pandas和polars简单的对比分析
pandas
pandas是基于python写的,底层的数据结构是Numpy数据(ndarray)。pandas自身有两个核心的数据结构:DataFrame和Series,前者是二维的表格数据结构,后者是一维标签化数组。
polars
polars是用Rust(一种系统级编程语言,具有非常好的并发性和性能)写的,支持Python、Rust和NodeJS。主要特性有:
- 快:Polars从零开始,没有任何扩展依赖,底层设计(import速度非常快)。
- I/O:完美支持常见的数据存储层:本地、云存储、数据库。
- 使用简单:使用它的内置操作,Polars内部决定使用最有效的方法执行。
- 核外:Polars支持使用它的streaming API操作核外数据转化。基于磁盘的内存映射技术,大数据下允许数据在磁盘和内存之间进行高效的交换。可以处理比机器可用RAM更大的数据集。
- 并行:Polars在不增加额外配置事,会充分利用机器可利用的cpu(可利用的所有核)。
- 矢量查询引擎:Polars使用Apache Arrow(一种列式数据格式,Arrow内存格式支持零拷贝读取,以实现闪电般快速的数据访问,而无需序列化开销)。以矢量的方式处理queries。它使用SIMD(单指令多数据,一种并行处理方式)优化CPU的利用。
pandas vs polars
-
性能:pandas提供了强大的数据分析功能,对处理小数据集更方便。polars利用多线程和内存映射技术,具有更快的速度,适合处理大型数据集。
-
内存使用:Pandas在加载数据时需要将其完全读入内存;polars支持streaming API操作核外数据转化,可以在处理大型数据集时降低内存使用,从而减少了内存限制。
-
数据操作:pandas具有丰富的数据操作和处理方法,使用DataFrame进行数据清洗、转换、分组、聚合等操作;Polars提供了类似于SQL的查询操作,使得对数据进行筛选、转换和聚合更加直观。
-
生态系统:pandas已经非常成熟,具有大量的学习文档、教程和扩展库;polars相对较新,对应的文档、教程等资源较少。
-
适用场景:pandas更适用于中小型数据集的数据分析和处理;polars更适用于大型数据集或追求更高性能的数据分析和处理场景。
运行时间对比
数据读取
# train.parquet: 2.35G
%time train_pd=pd.read_parquet('/Users/Downloads/archive/train.parquet') #Pandas dataframe
%time train_pl=pl.read_parquet('/Users/Downloads/archive/train.parquet') #Polars dataframe
CPU times: user 3.85 s, sys: 8.69 s, total: 12.5 s
Wall time: 10.4 s
CPU times: user 3.07 s, sys: 2.22 s, total: 5.29 s
Wall time: 3.39 s
聚合操作
%%time
# pandas query
nums = ["num_7", "num_8", "num_9", "num_10", "num_11", "num_12", "num_13", "num_14", "num_15"]
cats = ["cat_1", "cat_2", "cat_3", "cat_4", "cat_5", "cat_6"]
train_pd[nums].agg(['min','max','mean','median','std']) %%time
# Polars query
train_pl.with_columns([ pl.col(nums).min().suffix('_min'), pl.col(nums).max().suffix('_max'), pl.col(nums).mean().suffix('_mean'), pl.col(nums).median().suffix('_median'), pl.col(nums).std().suffix('_std'),
])
CPU times: user 6.06 s, sys: 4.19 s, total: 10.3 s
Wall time: 15.8 s
CPU times: user 4.51 s, sys: 5.49 s, total: 10 s
Wall time: 8.09 s
查询后计算
# Pandas filter and select
%time train_pd[train_pd['cat_1']==1][nums].mean()
# Polars filter and select
%time train_pl.filter(pl.col("cat_1") == 1).select(pl.col(nums).mean())
CPU times: user 730 ms, sys: 1.65 s, total: 2.38 s
Wall time: 4.24 s
CPU times: user 659 ms, sys: 3.22 s, total: 3.88 s
Wall time: 2.12 s
分类再聚合
%time Function_3= train_pd.groupby(['user'])[nums].agg('mean')
%time Function_3 = train_pl.groupby('user').agg(pl.col(nums).mean())
CPU times: user 2.4 s, sys: 938 ms, total: 3.33 s
Wall time: 3.46 s
CPU times: user 6.92 s, sys: 2.68 s, total: 9.6 s
Wall time: 1.78 s
分组的列逐渐增加
# PANDAS: TESTING GROUPING SPEED ON 5 COLUMNS
cols = []
for cat in ['user', 'cat_1', 'cat_2', 'cat_3', 'cat_4']:cols+=[cat] st=time.time() temp=train_pd.groupby(cols)['num_7'].agg('mean') en=time.time() print(f"{cat}:{round(en-st, 4)}s") # POLARS: TESTING GROUPING SPEED ON 5 COLUMNS
cols = []
for cat in ['user', 'cat_1', 'cat_2', 'cat_3', 'cat_4']: cols+=[cat] st=time.time() temp=train_pl.groupby(cols).agg(pl.col('num_7').mean()) en=time.time() print(f"{cat}:{round(en-st, 4)}s") 每增加一列进行groupby后计算,所需要的时间:
cols 耗时 [“user”] 0.7666s [“user”,“cat_1”] 1.8221s [“user”,“cat_1”,“cat_2”] 9.4581s [“user”,“cat_1”,“cat_2”,“cat_3”] 15.1409s [“user”,“cat_1”,“cat_2”,“cat_3”,“cat_4”] 16.5913s
cols 耗时 [“user”] 0.498s [“user”,“cat_1”] 1.1978s [“user”,“cat_1”,“cat_2”] 3.4107s [“user”,“cat_1”,“cat_2”,“cat_3”] 4.4749s [“user”,“cat_1”,“cat_2”,“cat_3”,“cat_4”] 4.6821s
排序
cols=['user','num_8'] # columns to be used for sorting
# Sorting in Pandas
%time a = train_pd.sort_values(by=cols,ascending=True)
#Sorting in Polars
%time b = train_pl.sort(cols,descending=False)
CPU times: user 31.9 s, sys: 7.28 s, total: 39.2 s
Wall time: 46.2 s
CPU times: user 32.2 s, sys: 7.04 s, total: 39.2 s
Wall time: 11.6 s
相关文章:

