统功能总览 🎯 系统概述 这是一个智能短视频自动化处理系统,专门用于视频搬运和二次创作。系统支持多赛道配置,可以根据不同的内容类型(如"外国人少系列"等)应用不同的处理策略。 Ἵ…...
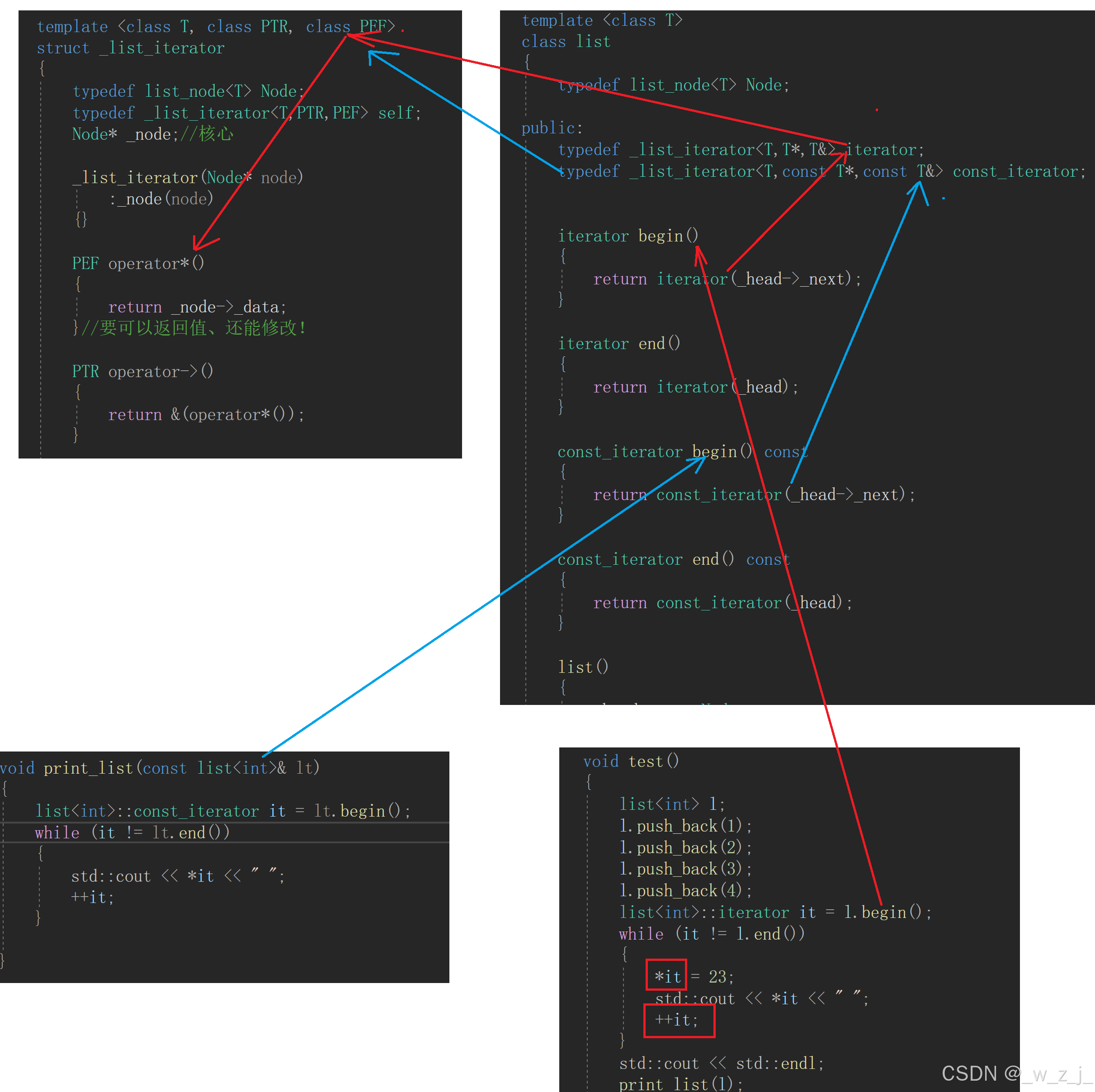
C++----剖析list
前面学习了vector和string,接下来剖析stl中的list,在数据库中学习过,list逻辑上是连续的,但是存储中是分散的,这是与vector这种数组类型不同的地方。所以list中的元素设置为一个结构体,将list设计成双向的&…...