pandas和polars简单的对比分析
pandas pandas是基于python写的,底层的数据结构是Numpy数据(ndarray)。pandas自身有两个核心的数据结构:DataFrame和Series,前者是二维的表格数据结构,后者是一维标签化数组。 polars polars是用Rust(一种系统级编程…...

Feign远程调用的使用
假设已配好nacos服务:并且已配好userservice、orderservice,点击跳转 Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign,其作用就是在程序中帮助我们优雅的实现http请求的发送,…...

Postman API测试之道:不止于点击,更在于策略
引言:API测试的重要性 在当今的软件开发中,API已经成为了一个不可或缺的部分。它们是软件组件之间交互的桥梁,确保数据的流动和功能的实现。因此,对API的测试显得尤为重要,它不仅关乎功能的正确性,还涉及到…...

5G 数字乡村数字农业农村大数据中心项目农业大数据建设方案PPT
导读:原文《5G 数字乡村数字农业农村大数据中心项目农业大数据建设方案PPT》(获取来源见文尾),本文精选其中精华及架构部分,逻辑清晰、内容完整,为快速形成售前方案提供参考。以下是部分内容, 喜…...
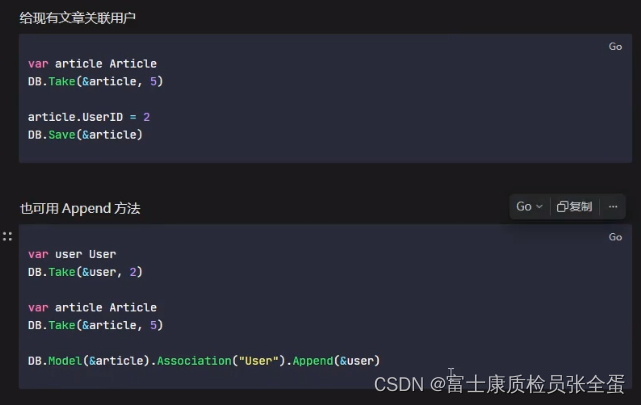
Golang Gorm 一对多的添加
一对多的添加有两种情况: 一种是添加用户的时候同时创建文章其次是创建文章关联已经存在的用户。 package mainimport ("gorm.io/driver/mysql""gorm.io/gorm" )// User 用户表 一个用户拥有多篇文章 type User struct {ID int64Name …...

图像扭曲之锯齿
源码: void wave_sawtooth(cv::Mat& src,cv::Mat& dst,double amplitude,double wavelength) {dst.create(src.rows, src.cols, CV_8UC3);dst.setTo(0);double xAmplitude amplitude;double yAmplitude amplitude;int xWavelength wavelength;int yWave…...
【分布式技术专题】「OSS中间件系列」Minio的文件服务的存储模型及整合Java客户端访问的实战指南
Minio的元数据 数据存储 MinIO对象存储系统没有元数据数据库,所有的操作都是对象级别的粒度的,这种做法的优势是: 个别对象的失效,不会溢出为更大级别的系统失效。便于实现"强一致性"这个特性。此特性对于机器学习与大数据处理非…...

构建个人博客_Obsidian_github.io_hexo
1 初衷 很早就开始分享文档,以技术类的为主,一开始是 MSN,博客,随着平台的更替,后来又用了 CSDN,知乎,简书…… 再后来是 Obsidian,飞书,Notion,常常有以下困…...

烟花厂人员作业释放静电行为检测算法
烟花厂人员作业释放静电行为检测算法通过pythonyolo系列算法模型框架,烟花厂人员作业释放静电行为检测算法在工厂车间入口处能够及时捕捉到人员是否触摸静电释放仪。一旦检测到人员进入时没有触摸静电释放仪,系统将自动触发告警。Python是一种由Guido va…...

ARTS挑战第二周-T:PHP数组相关操作
array_combine() 函数 合并两个数组 array_combine()传入2个参数,使用方法如下 array_combine(array $keys, array $values): array 返回一个 array,用来自 keys 数组的值作为键名,来自 values 数组的值作为相应的值。 array_key_exists() 函…...

【如何对公司网络进行限速?一个案例详解】
有不少朋友问到了关于企业网络QoS配置,这个确实在实际网络应用中非常多,基本上大部分企业或个人都用到这个功能,本期我们详细了解下QoS如何对宽带进行限制,QoS如何企业中应用。 一、什么是QoS? Qos是用来解决网络延迟和阻塞等问…...
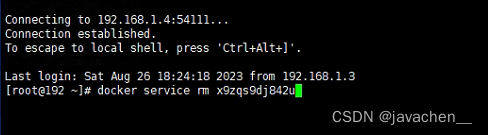
服务器安全-修改默认ssh端口
防火墙先打开指定端口,要不修改后连不上(端口需要在65535之内) firewall-cmd --list-ports firewall-cmd --add-port54111/tcp --permanent firewall-cmd --reload-------------------- 先让两个端口同时存在,等配置成功后关闭22端口 vim /etc/ssh/sshd_config重启sshd service…...
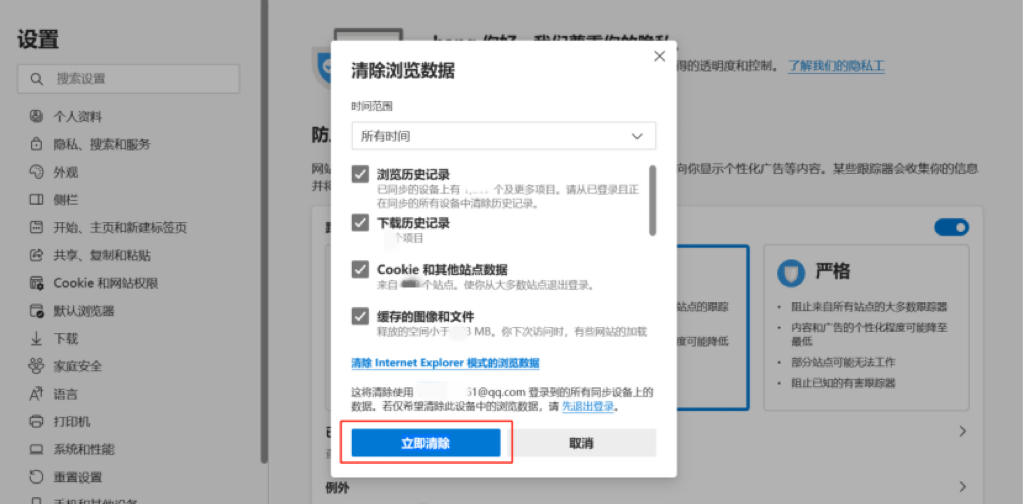
保护隐私的第一步:从更新浏览器开始
当今社会已经进入了数字化和网络化的时代,而网络安全问题也日益突显。随着互联网在我们生活中的不断渗透,网络威胁变得愈发普遍和隐蔽。在这样的背景下,网络浏览器作为人们访问互联网的主要工具之一,不仅为我们提供了便捷的上网方…...