纳米AI搜索与百度AI搜、豆包的核心差异解析
一、技术定位与设计目标 1、纳米AI搜索:轻量化边缘计算导向 专注于实时数据处理与资源受限环境下的高效响应,通过算法优化和模型压缩技术,实现在物联网设备、智能终端等低功耗场景的本地化部署。其核心优势在于减少云端依赖,保障…...

不到 2 个月,OpenAI 火速用 Rust 重写 AI 编程工具。尤雨溪也觉得 Rust 香!
一、OpenAI 用 Rust 重写 Codex CLI OpenAI 已用 Rust 语言重写了其 AI 命令行编程工具 Codex CLI,理由是此举能提升性能和安全性,同时避免对 Node.js 的依赖。他们认为 Node.js “可能让部分用户感到沮丧或成为使用障碍”。 Codex 是一款实验性编程代理…...

人工智能:网络安全的“智能守护者”
在数字化时代,网络安全已经成为企业和个人面临的重大挑战。随着网络攻击的复杂性和频率不断增加,传统的安全防护手段已经难以应对。人工智能(AI)技术的出现为网络安全带来了新的希望和解决方案。本文将探讨人工智能在网络安全中的…...
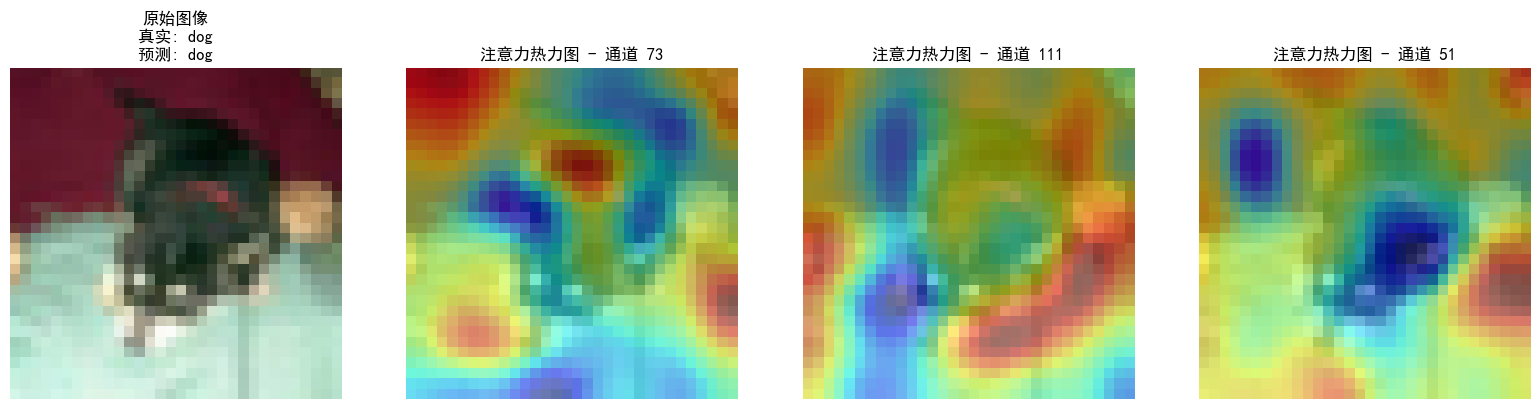
Python60日基础学习打卡Day46
一、 什么是注意力 注意力机制的由来本质是从onehot-elmo-selfattention-encoder-bert这就是一条不断提取特征的路。各有各的特点,也可以说由弱到强。 其中注意力机制是一种让模型学会「选择性关注重要信息」的特征提取器,就像人类视觉会自动忽略背景&…...

综述论文解读:Editing Large Language Models: Problems, Methods, and Opportunities
论文为大语言模型知识编辑综述,发表于自然语言处理顶会ACL(原文链接)。由于目前存在广泛的模型编辑技术,但一个统一全面的分析评估方法,所以本文: 1、对LLM的编辑方法进行了详尽、公平的实证分析,探讨了它们各自的优势…...