Python爬虫框架之快速抓取互联网数据详解
概要 Python爬虫框架是一个能够帮助我们快速抓取互联网数据的工具。在互联网时代,信息爆炸式增长,人们越来越需要一种快速获取信息的方式。而Python爬虫框架就能够帮助我们完成这个任务,它可以帮助我们快速地从互联网上抓取各种数据…...

【算法专题突破】双指针 - 盛最多水的容器(4)
目录 1. 题目解析 2. 算法原理 3. 代码编写 写在最后: 1. 题目解析 题目链接:11. 盛最多水的容器 - 力扣(Leetcode) 这道题目也不难理解, 两边的柱子的盛水量是根据短的那边的柱子决定的, 而盛水量…...
循环神经网络(RNN) | 项目还不成熟 |还在初级阶段
一,定义 循环神经网络(Recurrent Neural Network,RNN)是一种深度学习神经网络架构,专门设计用于处理序列数据,如时间序列数据、自然语言文本等(一般用来解决序列问题)。 因为它们具…...
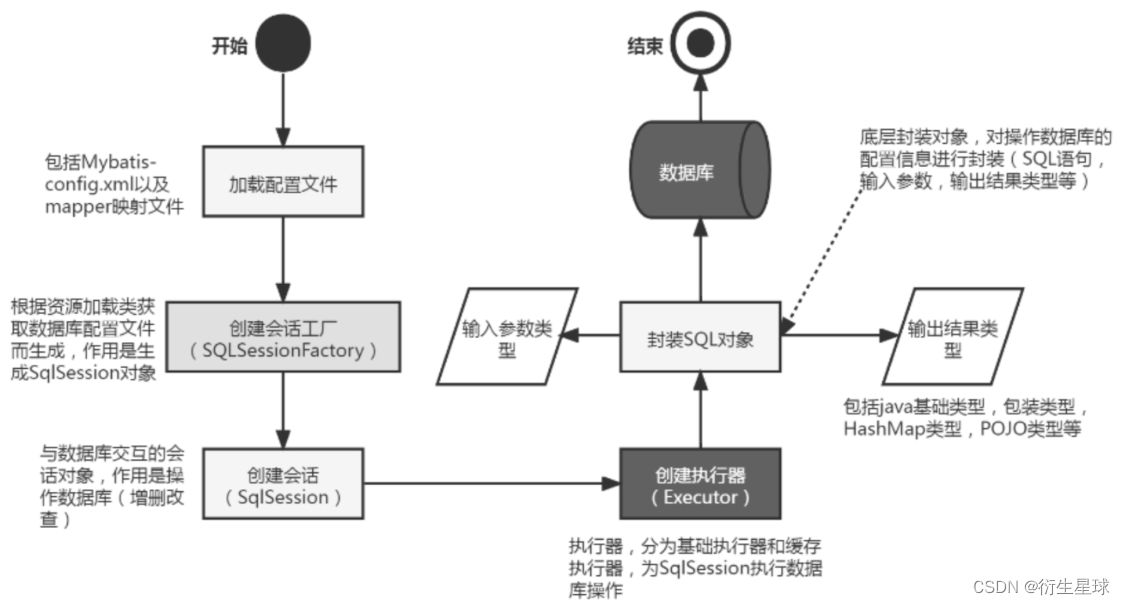