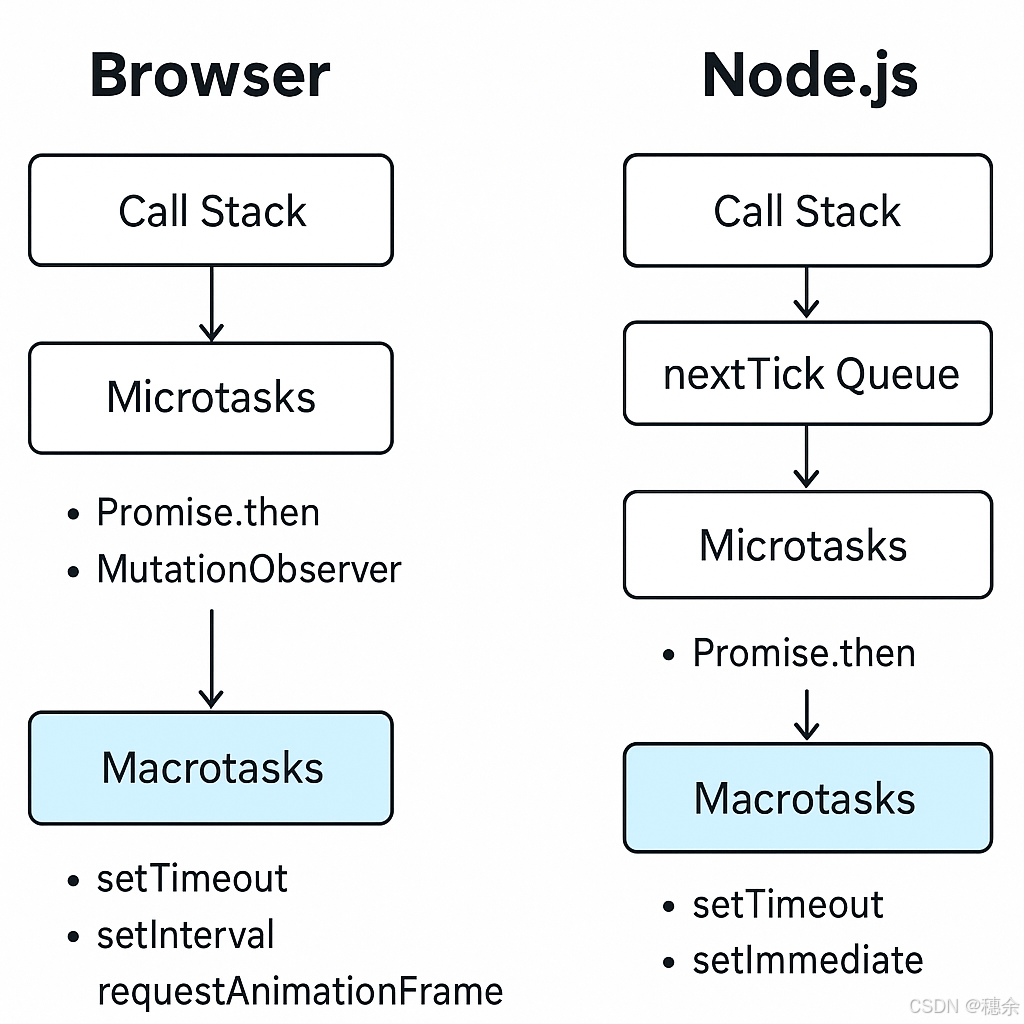
WEB3全栈开发——面试专业技能点P1Node.js / Web3.js / Ethers.js
一、Node.js 事件循环 Node.js 的事件循环(Event Loop)是其异步编程的核心机制,它使得 Node.js 可以在单线程中实现非阻塞 I/O 操作。 🔁 简要原理 Node.js 是基于 libuv 实现的,它使用事件循环来处理非阻塞操作。事件…...