【Spring Boot】数据库持久层框架MyBatis — MyBatis简介
MyBatis简介 本节首先会介绍什么是ORM、什么是MyBatis、MyBatis的特点以及核心概念,最后介绍MyBatis是如何启动、如何加载配置文件的? 1.什么是ORM ORM(Object Relational Mapping,对象关系映射)是为了解决面向对象…...
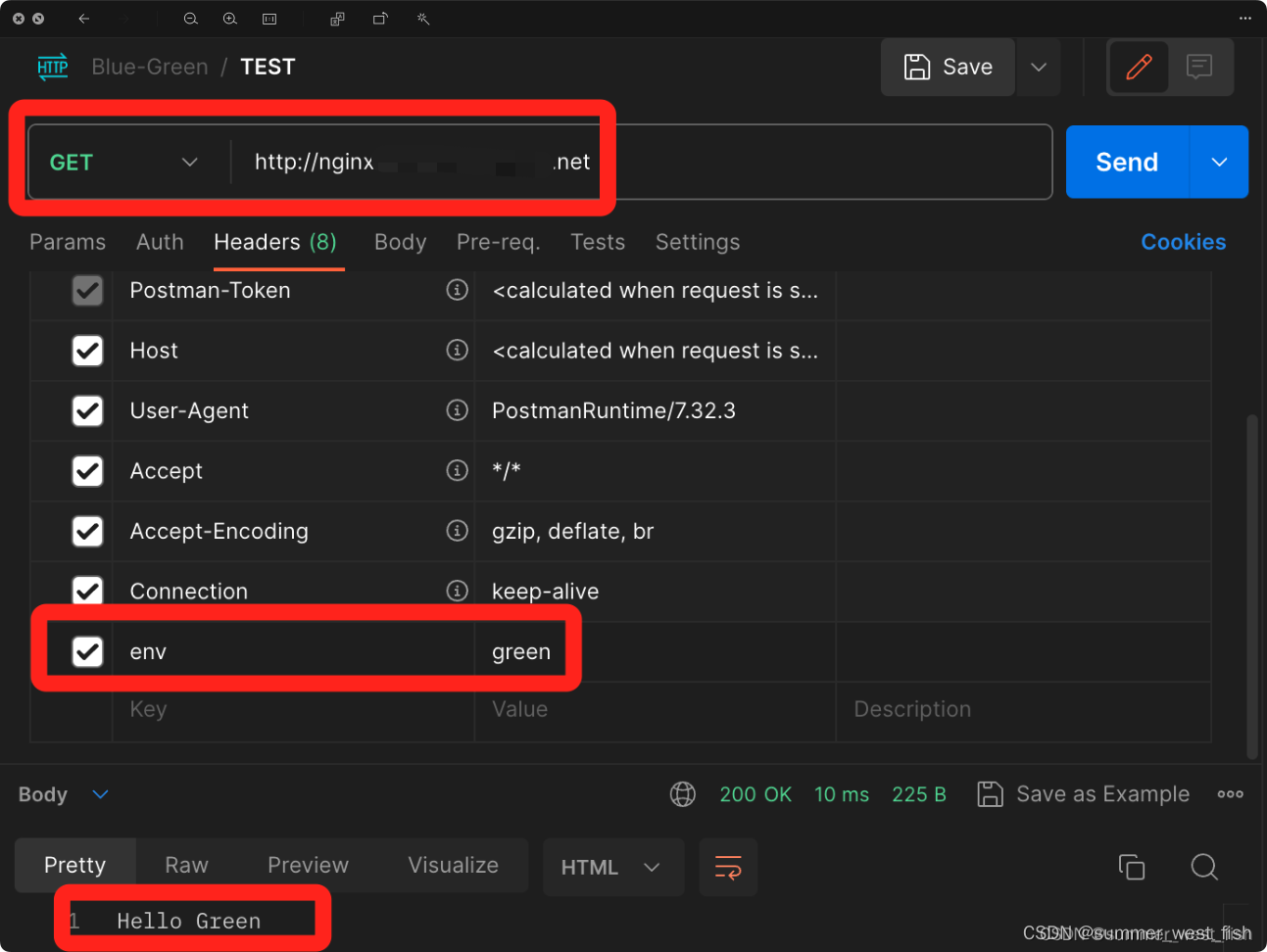
K8S Nginx Ingress实现金丝雀发布
通过给 Ingress 资源指定 Nginx Ingress 所支持的 annotation 可实现金丝雀发布。 需给服务创建2个 Ingress,其中1个常规 Ingress,另1个为带 nginx.ingress.kubernetes.io/canary: "true" 固定的 annotation 的 Ingress,称为 Cana…...