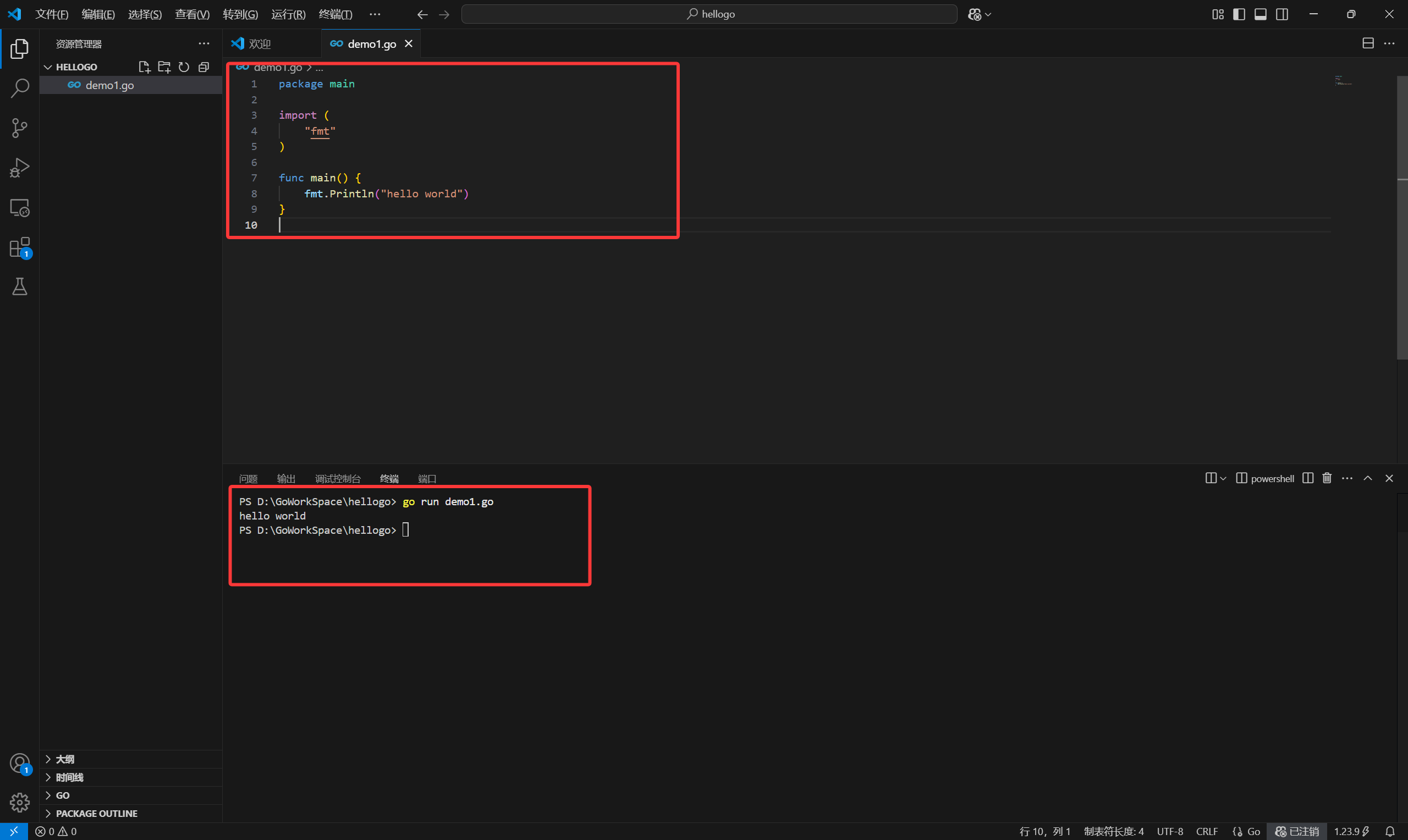
Vscode下Go语言环境配置
前言 本文介绍了vscode下Go语言开发环境的快速配置,为新手小白快速上手Go语言提供帮助。 1.下载官方Vscode 这步比较基础,已经安装好的同学可以直接快进到第二步 官方安装包地址:https://code.visualstudio.com/ 双击一直点击下一步即可,记…...

Java八股文——MySQL篇
文章目录 Java八股文——MySQL篇慢查询如何定位慢查询?如何分析慢SQLExplain标准答案 索引索引类型索引底层数据结构什么是聚簇索引什么是非聚簇索引?(二级索引)(回表)聚集索引选取规则回表查询 什么是覆盖…...