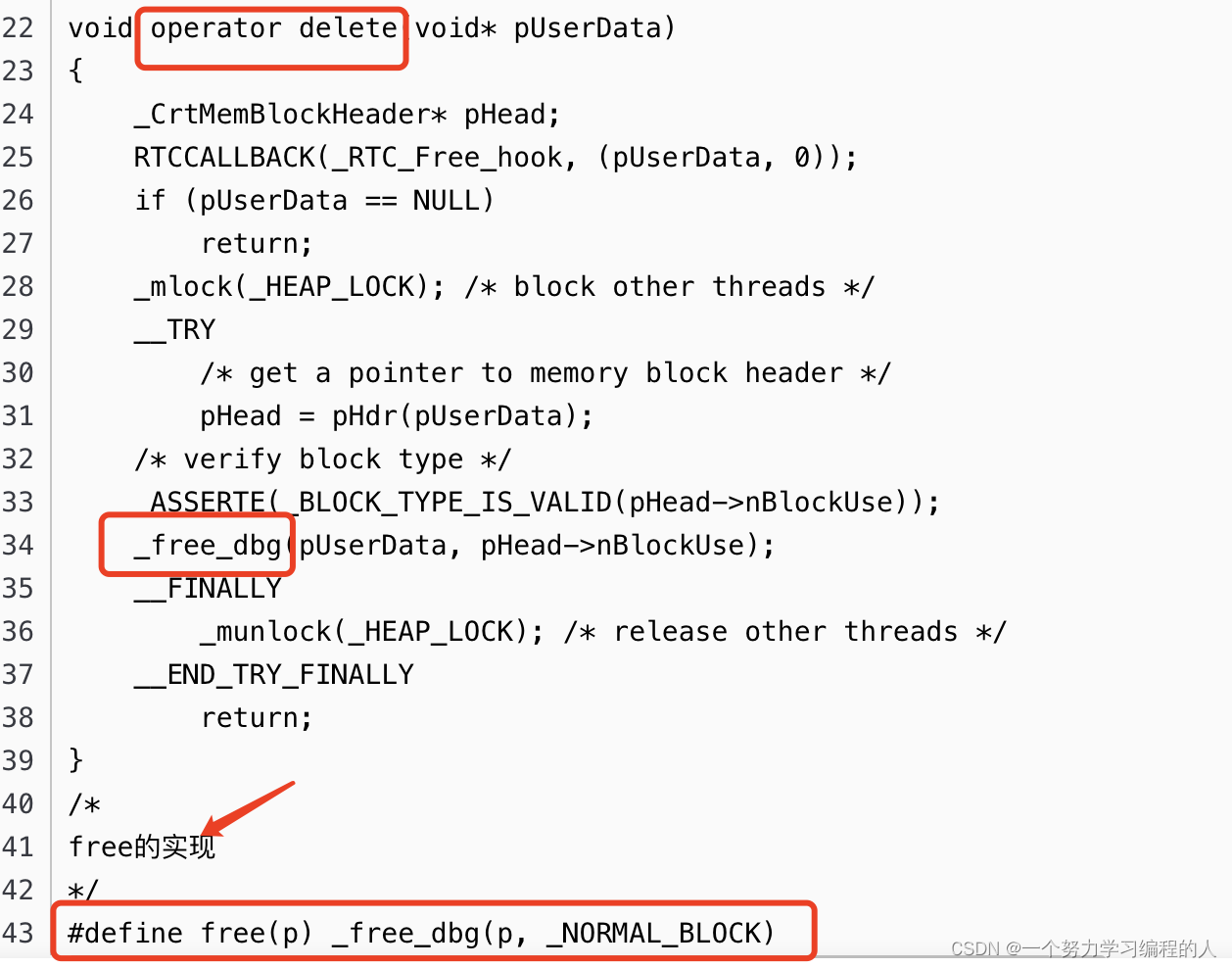
【C++入门】new和delete(C/C++内存管理)
目录 1.C/C内存分布2.C语言中动态内存管理方式3.C内存管理方式3.1new/delete操作内置类型3.2new和delete操作自定义类型 4.operator new与operator delete函数5.new和delete的实现原理5.1内置类型5.2自定义类型 6.malloc/free和new/delete的区别7.定位new表达式(了解…...
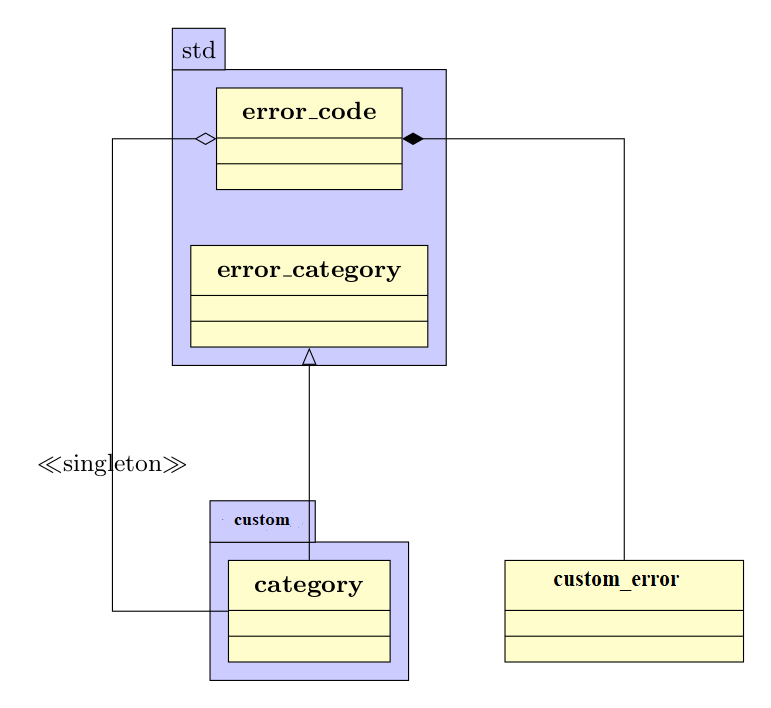
C++设计模式之桥接模式
文章目录 一、桥接模式二、std::error_code与设计模式(桥接模式)参考 一、桥接模式 在C中,桥接模式通常涉及以下几个角色: 抽象类接口(Abstraction):定义抽象部分的接口,并维护一个…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