Oracle数据库学习笔记 - 创建、备份和恢复
Oracle数据库学习笔记 创建,备份和恢复 Oracle 版本基于11g 尽量不使用图形界面方式,操作适用于linux和windows 创建数据库 创建实例 # 步骤1:设置环境变量 export ORACLE_SIDmyorcl export ORACLE_HOME/u01/app/oracle/product/19.0.0/dbh…...
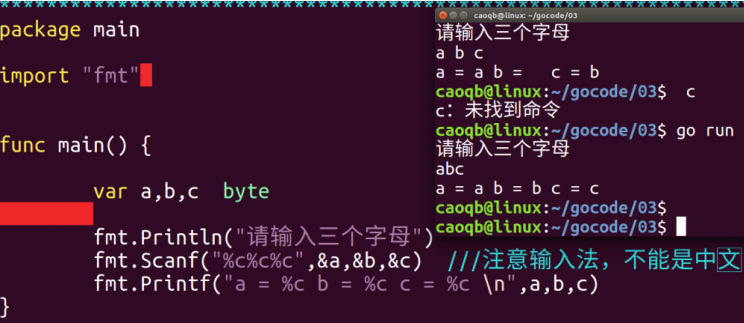
Go语言--语法基础5--基本数据类型--输入输出(1)
I : input 输入操作 格式化输入 scanf O : output 输出操作 格式化输出 printf 标准输入 》键盘设备 》 Stdin 标准输出 》显示器终端 》 Stdout 异常输出 》显示器终端 》 Stderr 1 、输入语句 Go 语言的标准输出流在打印到屏幕时有些参数跟别的语言…...

永磁同步电机无速度算法--自适应龙贝格观测器
一、原理介绍 传统龙伯格观测器,在设计观测器反馈增益矩阵K时,为简化分析与设计,根据静止两相坐标系下的对称关系,只引入了K、K,两个常系数,且在实际应用时,大多是通过试凑找到一组合适的反馈增益系数缺乏…...
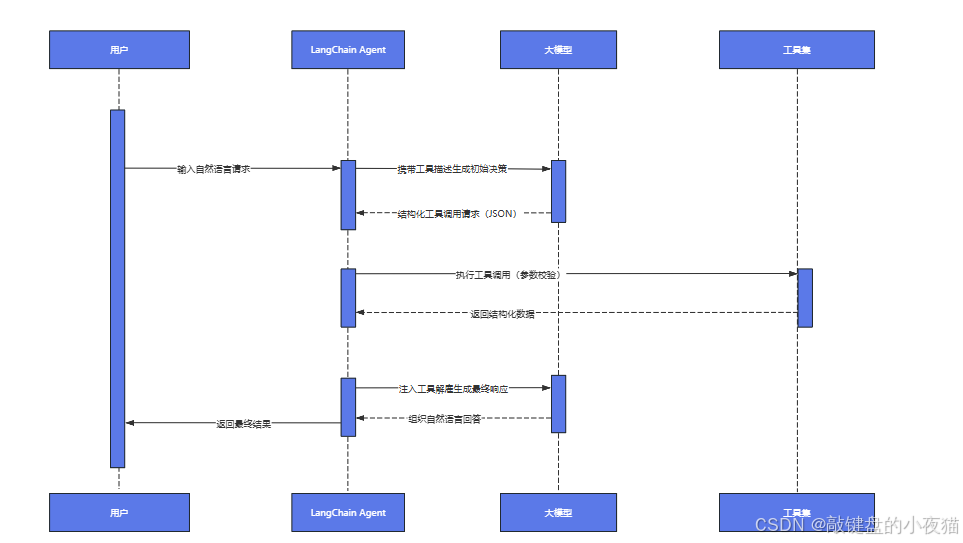
LangChain工具集成实战:构建智能问答系统完整指南
导读:在人工智能快速发展的今天,如何构建一个既能理解自然语言又能调用外部工具的智能问答系统,成为许多开发者面临的核心挑战。本文将为您提供一套完整的解决方案,从LangChain内置工具包的基础架构到复杂系统的工程实践。 文章深…...