Onekey:重构Steam Depot清单下载流程的现代化解决方案
Onekey:重构Steam Depot清单下载流程的现代化解决方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey作为一款专为Steam Depot清单设计的自动化下载工具,通过其创…...

AI增强型写作工具Hermes-Writer:为开发者打造的智能写作助手
1. 项目概述:一个面向开发者的智能写作助手最近在GitHub上看到一个挺有意思的项目,叫dav-niu474/Hermes-Writer。乍一看标题,你可能会觉得这又是一个普通的Markdown编辑器或者写作工具。但如果你点进去,仔细研究一下它的README、代…...

Argo Workflows:Kubernetes原生工作流引擎从入门到生产实践
1. 项目概述:一个开源的容器化工作流引擎如果你在云原生、数据科学或者自动化运维领域摸爬滚打过一阵子,大概率听说过 Argo。它不是某个游戏里的角色,而是一个在 Kubernetes 生态中,用来编排和运行复杂工作流的强大引擎。简单来说…...

如何在Chrome浏览器中快速生成与解析二维码:Chrome QRCode插件终极指南
如何在Chrome浏览器中快速生成与解析二维码:Chrome QRCode插件终极指南 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的…...

AI代码管理器:统一多模型编程助手,提升开发效率与代码质量
1. 项目概述:一个面向开发者的多模型代码管理技能最近在折腾AI编程助手,发现一个挺有意思的现象:很多开发者手头可能同时用着Claude、CodeGemini这类工具,但每次切换都得重新配置环境、调整提示词,甚至要处理不同模型输…...

低成本接入GPT-4级能力:从开源模型自建到安全API实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫a37836323/-chatgpt4.0-api-key。光看这个标题,很多朋友可能会立刻联想到“免费API密钥”、“共享资源”之类的。确实,在AI工具日益普及的今天,如何高效、低成本地使…...

2026年十大最佳地区搜索排名优化工具:权威榜单赋能企业高效增长
本文全面梳理了2026年十大主流地区搜索排名优化工具的核心功能与应用价值,旨在为本地企业提供客观、实用的选型参考。通过对各工具地域关键词布局、多平台同步能力及实时数据监控等关键模块的解析,结合具体参数指标与套餐定价,系统呈现不同场…...